论边云协同架构在自动驾驶系统中的应用
摘要
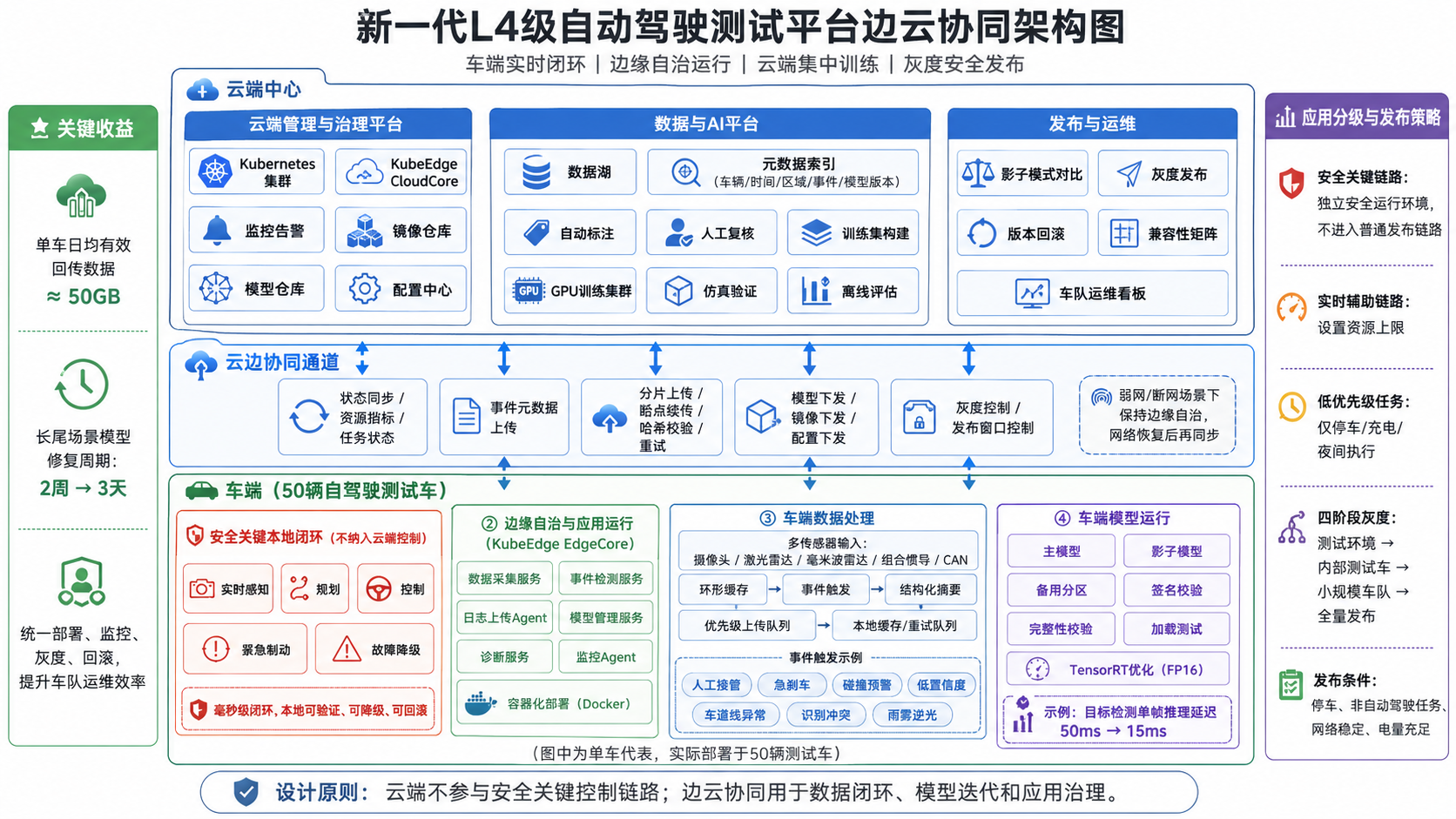
2024年3月,我参与某科技公司“新一代L4级自动驾驶测试平台”研发,担任系统架构师,负责边云协同总体架构、数据闭环、模型发布与车队运维方案设计。该平台面向50辆自动驾驶测试车,接入摄像头、激光雷达、毫米波雷达、组合惯导和CAN总线数据,主要解决数据规模大、长尾场景沉淀慢、车端版本分散和弱网运维困难等问题。考虑到自动驾驶实时感知、规划和控制链路必须在车端闭环,我没有将云端计算引入安全关键控制链路,而是基于 KubeEdge 构建边缘自治和云边协同能力。车端负责实时推理、事件触发、数据缓存和弱网自治,云端负责数据湖存储、自动标注、模型训练、仿真验证和灰度发布。项目上线后,单车日均有效回传数据控制在50GB量级,典型长尾场景模型修复周期由两周缩短至三天。
正文
一、项目背景与问题分析
随着高级别自动驾驶测试规模扩大,架构难点已不只是单车算法能力,而是如何把车端计算、云端训练、数据闭环和车队运维整合为可迭代平台。我参与的“新一代L4级自动驾驶测试平台”主要服务城市开放道路测试,要求支持传感器数据采集、长尾场景挖掘、模型回流和车端应用治理。
项目初期,我发现原有方案有三个问题。第一,数据回传成本高。单车每日产生TB级原始数据,若图像、点云和日志全量上传,移动网络和云存储成本不可接受,进入隧道或地下车库时还会中断。第二,长尾样本沉淀慢。人工接管、急刹车、异形车辆、雨雾逆光等场景价值高,但旧系统依赖人工回收和离线筛选,进入训练集约需两周。第三,车端应用版本分散。数据采集程序、日志上传Agent和模型管理服务缺乏统一部署、灰度发布和快速回滚能力。
基于这些问题,我确定了架构边界:边云协同不参与毫秒级驾驶控制,也不替代车端安全闭环;实时感知、规划、控制和紧急降级仍由车端安全计算平台完成。边云协同的作用是支撑数据闭环、模型迭代和应用治理。因此,我提出“车端实时闭环、边缘自治运行、云端集中训练、灰度安全发布”的总体方案,并从资源、数据、智能和应用管理四个方面实施。
二、边云协同架构设计与实施
1. 资源协同:解决弱网下边缘自治问题
设计思路是用云端统一管理车队资源,用车端保持本地自治能力。云端部署 Kubernetes 集群、GPU训练集群、数据湖、模型仓库和监控平台;车端部署具备GPU/NPU能力的计算单元,运行数据采集、事件检测、模型管理和诊断监控等任务。为适配车辆弱网、断网和资源受限场景,我选用 KubeEdge 作为边缘治理底座,通过 CloudCore 和 EdgeCore 实现云边状态同步。
实施中遇到的问题是,测试车辆进入隧道后,云端控制面短时不可达,若按普通 Kubernetes 节点管理,容易出现节点状态异常和任务管理失控。为此,我在车端配置 EdgeCore 的离线自治能力,使边缘侧保存必要的应用元数据和运行状态。断网时,数据采集、事件缓存和日志记录继续运行;网络恢复后,再将任务状态、资源指标和上传队列同步到 CloudCore。
同时,我对车端任务进行了分级。安全关键链路,如控制、紧急制动和故障降级,不纳入普通容器编排;实时辅助链路,如感知推理、事件检测和数据采集,设置资源上限;低优先级任务,如日志压缩和数据格式转换,只允许在车辆停车、夜间充电或测试结束后执行。这样既利用闲置算力,又避免离线任务干扰实时业务。
2. 数据协同:解决“传什么、怎么传”的问题
数据协同是项目收益最大的部分。我的思路是车端不做全量上传,而是通过事件触发、环形缓存、低频采样和优先级队列,把有限带宽用于高价值数据。
具体实现时,我在车端建立传感器环形缓存,持续保留最近一段时间的图像帧、点云片段、定位数据、车辆状态和算法输出。当发生人工接管、急刹车、碰撞预警、感知置信度低于阈值、车道线异常或目标识别冲突时,系统自动截取事件前后30秒数据,并生成事件元数据,包括时间戳、GPS位置、车速、触发原因、模型版本和传感器状态。对于普通直行和无异常事件数据,只保留结构化摘要,并按低频策略抽取代表性样本,避免样本分布失真。
在传输层,我没有采用简单HTTP整包上传,而是设计了分片上传、断点续传、哈希校验和失败重试机制。上传队列按优先级处理:人工接管和急刹车最高,低置信度识别和误检漏检次之,雨雾逆光、施工道路等环境样本再次,常规采样最后。大文件先上传元数据,再上传原始片段;弱网中断后进入本地重试队列,网络恢复后继续上传。云端接收后进入数据湖,按车辆、时间、区域、事件类型和模型版本建索引,支撑事故回溯和训练集构建。
3. 智能协同:解决模型训练与车端推理闭环问题
智能协同的设计思路是“云端训练,车端推理,发布前验证”。云端使用回传的长尾数据进行清洗、自动标注、人工复核和训练集构建,再通过GPU集群完成模型重训练。训练完成后,新模型必须经过离线指标、仿真回归、影子模式和小规模灰度验证,不能直接推送到全量车辆。
项目中遇到的关键问题是模型更新的安全性。自动驾驶主模型不能像普通互联网服务一样在行驶中随意热切换。我的解决方案是双版本加影子模式。新模型先下载到备用分区,完成签名校验、完整性校验和加载测试后,在车端以影子模式运行,只记录推理结果,不参与控制决策。云端对比主模型和影子模型的误检率、漏检率、推理延迟和资源占用,确认稳定后,再选择车辆停车、充电或测试结束窗口完成切换。如果新版本异常,系统立即回滚到上一稳定版本。
为降低车端推理压力,我在模型发布前加入 TensorRT 优化流程。以目标检测模型为例,通过算子融合和 FP16 推理优化,在验证集精度下降可控的前提下,将单帧推理延迟由约50ms降至约15ms。
4. 应用管理协同:解决车队版本治理问题
应用管理协同的目标是统一测试车队的软件部署、监控和回滚。我将车端应用按安全等级分层管理。数据采集服务、日志上传Agent、事件检测服务、模型管理服务、诊断服务和监控Agent采用 Docker 容器化部署,并通过 KubeEdge 统一编排;规划控制、安全监控和紧急制动仍由车端安全运行环境独立保障,不进入普通发布链路。
在发布流程上,我设计了四阶段灰度机制。第一阶段在云端测试环境验证镜像依赖、配置文件和资源限制;第二阶段推送到少量内部测试车;第三阶段扩展到小规模测试车队;第四阶段才进行全量发布。发布过程中,云端持续观察CPU、内存、GPU、磁盘水位、容器崩溃率、上传成功率、推理耗时和错误日志。若指标异常,立即暂停发布并执行回滚。
此外,我设置了发布窗口控制。只有当车辆停车、非自动驾驶任务、网络稳定且电量充足时,EdgeCore 才允许拉取镜像和更新服务。对于模型版本和数据协议变更,还必须检查兼容性矩阵,防止新旧版本混用造成数据格式错误。
三、实施效果与总结
平台上线后,支撑50辆测试车开展城市开放道路测试,累计里程超过10万公里。通过边云协同,项目取得三方面效果。
第一,数据成本明显下降。通过事件触发、环形缓存、摘要化和优先级上传,单车日均有效回传数据控制在50GB量级,带宽和云存储压力显著降低。第二,模型迭代效率提升。高价值事件数据可以更快进入样本池,典型长尾场景的模型修复周期由两周缩短至三天左右。第三,车队运维能力增强。边缘应用实现统一部署、灰度发布、状态监控和快速回滚,减少了人工排查和手工升级。
本项目表明,边云协同在自动驾驶系统中的合理定位,不是替代本地实时控制,而是建设数据闭环、模型迭代和边缘治理基础设施。未来,我计划进一步引入 MEC 节点,将部分区域交通感知、路侧事件广播和多车协同分析下沉到近场边缘侧。但无论架构如何演进,自动驾驶安全关键链路都必须坚持本地闭环、可验证、可降级和可回滚原则。
架构师论文写作要点(机考特供版)
1. 篇幅与排版:利用键盘优势
-
字数上浮:机考打字速度远快于手写,建议将正文目标定在 2500~2800字(摘要300-330字)。更充实的内容意味着展示了更多的技术细节,是拿高分的关键。
-
视觉分段:屏幕阅读容易疲劳,严禁长篇大论不分段。每个小标题下建议拆分为 2-3 个自然段。利用 (1) ... (2) ... 或 第一,... 第二,... 等序号强行分割视觉块,让阅卷老师一眼看到逻辑结构。
-
标点规范:注意中英文标点的切换,英文单词前后建议留一个空格(如:使用 KubeEdge 框架),这样排版更美观、专业。
2. 术语准确性:警惕“提手忘音”
-
大小写规范:机考中,英文术语必须严格遵守官方写法。例如 KubeEdge(注意K和E大写)、TensorRT、Docker、MQTT。不要出现全小写(如 kubeedge)或全角字符,这显得非常不专业。
-
输入法陷阱:机考输入法(通常是微软拼音)没有手机智能。务必检查同音错别字!
-
❌ 错误示例:阀值、步署、回朔、按装。
-
✅ 正确写法:阈值、部署、回溯、安装。
-
-
高分词汇:文中提到的 CloudCore、EdgeCore、QUIC、离线自治、影子模式 等词汇,是体现你技术深度的关键,输入时要确保零失误。
3. 逻辑结构:“问题-解决”闭环
-
核心写法:坚持采用 “设计思路 -> 遇到具体问题 -> 架构决策与解决” 的写法。
-
示例:不要只写“我们用了EdgeCore”。要写“原生kubelet内存占用高且断网会驱逐Pod(问题),因此我们引入了轻量级的EdgeCore,并配置了离线自治功能(解决)”。
-
-
非线性写作:利用机考优势,先敲出一、二、三级标题的骨架,防止跑题。然后再往里面“填肉”。这样能确保你的“问题-解决”逻辑链条在整篇文章中是严密扣合的。
4. 真实感:细节决定成败
-
拒绝空谈:文中提到的“夜间充电时调度”、“进入隧道断网”、“加速度阈值触发截取数据”等业务场景细节,是证明项目真实性的铁证。
-
数据支撑:在机考中,你可以更从容地补充量化数据。例如:“带宽节省了90%”、“延迟从50ms降至15ms”、“模型更新周期缩短至3天”。这些具体的数字比“效果很好”更有说服力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 32
32 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)