AI科研写作新突破:谷歌提出PaperOrchestra,AI智能体天团协作,从草稿到LaTeX一键搞定,模拟顶会接收率84%!
本文提出神经分布先验(NDP)以解决LiDAR类别不平衡下的OOD检测,在STU测试集上AP提升超10倍。
研究背景:自动驾驶中的LiDAR感知模型通常在封闭集假设下运行,无法识别分布外(OOD)的未知物体(如路障、杂物),构成严重安全隐患。现有OOD检测方法在LiDAR数据上表现不佳,因为它们忽略了LiDAR场景中普遍存在的严重类别不平衡问题,导致OOD评分存在偏差。
本文方案:论文提出了一个名为神经分布先验(Neural Distribution Prior, NDP)的可学习框架。其核心创新在于,通过一个基于注意力机制的模块来学习网络预测的分布结构,并以此先验知识自适应地调整和校准OOD分数,从而纠正类别不平衡带来的置信度偏差。同时,论文还提出了一种基于Perlin噪声的OOD样本合成策略,无需外部数据集即可生成多样化的训练样本。
在这里我整理了,与本篇论文研究方向高度相关的论文合集

核心贡献
-
提出神经分布先验 (NDP) :设计了一个可学习的注意力模块,对网络输出的 logits 分布进行建模,动态调整OOD分数,有效解决了LiDAR数据严重类别不平衡导致的检测偏差问题。
-
提出Perlin噪声OOD合成方法:通过对点云局部表面进行几何扰动,生成了多样化且真实的伪OOD样本,摆脱了对外部数据集的依赖,增强了模型的泛化能力。
-
提出软性离群点暴露 (SOE) :针对数据中不可靠的“空洞”区域,采用软标签进行训练,既利用了这些信息,又避免了模型对特定“空洞”类别过拟合,提升了训练稳定性。
方法解析
核心思路
该方法的核心思路是,不依赖固定的OOD评分函数,而是通过一个可学习的模块(NDP)来捕捉在分布(ID)数据上网络预测的固有分布模式。然后,将这个学到的“分布先验”作为基准,来判断新的预测是否符合正常模式,从而动态地、有区别地调整每个点的OOD分数,以对抗类别不平衡带来的影响。
模型架构
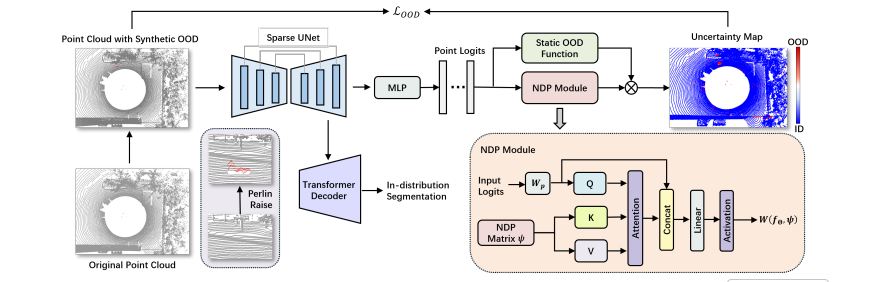
图2:模型结构图
整体架构基于Mask4Former-3D,包含一个稀疏UNet编码器和一个Transformer解码器。OOD检测分支利用UNet提取的逐点特征进行,而ID分割任务由Transformer解码器完成,两者并行训练。
-
Perlin噪声OOD合成 (Perlin Raise)
-
功能定位:在训练阶段生成多样化的辅助OOD样本。
-
具体实现:如算法1所示,在输入的点云中随机选择一个路面区域,生成一个Perlin噪声场,对该区域内的点进行平滑且符合自然纹理的高度扰动,然后将其中连接性最强的扰动点簇标记为OOD样本。
-
设计动机:克服使用外部数据集带来的域差异和处理复杂性问题,同时避免使用数据集中固有的“空洞”点(通常种类单一)导致过拟合。Perlin噪声能生成结构多样、非语义的几何异常。
-
-
神经分布先验 (NDP) 模块
-
功能定位:对基础OOD分数进行自适应加权,以校准类别不平衡带来的偏差。
- 具体实现:
-
对于一个基础OOD分数 ,NDP调整后的分数为:
-
其中, 是一个神经加权函数。它首先将网络输出的logits 投影到潜空间得到嵌入向量 。
-
然后,通过与一个可学习的先验矩阵 (K为类别数, d为嵌入维度) 进行交叉注意力计算,得到上下文向量 :
-
最后,将 和 拼接后通过一个线性层得到最终的权重 ,即 。
-
-
设计动机:静态的OOD分数(如能量、熵)无法适应不同类别置信度分布的差异。NDP通过学习一个先验分布 ,并利用注意力机制衡量当前预测与该先验的对齐程度,从而动态地调整OOD分数,使模型对高频类的过高置信度和低频类的过低置信度进行校正。
-
-
扩展能量分数 (Extended Energy Score)
-
功能定位:一种为NDP设计的新基础OOD分数,能更好地分离ID和OOD样本。
-
具体实现:网络输出 维的logits,前 维对应ID类别 (),后 维对应其OOD负样本。扩展能量分数(NDP-EE)定义为:
-
设计动机:通过显式地为OOD样本分配负logits,可以更精细地划分logit空间,从而增强ID和OOD样本之间的可分性。
-
-
训练目标
-
功能定位:结合多种监督信号,稳定地训练OOD检测器。
- 具体实现:总损失 。
-
:对ID点进行标准的交叉熵分类损失。
-
:对ID点和Perlin噪声生成的OOD点进行二元分类,目标是使ID点的分数低,OOD点的分数高。
-
(软性离群点暴露):对数据中固有的“空洞”点,使用一个软标签 (如0.9)进行回归,而不是硬性地将其视为OOD。损失函数为:
-
-
设计动机: 利用高质量的合成OOD样本学习判别边界。 则温和地利用了不纯净的“空洞”点,防止模型对其中的特定物体(如垃圾桶)过拟合,提升泛化性。
-
实验验证
实验设置
- 数据集:
-
STU (Spotting the Unexpected): 专为LiDAR异常分割设计的大规模数据集,包含真实道路场景中的自然及人为放置的异常物体。是评估模型性能的核心。
-
SemanticKITTI: 标准的LiDAR语义分割数据集,通过将
other-structure等类别视为OOD来模拟OOD检测场景,用于验证泛化性。
-
- 评测指标:
-
点级别: AP (平均精度)、AUROC、FPR@95。AP是核心指标,因为它能很好地处理ID和OOD点之间的严重不平衡。
-
物体级别: PQ (全景质量)、UQ (未知质量) 等,衡量实例级别的检测和分割效果。
-
-
对比方法:与多种基于后处理的OOD评分方法(如Deep Ensemble, MaxLogit)和需要额外训练的方法(如Void Classifier, RbA)进行比较,均基于相同的Mask4Former-3D架构。
主实验结果
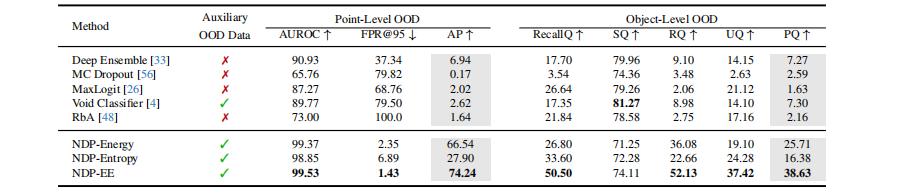
表1:STU验证集和测试集上的异常分割性能
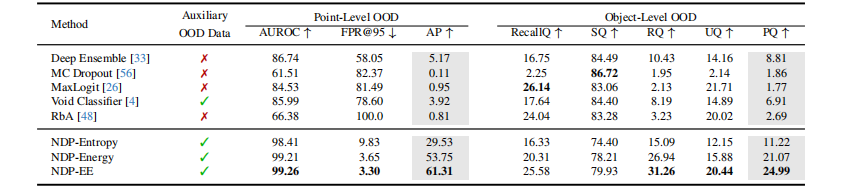
表2:STU验证集和测试集上的异常分割性能
-
提升巨大:在STU基准上,NDP框架取得了SOTA性能。特别是在测试集上,NDP-EE(使用扩展能量分数的NDP)的点级别AP达到了61.31% ,相比之前的最佳方法(Deep Ensemble的5.17%)提升了超过10倍。物体级别的PQ也提升了近2倍。
-
效果显著:在STU验证集和测试集上,结合了NDP的三种分数(Energy, Entropy, EE)均远超所有基线方法。
-
提升原因:这一巨大提升主要归功于NDP有效缓解了类别不平衡问题,使得OOD分数更加校准和可靠。同时,Perlin噪声合成和SOE训练策略为模型提供了高质量和多样化的负样本,学习到了更鲁棒的决策边界。
消融实验
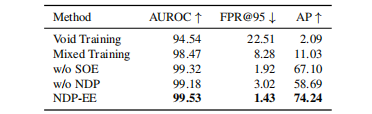
表5:NDP框架的消融研究
-
NDP模块最关键:去掉NDP模块(w/o NDP),仅使用静态的扩展能量分数,AP从74.24%骤降至58.69%,下降了15.55%,证明了NDP在校准OOD分数、对抗类别不平衡方面的核心作用。
- 训练策略同样重要:
-
去掉SOE损失(w/o SOE),AP下降了7.14%,说明温和地利用“空洞”点对于泛化至关重要。
-
仅使用“空洞”点进行训练(Void Training),效果最差(AP为2.09%),证明了高质量合成样本的必要性。
-
结论与启示
总结:这篇论文的核心发现是,通过一个可学习的神经分布先验(NDP)来动态校准OOD分数,可以极其有效地解决LiDAR数据严重类别不平衡下的OOD检测难题。
启示:
-
对于存在严重数据不平衡的OOD检测任务,单纯依赖静态评分函数是不足的。引入一个学习模块来建模和利用数据的内在分布特性,是提升性能的有效途径。
-
高质量的、多样化的辅助OOD样本对训练至关重要。论文提出的Perlin噪声合成方法是一种轻量且高效的解决方案,可启发其他领域生成伪异常样本。
-
对于数据集中存在的不纯净或不可靠的负样本(如“空洞”类),软标签和定制化的损失函数(如SOE)是比硬性二元分类更优的利用方式。
论文:Neural Distribution Prior for LiDAR Out-of-Distribution Detection
在这里我整理了,与本篇论文研究方向高度相关的论文合集

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)