Harness Engineering 是什么?同样的模型,为什么别人的Agent能跑95%成功率,你的却总“翻车”?
第一步:认识Harness Engineering的起源与背景
今天我们来聊一个最近在AI圈特别火,但很多人还没真正弄懂的词,Harness Engineering。如果你最近也在做Agent或者关注AI应用的落地,或多或少可能都会遇到这样的问题:为什么同样的模型,别人做出来的Agent可以连续跑很久,成功率很高,到了自己手里就总是差强人意呢?
很多人可能会想,是不是模型不够强?是不是提示词没调好?是不是RAG没调明白?当然这些都有影响。但是越来越多的团队最后发现,真正决定我们的系统能不能稳定地跑起来,往往不是模型本身,而是模型外面那套运行的系统。这套东西现在有了一个统一的名字,就叫 Harness。
为什么这个话题如此重要?
结合真实案例,因为我有个朋友他们团队当时在调一个Agent。他们团队之前已经做了很多努力,换上了最好的旗舰模型,提示词改了上百版,各种参数也调了不少。但在真实场景下效果还是不稳定,有的时候很聪明,有的时候又莫名的跑偏,任务的成功率不到65%。
后来我去帮他们看了一下,最后的改动最大的地方反而不是模型,也不是提示词。我的改进点在于:
- 任务是怎么拆的
- 状态是怎么管的
- 关键的步骤要怎么校验
- 失败之后要怎么恢复
结果新版本上线之后,还是同样的模型,同样的提示词,成功率拉到了90%以上。
当时这个朋友问我:“你到底改了什么呢?”说实话,那个时候我没有一个特别准确的词来形容。直到最近 Harness Engineering 这个概念越来越火,我才意识到我当时改的这些东西,本质上就是Harness。
第二步:理解AI工程的三次重心迁移
过去两年,AI工程其实经历了三次很明显的重心迁移:从 Prompt Engineering 到 Context Engineering,再到最近的 Harness Engineering。
表面上看好像只是换了几个新的名词,但如果你只是把它理解成术语流行史,那就完全低估它们了。这三个词分别对应了现在AI系统发展的三个阶段性问题:
- Prompt Engineering: 模型有没有听懂你在说什么?
- Context Engineering: 模型有没有拿到足够而且正确的信息?
- Harness Engineering: 模型在真实的执行力能不能持续地做对?
你会发现这些问题是一层一层往外扩张的。
2.1 第一阶段:Prompt Engineering(提示词工程)
在大模型刚火起来的时候,大家最直观的感受就是同一个模型,你换一种说法结果可能差很多。所以那个阶段大家都相信一件事情:模型不是不会,而是你没有把问题说明白。于是大家开始疯狂地研究提示词,什么角色设定、风格约束、分步引导输出格式等等。

- 为什么有效? 因为大模型本质上是一个对上下文非常敏感的概率生成系统。你给他什么身份,他很容易沿着那个身份去回答;你给他什么样的样例,他很容易沿着那个范式去补全。
- 本质: 提示词工程的本质不是命令模型,而是塑造一个局部的概率空间。这个阶段最重要的能力不是系统的设计,而是语言的设计。
2.2 第二阶段:Context Engineering(上下文工程)
但提示词工程很快就遇到了天花板,因为很多任务不是你说清楚就行,而是你真的得知道。比如你让模型分析一份公司的内部文档,回答一个产品的最新配置,按照一套非常长的规范去写代码。这个时候你会发现提示词写得再漂亮也替代不了事实本身。
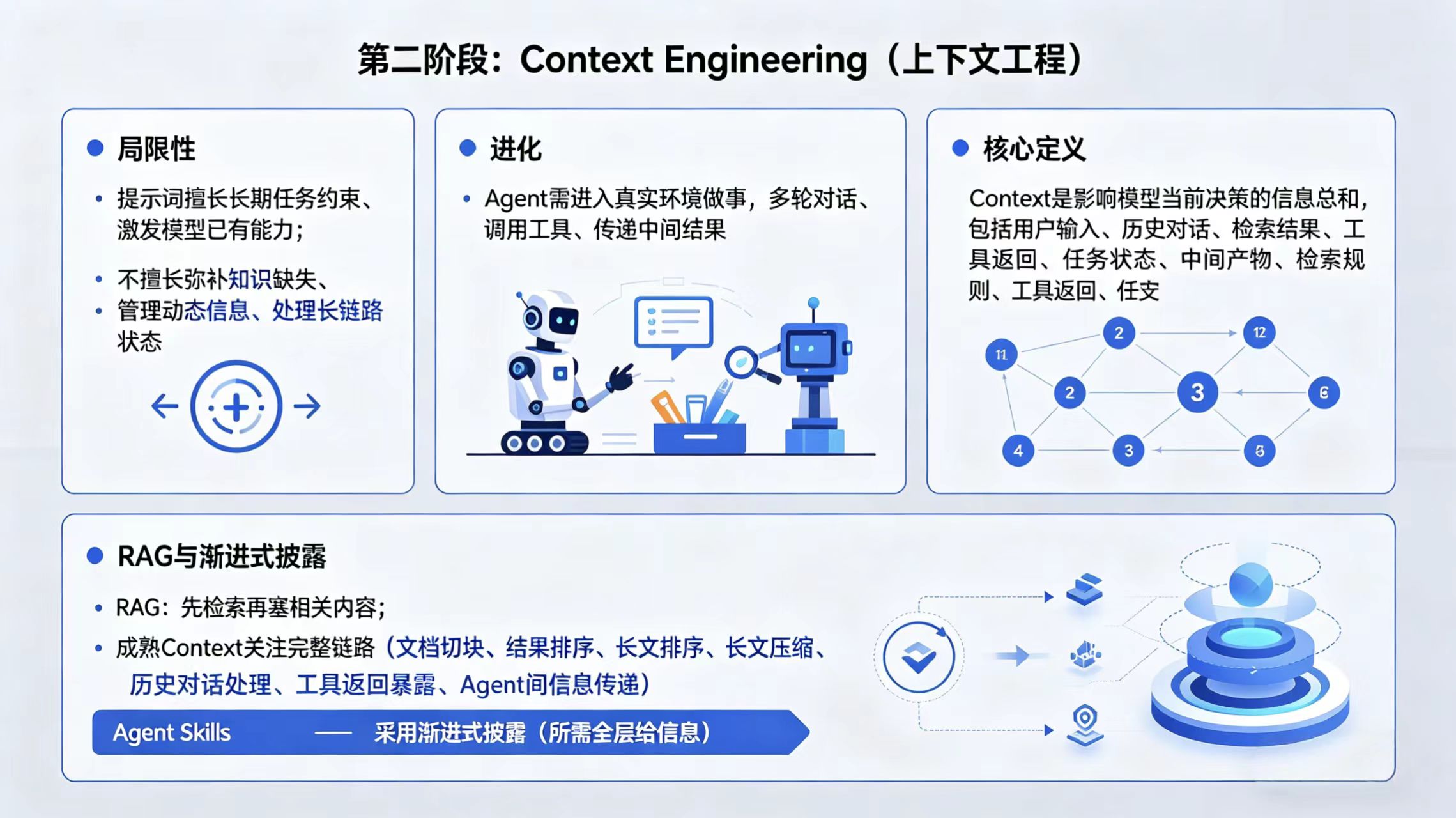
- 局限性: 提示词擅长的是长期任务约束、输出激发模型的已有能力,但是它不擅长凭空弥补缺失的知识、管理大量动态的信息、处理长链路任务里的状态。说白了,提示词解决的是表达的问题,不是信息的问题。
- 进化: 当Agent开始火了,模型不只是要回答问题,而是要进到真实的环境里面做事情。他要多轮对话,调浏览器、写代码、数据库这些工具,还要在多个步骤之间传递中间结果。
- 核心定义: Context Engineering的核心就变成一句话:模型未必是知道的,系统必须在合适的时机把正确的信息送进去。
这里的Context也不只是几段背景的资料,在工程的意义上,它代表了所有影响模型当前决策的信息的总和,包括:
- 用户的输入
- 历史对话
- 检索结果
- 工具返回
- 当前任务的状态
- 中间产物
- 系统规则
- 安全约束
RAG与渐进式披露
RAG(检索增强生成)也算是一个比较典型的实践。做法大家都知道,先检索再把相关的内容塞到上下文。但是真正成熟的Context Engineering,关注的肯定不只是检索,它关注的是整条完整的链路:
- 文档怎么切块?
- 结果怎么排序?
- 长文怎么压缩?
- 历史对话什么时候要保留,什么时候要摘要?
- 工具返回要不要全部暴露给模型?
- 多个Agent之间到底传原文、摘要还是结构化字段?
包括最近很火的Agent Skills,我觉得本质上也是上下文工程的高级实践。因为它解决了一个特别现实的问题:如果你把十几个不同的工具、工具的说明、所有的参数定义全部一上来就塞给模型,理论上模型会知道的更多,但是实践往往会更糟糕。为什么呢?因为上下文的窗口是非常稀缺的资源,信息一多注意力就会涣散。
所以Skill采用的是一个非常典型的思路,叫渐进式披露。不是一开始就把能力全部给模型看,而是只给他看最少量、最原始的信息。等他真正的要触发某些能力的时候,再把那部分的SOP、详细的参考信息、脚本动态地加进来。
这个思路其实非常重要,因为它告诉我们:上下文的优化不只是给的更多,而是按需给、分层给,在正确的时机给。
第三步:深入Harness Engineering的核心定义
但是上下文工程其实也不是终点。因为后来大家又发现了一个更麻烦的问题:就算信息给对了,模型也不一定能稳定地执行得正确。
- 他可能计划做得很好,但是执行跑偏了。
- 调了工具但理解错了返回结果。
- 在一个很长的链路里已经慢慢偏航了,但是系统却没有发现。
这个时候我们发现提示词和上下文其实主要解决都在输入侧的问题。提示词优化意图的表达,上下文优化的是信息的供给。但是复杂的任务里还有一个更难的问题:当模型开始连续行动的时候,谁来监督它、约束它和纠正它呢?
这个时候第三阶段来了。
Harness 这个词原本的意思是“马具、约束装置”的意思。放到AI系统里面,其实就是在提醒我们一件非常朴素的事情:当模型从回答问题走向执行任务,系统不只要能够负责喂信息,还要能够驾驭整个过程。这个就是Harness Engineering的出发点。
如果前两代工程关注的是怎么让模型更会“想”,那Harness更关注的就是怎么让模型别跑偏、跑得稳,出了错还能拉回来。
3.1 一个通俗的例子:客户拜访
假设你要派一个新人去完成一次很重要的客户拜访的工作:
- Prompt Engineering: 就是你要告诉他先把任务讲清楚。比如见面先寒暄,再介绍方案,再问需求,最后确认下一步。重点是把话说明白。
- Context Engineering: 你要告诉他把资料要准备齐全。比如说这个客户的背景,过往的沟通记录,产品的报价,竞品的情况,这次会议的目标。重点是把信息要给对。
- Harness Engineering: 如果这个会真的很重要,你还会继续做很多事情。比如说让他带着Checklist去,让他在关键的节点实时汇报,会后核实纪要和录音,如果发现偏差马上纠正,最后按照明确的标准去验收结果。
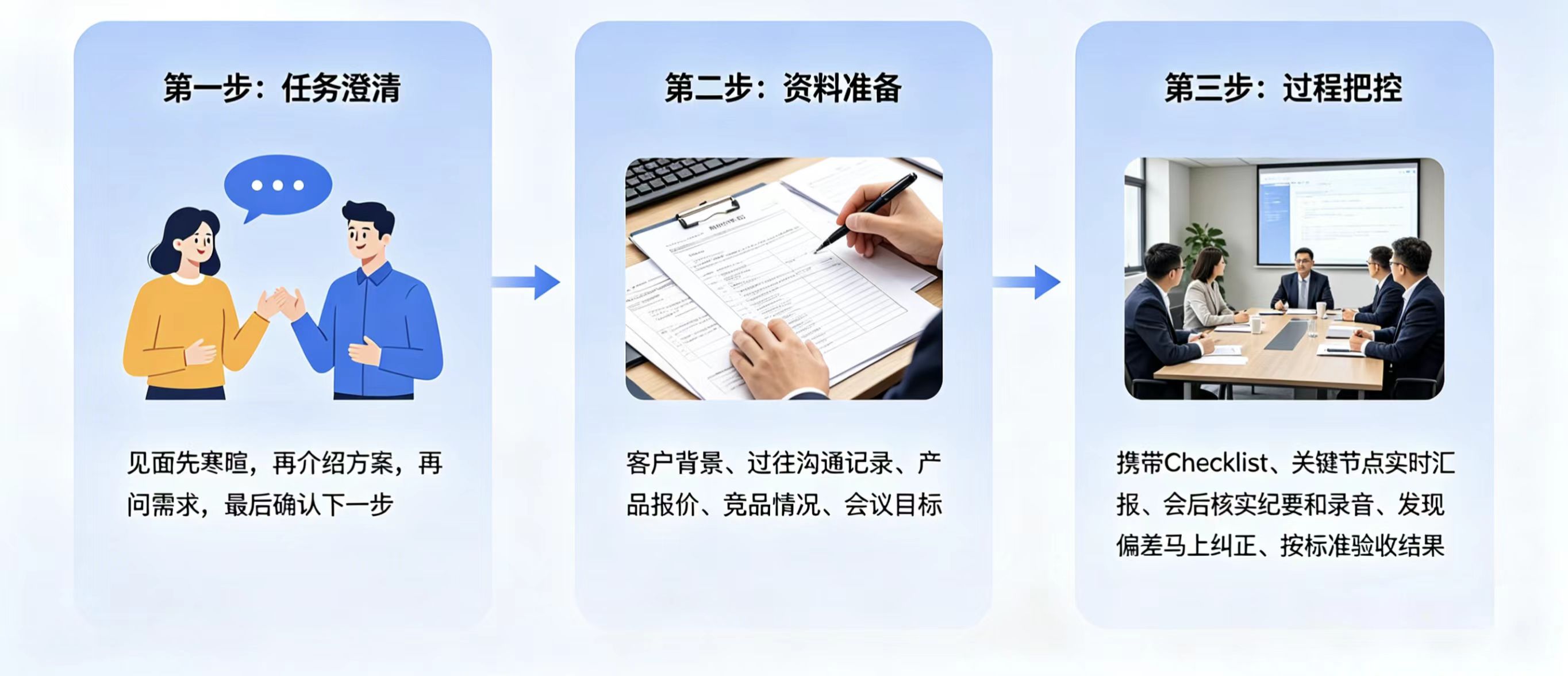
重点已经不是“说清楚”和“资料齐不齐”了,而是有没有一套持续观测、持续纠偏、最终验收结果的机制。
3.2 核心公式与六层架构
LangChain的工程师给Harness下了一个很典型的定义:
Agent = Model + Harness
翻译成人话就是:Harness = Agent - Model
在一个Agent的系统里面,除了模型本身以外,几乎所有能决定它能不能稳定交付的东西都可以算进Harness。
如果拆开来看,我自己会把一个成熟的Harness Engineering分成6层:
-
第一层:重新站在Harness的视角去看Context
模型能不能稳定发挥,很多时候不仅取决于它聪不聪明,而取决于它看到了什么。所以Harness的第一职责就是让模型能够在正确的信息边界内思考。
通常包括三件事情:- 角色的目标和定义: 模型要知道自己是谁,任务是什么,成功的标准是什么。
- 信息的裁剪和选择: 上下文不是越多越好,而是越相关越好。
- 结构化的组织: 固定的规则放在哪儿?当前的任务放在哪儿?任务运行的状态放在哪儿?外部的证据又放在哪儿?最好分层清楚。因为信息一旦乱掉,模型就很容易漏重点、忘约束,甚至自我污染。
-
第二层:工具系统
没有工具,大模型本质上还是一个文本预测器,会解释、会总结,但它接触不到真实的世界。一旦连上工具,模型才可以真正的做事儿,比如搜网页、读文档、写代码、调API等等。
但是Harness在这里做的不是简单的把工具挂上去,而是也要解决三个问题:- 给他什么工具? 工具太少能力不够,工具太多模型又会乱用。
- 什么时候该调用? 工具本来不需要查的时候别乱查,该查证的时候也别应答。
- 工具结果怎么重新喂回模型? 搜索回来的几十条结果不应该原封不动地塞回去,而是要提炼筛选,保持和任务的相关性。
-
第三层:执行编排
这一层解决的核心问题就是模型下一步该做什么。很多Agent的问题不是某一步不会,而是不会把所有的步骤给串起来。它会搜索,也会总结,也会写代码,但整个过程想到哪做到哪儿,最后交付出来一堆半成品。
所以一个完整的任务通常需要有这样的轨道:- 理解目标
- 判断信息够不够,不够继续补
- 基于结果继续分析
- 生成输出
- 检查输出,不满足要求就重新修正或者重试
这个时候你会发现这已经非常接近人在工作了。区别在于人靠经验,Agent靠Harness这套环境。
-
第四层:记忆和状态
没有状态的Agent每一轮都会像失忆一样,他不知道自己刚做了啥,也不知道哪些结论已经确认了,哪些问题还没解决。所以Harness还必须要管理状态。
这里我们要至少让它分清三类东西:- 当前任务的状态
- 会话中的中间结果
- 长期的记忆和用户偏好
这三类如果混在一起,系统会越来越乱。看清楚之后Agent才会像一个稳定的协作者。
-
第五层:评估和观测
这个就是很多团队最容易忽视的一层。很多系统其实不是生成不出来,而是生成完了之后根本不知道自己做的好不好。如果没有独立的评估和观测的能力,Agent就会长期停留在“自我感觉良好”的状态。
这一层通常包括:- 输出和验收环境的验证
- 自动的测试
- 日志和指标
- 错误的归因
也就是说,系统不仅是要会做,还要知道自己有没有真的能够做对。
-
第六层:约束、校验、失败和恢复
最后一层往往才是真正决定这个系统能不能上线的关键环节。因为在真实的环境里面,失败不是例外,而是常态。可能搜索不准,可能是API超时,也可能文档格式混乱,或者模型误解了任务。那如果没有恢复的机制,Agent每次出错就只能从头再来。
所以一个成熟的Harness一定要包括三件事情:- 约束: 哪些能做,哪些不能做。
- 校验: 比如输出之前、输出之后要怎么检查?
- 恢复: 失败之后咱们重试、切入静默模式、回滚到稳定的状态。
第四步:一线公司的真实实践(Anthropic & OpenAI)
说完概念,我们来看最有参考价值的部分,一线公司的真实实践。因为Harness这个词最近之所以突然火起来,不是大家在空谈这个方法论,而是很多公司都已经把它做进了产品和工程体系里面了。
- LangChain: 在底层模型完全不变的情况下,只通过改造和迭代Harness,就把他自家的智能体验从一个榜单上的排名直接从30开外杀到了前五。
- OpenAI: 依靠一个只有几名人类工程师的团队,用Agent从零构建了一个超百万行代码的生产级应用。100%的代码都是由Agent编写的,耗时只有纯人工开发的1/10。
- Anthropic: 也构建了一个可以完全自主编码的系统,只凭一句自然语言的需求,就能在无需人类干预的情况下连续运行几个小时,最后做出完整的游戏、完整的数字音频工作站。
4.1 Anthropic 的实践
首先他们在长程自主的任务上总结了两个特别典型的问题。
问题一:上下文焦虑
时间一长上下文越来越满,模型就开始丢细节,丢重点。甚至还会出现一种很有意思的现象,他好像知道自己快装不下了,于是开始着急的去收尾。
很多系统面对这种问题都会做Context Compaction,也就是把前面的历史上下文压缩一下再继续跑。但Anthropic发现对于一些模型来说,这还是不够的。因为压缩只是变短了不代表那种负担感真的消失了。
所以他们做了一件更激进的事情叫Context Reset:不是在原上下文里面继续压,而是换了一个非常干净的新的Agent把工作交接给他。这个思路很像什么呢?特别像工程里面遇到内存泄露之后,不是继续清缓存,而是直接重启整个进程再恢复状态。这个其实就是一种非常典型的Harness设计。
问题二:自评失真
首先模型自己干活,再让他自己给自己打分,往往会是乐观的。那尤其是在设计、体验、产品完整度这一类没有标准答案的问题上,偏差是更明显的。
所以他们采用了一个非常关键的思路:把干活的人和验收的人分开。他们是这样拆分的:
- Planner: 负责把模糊的需求扩展成完整的规格。
- Generator: 负责逐步地去实现。
- Evaluator: 负责像QA一样去真实的测试。
更关键的是这个Evaluator它不只是会看代码,而是会真实的操作页面,看具体的交互,检查实际的结果。也就是说这不是一个抽象的审查,它是一个带具体环境的验证。
这个事情非常重要,因为它背后是一个很明确的工程原则:生产验收必须分离。只要评估者足够独立,系统就能形成一个真正的有效循环:生成 → 检查 → 修复 → 再检查。
4.2 OpenAI 的实践
OpenAI在这方面给我的感觉是他们重新定义了工程师在Agent时代的工作。他们做了一个非常有意思的思路:人类在这个环境里面不需要写一行的代码,人类只需要去负责设计环境。
具体来说说,工程师的工作变成了三件事情:
- 把产品目标拆解成Agent能理解的小任务。
- Agent失败的时候,不是让他更努力一点,而是问环境里面缺了什么能力。
- 最后建立反馈的链路,让Agent真正的能够看到自己的工作结果。
这句话我是非常认同的:当Agent出了问题的时候,修复方案几乎从来不是要更努力一点,而是确定它缺了什么样的结构性的能力。这个其实也是典型的Harness思维。
OpenAI还有一个特别典型的事件,也是渐进式披露。他们早期犯过一个很多团队都会犯的错误,写了一个巨大的Agent Prompt,把所有的规范、框架、约定全部塞进去了。结果Agent更糊涂了,因为上下文窗口是一个稀缺的资源,塞得太满其实等于什么都没说。
那后来他们怎么改的呢?把Agent Prompt变成一个目录页,页面只保留核心的索引。更详细的内容拆到架构文档、设计文档、执行计划、质量评分、安全规则这些具体的子文档里面去了。那Agent的先看目录,需要的时候再钻进去。这个时候我们会发现,这个和我们前面说的Skills本质上是一个思路,不是一次性全给,而是按需暴露。
还有一个实践就是OpenAI不只是让Agent写代码,还会让Agent看见整个应用。因为产出速度一旦上来,瓶颈其实就不再是写,而是验了。那人类根本是验不过来的,所以他们让Agent自己去验,怎么验呢?
- 首先接浏览器,能截图、点页面,能模拟用户的真实操作。
- 然后去给Agent接日志系统和指标系统,让他能够查Log、查监控。
- 最后每个任务都独立隔离的环境在跑,互不影响。
结果就是Agent不再是写完代码就说是写完了,而是真正的可以跑起来看结果,发现Bug、修Bug、再验证。这个其实就是Harness里非常完整的一套工具系统、执行编排、评估和观测、约束和恢复。
还有一点需要注意的是,OpenAI不只会靠人类在最后的Code Review环节去兜底质量。因为Agent的提交速度太快了,人类是盯不过来的。所以他们把很多资深工程师的经验直接写成了系统规则。比如模块怎么分层,哪一层不能依赖哪一层,什么情况下必须拦截,发现问题之后应该怎么修。重点是这些规则不只是负责报错,而是会把怎么修也一起反馈给Agent,进入下一轮的上下文。那你会发现这已经不是传统意义上的代码规范了,而是一套可持续运行的自动治理系统。这个也是Harness的典型形态。
第五步:总结与展望
最后我们总结一下:
- Prompt Engineering 解决的是怎么把任务讲清楚。
- Context Engineering 解决的是怎么把信息都给对。
- Harness Engineering 解决的是怎么让模型在真实的执行中持续做对。
所以Harness不是在取代Prompt,也不是在取代Context,它是在更大的系统边界上把前两者都包含进来。
- 当任务还是简单的单轮生成的时候,Prompt是很重要的。
- 当任务开始依赖外部知识去运行信息的时候,Context就很关键了。
- 当模型真的进入了长链路、可执行、低容错的真实场景里面,Harness几乎就是不可避免的。
这也是为什么同样的模型在不同的产品里面表现差距会这么大了。因为真正决定上限的可能是模型,但是真正决定能不能落地、能不能稳定交付的就是Harness。
到了这个阶段,我们也看清了一个现实:AI落地的核心挑战正在从“让模型看起来更聪明”转向“让模型在真实世界里稳定的工作”。如果你最近也在做Agent,我觉得这件事情非常值得你趁早想明白。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)