【强化学习】reward shaping经典文章:从“奖励更密”到“策略不变”
本文摘要
1999 年,Andrew Ng、Daishi Harada 和 Stuart Russell 在 ICML 发表了经典论文 Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping。这篇工作讨论了一个非常根本的问题:我们能否修改奖励函数,让学习更快,但又不改变最优策略? 论文给出的核心答案是:除了正线性变换之外,若要“普遍地”保持最优策略不变,附加奖励必须具有一种特殊结构——potential-based reward shaping。
很多强化学习实践者第一次接触 reward shaping 时,会把它理解成“多给点中间奖励”。这当然没错,但也不够。真正困难的是:中间奖励一旦设计不当,智能体就会学会刷分,而不是完成任务。论文中的结论之所以重要,正是因为它把“哪些奖励修改是安全的”说清楚了。
论文信息相关地址
参考文献:
【强化学习论文解读 2】 Theory and application to reward shaping
[伏羲讲堂]奖励设计相关论文介绍
原文下载链接:Theory and application to reward shaping
1. 从一个 5×5 网格世界开始:稀疏奖励的问题
先看一个简单环境。
环境设定
- 状态空间:5×5 网格世界,坐标记为 $ (x,y) $,其中 $ x,y\in{1,2,3,4,5} $
- 起点:默认设为 $ (1,1) $
- 终点:$ (5,5) $
- 动作:上移、右移、下移、左移
- 终止条件:智能体到达目标位置 $ (5,5) $ 后终止
2. 案例 1:奖励太稀疏,学习很慢
奖励设计(案例 1)
- 撞边界:奖励 $ -5 $
- 到达目标:奖励 $ +5 $
- 其他位置:奖励 $ 0 $
这是一种很常见的“目标奖励 + 违规惩罚”设计。它的优点是简单、直观,也确实表达了任务目标:不要撞墙,尽快到达终点。
但它的问题也非常明显:
2.1 奖励极其稀疏
在绝大多数状态转移中,奖励都是 0。也就是说,智能体只有在两类时刻能拿到明确反馈:
- 走到边界,得到 $ -5 $
- 终于走到目标,得到 $ +5 $
这意味着什么?意味着在训练初期,智能体很难判断“哪一步是在朝正确方向前进”。在从 $ (1,1) $ 到 $ (5,5) $ 的过程中,大量动作都不会立刻带来差异化反馈。于是,学习信号延迟、信用分配困难、探索效率低。
2.2 价值传播慢
即便目标奖励 $ +5 $ 很重要,它也只会在轨迹结束时出现。TD 学习或 Q-learning 需要许多轮更新,才能把这一终点价值逐步向前传播。状态越多、路径越长,这个问题越严重。
2.3 工程上的典型后果
- 训练前期几乎像在“瞎走”
- Q 值更新幅度小、区分度低
- 算法需要更多采样才能形成稳定策略
所以,工程上很自然的想法是:能不能把奖励改得更密一点?
3. 案例 2:奖励更稠密了,但新的问题出现了
奖励设计(案例 2)
- 撞边界:奖励 $ -10 $
- 到达目标:奖励 $ +10 $
- 其他位置:奖励 $ +1 $
和案例 1 相比,这个奖励函数明显“更积极”:
- 只要不撞墙、不终止,几乎每一步都有 $ +1 $
- 目标奖励更大,边界惩罚也更大
- 从表面看,反馈更丰富了,训练似乎也更稳定
但这里恰恰埋下了一个经典陷阱。
3.1 为什么案例 2 会诱发奖励投机
如果每走一步都能得到 $ +1 $,那么智能体就可能学会这样一件事:
不要着急结束任务,而是在安全区域里尽量多走几步,持续刷取过程奖励。
这就是所谓的 reward hacking / reward exploitation / 奖励投机:
智能体最大化的是你写下来的奖励函数,不是你心里真正想要的任务目标。
在这个例子里,人类真正想要的是:
“尽快到达 $ (5,5) $ 并结束任务。”
但案例 2 写下来的目标却更像是:
“在不撞墙的前提下,多活一会儿、多拿一些 $ +1 $。”
如果折扣因子接近 1,或者 episode 上限较长,那么绕路、循环、拖延终止,都可能变成高回报策略。
3.2 一个直观比较
假设从某状态出发:
- 方案 A:4 步到达终点,总回报约为 $ 1+1+1+10=13 $
- 方案 B:先绕 8 步,再到终点,总回报约为 $ 1\times 8 + 10=18 $
如果没有别的约束,绕路反而更优。
这说明案例 2 虽然“奖励更稠密”,但它已经在悄悄改变任务本身了。
4. 什么是奖励投机,真正的问题又是什么
Reward Hacking(奖励投机):是强化学习中的一个现象,指智能体通过利用奖励函数的设计缺陷或漏洞,采取非预期的策略来最大化奖励,而非真正完成设计者的目标任务
论文关注的问题可以表述为:
我们能对奖励函数做怎样的修改,使得奖励更稠密、学习效率更高,同时又保证最优策略不变?
这正是 reward shaping 的出发点。论文指出:随意加中间奖励是危险的;要想既加速学习又不改最优策略,需要对 shaping reward 的形式加以严格限制。
5. Reward Shaping:核心思想是什么
reward shaping 的想法很简单:
在原始环境奖励 $ R $ 之外,再加一个“引导性奖励” $ F $,构造新的奖励
$ R’(s,a,s’) = R(s,a,s’) + F(s,a,s’) $
其中 $ F $ 的作用不是改变任务目标,而是给学习过程“指路”。
比如,在网格世界中,我们希望:
- 朝目标靠近时,额外给一点正反馈
- 远离目标时,额外给一点负反馈
- 但不能因为这些额外反馈,让“绕圈刷分”变成更优策略
论文的关键贡献就在于:它给出了 什么样的 $ F $ 才是安全的。
6. 预备知识:理解 reward shaping 前需要什么
6.1 MDP
一个马尔可夫决策过程可以写成:
$ M=\langle S,A,T,\gamma,R\rangle $
其中:
- $ S $:状态集合
- $ A $:动作集合
- $ T(s’|s,a) $:转移概率
- $ \gamma\in[0,1] $:折扣因子
- $ R(s,a,s’) $:奖励函数
给定策略 $ \pi $,状态价值函数为:
$ V\pi(s)=\mathbb{E}\left[\sum_{t=0}\infty \gamma^t r_{t+1}\mid s_0=s,\pi\right] $
动作价值函数为:
$ Q^\pi(s,a)=\mathbb{E}\left[r_{1}+\gamma V^\pi(s_1)\mid s_0=s,a_0=a\right] $
最优策略满足:
$ \pi^(s)=\arg\max_a Q^(s,a) $
这些就是后面所有推导的基础。
6.2 reward shaping 的形式
我们定义一个附加奖励函数 $ F $,得到新奖励:
$ R’(s,a,s’)=R(s,a,s’)+F(s,a,s’) $
问题是:什么样的 $ F $ 不会改变最优策略?
7. 核心定理:什么样的 shaping 不改变最优策略
论文给出的定义是:
若存在某个势函数 $ \Phi:S\to\mathbb{R} $,使得
$ F(s,a,s’)=\gamma \Phi(s’)-\Phi(s) $
则 $ F $ 称为 potential-based shaping。
核心定理
如果 shaping reward 具有上式形式,那么在新 MDP
$ M’=\langle S,A,T,\gamma,R+F\rangle $
中,最优策略与原 MDP 完全一致;反过来也成立。论文还给出更强的结论:不仅最优策略保持不变,连任意策略 $ \pi $ 的 $ Q^\pi $ 与 $ V^\pi $ 都只会发生一个与状态有关的整体平移。
更具体地说:
$ Q_{M’}\pi(s,a)=Q_M\pi(s,a)-\Phi(s) $
$ V_{M’}\pi(s)=V_M\pi(s)-\Phi(s) $
由于对同一个状态 $ s $,所有动作的 Q 值都减去了同一个常数 $ \Phi(s) $,所以:
$ \arg\max_a Q_{M’}^\pi(s,a)=\arg\max_a Q_M^\pi(s,a) $
最优动作排序不变,最优策略自然不变。
8. 为什么这个形式有效:从 Bellman 方程看
论文中的证明思路很漂亮。先从原 MDP 的最优 Q 函数出发:
$ Q_M^(s,a)=\mathbb{E}{s’\sim P(\cdot|s,a)}
\left[
R(s,a,s’)+\gamma \max{a’}Q_M^(s’,a’)
\right] $
现在定义:
$ \hat Q(s,a)=Q_M^*(s,a)-\Phi(s) $
把它代进去:
$ \hat Q(s,a)
=\mathbb{E}\left[
R(s,a,s’)+\gamma\Phi(s’)-\Phi(s)
+\gamma \max_{a’}(Q_M^*(s’,a’)-\Phi(s’))
\right] $
注意到:
$ F(s,a,s’)=\gamma\Phi(s’)-\Phi(s) $
于是:
$ \hat Q(s,a)
=\mathbb{E}\left[
R(s,a,s’)+F(s,a,s’)
+\gamma \max_{a’}\hat Q(s’,a’)
\right] $
这恰好就是新 MDP $ M’ $ 的 Bellman 最优方程,所以:
$ \hat Q(s,a)=Q_{M’}^*(s,a) $
即:
$ Q_{M’}*(s,a)=Q_M*(s,a)-\Phi(s) $
这就证明了策略不变性。
9. 望远镜求和:为什么“整条轨迹上只差一个边界项”
上面的 Bellman 证明已经足够,但从轨迹回报的角度看,这个定理更容易直觉理解。
设原始回报为:
$ G=\sum_{t=0}{T-1}\gammat r_{t+1} $
加入 shaping 后:
$ G’=\sum_{t=0}{T-1}\gammat \big(r_{t+1}+F(s_t,a_t,s_{t+1})\big) $
如果
$ F(s_t,a_t,s_{t+1})=\gamma\Phi(s_{t+1})-\Phi(s_t) $
那么:
$ \sum_{t=0}{T-1}\gammat F(s_t,a_t,s_{t+1}) =
\sum_{t=0}{T-1}\gammat(\gamma\Phi(s_{t+1})-\Phi(s_t)) $
展开得:
$ =\sum_{t=0}{T-1}\gamma{t+1}\Phi(s_{t+1})-\sum_{t=0}{T-1}\gammat\Phi(s_t) $
把前几项写开:
$ =(\gamma\Phi(s_1)+\gamma2\Phi(s_2)+\cdots+\gammaT\Phi(s_T))
-(\Phi(s_0)+\gamma\Phi(s_1)+\gamma2\Phi(s_2)+\cdots+\gamma{T-1}\Phi(s_{T-1})) $
中间全部抵消,得到:
$ \sum_{t=0}{T-1}\gammat F(s_t,a_t,s_{t+1})
=-\Phi(s_0)+\gamma^T\Phi(s_T) $
因此:
$ G’=G-\Phi(s_0)+\gamma^T\Phi(s_T) $
这就是“望远镜求和”的本质:
整条轨迹上附加的 shaping 奖励,不是和路径细节强绑定,而只是把总回报改成了“原回报 + 一个起点项 + 一个终点项”。
这也是它不改变最优策略的根本原因。
10. 分别看 $ \gamma=1 $ 和 $ \gamma=0.9 $:望远镜求和怎么理解
10.1 当 $ \gamma=1 $
这时:
$ F(s,a,s’)=\Phi(s’)-\Phi(s) $
沿轨迹累加:
$ \sum_{t=0}^{T-1}F(s_t,a_t,s_{t+1})=\Phi(s_T)-\Phi(s_0) $
于是:
$ G’=G+\Phi(s_T)-\Phi(s_0) $
如果终止状态是吸收态,并且设 $ \Phi(s_T)=0 $,那么:
$ G’=G-\Phi(s_0) $
这表示:从同一个起点出发,所有轨迹总回报都统一平移了一个常数。
既然只是平移,轨迹优劣排序当然不变。
这也是为什么在 undiscounted setting 下,论文需要额外假设吸收终止态,并对终止态作特殊处理。
10.2 当 $ \gamma=0.9 $
这时:
$ F(s,a,s’)=0.9\Phi(s’)-\Phi(s) $
轨迹 shaping 总和为:
$ -\Phi(s_0)+0.9^T\Phi(s_T) $
如果终止态设 $ \Phi(s_T)=0 $,那么仍有:
$ G’=G-\Phi(s_0) $
和 $ \gamma=1 $ 的不同之处在于:
- $ \gamma<1 $ 时,未来势能的影响会被折扣
- shaping 的定义中必须乘上 $ \gamma $,否则望远镜结构会被破坏
- 正是这个 $ \gamma\Phi(s’) $ 而不是单纯 $ \Phi(s’) $,保证了折扣回报下的策略不变性
这是很多人第一次接触 shaping 时最容易忽略的点。
11. 结合案例 1:构造一个安全的案例 3
现在我们回到你的 5×5 网格世界,在 案例 1 的基础上构造一个 符合 reward shaping 的案例 3。
案例 3 的目标
我们希望:
- 保留案例 1 的任务目标
- 奖励更密,让智能体知道“靠近目标是好事”
- 仍然保证最优策略不变
原始奖励(仍然是案例 1)
$ R(s,a,s’)=
\begin{cases}
-5, & \text{如果撞边界} \
+5, & \text{如果到达目标 }(5,5) \
0, & \text{其他情况}
\end{cases} $
设折扣因子
$ \gamma=0.9 $
设计势函数:曼哈顿距离
令目标为 $ g=(5,5) $,定义曼哈顿距离:
$ d(s,g)=|x-5|+|y-5| $
定义势函数:
$ \Phi(s)=-d(s,g) $
这个选择非常自然:离目标越近,曼哈顿距离越小,$ \Phi(s) $ 越大。
shaping 奖励
$ F(s,a,s’)=0.9\Phi(s’)-\Phi(s) $
于是新的奖励函数为:
$ R_3(s,a,s’)=R(s,a,s’)+0.9\Phi(s’)-\Phi(s) $
这就是案例 3。
12. 案例 3 的直观含义
因为 $ \Phi(s)=-d(s,g) $,所以:
$ F(s,a,s’)=0.9(-d(s’))-(-d(s))
=d(s)-0.9d(s’) $
于是:
- 如果朝目标前进,$ d(s’)=d(s)-1 $,则
$ F=d-0.9(d-1)=0.1d+0.9>0 $
- 如果远离目标,$ d(s’)=d(s)+1 $,则
$ F=d-0.9(d+1)=0.1d-0.9 $
- 在靠近目标区域通常为负
- 如果撞边界导致原地不动,$ d(s’)=d(s) $,则
$ F=0.1d $
- 但此时原始奖励里已经有 $ -5 $,总奖励仍强烈为负
所以案例 3 做到了:
- 靠近目标:有额外正反馈
- 远离目标:有额外负反馈或更小反馈
- 撞边界:仍然明显不划算
- 更关键的是:最优策略不变
13. 案例 3 的状态势能图示
下面给出 5×5 网格中各状态的曼哈顿距离和势函数值。为了方便展示,我把 $ y=5 $ 放在最上面。
13.1 网格世界势函数图 $ \Phi(s)=-d(s,g) $
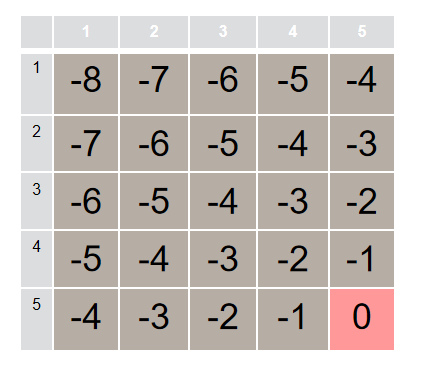
14. 案例 3 的具体数值计算
14.1 从 $ (2,2) $ 向右走到 $ (3,2) $
- 当前状态:$ (2,2) $,距离 $ d=6 , , , \Phi=-6 $
- 下一状态:$ (3,2) $,距离 $ d’=5 , , , \Phi’=-5 $
shaping 奖励:
$ F=0.9\times(-5)-(-6)=1.5 $
若该步不是边界也不是终点,则案例 1 原始奖励为 0,所以:
$ R_3=0+1.5=1.5 $
说明:向目标靠近,立刻得到正反馈。
14.2 从 $ (2,2) $ 向左走到 $ (1,2) $
- 当前距离 $ d=6 $
- 下一距离 $ d’=7 $
$ F=0.9\times(-7)-(-6)=-0.3 $
原始奖励仍是 0,所以:
$ R_3=-0.3 $
说明:远离目标,立刻受到轻微惩罚。
14.3 从 $ (1,2) $ 再向左,撞边界
撞边界后仍停在 $ (1,2) $,于是:
- $ d=d’=7 $
- $ \Phi=\Phi’=-7 $
$ F=0.9\times(-7)-(-7)=0.7 $
但案例 1 中撞边界的原始奖励是 $ -5 $,所以:
$ R_3=-5+0.7=-4.3 $
说明:虽然 shaping 项本身可能为正,但总奖励仍然强烈惩罚撞墙。这也提醒我们:看 shaping 时必须看“总奖励”,而不是只看附加项。
14.4 终点附近的一步:$ (4,5)\to(5,5) $
- $ (4,5) $ 距离 $ d=1 , , , \Phi=-1 $
- $ (5,5) $ 距离 $ d’=0 , , , \Phi’=0 $
$ F=0.9\times 0 - (-1)=1 $
原始到达目标奖励为 $ +5 $,所以:
$ R_3=5+1=6 $
说明:最后一步会得到更强的正反馈,但它并没有改变“到终点最好”这件事。
15. 为什么案例 3 不会像案例 2 那样刷分
关键就在于:案例 2 给的是“每走一步固定 +1”,它和轨迹长度正相关,所以会鼓励拖延终止。
而案例 3 里,每一步额外奖励不是固定的,而是:
$ F(s,a,s’)=0.9\Phi(s’)-\Phi(s) $
沿一整条轨迹加总之后,它会坍缩成:
$ -\Phi(s_0)+0.9^T\Phi(s_T) $
如果终点势能取 0,那么总 shaping 回报就是:
$ -\Phi(s_0) $
它只由起点决定,与中间你是“直走”还是“绕圈”无关。
这就是为什么它不会系统性鼓励刷过程奖励。
一句话总结:
案例 2 奖励的是“走了多少步”,案例 3 奖励的是“状态势能的净变化”。
前者会诱导刷分,后者不会。
16. Reward shaping 成立的必要条件是什么
论文的结论不是“potential-based shaping 很好用”这么简单,而是更强:
在没有额外领域知识可利用时,若希望对任意 MDP 都保持最优策略不变,那么附加奖励必须是 potential-based 的;否则,总能构造出某些 MDP,使得这种奖励修改改变最优策略。
这就是“充要条件”里最重要的一半:
不是你恰好构造出了一个有效 shaping,而是只有这类结构,才有普适的安全保证。
这背后的直觉是什么
如果附加奖励不能写成势差,那么它对一条闭环轨迹的累计奖励一般就不为 0。
于是智能体可能通过反复绕圈,凭空制造额外回报。
这正是论文里“正向奖励循环”问题的本质,也是很多 reward hacking 的共同根源。
17. 一个重要旁支:它和 Q 值初始化有什么关系
后续工作进一步指出,potential-based shaping 与某种 Q 值初始化在更新轨迹上是等价的。直观讲:
- 你可以把 shaping 看成“每一步都给额外奖励”
- 也可以把它理解成“先验地告诉模型哪些状态更有前景”
这给工程实践一个启发:
有时你不一定非得改奖励函数,也可以通过 value initialization / Q initialization 注入相同偏好。
18. 在 RLHF 中,reward shaping 还成立吗
这是最值得讨论的问题之一。
我的结论是:
在“形式上”,reward shaping 的理论仍然成立;但在“现实的 RLHF 系统”里,它通常不能直接原样套用。
18.1 为什么说“形式上成立”
如果你把 RLHF 也写成一个标准 MDP:
$ M=\langle S,A,T,\gamma,R\rangle $
并且你真的往奖励里加入了一个严格满足
$ F(s,a,s’)=\gamma\Phi(s’)-\Phi(s) $
的 shaping 项,那么策略不变性的定理依然成立。
因为定理依赖的是 MDP 结构和 reward transformation 的形式,不依赖任务是不是语言模型。
18.2 为什么说“现实里往往不成立”
RLHF 有几个困难点:
第一,状态定义并不稳定
在语言生成里,“状态”通常是前缀 token 序列。理论上可以这么定义,但现实中:
- 上下文极高维
- 部分可观测性强
- 截断、packing、batching、masking 会改变训练接口
于是想构造一个“真正只依赖状态的势函数 $ \Phi(s) $”并不容易。
第二,实际奖励常常不是环境真奖励
RLHF 里的奖励通常来自 reward model,它本身就是一个近似器。
一旦 reward model 有偏差,模型就可能学会 exploit 这个近似器,而不是满足真实人类偏好。
第三,训练目标往往不只是“总奖励”
现代大模型 RL 微调经常还包含:
- KL 惩罚
- 长度控制
- 格式奖励
- 安全惩罚
- 拒答偏好
- 参考模型约束
这些项混在一起后,整体优化目标已经不再是“原始奖励 + 一个纯势差项”这么简单。
第四,很多 shaping 是 action-dependent 或 sequence-level 的
例如:
- “回答更长一点加分”
- “出现某些关键词加分”
- “给出链式推理格式加分”
这些往往不能写成 $ \gamma\Phi(s’)-\Phi(s) $ 的形式,因此没有策略不变性的理论保证。
18.3 所以 RLHF 中 reward shaping 的正确理解
在 RLHF 中,reward shaping 更现实的角色是:
- 改善优化稳定性
- 改善梯度尺度
- 减少 reward model 的局部漏洞被利用
- 不是严格保证 policy invariance,而是降低 reward hacking 风险
所以答案是:
- 狭义理论上:成立
- 广义工程上:通常不严格成立,只能部分借鉴其思想
19. 这篇论文对大模型强化学习微调有什么启示
这篇论文最大的启发不是“给奖励加个公式”,而是:
奖励设计不是只看训练快不快,更重要的是看它有没有偷偷改掉真正想优化的行为。
在大模型强化学习微调里,这一点尤其重要。因为模型能力越强,越擅长发现漏洞。
下面给出一些具体建议。
20. 给大模型 RL 微调奖励设计的 12 条建议:尽量避免奖励投机
1)先写“真实任务目标”,再写 reward
不要一上来就写一堆启发式奖励。先明确:
- 你真正想优化的是正确性、帮助性、安全性,还是用户满意度?
- 哪些只是代理指标?
很多奖励投机,根源是把代理指标误当目标本身。
2)避免“固定每步加分”式设计
类似案例 2 的“每生成一个 token 就加分”“回答越长越加分”,极易诱导拖长、重复、空话。
3)优先使用“进度差分”而不是“过程累计”
若要塑造过程奖励,尽量奖励“状态势能净变化”,不要奖励“停留时长”或“动作次数”。
4)把 shaping 设计成 state-based,而非 ad hoc 的 action bonus
如果奖励依赖某个动作模板、措辞模板、表面格式,很容易被语言模型模板化利用。
5)能写成 potential-based 的,尽量写成 potential-based
例如:
- 更接近完成约束
- 更接近正确答案
- 更接近任务终止条件
这类“接近目标程度”的信号,比“出现某关键词加分”更稳健。
6)对终止奖励与过程奖励做量纲校准
要防止过程奖励总和盖过最终任务奖励。
否则模型会优化“看起来像在做任务”,而不是“真正完成任务”。
7)避免单一标量奖励承载太多目标
帮助性、安全性、事实性、简洁性常常冲突。
把它们粗暴塞进一个分数,容易让模型找到奇怪折中点。
8)给奖励做上界和裁剪
有界奖励有助于降低训练不稳定和 reward hacking 风险。
9)警惕“长度”“格式”“拒答率”成为刷分通道
任何可被模型低成本操控、却和真实任务质量不完全一致的指标,都可能被 exploit。
10)做 counterexample 测试
不要只看平均 reward,要专门构造对抗样本:
- 冗长空洞回答
- 套模板回答
- 安全但没帮助的回答
- 看似正确实则胡编的回答
如果这些样本得分偏高,你的奖励就有漏洞。
11)分开评估“reward 提升”和“真实质量提升”
训练日志里 reward 上升,不等于用户体验上升。
必须用独立评测、人工审查、偏好对比去验证。
12)能用初始化、约束、数据清洗解决的问题,不一定非要改 reward
类似地,在 LLM 中,很多“奖励修补”问题,其实更适合通过:
- 更好的 SFT 数据
- 更强的 reference/KL 约束
- 更干净的 preference data
来解决。
21. 一句话总结这篇论文
这篇论文最值得记住的,不是某个公式,而是一条设计原则:
好的 reward shaping 不是“多给奖励”,而是“在不改变最优策略的前提下,让正确行为更容易被学到”。
在你的两个网格案例里:
- 案例 1:目标明确,但奖励稀疏,学习慢
- 案例 2:奖励更密,但引入了奖励投机
- 案例 3:用
$ F(s,a,s’)=\gamma\Phi(s’)-\Phi(s) $
- 这样的 potential-based shaping,在保留任务本意的同时,让“朝目标前进”获得了更密集的反馈
这就是 reward shaping 的精髓。
22. 结语
很多强化学习失败案例,看起来像是算法不够强,实际上是奖励函数写错了。
而这篇 1999 年的论文之所以经典,正是因为它把奖励工程从“经验技巧”提升成了“可证明的设计原则”。它告诉我们:
- 奖励可以改
- 学习可以加速
- 但不是随便改
- 一旦你修改奖励,就必须问:最优策略还在吗?
对传统 RL 是这样,对今天的大模型 RLHF 也是这样。区别只在于:LLM 更复杂,也更擅长钻空子,所以我们更需要这种“先保证目标不变,再谈训练效率”的思维方式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)