大模型后训练全解:SFT、RLHF/PPO、DPO 的原理、实践与选择
本文覆盖范围:SFT 监督微调、RLHF(PPO)强化学习对齐、DPO 直接偏好优化,以及它们的变体、工具链、实战代码和选择决策。结合 InstructGPT、LLaMA 2/3、Zephyr、DeepSeek-R1、Qwen3 等真实案例说明。
一、为什么需要后训练(Post-Training)?
预训练(Pre-Training)让一个语言模型学会了"下一个 token 是什么"——它掌握了语言规律、广博的世界知识、甚至初步的推理能力。但预训练的优化目标是最大化训练语料的对数似然,这意味着模型学会的是"互联网平均水平的文字接龙",而不是"对人类有帮助、无害、诚实的回答"。
给一个纯预训练模型发送"帮我写一封道歉信",它可能会继续生成"帮我写一封道歉信的示例……"或者索性开始胡说八道——因为训练数据里这类格式的文本不少。它不理解"用户"和"助手"的角色关系,不知道什么是有用的回答,也不懂得拒绝有害请求。
后训练(Post-Training)正是解决这个问题的一套流程,其核心目标是:
- 行为对齐(Behavioral Alignment):让模型按照指令行事,而不只是续写文本
- 偏好对齐(Preference Alignment):让模型的输出符合人类的价值偏好(有用、无害、诚实)
- 能力激活(Capability Activation):激发模型在推理、代码、数学等特定领域的潜力
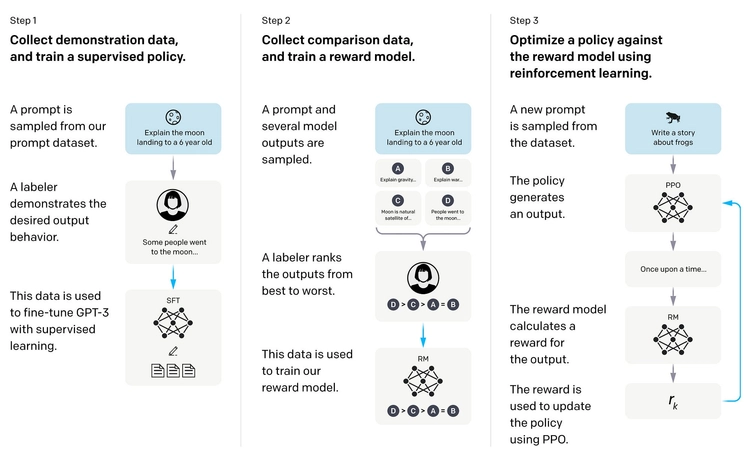
一个完整的后训练历史可以分为三个阶段:第一阶段,InstructGPT 提出了 SFT + RLHF 的标准流程,让模型能够遵循指令,代表模型是 GPT-3.5 和早期 ChatGPT;第二阶段,DPO 通过消除独立奖励模型降低了对齐的复杂度,让中小团队也能做对齐,代表模型是 Zephyr、Intel NeuralChat、早期 LLaMA 微调版本;第三阶段,DeepSeek-R1 证明了纯 RL 能产生突破性推理能力,GRPO 成为标准,代表模型是 DeepSeek-R1、QwQ、Kimi k1.5。
理解这三个阶段,就等于理解了整个后训练技术的演化逻辑。下面我们逐一深入。
二、SFT:监督微调,一切的起点
2.1 什么是 SFT?
SFT(Supervised Fine-Tuning,监督微调)是后训练的第一步,也是最直观的一步:给模型看大量高质量的(指令,回答)对,用标准的交叉熵损失训练模型去模仿这些示范回答。
从优化角度,SFT 的损失函数是:
其中 是指令(prompt),
是期望的回答,
是模型。这与预训练的语言建模损失在形式上完全一样,差别只在于:SFT 的数据是精心设计的高质量(指令, 回答)对,而且只在回答部分计算 loss,不对指令部分计算 loss(让模型学会"如何回答",而不是"如何提问")。
这一点在代码上体现为:将指令部分的 token 的 label 设置为 -100(PyTorch 会忽略 label=-100 的位置),只让模型在回答 token 上反向传播。
2.2 SFT 数据的格式
现代大模型的 SFT 数据通常用 ChatML 格式组织多轮对话:
<|im_start|>system
你是一个有帮助的助手。<|im_end|>
<|im_start|>user
帮我解释一下什么是黑洞。<|im_end|>
<|im_start|>assistant
黑洞是宇宙中一种极端的天体,其引力强到连光都无法逃脱……<|im_end|>
这种格式明确区分了系统提示、用户输入和模型回答,让模型学会角色扮演。
2.3 SFT 用在哪些模型中?
Stanford Alpaca(2023):最早的开源 SFT 实验之一。用 GPT-3.5 生成的 52K 条指令-回答对,对 LLaMA-7B 做 SFT,就能得到一个基本能对话的模型。成本极低但效果惊人,开启了"用 AI 生成 SFT 数据"的先河。
InstructGPT(OpenAI, 2022):SFT 是 RLHF 三阶段流程的第一步。先用人工标注的约 13000 条(prompt, 演示回答)对做 SFT,得到一个基础对话模型,再继续做 RLHF。
LLaMA 2-Chat(Meta, 2023):在经过 SFT 预热后,再做 RLHF(迭代式 PPO + 拒绝采样)。SFT 数据来自 Meta 内部的人工标注对话。
DeepSeek-R1-Distill 系列:通过对 LLaMA 3 和 Qwen2.5 基座模型,用 DeepSeek-R1 生成的 80 万条长链式推理(CoT)数据做 SFT,直接蒸馏出了具备推理能力的小模型——完全不用 RL。这说明 SFT 在数据质量足够高时,能够有效传递大模型的推理模式。
2.4 SFT 的局限性
SFT 的本质是模仿学习(Imitation Learning),它有两个根本局限:
第一,覆盖范围限于训练数据。模型只能学到训练数据中展示过的行为模式。对于训练数据没有涉及的新场景,SFT 模型的泛化能力有限。
第二,无法表达"哪个更好"。SFT 给模型展示的是"正确"答案,但没有展示"哪种正确答案更好"。对于同一个问题,简洁清晰的回答和冗长啰嗦的回答,在 SFT 的 loss 里差别不大——只要都是"正确"的。
第二个局限正是 RLHF 和 DPO 要解决的问题。
2.5 用 TRL 的 SFTTrainer 做实战
HuggingFace TRL 库提供了 SFTTrainer,封装了 SFT 的完整流程:
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
# LoRA 配置:只训练部分参数,节省显存
lora_config = LoraConfig(
r=64,
lora_alpha=128,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 加载对话数据集(ChatML 格式)
dataset = load_dataset("trl-lib/Capybara", split="train")
# SFT 训练配置
sft_config = SFTConfig(
output_dir="./sft_output",
num_train_epochs=3,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=2e-4,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
bf16=True,
logging_steps=10,
save_steps=500,
max_length=2048,
# 关键:只在 assistant 的回答部分计算 loss
dataset_text_field="messages",
)
trainer = SFTTrainer(
model=model,
args=sft_config,
train_dataset=dataset,
peft_config=lora_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model("./sft_final")
对于自定义数据集,数据格式需要包含 messages 字段,每条样本是一个对话列表:
# 自定义数据集格式
{
"messages": [
{"role": "system", "content": "你是一个专业的法律顾问。"},
{"role": "user", "content": "合同违约怎么处理?"},
{"role": "assistant", "content": "合同违约的处理方式包括……"}
]
}
TRL 的 SFTTrainer 会自动检测对话格式,应用对应的 chat template,并将 assistant 之外的 token 的 label 设为 -100。
三、RLHF:用人类反馈做强化学习
3.1 为什么需要 RLHF?
SFT 之后,模型已经能按格式回答问题了,但回答质量的细微差别——是否更有帮助、是否更安全、语气是否合适——SFT 数据难以精确刻画。
这里有一个著名的洞察,来自 InstructGPT 论文:与其让标注员写出"完美答案"(这很难),不如让他们比较两个答案哪个更好(这相对容易)。人类擅长做评判,不擅长从头创作完美示范。
RLHF(Reinforcement Learning from Human Feedback)正是利用了这一点:收集人类对模型输出的偏好比较,训练一个奖励模型来量化这种偏好,然后用强化学习(通常是 PPO)来优化模型使其最大化奖励模型的得分。
3.2 RLHF 的三个阶段
阶段一:SFT(已覆盖)
预训练模型 → SFT 微调 → 得到 ,作为后续的初始策略和参考模型。
阶段二:训练奖励模型(Reward Model, RM)
收集偏好数据:对同一个 prompt,让 SFT 模型生成多个回答,让人工标注员对这些回答进行排序(哪个更好)。这个排序数据被整理成对 ,其中
是被偏好的(chosen)回答,
是被拒绝的(rejected)回答。
奖励模型的训练目标是:让 ,即给好的回答打更高的分。标准做法是在 SFT 模型的基础上添加一个回归头(regression head),训练损失为:
这是一个 Bradley-Terry 模型——只关心两个回答奖励分的相对大小,不需要绝对分数。
阶段三:用 PPO 做强化学习
有了奖励模型,现在把语言模型的生成过程视为一个强化学习问题:
- 状态(State):当前的 prompt 和已生成的 token 序列
- 动作(Action):生成下一个 token(词表大小的离散动作空间)
- 奖励(Reward):只在序列结束时给予一次奖励(来自奖励模型的评分)
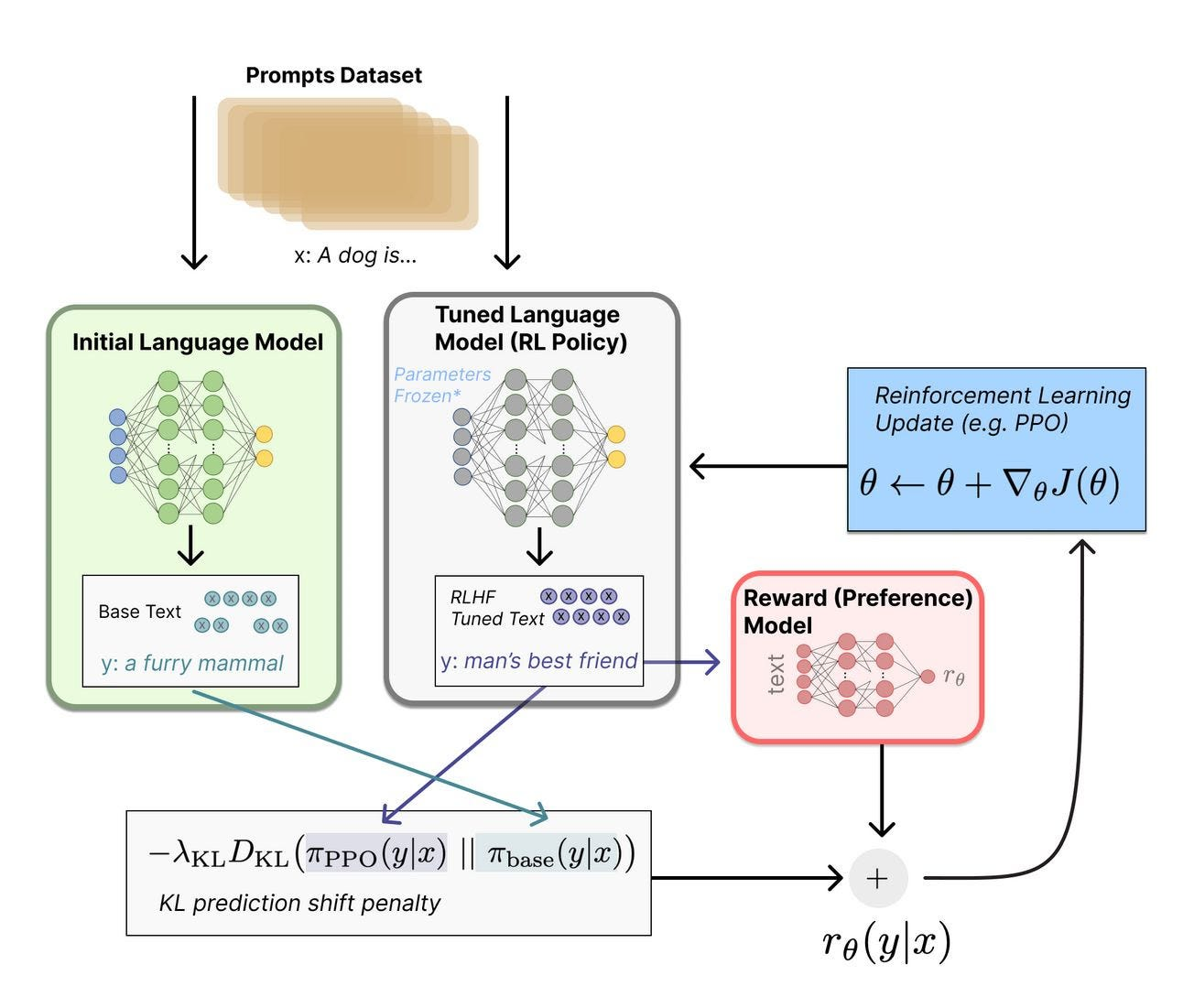
问题是奖励函数不连续、序列很长(稀疏奖励),直接做梯度优化困难。PPO 通过重要性采样和 clip 操作解决了训练稳定性问题,同时加入 KL 散度约束防止模型偏离 SFT 版本太远。在3.3中详细补充解释了使用PPO的重要性。
完整的 PPO 优化目标是:
其中 是 KL 惩罚系数。KL 项有两个作用:防止奖励黑客(reward hacking,模型学会用奇怪的方式骗过奖励模型而不是真正有用);防止模型能力退化(偏离 SFT 太远会丢失已学到的知识)。
3.3 语言模型的 RL 难题,以及 PPO 如何解决它
注:本部分基于你略懂强化学习基础知识,若理解困难可先学习RL基本原理。
要理解为什么 PPO 是 RLHF 的标准算法,需要先搞清楚"直接用 RL 优化语言模型"面临哪些根本性困难。
困难一:动作空间是离散的,无法直接求梯度
强化学习的目标是最大化期望累积奖励。在连续动作空间(比如控制机器人关节角度)里,可以直接对动作求梯度,用梯度上升来改进策略。
但语言模型的"动作"是从词表中采样一个 token——这是一个离散的采样操作。离散采样不可微,梯度无法通过采样操作反向传播回模型参数。这意味着你没法用一个简单的 loss.backward() 来更新模型,RL 必须用策略梯度(Policy Gradient)方法:通过"好的回答就增大其概率,坏的回答就减小其概率"这样的估计来间接更新参数。
困难二:稀疏奖励
一个完整的回答可能有几百到几千个 token。但奖励模型只在整条回答生成完毕之后,对整个回答打一个分数——这就是稀疏奖励(Sparse Reward)。
"稀疏"的意思是:模型在生成过程中,对每一步(每个 token)的决策都是在"盲飞",没有任何即时信号告诉它这一步走得好不好,直到最后才得到一个全局评分。举个极端的例子:生成了 500 个 token,奖励模型打了 6 分。你不知道是前 100 个 token 写得好、还是后 100 个,还是某个关键转折点决定了这个分。
这种信用分配(credit assignment)问题让训练极其困难——模型很难从稀疏信号中学到"哪一步导致了好结果"。
困难三:每步 policy 更新后数据立即过期
策略梯度方法要求用"当前策略"生成的数据来计算梯度更新当前策略(on-policy)。这意味着每次更新模型参数之后,刚才生成的那批数据就作废了,必须重新采样——计算效率极低。
更糟的是,如果你想多次利用同一批数据做几步梯度更新(提升数据效率),每更新一步,当前策略就和生成数据时的旧策略之间的差距就大了一步。如果差距太大,梯度估计就会偏差很大,甚至导致策略崩溃(更新步子太大,模型直接退化)。
PPO 如何解决这三个问题
PPO(Proximal Policy Optimization,近端策略优化)是一个策略梯度算法,专门为解决上面第三个问题——"如何安全地多次利用旧数据"——而设计的,同时配合其他机制处理前两个问题。
重要性采样(Importance Sampling):让旧数据可以复用
核心思路是:用当前策略 的期望奖励来表达,但实际采样来自旧策略
,通过乘以一个修正系数(重要性权重)来补偿两者之间的分布差异:
这个比值 就是重要性权重。当
时,说明当前策略比旧策略更倾向于生成这个 token;
则相反。通过乘以这个比值,就可以用旧数据来近似估计当前策略的梯度。
但问题是:如果 和
差距太大,这个比值可以变得非常大或非常小,导致梯度估计方差爆炸,更新极不稳定。
Clip 截断:给更新幅度加保险
PPO 的核心创新就在这里——对重要性权重进行截断(clip),防止单步更新幅度过大:
其中 通常取 0.1 或 0.2。这个公式的含义是:
- 如果
(这个 token 是好的,应该增大概率),当
时,梯度被截断——不允许当前策略比旧策略在这个方向上走太远
- 如果
(这个 token 是坏的,应该减小概率),当
时,同样截断
取 min 的目的是:总是选择"更保守"的那个估计,确保策略更新是悲观的而非激进的。这个简单的截断操作使得 PPO 在实践中极其稳定,即便在每批数据上做多次梯度更新也不容易崩溃。
优势函数(Advantage):解决稀疏奖励的信号分配
策略梯度不能直接用原始奖励 ,而是用优势函数
。优势函数的定义是:在状态
下采取动作
的实际回报,与该状态下平均期望回报之差:
其中 是价值函数(当前状态的期望回报),
是采取了动作
之后的实际累积回报。
意味着这步动作比平均水平好,应该增强;
意味着比平均水平差,应该抑制。
用优势而非原始奖励的好处是:减少了梯度估计的方差(即使奖励绝对值很大,优势函数代表的是相对增益,更稳定),并且通过价值函数 对奖励信号做了时序上的分解,缓解了稀疏奖励带来的信用分配问题。
但要计算 ,你需要一个能估计"当前序列接下来能拿多少分"的网络——这就是 Critic 模型的来历。
为什么 PPO 需要四个模型
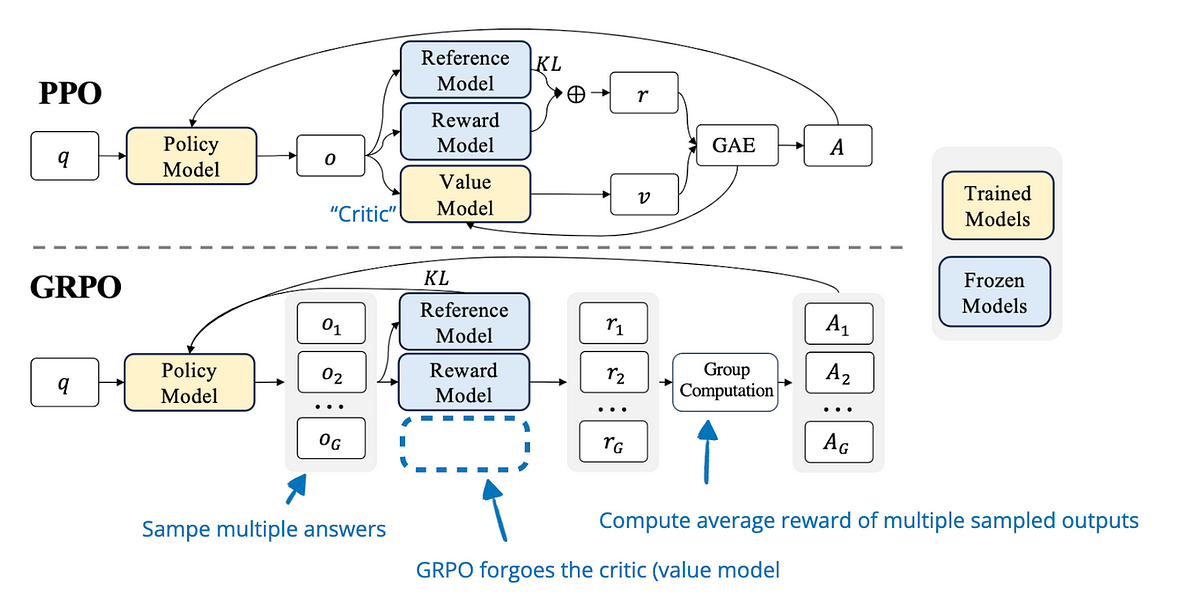
这里从头捋清楚。在进入 PPO 阶段之前,已经存在三个模型:
① SFT 模型(Reference Model,参考模型)
SFT 阶段训练完的模型,在 PPO 阶段被冻结,不参与训练。它的作用是提供 KL 散度约束的基准——PPO 在优化策略模型时,会惩罚策略模型与 SFT 模型之间的 KL 散度过大。这防止了奖励黑客:如果策略模型可以无限偏离 SFT 模型,它可能会学会用乱码或奇怪格式来骗奖励模型打高分,同时完全丧失语言能力。冻结的参考模型是一个"语言能力的锚点"。
② 奖励模型(Reward Model,RM)
用人类偏好数据(chosen/rejected 对)单独训练的一个打分网络,在 PPO 阶段也被冻结。它负责对策略模型生成的每条完整回答给出一个标量分数,这个分数就是稀疏奖励信号的来源。没有奖励模型,PPO 就不知道往哪个方向优化。
这两个模型(参考模型和奖励模型)加在一起,就是 RLHF 体系在进入 PPO 前就需要准备好的部分。
③ Actor 模型(策略模型,Policy)
这是我们真正要训练的目标模型,初始化自 SFT 模型,在 PPO 过程中持续更新。它负责接收 prompt,生成回答,参数不断被梯度更新。
④ Critic 模型(价值模型,Value Model)
如上所述,Critic 是 PPO 引入的额外模型,负责估计当前状态(已生成的序列)的期望未来奖励 ,用于计算优势函数
。没有 Critic,PPO 无法计算优势,只能用原始奖励做策略梯度,方差极大,训练极不稳定。
Critic 通常初始化自奖励模型(因为奖励模型已经理解了"什么样的输出是好的"),并在训练过程中与 Actor 一起更新。在实现上,Critic 的大小通常与 Actor 相同——因为它需要处理同样的长序列输入,同样需要深度理解语义。
四个模型的协作流程是这样的:
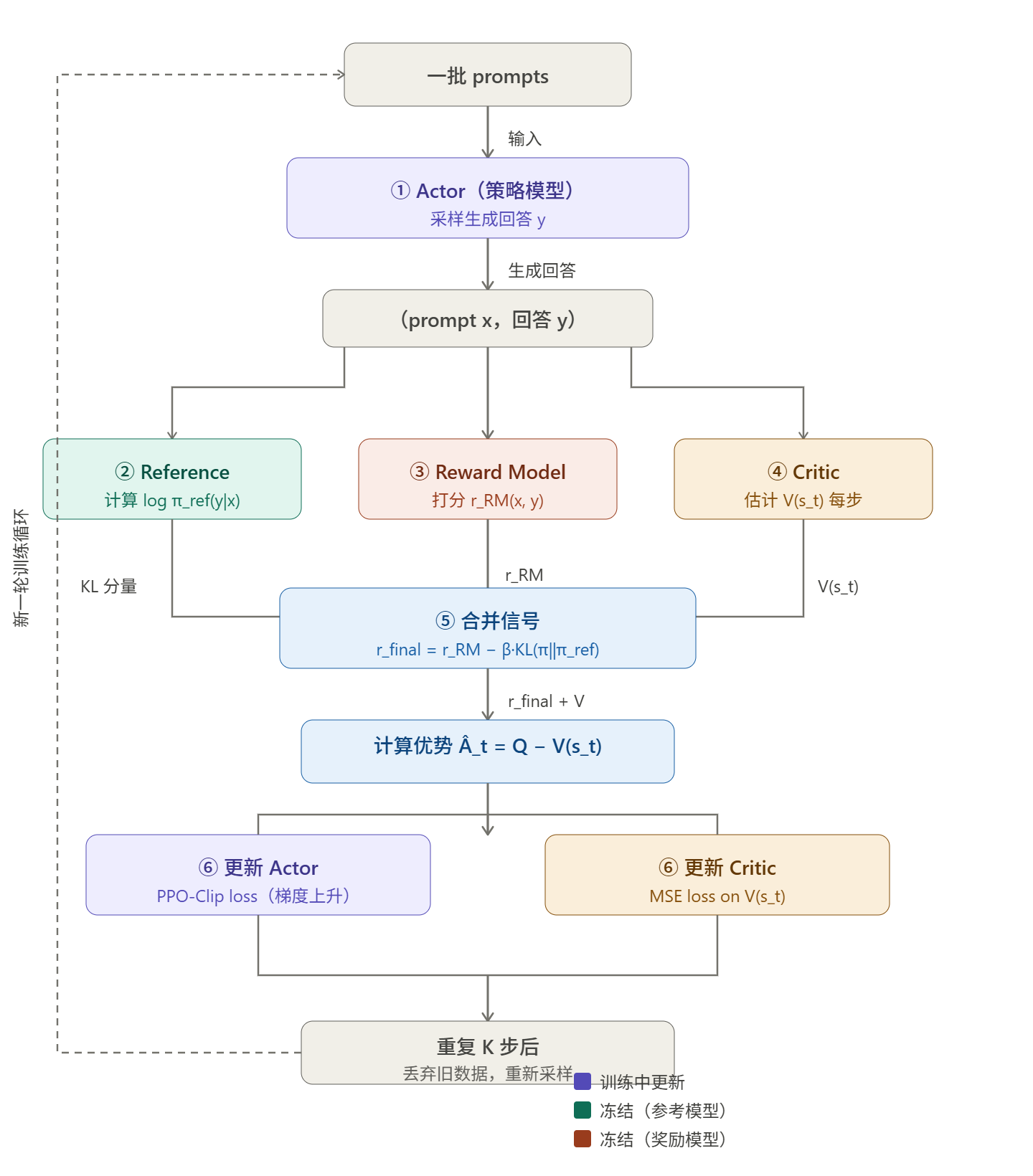
这四个模型在训练时通常需要同时保持在 GPU 内存中(或通过 offload 换出),这正是 PPO-RLHF 内存开销极大的根本原因。对于一个 7B 的 Actor,在 BF16 下约需 14GB;Critic 同样 14GB;Reference 14GB;RM 14GB——合计约 56GB,还不算梯度、优化器状态、激活值。这就是为什么完整的 PPO-RLHF 需要多卡甚至大规模集群,也是 DPO(只需 Actor + Reference,两个模型)和 GRPO(消除 Critic)被广泛采用的核心动机。
3.4 一个具体例子:PPO 在语言模型中的每一步
光看公式很难理解,我们用一个真实场景把上面所有机制串起来走一遍。
场景设定
用户问:"如何快速入睡?"
Actor 模型对同一个 prompt 采样生成了两条回答:
回答 A:"建议你睡前一小时放下手机,保持房间黑暗和凉爽,可以尝试4-7-8呼吸法:吸气4秒,屏住7秒,呼气8秒。"
回答 B:"你可以试试喝热牛奶,虽然科学上还没有定论,但很多人觉得有用,也可以数羊,总之就是放松。"
假设奖励模型对回答 A 打了 8.2 分,对回答 B 打了 4.1 分。
第一步:Actor 采样,旧策略生成数据
当前的 Actor(参数为 )生成了这两条回答,同时记录下每个 token 的生成概率。例如回答 A 中"4-7-8呼吸法"这个片段,旧策略的生成概率为
(这类专业术语本来概率就不高)。
第二步:奖励模型打分,得到稀疏奖励
奖励模型读入完整的(prompt + 回答),输出一个标量:A 得 8.2,B 得 4.1。
注意"稀疏"体现在这里:回答 A 有 40 个 token,奖励模型只给整条回答一个分,不告诉 Actor 是哪个 token 起了决定性作用。是"4-7-8呼吸法"这个具体建议加分了,还是整体语气加分了?模型不知道。
第三步:Critic 估计每一步的价值,计算优势函数
Critic 模型来解决"稀疏"问题。它对回答 A 的每个生成时刻估计价值 ——即"从当前这个位置继续生成下去,预计能拿多少分"。
举个例子,当 Actor 已经生成了"建议你睡前一小时放下手机,保持房间黑暗和凉爽,"之后,Critic 估计 ——已经是一个不错的开头,预计能拿 7.5 分。
此后 Actor 生成了"可以尝试4-7-8呼吸法",这一片段生成完之后 Critic 重新估计 ,说明加上这个具体建议之后整体质量提升了。
于是这个动作(生成"4-7-8呼吸法")的优势为:
优势为正,说明这个 token 比 Critic 的平均预期要好,PPO 应该增大它的概率。
反过来,对于回答 B,当 Actor 生成了"虽然科学上还没有定论"这个片段时,Critic 估计价值从 5.0 跌到了 4.2:
优势为负,说明这个表达削弱了整体质量,PPO 应该减小它的概率。
这就是 Critic 把一个整体奖励"分解"到每个 token 的机制——不是均匀分配,而是通过前后价值差来推断每一步的贡献。
第四步:重要性采样,复用旧数据做多步更新
现在已经有了每个 token 的优势 ,可以开始更新 Actor 了。但这里有一个问题:我们希望对同一批数据做 K 次梯度更新来提升数据效率,而每更新一次 Actor 的参数就从
变成了
,后续的梯度计算用的策略和生成数据时的策略就不一样了。
重要性采样的作用就是修正这个偏差。对于回答 A 中"4-7-8呼吸法"这个 token:
假设第一次更新后,新 Actor 对这个 token 的概率从 0.03 提升到了 0.045,则:
这说明新策略比旧策略更倾向于生成这个 token,方向是对的(因为 ),但幅度有点大。
第五步:PPO Clip 截断,防止更新步子太大
取 ,PPO 的 Clip 机制会检查:
超出了截断范围!此时 Clip 把梯度贡献限制在 ,而不是
。
为什么要这么做? 假设没有 Clip,第一步更新把"4-7-8呼吸法"的概率从 0.03 推到了 0.045,第二步又从 0.045 推到了 0.09,几步下来这个 token 的概率变得极高,模型开始在所有问题的回答里都强行塞入"4-7-8呼吸法"——这就是无约束 RL 的过拟合,俗称"奖励黑客"。Clip 保证每次更新最多走"一小步",整体训练在多步之间保持稳定。
对于回答 B 中"虽然科学上还没有定论"这个 token,,PPO 会减小它的生成概率。如果新策略把这个 token 的概率压得太低(
),同样会被截断,防止模型矫枉过正、把这类表达完全抹去。
第六步:KL 约束兜底,防止整体退化
除了 Clip,RLHF 还在奖励上额外加了一个 KL 惩罚项:
假设经过若干步更新后,Actor 在回答"如何入睡"时已经非常激进——它开始在所有问题上都用类似回答 A 的口吻输出大量专业术语,同时忘记了 SFT 阶段学会的礼貌、安全拒绝等行为。这时 KL 散度 会变得很大,KL 惩罚项拉高了等效损失,自动压制 Actor 偏离 SFT 版本过远。
两道保险的分工是:Clip 在每一步的 token 级别防止单步过大;KL 约束在整个训练过程的分布级别防止长期漂移。两者一起,才是 PPO 在语言模型上训练稳定的根本原因。
把这个例子和三个困难对照起来
| 困难 | 体现在例子中 | PPO 的解法 |
|---|---|---|
| 离散动作不可微 | "4-7-8呼吸法"是采样出来的,无法直接对采样求梯度 | 策略梯度:用 |
| 稀疏奖励 | 整条回答只有一个分数 8.2,不知道哪个 token 贡献了多少 | Critic 估计 |
| 数据立即过期 | 生成数据时是 |
重要性采样修正分布差异 + Clip 截断防止比值过大 |
3.5 真实案例:InstructGPT 和 LLaMA 2
InstructGPT(OpenAI, 2022):标准 RLHF 三阶段流程的教科书案例。用约 33000 个偏好比较对训练奖励模型,用 PPO 对策略模型做 RL 优化。论文中著名的结论是:经过 RLHF 的 1.3B 参数模型在人类偏好评分上超过了未经 RLHF 的 175B 参数模型——说明对齐的重要性远超单纯的参数规模。
LLaMA 2-Chat(Meta, 2023):Meta 的 LLaMA 2-Chat 模型通过对大规模助手风格语料做 SFT,然后用迭代式 RLHF 训练。训练了独立的有用性和安全性奖励模型,使用来自 Meta 自身聊天数据集的数百万人类偏好比较。RLHF 在拒绝采样和 PPO 步骤之间交替进行。
3.6 RLHF 的局限性
RLHF/PPO 的工程复杂度和计算成本极高,而且存在以下问题:
奖励黑客(Reward Hacking):模型学会了取悦奖励模型而不是真正有用。例如,某些奖励模型喜欢长回答,模型就会不断生成冗余内容来刷高分,而不是给出简洁有效的回答。
训练不稳定:PPO 本身就对超参数敏感,在语言模型这种极大的动作空间(词表大小的动作)上更难调优。
数据收集成本:收集高质量的人类偏好标注数据成本高昂,且难以规模化。
这些局限性催生了 DPO 的出现。
四、DPO:把 RLHF 重新表述为分类问题
4.1 DPO 的出发点:RLHF 能不能更简单?
回顾 RLHF 的流程:先训练一个奖励模型,再用 PPO 让语言模型最大化奖励。这套流程需要四个模型同时在显存中,训练极不稳定,超参数难调。
DPO 的核心问题是:奖励模型和 PPO 这两步,真的缺一不可吗?
答案是——在特定假设下,不需要。DPO 通过一系列数学推导,证明了可以跳过奖励模型的显式训练和 PPO 的 RL 循环,直接用偏好数据端到端地优化语言模型本身。
要理解这个推导,需要先把 RLHF 的目标写清楚。
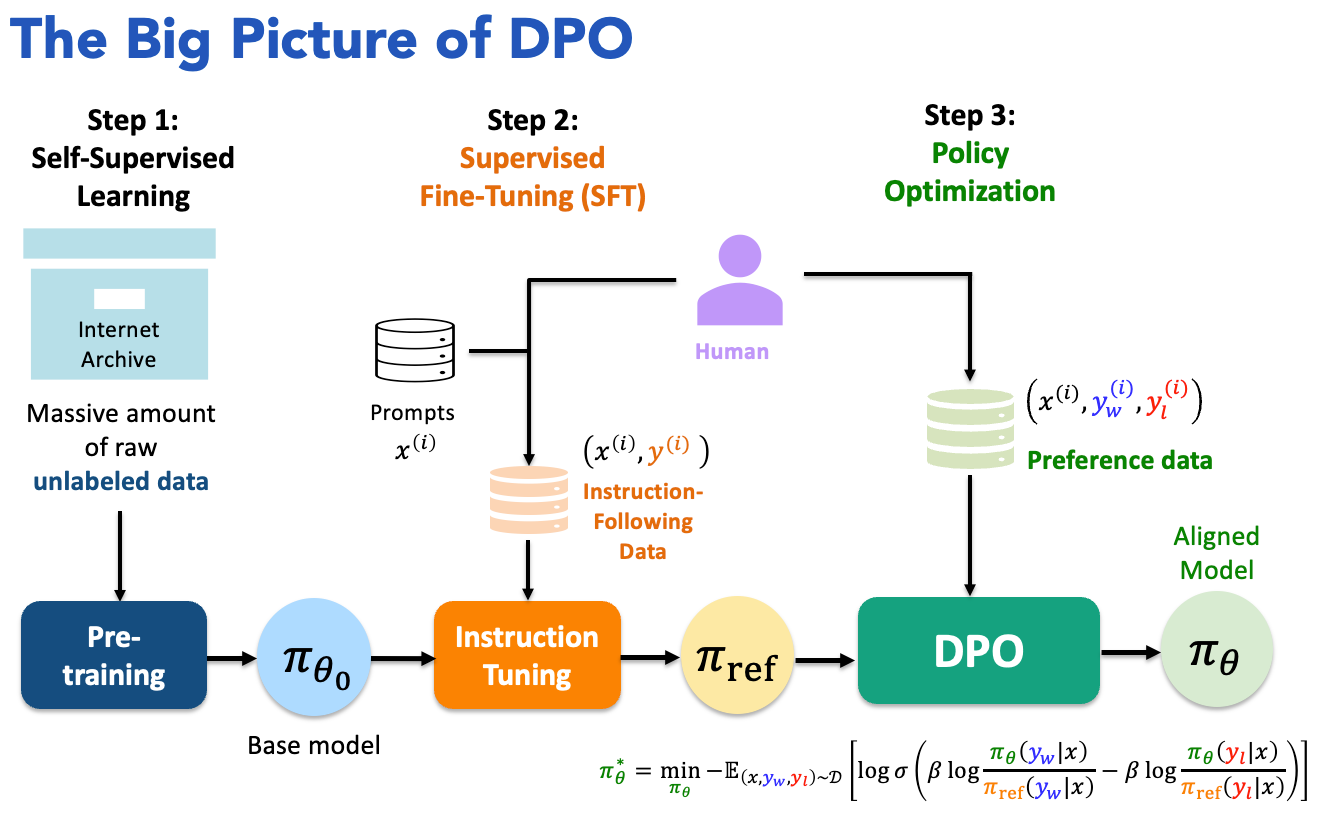
4.2 第一步:把 RLHF 写成一个明确的优化问题
RLHF 想做的事情,用数学语言表达就是:找一个策略(即语言模型),让它生成的回答尽可能得到高奖励,同时不要偏离 SFT 模型
太远。
拆开来看每一项:
:期望奖励,越高越好
:KL 散度,衡量当前策略偏离 SFT 模型有多远
:权衡系数,
KL 散度的展开形式是:
所以完整目标可以写成:
这是一个有约束的优化问题,目标是找最优的 。
4.3 第二步:求解最优策略的闭合形式
这一步是整个 DPO 推导的核心,我们来一步步推。
对于固定的 prompt ,上面的优化目标是在所有可能的回答分布
上做优化。把它写成对
求和的形式:
加上概率分布的归一化约束 ,这是一个有约束的变分优化问题,可以用拉格朗日乘数法求解。
对 求偏导并令其为零:
其中 是拉格朗日乘子(常数)。整理得:
两边取指数:
其中 是某个与
无关的常数。为了让
是一个合法的概率分布(所有
上加和为 1),
必须等于归一化常数的倒数,定义:
于是最优策略的闭合形式为:
这个公式的直觉是什么?
可以这样理解:最优策略是在参考模型 的基础上,对每个回答按奖励进行指数加权。奖励越高的回答被放大,奖励越低的被压缩,
控制放大的幅度。当
时,惩罚项占主导,最优策略退化为
,不做任何改变;当
时,KL 约束消失,策略会无限放大高奖励回答的概率。
注意:这里的 是对所有可能回答的求和,在语言模型中词表是离散的、序列是指数级的,
在实践中无法计算——这正是 RLHF 的难点所在。DPO 的关键一步就是绕过这个计算不可行的
。
4.4 第三步:反解奖励函数,用策略来表达奖励
既然已经得到了最优策略 和
之间的关系,可以把它反过来,用
和
来表达
。
从最优策略的公式出发:
两边取对数:
移项,把 解出来:
注意 只与
有关,与回答
无关,所以它对于同一个 prompt 下的所有回答是一个常数偏置。
这一步的意义是:我们把"奖励"重新表达成了"当前策略相对于参考模型的对数概率比"加上一个常数。 奖励不再是一个独立的模型,而是隐式地编码在策略与参考策略的比值里。
4.5 第四步:代入 Bradley-Terry 模型,消去不可计算的 Z(x)
现在需要一个"人类偏好"的概率模型。RLHF 使用的是 Bradley-Terry 模型,它假设人类偏好回答 (chosen)胜过
(rejected)的概率为:
其中 是 sigmoid 函数。直觉上:两个回答的奖励差越大,人类越倾向于更高奖励那个。
现在把第三步推导出的 代入:
这一项在相减时完全消掉了——这是整个推导最关键的一步。不可计算的归一化常数
消失了。
于是偏好概率变成:
4.6 第五步:构造 DPO 的损失函数
有了偏好概率的表达式,训练目标就是最大化观测到的偏好数据的对数似然——即对于数据集中每个偏好对 ,最大化
。
等价地,最小化负对数似然,得到 DPO 的损失函数:
整个推导到这里完成。回顾一下每步做了什么:
| 步骤 | 做了什么 | 关键结果 |
|---|---|---|
| 第一步 | 把 RLHF 写成带 KL 约束的优化问题 | 有明确数学形式的目标函数 |
| 第二步 | 对该优化问题求解析解 | 最优策略 |
| 第三步 | 从最优策略反解奖励函数 | |
| 第四步 | 代入 Bradley-Terry,相减消去 |
偏好概率只含 |
| 第五步 | 最大化偏好数据的对数似然 | DPO 损失函数 |
4.7 DPO 损失函数的直觉解读
把损失函数写成梯度的形式来理解它在做什么。当 内的值比较小时(即当前策略还没有把 chosen 和 rejected 区分得很好),梯度会推动:
对于 chosen 回答 :增大
,即让当前模型相对于参考模型,更倾向于生成
。
对于 rejected 回答 :减小
,即让当前模型相对于参考模型,更不倾向于生成
。
关键在"相对于参考模型":DPO 优化的不是绝对概率 ,而是相对概率比
。参考模型
起到了自适应基线的作用——如果某个 chosen 回答本来就是参考模型已经倾向于生成的(
很高),那它实际上不需要被进一步强化;相反,如果某个 rejected 回答是参考模型本来就不太会生成的(
很低),那它也不需要被进一步压制。这个机制防止了模型盲目强化已经合理的行为或盲目压制已经罕见的行为。
一个具体例子帮助理解:假设 是一个简洁有用的回答,
是一个冗长废话的回答。
- 如果参考模型(SFT 之后)本来就已经以 80% 的概率倾向于
,DPO 的梯度对这个样本的更新很小——参考模型已经表现得很好了,不需要大幅改变。
- 如果参考模型只有 20% 的概率倾向于
4.8 DPO 与 RLHF 的本质区别
把两套流程并排放在一起:
RLHF 的流程是三阶段分离的:第一阶段用(指令, 回答)对做 SFT,初始化策略;第二阶段单独用偏好数据训练一个奖励模型,这个奖励模型是一个独立的神经网络,输出一个标量分数;第三阶段冻结奖励模型,用 PPO 对策略做 RL 优化,同时需要 Critic 模型估计价值函数。整个过程中,奖励是显式的,存在于一个独立的模型里,策略优化通过 RL 算法间接进行。
DPO 的流程把第二、三阶段合并为一步:不训练奖励模型,而是把奖励隐式地编码在策略和参考策略的对数概率比中;不用 PPO,而是直接对语言模型做监督式的梯度下降,损失函数就是上面推导出的 DPO loss。奖励是隐式的,它在数学上等价于 RLHF 的最优解,但从不被显式计算出来。
可以用一句话总结两者的本质区别:
RLHF 先学"什么是好的"(奖励模型),再用这个知识去优化策略(PPO)。DPO 直接问"怎样调整策略才能让它符合偏好",把这两步合并成一个有监督的分类问题。
代价是什么? DPO 成立依赖于一个关键假设:偏好数据必须来自于与参考模型分布相近的策略(即 off-policy 数据时效果会变差)。如果用 GPT-4 生成的回答来做偏好对,而你的参考模型是一个 7B 的 SFT 模型,两者分布差异很大,DPO 的隐式奖励估计就会出现偏差,效果不如 PPO。这也是"Online DPO"(用当前模型实时生成偏好对)效果通常优于"Offline DPO"的根本原因。
4.9 用 TRL 的 DPOTrainer 做实战
以下是一个完整的 DPO 训练流程,包括数据准备和训练:
from datasets import load_dataset, Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOConfig, DPOTrainer
from peft import LoraConfig
import torch
# 1. 加载 SFT 之后的模型作为起点
model = AutoModelForCausalLM.from_pretrained(
"./sft_final", # 用上一步 SFT 训练好的模型
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("./sft_final")
# 2. 偏好数据集格式:每条样本需要 prompt, chosen, rejected 三个字段
# 使用 UltraFeedback 二元偏好数据集
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
# 该数据集的格式:{"prompt": [...], "chosen": [...], "rejected": [...]}
# 其中 prompt/chosen/rejected 均为 messages 列表(ChatML 格式)
# 3. 也可以自定义偏好数据集
def create_preference_dataset():
data = [
{
"prompt": [{"role": "user", "content": "解释量子纠缠"}],
"chosen": [{"role": "assistant", "content": "量子纠缠是指两个或多个粒子...(详细准确的解释)"}],
"rejected": [{"role": "assistant", "content": "量子纠缠就是两个东西纠缠在一起,没什么好解释的。"}],
},
# 更多样本...
]
return Dataset.from_list(data)
# 4. DPO 训练配置
dpo_config = DPOConfig(
output_dir="./dpo_output",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=5e-7, # DPO 的学习率应比 SFT 小得多
beta=0.1, # KL 惩罚系数,控制偏离参考模型的程度
warmup_ratio=0.1,
bf16=True,
logging_steps=10,
save_steps=500,
# 重要:不要设置 max_length,防止截断偏好对
max_length=None,
max_prompt_length=512,
)
# 5. LoRA 配置(DPO 也支持 PEFT)
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
task_type="CAUSAL_LM"
)
# 6. DPOTrainer 自动处理 reference model
# 如果传入 peft_config,ref_model 会自动从 model 的 base model 创建
trainer = DPOTrainer(
model=model,
ref_model=None, # 使用 LoRA 时设为 None,TRL 会自动处理
args=dpo_config,
train_dataset=dataset,
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
# 7. DPO 训练完成后,合并 LoRA 权重
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(
"./sft_final", torch_dtype=torch.bfloat16
)
peft_model = PeftModel.from_pretrained(base_model, "./dpo_output/checkpoint-xxx")
merged_model = peft_model.merge_and_unload()
merged_model.save_pretrained("./dpo_final")
关于 beta 参数:这是 DPO 最重要的超参数。beta 越大,对偏离参考模型的惩罚越重,模型改变越保守;beta 越小,模型能更自由地向偏好方向优化,但也更可能过拟合或退化。通常取值范围是 0.01~0.5,0.1 是常用的默认值。
五、GRPO:DeepSeek-R1 的新范式
严格来说 GRPO 属于 RLHF 的变体,但它的影响力足以单独成章,尤其是在推理模型的训练上。
5.1 GRPO 的动机:消除 Critic 模型
PPO 需要一个与 Actor 等大的 Critic 模型来估计状态价值函数(Value Function),作为计算优势函数(Advantage)的基线。这个 Critic 模型是 RLHF/PPO 内存开销巨大的主要来源之一。
GRPO(Group Relative Policy Optimization)的思路是:用同一 prompt 的多个采样回答的平均奖励作为基线,代替 Critic 模型。对于每个 prompt,生成一组 个回答
,用可验证奖励函数评分,然后用组内归一化的相对奖励作为每个回答的优势:
这样完全不需要 Critic 模型,内存减少约 25%~50%(取决于具体实现)。
5.2 GRPO 与可验证奖励(RLVR)
GRPO 特别适合与可验证奖励(Verifiable Rewards)结合。可验证奖励是指可以用程序判断对错的任务:数学题(答案是否正确)、代码(是否能通过测试用例)、逻辑推理(结论是否有效)。
DeepSeek-R1 使用了 RLVR(Reinforcement Learning with Verifiable Rewards)结合 GRPO,完全绕开了人类偏好和奖励模型。与标准 RLHF 不同,RLVR 从确定性工具(如计算器、编译器)获取直接的二元反馈(正确或错误),而不是从人工标注示例中学习什么是"好"答案。
这一方案的优势是彻底:不需要人工标注偏好,不需要奖励模型,奖励信号来自程序化验证,无法被"黑客"。DeepSeek-R1 的成功证明了这条路线的可行性,也直接催生了整个开源推理模型生态(QwQ、Kimi k1.5、Qwen3 的 Thinking 模式等)。
用 TRL 训练 GRPO 的最简示例:
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
from trl.rewards import accuracy_reward # 内置的准确率奖励函数
# 数学推理数据集
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
config = GRPOConfig(
output_dir="./grpo_output",
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=16,
learning_rate=1e-6,
num_generations=8, # 每个 prompt 采样 8 个回答
max_new_tokens=512,
bf16=True,
)
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-7B-Instruct",
reward_funcs=accuracy_reward, # 可验证的答案准确率奖励
args=config,
train_dataset=dataset,
)
trainer.train()
六、方法选择:什么时候用哪个?
这是最实际的问题。下面用几个维度帮你做决策。
6.1 按任务目标选择
你的目标是让模型学会某个特定领域的知识或格式 → SFT
例如:让通用模型学会回答医疗问诊、提取结构化信息、按特定格式输出 JSON、学习公司内部 FAQ。这类任务的关键在于数据质量,有 500~5000 条高质量的(指令, 回答)对,SFT 通常就足够了。不需要 RLHF 或 DPO。
你的目标是让模型的回答风格更贴合人类偏好(更友好、更安全、更有帮助) → DPO(优先)或 RLHF
例如:通用对话助手的偏好对齐、减少有害内容、改善回答的礼貌程度。如果资源有限,DPO 是首选——它稳定、高效,数据要求相对低(只需偏好对,不需要复杂的 RL 基础设施)。
你的目标是提升数学、代码、推理等可验证任务的能力 → GRPO/RLVR
如果任务的对错可以用程序验证,GRPO + 可验证奖励是目前最有效的方案,也是 DeepSeek-R1、Qwen3 Thinking 等模型的核心路线。
你的目标是通用旗舰模型,追求极致的对话质量 → SFT → RLHF(PPO)
这是 OpenAI(GPT-4)、Anthropic(Claude)等顶级实验室的路线,效果最好,但需要巨大的工程投入和人工标注成本,不适合中小团队。
6.2 按资源约束选择
| 约束条件 | 推荐方法 |
|---|---|
| 单卡 24G 显存,快速验证 | SFT + LoRA,或 DPO + LoRA |
| 多卡服务器(4×80G),中等规模 | DPO 全参数,或 SFT → DPO 两阶段 |
| 大规模集群(100+ GPU) | SFT → RLHF(PPO),或 SFT → GRPO |
| 无 GPU,只有 API 预算 | 用 GPT-4 生成 SFT 数据,再 SFT 小模型 |
| 无标注预算 | 用 AI 模型(如 GPT-4)生成偏好数据,再 DPO |
6.3 按数据类型选择
| 数据类型 | 推荐方法 |
|---|---|
| 高质量(指令, 回答)对 | SFT |
| (prompt, 好回答, 坏回答)偏好三元组 | DPO |
| (prompt, 回答, 满意/不满意)二元标注 | KTO |
| 数学/代码题目 + 正确答案 | GRPO + 可验证奖励 |
| 人工排序的多个回答 | RLHF(PPO) |
6.4 现实的流水线建议
新兴共识是一个模块化流水线:SFT 用于指令遵循 → DPO/SimPO 用于通用偏好对齐 → GRPO/DAPO 结合可验证奖励用于推理能力。每一层解决不同类型的对齐问题——行为对齐、偏好对齐和逻辑对齐。
对于大多数工程实践者,以下两种组合最常见:
方案 A(通用对话模型):SFT(1-3轮)→ DPO(1轮) 这是 Zephyr、LLaMA 3 Instruct 等开源模型常用的轻量路线,效果稳定,工程简单。
方案 B(推理/代码模型):SFT 冷启动(少量 CoT 数据)→ GRPO/RLVR(大量可验证任务) 这是 DeepSeek-R1、Qwen3 Thinking 的路线,适合以推理能力为核心目标的模型。
七、完整工具链
7.1 HuggingFace TRL
TRL(Transformer Reinforcement Learning)是目前最广泛使用的后训练框架,支持:
| Trainer | 用途 |
|---|---|
SFTTrainer |
监督微调 |
RewardTrainer |
训练奖励模型 |
DPOTrainer |
DPO 及其变体(SimPO, IPO, KTO 等) |
PPOTrainer |
标准 RLHF PPO |
GRPOTrainer |
GRPO(DeepSeek-R1 的方法) |
ORPOTrainer |
ORPO(SFT + 对齐一步完成) |
TRL 还提供了命令行接口,可以不写代码直接训练:
# SFT 训练
trl sft \
--model_name_or_path Qwen/Qwen2.5-7B \
--dataset_name trl-lib/Capybara \
--output_dir ./sft_output \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--learning_rate 2e-4 \
--use_peft \
--lora_r 64 \
--bf16
# DPO 训练
trl dpo \
--model_name_or_path ./sft_output \
--dataset_name trl-lib/ultrafeedback_binarized \
--output_dir ./dpo_output \
--beta 0.1 \
--learning_rate 5e-7 \
--use_peft \
--lora_r 16
7.2 ModelScope ms-swift
ms-swift 是 ModelScope 社区提供的大模型微调框架,支持 600+ LLM 和 400+ 多模态大模型的全参数或 PEFT 微调,包括 SFT、DPO、GRPO 等方法,以及 Megatron 并行训练技术。
# DPO 微调 Qwen3
CUDA_VISIBLE_DEVICES=0 swift rlhf \
--rlhf_type dpo \
--model Qwen/Qwen3-4B-Instruct \
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji \
--tuner_type lora \
--output_dir output
# GRPO 微调
CUDA_VISIBLE_DEVICES=0,1,2,3 NPROC_PER_NODE=4 swift rlhf \
--rlhf_type grpo \
--model Qwen/Qwen3-4B-Instruct \
--use_vllm true \
--dataset AI-MO/NuminaMath-TIR \
--output_dir output
7.3 OpenRLHF
专为大规模 RLHF 设计,基于 Ray 分布式架构,支持 70B+ 模型的全参数 PPO 训练:
# 70B 模型的完整 PPO-RLHF(需要大规模集群)
ray job submit --address="http://127.0.0.1:8265" -- \
python3 -m openrlhf.cli.train_ppo_ray \
--pretrain OpenRLHF/Llama-3-8b-sft-mixture \
--reward_pretrain OpenRLHF/Llama-3-8b-rm-700k \
--save_path ./checkpoint/llama3-8b-rlhf \
--train_batch_size 128 \
--rollout_batch_size 1024 \
--actor_num_nodes 1 \
--actor_num_gpus_per_node 8 \
--reward_num_nodes 1 \
--reward_num_gpus_per_node 8
7.4 Unsloth
针对单卡或小规模环境优化,通过内核级优化使训练速度提升 1.7x,显存减少 60%:
from unsloth import FastLanguageModel
from trl import SFTTrainer
model, tokenizer = FastLanguageModel.from_pretrained(
"unsloth/Qwen2.5-7B-Instruct-bnb-4bit", # 4bit 量化
max_seq_length=2048,
load_in_4bit=True,
)
# 添加 LoRA
model = FastLanguageModel.get_peft_model(
model,
r=64,
lora_alpha=128,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
)
# 后续与标准 TRL 完全兼容
八、常见坑与实战经验
8.1 SFT 的常见问题
灾难性遗忘(Catastrophic Forgetting):SFT 数据太集中在某个领域,导致模型在通用任务上退化。解决方法是在 SFT 数据里混入 5%~10% 的通用指令数据(如 Alpaca、OpenHermes),保持通用能力。
学习率过大:SFT 的学习率通常在 1e-5 到 2e-4 之间,大于此范围容易破坏预训练权重。推荐使用余弦调度(cosine schedule)配合 warmup。
过拟合:SFT 只需要 1~3 个 epoch,超过 3 个 epoch 通常会过拟合,导致模型回答死板、缺乏多样性。
8.2 DPO 的常见问题
偏好数据质量比数量更重要:差的偏好对(chosen 和 rejected 区别不明显)比没有偏好数据更糟糕,会把模型训歪。宁可用 1000 条高质量偏好对,也不用 10000 条模糊的偏好对。
beta 值过小导致退化:beta 过小时,DPO 对 KL 约束的惩罚太弱,模型会在偏好方向上过度优化,丢失多样性甚至出现重复生成。建议从 0.1 开始,如果回答变得僵硬或重复,适当增大。
On-policy vs Off-policy:如果偏好数据是由另一个模型(如 GPT-4)生成的,这是 off-policy 数据,DPO 效果可能不如期望。理想情况是用当前模型本身生成候选回答,再通过奖励模型或规则筛选偏好对(on-policy DPO),实验证明效果更好。
8.3 RLHF/PPO 的常见问题
奖励模型过拟合:奖励模型如果在分布外输入上给出极端分数,PPO 会利用这一点进行奖励黑客。解决方法是加入 KL 惩罚(TRL 默认启用),并监控 KL 值不超过 5~10。
训练崩溃:PPO 训练不稳定时可能突然崩溃(loss 突然变为 NaN 或奖励骤降)。建议:降低学习率(1e-6 量级)、增大 KL 系数、使用梯度裁剪(max grad norm = 0.5~1.0)。
九、总结:三种方法的定位
把三种方法放在一个框架里看:
SFT 是"教会模型做某件事"。它通过示范回答告诉模型"这样做",是行为对齐的基础。几乎所有大模型都需要 SFT,是必经之路而非可选项。
RLHF/PPO 是"让模型越做越好"。通过奖励信号引导模型在给定的偏好分布上探索,适合追求极致效果的大规模训练场景。代价是工程复杂、计算昂贵,是顶级实验室的专属工具。
DPO 是"告诉模型什么更好"。通过偏好对直接优化策略,绕过了 RL 循环,是平衡效果与工程复杂度的最佳选择,适合大多数工程实践者。
GRPO 是"让模型通过试错发现推理方式"。结合可验证奖励,适合推理、代码等有客观正确答案的任务,是 2025 年后推理模型训练的主流范式。
理解这三者(以及它们的扩展),等于掌握了现代大模型后训练的核心工具箱。选对工具,远比堆参数更能决定模型的最终质量。
参考资料
- Ouyang et al., Training language models to follow instructions with human feedback(InstructGPT), NeurIPS 2022
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model, NeurIPS 2023
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024
- Guo et al., DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025
- HuggingFace TRL Documentation: https://huggingface.co/docs/trl
- Philschmid Blog: How to align open LLMs in 2025 with DPO, 2025
- Sebastian Raschka: The State of Reinforcement Learning for LLM Reasoning, 2025

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)