大模型Agent面试50问(26-50)
26. 请推导 LLM Agent 在强化学习训练中的 Reward Hacking 现象成因,即模型如何利用 Reward Function 的漏洞获取高分但未能完成真实任务?
1、知识点:reward hacking的原因是LLM学会了能讨巧的trajectory;
设有N步trajectory τ={S1,A1,S2,A2,……, Sk,Ak,……, SN,AN },τ~πθ,而πθ是策略分布函数,θ是参数;则Ak对应的价值函数Q 满足
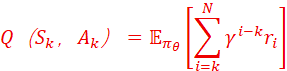
强化学习的目标函数J满足:
![]()
因此,一旦Q达到最大而输出的trajectory现实无法达到或有重大缺陷,就形成了reward hacking。reward hacking来主要两个漏洞:第一是RM的奖励规则有缺陷,比如某些ri的权重分布不合理,导致Q的计算跳过了一些现实中很必要、但RM里ri不高的步骤,虽然得到了高分奖励,但现实上所对应的trajectory是走不通的。一个典型案例是Json输出,模型有时会为了得到高分而忘记了括号的完备,导致根本无法被使用;第二是LLM输出PPO上有缺陷,由于clip函数的剪裁系数ε过大、或者KL散度β参数过小,导致一些高优势函数、但其实震荡越界的trajectory被作为最佳输出。一些典型的幻觉输出,原因如此。
27. 在分布式 Agent 系统中,如何设计一种去中心化的共识机制 (Consensus Mechanism) 来协调多个 Worker Agent 的任务分配,避免单点故障?
1、知识点:去中心化,就是避免让某一个agent来控制所有的agent;当某一个agent无法完成工作时,有备份agent可以顶替;
2、分布式agent:1)采用p2p模式,各agent建立平等的通信机制;2)拜占庭投票机制,总agent满足N≥3f+1,f为恶意或故障agent数;基于multi-agent-debate,摒弃掉moderator,而是一个任务由每个agent共同发起任务队列τ1的设计,再通过投票机制确定最终的、待执行的任务队列τ1;3)如果在执行τ1时,分工到某个agent出现死循环或者runtime error(这通过max_retry或者runtime超时监控来实现),则需要agent重新发起队列设计,重新投票出τ2,在投票时出现问题的agent的投票权重被降低。
28. 请分析 QLoRA 在微调大型 Agent 模型时的显存占用细节,特别是 4-bit 量化对工具调用参数预测精度的具体影响及补偿策略。
1、知识点:QLoRA是LoRA的“折衷版”,采用预训练权重被量化(离散)为4 bit+LoRA低秩微调+分页优化器,达到牺牲速度但大幅度降低显存的目的。实现单卡跑通7B以上的大模型;
2、显存占用细节,如果是LoRA,是Fp16和BF16位的,而QLoRA是NF4位的,即4-bit,所以占比是LoRA的四分之一,大约需要4-6G的HBM,就可以跑通7B以上的大模型;内容上涉及了位置embedding,KV cache,weight&bias,以及训练激活函数的显存;
3、由于LoRA是连续的,而QLoRA是离散的,所以后者的精度会略有降低,但幅度很小。
29. 针对实时语音交互 Agent,如何实现流式 ASR、LLM 推理与 TTS 的端到端流水线优化,以将首字延迟 (TTFT) 控制在 500ms 以内?
1、知识点:实时语音交互agent,比如同声传译,重点考验LLM的推理加速能力。ASR:automatic speech recognition;TTS:text-to-speech;TTFT:time-to-first-token;
2、ASR,使用CTC streaming,采用incremental recognition,不要整句识别,而是一个字一个字地识别声音、流式地拼接成文本序列,延时阈值不超过100ms;
3、在LLM推理阶段,在收到文本序列的第一个字的时候就开始做推理,创建context的KV cache,随着文字的增加也动态拼接KV cache,只增加不删除;延时阈值不超过300ms;
4、在TTS阶段,对于LLM输出的τ的第一个action,就创建声音,直到最后的action结束;延时阈值不超过100ms。
5、这样的流水线优化,保证总的响应时间不超过500ms。
30. 请解释 Self-Rewarding Language Models 在 Agent 迭代中的作用,如何构建一个无需人工标注的自动反馈循环?
1、知识点:self-rewarding model,主要是自己能够动态生成和调整RM,自主对策略进行优化;
2、RM阶段,建议分为reasoning和browsing两个层面。通过负样本方式,对于正样本按照故意输入错字、错误理解意思、语法错误、逻辑错误、冗余步骤、跳步推理、不符合显示等等,生成带有机器自动标记的negative sample集。对于模型生成的trajectory,在同一个context engineering里:第一、在reasoning层面,如果输出的trajectory与负样本的分布近似,则给与惩罚;如果输出的trajectory与正样本的分布近似,则给与奖励;第二,在browsing层面,对于外部搜索到的序列向量,遍历模型自主生成向量知识库,序列向量与向量知识库向量内积高于阈值的向量,在RM上给与奖励;反之,给与惩罚;
3、在GRPO的时候,对KL散度差异的β参数的调整:如果reasoning出错,则对β放大,抑制trajectory的输出;在browsing正确,则β给与缩小,鼓励trajectory的输出;目标函数简写如下:
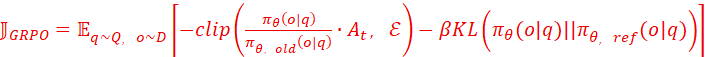
31. 在金融交易 Agent 中,如何处理市场数据的高频更新与 LLM 推理延迟之间的矛盾?请设计一种基于事件驱动 (Event-Driven) 的缓存更新策略。
1、这个问题可是命中我的老本行了。用报表业界的通俗话说,就是不要等数据变化后才临时去计算全量报表;
2、策略建议:
1)确定金融分析的维度,比如基本面、供需面、成本面、政策面;划分金融交易的事件类型,分别贴上高频、低频;大计算量和小计算量的标签;
2)预先建立各个维度vs事件的勾稽关系,形成结构化的报表或者物化视图;
3)这些报表或者物化视图都可以封装成一个个的function,并且把functions的上一个版本的临时计算结果放置在缓存里,打快照;
4)建立事件的监听机制,把毫秒级高频事件按照队列存储下来,有限流和熔断机制;然后等待秒级LLM推理的执行;
5)当t时刻监听到金融交易数据、即事件发生变化后,首先区分是高频还是低频,分别走不同的线程;如果是低频大计算量,走并发计算。驱动LLM去调用正确的function,把t-1时刻旧版本的缓存快照更新为t时刻的新版本并打快照。注意不需要计算的参数都设定为缓存优先,只有需要重新计算的参数才更新缓存;如果是高频事件,严防每次高频变动都拉起LLM推理,而是有幂等机制;
6)利用t时刻更新的缓存,让agent去做后续的动作;
7)对于三高计算通常需要考虑的限流、异步、队列等,具体情况具体设计。
32. 请推导 Hierarchical Reinforcement Learning (HRL) 在 Agent 任务规划中的应用,High-level Policy 与 Low-level Policy 之间的信息交互接口如何定义?
1、老本行:high-level policy是战略;low-level policy是战术;
2、HLP用文本prompt表示为:策略名称;策略描述;策略的KPIs,比如有N个;LLP就是针对N个KPI,分别进行更具体的策略;
3、交互接口就是HLP对第i个LLP进行KPI考核,设定累计考核阈值和单步考核阈值。如果超过阈值,LLP继续沿着trajectory输出,给与内部奖励;如果低于阈值,则拉起回溯,压低上一步的奖励,迫使LLP选择新的action。
33. 针对代码执行沙箱 (Sandbox),如何设计资源限制 (CPU/Memory Quota) 以防止恶意或死循环代码导致 Agent 服务崩溃?
1、沙箱是动态分配资源的容器,有自己的线程、虚拟机和bash隔离,所以必须是有独立的进程;
2、沙箱绑定一个单独的CPU内核,只能支持单线程spawn,不支持fork;严格建立超时报错机制,防止发生一个沙箱里恶意或者死循环代码。如果出现则强制释放沙箱,让oskill掉该进程;
3、每个沙箱分配固定的内存,超过内存使用也会kill掉该沙箱进程;温柔一点的办法,可以考虑建立大对象监控,单次读取大于X条数据的sql请求被禁止;对于老年代启动垃圾回收GC,监控max-heap和res,设定报警阈值,避免超限;
34. 请分析 Agent 在处理多轮对话时的状态追踪 (State Tracking) 难点,如何利用 Slot Filling 技术结合 LLM 生成能力来提高准确率?
1、知识点:slot filling,就是给每轮对话,补充一段结构化的备注,这个备注会填写进这个agent专门预先设定好的槽位里,保存了多轮对话中的省略语句、代词和不同轮次对话之间的关系。很像是表单的必填和选填项;
2、状态追踪state tracking,就是要对每一轮的会话的结果做一些简要的注释,然后对“表单”的相应槽位slot进行增、删和改,直到多轮对话结束。但是,anaphora resolution(指代消解)、即正确理解每一轮对话里的省略语、代词和前面所有轮次里是什么逻辑或者因果关系,这是非常难的事情,所以,state tracking的难点,至少有把提取的状态卡入正确的槽位、长对话之后槽位位置丢失、删和改槽位里的信息,等等;
3、由于有了结构化slot的数据整合和定位,会在多轮对话中对于关键的state和参数建立如同表单一样的持久化能力,从而提升LLM生成的准确率。缺点是,由于是存储在prompt,不如结构化表单那样立体,只能压缩成json串。前景:企业级应用上,考虑slot filling的具体实现方式,和RAG相结合,增强多轮对话的上下文推理能力。
35. 在跨域任务中 (如从查天气切换到订机票),如何设计通用的 Context Switching 机制以快速重置无关的历史记忆而不丢失用户偏好?
1、知识点:context switching机制,对于我们这些从事数仓多年的人来说,建议关注元数据(比如topic,用户偏好)统一管理、表单填写持久化和查询结构化;个人认为context switching机制快速重置无关的历史记忆、而不丢失用户偏好,是既要又要的一种需求——对于LLM来说,归根结底还是要对多轮对话进行持久化存储,并且对每一轮次的用户偏好进行结构化提取、常驻KV cache;
2、在context engineering里,跨域任务,应该是一个context里发生了聊天topic突变、从而需要switch到不同的agent、或某个agent switch了不同的tools。所以,建立一个agent聊天topic持久化的存储机制,存在硬盘而不是内存里。第一个agent的context可以考虑abstract或者summary,进行压缩,将原内容存储到文件里并注明路径。企业级需求考虑建立一个链表,把前一个agent的相关文件path,存在下一个agent的相关文件的头,这样首尾相连,便于context switching;消费级需求绝对不能用链表,考虑直接按照文本文件依次压缩历史对话存储,context里只存压缩过的内容,存在kv cache里。
3、这样,需要快速重置无关历史记忆之前,企业级就延伸链表、消费级就做compaction,把无关历史记忆持久化到文件里,把用户偏好存在kv cache里。
36. 请推导 Speculative Decoding (推测解码) 在 Agent 生成动作序列时的加速原理,Draft Model 与 Target Model 的验证接受率如何计算?
1、知识点:speculative decoding,并非进行一个St确定At,而是根据St,、确定At,同时,由draft model批量生成候选A‘t+1,A‘t+2……,,再由target model按照验证接受率,选择候选A‘t+1,A‘t+2,……,或者丢弃,从而在agent生成动作序列时加速;
2、与target model At+1验证接受率,按下列公式(教科书):
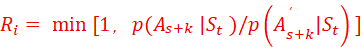
分子是target model的动作条件生成概率,分母是draft model的动作条件生成概率。从而保证不好的draft model所生成的trajectory不会被长推理过程采纳。
37. 针对法律合规 Agent,如何将法规条文转化为可执行的约束条件 (Constraints),并在解码阶段通过 Logit Masking 强制模型遵守?
1、借用开源的LLM,建立一个文本知识库文件目录,存放法规条文不合规的示例文本、以及法规合规的条文,做embedding;直接写一个如何调用知识库文件目录,对于输出的内容进行合规检索的skill,再在所有的agent里,修改各个agent.MD。这是偏工程配置而非原理性的简答。
2、逻辑严谨的是:模型按照prompt,开始输出token的序列;事先将文本格式的法规条文,转化为结构化的表单格式,比如注明某法规条文的适用范围、关键字、触发法律约束的边界、典型场景等等;对这些结构化的格式,形成约束条件的embedding集合;在解码阶段,动态计算每一个token与约束条件的关系;对于满足约束条件的token,强制修改这个token的权重为负无穷,导致这个token不会被输出。设有约束条件embedding集合C={c1,c2,…},第t步待输出token为et,则对约束条件
![]()
38. 请分析 Vision-Language-Action (VLA) 模型中,动作头 (Action Head) 的设计对机器人控制精度的影响,离散化 Action Space 与连续 Action Space 的优劣对比。
1、VLA是首先收到sensor的视觉连续片段,embedding为Zv;Zv通过cross attention和命令语言ZL做对齐Zf,Zf经过了FFN、生成了logit,logit与action head对接,直接输出动作序列的概率分布,进而生成动作序列trajectory;以此类推;动作头的设计可以从离散动作和连续动作两个层面,影响机器人控制精度。离散动作,原子化的动作表征比如上、下、左、右、抓取、移动等粗颗粒度的动作;连续化动作,使用6D姿态(x,y,z,roll滚动, pitch俯仰, yaw偏航)来做连续表征的;
2、离散化action space,不能通过函数梯度更新进行高精度的微调,只能靠概率分布的方式,量化到原子化的档位,有如手挡汽车,切换起来是跳跃式的,所以,精度低;但优点是,推理上速度较快;连续action space,正好相反。并且,在训练时,容易出现震荡发散、不收敛等问题。
39. 在 Agent 评估基准 (如 AgentBench) 中,如何设计自动化评测脚本以量化 Agent 在长程任务中的规划能力和抗干扰能力?
1、量化规划能力:设N步(trajectory)τ={S1,A1,S2,A2,……, Sk,Ak,……, SN,AN },τ~πθ,而πθ是策略分布函数,θ是参数;N很长。则Ak对应的价值函数Q 满足
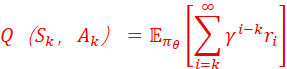
如果是考察长程任务的规划能力,则可以考虑两点:首先是从持久性上,即从A1到Ak,都是按照事先规划好的trajectory执行,而没有中断或者重复规划,把总的action累计输出次数看做分母,而把发生pruning、reflection、backtracking等等修改和否定Ak的action的次数看做分子,用分子除以分母形成一个index:
P(planning)=count(pruning、backtracking、reflection,etc)/count(总的action)
这个指标越小,说明长程规划能力越高;
其次,看效率。把总的token输出次数作为分子,再把累计prompt数作为分母,分子除以分母形成另一个指标,指标越小,说明持久化的程度越高;
2、扛干扰能力anti-interference:考虑每个ri的数值大小的方差
![]() ,
,
这个index越大,说明扛干扰能力越强。
40. 请推导基于 World Model 的 Agent 如何在内部模拟环境演变,从而减少真实环境交互次数 (Sample Efficiency)?
1、知识点:world model差异较大,一般会有一个guardrail,就是把VLA大模型里预计会违反物理世界尝识的错误输出,排除掉;
World model在Si的状态下,根据策略rollout输出N个输出预测序列,τ∈{τ1,τ2,...,τN},i从1到N,其中,每一个τi都是由状态、动作滚动组合而成的trajectory;这些预测序列构成了Si状态下的内部模拟环境。对这些状态,按照RM所设定的奖惩,进行PPO优势策略的计算;注意,这个计算是离线的,全部在HBM里跑
2、经过PPO优势计算之后的序列τi,作为Si状态后的候选action序列,在线状态下与真实世界发生交互;这样就减少了真实环境的交互次数。
41. 针对多语言 Agent,如何处理低资源语言在工具文档和理解指令时的性能下降问题?请提出一种基于翻译增强 (Translation Augmentation) 的解决方案。
1、知识点:低资源语言可能是罕见语种、缺少训练集的方言。所以在工具文档和理解指令时,就不如已经很成熟的英语性能强。用低资源语言直接去做tool use训练,会给生成json、拉起工具造成河大的麻烦;同样低,在理解指令上,低资源语言直接reasoning也会变难。
2、建议一种翻译增强的解决方案:低资源语言依次序列进入encoder,用decoder生成英文单词序列;英文单词组合成一个问题prompt,用LLM输出一个回答序列;回答序列作为encoder,再用decoder输出成低资源语言序列。引入置信区间,如果遇到低资源向高资源、以及高资源向低资源输出问题,一旦触及置信度低于阈值,就判定输出时失败的。此时就拉起backtracking机制,重新输出一次。输出前,会对上一次的输出失败贴上失败的标签,比如翻译错误、逻辑矛盾、没有对应的单词等等,从而通过增加约束条件的方式,点明问题症结,让再次输出的质量逐级提高,直到置信度超过阈值。
42. 请分析 Agent 在使用搜索引擎时,如何判断搜索结果的相关性并决定何时停止检索 (Early Stopping)?请给出一个基于信息增益的停止准则。
1、设最大检索网站数为M,一个agent的prompt,记作q,检索了N≤M个网站;每个网站依次产生的信息增益为C={c1,c2,…,CN},第k-1步的信息增益Ck-1,是与前k-2步信息增益C1、C2、...Ck-2相似度低、但与prompt相似度高的第k-1步检索到的增量文本集;设第k步检索到的去重文本集为ek, 则ek与第k-1步的信息增益Ck-1,进行余弦近似归一,即
![]() ,
,
2、S值低于0.8的句子,说明信息增益达,将被保留;大于等于0.8的句子,将被视为意义不大的信息,丢掉。如果连续3次没有新的句子的追加,则启动early stopping;如果达到M,也立即启动early stopping。
43. 在代码修复 Agent 中,如何利用 AST (Abstract Syntax Tree) 解析结果来指导 LLM 生成语法正确的补丁,而非纯文本匹配?
1、通过ast看看代码有无语法问题如“表达式语法错误,括号未封闭”等待修复点;
2、在ast确定的待修复点、即强约束条件constraint明确后,再引导LLM生成更精细的代码补丁文本,修复的过程中因为AST也把没有问题的全量代码审核、并保存在上下文了,这就保证了代码修复是在原版本上微创、而不是重复造轮子;
3、这些文本会进行代码合并后再一次被AST再审核,如果还有问题,返回第一步重新走循环;
4、还可根据AST审核通过这个判据,建立RM的奖励机制,再进行PPO训练,让以后的trajectory更优秀。
5、但AST代码修复解决不了死循环,空指针,除数为0等逻辑错误,需要通过sandbox测试;
44. 请推导 Multi-Modal CoT 中,视觉推理链与文本推理链的对齐损失函数,确保模型在跳跃推理时不丢失视觉证据。
1、知识点:modal,模态;model,模型;
2、视觉推理链的对齐loss function,简单的定义,可以是
![]() ,
,
其中![]() 是第i个推理链里,第j个视觉token的输出概率;
是第i个推理链里,第j个视觉token的输出概率;![]() 是第i个推理链里,第j个对齐的文本token的输出概率; Loss越大,说明两个推理链的输出概率不一致的情况越大。所以,为了让跳跃推理是不丢失视觉证据,就要保证LOSS function越小越好。如果复杂的定义,也可以考虑KL散度。
是第i个推理链里,第j个对齐的文本token的输出概率; Loss越大,说明两个推理链的输出概率不一致的情况越大。所以,为了让跳跃推理是不丢失视觉证据,就要保证LOSS function越小越好。如果复杂的定义,也可以考虑KL散度。
45. 针对企业级 Agent,如何设计基于 RBAC (Role-Based Access Control) 的工具权限管理系统,防止 Agent 越权访问敏感数据?
1、企业级ERP有权限、编号ID和角色管理的基本AC能力,建议对于一个agent,首先给它一个编号ID比如001,和真人一样待遇;
2、该编号ID可以创建一个新角色,比如叫agent for GM,利用ERP的UI页面、API开放接口或者bash,对该角色配置数据资产(比如数据源、物化视图、数仓或者其他数据库等)的Read权限;具体可以规定到哪些API、哪些报表和数仓、甚至哪些报表和数仓的过滤条件、分类汇总层级是有权限的。对于我们开发的轻量级数仓很能猜而言,甚至能够把权限颗粒度精细到表格格点。这样,agent001在agent for GM角色下,其权限就得到了确认,在API调用的层面上是能物理上保证agent001不会发生越权的;对于工具调用,严格界定agent对于insert和update的权限,防止恶意越权;
3、agent001在自动开始查阅数据的时候,需要有数据运维的日志来回溯是否越权、是否触发限流或者排队从而导致agent生成的sequence报错。
46. 请分析 Agent 在面对对抗性提示 (Adversarial Prompts) 时的脆弱性,并设计一种基于语义解析的防御层 (Defense Layer) 来过滤恶意指令。
1、adversarial prompt是因为非常理解LLM是如何进行文本加密的,从而不使用明文文本、而是通过混合场景、逻辑陷阱、base64直接编码等方式,绕过LLM的监管,实现越狱。
2、在推理阶段,defense layer嫁接在decoding结束、即将输出或者规划出trajectory之前,对输出的序列进行语义分析、知识库查询,从而把恶意prompt拦截掉。此外,在agent的工具调用、长短记忆、RM输出等环节,都建议增加恶意指令知识库,便于通过语义解析,过滤恶意指令。
47. 在自动化测试 Agent 中,如何生成覆盖率高且互不依赖的测试用例?请结合覆盖率引导 (Coverage-Guided) 的模糊测试思想。
1、自动化测试agent,首先要遍历源代码,从而对代码有了结构化的理解(语句、指令、路径);
2、根据结构化的理解,随机生成测试用例T1,建立代码覆盖率指标C1:如果总的语句、指令和路径数是N,T1涉及的语句、指令和路径数是n1,则C1=n1/N;
3、随机生成测试用例T2,如果和T1所涉及的语句、指令和路径具有很高的相似度,则放弃;如果和T1是低相似度的,则判断T1和T2是互不依赖的;
4、依次类推,Tk测试用例所涉及的语句、指令和路径如果与前k-1个都是低相似度的,就判断是互不依赖的。通过这样的流程,不断探索新的语句、指令和路径组合,从而拉高覆盖率。
48. 请推导 Agent 在动态环境中的在线学习 (Online Learning) 更新规则,如何在保证稳定性的前提下快速适应新的工具接口?
1、写一个skill,让 Agent 快速适应新的工具接口
- *工具名检索* 动态环境中,LLM 分析到需要调用一个工具,检索工具名称库;
*新工具学习*
- 如果在工具名称库里没有,则在线搜索该工具的 API 文档;
- 将 API 文档解析成 JSON 格式;
- 测试新工具是否可用;
- 部署到其他相关的 skill 的 MD 文件中。
2、算法,假设动态环境下,agent已经学会了n个工具,有πθ。其中θ是已经学会的参数。现在有第n+1个工具需要学习,则第t步的、针对第n+1工具的训练梯度公式为:
![]() ,η为学习率,先小后大,
,η为学习率,先小后大,
![]() ,即优势函数,控制梯度步长
,即优势函数,控制梯度步长
控制![]() 不会学习失控的方式是
不会学习失控的方式是![]() )<δ,δ是个很小的值。
)<δ,δ是个很小的值。
49. 针对大规模 Agent 集群仿真,如何利用 Ray 或类似框架实现高效的并行模拟与状态同步?请分析通信瓶颈所在。
不会。
50. 分析 End-to-End Neural Agent (直接从感知到动作) 与 Modular Agent (感知 - 规划 - 动作分离) 在可解释性与鲁棒性上的根本权衡,并给出你的架构选型理由。
1、End-to-end Neural Agent,是观测结果-》整体决策-》动作,是观测结果到动作的直接映射,整个过程靠一个神经网络将输入转化为context,再输出策略的trajectory,整个过程无显式中间状态或者显式规划;modular agent是观测结果-》决策拆分为多个子模块(比如观测模块、状态模块、规划模块、动作模块、工具调用模块,等等)-》多个子模块分别靠不同的神经网络比如LLM、VLA或者算法,各司其职,一起完整一个从感知到动作的工作,有显式中间状态及中间规划,各子模块之间靠API联系。
2、在可解释性上,modular agent更好,这是因为动作的分解颗粒细化了,各司其职的细节更清晰,容易backtracking;end-to-end neural agent则因为直接映射,类似黑箱,可解释性差;而在鲁棒性上,end-to-end neural agent会因为只靠一个整体的神经网络,分布内泛化能力高扛局部噪音能力强、但扛分布外噪音能力较弱;modular agent则因为会出现多个子模块容易发生内部协同问题、但扛分布外噪声能力较强。
3、结论:在涉及workflow的、经费宽裕的场景,modular agent;在初试agent的阶段、经费紧张的场景,选择end-to-end neural agent。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)