Agentic-GraphRAG 应用开发实战
Agentic-GraphRAG 应用开发实战
本文详细介绍了如何从零搭建一个垂直领域 Agentic-GraphRAG 智能问答系统,包括 RAG 痛点分析、GraphRAG 技术方案、LangExtract 信息抽取、MinerU PDF 解析、ChromaDB 向量存储、知识图谱构建,以及最后使用 LangChain Agent 实现可溯源问答。简单来说,就是让大模型不仅能“查资料”,还能根据问题自己选择向量检索、图谱检索或者混合检索,并且回答的每个关键信息都能追溯到原文位置。
1、项目功能介绍
首先先看一下这个项目主要解决什么问题。传统 RAG 一般是把文档切分成很多片段,然后把片段向量化,用户提问的时候再做相似度检索,最后把检索到的内容交给大模型回答。
这种方式在简单知识库问答里面很好用,但是在医疗、法律、金融、企业制度问答这类垂直领域里面,很容易遇到两个问题:
- 问题涉及多个文档、多个实体、多个关系时,普通向量检索很难把这些碎片串起来。
- 检索结果里混入无关内容时,大模型可能会被误导,回答看起来合理,但其实并不准确。
所以我们需要引入 GraphRAG 的思路,把文档里面的实体、关系、事件、指标提取出来,形成一个轻量级知识图谱。然后再结合 Agent 的工具调用能力,让 Agent 根据问题自动决定使用哪种检索方式。
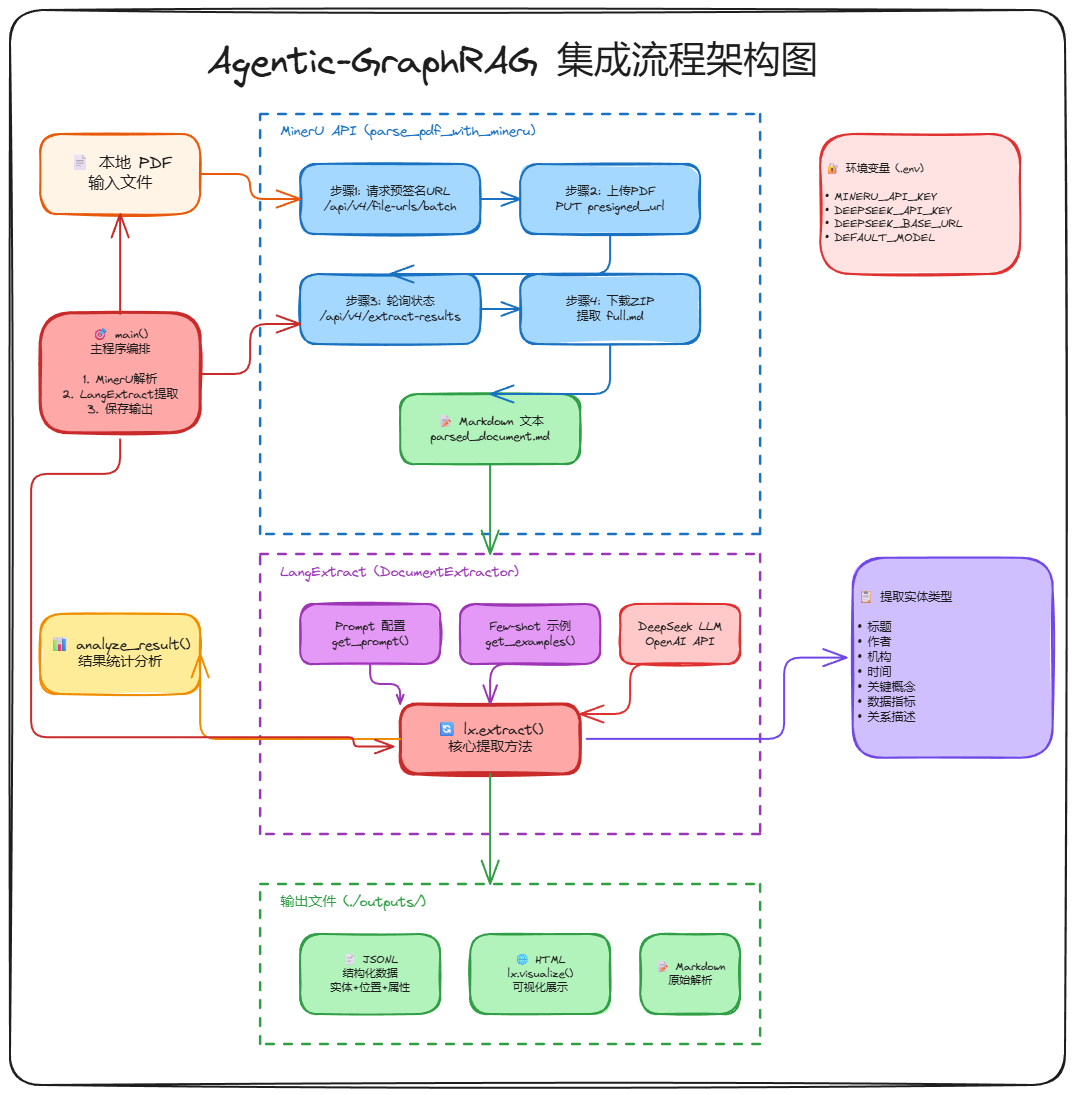
项目整体流程如下:
PDF 文档
↓
MinerU 解析成 Markdown
↓
LangExtract 提取实体、关系、指标、事件
↓
ChromaDB 存储向量
↓
构建轻量级知识图谱
↓
LangChain Agent 调用检索工具
↓
输出答案和溯源信息
如下图所示:
2、为什么需要 GraphRAG
先简单说一下普通 RAG 的流程。普通 RAG 一般是:
文档切分 → 文本向量化 → 用户问题向量化 → 相似度检索 → 大模型生成答案
这种方式实现简单,上手也快。但它本质上还是“相似片段检索”,如果问题需要跨段落、跨文档、多跳推理,就很容易漏掉关键关系。
比如用户问:
某个政策对哪些地区的人工智能产业产生影响?
普通 RAG 可能只找到某一段政策描述,但找不到“政策 - 地区 - 产业 - 资金支持”之间的完整关系链。
GraphRAG 的思路就是把文本里面的实体和关系提取出来:
实体:国家发展改革委、上海、深圳、人工智能+制造
关系:发改委支持试点城市、试点城市包括上海和深圳
指标:专项资金、覆盖 10 个城市
这样在问答时,就不只是找相似文本,而是可以沿着实体和关系继续查找相关信息。
3、Agentic-GraphRAG 的实现思路
传统 GraphRAG 一般需要构建完整知识图谱,甚至还需要图数据库、社区发现、分层摘要等流程,落地成本比较高。
所以本项目采用一个更轻量的方案:不一上来就做特别复杂的图数据库,而是先把知识抽取成结构化结果,然后同时存入向量库和轻量级知识图谱,最后把这些检索能力注册成 Agent 工具。
这样做的好处是:
- 简单问题直接走向量检索。
- 实体关系问题走图谱检索。
- 复杂问题走混合检索。
- 每条结果都保留原文位置,方便溯源。
整体上,Agent 就相当于一个“检索调度器”,它会根据问题类型自己选择工具。
4、安装项目环境
首先安装需要的依赖:
pip install openai python-dotenv langextract requests chromadb langchain langchain-openai langchain-chroma dashscope
如果是在 notebook 中运行,也可以使用:
%pip install openai python-dotenv langextract requests chromadb langchain langchain-openai langchain-chroma dashscope
安装完成之后,先导入基础库:
import os
import io
import json
import time
import uuid
import zipfile
import textwrap
import requests
from pathlib import Path
from dataclasses import dataclass, field, asdict
from typing import Optional
from collections import Counter
这里没有报错就说明环境正常,可以继续。
5、配置 API Key
项目中主要用到了三个配置:
MINERU_API_KEY:用于调用 MinerU API,把 PDF 解析成 MarkdownDEEPSEEK_API_KEY:用于 LangExtract 信息抽取和 Agent 问答DASHSCOPE_API_KEY:用于阿里云百炼 Embeddings 向量化
建议把这些配置写到 .env 文件中:
MINERU_API_KEY=your-mineru-api-key
DEEPSEEK_API_KEY=your-deepseek-api-key
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEFAULT_MODEL=deepseek-chat
DASHSCOPE_API_KEY=your-dashscope-api-key
DASHSCOPE_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_MODEL=text-embedding-v4
然后在代码中加载:
from dotenv import load_dotenv
load_dotenv()
MINERU_API_KEY = os.getenv("MINERU_API_KEY", "")
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY", "")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
DEFAULT_MODEL = os.getenv("DEFAULT_MODEL", "deepseek-chat")
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY", "")
DASHSCOPE_BASE_URL = os.getenv(
"DASHSCOPE_BASE_URL",
"https://dashscope.aliyuncs.com/compatible-mode/v1"
)
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text-embedding-v4")
6、先看普通 Prompt 抽取的问题
在正式使用 LangExtract 之前,可以先用普通 Prompt 做一次信息抽取,看看它的问题在哪里。
假设我们有这样一段新闻文本:
input_text = """
2025年12月22日上午,国家统计局在北京国务院新闻办公室举行新闻发布会,公布2025年前11个月国民经济运行情况。
国家统计局新闻发言人付凌晖表示,规模以上工业增加值同比增长6.1%,社会消费品零售总额增长7.3%。
同日,国家发展改革委在例行发布会上介绍,将于2026年起对"人工智能+制造"试点城市给予专项资金支持,首批覆盖上海、深圳、成都等10个城市。
"""
我们可以写一个 Prompt,让模型抽取时间、地点、机构、人物、事件和指标:
prompt = f"""
请从下面的新闻文本中提取结构化信息。
【抽取类别】
- 时间
- 地点
- 机构
- 人物
- 事件
- 指标
【要求】
1. 所有 text 必须是原文中的精确子串,不要改写
2. 去重并按原文出现顺序输出
【输出格式】
请严格输出 JSON:
{{
"extractions": [
{{"class": "类别", "text": "原文精确文本"}}
]
}}
新闻文本:
{input_text}
"""
这种方式能跑,但是实际项目中容易遇到几个问题:
- 输出格式有时不稳定。
- 重复实体需要自己处理。
- 很难自动拿到实体在原文中的位置。
- 长文本分块、多轮抽取、可视化都要自己写。
所以后面我们使用 LangExtract。
7、使用 LangExtract 做信息抽取
LangExtract 是 Google 开源的一个 Python 库,它的核心作用就是把非结构化文本转成结构化数据,并且可以记录每个提取结果在原文中的位置。
先导入相关库:
import langextract as lx
from langextract.providers.openai import OpenAILanguageModel
from langextract.prompt_validation import PromptValidationLevel
定义提取任务:
langextract_prompt = """
从新闻文本中提取以下信息:
- 时间
- 地点
- 机构
- 人物
- 事件
- 指标(数值/增速/比例/数量等)
要求:
1. 使用原文中的完整表述
2. 不要重复
3. 按出现顺序提取
"""
再定义 Few-shot 示例:
example_text = "2025年6月3日,工业和信息化部在北京发布《算力基础设施高质量发展行动计划》。"
examples = [
lx.data.ExampleData(
text=example_text,
extractions=[
lx.data.Extraction("时间", "2025年6月3日"),
lx.data.Extraction("机构", "工业和信息化部"),
lx.data.Extraction("地点", "北京"),
lx.data.Extraction("事件", "发布《算力基础设施高质量发展行动计划》"),
]
)
]
创建模型:
model = OpenAILanguageModel(
model_id=DEFAULT_MODEL,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL
)
执行抽取:
result = lx.extract(
text_or_documents=input_text,
prompt_description=langextract_prompt,
examples=examples,
model=model,
fence_output=True,
use_schema_constraints=False,
prompt_validation_level=PromptValidationLevel.OFF,
)
打印结果:
for ext in result.extractions:
if ext.char_interval:
pos_info = f"[{ext.char_interval.start_pos}-{ext.char_interval.end_pos}]"
else:
pos_info = ""
print(f"[{ext.extraction_class}] {ext.extraction_text} {pos_info}")
这里最关键的是 char_interval,它记录了实体在原文中的起始和结束字符位置。后面做溯源时就靠它。
8、LangExtract 长文本提取
短文本提取跑通之后,接下来再看长文本。比如一篇几万字的小说、法规、合同、论文,如果直接丢给模型,很容易超过上下文长度,也容易漏抽。
LangExtract 处理长文本主要靠三个参数:
| 参数名 | 示例值 | 作用 |
|---|---|---|
extraction_passes |
3 | 多轮提取,提高召回率 |
max_workers |
20 | 并行处理,加快速度 |
max_char_buffer |
1000 | 控制分块大小 |
执行长文本提取:
result = lx.extract(
text_or_documents=input_text,
prompt_description=extraction_prompt,
examples=examples,
model=model,
extraction_passes=3,
max_workers=20,
max_char_buffer=1000,
show_progress=True,
)
提取完成后,可以保存成 JSONL:
OUTPUT_DIR = Path("./outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
lx.io.save_annotated_documents(
[result],
output_name="extractions.jsonl",
output_dir=str(OUTPUT_DIR)
)
还可以生成可视化 HTML:
html_content = lx.visualize(str(OUTPUT_DIR / "extractions.jsonl"))
html_file = OUTPUT_DIR / "visualization.html"
with open(html_file, "w", encoding="utf-8") as f:
if hasattr(html_content, "data"):
f.write(html_content.data)
else:
f.write(html_content)
打开这个 HTML 文件,就能看到原文高亮、实体分类、位置信息等内容。
9、使用 MinerU 解析 PDF
有了 LangExtract 之后,我们还需要解决 PDF 文档解析问题。因为企业文档、合同、论文、报告一般都是 PDF 格式,直接给模型处理并不方便。
这里使用 MinerU API,把 PDF 转成结构化 Markdown。
先准备 PDF 路径:
PDF_PATH = "test.pdf"
pdf_file = Path(PDF_PATH)
if pdf_file.exists():
print("PDF 文件存在,可以继续")
else:
print("PDF 文件不存在,请检查路径")
MinerU 在线 API 大概分为四步:
请求上传 URL → 上传 PDF → 轮询解析状态 → 下载解析结果
请求上传 URL:
MINERU_BASE_URL = "https://mineru.net"
headers = {
"Authorization": f"Bearer {MINERU_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
f"{MINERU_BASE_URL}/api/v4/file-urls/batch",
headers=headers,
json={
"files": [{"name": pdf_file.name, "data_id": pdf_file.name}],
"model_version": "vlm",
}
)
response.raise_for_status()
data = response.json()["data"]
batch_id = data["batch_id"]
upload_url = data["file_urls"][0]
上传 PDF:
with open(PDF_PATH, "rb") as f:
file_content = f.read()
upload_response = requests.put(upload_url, data=file_content)
upload_response.raise_for_status()
轮询解析状态:
max_wait = 600
poll_interval = 3
elapsed = 0
full_zip_url = None
while elapsed < max_wait:
status_response = requests.get(
f"{MINERU_BASE_URL}/api/v4/extract-results/batch/{batch_id}",
headers={"Authorization": f"Bearer {MINERU_API_KEY}"}
)
result = status_response.json()["data"]["extract_result"][0]
state = result["state"]
if state == "done":
full_zip_url = result["full_zip_url"]
break
elif state == "failed":
print("解析失败")
break
time.sleep(poll_interval)
elapsed += poll_interval
下载并提取 Markdown:
if full_zip_url:
zip_response = requests.get(full_zip_url)
with zipfile.ZipFile(io.BytesIO(zip_response.content)) as zf:
md_files = [f for f in zf.namelist() if f.endswith(".md")]
target_file = next((f for f in md_files if "full" in f.lower()), md_files[0])
with zf.open(target_file) as f:
markdown_text = f.read().decode("utf-8")
md_file = OUTPUT_DIR / "parsed_document.md"
with open(md_file, "w", encoding="utf-8") as f:
f.write(markdown_text)
到这里,PDF 就已经变成 Markdown 文本了,后面就可以做结构化知识抽取。
10、定义知识提取数据结构
为了让后面的向量库和知识图谱都能统一处理,我们先定义一个数据结构 KnowledgeExtraction。
@dataclass
class KnowledgeExtraction:
doc_id: str
doc_title: str
extraction_class: str
extraction_text: str
char_interval: Optional[dict] = None
attributes: dict = field(default_factory=dict)
def to_dict(self) -> dict:
return asdict(self)
def to_searchable_text(self) -> str:
parts = [
f"类型: {self.extraction_class}",
f"内容: {self.extraction_text}",
f"来源: {self.doc_title}"
]
for k, v in self.attributes.items():
parts.append(f"{k}: {v}")
return " | ".join(parts)
其中最重要的是 char_interval,它保存原文字符区间,比如:
{
"start_pos": 120,
"end_pos": 136
}
这样后面 Agent 回答时,就可以告诉用户“这个信息来自原文的字符 120 - 136”。
11、从 Markdown 中提取知识
现在有了 Markdown 文本,就可以使用 LangExtract 提取实体、关系、指标和事件。
定义提取 Prompt:
extraction_prompt = textwrap.dedent("""
从文档中提取以下结构化知识:
- 实体: 人物、机构、地点、时间、概念、技术术语
- 数据指标: 数值、百分比、统计数据
- 关系描述: 实体之间的关系(合作、隶属、引用等)
- 事件: 重要事件和行为
要求:
1. extraction_text 必须是原文的精确子串
2. 为每个提取添加丰富的属性信息
3. 关系类型必须在 attributes 中标注涉及的主体
4. 保持原文出现顺序
""")
定义 Few-shot 示例:
example_text = """
# 人工智能发展报告
张三(清华大学)、李四(北京大学)联合开展了人工智能研究。
研究显示,大模型参数量增长了300%。
""".strip()
example_extractions = [
lx.data.Extraction(
extraction_class="实体",
extraction_text="张三",
attributes={"类型": "人物", "机构": "清华大学"}
),
lx.data.Extraction(
extraction_class="数据指标",
extraction_text="增长了300%",
attributes={"指标": "大模型参数量", "类型": "增长率"}
),
lx.data.Extraction(
extraction_class="关系描述",
extraction_text="张三(清华大学)、李四(北京大学)联合开展了人工智能研究",
attributes={"类型": "合作关系", "主体1": "张三", "主体2": "李四"}
),
]
examples = [
lx.data.ExampleData(
text=example_text,
extractions=example_extractions
)
]
执行提取:
langextract_model = OpenAILanguageModel(
model_id=DEFAULT_MODEL,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)
result = lx.extract(
text_or_documents=markdown_text[:8000],
prompt_description=extraction_prompt,
examples=examples,
model=langextract_model,
fence_output=True,
use_schema_constraints=False,
prompt_validation_level=PromptValidationLevel.OFF,
show_progress=True,
)
转换成 KnowledgeExtraction:
extractions = []
doc_id = "doc_001"
doc_title = PDF_PATH
for ext in result.extractions:
if ext.char_interval:
char_interval = {
"start_pos": ext.char_interval.start_pos,
"end_pos": ext.char_interval.end_pos
}
else:
char_interval = None
extractions.append(
KnowledgeExtraction(
doc_id=doc_id,
doc_title=doc_title,
extraction_class=ext.extraction_class,
extraction_text=ext.extraction_text,
char_interval=char_interval,
attributes=ext.attributes or {}
)
)
提取完成后,可以统计一下不同类型的数量:
type_counts = Counter(e.extraction_class for e in extractions)
for entity_type, count in type_counts.most_common():
print(entity_type, count)
如果 char_interval 对齐率比较高,说明后面的溯源质量也会比较好。
12、存入 ChromaDB 向量库
提取出来的结构化知识,需要先存入向量数据库,方便后面做语义检索。
初始化 Embeddings:
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
import chromadb
embeddings = OpenAIEmbeddings(
model=EMBEDDING_MODEL,
api_key=DASHSCOPE_API_KEY,
base_url=DASHSCOPE_BASE_URL,
check_embedding_ctx_length=False,
chunk_size=10,
)
初始化 ChromaDB:
CHROMA_PERSIST_DIR = "./chroma_db_chapter5"
COLLECTION_NAME = "pdf_knowledge_graph"
persist_dir = Path(CHROMA_PERSIST_DIR)
persist_dir.mkdir(parents=True, exist_ok=True)
client = chromadb.PersistentClient(path=str(persist_dir))
vectorstore = Chroma(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
client=client,
)
把提取结果写入向量库:
texts = [ext.to_searchable_text() for ext in extractions]
metadatas = []
ids = []
for ext in extractions:
ids.append(str(uuid.uuid4()))
metadatas.append({
"doc_id": ext.doc_id,
"doc_title": ext.doc_title,
"extraction_class": ext.extraction_class,
"extraction_text": ext.extraction_text,
"char_interval": json.dumps(ext.char_interval) if ext.char_interval else "",
"attributes": json.dumps(ext.attributes, ensure_ascii=False),
})
vectorstore.add_texts(texts=texts, metadatas=metadatas, ids=ids)
注意,这里一定要把 char_interval 保存到 metadata 里面。否则虽然能检索到内容,但后面就没办法做溯源了。
13、构建轻量级知识图谱
接下来根据提取结果构建一个简单的知识图谱。这里不使用复杂图数据库,先用 Python 字典保存实体和关系即可。
knowledge_graph = {
"entities": {},
"relations": []
}
for ext in extractions:
if ext.extraction_class == "关系描述":
attrs = ext.attributes
knowledge_graph["relations"].append({
"text": ext.extraction_text,
"type": attrs.get("类型", "未知"),
"subject": attrs.get("主体1"),
"object": attrs.get("主体2"),
"relation": attrs.get("关系"),
"source": ext.doc_title
})
elif ext.extraction_class in ["实体", "数据指标"]:
entity_name = ext.extraction_text
if entity_name not in knowledge_graph["entities"]:
knowledge_graph["entities"][entity_name] = {
"type": ext.extraction_class,
"attributes": ext.attributes,
"mentions": []
}
knowledge_graph["entities"][entity_name]["mentions"].append({
"source": ext.doc_title,
"position": ext.char_interval
})
保存知识图谱:
kg_file = OUTPUT_DIR / "knowledge_graph.json"
with open(kg_file, "w", encoding="utf-8") as f:
json.dump(knowledge_graph, f, ensure_ascii=False, indent=2)
这样我们就有了两个知识入口:
- ChromaDB:负责语义相似检索。
- knowledge_graph:负责实体关系检索。
14、定义向量检索和图谱检索
先定义向量检索函数:
def search_knowledge(query: str, top_k: int = 5):
results = vectorstore.similarity_search_with_score(query, k=top_k)
formatted_results = []
for doc, score in results:
char_interval_str = doc.metadata.get("char_interval", "")
char_interval = json.loads(char_interval_str) if char_interval_str else None
formatted_results.append({
"score": 1 / (1 + score),
"doc_title": doc.metadata.get("doc_title"),
"extraction_class": doc.metadata.get("extraction_class"),
"extraction_text": doc.metadata.get("extraction_text"),
"char_interval": char_interval,
"attributes": json.loads(doc.metadata.get("attributes", "{}")),
})
return formatted_results
再定义图谱检索函数:
def graph_search(query_entity: str, hop: int = 1):
results = {
"matched_entities": [],
"related_relations": [],
"connected_entities": set()
}
for entity_name, entity_data in knowledge_graph["entities"].items():
if query_entity.lower() in entity_name.lower():
results["matched_entities"].append({
"name": entity_name,
**entity_data
})
matched_names = [e["name"] for e in results["matched_entities"]]
for relation in knowledge_graph["relations"]:
subject = relation.get("subject", "")
obj = relation.get("object", "")
for name in matched_names:
if name.lower() in str(subject).lower() or name.lower() in str(obj).lower():
results["related_relations"].append(relation)
if subject:
results["connected_entities"].add(subject)
if obj:
results["connected_entities"].add(obj)
results["connected_entities"] = list(results["connected_entities"])
return results
到这里,GraphRAG 的两个核心能力就都有了。
15、把检索能力注册成 Agent 工具
接下来使用 LangChain 的 tool 把检索函数包装成 Agent 可以调用的工具。
from langchain.tools import tool
@tool
def vector_search_tool(query: str) -> str:
"""
向量语义检索:根据问题搜索相关知识片段。
"""
results = search_knowledge(query, top_k=5)
if not results:
return "未找到相关信息"
output_parts = []
for i, r in enumerate(results, 1):
part = f"[V{i}] {r['extraction_class']}: {r['extraction_text']}"
if r.get("char_interval"):
interval = r["char_interval"]
part += f"\\n位置: 字符 {interval['start_pos']}-{interval['end_pos']}"
part += f"\\n来源: {r['doc_title']}"
output_parts.append(part)
return "\\n\\n".join(output_parts)
图谱检索工具:
@tool
def graph_search_tool(entity: str) -> str:
"""
知识图谱检索:根据实体名称查找相关实体和关系。
"""
results = graph_search(entity, hop=1)
output_parts = []
if results["matched_entities"]:
output_parts.append("【匹配的实体】")
for e in results["matched_entities"][:5]:
mentions = e.get("mentions", [])
output_parts.append(
f"- {e['name']},类型: {e.get('type', '未知')},提及次数: {len(mentions)}"
)
if results["related_relations"]:
output_parts.append("【相关关系】")
for i, rel in enumerate(results["related_relations"][:5], 1):
subject = rel.get("subject", "?")
relation = rel.get("relation", rel.get("type", "相关"))
obj = rel.get("object", "?")
output_parts.append(f"[G{i}] {subject} --[{relation}]--> {obj}")
return "\\n".join(output_parts) if output_parts else f"未找到与 {entity} 相关的图谱信息"
最后再定义一个混合检索工具:
@tool
def hybrid_search_tool(query: str) -> str:
"""
混合检索:同时进行向量语义检索和知识图谱检索。
"""
vector_result = vector_search_tool.invoke(query)
graph_result = graph_search_tool.invoke(query)
return "=== 向量检索结果 ===\\n" + vector_result + "\\n\\n=== 图谱检索结果 ===\\n" + graph_result
16、创建 GraphRAG Agent
工具定义完成后,就可以创建 Agent 了。
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.messages import HumanMessage
llm = ChatOpenAI(
model=DEFAULT_MODEL,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
temperature=0.3
)
graphrag_agent = create_agent(
model=llm,
tools=[vector_search_tool, graph_search_tool, hybrid_search_tool],
system_prompt="""
你是一个 GraphRAG 知识图谱问答助手。
你有以下工具可用:
1. vector_search_tool - 向量语义检索,找语义相似的内容
2. graph_search_tool - 图谱检索,根据实体名找关系
3. hybrid_search_tool - 混合检索,同时使用向量和图谱
回答策略:
- 简单的内容查询:用 vector_search_tool
- 查找实体关系:用 graph_search_tool
- 复杂问题:用 hybrid_search_tool
回答要求:
1. 综合检索到的信息回答问题
2. 标注信息来源,如 [V1]、[G1]
3. 如果有溯源位置信息,也一并说明
"""
)
这里最重要的是 system prompt,要明确告诉 Agent 每个工具适合什么场景。否则模型可能会乱用工具,或者明明需要图谱检索,却只做普通向量检索。
17、封装问答函数
最后封装一个 agent_query 函数,方便后面直接提问:
def agent_query(question: str):
result = graphrag_agent.invoke({
"messages": [HumanMessage(content=question)]
})
answer = result["messages"][-1].content
tool_calls = []
for msg in result["messages"]:
if hasattr(msg, "tool_calls") and msg.tool_calls:
for tc in msg.tool_calls:
tool_calls.append({
"type": "call",
"tool": tc.get("name", "unknown"),
"args": tc.get("args", {})
})
if hasattr(msg, "name") and msg.name:
tool_calls.append({
"type": "result",
"tool": msg.name,
"content": msg.content[:500]
})
return {
"question": question,
"answer": answer,
"evidence": tool_calls
}
测试一下:
test_questions = [
"民间借贷的利率上限是多少?",
"借款合同违约如何处理?",
"民法典第六百七十五条"
]
for question in test_questions:
result = agent_query(question)
print("问题:", question)
print("回答:", result["answer"])
print("工具调用记录:", result["evidence"])
如果能看到 Agent 自动调用 vector_search_tool、graph_search_tool 或 hybrid_search_tool,并且回答中带有来源编号和字符位置,就说明 Agentic-GraphRAG 系统已经跑通了。
18、总结
到这里,一个完整的 Agentic-GraphRAG 应用就搭建完成了。整体来看,它不是简单地把文档丢进向量库,而是先通过 MinerU 把 PDF 解析成 Markdown,再用 LangExtract 提取实体、关系、事件和指标,同时保留每个知识点的原文位置。然后把这些知识分别写入 ChromaDB 和轻量级知识图谱,最后交给 LangChain Agent 统一调度。
这个项目的核心亮点就是可溯源。普通 RAG 只能告诉你“答案可能来自这些片段”,而这个系统可以进一步告诉你“这个实体、关系或指标来自原文哪个字符区间”。这对于法律文书分析、企业知识库问答、学术论文检索、金融报告分析等场景非常重要。
后面如果继续扩展,可以把这个轻量级字典图谱替换成 Neo4j,也可以加入更完整的实体消歧、关系合并和多跳推理能力。
19、系统演示
1、智能问答模式: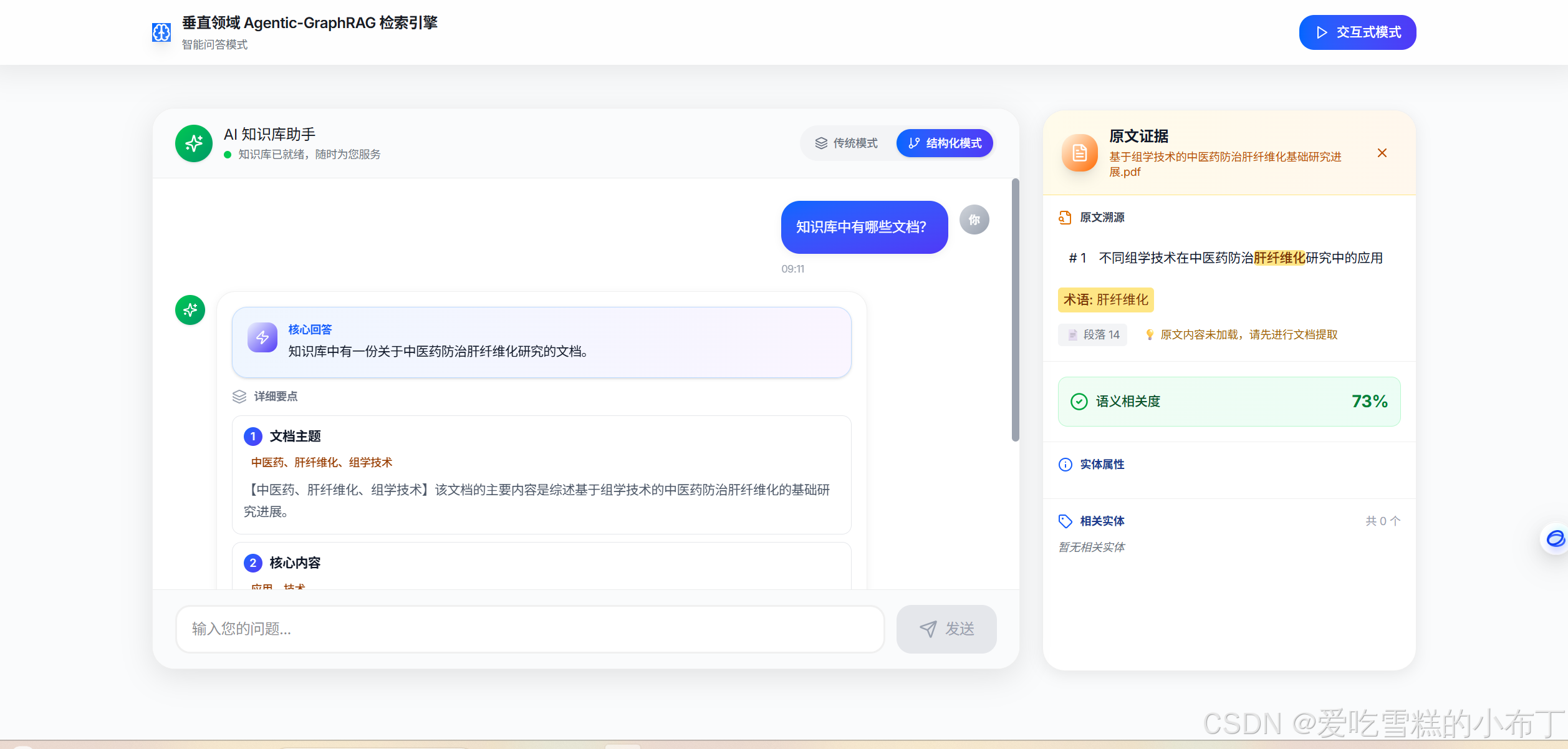
2、交互模式: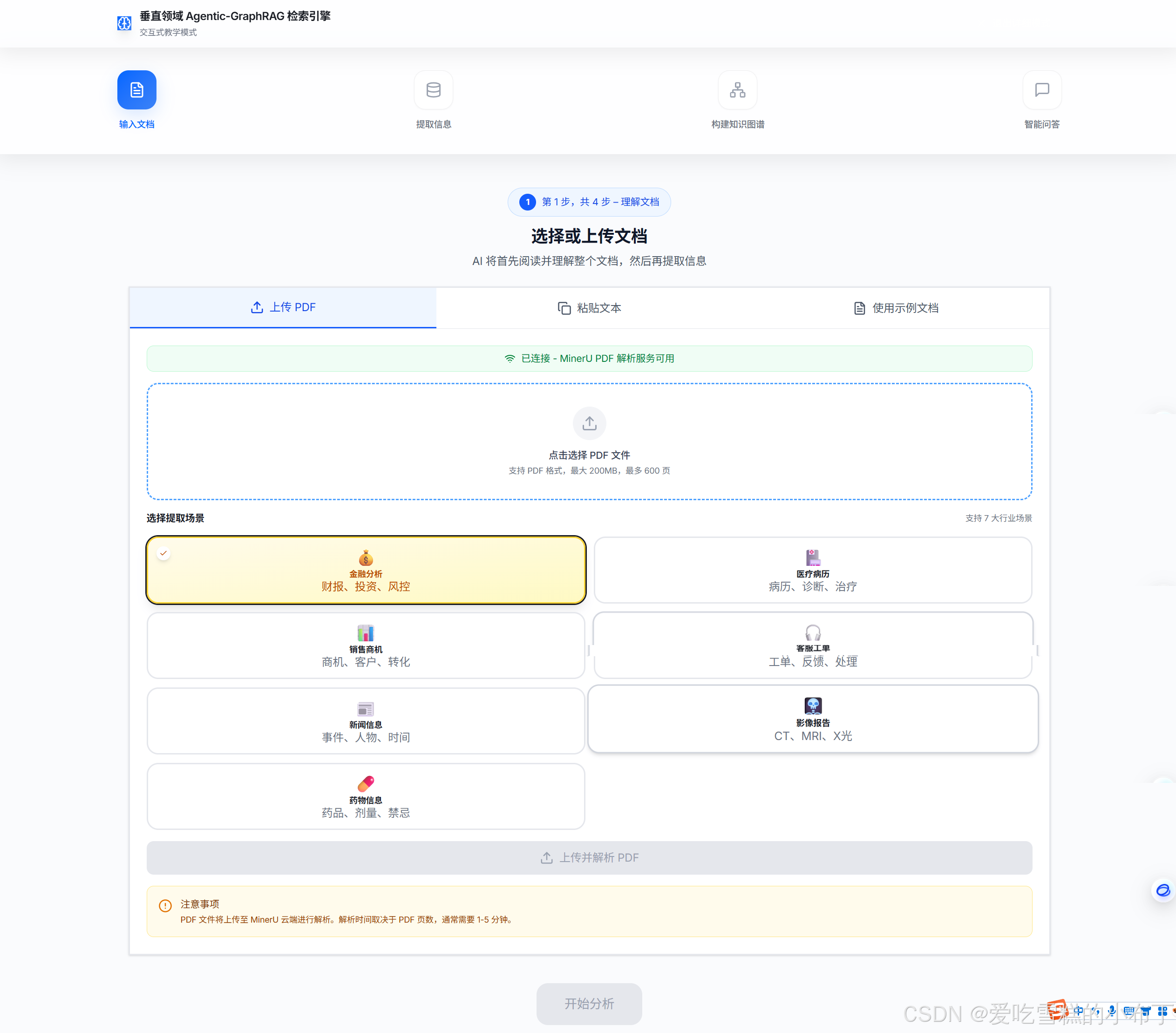
3、开始上传解析PDF文件: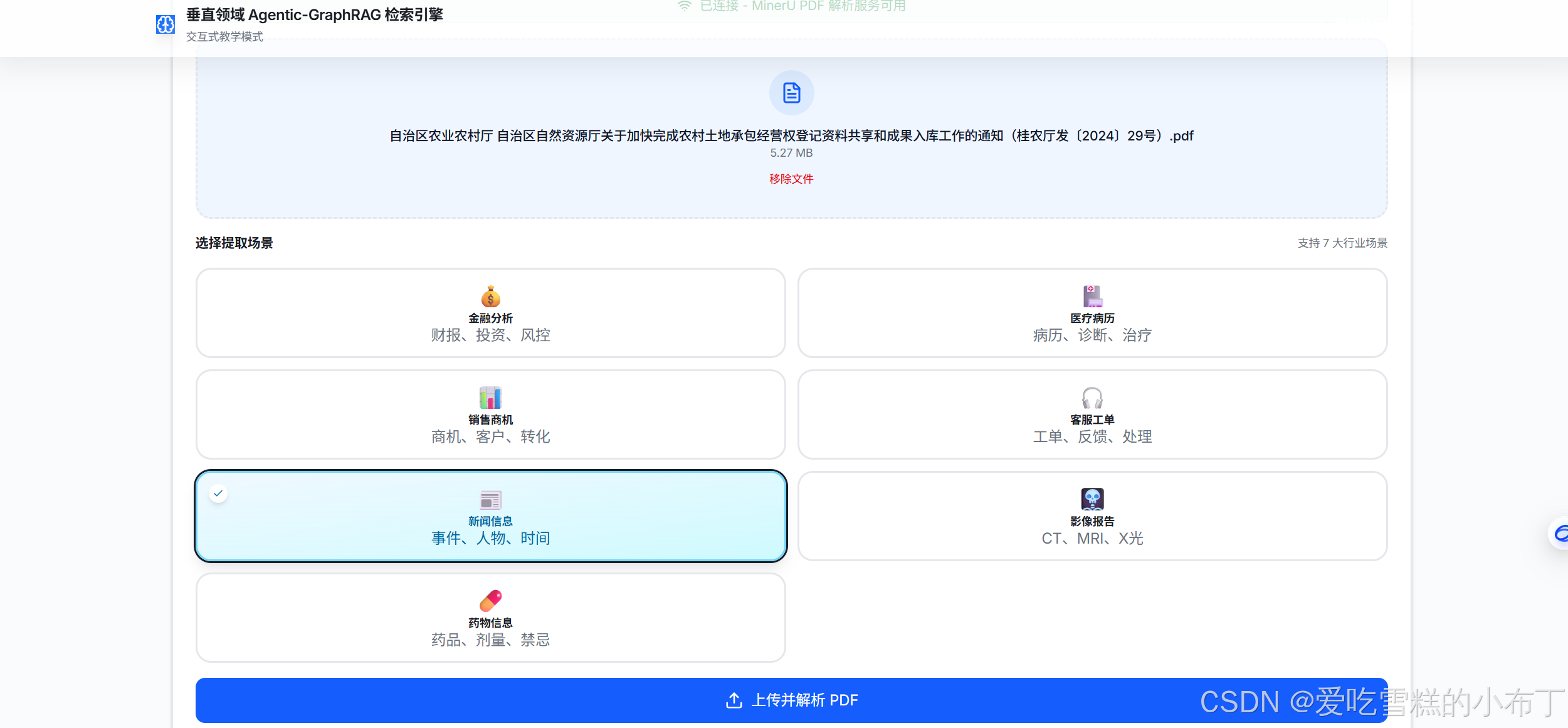
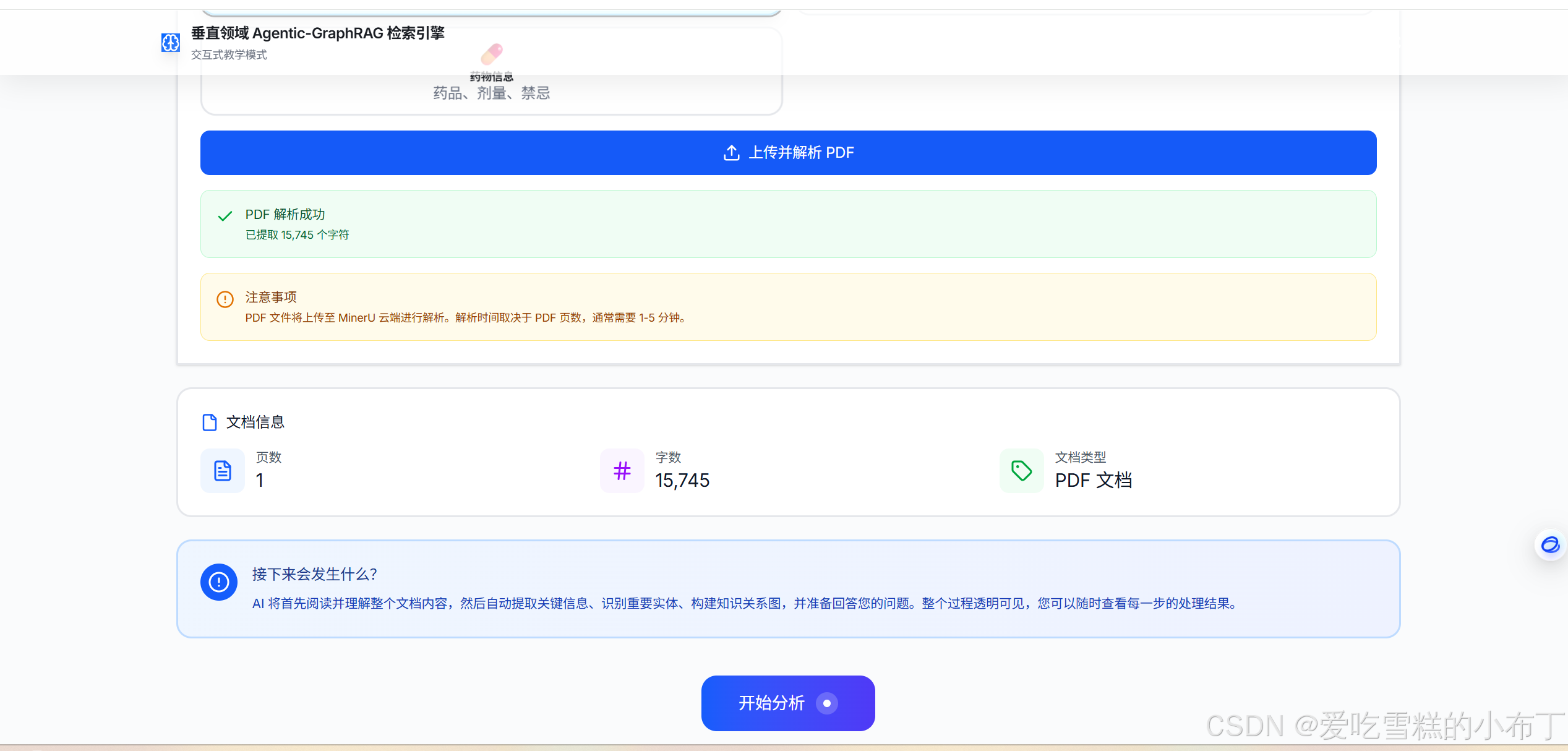
4、智能提取结构化数据:
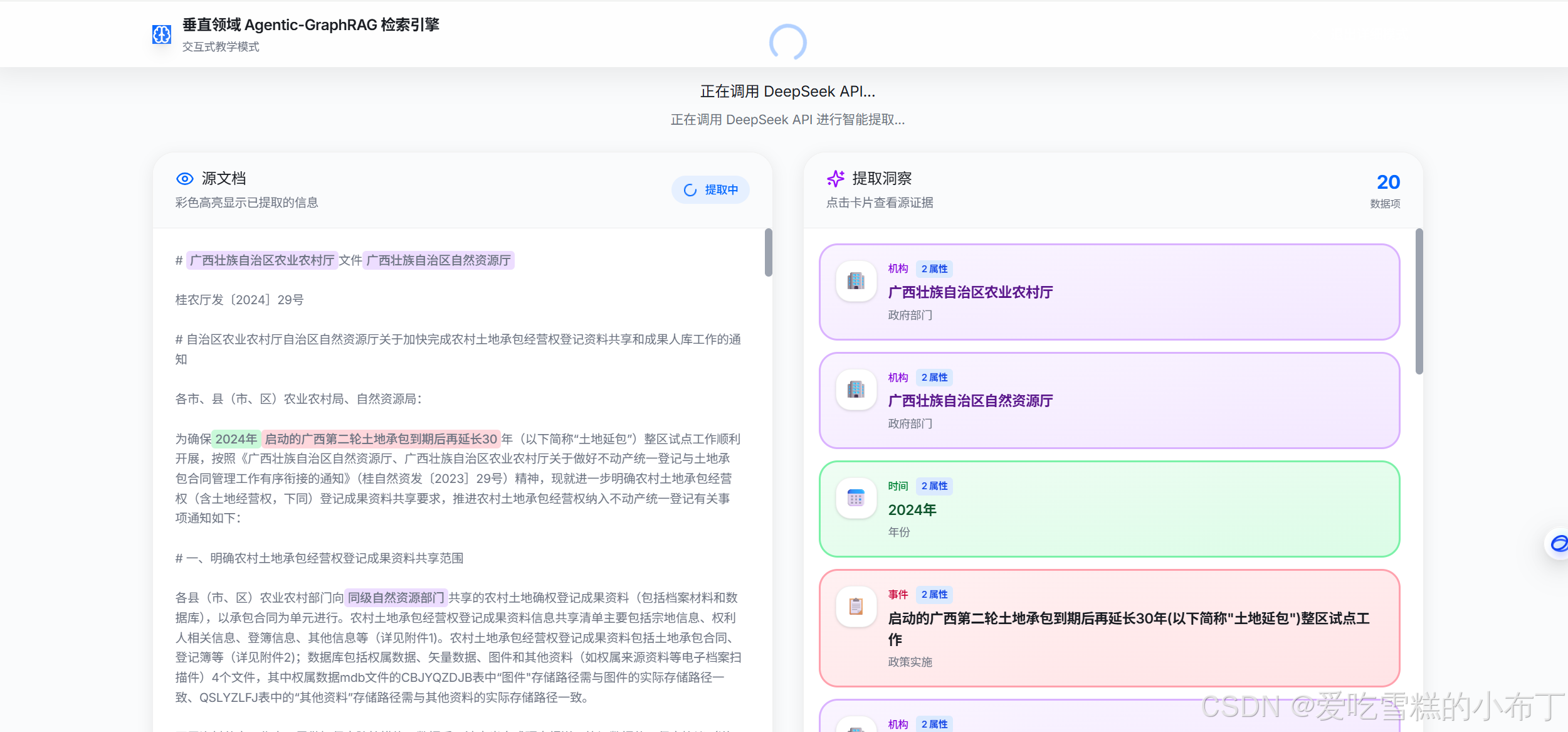
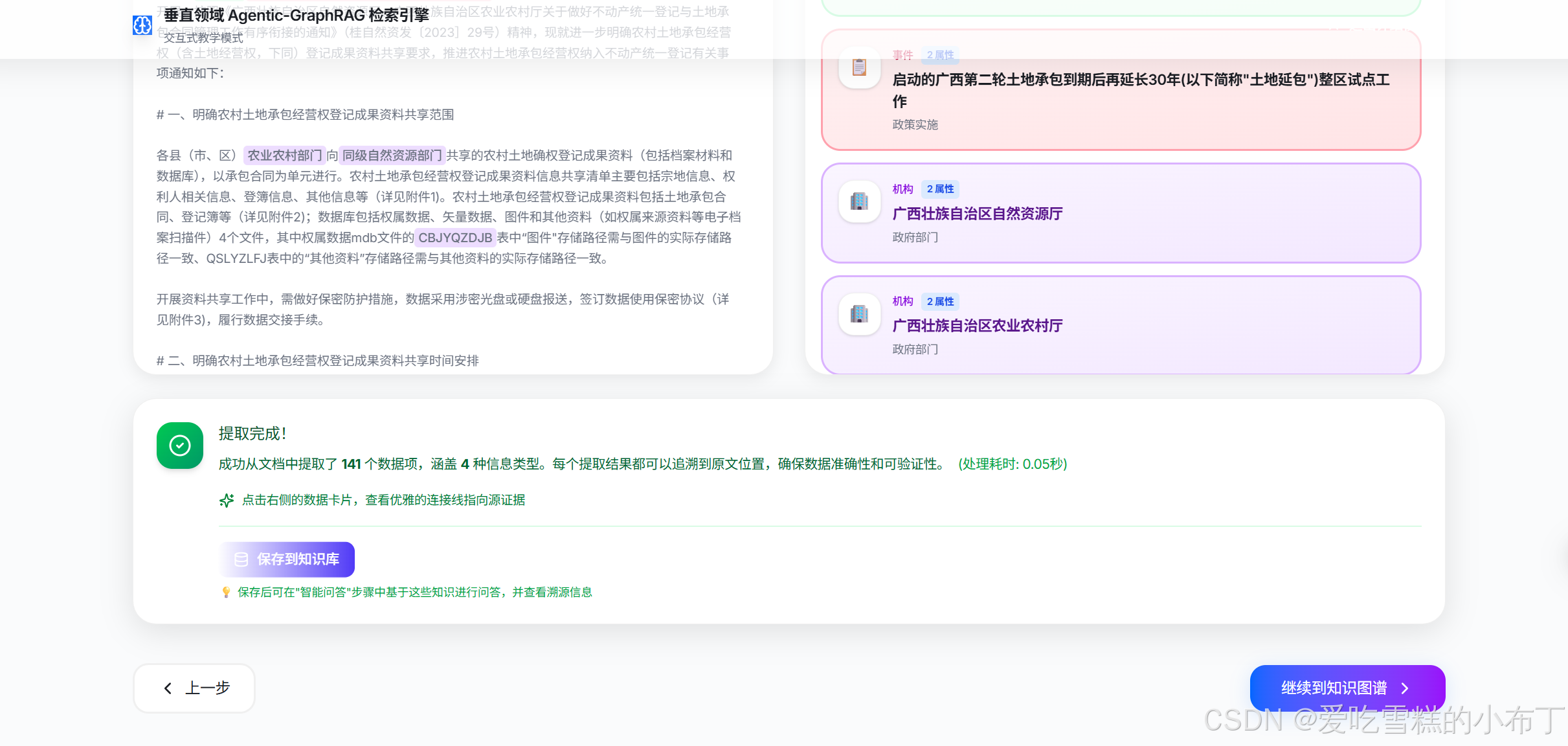
这一步点击保存到知识库的话,可以将提取的数据存到向量数据库中。
5、构建知识图谱: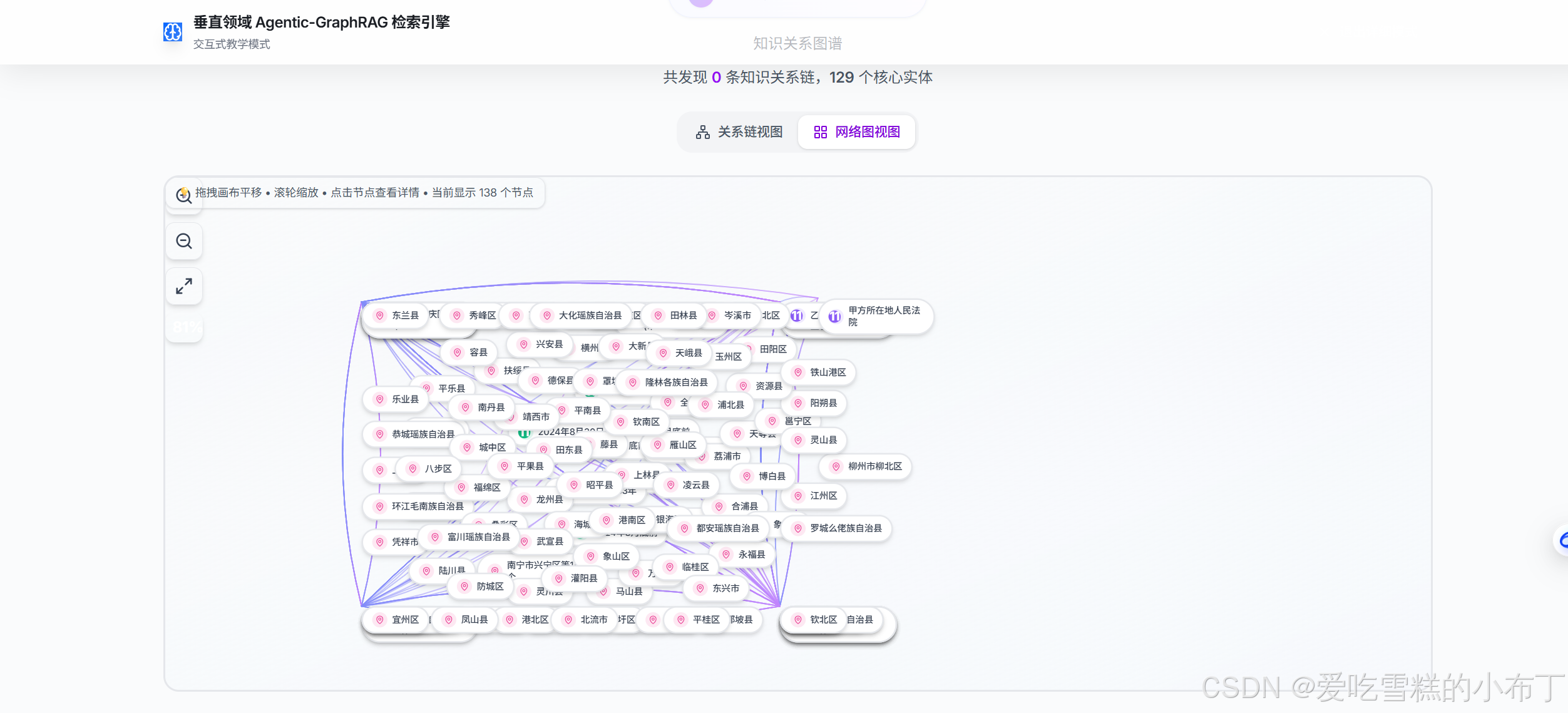
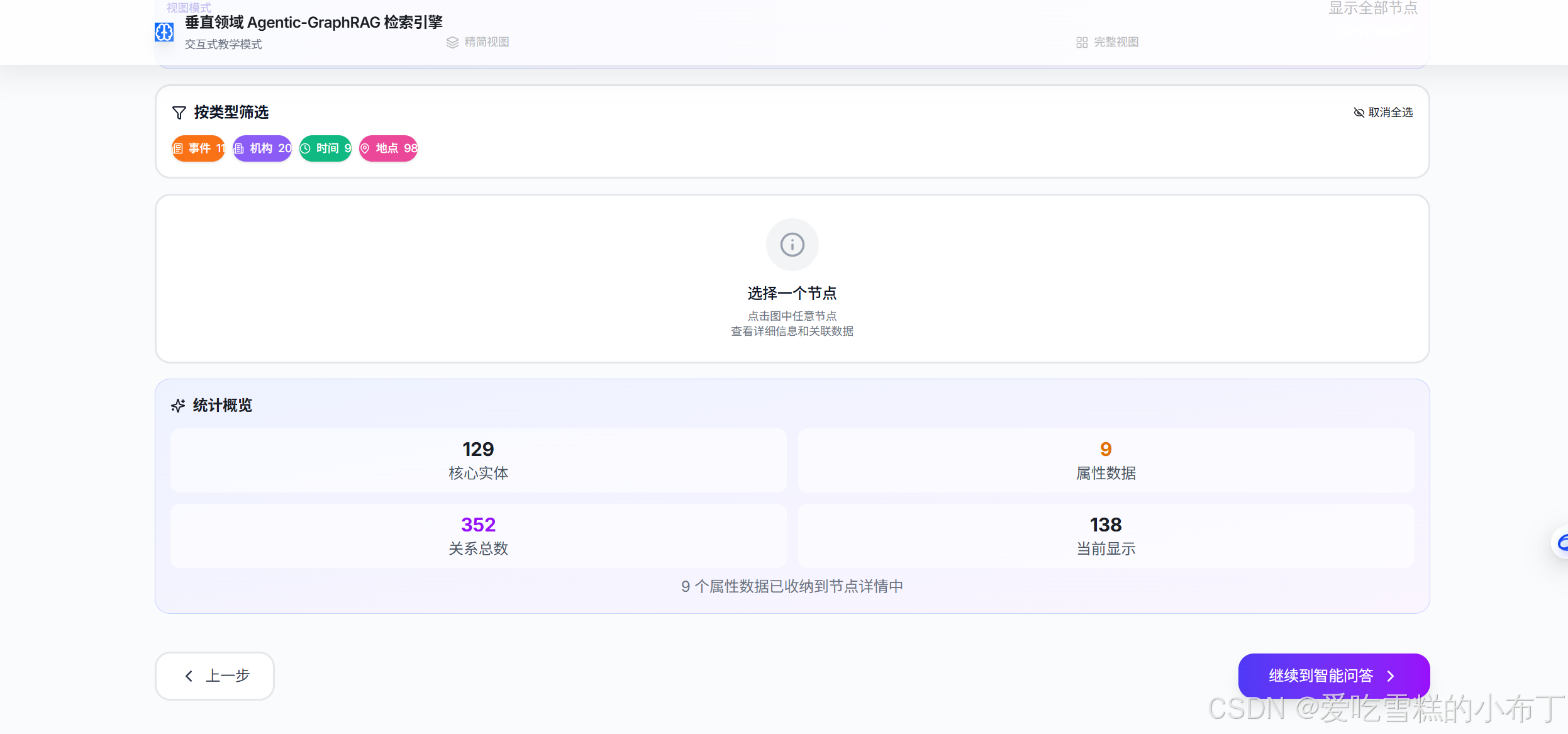
6、开始智能问答:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)