岭回归怎么做:SPSSAU操作步骤与结果解读
一、岭回归方法所属模块
岭回归在SPSSAU中属于【进阶方法】模块。
二、方法概述
岭回归主要用于处理自变量之间相关性较强、普通回归系数不稳定的场景。它常见于指标较多、变量彼此关系紧密的研究中,适合在解释关系的同时提升模型稳定性。
三、变量设置规则
岭回归需要设置1个因变量和至少1个自变量,变量框共2类,均为必填项。
1. 因变量设置
(1)变量类型:因变量只能放入定量变量。
(2)放入数量:仅可放入1个。
(3)是否必填:必填,不可留空。
2. 自变量设置
(1)变量类型:自变量可放入定量变量或定类变量。
(2)放入数量:至少放入1个,最多可放入200个。
(3)是否必填:必填,至少需要1个自变量才能开展分析。
四、参数设置及解释说明
岭回归在SPSSAU中可设置K值,并可选择是否保存残差和预测值。不同设置会影响输出结果的呈现方式与后续使用。
1. K值设置
(1)是否必须填写:不是必填项,可以先不填。
(2)参数含义:K值用于帮助确定岭回归模型的稳定程度,是岭回归分析中的关键调节参数。
(3)如何选择:如果暂时无法确定合适的K值,可以先不输入,系统会先输出岭迹图和VIF值相关结果,用于辅助判断;如果已经有明确的K值,可直接输入并输出对应模型结果。
2. 保存残差和预测值
(1)设置方式:通过勾选方式启用。
(2)参数含义:勾选后,系统会把残差和预测值分别保存下来,便于后续继续查看或开展其他分析。
(3)使用提醒:启用后每次分析都会生成新的保存结果,适合需要保留过程数据或继续做诊断分析的场景。
五、分析结果表格及其解读
岭回归在SPSSAU中会根据是否输入K值输出不同结果,常见结果包括岭迹图中间过程值表、模型汇总表、ANOVA表格、回归结果表、简化结果表,以及样本缺失情况汇总表。
1. 表1:岭迹图中间过程值(标准化回归系数值)
该表用于观察不同K值下各自变量标准化回归系数的变化趋势,是判断系数是否逐步稳定的重要依据。表中主要包含K值以及各自变量对应的标准化回归系数。
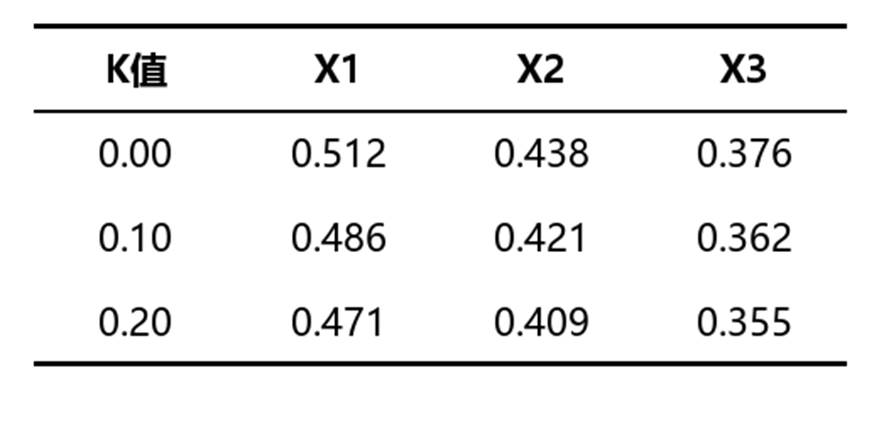
• K值:表示岭参数的取值水平,作用是配合查看模型在不同参数下的稳定性。判断时通常不是单看大小,而是结合各系数变化是否趋于平稳来综合确定。
• 标准化回归系数值:表示各自变量对因变量影响方向和相对强弱的稳定表现。若随着K值变化,系数波动明显收敛并趋于平缓,说明模型逐渐稳定;若波动仍很大,往往说明K值还需继续观察。
2. 表2:岭迹图中间过程值(VIF值)
该表用于观察不同K值下多重共线性的缓解情况,包含K值、VIF最大值以及各自变量对应的VIF值。
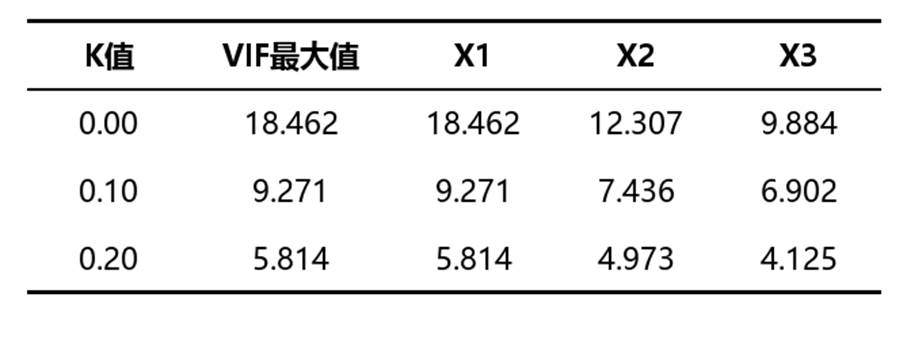
• VIF最大值:表示当前K值下所有自变量中共线性最严重的水平,作用是快速判断模型整体共线性是否得到改善。一般来说,VIF越小越好;若已明显下降并处于较低水平,说明K值设置更合适。
• 各变量VIF值:用于分别查看每个自变量的共线性情况。若大多数变量的VIF都随K值增加而下降并趋稳,说明岭回归确实起到了缓解共线性的作用。
3. 表3:模型汇总
该表用于整体查看岭回归模型的拟合情况,包含样本量、R²、调整R²和模型误差RMSE等指标。
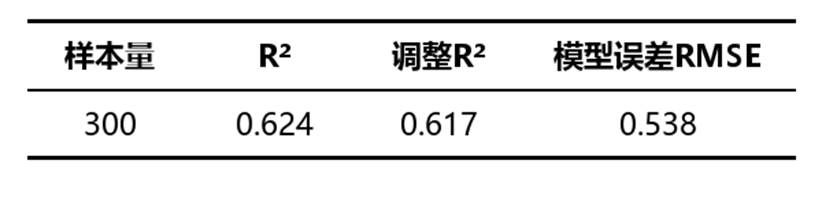
• 样本量:表示实际进入模型分析的有效样本数,作用是帮助判断结果是否建立在足够样本基础上。样本量越充分,模型结果通常越稳健。
• R²:表示自变量对因变量变动的解释程度,作用是衡量模型整体解释力。数值越接近1,说明解释效果越强;若数值较低,则说明模型解释力度有限。
• 调整R²:是在考虑自变量数量后对解释力做出的修正,作用是更稳妥地评价模型质量。若它与R²差距较小,说明模型较稳定;差距较大则提示变量加入后带来的有效解释并不充分。
• 模型误差RMSE:表示模型预测误差的整体水平,作用是衡量模型预测偏差。该值越小越好,说明模型预测结果与实际情况越接近。
4. 表4:ANOVA表格
该表用于检验整个岭回归模型是否具有统计意义,包含平方和、df、均方、F值和p值等指标。
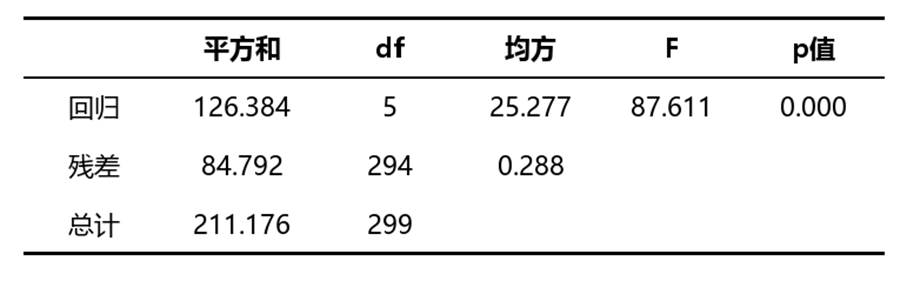
• F值:用于判断模型整体是否有效,也就是自变量整体能否对因变量产生解释作用。F值通常需要结合p值一起判断,不能单独下结论。
• p值:表示模型整体显著性的判断依据。通常当p值小于0.05时,可认为模型整体具有统计意义;若大于等于0.05,则说明整体解释作用不显著。
• 平方和与均方:这两类指标主要用于构成整体检验结果,实务中更常配合F值和p值理解模型是否成立。
5. 表5:Ridge回归分析结果
该表是岭回归的核心结果表,用于查看各自变量对因变量的影响方向、影响大小、显著性以及共线性水平,包含B、标准误、Beta、t值、p值和VIF值等指标。
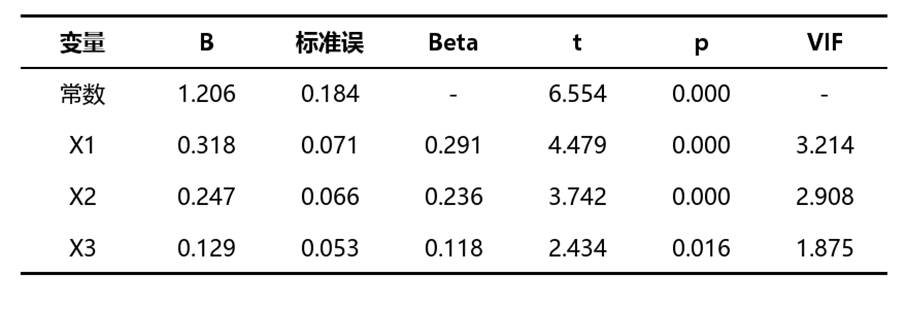
• B:表示非标准化回归系数,作用是判断自变量对因变量影响的方向和变化幅度。若B为正,说明正向影响;若B为负,说明负向影响。判断是否有实际解读意义时,要结合p值一起看。
• 标准误:表示回归系数的波动程度,作用是辅助判断系数稳定性。通常标准误越小,说明估计越稳定。
• Beta:表示标准化回归系数,作用是比较不同自变量对因变量影响强弱。绝对值越大,通常说明影响相对越强。
• t值:用于辅助判断单个自变量是否显著。实务中通常不单独看t值,而是配合p值使用。
• p值:用于判断单个自变量的影响是否显著。通常p值小于0.05,说明该变量对因变量具有显著影响;大于等于0.05,则说明影响不显著。
• VIF值:表示该自变量的共线性程度,作用是检查岭回归后共线性是否得到控制。一般来说,VIF越小越好;若仍偏高,说明变量间相关性问题仍需关注。
6. 表6:Ridge回归分析结果-简化格式
该表以更精简的方式呈现核心结果,主要用于快速汇报,包含回归系数、VIF值,以及样本量、R²、调整R²、F值等关键信息。
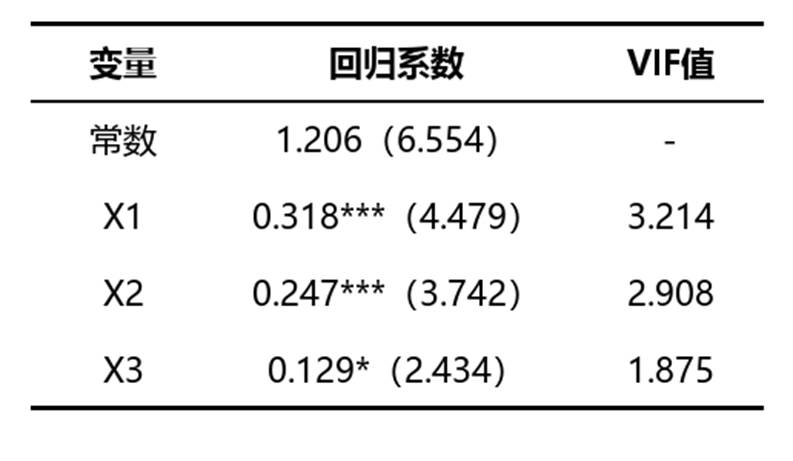
• 回归系数:用于快速查看各变量影响方向、大小及显著性标记,适合做汇报展示。若系数方向明确且显著性达标,可直接用于结论表达。
• VIF值:用于同步查看变量共线性是否控制在合理水平。数值较低时,说明模型稳定性更好。
• 样本量、R²、调整R²、F值:这些指标共同用于快速判断模型是否可用、解释力如何、整体是否显著。实际解读时可与完整结果表相互印证。
7. 表7:样本缺失情况汇总
该表用于说明最终参与分析的样本保留情况,包含有效样本、排除无效样本以及总计。
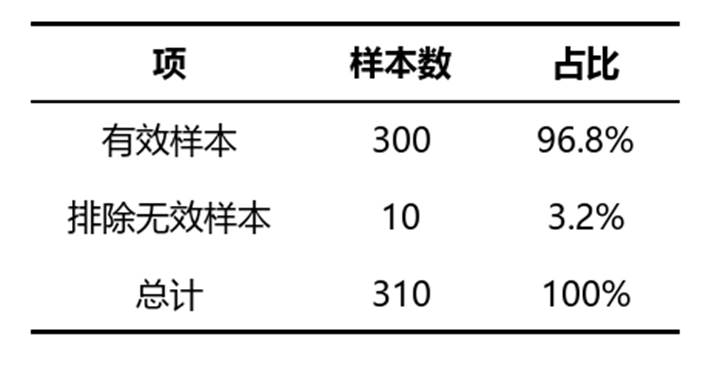
• 有效样本:表示最终进入岭回归分析的数据量,作用是确认模型建立所依据的实际样本规模。有效样本占比越高,通常说明数据可用性越好。
• 排除无效样本:表示因缺失或不满足分析要求而被剔除的数据量,作用是帮助判断数据损失程度。若占比过高,需关注样本代表性是否受影响。
• 占比:用于直观展示有效与无效样本所占比例。一般希望有效样本占比较高,这样结果更具参考价值。
六、分析结果图表及其解读
岭回归在SPSSAU中会输出用于判断K值或展示模型关系的图表,常见包括岭迹图和模型结果图。
1. 岭迹图
岭迹图用于观察不同K值下各自变量回归系数的变化轨迹,核心用途是辅助确定合适的K值。解读时重点看各条曲线是否由波动明显逐步转向平稳:如果多条曲线在某一区间开始趋于稳定,且VIF也同步下降,通常说明该区间的K值更适合;如果曲线仍明显起伏,则说明还需要继续观察。
2. 模型结果图
模型结果图用于展示自变量与因变量之间的影响关系,便于直观看到各变量作用方向和强弱。解读时可重点关注连线对应的系数方向及大小:若系数为正,说明正向影响;若系数为负,说明负向影响;若数值更大且显著,一般说明该变量在模型中的作用更突出。
以上就是SPSSAU岭回归方法的相关内容,更深入教程可查看SPSSAU帮助手册、教学视频、疑难解惑等资料。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)