VLA 进入涌现时代!π0.7发布:组合泛化、长程灵巧操作与跨本体迁移全面实现

多模态上下文prompt + 混合质量数据学习 + 跨本体对齐机制
——新一代可引导通用机器人基础模型
目录
02 π0.7:多模态上下文prompt,重新定义VLA学习范式
06 从“执行模型”到“智能体”,π₀.₇定义下一代VLA标准
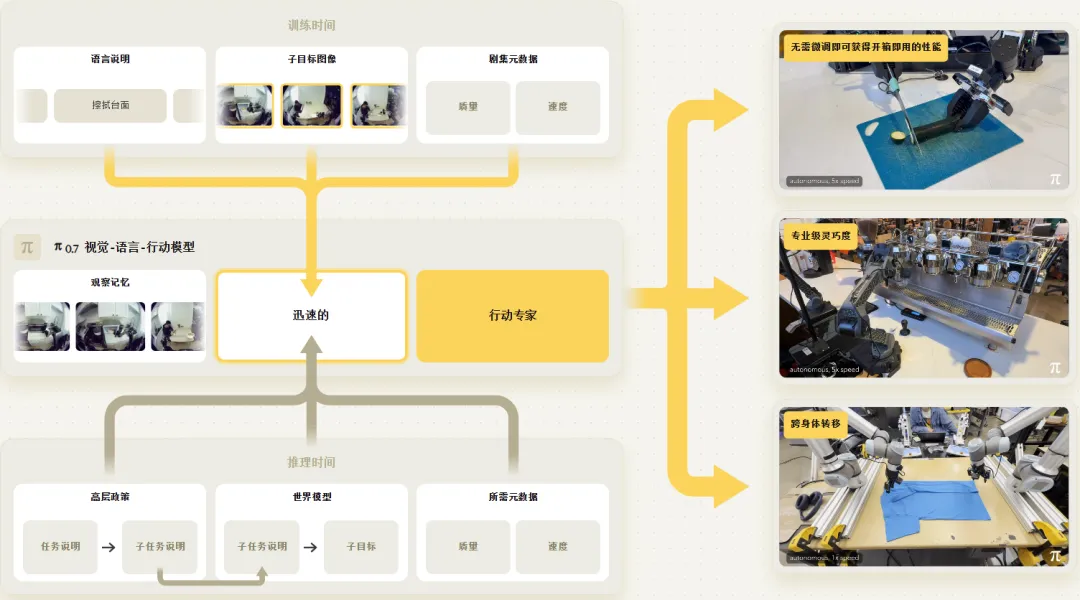
今日,Physical Intelligence 正式发布 π 系列最新机器人基础模型 π0.7,同步公开技术报告。
从π₀、π₀.₅到π₀.₆已经证明,统一视觉、语言与动作的大模型范式,能够让机器人在多任务、多环境下完成基础操作,成为具身智能最具落地潜力的技术路线。
但行业始终面临一个难以绕过的瓶颈:通用化与精细化、鲁棒性与泛化性始终难以兼顾。
π₀.₇没有选择堆叠更大参数量或引入全新网络结构,而是从prompt 工程、数据利用、上下文建模三个核心维度重新设计VLA框架。

它首次将“任务指令+子任务指令+子目标图像+任务元数据”多模态信息融入prompt,让模型能从混合质量、多源异构数据中学习,同时实现开箱即用的精细操作、跨本体零样本迁移与 compositional 泛化。
01 前作局限:π系列三代模型的共性瓶颈
在π₀.₇之前,π₀、π₀.₅、π₀.₆已经奠定了VLA在机器人操控领域的基础范式,但三者均存在明确的技术短板:
- prompt 信息单一,无法利用异构数据
前三代模型仅依赖顶层任务文本指令作为上下文,无法区分数据质量、执行速度、操作正误。这导致模型只能从高质量演示数据学习,无法利用次优数据、失败数据与自主探索数据,数据利用率极低。

▲π₀架构
- 缺乏细粒度引导,长程与精细任务表现差
没有子任务分解与子目标视觉引导,模型在折叠衣物、操作咖啡机、组装纸箱等精细长程任务中,容易丢失步骤、动作粗糙,必须经过任务专属微调才能达到可用精度。

▲π₀长程任务
- 跨本体泛化能力弱,零样本迁移几乎不可行
模型与机器人本体强绑定,针对双臂机器人训练的策略,无法直接迁移到单臂、长轴、高负载机械臂,跨形态迁移需要大量目标本体数据微调。
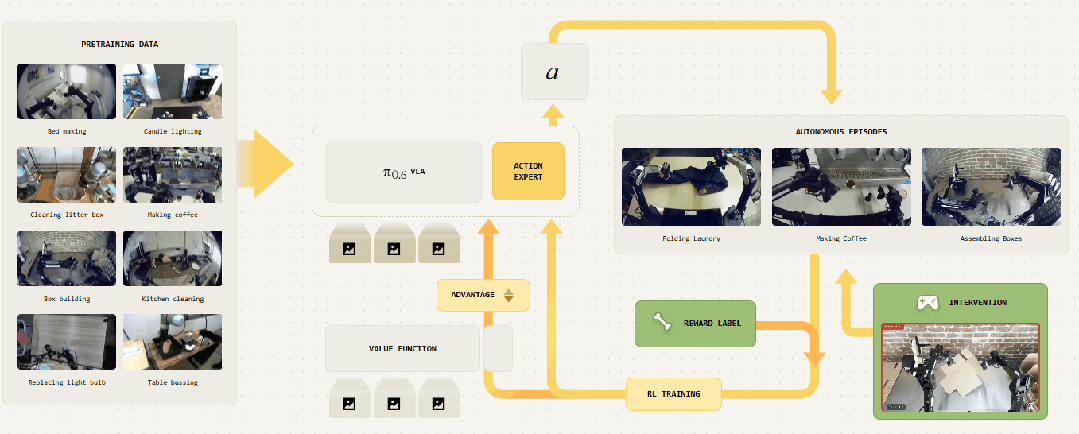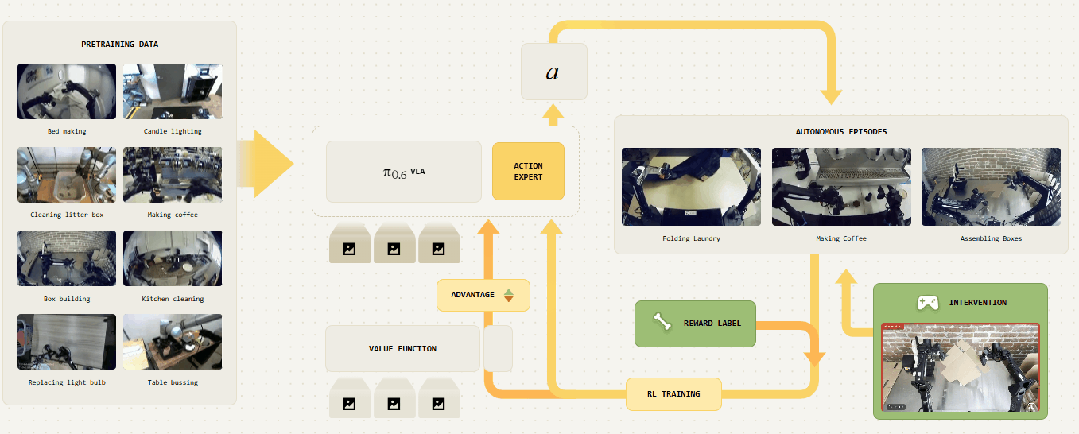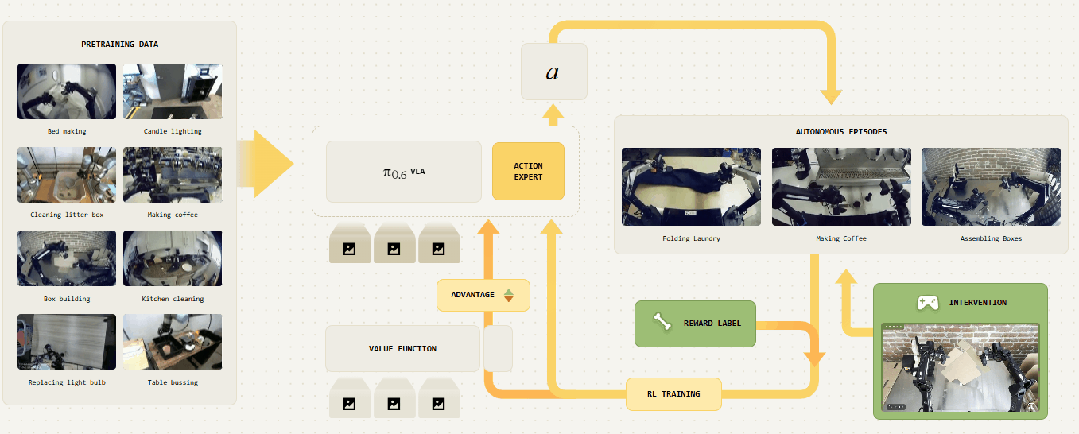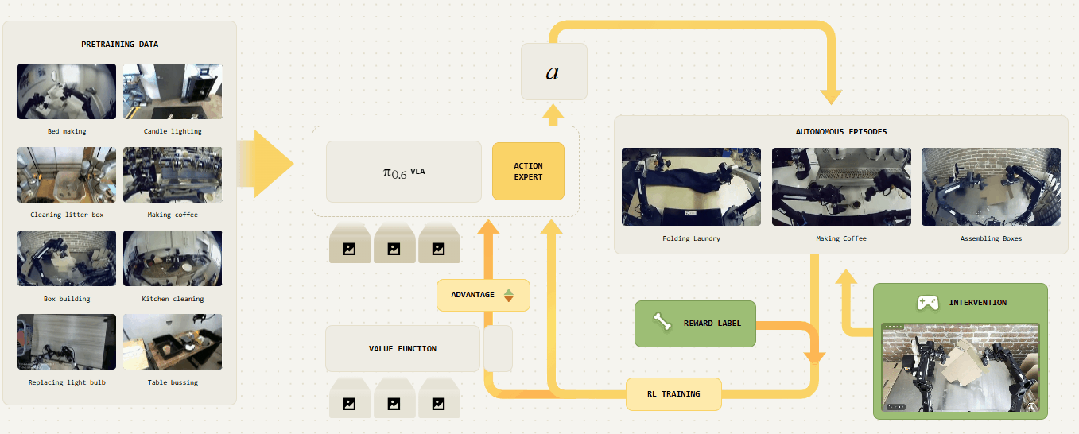
▲π₀.₆架构
- 无法 compositional 泛化,技能无法自由组合
模型只能复现训练过的任务,无法将“打开容器”“放置物体”“关闭设备”等基础技能组合成全新任务,不具备真正的通用推理能力。
02 π0.7:多模态上下文prompt,重新定义VLA学习范式
π₀.₇的设计目标,正是针对性解决以上全部瓶颈,同时保持模型架构兼容、推理效率可控。
π₀.₇的所有能力升级,都源于一个极简的核心设计:用丰富多模态上下文替代单一文本指令,让模型理解“做什么、怎么做、做得好不好”。
模型整体仍基于VLA架构,以Gemma3 4B作为VLM主干,搭配860M参数flow matching动作专家,总参数量约5B,延续了π系列轻量化高效的风格。
但在上下文输入层面,π₀.₇做了颠覆性扩展。
四层prompt结构:文本+视觉+元数据+控制模式
π₀.₇构建了统一的多模态prompt体系,包含四类互补信息:

▲提示词概览
- 任务指令+子任务指令:顶层目标+分步语义目标,实现长程任务拆解;
- 多视角子目标图像:视觉化下一阶段目标状态,提供空间执行依据;
- 任务元数据:执行速度、任务质量、是否出错,用于区分数据优劣;
- 控制模式:关节空间/末端执行器控制,适配不同机器人本体。
训练时随机dropout不同组件,让模型在推理时可灵活组合输入,支持纯文本、文本+图像、全模态等多种prompt方式。
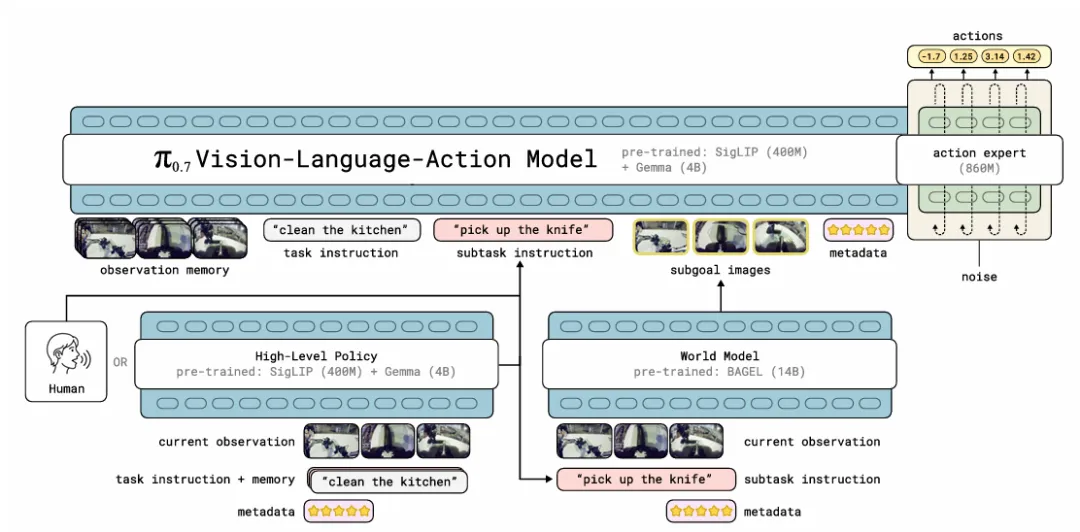
▲模型架构总览
子目标图像:从语言语义到视觉空间的精准对齐
仅靠语言指令无法传递空间细节,例如“打开冰箱门”无法告诉机器人抓取角度、姿态与轨迹。
π₀.₇引入由轻量级世界模型(BAGEL 14B)生成的多视角子目标图像,将语义目标转化为视觉目标。
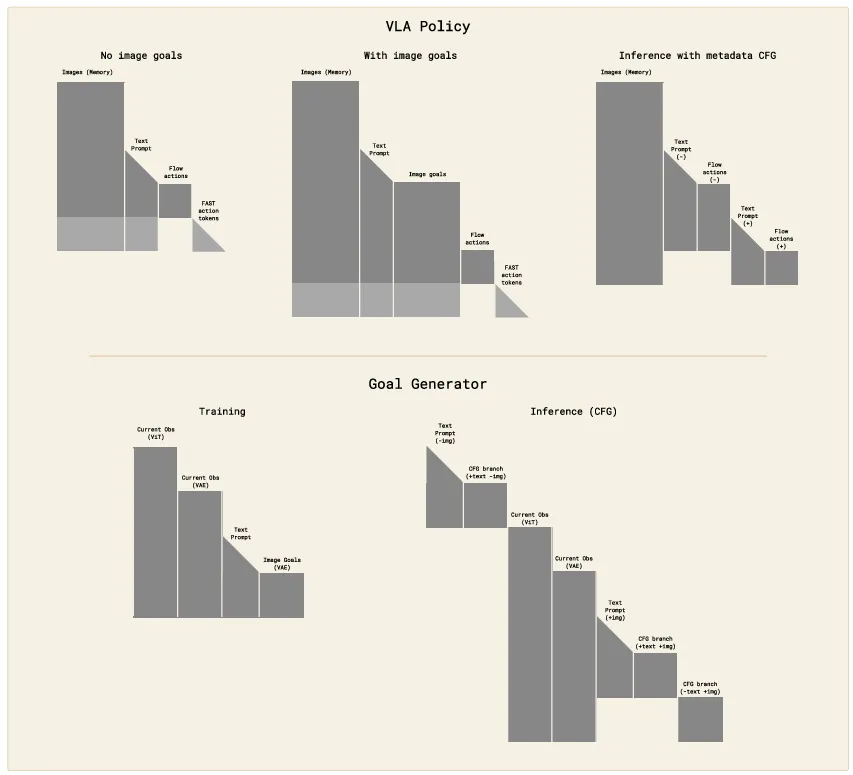
▲π0.7 模型与世界模型注意力模式
这一设计带来两个关键收益:
- 动作预测简化为“从当前帧到子目标帧”的逆动力学问题,学习更稳定;
- 跨本体迁移时,子目标图像提供统一空间目标,弱化本体形态差异。
任务元数据:让模型学会从“好坏数据”中学习
这是π₀.₇最具“工程价值”的创新——传统VLA必须过滤低质量数据,而π₀.₇通过元数据标注:
- 执行速度(episode步数)
- 整体质量评分(1–5)
- 是否存在操作错误
模型可以直接学习失败案例、次优演示与自主探索数据,实现“从所有经验中学习”,大幅降低数据采集成本。
先文本鲁棒、后视觉精调的训练策略
与STRONG-VLA的解耦思想相似,π₀.₇在训练中也采用分步强化:
- 先学习语言指令与元数据,建立任务语义与执行策略的关联;
- 再引入子目标图像,优化空间操控精度。
这种分步策略避免了多模态输入的梯度冲突,训练更稳定。
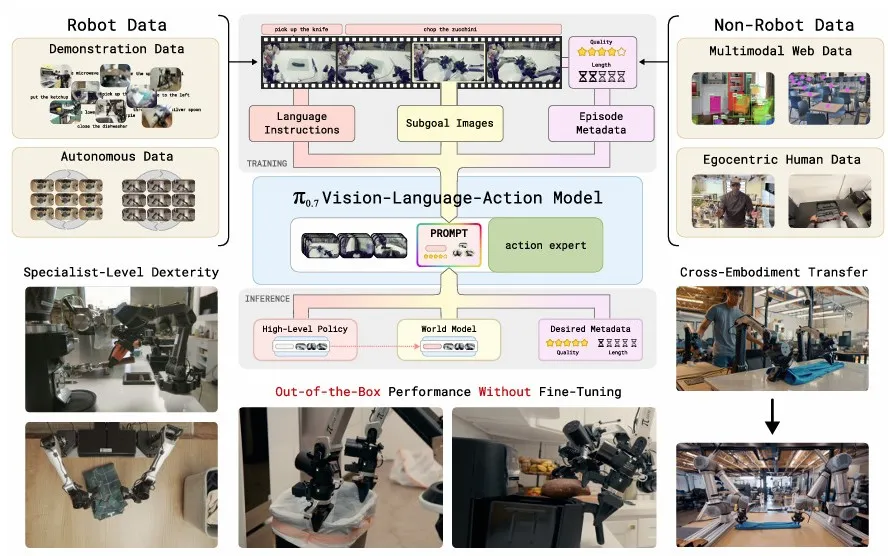
▲π₀.₇通用机器人基础模型总览
03 能力跃迁:与前作π₀.₆的核心对比
π₀.₇并非简单的性能迭代,而是在能力维度上实现了代际跨越,以下为与π₀.₆的关键差异:
开箱即用性能:无需微调即可匹敌RL专家模型
π₀.₆需要针对每个精细任务做RL微调才能达到高成功率;
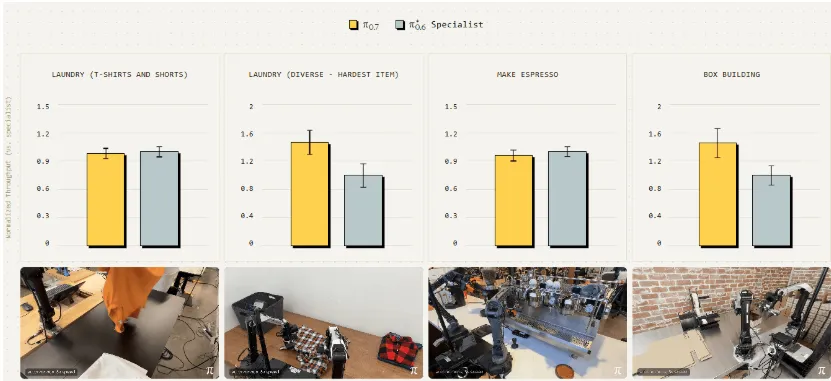
π₀.₇开箱即用,在制作意式咖啡、折叠衣物、组装纸箱、削蔬菜等任务上,成功率与吞吐量直接匹配π₀.₆* RL微调专家模型。
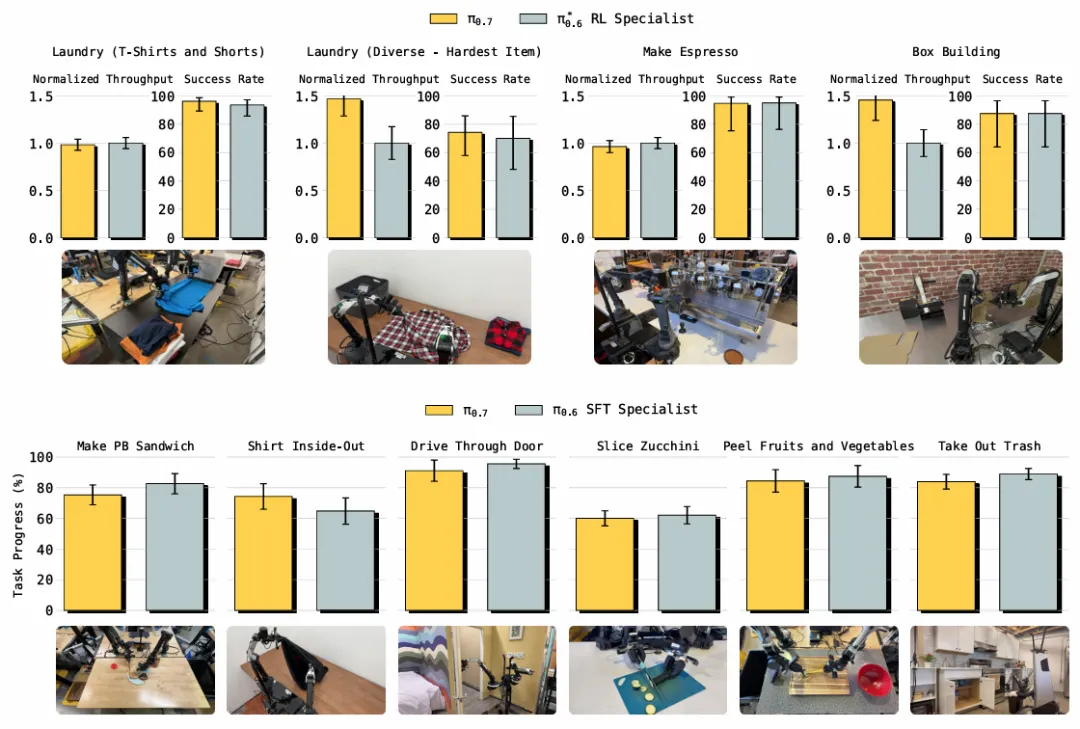
▲开箱即用的精细操作能力
在折叠复杂衣物与组装纸箱任务中,π₀.₇的吞吐量超过RL微调模型,这是通用VLA首次在精细任务上超越专属专家策略。
跨本体零样本迁移:从“不可行”到“媲美专业遥操作手”
π₀.₆在跨本体(如从轻型双臂→UR5e重型双臂)迁移时性能大幅下降;
π₀.₇实现零样本跨本体迁移,在从未见过的UR5e上折叠衣物,任务进度85.6%、成功率80%,与经验丰富的遥操作专家(90.9%进度、80.6%成功率)几乎持平。
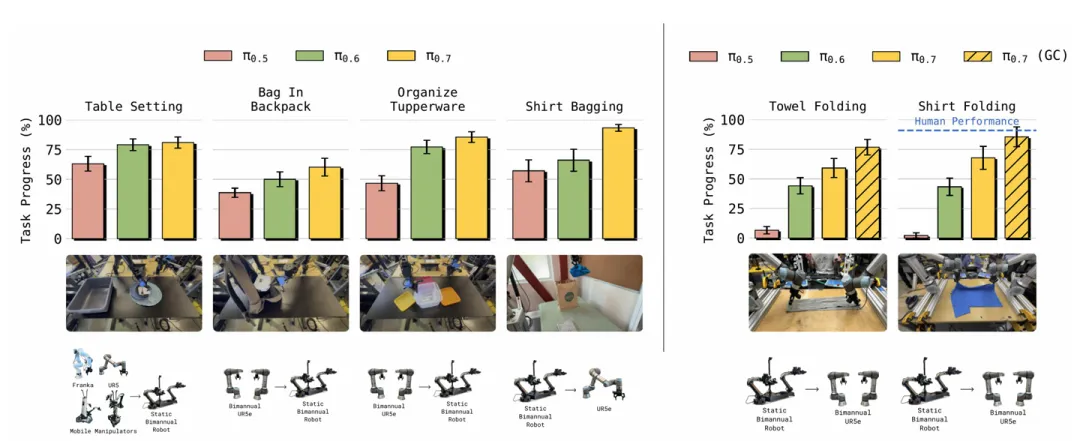
▲跨本体迁移性能
核心原因是子目标图像+元数据让模型学习任务本质,而非特定本体的运动模式。
指令遵循:突破数据集偏见,理解复杂指代
π₀.₆容易被数据集分布误导,忽略与常见模式冲突的指令;
π₀.₇可以执行反常识/反偏见指令,例如“把餐具扔进垃圾桶、垃圾放进收纳盒”。
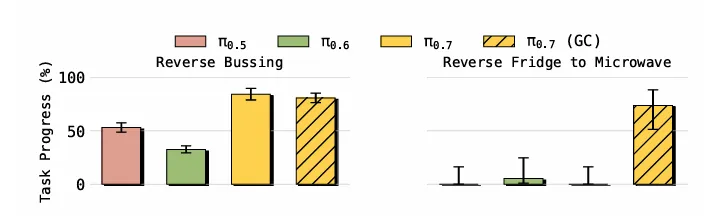
▲通过遵循指令打破数据集偏见
同时,π₀.₇能理解复杂空间指代,如“拿起最大盘子上的水果”“拿起喝汤用的餐具”,在未见环境中指令遵循成功率显著领先。
compositional泛化:零样本完成全新长程任务
π₀.₆只能执行训练任务;
π₀.₇可以通过语言分步教学,零样本完成全新任务,如使用空气炸锅、烤贝果,无需任何新演示数据。
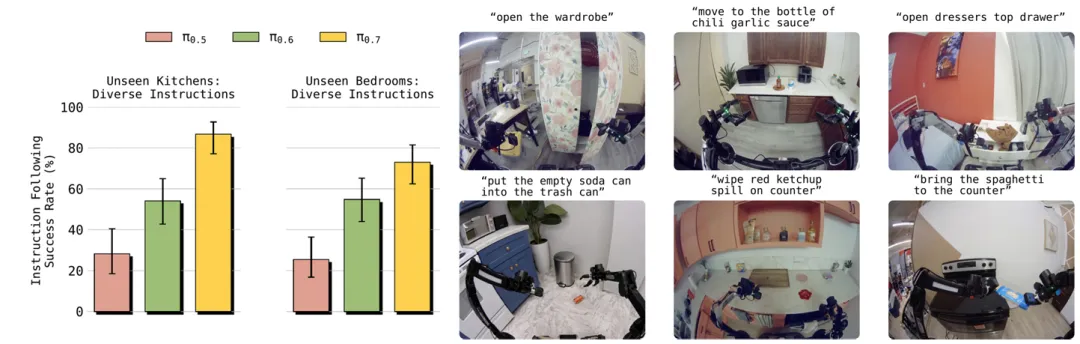
▲全新环境下的泛化指令遵循
教学数据还能训练高层策略,实现完全自主执行。

▲语言教学示例
数据效率:从“精选高质量数据”到“全数据利用”
π₀.₆依赖高质量人工演示;
π₀.₇可以直接使用失败数据、自主探索数据、异构机器人数据,数据规模与多样性大幅提升,且性能随数据量持续上涨。
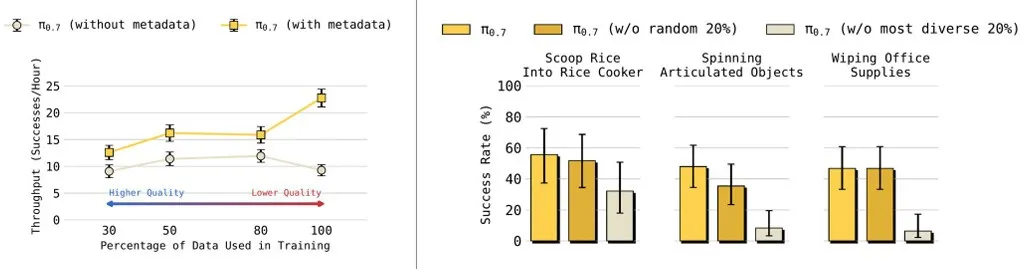
▲泛化性能随多样化上下文与数据的扩展曲线
04 实验验证:多场景、多本体、多任务全面领先
论文在LIBERO之外,构建了覆盖厨房、家居、操作的大规模测试集,使用四类机器人平台验证性能:
- 轻型双臂机器人
- 移动双臂机器人
- 单臂UR5e
- 重型双臂UR5e

▲实验所用机器人平台示意图
精细长程任务
在10余项高难度任务中,π₀.₇开箱即用成功率均超过π₀.₆ SFT与π₀.₅,在折叠衣物、换垃圾袋、切菜等任务上优势尤为明显。

▲语言教学长时序新任务完成度对比
跨本体迁移实验
在桌台布置、背包装袋、收纳整理、衣物折叠等任务中:
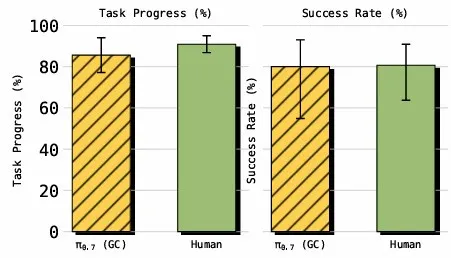
▲π₀.₇与人类遥操作专家性能对比
- π₀.₅在本体差异较大时几乎失效;
- π₀.₆保持中等性能;
- π₀.₇在最大本体差异下仍保持高成功率。
消融实验:关键组件缺一不可
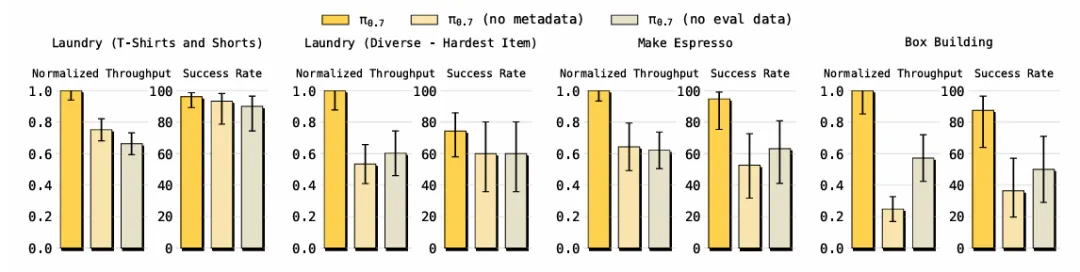
▲提示词结构与评估数据对性能的影响
- 无元数据:无法利用低质量数据,精细任务性能暴跌;
- 无子目标图像:跨本体迁移与复杂指令遵循能力明显下降;
- 无分步指令:长程任务完成度大幅降低。
这证明多模态prompt并非简单叠加,而是形成互补增益的系统。
05 审视:π₀.₇的突破、局限与行业价值
核心贡献
首次在VLA中实现多模态可操控prompt,统一语义、视觉、质量、控制模式;
首次让通用VLA模型开箱即用匹敌RL微调专家,大幅降低落地成本;
实现真正跨本体零样本迁移,打通从低成本机器人到工业臂的技能迁移;
支持 compositional 泛化与语言教学,让机器人具备持续学习新任务的能力;
数据利用方式革新,可直接学习混合质量、多源、跨本体数据。
现存局限
子目标图像依赖外部世界模型,推理时延增加,端到端整合度不足;
对动态环境、突发干扰、非结构化杂乱场景的鲁棒性仍依赖数据覆盖;
跨本体迁移在极端形态差异(如人形→轮式机器人)下仍有限制;
未完全解决物理交互中的力控、柔顺控制,精细操作仍有上限。
06 从“执行模型”到“智能体”,π₀.₇定义下一代VLA标准
π₀.₇没有带来颠覆性的架构革命,却用一套简洁、可扩展、可落地的prompt体系,解决了通用VLA长期存在的核心矛盾:
- 通用化 vs 精细化
- 泛化性 vs 鲁棒性
- 数据效率 vs 性能上限
π₀.₇的出现,标志着VLA模型进入可控通用时代:
它让VLA模型从“只能在限定条件下完成指定动作”的执行器,升级为“可理解任务策略、可迁移本体、可组合技能、可从任意经验学习”的智能体。
对于行业而言,π₀.₇提供了一套可复制的范式:
强通用VLA = 多模态上下文prompt + 混合质量数据学习 + 跨本体对齐机制。
Ref:
论文:π₀.₇: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Pi官网:https://www.pi.website/
博客地址:https://www.pi.website/blog/pi07
论文地址:https://www.pi.website/download/pi07.pdf

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)