深入了解强化学习
如果说LSTM是精于“预测”的学者,那么强化学习(Reinforcement Learning) 就是一位在市场中磨砺的“操盘手”。它不再满足于“预测价格涨跌”,而是专注于“在动态变化的环境中,如何做出一连串最优决策”,以最终实现收益最大化。
🧠 核心原理:像交易员一样“试错学习”
强化学习(RL)的核心是一个“智能体(Agent)”通过与环境(Environment)不断互动,从“试错”中学习最优策略的过程。其核心思想是通过“奖励(Reward)”来塑造“智能体”的行为。
核心概念
-
智能体(Agent):决策者,即你的AI交易系统。它接收市场信息,做出交易决策,并观察结果。
-
环境(Environment):智能体外的一切。在量化交易中,这就是整个金融市场。
-
状态(State):环境在某个时刻的概况,即用于决策的市场数据。
-
行动(Action):智能体在某个状态下可以执行的操作,即交易决策(如买入、卖出、持有或调整仓位)。
-
奖励(Reward):智能体采取行动后环境给出的反馈,用于判断行动的好坏。奖励函数是策略优化的核心,例如可以是该步行动带来的即时收益或风险调整后的夏普比率。
其工作流程如下图所示:
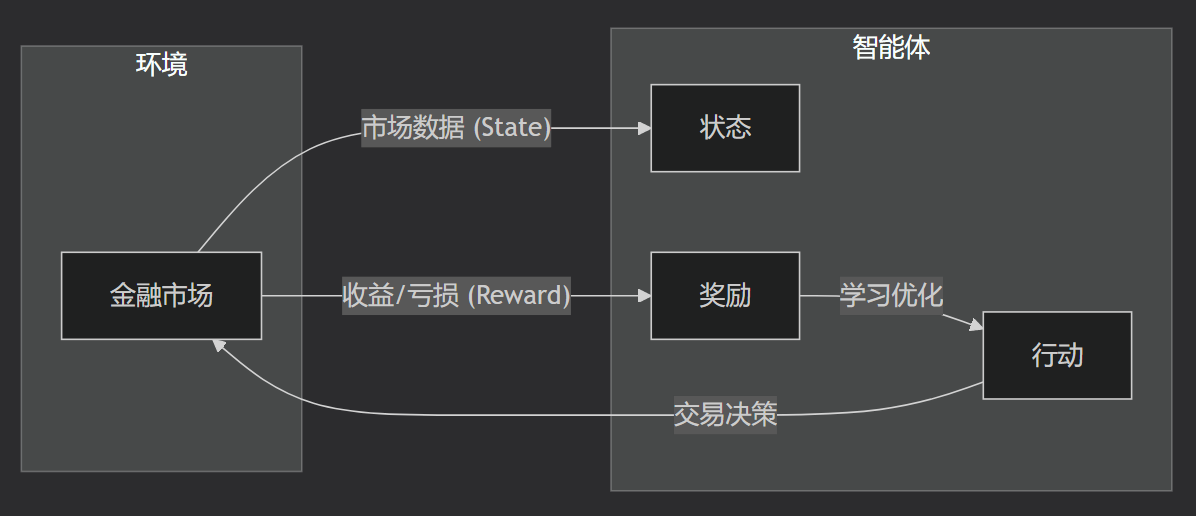
RL通过学习,目标是找到最优的策略(Policy),即在每个状态下应该采取什么行动的规则。在RL的术语中,这个优化问题常被描述为一个马尔可夫决策过程(Markov Decision Process, MDP)。MDP为智能体提供了一个数学框架:当前状态(S)下采取行动(A)获得奖励(R),并到达下一个状态(S')。智能体通过不断循环这个流程,来学习使累积期望奖励最大化的最优策略。
🕹️ 核心算法:从DQN到PPO的演进
RL在金融等复杂领域落地,必须处理高维度的连续状态和行动空间。深度强化学习(DRL) 的出现,正是为了解决这一难题,它利用深度神经网络来近似状态或策略。
以下是一些主流的DRL算法对比:
| 算法类型 | 代表算法 | 核心思想 | 量化交易中的适用场景 |
|---|---|---|---|
| 基于值函数 | DQN | 学习状态-动作的价值(Q值),选择价值最高的动作。优点是离散空间效果好,但处理连续动作(如仓位调整)能力弱。 | 离散决策场景,如信号的“买卖/持有”分类。 |
| 基于策略梯度 | PPO | 直接学习策略函数,将状态映射为动作的概率分布。优点是擅长处理连续动作(如调整仓位权重),稳定性好。 | 优化连续变量决策,如投资组合中资产的权重分配。 |
| 演员-评论家 | A2C/A3C | 结合了值函数(评论家)和策略函数(演员)的优点,既能评估当前策略的价值,又能直接优化策略。 | 适合复杂的任务,如结合仓位管理和风险控制。 |
| 确定性策略 | DDPG | 直接从状态映射到确定性的动作,适合行动空间是连续且维数较高的问题。 | 投资组合管理中学习不同资产间的资金配置比例。 |
🏦 量化交易中的典型应用
RL为传统量化交易带来了全新的解决方案,尤其在以下三个核心场景中展现出巨大潜力:
-
投资组合管理:这是RL在金融领域的核心应用。RL通过动态再平衡来实现风险调整后的收益最大化。例如,DDPG算法已被用于构建自适应投资组合管理系统。
-
算法交易与订单执行:RL能学习最优交易策略,在减少对市场冲击和控制成本的同时完成大额订单。例如,PPO智能体可用于执行比特币的清算策略,模拟市场影响,以寻找最优的执行时机。
-
做市与风险管理:RL是做市商的理想工具。它可以学习实时调整买卖报价,从买卖价差中获利。RL智能体还擅长管理投资组合风险,通过学习动态调整风险敞口,来应对市场剧变。
📈 实战案例:RL在金融市场中的真实表现
以下是一些近期公开的、经过回测验证的RL在金融市场中的应用案例:
-
股票交易 (AAPL):Hi-DARTS框架通过多智能体协同,在2024年1月至2025年5月期间对苹果(AAPL)股票进行回测,实现了25.17% 的累计回报,夏普比率为0.75,均超过了买入持有(12.19%)和标普500 ETF(20.01%)的同期表现。
-
加密货币 (ETH/USDT):SAC(Soft Actor-Critic)算法在以太坊(ETH)交易中实现了惊人的152% 超额收益,夏普比率高达2.81。
-
多资产策略:PPO-DQN分层框架在投资组合管理中表现优异。将RL与模糊逻辑结合的策略系统,也已在多个期货市场验证了其强大的市场择时能力和鲁棒性。
⚖️ 优势与挑战
RL虽然强大,但在金融领域的应用也伴随着独特的挑战。
核心优势
-
适应性强:可自动适应市场风格转换,无需人为设定规则。
-
处理复杂性:擅长处理连续状态和行动空间、交易成本等复杂约束。
-
目标导向:直接优化最终目标,如最大化夏普比率或最终收益。
主要挑战
-
奖励函数设计:简单使用价格涨跌作为奖励可能导致过度投机。一个更平衡的奖励函数应将夏普比率或最大回撤等风险指标纳入其中。
-
过拟合与稳健性:RL模型极易在历史数据上过拟合,导致在实际市场中失效。采用稳健的验证方法是关键。
-
可解释性:DRL模型是著名的“黑箱”,其决策过程难以理解,这在金融监管和风险控制中是重大障碍。
🔮 未来趋势:RL + 多智能体 + 大模型
RL未来的演进,将聚焦于与多智能体系统(Multi-Agent Systems, MAS) 和大型语言模型(LLMs) 等前沿AI技术进行深度融合:
-
多智能体系统(MAS):通过多个AI智能体分工协作(如不同智能体分别负责识别趋势、控制风险和优化仓位),来构建更强大、稳健的交易系统。
-
大型语言模型(LLMs)赋能:LLMs能处理新闻、财报等非结构化数据,生成交易信号供RL智能体使用,从而做出更全面的决策。
-
分层强化学习(HRL):通过高层智能体制定宏观策略(如“进入进攻模式”),低层智能体执行微观交易(如“每次买入多少”),以提高策略在复杂市场中的适应性和计算效率。
💎 总结
总的来说,强化学习为量化交易提供了一种全新的范式。与LSTM专注于“预测”不同,RL更像一位实战派的交易员,其优势在于决策而非预测。
作为个人开发者,在实践RL时可以参考以下路径:
-
打牢基础:学习Sutton和Barto的经典教材《Reinforcement Learning: An Introduction》,并尝试用Python实现一个基础环境。
-
选择框架:使用
Stable-Baselines3、RLlib、FinRL-X等成熟库,避免重复造轮子。 -
模拟实战:从简单的环境(如单只股票的仓位管理)入手,逐步过渡到投资组合管理。
-
拥抱前沿:关注RL与大模型、多智能体系统的结合,这很可能是未来的重要演进方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)