系统架构设计师常见高频考点总结之组成结构与操作系统
1. 操作系统四大基本管理功能
操作系统的内核(Kernel)作为最底层的软件,其四大基本管理功能是计算机基础理论中的常识:
-
进程管理:负责CPU的时间片分配、任务调度等(对应处理器管理)。
-
内存管理:负责内存的分配与回收。
-
文件管理:负责文件的存储、检索和保护。
-
设备管理:负责管理各类外设(I/O设备)。
2. 前趋图与PV操作(信号量)
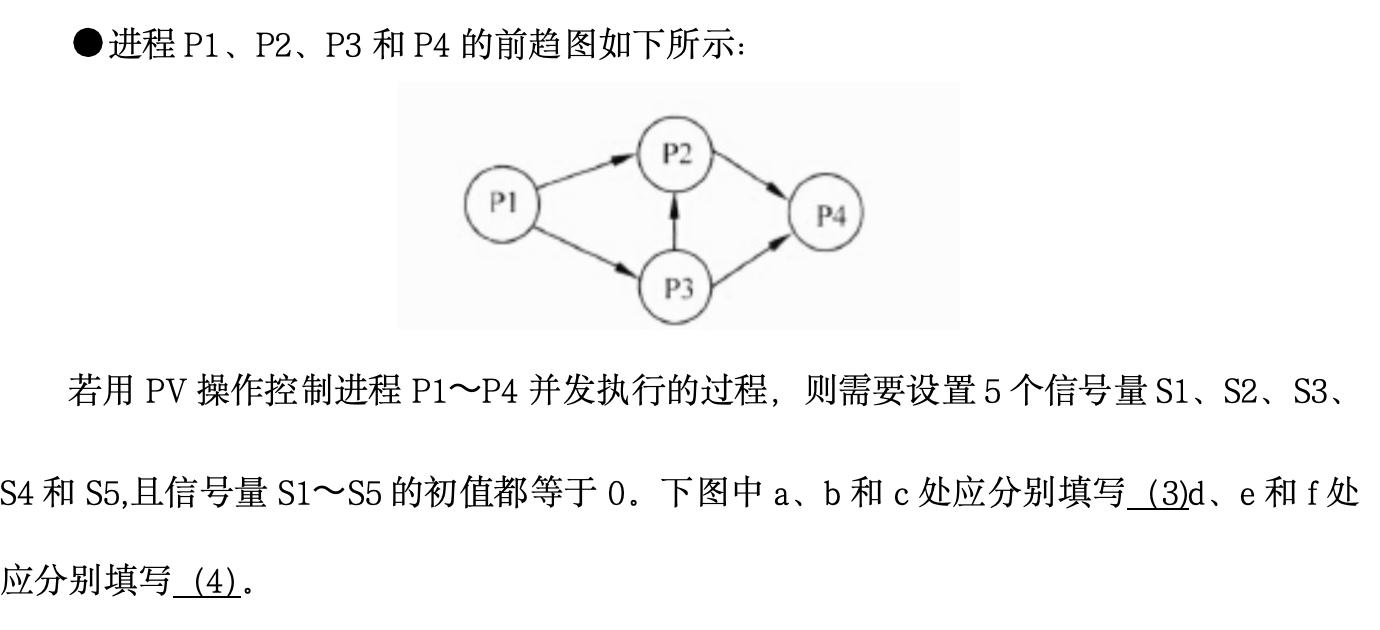
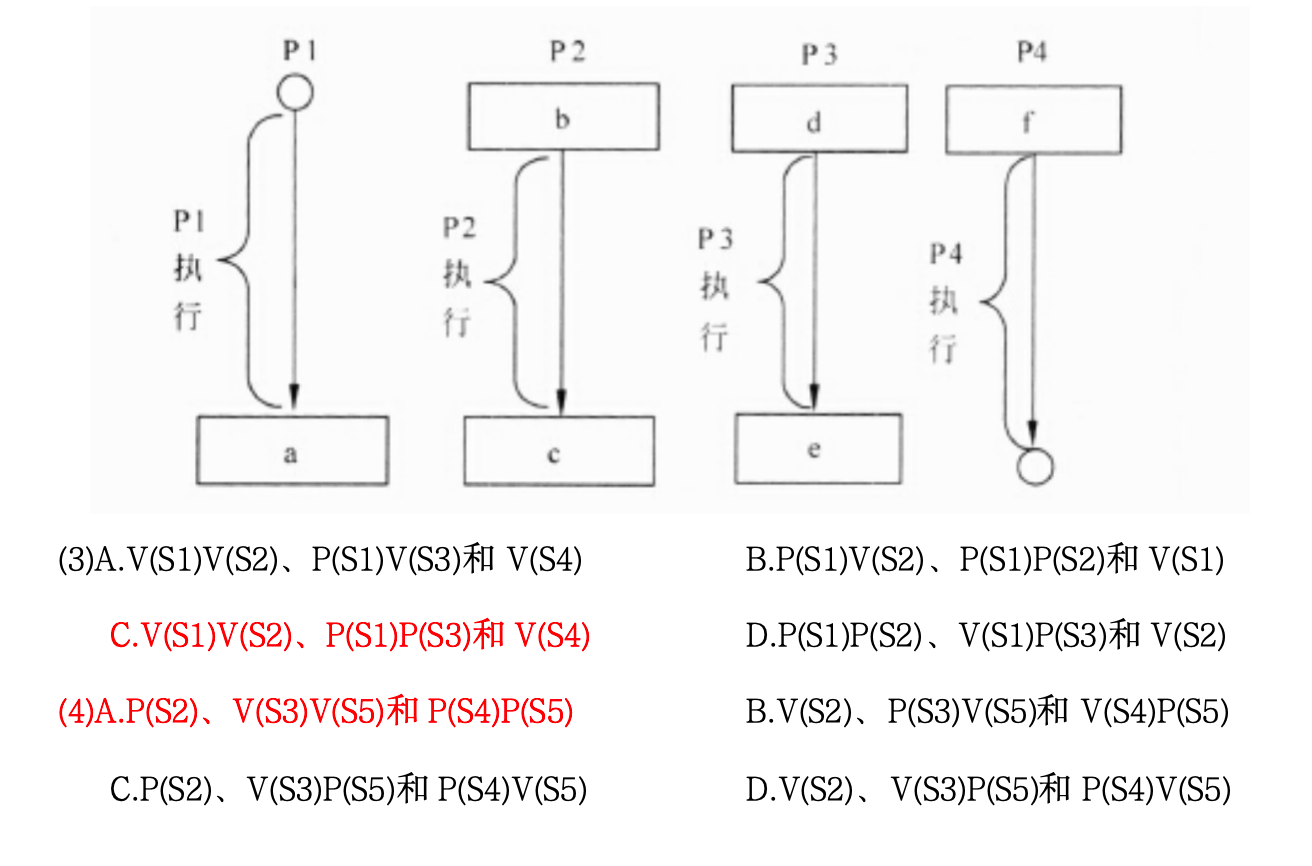
非常经典的前趋图与PV操作(信号量)题目。在软考的操作系统模块中,这类题几乎每年必考。在进程同步中,我们使用信号量(Semaphore, S)来控制执行顺序:
-
前趋进程(先做完的):执行 V操作(V(S),相当于“发送信号/释放资源”),告诉后面的人“我做完了”。
-
后继进程(后开始的):执行 P操作(P(S),相当于“等待信号/申请资源”),检查前面的人有没有做完。
口诀:箭头出发点写 P,箭头指向点写 V
3. 前驱图(DAG)的并发控制逻辑
某计算机系统中有一个CPU、一台扫描仪和一台打印机。现有三个图像处理任务,每个任务有三个程序段:扫描Si,图像处理Q和打印Pi(i=l,2,3)。下图为三个任务各程序段并发执行的前驱图,其中,(1)可并行执行,(2)的直接制约,(3)的间接制约。
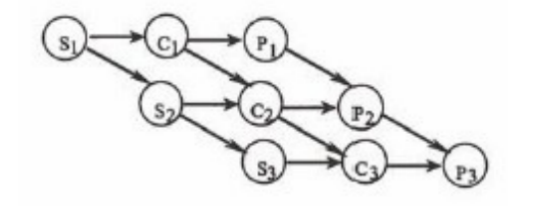
(1) A.“C1S2”,"P1C2S3“,“P2C3” B.“C1S1",“S2C2P2”,“C3P3”
C."S1C1P1",“S2C2P2",“S3C3P3” D."S1S2S3","C1C2C3","P1P2P3"
(2) A.S1受到S2和S3、C1受到C2和C3、P1受到P2和P3
B.S2和S3受到S1、C2和C3受到C1、P2和P3受到P1
C.C1和P1受到S1、C2和P2受到S2、C3和P3受到S3
D.C1和S1受到P1、C2和S2受到P2、C3和S3受到P3
(3) A.S1受到S2和S3、C1受到C2和C3、P1受到P2和P3
B.S2和S3受到S1、C2和C3受到C1、P2和P3受到P1
C.C1和P1受到S1、C2和P2受到S2、C3和P3受到S3
D.C1和S1受到P1、C2和S2受到P2、C3和S3受到P3
- “直接制约”就是我们常说的同步。它是指进程之间存在业务逻辑上的前后依赖(数据传递)。就像流水线,后一个工序必须等前一个工序把半成品送过来才能开工。
- “间接制约”就是我们常说的互斥。它是指进程之间本身没业务交集,但因为争抢同一个有限的物理硬件资源而被迫排队。
4. 操作系统分页存储管理
这是一道关于操作系统分页存储管理的基础计算题。这类题目在软考中属于送分题,只要掌握了“除法取整”和“页表映射”两个概念即可轻松搞定。地址转换(逻辑地址转物理页号)
核心概念:
在分页系统中,逻辑地址不是直接对应物理内存的,它被切割成了两部分:
-
页号 (Page Number):数据在第几页?
-
页内偏移 (Offset):数据在该页的第几个位置?
计算公式:
页号 = 逻辑地址 / 页面大小 (取整数部分)
页内偏移 = 逻辑地址 % 页面大小 (取余数部分)
5. 流水线时间计算
1.基础定义
n = 指令条数
![]() = 一条指令完整执行的时间(非流水线时间)
= 一条指令完整执行的时间(非流水线时间)
![]() = 流水线周期(瓶颈时间)
= 流水线周期(瓶颈时间)
k = 流水线级数
-
不使用流水线:n*
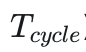
-
使用流水线:公式: (𝑘+𝑛−1) *
(公式:其中 k=级数, n=指令数)
2.最大吞吐率
1. 核心概念:木桶效应(瓶颈)
流水线的工作原理就像工厂的流水线。不管你的其他工序(取指、分析)做得多快,整个流水线的生产速度(也就是时钟周期 ![]() )只能取决于最慢的那一道工序。
)只能取决于最慢的那一道工序。
2. 吞吐率计算
-
吞吐率 (TP):单位时间内处理指令的数量。
-
公式:
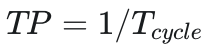
3. 最大理论加速比
标准公式是
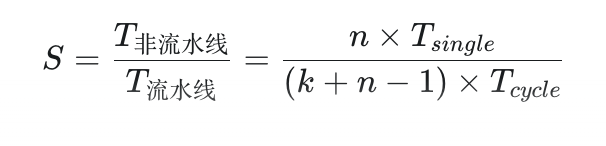
当任务量巨大时(n→∞)想象一下,如果不是执行 10 条指令,而是执行 10亿 条指令(n 非常大)。此时,分母里的 (k−1)(也就是流水线的建立时间)相对于 n 来说,小到可以忽略不计。公式就变成了:
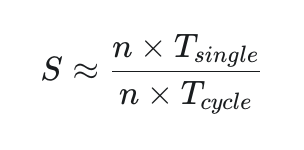
把 n 约掉:
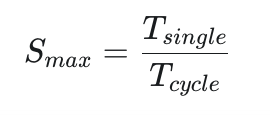
6. 磁盘阵列(RAID)容量计算规则
1. 基础知识:RAID 5 是什么
-
特点:它把数据切块存在不同硬盘上,同时计算出一份“校验数据”(Parity)。
-
代价:为了保证坏掉一块盘还能找回数据,RAID 5 必须消耗掉相当于 1 块硬盘容量的空间来存校验信息。
- 核心公式:可用容量=(𝑁−1)×单块盘容量(其中 N 是硬盘的总数量)
2. 场景一:三块盘大小一样
题目:3 块 80G 的硬盘做 RAID 5 这是最标准的情况。
-
损耗:必须扣除 1 块盘的空间存校验码。
-
计算:(3−1)×80G=2×80G=160G
3. 场景二:硬盘大小不一样
题目:2 块 80G + 1 块 40G 做 RAID 5。
解析:这里涉及到一个极其重要的原则:木桶效应(短板效应)。
在组建标准 RAID 时,为了保证数据能整齐地切分和排列,所有硬盘的“有效容量”必须向最小的那块看齐。
-
短板:最小的盘是 40G。
-
后果:系统会强行把那两块 80G 的盘也当成 40G 来用。
-
80G 盘 A → 只用前 40G,剩下 40G 浪费掉。
-
80G 盘 B → 只用前 40G,剩下 40G 浪费掉。
-
40G 盘 C → 用满 40G。
-
-
现在的情况变成了:相当于你有 3 块 40G 的硬盘在做 RAID 5。
4. 总结记忆公式
遇到 RAID 容量计算题,记住这两个步骤:
-
先看齐(切短板):
如果硬盘大小不一样,先找到最小的那块。把所有硬盘的容量都视为这个最小容量(多余的舍弃)。 -
再扣除(算校验):
-
RAID 0:不扣除。容量 = N×最小容量。
-
RAID 1:扣一半(只有2块盘时)。容量 = 1×最小容量
-
RAID 5:扣一块。容量 = (𝑁−1)×最小容量
-
RAID 6:扣两块。容量 = (𝑁−2)×最小容量
-
7. 磁盘I/O性能计算题
1. 核心参数提取
拿到题目,先在草稿纸上写下这三个数值:
1. ![]()
(读取/传输时间):读取一个物理块需要的时间。
计算公式:𝑑=旋转周期/每道块数Tread=旋转周期/每道块数
2. ![]()
(处理时间):CPU 处理一条记录的时间。
3. 缓冲区类型:
-
单缓冲区:读和处理是串行的(读入->处理->读入...)。
-
双缓冲区:读和处理是并行的(处理第1个的同时,可以读第2个)。
2. 两种情况的计算公式
针对软考中的磁盘I/O性能计算题(尤其是单/双缓冲区、优化/非优化分布),这类题目有非常固定的解题套路和“软考专用逻辑”。
2.1. 非优化分布(顺序存放)—— “错过等一圈”逻辑
场景:数据按 𝑅1,𝑅2,𝑅3... 物理相邻存放。
逻辑:
读完 R1 花了 3ms。
接着处理 R1 花了 6ms。
关键点:在处理的这 6ms 里,磁盘还在转!它转过了 6/3= 个块。
后果:当系统处理完 R1 想去读 R2 时,磁头已经越过了 R2 的位置(跑到了 R4 开头)。
惩罚:必须等磁盘转一整圈,再次回到 R2 的开头。
计算公式(前 N-1 个 + 最后一个):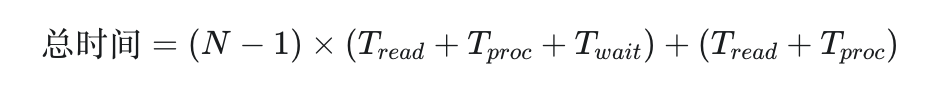
通常为了简化,可以直接算:N * 每条记录耗时 = N * (读取 + 处理 + 等待回转) 。
2.2. 优化分布(间隔存放)—— “无缝衔接”逻辑
场景:数据按 𝑅1,空,空,𝑅2...R1,空,空,R2... 间隔存放。
逻辑:
读完 R1 花了 3ms。
处理 R1 花了 6ms。
关键点:在这 6ms 里,磁盘转过了 2 个块的位置。
优化目标:我们将 R2 正好放在 R1 后面隔 2 个块的地方。
结果:当 CPU 处理完 R1,磁头刚好转到了 R2 的开头。不需要任何等待(寻道/旋转延迟为0)。
单缓冲区下的计算逻辑:
由于是单缓冲区,系统必须“读完 -> 才能处理 -> 处理完缓冲区空了 -> 才能再读”。哪怕物理位置对上了,你也必须先把 R1 处理完,才能发指令读 R2。
读 R1:3ms
处理 R1:6ms (此时磁头转到 R2 开头,完美!)
读 R2:3ms
处理 R2:6ms
...
总时间公式: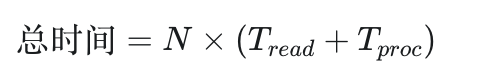
3. 软考做题“秒杀”技巧
遇到这种题,直接套用以下经验:
-
非优化:时间特别长,通常是几百毫秒。

-
优化:时间短。
-
单缓冲区(最常见):
-
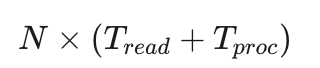
-
双缓冲区(较少考):
磁盘读取:旋转延迟演示
4. 题目变形
某磁盘磁头从一个磁道移至另一个磁道需要10ms。文件在磁盘上非连续存放,逻辑上相邻数据块的平均移动距离为10个磁道,每块的旋转延迟时间及传输时间分别为100ms和2ms,则读取一个100块的文件需要 ms的时间。
机械硬盘 (HDD) 工作原理演示
很多人在刚接触磁盘物理结构时,都会把“移动时间(寻道时间)”和“旋转延迟时间”混为一谈,因为它们听起来都是“找数据花的时间”。
但实际上,它们对应的是磁盘内部两个完全不同的机械运动。
为了直观地理解,准备了一个磁盘读取的交互式动态演示图。在看图之前,我们先用一句话总结它们的区别:
移动时间(寻道时间): 是磁头臂在做横向伸缩运动,找对“哪一圈”(磁道)。
旋转延迟时间: 是磁盘盘片在做圆周旋转运动,等目标数据“转过来”(扇区)。
8. 单双缓冲区问题
某计算机系统输入/输出采用双缓冲工作方式,其工作过程如下图所示,假设磁盘块与缓冲区大小相同,每个盘块读入缓冲区的时间T为10μs,缓冲区送用户区的时间M为6μs,系统对每个磁盘块数据的处理时间C为2μs。若用户需要将大小为10个磁盘块的Docl文件逐块从磁盘读入缓冲区,并送用户区进行处理,那么采用双缓冲需要花费的时间为___μs,比使用单缓冲节约了___μs时间。
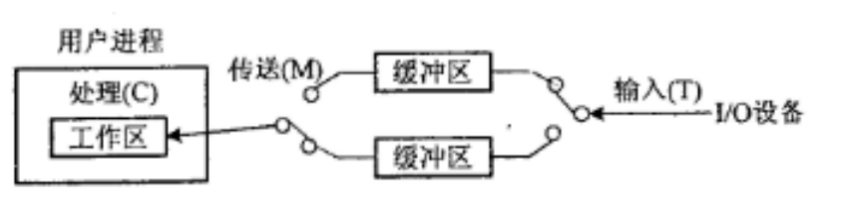
1. 计算单缓冲区的总时间
在单缓冲机制下,缓冲区是一个“独木桥”。磁盘把数据放进缓冲区(T),然后缓冲区把数据传给工作区(M),在这两个动作完成之前,磁盘都不能去读下一个块。
只有当数据传送完毕(M结束),缓冲区空出来了,磁盘才能开始读下一块。而在读下一块的同时,CPU 可以处理上一块的数据(C)。
-
运行规律: 每一块数据的耗时主体是读入(T) + 传送(M)。因为 T (10) > C (2),所以读下一块的时间完全可以把处理上一块的时间“盖住”。
-
通项公式: (T + M) *n + C
-
代入计算: (10 + 6) *10 + 2 = 162
-
(也就是:前面10块都在不断地读和传,花了160微秒,最后一块传完后,还需要2微秒处理完毕)
2. 计算双缓冲区的总时间
双缓冲区就像是有了两个备用盘子。磁盘在把数据装进“缓冲区1”后,不用等它传完,可以直接开始把下一块数据装进“缓冲区2”。
这就形成了一个完美的流水线:磁盘疯狂往里读 (T),同时内部疯狂往外传和处理 (M+C)。
-
找瓶颈(谁慢听谁的): * 磁盘进货速度:T = 10
-
内部消耗速度:M + C = 6 + 2 = 8
-
因为 T (10) > M+C (8),说明“进货太慢,消耗太快”。整个系统的瓶颈卡在磁盘读入(T)上。
-
-
通项公式(当 T > M+C 时): T * n + M + C
-
理解:既然读入最慢,那就按读入的时间算大头(10块一直读完需要 10 *10),等最后一块读完后,顺理成章地加上它最后的传送和处理时间(M+C)。
-
-
代入计算: 10 * 10 + 6 + 2 = 108
3. 计算节约的时间
这一步最简单,直接拿单缓冲的时间减去双缓冲的时间即可。
-
计算: 162 - 108 = 54
以后遇到这种题,直接套这个模板,连图都不用画:
单缓冲区: 直接算 (T + M) * n + C
双缓冲区: 先比较 T 和 (M+C)谁大:
如果 T大(最常见):时间 = T *n + M + C
如果 (M+C) 大(少数情况):时间 = T + (M+C) * n
某磁盘磁头从一个磁道移至另一个磁道需要10ms。文件在磁盘上非连续存放,逻辑上相邻数据块的平均移动距离为10个磁道,每块的旋转延迟时间及传输时间分别为100ms和2ms,则读取一个100块的文件需要(11) ms的时间。
9. 最短移臂调度算法 (SSTF)
核心解题规则
1.第一优先级:移臂调度(找柱面/磁道)
-
原则:最短移臂调度(SSTF, Shortest Seek Time First)。
-
做法:看当前磁头在哪里,下一步去离当前位置最近的那个柱面(Cylinder)。
-
原因:机械臂移动是最耗时的动作(毫秒级),必须优先优化。
2.第二优先级:旋转调度(找扇区)
-
原则:当几个请求都在同一个柱面上时,不需要移动机械臂了。此时为了减少等待磁盘旋转的时间,按照扇区号(Sector)从小到大的顺序处理(模拟磁盘旋转的方向)。
-
做法:柱面相同,谁的扇区号小,谁先执行。
3. 第三优先级(如有必要):磁头号
-
如果柱面和扇区都一样,通常按磁头号排序(电子切换速度极快),或者按照请求的先后顺序。
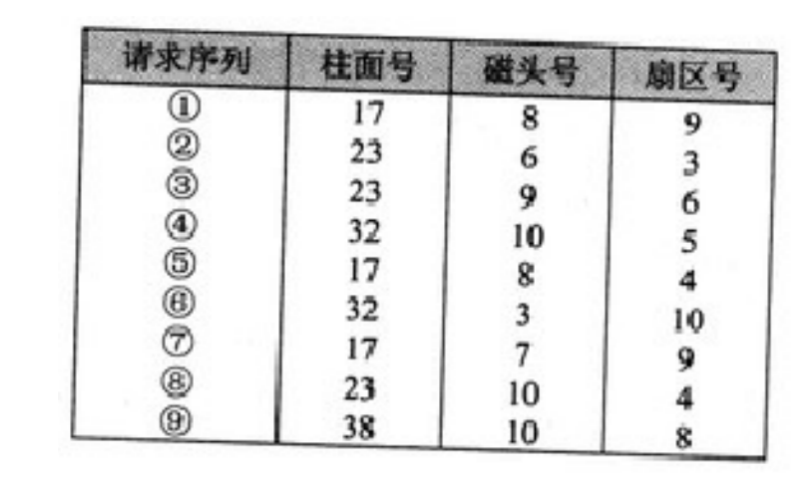
在柱面 23 时(请求 ②, ③, ⑧):
②的扇区是 3
③的扇区是 6
⑧的扇区是 4
从小到大排序:3 -> 4 -> 6,对应请求顺序:② -> ⑧ -> ③
在柱面 17 时(请求 ①, ⑤, ⑦):
①的扇区是 9
⑤的扇区是 4
⑦的扇区是 9
从小到大排序:4 -> 9 -> 9,对应请求顺序:⑤ -> ⑦ -> ① (同扇区的①和⑦顺序其实无所谓,看选项定)
在柱面 32 时(请求 ④, ⑥):
④的扇区是 5
⑥的扇区是 10
从小到大排序:5 -> 10,对应请求顺序:④ -> ⑥
在柱面 38 时(请求 ⑨):
只有 ⑨。
将上面的微观顺序拼接起来,最终完美的响应序列就是:
🎯 结论 : 将上面的微观顺序拼接起来,最终完美的响应序列就是:② ⑧ ③ -> ⑤ ⑦ ① -> ④ ⑥ -> ⑨
10. CRC 循环冗余校验码
1.计算逻辑
信息码字为111000110,生成多项式 G(x)=x^5+x^3+x+1,计算校验码,。
-
多项式转二进制:G(x) 对应 101011。
-
补位与模二除法:在信息码后加5个0(由x^5决定),用 11100011000000 除以 101011。
-
结果:余数为 11001,即为校验码,。理解核心在于模二除法不借位的运算规则。
2. 模二除法
不要像传统除法那样每一位都写商。我们只关注余数。规则:
对齐:永远把除数的最高位 1,对齐被除数(或当前余数)的最高位 1。
异或:进行异或运算(相同为0,不同为1)。
拉位:运算结果去掉开头的 0,然后从被除数后面把数字拉下来。关键点:如果拉下来后位数不够6位,就继续拉,直到凑够6位(或者首位是1)再进行下一次运算。
第 1 步:
111000 (取前6位,首位是1,够除)
101011 (除数对齐)
------
010011 (异或结果)
10011 (去掉首位0,剩5位)第 2 步:(拉下来一位 1,凑够6位)
10011 1 (拉下来1,变成6位,首位是1,够除)
10101 1 (除数对齐)
-------
00110 0 (异或结果)
110 0 (去掉首位两个0,剩4位)第 3 步:(连续拉位 —— 这是简便法的精髓)
-
当前余数:1100(4位)
-
拉一位 1 → 11001 (5位,不够除数6位,不要做运算,直接跳过)
-
再拉一位 0 → 110010 (6位,够了!)
11001 0 (凑够了6位,进行运算)
10101 1
-------
01100 1 (异或结果)
1100 1 (去掉首位0,剩5位)第 4 步:(继续拉位)
-
当前余数:11001(5位)
-
拉一位 0 → 110010 (6位,够了)
-
观察:这一步和第3步一模一样!说明进入了循环模式。
11001 0
10101 1
-------
01100 1
1100 1 (去掉首位0,剩5位)第 5 步:(继续拉位)
-
当前余数:11001
-
拉一位 0 → 110010
-
继续一样的运算...
11001 0
10101 1
-------
1100 1第 6 步:(最后一位 0)
-
当前余数:11001
-
拉一位 0 → 110010
-
最后一次运算...
11001 0
10101 1
-------
1100 1 (最终余数)最终剩下的 5 位数是 11001。
考场操作建议:
在草稿纸上,按照上面的阶梯状格式写,每次运算完划掉前面的0,不够就往下拉,直到被除数的所有位都被拉完为止。
11. 文件索引节点法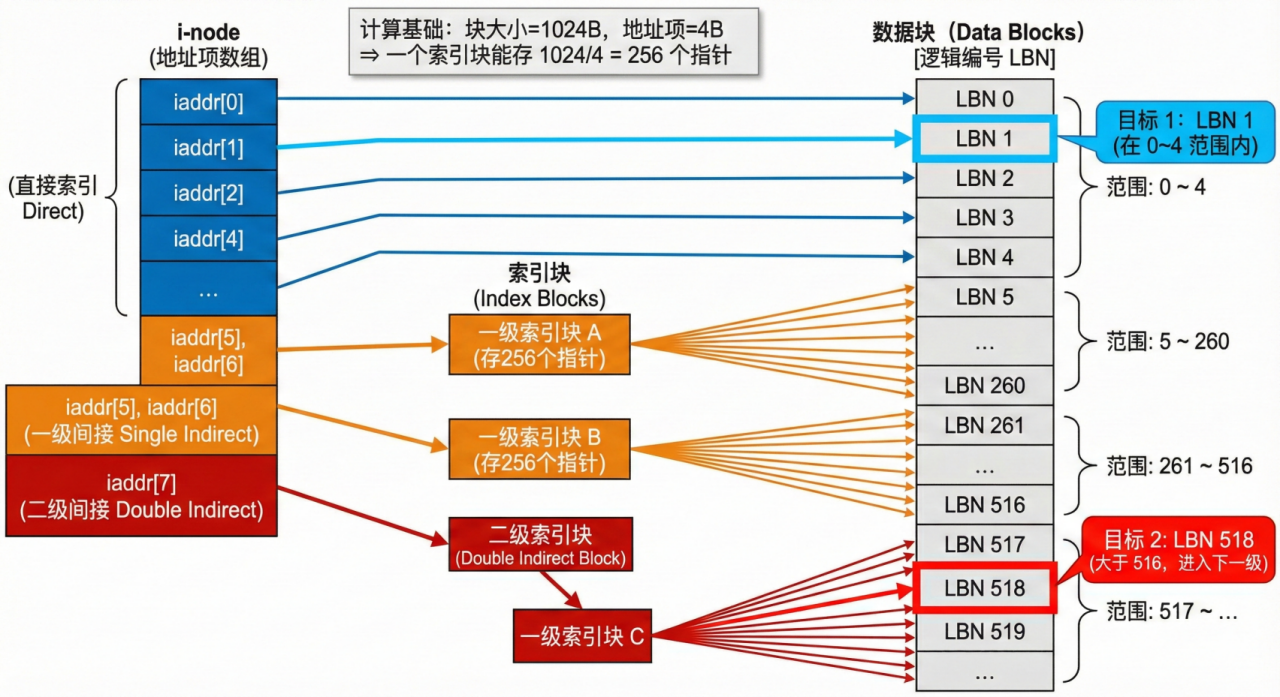
1. 计算核心参数(“一把钥匙开多少锁”)
这是所有计算的基础。
-
磁盘块大小:1KB = 1024 字节。
-
地址项大小:4 字节。
-
一个索引块能存多少地址:1024÷4=256 个。
-
理解: 当我们要用“间接索引”时,系统会拿出一个空的磁盘块专门存地址。这个块能存 256 个指向数据块的指针。
-
2. 划分各个地址项的“势力范围”
数据块是从 0 开始编号的。我们来看看这 8 个地址项(iaddr[0]~iaddr[7])分别管到哪里:
1. 直接地址索引(iaddr[0] ~ iaddr[4])
-
数量:共 5 个地址项。
-
负责范围:逻辑块号 0 ~ 4(共 5 个块)。
-
结论:如果要找 逻辑块号 1,它就在这个范围内。所以第 1 个空填:直接地址索引。
2. 一级间接地址索引(iaddr[5]、iaddr[6])
-
原理:这两项不直接存数据,而是指向两个“索引块”。
-
iaddr[5] 能管多少? 256 个块。
-
接在直接索引后面,范围是:5∼(5+256−1)=5∼260
-
-
iaddr[6] 能管多少? 又是一个 256 个块。
-
接在 iaddr[5] 后面,范围是:261∼(261+256−1)=261∼516
-
-
累计范围:目前 0~6 号地址项总共管到了 516 号逻辑块。
3. 更高级别的索引(iaddr[7])
-
现状:我们要找的是 逻辑块号 518。
-
比对:518 已经超过了前面一级间接索引管辖的最大范围(516)。
-
结论:518 必须存放在下一级地址项,即 iaddr[7] 中。
3. 做题套路总结
-
算出 块大小 / 地址大小(通常是 256 或 128)。
-
列出直接索引能到多少(比如 0-4)。
-
一级索引就是在直接索引的基础上加 256(或 256 的倍数)。
-
如果题目问的块号大于一级索引的最大值,不用犹豫,直接选二级间接。
12. FCB与“按名存取”机制
- 按名存取(核心目标): 文件系统是操作系统中专门负责管理和存取文件信息的软件机构。它向用户提供的一个最基本、最重要的功能就是“按名存取”,即用户不需要知道文件存放在磁盘的哪个具体物理地址,只需要提供文件名即可进行读写操作。
- 文件控制块(FCB): 为了实现“按名存取”,操作系统必须为每个文件设置一个数据结构,用来记录文件的描述和控制信息(最起码要包含文件名和物理存放地址)。这个数据结构就叫作文件控制块(FCB)。
- 系统目录(文件目录): 文件控制块(FCB)的有序集合就构成了文件目录,或者叫系统目录文件。它是整个文件系统的“索引地图”。
13. 缺页中断
某虚拟存储系统采用最近最少使用(LRU)页面淘汰算法,假定系统为每个作业分配4个页面的主存空间,其中一个页面用来存放程序。现有某作业的程序如下:
设每个页面可存放200个整数变量,变量i、j存放在程序页中。初始时,程序及i、j均已在内存,其余3页为空。若矩阵A按行序存放,那么当程序执行完后共产生 次缺页中断;若矩阵A按列序存放,那么当程序执行完后共产生 次缺页中断。

对于每一行,访问奇数列(
j=1, 3, 5...)时必定发生缺页中断(50次),访问偶数列(j=2, 4, 6...)时命中。 因此,每遍历 1 行会产生 50 次缺页中断。 矩阵共有 100 行:100 行 × 50 次/行 = 5000 次缺页中断。
行列分页缺页中断原理
14. CPU核心寄存器与总线
控制器和运算器中核心寄存器的功能辨析(绝对高频考点) 这是本题考查的最直接知识点,软考中经常通过描述功能让考生选择对应的寄存器。您必须清晰区分以下几个核心寄存器的作用:
- 程序计数器(PC): 专门用于存储下一条要执行指令的地址。在指令周期的取指阶段,为了从内存中读出指令操作码,CPU第一步必须知道去内存的哪个位置取,因此必须将 PC 中的内容(地址)送到地址总线上。每执行一条指令,PC的内容会自动更新以指向下一条指令。
- 指令寄存器(IR: 专门用于存储即将(或正在被翻译)执行的指令本身。当PC把地址送出去,内存把指令代码传回CPU后,这条指令就会被暂存到 IR 中,随后指令译码器(ID)会对 IR 中的操作码进行分析解释。
- 状态条件寄存器(SR/PSW): 用于存储系统运算后的状态标志与控制标志(例如计算结果是否溢出、是否为零、有无进位等)。
- 通用寄存器(GR / AC等): 通常属于运算器的一部分,主要为算术逻辑单元(ALU)提供一个工作区,用来暂存参与运算的数据或中间结果。
2. 计算机指令执行的微观过程(取指周期原理) 理解这道题背后的动态过程有助于不靠死记硬背来解题。计算机执行一条指令通常经历:取指 → 分析(译码) → 执行等阶段。 在**“取指”阶段,数据流向是:上传给内存 → 内存按地址找到相应的指令操作码 → 指令通过数据总线传回CPU → 存入指令寄存器(IR)**中等待翻译。
3. 三大总线的功能区别 题干中提到了“地址总线”,理解总线的分类也是相关考点:
- 地址总线: 用于传送地址信息,指定内存或外设的物理存储位置。既然是地址总线,上面流转的一定是地址,这进一步印证了为什么填提供地址的 PC,而不是填提供数据的寄存器。
- 数据总线: 用于在CPU与内存之间双向传送需要处理的数据或指令代码本身。
- 控制总线: 用于传送各种控制信号。
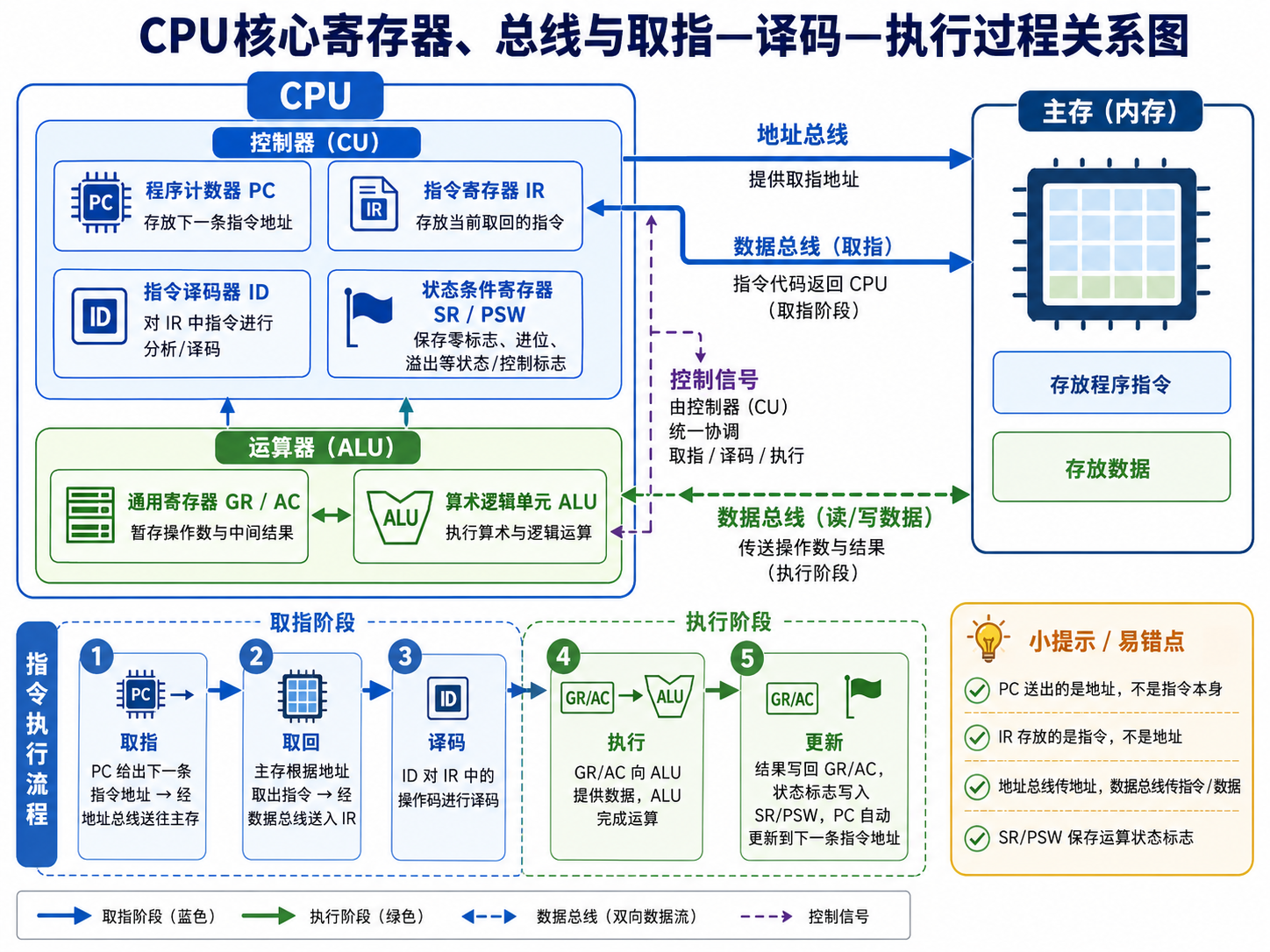
💡 备考秒杀技巧总结: 在软考上午的综合知识题中:
- 看到题干有 “下一条指令” 或 “提供(指令)地址” 的字眼,盲选 程序计数器(PC)。
- 看到题干有 “存放刚取出的指令” 或 “用于指令译码” 的字眼,盲选 指令寄存器(IR)。
- 看到题干有 “暂存数据” 或 “ALU工作区” 的字眼,选 通用寄存器或累加器(AC)。
15. 主存容量计算与存储芯片扩展
内存按字节编址,利用8KX4b的存储器芯片构成84000H到8FFFFH的内存,共需 片。
第一步:计算目标内存的总地址数与总容量
-
求出地址总数: 用末地址减去首地址,再加 1(千万别忘了加1,就像从第1页看到第10页,总共是10页而不是9页)。
-
8FFFFH - 84000H + 1 = BFFFH + 1 = C000H
-
-
将十六进制转换为十进制(以 K 为单位): 十六进制的
C代表 12。-
C000H = 12 * 16^3 = 12 * 4096 = 49152个地址。 -
换算成 K(1K = 1024):
49152 / 1024 = 48K个地址。
-
-
确定目标总容量: 题目明确说明是“按字节编址”,这就意味着每一个地址里面存储的是一个字节(1 Byte = 8 bits)。
-
所以,目标总容量为:48K × 8位。
-
第二步:明确单片芯片的容量
题目给出的存储器芯片规格是:8K × 4位。
第三步:计算所需芯片总数
最直接的计算公式:所需芯片数 = 目标总容量 / 单片芯片容量
-
所需芯片数 = (48K × 8位) / (8K × 4位) = (48K / 8K) × (8 / 4) = 6 × 2 = 12片。
💎 进阶理解:这 12 片芯片在主板上是怎么拼的?
如果从物理连接的“位扩展”和“字扩展”角度来看,逻辑会更加具象:
位扩展(拼宽度): 目标内存要求每个地址有 8 位(一个字节),但单块芯片只有 4 位宽。所以,必须拿 2 片芯片并联成一组,才能凑够 8 位的宽度。
字扩展(拼长度): 目标内存需要 48K 个地址,而刚才并联好的那一组芯片只能提供 8K 的地址长度。所以,需要 6 组这样的组合(48K / 8K = 6)。
总计: 6 组 × 每组 2 片 = 12 片。
16. 处理机系统
- SIMD(单指令流多数据流)—— 认准“阵列”
- 考法:最常考的分类。
- 秒杀关键词:看到 “阵列处理机” 或 “并行处理机”,毫不犹豫选 SIMD。这种结构就是用一个大脑(单一指令部件)控制多个手脚(多个处理单元)同时干一样的活,但处理不同的材料(不同数据)。
- MIMD(多指令流多数据流)—— 认准“多机/集群/MPP”
- 考法:结合现代高性能架构考。
- 秒杀关键词:看到 “多处理机系统”、“集群系统”、或真题中的 “大规模并行处理器(MPP)”,秒选 MIMD。这是能实现任务、指令等各级全面并行的多机系统。
- MISD(多指令流单数据流)—— 认准“极少见/不存在”
- 考法:考它的“罕见性”。
- 秒杀关键词:题干只要出现 “这类系统实际上很少见到” 或 “仅作为理论模型”,秒选 MISD。
- SISD(单指令流单数据流)—— 认准“传统单核”
- 考法:通常作为基础对比项出现。
- 秒杀关键词:看到 “传统的顺序执行的单处理器计算机”,秒选 SISD。
一句话总结这道题的拿分策略: 不纠结指令是怎么译码的,只背:阵列=SIMD,MPP/多处理机=MIMD,很少见=MISD,传统单机=SISD。
17. 分时操作系统
- 分时操作系统是将计算机系统与多个终端设备连接,将CPU的工作时间划分为许多很短的“时间片”,轮流为各个终端的用户提供服务或者执行一个作业。
- 轮换时间(响应时间)与用户数量的关系 教材中给出了一个非常直观的计算例子来解释系统轮换(响应)时间的原理: “例如,一个带20个终端的分时系统,若每个用户每次分配一个50ms的时间片,则每隔1s(即 20 × 50ms = 1000ms = 1s)即可为所有的用户服务一遍。”
通过这个例子可以清晰地得出结论:在时间片长度(如50ms)固定的情况下,系统轮换一圈所需的总时间完全取决于连接的终端(用户)数量。
18. 任务的工作状态
任务一旦被加载到计算机内存后,通常会处于不同的工作状态,这种状态可随着计算机运行而转变。在嵌入式操作系统中,任务的工作状态最简单的可分为三种:执行态、就绪态和阻塞态。
- 执行态:当任务已获得处理机,其程序正在处理执行态机上执行,此时的任务状态称为执行状态。
- 就绪态:当任务已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的任务状态称为就绪状态。
- 阻塞态:正在执行的任务,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)