我把 GPT-2 的 KV Cache 跑通了:miniONNXRuntime 工程拆解
这篇文章聚焦一个问题:在
miniONNXRuntime里,GPT-2 的生成链路为什么会在长上下文下变慢,以及 KV Cache 是如何通过 prefill/decode 双图把重复计算降下来的。文章会按“负载差异 -> KV 原理 -> 双图执行 -> 进阶优化点”展开,重点解释设计思路和实现细节之间的对应关系。
相关阅读:
- 我做了一个迷你版 ONNX Runtime,终于把推理引擎的主线看懂了
- 我做了一个迷你版 ONNX Runtime,终于把图优化看懂了
- 我做了一个迷你版 ONNX Runtime,终于把buffer复用看懂了
- 我给 miniONNXRuntime 做了 mac + CUDA 的 EP,这里是实现思路
项目地址:
https://github.com/WWandP/miniONNXRuntime
pipeline介绍
如图所示: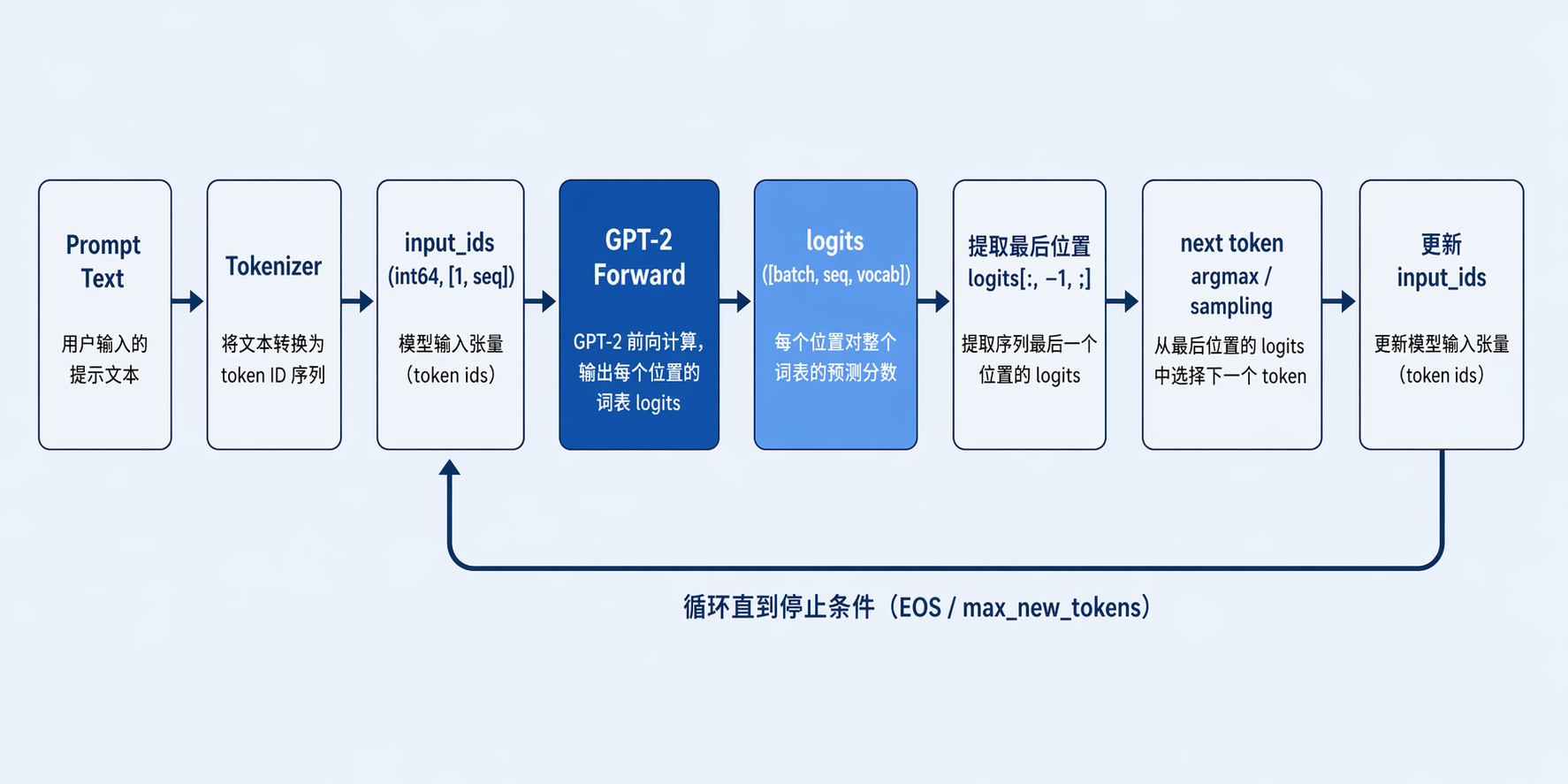
这张图从左到右展示了一轮gpt2生成的完整链路:文本输入经过 tokenizer 变成 token ids,模型前向后得到 logits,再从最后一个位置选出 next token。只取最后位置是因为自回归语言模型在第 t 轮的目标就是预测第 t+1 个 token,不需要对前面位置重复做决策。图里的回环箭头表示新 token 会拼回上下文并触发下一轮前向,这也是“训练一次、推理循环使用”的核心思路。
负载差异
YOLO 推理通常是一轮前向,输入一张图,输出一次结果。
GPT-2 续写是多轮前向。模型每轮只生成一个 token,然后把这个 token 追加回上下文,继续下一轮。
这意味着性能瓶颈不只在“单轮算得快不快”,还在“历史内容会不会被反复重算”。
最小流程可以写成下面的伪代码:
prompt = "The sky is"
token_ids = tokenizer.encode(prompt) # [464, 6766, 318] (示意)
while not stop_condition:
logits = model(token_ids) # shape: [1, seq, vocab]
next_id = argmax(logits[:, -1, :]) # 取最后位置
token_ids.append(next_id) # 进入下一轮
只要模型还没遇到结束条件,这个循环就会持续。
Baseline 重算开销
baseline 路径的逻辑很直观:每一轮都把“完整上下文”重新喂给模型。
例如:
- 第 1 轮输入长度是 10。
- 第 2 轮输入长度是 11。
- 第 3 轮输入长度是 12。
每增长 1 个 token,历史 token 的 attention 路径仍然会被再算一遍。
从算子层看,MatMul 和相关 shape 变换会随着序列长度持续放大。
从体验层看,就是“前几轮快,后几轮越来越慢”。
KV Cache 原理
自注意力中,当前轮会计算 Q/K/V。其中历史 token 的 K/V 对下一轮仍然有效。
KV cache 的核心思想是:
- 首轮把 prompt 跑完,得到每层的
K/V。 - 后续轮次只输入新 token,并把历史
K/V作为past_kv直接喂给模型。 - 本轮新增的
K/V再追加到缓存中,供下一轮使用。
它减少的是“历史部分的重复计算”,所以在长上下文下收益更明显。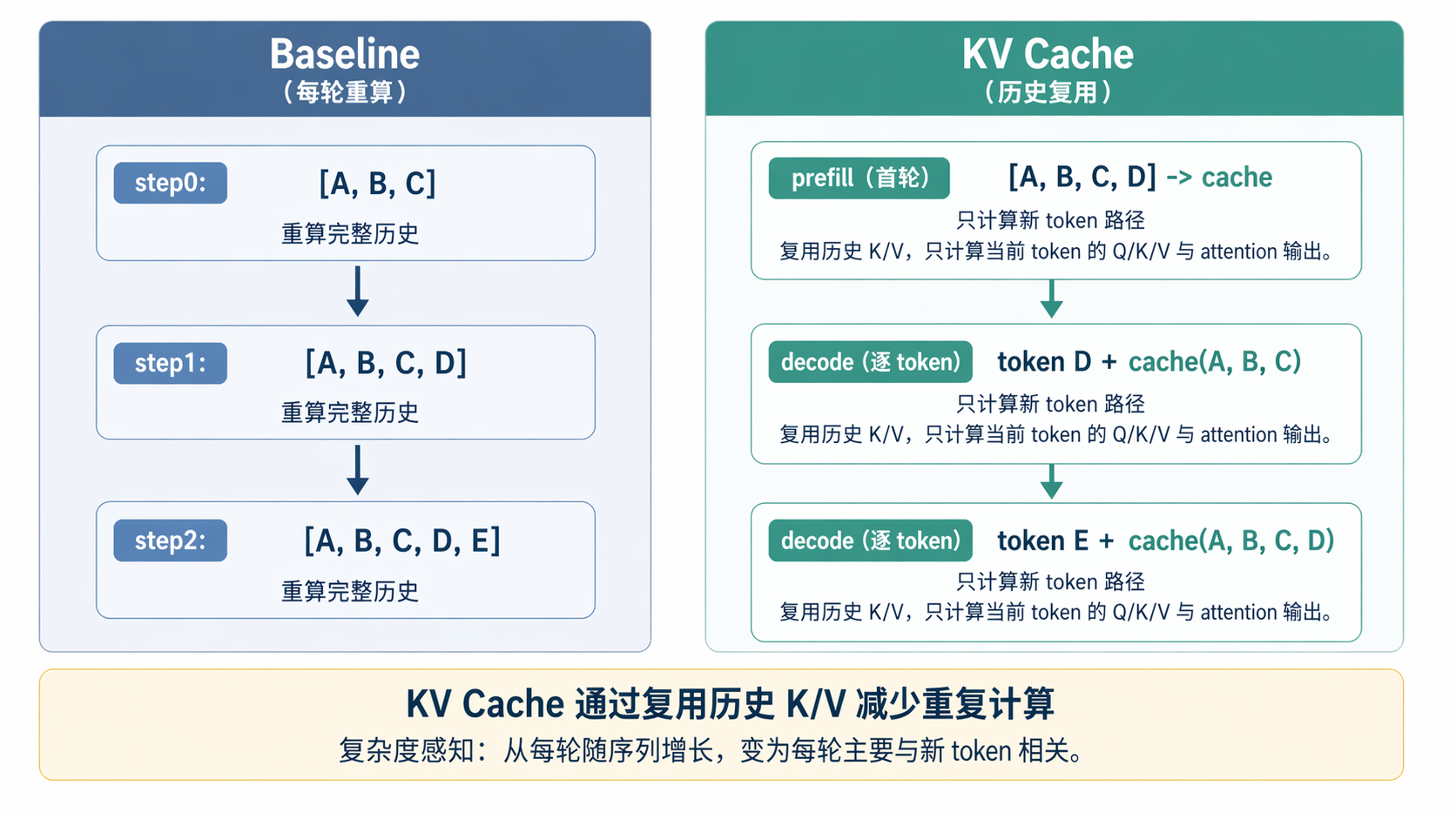
左侧 baseline 每一轮都会把历史 token 的 attention 路径再算一遍,历史越长,重复计算越多;右侧 KV cache 把历史 K/V 保留下来并直接复用,每轮只计算新 token 的增量部分。背后的原理是 attention 的历史键值在下一轮不会改变,它们属于可缓存状态,不需要在每轮重新计算。图中重复计算区域的差异,对应的就是长序列下两条路径的实际开销差异。
Prefill/Decode 双图
在工程实现上,miniONNXRuntime 采用两张 ONNX 图:
prefill graph:输入完整 prompt,产出首轮logits和初始 cache。decode graph:输入1 token + past_kv,产出本轮logits和更新 cache。
这么拆分的好处是边界清晰。
prefill 负责“把上下文烘热”,decode 负责“低延迟迭代”。
另一个关键点是 cache 绑定策略。运行时通过张量命名自动解析层号和类型,再建立映射,不需要手写“第 N 层 key/value 对应哪个张量”。这样更适合不同导出版本的模型命名差异。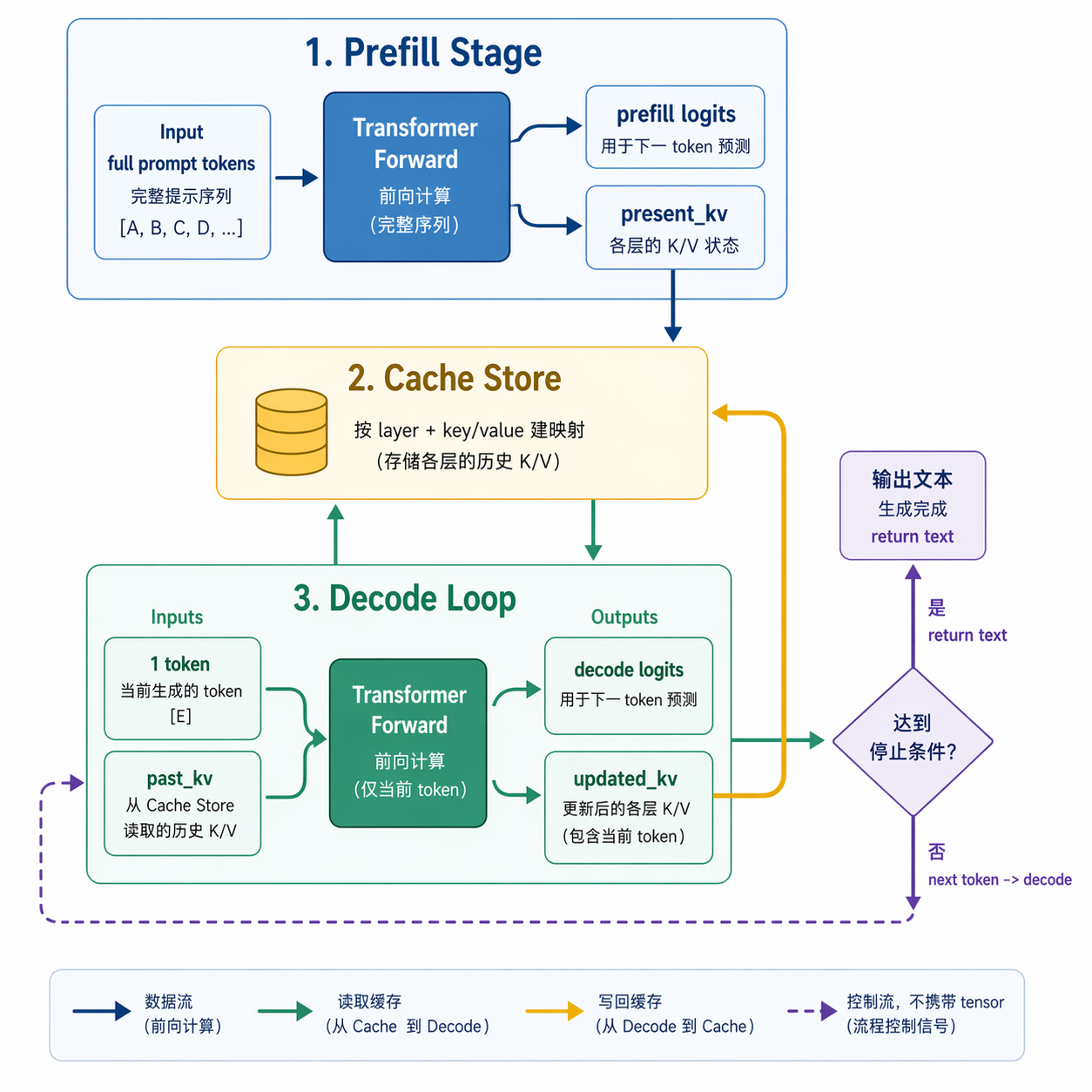
这张图展示了双图执行的节奏。先用 prefill 图吃完整 prompt,拿到首轮 logits 和初始 cache;然后切到 decode 图,每轮只输入一个 token 和 past_kv,产出本轮 logits 与更新后的 cache。图里的回流箭头表示状态闭环:本轮 decode 的 cache 输出会直接成为下一轮 decode 输入。之所以拆成双图,是因为这两段计算在工程目标上不同:prefill 追求一次性吞吐,decode 追求逐 token 延迟,把它们分开后更容易分别优化。
运行时分层
这一条链路可以按六层理解。先看职责分离,再看层间协作关系会更清楚:
- 工具层管理生成循环,包括输入组织、迭代调用和结果输出。
- Loader 把 ONNX 文件解析成内部图结构,提供可执行的拓扑信息。
- Session 负责调度主线,完成 provider 分配、节点执行和 summary 汇总。
- ExecutionContext 保存当前轮 tensor 状态,承接中间值与输出值流转。
- Kernel 实现每个
op_type的数学语义,是具体计算落地的位置。 - ExecutionProvider 管理后端能力和优先级,决定算子最终落在哪个执行后端。
这样排错会更直接:
如果是“文本重复”,先看生成策略和 logits;如果是“shape 错”,先看 context 中间值和 shape 算子链;如果是“性能抖动”,再看 provider 落点和热点算子。
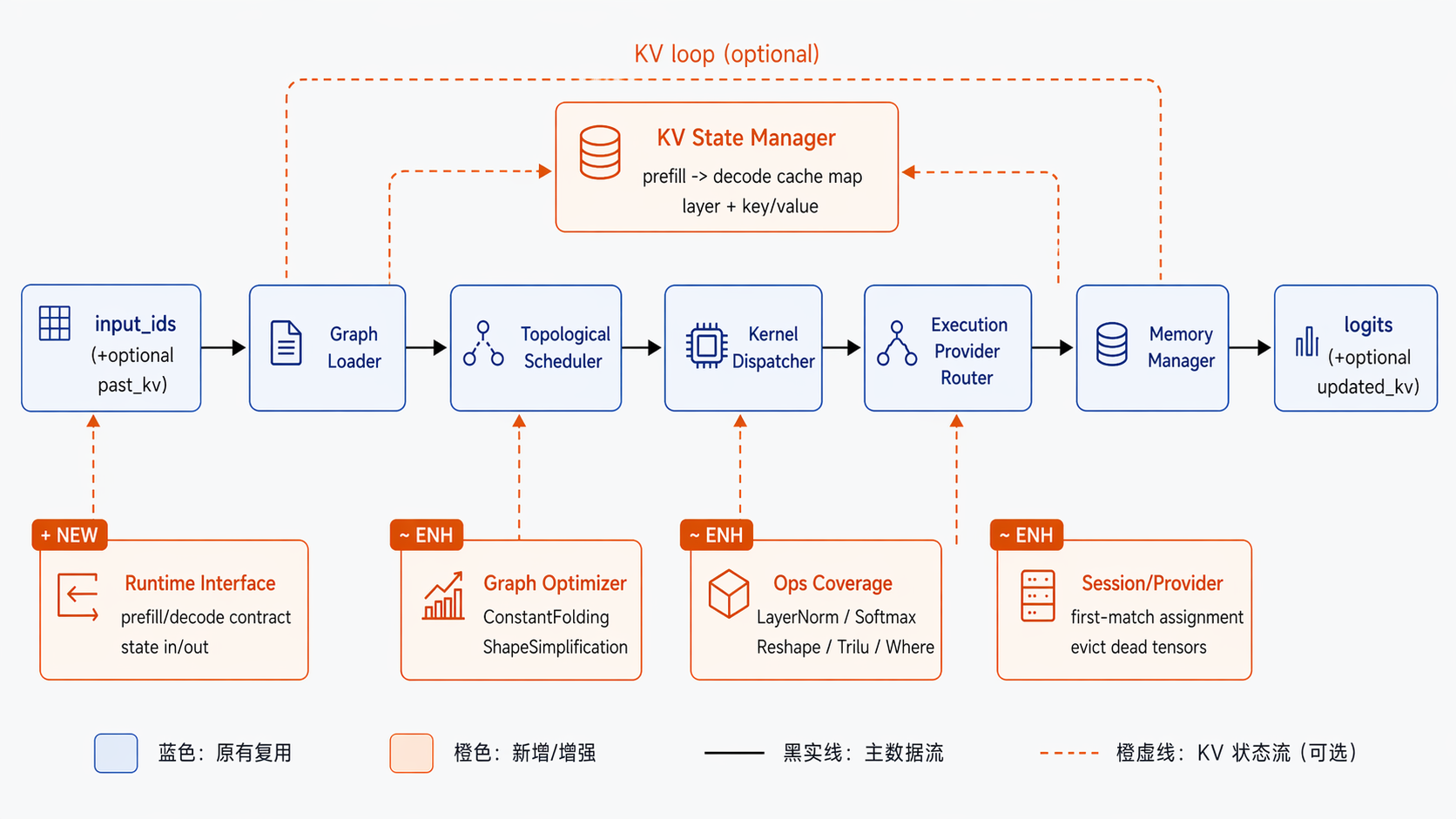
这张图可以按“上层控制流、下层执行能力”来理解。上层负责 prompt 编码、循环调用和结果输出;下层负责图解析、节点执行、kernel/provider 等通用 runtime 能力。纵向连线表示依赖方向,工具层通过 Session 驱动 ExecutionContext 和 Kernel 执行。横向模块体现的是可替换边界:provider 和算子实现可以演进,但上层生成主流程可以保持稳定。这种分层的原理是把“变化快的部分”和“稳定接口”隔离开,减少一次优化对全链路的连锁影响。
Decode Shape 示例
假设 batch 固定为 1,头数是 H,每头维度是 D。
prefill 之后某层 cache 可能是:
past_key:[1, H, T, D]past_value:[1, H, T, D]
进入下一轮 decode 时,新输入只有一个 token,当前轮会生成:
new_key:[1, H, 1, D]new_value:[1, H, 1, D]
然后在时间维拼接成:
updated_key:[1, H, T+1, D]updated_value:[1, H, T+1, D]
这个例子解释了一个常见报错来源:
只要某层的 rank 或拼接轴定义和导出图不一致,就会在 Concat/Reshape/Transpose 链条上触发 shape 错误。
进阶优化点
1. 生成策略
当前实现走确定性的 greedy 路径,尚未接入采样器。关键细节有三点:
- 只读取最后一个位置的 logits。实现里先按
offset = (sequence - 1) * vocab定位最后 token 的分数切片,再排序。 SelectGreedyNextToken直接取排序后第一个 id。PrintTopKFromLogits会打印 top-k 候选,但这个 top-k 只用于观测,不参与选 token。
可以把当前逻辑理解成:
ranked = sort_desc(logits[:, -1, :])
next_id = ranked[0].token_id
这条路径的优点是稳定、可复现,适合做 baseline 对齐和回归测试。后续要上采样时,可以在这个位置替换成 top-k/top-p 采样器。
2. Provider 选择
provider 选择在 Session 构造阶段就确定,核心是“首个命中优先”:
- 默认顺序是 CUDA(可用时)-> Accelerate(macOS)-> CPU。
- 每个 provider 先注册自己的 kernel 集合。
- 全局
kernel_registry对同一个op_type只接受第一次注册,后面的 provider 不覆盖。 - 节点分配策略是
kFirstMatch,节点归属到第一个支持该 op 的 provider。
这意味着 provider 顺序本身就是优化策略。把高性能 provider 放前面,会直接改变 MatMul/Gemm 等热点算子的落点。
另一个实现细节是严格模式:--strict 会把 allow_missing_kernels 和 allow_unassigned_nodes 设为 false,在构图阶段就提前暴露不支持算子,避免运行时静默跳过。
3. 内存生命周期
这部分实现里同时做了“复用”和“及时释放”。
-
缓存映射复用
BuildCacheBinding会从张量名自动解析层号与 key/value 类型,构建 prefill 输出、decode 输入、decode 输出三者映射。CollectCacheState每轮把 context 里的最新 cache 张量拷到下一轮 feeds,形成稳定回流。 -
buffer pool 复用
CpuTensorAllocator优先从池里找“容量够且最小”的 buffer 复用,减少频繁分配释放带来的抖动。 -
最后使用点释放
Session 在初始化时预计算每个中间 tensor 的last_use_topo_index。
开启evict_dead_tensors后,执行到最后使用点就EraseTensor,并把底层 storage 回收到 allocator。
这三件事叠加后,长序列生成时的内存曲线会更平稳,也更容易定位异常增长。
小结
这条工程主线可以归纳成一句话:
GPT-2 生成性能的关键不在“单轮跑多快”,而在“历史状态能否正确复用”。
KV cache 提供的是一个可扩展的状态复用框架。
当原理、图结构和运行时分层三件事对齐后,优化和排错都会更可控。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)