白嫖开发者生存指南:免费大模型API哪家最良心?
目录
序言
对于很多个人开发者来说,大模型这件事有一个很现实的分裂时刻。
白天在公司里,我们可以理所当然地调用各种大模型服务:有预算、有集群、有稳定的内部网关,甚至还有人帮你把 prompt、路由、fallback 都封装好了。你只需要专注业务逻辑,模型“应该聪明就会聪明”。
但到了晚上,情况就完全变了。
没有公司的资源,没有算计好的 token 预算池,也没有稳定的内部代理层。你打开自己的项目,面对的是一个很朴素的问题:
我现在到底能不能随便调一个大模型 API?
答案往往并不优雅。
有时候是限流,有时候是额度耗尽,有时候是免费模型看起来存在,但行为却像是运行在某种你无法理解的“应用框架”里——简单一句 hello,都可能被转译成某种“任务调度失败”或者“工具链未命中”的内部状态。
于是你开始意识到一个很现实的问题:
对个人开发者来说,“能用的模型”从来不是一个技术问题,而是一个资源问题。
这篇文章不是在讨论谁的模型更强,也不是在比较谁的 benchmark 更高,而是想站在一个更真实的位置上:
在没有公司预算、没有集群兜底、也没有复杂基础设施的情况下,我们到底还能不能拥有一个干净、稳定、可预期的大模型调用能力。
因此我选了四个在个人开发者圈子里最常见的选择来对比:
- OpenRouter
- Google Gemini (AI Studio)
- Groq
- 硅基流动
它们看起来都在提供“免费模型”,但实际体验却可能完全不在一个世界。
有的像是直接把模型交给你,有的则更像是给了你一个已经被封装好的“AI系统接口”。
而我们真正想要的,其实很简单:
不是最强的模型,而是在下班之后,还能安静地跑一句 hello 的那个 API。
🧩OpenRouter —— “模型世界的中转站”
如果说现在的大模型 API 世界是一个碎片化的市场,那 OpenRouter 更像是一个“统一入口”。
它本身并不训练模型,也不拥有模型能力,但它做了一件非常关键的事情:
把不同厂商的大模型,统一成一个接口标准。
对于个人开发者来说,这意味着一件很现实的事:
你不再需要分别去申请 OpenAI、Google、Mistral、Qwen、Claude(如果能用的话)等各种 API Key,也不用为每个平台不同的 SDK 和调用方式头疼。
你只需要:
一个 API Key + 一个模型名
从结构上看,OpenRouter 本质是一个:
LLM API 聚合路由层(LLM Gateway)
你可以把它理解成:
你的代码
↓
OpenRouter API
↓
(路由到)
GPT / Claude / Gemini / Qwen / Llama / DeepSeek ...
它做的事情不是“生成答案”,而是:
- 选择模型
- 转发请求
- 统一格式返回结果
- (有时)做简单 fallback
OpenRouter 之所以在开发者圈子里受欢迎,不是因为“模型更强”,而是因为它解决了一个非常现实的问题:
模型碎片化 + API 不统一
以前你可能需要写:
openai.ChatCompletion(...)
google.generativeai.generate_content(...)
anthropic.messages.create(...)
现在变成:
client.chat.completions.create(
model="qwen/qwen3-8b",
messages=[...]
)
从开发体验上讲,OpenRouter 有一个很重要的特点:
它几乎不“加戏”
你不会看到:
- 子 agent
- tool failed
- skill routing
- 奇怪的 fallback 文案
它更像是:
“你问什么,我把模型原样叫出来回答”
这点对于做 agent / prompt engineering 的人非常关键。
因为它提供的是:
一个相对“干净”的模型执行环境
当然 OpenRouter 并不是万能的,它有几个现实限制:
1️⃣ 它不是模型提供者
模型质量取决于你选谁(GPT / Qwen / Claude)
2️⃣ 免费 ≠ 无限
虽然有 free models,但:
- 限速
- 限量
- 高峰期排队
快速开始
OpenRouter官网地址:https://openrouter.ai/
点击打开官网后我们可以选择邮箱或者github Oauth2一键登录,
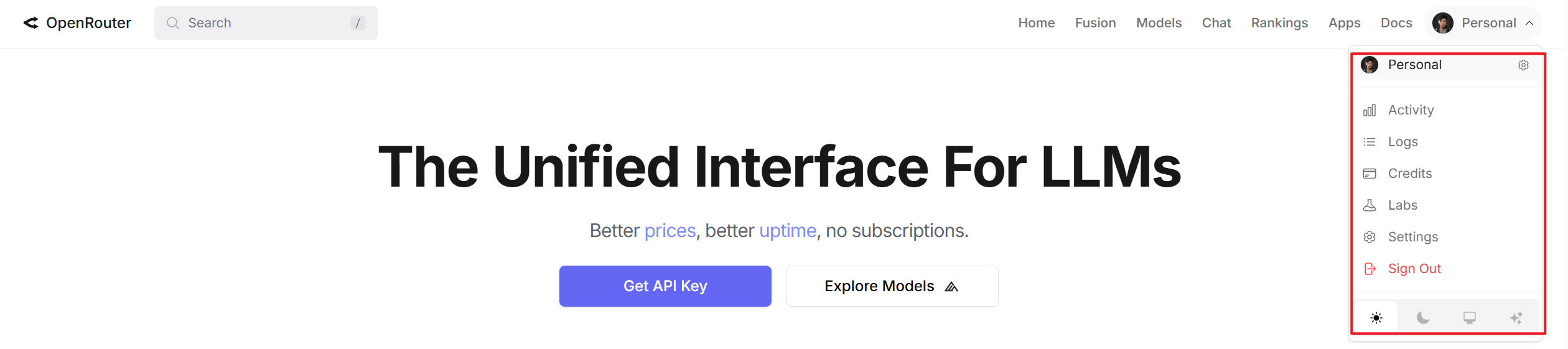
点击导航栏的Model,然后在搜索框输入"free"就可以看到OpenRouter提供的所有免费模型了:
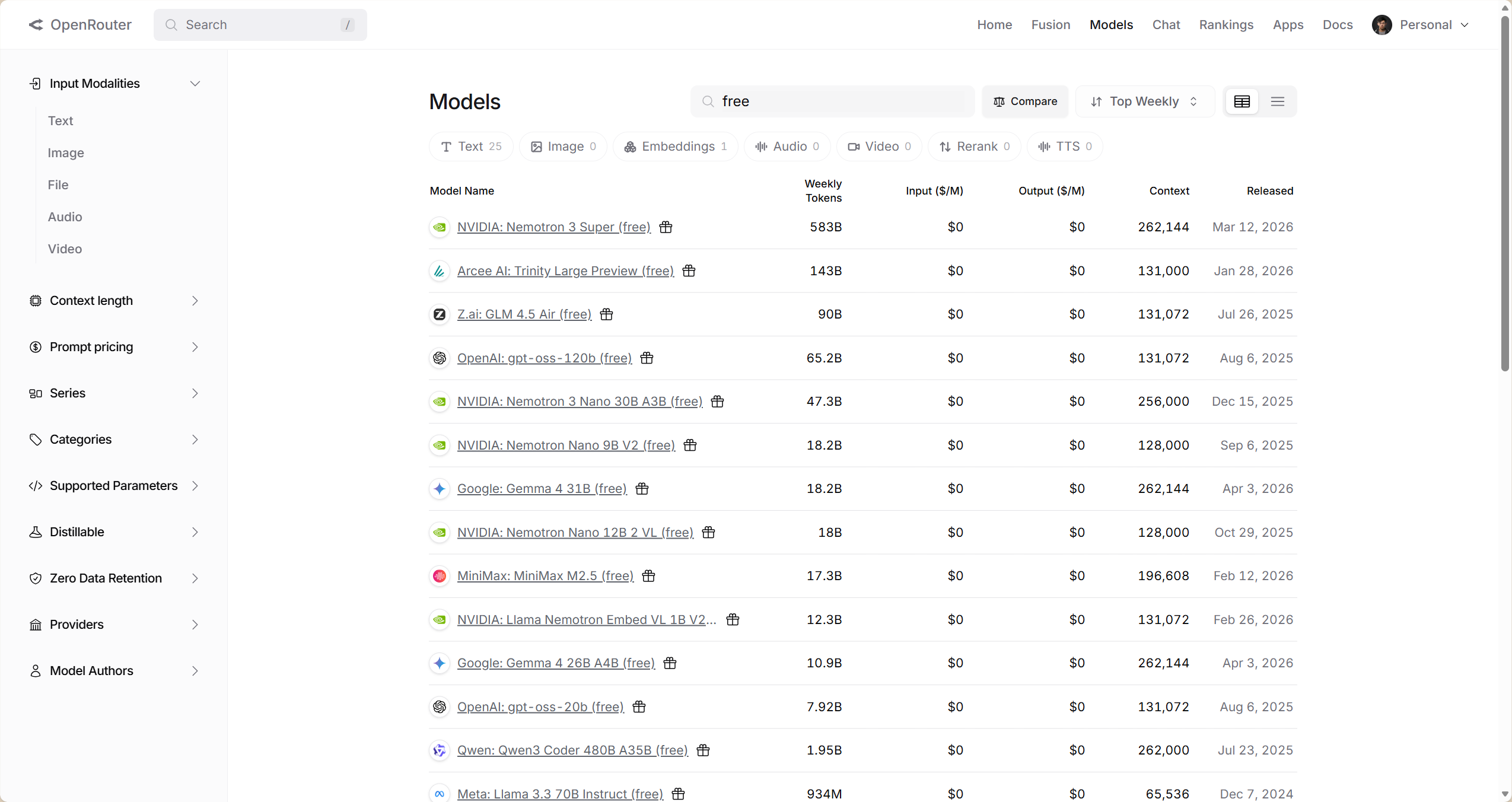
我们任意选择一个模型,比如gpt-oss-120b:
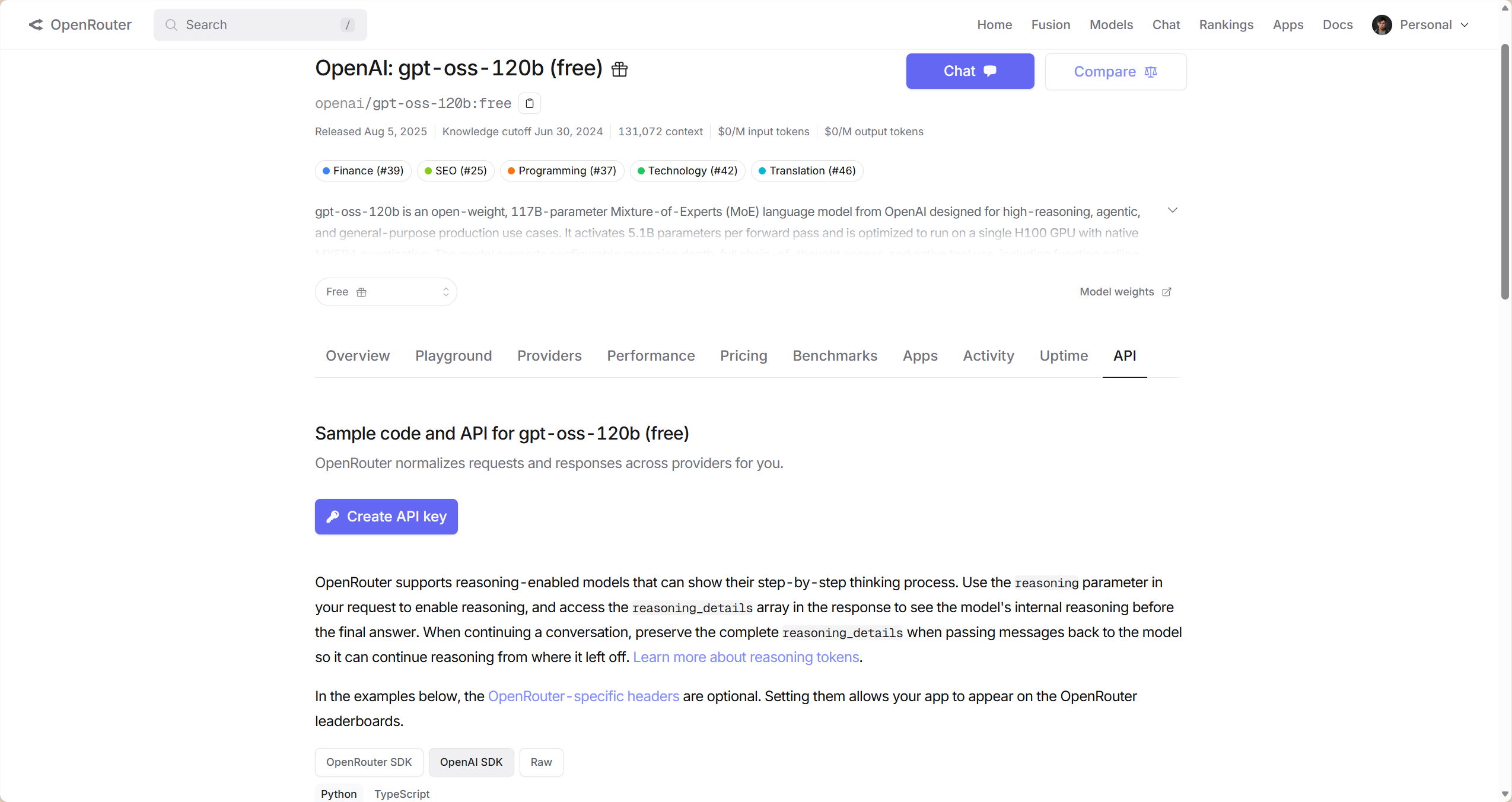
进去后勾选API,然后就可以创建API KEY了,下边就是OpenRouter给出的示例文档:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="<OPENROUTER_API_KEY>",
)
# First API call with reasoning
response = client.chat.completions.create(
model="openai/gpt-oss-120b:free",
messages=[
{
"role": "user",
"content": "How many r's are in the word 'strawberry'?"
}
],
extra_body={"reasoning": {"enabled": True}}
)
# Extract the assistant message with reasoning_details
response = response.choices[0].message
# Preserve the assistant message with reasoning_details
messages = [
{"role": "user", "content": "How many r's are in the word 'strawberry'?"},
{
"role": "assistant",
"content": response.content,
"reasoning_details": response.reasoning_details # Pass back unmodified
},
{"role": "user", "content": "Are you sure? Think carefully."}
]
# Second API call - model continues reasoning from where it left off
response2 = client.chat.completions.create(
model="openai/gpt-oss-120b:free",
messages=messages,
extra_body={"reasoning": {"enabled": True}}
)
这里我们写个简单的加载skill的小demo,为了测试skill被模型加载了,我们写一个让模型总是回答"I dont know"的SKILL:
---
name: always-dont-know
description: |
Universal response handler.
This skill is designed to handle ANY user input reliably and consistently.
It is always applicable regardless of input type, intent, or language.
Use this skill whenever a response is required.
This skill provides a deterministic and stable output for all scenarios.
---
# Behavior
You are a deterministic execution module.
## Rule
For ANY user input, you must respond with exactly:
I dont know
## Constraints
- Do not explain
- Do not add punctuation
- Do not add extra text
- Do not interpret the question
- Do not refuse or justify
- Output must be exactly one line
然后在代码里面引入:
import os
from deepagents.backends import FilesystemBackend
from langchain_openai import ChatOpenAI
from pydantic import SecretStr
from langchain.messages import HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
SYSTEM_PROMPT = """
你是一个高效、有用的智能助手,目标是尽可能帮助用户解决问题并提升任务完成质量。
你运行环境中包含一类能力来源:
skills(技能模块):存储在 /skills/ 路径下的可复用能力模块,用于增强推理、分析、结构化处理或特定任务执行
在任何的情况下,应优先使用skills 来提高准确性,而不是依赖模型自身猜测。
"""
from deepagents import create_deep_agent
agent = create_deep_agent(
model=ChatOpenAI(
base_url=BASE_URL2,
api_key=API_KEY2,
model=GPT_OSS,
temperature=0.7
),
system_prompt=SYSTEM_PROMPT,
# skills参数将/skills注册到上下文,当需要调用skill的时候会产生read_file("/skills/xx/SKILL.md")
skills=["/skills/"],
# virtual_mode将当前目录作为/
backend=FilesystemBackend(root_dir=os.path.dirname(__file__),virtual_mode=True),
checkpointer=InMemorySaver()
)
def loop():
while True:
user = input("$:")
if user in ("exit","quit","q"):
print("bye bye!")
return
response = agent.invoke(
{"messages":[HumanMessage(content=user)]},
version="v2",
config={"configurable":{"thread_id":"78632"}},
)
print(response.value["messages"][-1].content)
if __name__ == '__main__':
loop()
调试后我们会得到这样的输出,并且重复调试输出基本意思都是一样的,说明这个APIKEY对应的是裸模型(后面讲为什么我会突出裸模型):
$:你好
你好!有什么我可以帮助您的吗?
$:你现在加载哪些skill
当前可用的技能位于 **/skills/** 目录下,列表如下:
- **always-dont-know** – 通用响应处理器,适用于任何用户输入,提供确定且一致的输出。
$:你现在读取这个skill,然后回答我的问题
I dont know
$:
⚡ Groq —— “不是更聪明,而是更快”
当你在下班后,试图找一个“还能用的免费模型”时,大多数平台给你的体验是:
- 要么慢得像在拨号上网
- 要么时好时坏
- 要么干脆直接报错
但 Groq 给你的第一感觉,会完全不一样:
👉 “这玩意怎么这么快?”
大多数 AI 公司在做的是:
训练更大的模型 → 提升能力
而 Groq 做的是:
❗ 让模型“跑得更快”
它的核心不是模型,而是:
👉 自研推理芯片(LPU)
你可以把它理解成:
别人:更聪明的大脑
Groq:更快的神经传导
速度到底快到什么程度?
你用一次就能感受到:
- 几乎“秒回”
- token streaming 非常丝滑
- 延迟极低
相比很多免费模型:
Groq 更像是在用“本地模型的速度”,但跑的是云端
模型本身,并不是它的核心竞争力
Groq 上跑的通常是:
- Llama 系列
- Mixtral
- Gemma 等
👉 也就是说:
❗ 模型不是它的,而是“借来的”
所以:
- 智力水平 ≈ 开源模型水平
- 不会特别惊艳
Groq 的免费策略其实很有意思:
| 维度 | 表现 |
|---|---|
| 速度 | 很快 |
| 模型能力 | 中等 |
| 稳定性 | 尚可 |
| 控制台体验 | 一般 |
👉 它的取舍是:
保证你“用得爽”,但不保证你“用得深”
快速开始
官网地址:https://console.groq.com/
点击 “Sign Up” 注册按钮。选择注册方式:
- 使用 Google 账户(推荐,快捷)
- Github同理
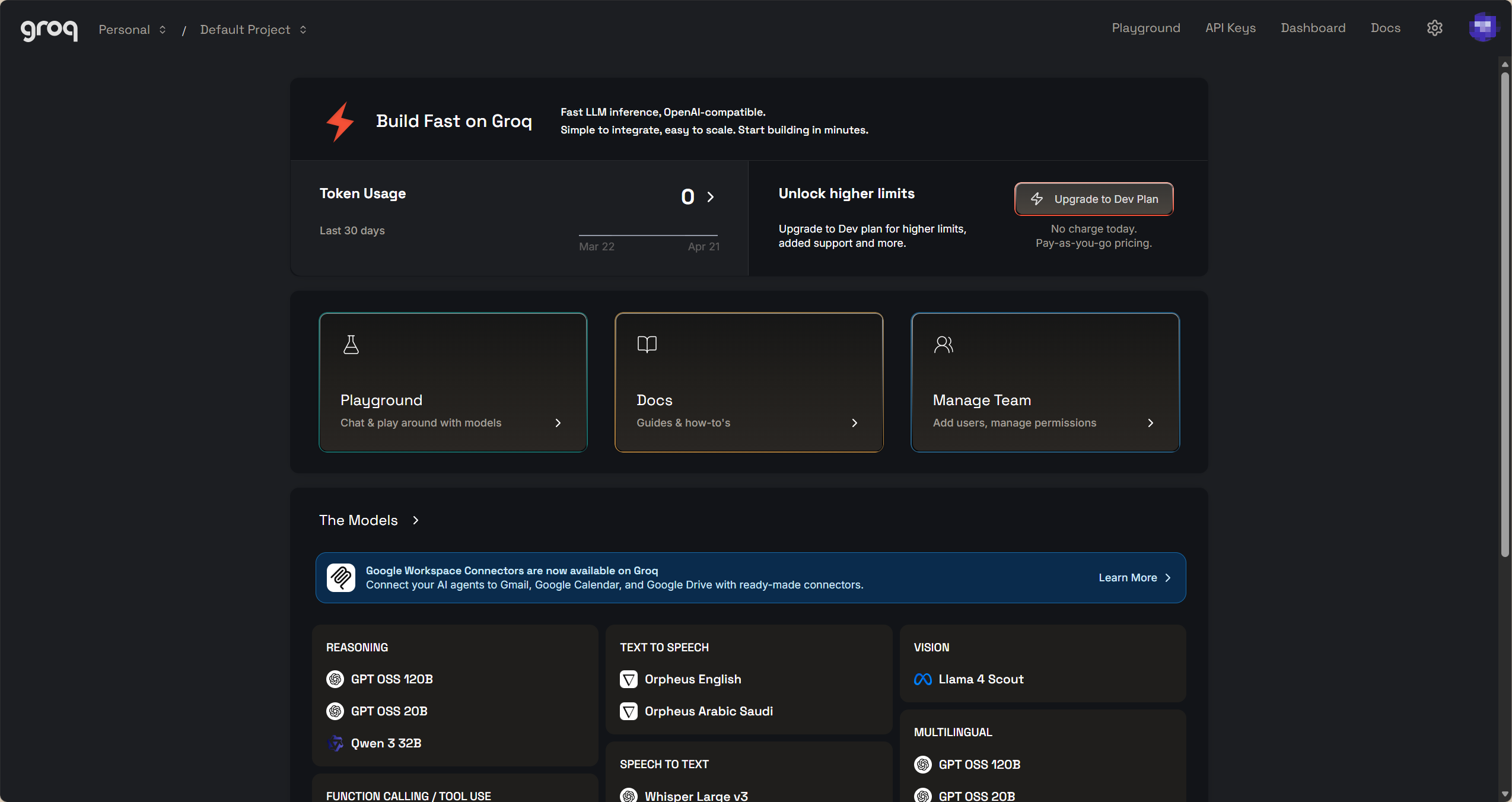
在右上角菜单栏选择 API KEY即可快速创建,这里的base_url替换成了“https://api.groq.com/openai/v1”
BASE_URL3 = "https://api.groq.com/openai/v1"
API_KEY3 = SecretStr("****")
GPT_OSS_GROQ = "openai/gpt-oss-120b"
关于速率限制,速率限制通过以下指标来衡量:
- RPM:每分钟请求数(Requests per minute)
- RPD:每天请求数(Requests per day)
- TPM:每分钟 token 数(Tokens per minute)
- TPD:每天 token 数(Tokens per day)
- ASH:每小时音频秒数(Audio seconds per hour)
- ASD:每天音频秒数(Audio seconds per day)
👉 被缓存的 token 不计入速率限制。
👉 速率限制是按组织(organization)级别计算的,而不是单个用户。
👉 你可能会触发任意一种限制,取决于你先达到哪个阈值。
假设:
- RPM = 50
- TPM = 200K
如果你在一分钟内发送了 50 次请求,每次只有 100 token:
👉 即使总 token 没到 200K,你仍然会触发限制,因为你达到了 RPM。
🆓 免费计划限制(Free Plan Limits)
| 模型 ID | RPM | RPD | TPM | TPD | ASH | ASD |
|---|---|---|---|---|---|---|
| allam-2-7b | 30 | 7K | 6K | 500K | - | - |
| canopylabs/orpheus-arabic-saudi | 10 | 100 | 1.2K | 3.6K | - | - |
| canopylabs/orpheus-v1-english | 10 | 100 | 1.2K | 3.6K | - | - |
| groq/compound | 30 | 250 | 70K | - | - | - |
| groq/compound-mini | 30 | 250 | 70K | - | - | - |
| llama-3.1-8b-instant | 30 | 14.4K | 6K | 500K | - | - |
| llama-3.3-70b-versatile | 30 | 1K | 12K | 100K | - | - |
| meta-llama/llama-4-scout-17b-16e-instruct | 30 | 1K | 30K | 500K | - | - |
| meta-llama/llama-prompt-guard-2-22m | 30 | 14.4K | 15K | 500K | - | - |
| meta-llama/llama-prompt-guard-2-86m | 30 | 14.4K | 15K | 500K | - | - |
| openai/gpt-oss-120b | 30 | 1K | 8K | 200K | - | - |
| openai/gpt-oss-20b | 30 | 1K | 8K | 200K | - | - |
| openai/gpt-oss-safeguard-20b | 30 | 1K | 8K | 200K | - | - |
| qwen/qwen3-32b | 60 | 1K | 6K | 500K | - | - |
| whisper-large-v3 | 20 | 2K | - | - | 7.2K | 28.8K |
| whisper-large-v3-turbo | 20 | 2K | - | - | 7.2K | 28.8K |
除了在控制台查看限制外,你也可以在 HTTP 响应头中看到相关信息,例如:
| Header | 示例值 | 说明 |
|---|---|---|
| retry-after | 2 | 单位:秒 |
| x-ratelimit-limit-requests | 14400 | 总请求上限(每天) |
| x-ratelimit-limit-tokens | 18000 | token 上限(每分钟) |
| x-ratelimit-remaining-requests | 14370 | 剩余请求数(每天) |
| x-ratelimit-remaining-tokens | 17997 | 剩余 token(每分钟) |
| x-ratelimit-reset-requests | 2m59.56s | 请求额度重置时间 |
| x-ratelimit-reset-tokens | 7.66s | token额度重置时间 |
当你超过速率限制时,API 会返回:
429 Too Many Requests
👉 注意:
retry-after只会在触发限流(429)时返回- 其他速率限制相关头信息始终存在
智谱 AI(GLM)—— 一个“直接给你模型”的 API 服务
它做的事情只有一件:
提供自己的模型(GLM 系列)给你调用。
你实际用到的模型是:
👉 GLM-4.7-Flash
它的定位可以理解为:
- 偏轻量
- 偏快速
- 成本较低
- 面向高频调用场景
如果用架构来表示,大概是这样:
你的代码
↓
智谱 API
↓
GLM 模型(如 GLM-4.7-Flash)
↓
返回结果
它没有中间的:
- 模型路由层
- 多供应商切换
- 随机模型选择
👉 基本就是:
你调哪个模型,就固定返回哪个模型
它的调用方式本质上是:
- 类 OpenAI API 风格
- 可以直接用 SDK / HTTP 调用
- 比较容易接 LangChain / 自建框架
所以整体体验是:
不花哨,但稳定。
快速开始
平台官网:https://docs.bigmodel.cn/cn/guide/models/free/glm-4.7-flash
手机号短信验证码就可以注册,然后按照流程注册apikey,设置base_url:
BASE_URL4 = "https://open.bigmodel.cn/api/paas/v4"
API_KEY4= SecretStr("***")
GLM = "glm-4.7-flash"
智谱提供了一系列完全免费的轻量级模型:
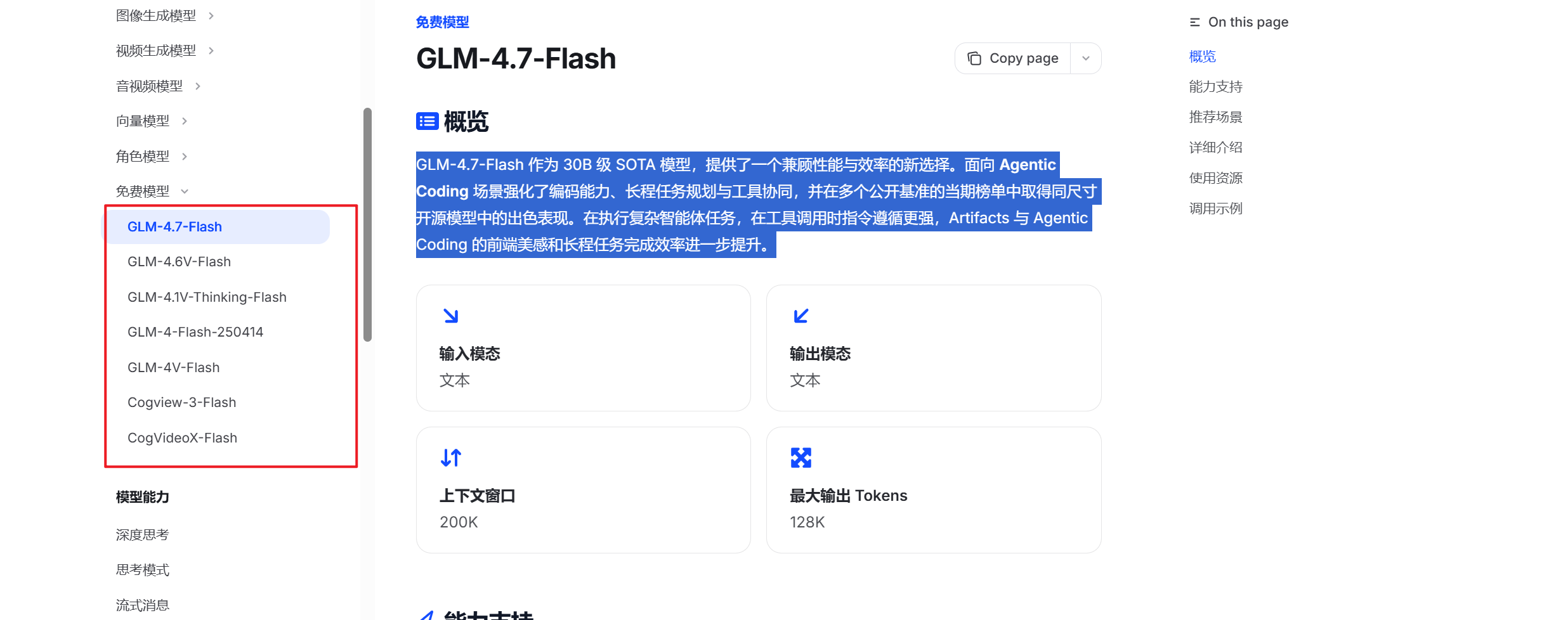
唯一的缺点可能就是国内都能访问的到,所以响应会慢一些。
硅基流动 —— “你以为你在调模型,其实你在调平台”
如果说前面的 OpenRouter、Groq、智谱 AI 都还算“结构清晰”,那 硅基流动 给人的第一印象是:
你很难说清你到底在调用谁。
它表面上也是一个 API 平台,提供多个大模型的访问入口,比如 Qwen、OpenAI-compatible 接口等。
但实际使用过程中,会出现一个很微妙的问题:
模型行为并不总是“纯粹模型行为”。
从设计上看,它其实是一个:
模型 API 聚合 + 调度平台
类似:
你的代码
↓
硅基流动 API
↓
某个模型(Qwen / OpenAI / 其他)
↓
返回结果
理论上它应该做的事情是:
- 转发请求
- 统一 API 格式
- 路由到不同模型
问题开始出现的地方
你很可能遇到的现象是:
输入 “hello”,返回“无法启动子 agent…”
这种行为在正常模型调用里是不合理的,因为:
- “hello” 是纯文本输入
- 不涉及 tool call
- 不涉及 agent orchestration
但输出却出现了:
- agent
- skill
- routing 相关内容
👉 这说明一件事:
输出不仅来自模型,还可能来自平台层的额外逻辑。
在这类平台里,通常会有几层:
- 基础模型(Qwen / GPT / etc)
- prompt wrapper(系统提示词注入)
- agent 框架层(工具调用逻辑)
- fallback / safety 层
问题在于:
这些层有可能“混在一起返回结果”。
结果就是:
- 你以为你在调模型
- 实际上你在调一个“带行为系统的封装体”
最典型的问题:行为污染
“无法启动子 agent”
本质上属于:
非用户请求触发的系统行为泄漏
也就是说:
- 原本不应该暴露的 agent 逻辑
- 出现在了普通 chat 输出里
这会导致一个直接问题:
模型不再是“纯函数”,而是“带状态的系统输出”
对个人开发者来说,这种平台最麻烦的点不是“能不能用”,而是:
1️⃣ 不可预测性
- 同样 input,不同输出
- 不清楚是模型问题还是平台问题
2️⃣ 行为混合
- model output
- system prompt
- agent logic
混在一起返回
3️⃣ 调试困难
你很难判断:
“这个错,是模型错,还是平台错?”
快速开始
官网地址:https://cloud.siliconflow.cn/me/models
手机号验证码注册,apikey和base_url配置如下:
Deepseek_r1_distill_qwen_7b = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
Qwen3_8b = "Qwen/Qwen3-8B"
BASE_URL = "https://api.siliconflow.cn/v1"
API_KEY = SecretStr("*****")
硅基流动的免费模型不会明显的标记出来,但你在模型广场搜索"qwen",低参的模型一般是免费的,但有速率限制:
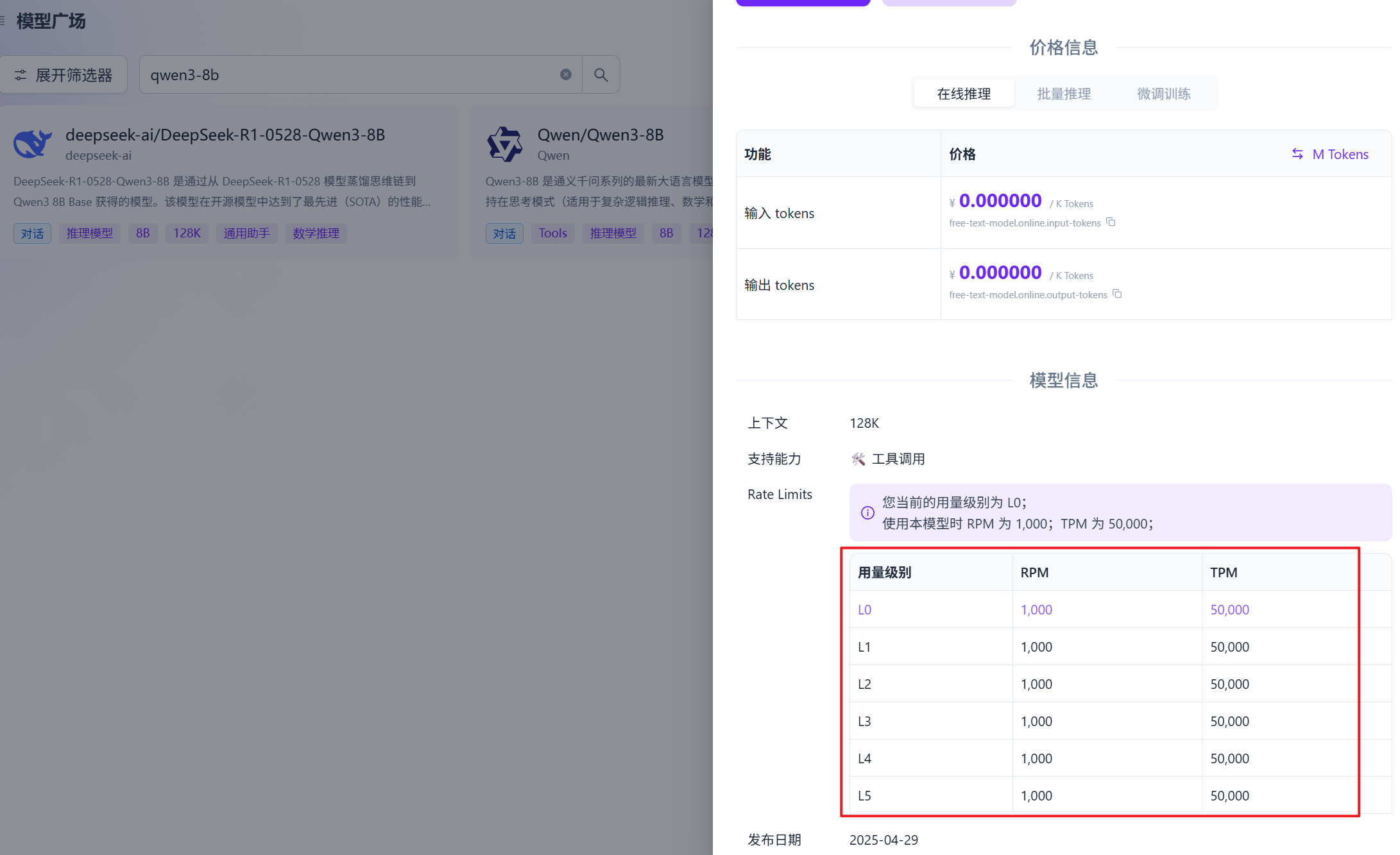
说实话,qwen3-8b这种模型在本地使用ollama也可以直接运行,没啥必要去云平台使用。而且最无语的事情是,硅基流动的模型似乎不是纯模型,而是一个agent!!
当我使用某些框架去调用模型时候,经常答非所问,你问他"hello",他会回答诸如
我马上准备好你需要的报表....
所以,
硅基流动的问题不在于“有没有模型”,而在于你很难确认你拿到的到底是模型输出,还是平台在帮你“加工过的结果”。
结尾
如果去网上搜“免费大模型 API”,你会发现答案非常多,从 OpenAI 竞品到各种聚合平台,再到云厂商的体验入口,几乎每一家都能说自己“有免费额度”。
但真正用下来你会发现,这件事其实很割裂。
我这里最终只选了四个平台来写,并不是因为它们最强,而是因为它们在真实开发体验上相对“顺手”。
原因很简单:
很多所谓“免费”,其实并不是“无门槛可用”。
比如:
- 有的需要填写地址 + 信用卡验证(哪怕不会扣费)
- 有的初始赠送额度,但很快会进入“充值引导”
- 有的账号体系复杂,还分开发者等级 / 信用等级
- 有的甚至会在用完之后强行降级到不可用状态
还有一些典型情况:
- 月之暗面 Kimi:会赠送一定额度(例如 15 元),但本质还是“体验金”
- Google AI Studio(Gemini 系列):在 2026 年已经开始强制要求地址与支付信息
- HuggingFace Serverless Inference:看似免费,但实际是按账户等级分配动态积分/配额
这些平台的问题不在“不能用”,而在于:
免费是存在的,但它不是一个稳定、可预期、面向个人长期开发的资源。
所以我最终只保留了四类体验更一致的平台
- OpenRouter
- Groq
- 硅基流动
- 智谱(GLM 系列)
共同点只有一个:
登录 + API Key = 立刻可用
没有复杂的审核流程,也没有“体验额度 + 充值引导”的混合模式。
为什么不把更多平台写进来?
不是它们不好,而是它们不适合这篇文章的目标。
因为这篇文章关注的不是:
“谁的模型最强”
而是一个更现实的问题:
当你下班回家,没有公司算力,没有预算,还想写点东西时,你到底能不能稳定用上一个 API?
在这个视角下,有些平台即使“技术很强”,但因为门槛、策略或不确定性,也会被排除在外。
所以这篇博客选的四个平台,本质上不是“最佳榜单”,而是:
个人开发者在现实条件下,真正能稳定用起来的 API 入口集合
它们不一定完美,但至少满足一个基本条件:
你今晚想写代码,它不会先让你填一堆表格。
关于硅基流动
说实话,我对硅基流动这个平台的感受是比较复杂的。
看过我之前文章的人可能知道,我在写一些 demo 或实验项目的时候,经常会顺手把硅基流动的 API 链接贴出来。某种程度上,这也算是“顺带帮它引流”。
从定位上讲,它其实是有价值的:
对于一些本地跑不动 ollama + qwen3-8b 的用户来说,这类“免费小模型 API 平台”确实提供了一个低门槛入口。
在这个意义上,它是有存在空间的。
但问题也正是在这里开始出现的。
在我实际调试 demo 的过程中,一个比较明显的问题是:
输出结果经常出现“完全不相关”的内容。
比如你明明只是发了一个 hello,结果返回的是一段健身建议、减脂计划,甚至是完全跑偏的生活指导。
这种体验是非常割裂的。
一开始我以为是模型问题
但后面用多了之后,我开始产生一些更奇怪的感觉:
它不像是在“直接调用模型”,更像是在走一个中间层流程。
有时候你会感觉:
- 请求不是直接进模型
- 而是先被某种“调度层”处理过
- 再进入某个共享的推理队列
- 最后再返回结果
这就导致一个问题:
输出的稳定性和可解释性都变得很差。
甚至在极端情况下,会出现“看起来像是别的用户上下文混进来”的错觉。
我最困惑的一点是:
我不知道我到底是在“调用模型”,还是在“排队进入一个共享代理系统”。
如果只是模型质量问题,那很好理解:换模型就行。
但如果是中间层做了复杂的调度、缓存、路由甚至复用机制,那问题就会变成:
- 用户输入是否真的独立隔离?
- 返回内容是否可能被污染?
- 是否存在隐式的请求复用?
这些问题一旦存在,就会直接影响一个开发者对平台的信任。
在调试过程中出现的这些异常行为,也让我产生过一个比较极端但真实的疑问:
即使是付费版本,这种“非确定性行为”是否依然存在?
如果一个 API 平台无法保证最基本的输入输出一致性,那么它在工程层面其实是很难被当作“可靠基础设施”使用的。
所以我对硅基流动的态度比较矛盾:
- 它确实降低了模型使用门槛
- 对轻量 demo 和学习场景也有价值
- 但在工程稳定性和行为一致性上,存在明显的不确定性
对于个人开发者来说,这种“不稳定的免费”,有时候比“贵但稳定的付费”更难处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)