如何速成LLM以伪装成一个AI研究者(1)——循环,卷积,编解码器,注意力机制,Transformer
前言
我们假设你面对着包括但不限于如下情景:
- 你是一个本科学生,刚进入实验室,老师给你丢了一大堆LLM相关的论文读,但你连标题都看不懂是什么意思。
- 你突然决定尝试LLM领域,但你还没来得及看完收藏夹里的16篇论文,就发现arxiv上又多了26篇你需要看的新论文。
- 你完全没有AI甚至计算机相关的基础,但是为了在一场学术会议骗吃骗喝或者在对象面前装一把,你决定在一周内掌握伪装成一名AI研究者并侃侃而谈的方法。
- 你正在尝试好好学习AI,但觉得AI领域存在大量难以区分语义的炒作名词,让你根本看不懂这些人都在叽里咕噜讲什么,从而感到非常愤怒。
那么这个系列文章将会适合你。但如果你是严谨的数学研究者,或者真的对AI领域有相当的了解,那么这篇文章可能并不适合你“加深理解”。
那么,为了快速伪装成一名AI研究者,让我们尝试以最快速、最感性的角度,梳理一遍你需要了解的那些LLM知识吧!
免责声明:作者也是伪装的,有错漏属于正常现象,欢迎评论指正。
Attention is all you need
Attention Is All You Need 是2017年由Google Brain团队提出的论文,也是AI领域被应用量最高的论文之一。我们的起点就从这里开始。
这篇论文的核心点是什么?一言以蔽之:作者提出了一个完全基于注意力机制(Attention Mechanisms) 的神经网络架构 Transformer,它无需依赖循环(recurrence) 或者 卷积(convolution),在翻译任务上,达到了质量更优、更具并行性、训练时间更少的效果。
停停,这一个两个的都是什么东西?那就让我们来逐步拆解吧。
CNN & RNN
既然论文强调“无需依赖循环或卷积”,那么第一个问题就是——什么是“循环”与“卷积”?
循环神经网络RNN
一个非常简单的神经网络(或许是二层全连接)结构如下图左所示,输入 x x x,计算 σ ( W T x + b ) \sigma(W^Tx+b) σ(WTx+b)( σ \sigma σ是非线性激活函数)得到隐藏层 h h h,然后再用另一组 W , b W,b W,b参数计算一遍得到输出层 y y y。这个结构可以用来做一些简单的问题,比如图像分类。输入可以是图像的所有像素的颜色值(维度:图像尺寸 × \times × 颜色通道数),输出是图像归属于每个类别的概率(维度:类别数量)。
而RNN是用于解决序列问题的,它的结构如图右所示。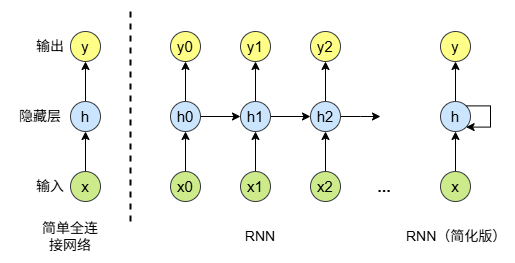
看到这里,你可能会问——诶?那RNN的输入和输出长度岂不是是一样的?那我要做个词性标注(标注每个单词的是名词还是介词)什么的还行,光是做个翻译,同一句话的中英文也不等长啊!
啊,没错,在 最普通的情况 下,的确如此。下一节“编解码器机制”,我们会再讨论这个问题。
补充
LSTM(长短期记忆网络),GRU(门控循环单元)与RNN的关系
LSTM是传统RNN的改进版,能有效控制信息保留与遗忘,解决长期依赖问题
GRU是LSTM的简化版,参数量更少、计算更快,效果通常与 LSTM 接近
卷积神经网络CNN
CNN其实一般用于 图像处理领域,所以在此只做最简要的介绍,感兴趣可以进一步查阅了解。
卷积 是一个用于提取局部特征的函数。卷积核的大小,决定了这个“局部”的范围有多大——比如只考虑9个像素点的纹理,或者框柱一整只狗脑袋的轮廓。设计CNN时,往往会并排放置多个不同尺寸的卷积,让它们各自提取不同的局部语义(比如同时提取“胡须”和“耳朵”),然后将这些特征在通道维度上堆叠(Concate)起来以进行后续处理。
简单来说:CNN可以提取不同层次(尺寸涵盖像素点层次到物体全局轮廓层次,内容涵盖边缘检测、平均颜色等等等等)的语义特征。
在文本任务领域,它有时也会被用了提取层次不同(从一个词组的用法,到一个句子的整体结构)的语义特征。
seq2seq问题与编解码器机制
seq2seq,也就是本文聚焦的任务类型,它指的是指一类序列数据到另一类的任务,例如翻译(中文序列到英文序列)。一般来说,解决seq2seq问题的序列转换模型(Sequence Transduction Model),是输入→ 编码器(Encoder) →隐状态→ 解码器(Decoder) →输出的结构。
你可能会问——那到底什么是编解码器啊?
那么就要了解一点:
编解码器机制是一种 设计哲学,而不是一种存在严格数学边界的神经网络架构分类方式。
这句话的意思是,并没有一个公认的定理说“要满足xx条件的神经网络架构才能被称为编解码器架构”,如果你乐意的话,你可以称呼上面那张图的两层全连接神经网络为编解码器——第一层负责编码,第二层负责解码,没毛病吧。
不过,无缘无故这样说有点像找茬。当我们说“这是一个编码器”和“这是一个解码器”时,在语境上想表达的意思是:网络的设计者希望这一部分网络结构担当“编码”(从输入提取/压缩/理解信息)或者“解码”(基于某些信息生成/展开/创建输出)的作用。
补充
从设计目的上来说,编解码器机制的引入是为了解耦输入和输出的长度。正如我们上文所说,最普通的RNN的输入和输出是等长的,有多少个输入 x i x_i xi,就有多少个隐藏状态 h i h_i hi。
我们以机器翻译打个比方,想要把英文的"Good morning"翻译成中文的“早上好”。下图展示了一个编码器/解码器结构。
其中,编码器会丢弃所有前缀的 h i h_i hi,只保留最后一个隐藏状态 h n h_n hn作为语义向量。不管输入多长,这个语义向量的维度(特征维度)是固定的。这是一个最简单的编解码器结构,我们认为这个简单的语义向量就足以包含所有必要的语义信息(不管它实际上做不做得到)。
接着进入解码器部分,它初始用语义向量+<SOS>(起始符)计算 h 0 ′ h'_0 h0′并解码得到第一个字符,之后不断用上一时刻的 h t ′ h'_t ht′(不需要新的输入)计算和解码新的的字符,直到输出结束符<EOS>。这个过程和输入句子的长度完全无关。这两部分神经网络的运行机制相对独立,除了传递语义向量以外没有其他交互。
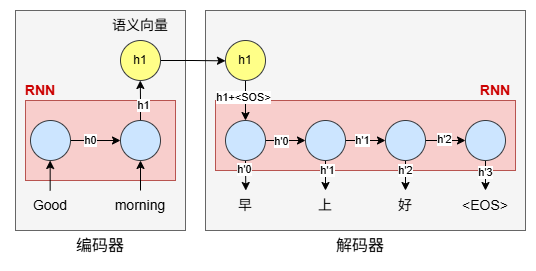

在论文中,作者一般会把一部分网络框起来,告诉你这个部分是做编码器用的。再把另一个部分框起来,说它是做解码器用的——而在 Attention is all you need 里,作者也这么干了。
补充
如果你有了解过BERT和GPT,大概会知道“GPT是基于解码器的网络架构,而BERT是基于编码器的架构”。
这是因为,GPT的输入是一个句子前缀,依次预测下一个Token的流式生成的句子,它需要不断解码当前文段的意图,从而得到接下来应该继续说什么词语。
而BERT的输出是一个用于分类之类的下游任务的上下文相关的表示向量,这是一个纯粹的编码过程。
注意力机制
现在你也大概理解了Attention is all you need 这篇论文的背景知识,接下来我们终于要开始介绍Attention了……吗?
Attention的输入是一对 ( Q , ( K , V ) ) (Q,(K,V)) (Q,(K,V))。想象一下你去图书馆查论文, Q Q Q是查询,也就是你查论文时关注的那些话题——LLM,名词解释,如何成为伪装大师云云。 K K K是键,可以视作论文的标题。而 V V V是值,就是论文的内容。
数学上, Q , K , V Q,K,V Q,K,V分别是 T q ∗ D q T_q * D_q Tq∗Dq, T k ∗ D k T_k * D_k Tk∗Dk, T v ∗ D v T_v * D_v Tv∗Dv的矩阵。 T T T是数量,也就是你有多少个关注的话题,图书馆有多少篇论文,显然 T k = T v T_k=T_v Tk=Tv,因为键和值需要一一对应。而 D D D是特征维度,为了做Attention,需要 D q = D k D_q=D_k Dq=Dk,也即键和查询的特征维度是一样的。而 D v D_v Dv,也就是具体值的特征维度,则可以不一样。
为什么 Q Q Q和 K K K的特征维度要一样呢?继续想象,面对这么多的论文,你怎么知道要更关注哪一些呢?一个直观的想法是:我要关注和我的查询相似度更高的论文。
那么,什么是“相似度更高”?
余弦相似度 & 点积相似度
假如我们想要比较两个人看电影的爱好是否相似,可以计算他们最近一个月内看过的不同类型的电影数量——比如小明看了1部科幻片,3部恐怖片,他的特征向量就是(1, 3)。而小红看了0部科幻片,10部恐怖片,她的特征向量就是(0, 10)。
好,现在你得到了每一个人的电影品味“特征向量”,它们分散在一个n维空间里,n即是特征向量的维度。怎么看两个人的爱好是否相似呢?你会有一个显而易见的思路——看距离!就像你问我B和C哪个和A更相似,这还用说吗?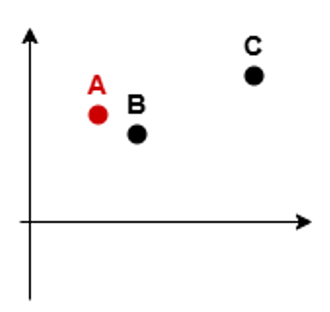
你说的“距离”又是哪个距离?我们这里有欧几里得距离,曼哈顿距离,切比雪夫距离,闵可夫斯基距离……
停停!选择恐惧症要犯了——有没有简单又好用的距离?
有的有的,那就是 余弦距离,它的计算公式是 x ⃗ ⋅ y ⃗ ∣ x ⃗ ∣ ∣ y ⃗ ∣ \frac{\vec x \cdot \vec y}{|\vec x| |\vec y|} ∣x∣∣y∣x⋅y,计算的是两个向量夹角的余弦值,越靠近则越大。模长归一化后,只要做点积,不用再开根和算绝对值,哇塞,算起来简直太简单啦!
补充
使用余弦相似度的好处:
- 消除模长值的影响,容易控制梯度,训练embedding模型时更稳定
- 点积计算高并发、速度快;模长值则可以预处理
使用神经网络进行的特征向量嵌入(embedding)计算,一般都会被训练得越相似的输入,余弦相似度越高,也是因为余弦相似度是一个相当容易的计算。
不过你也看出来了,用余弦距离计算电影品味相似的情况下,我们是假设上个月大家看的电影具体数量不重要 。假如小王看了3部科幻片,0部恐怖片;小李看了2部科幻片,0部恐怖片;小张看了5部科幻片,1部恐怖片。那么小王到底是和小李的品味更相似,还是和小张的呢?……嗯,好像不是很好说?
有的时候,我们也会使用 点积 本身作为相似度的衡量,在这种情况下,每个维度的数值可以视作一种“重要性”或“强度”。使用余弦相似度的情况下,小王和小李在归一化后的向量一样,所以小王和小李更相似。但使用点积的情况下,小王和小李的点积为6,和小张的点积为15,所以小王和小张的品味更相似。
不过,使用点积相似度的话,也需要进行一些归一化处理,否则乘积存在数值爆炸导致梯度爆炸/消失的可能性。
注意力(attention)
现在,你知道你可以用余弦相似度来衡量查询和键是否相似了,假设每一个询问,每一个键都已经模长归一化为1,则公式为:
s i m i l a r i t y _ s c o r e = Q K T / D k similarity\_score=QK^T/ \sqrt{D^k} similarity_score=QKT/Dk
计算出来为一个 T q ∗ T K T_q * T_K Tq∗TK的矩阵,第 i i i行 j j j列为询问 q i q_i qi和键 k j k_j kj的点积。而除以这个 D k \sqrt{D^k} Dk,则是出于防止梯度消失问题的一个缩放。具体的探讨可以推荐另一篇博文:为什么Attention计算公式中,QK的点积要除以根号d。核心关键点是保持点积后的方差不变。
而attention的总公式为:
a t t ( Q , ( K , V ) ) = s o f t m a x ( Q K T / D k ) V att(Q, (K,V))= softmax(QK^T/ \sqrt{D^k})V att(Q,(K,V))=softmax(QKT/Dk)V
Softmax
设输入为 ( x 1 , . . . x d ) (x_1,...x_d) (x1,...xd),输出为 ( y 1 , . . . , y d ) (y_1,...,y_d) (y1,...,yd),则softmax的公式为 y i = e x i / ∑ j = 1 d e x j y_i = e^{x_i}/\sum_{j=1}^d e^{x_j} yi=exi/∑j=1dexj
它的作用为:将原向量转换成一个“概率分布”,即一组总和为 1、且彼此可比(可以除)的正数。softmax后,向量每一维的取值都在 ( 0 , 1 ) (0,1) (0,1)范围内。
这个softmax的作用是将相似度转化为一个“每篇论文有多大概率需要被我注意”的概率分布(是矩阵每一行,也即关于每个问题,让所有论文和它的相关性变成一个和为1的概率分布)。然后, s o f t m a x ( Q K T / D k ) softmax(QK^T/ \sqrt{D^k}) softmax(QKT/Dk)被称为注意力分数。最终,我们会以注意力分数为依据,去聚合实际的值V(相当于聚合看每一篇论文的学习感悟),去得到最终的结果(学习成果),这个结果的维度为 T k ∗ D v T_k * D_v Tk∗Dv。
自注意力(self-attention)与多头注意力(multi-head attention)
自注意力:即Q,K,V来源相同——都是输入X与线性变换矩阵的乘积的注意力机制。 Q = W q X Q=W_qX Q=WqX, K = W k X K=W_kX K=WkX, V = W v X V=W_vX V=WvX。
多头注意力:将Q,K,V进行h组(h即为头数)线性变换,得到 Q i = W q i Q Q_i=W_{qi} Q Qi=WqiQ, K i = W k i K K_i=W_{ki} K Ki=WkiK, V i = W v i V V_i=W_{vi} V Vi=WviV。一般来说,变换后的特征维度为 D k / h , D k / h , D v / h D_k/h, D_k/h, D_v/h Dk/h,Dk/h,Dv/h。然后,将得到的h组 a t t i ( Q i , ( K i , V i ) ) att_i(Q_i,(K_i,V_i)) atti(Qi,(Ki,Vi))拼接起来,就又回重新得到一个 D v D_v Dv维的结果。多头注意力允许模型 从多种不同的角度来关注信息。
论文使用的是多头自注意力。
Transformer
Transformer,你很难说它的中文译名是什么……“变形金刚”?也许?大概?
一个Transformer,按论文的原图,就是下面这个东西:

其中,左边的框是编码器,右边的框是解码器。 N x N_x Nx,在论文中设置为超参 N x = 6 N_x=6 Nx=6,也即编解码器都是由6组相同的结构构成的。以下是一些详细讲解:
首先看向Inputs到粉红色的Input Embedding这一部分,这是将句子中的每个词,从词嵌入矩阵中查到一个词特征向量。假如句子有 T i T_i Ti个词,词特征向量的维度为 D D D(论文中 D = 512 D=512 D=512),则最后会得到一个 T i ∗ D T_i*D Ti∗D的矩阵。这个词特征矩阵一开始是随机初始化的,会跟随整个模型一起训练。
编码器自注意力层: h = 8 h=8 h=8的多头自注意力模块,输出的维度也是 T i ∗ D T_i*D Ti∗D。
feed forward(FFN):一个两层的全连接网络,输入、输出维度均为 T i ∗ D T_i*D Ti∗D。
层归一化和残差连接:从输入连接到Add & Norm的线条表示残差连接,这一层还会做归一化。知道这些是一些常见的稳定训练的网络架构设计技巧即可,不是本文技术重点,可以自行查阅资料了解更多。
Output (shifted right):训练时,假设正确答案句子为 ( y 0 , y 1 , y 2 ) (y_0, y_1, y_2) (y0,y1,y2),右移一格则变成 ( < S O S > , y 0 , y 1 ) (<SOS>, y_0, y_1) (<SOS>,y0,y1),期望输出 ( y 0 , y 1 , y 2 ) (y_0, y_1, y_2) (y0,y1,y2)。也即 ( < S O S > ) → y 0 (<SOS>)\rightarrow y_0 (<SOS>)→y0, ( < S O S > , y 0 ) → y 1 (<SOS>, y_0) \rightarrow y_1 (<SOS>,y0)→y1, ( < S O S > , y 0 , y 1 ) → y 2 (<SOS>, y_0, y_1) \rightarrow y_2 (<SOS>,y0,y1)→y2。
解码器自注意力层:也即那个masked multi-head attention。如图所示,会在Attention的Softmax前作一个mask。对于询问i(句子中的第i个词),所有 j > i j>i j>i的词j的注意力分数都要设置为负无穷(softmax完后为0)。
这是因为在训练时会同时计算整个输出句子每个位置的预测loss,输入的长度为 T o T_o To,即正确答案的词数。所以需要掩码来防止模型“看到未来的词”。而推理的时候,是没有未来的词的。
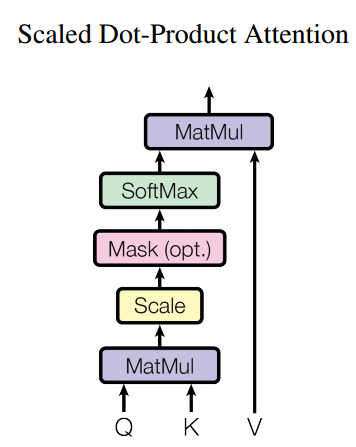
编码器-解码器注意力层:也即图右的multi-head atteantion。查询来自解码器的先前输出( T o ∗ D T_o * D To∗D),而K和V来自编码器 最后一层 的输出( T i ∗ D T_i *D Ti∗D),输出维度为 T o ∗ D T_o *D To∗D。此处实现了编解码器思想的输入/输出长度转换。
Positional Encoding:了解Attention机制后你会发现一个问题:attention不像RNN,并不天然带有对位置信息的处理,所以需要通过将位置编码叠加到词向量上,让网络处理时会考虑位置信息。
位置编码是一个和词嵌入向量等长的向量,所以可以直接和词嵌入向量相加。它可以是固定的,也可以是学习的,不过论文作者发现基于学习的位置编码和sine & cosine 编码的效果差不多,所以最后使用了这个位置编码公式:
P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / D ) PE_{(pos, 2i)}=\sin (pos/10000^{2i/D}) PE(pos,2i)=sin(pos/100002i/D)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / D ) PE_{(pos, 2i+1)}=\cos (pos/10000^{2i/D}) PE(pos,2i+1)=cos(pos/100002i/D)
其中,pos为位置值, i i i为维度索引 0 ≤ i ≤ D / 2 0 \leq i \leq D/2 0≤i≤D/2,最后生成一个 D D D维位置编码向量 P E p o s PE_{pos} PEpos。
全程没有RNN/CNN参与,only Attention。
Transformer的好处
- 减少每层计算复杂度:令序列长度为 N N N,则Self-Attention的单层计算复杂度为 O ( N 2 D ) O(N^2D) O(N2D)(矩阵乘法),RNN为 O ( N D 2 ) O(ND^2) O(ND2),在 N < D N<D N<D的情况下Transformer可以减少计算复杂度(对于短/中等长度的文本)。不过,对于长文本,Transformer的计算复杂度也会变得很高,所以以下两个优点才是现在大家还坚持使用Transformer的原因。
- 提高可并行化的计算量:RNN 必须等第 1 步算完才能算第 2 步(串行);Transformer 的 Attention 和 FFN 在序列长度 T 的维度上是完全并行的。
- 长距离作用:朴素RNN很难处理较长的生成,因为序列前期的信息,对序列后期生成的影响会变得越来越弱。而Transformer因为Attention机制更关注语义相关性而不是邻近性,就像一个学LLM的时候能够回忆起大一的高代课上的相关知识的学生(好羡慕),比只记得前几天的课程内容的学生对复杂任务的处理能力更好,更适合长序列处理。
总结
本文跟随经典论文Attention Is All You Need 梳理了seq2seq问题,以及LLM架构的理论基础。还没想好写什么的下一章,可能会简略讨论如何从Transformer走向现代大模型网络架构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)