LangChain v1.0 文档审核类 Agent 开发实战
LangChain v1.0 文档审核类 Agent 开发实战
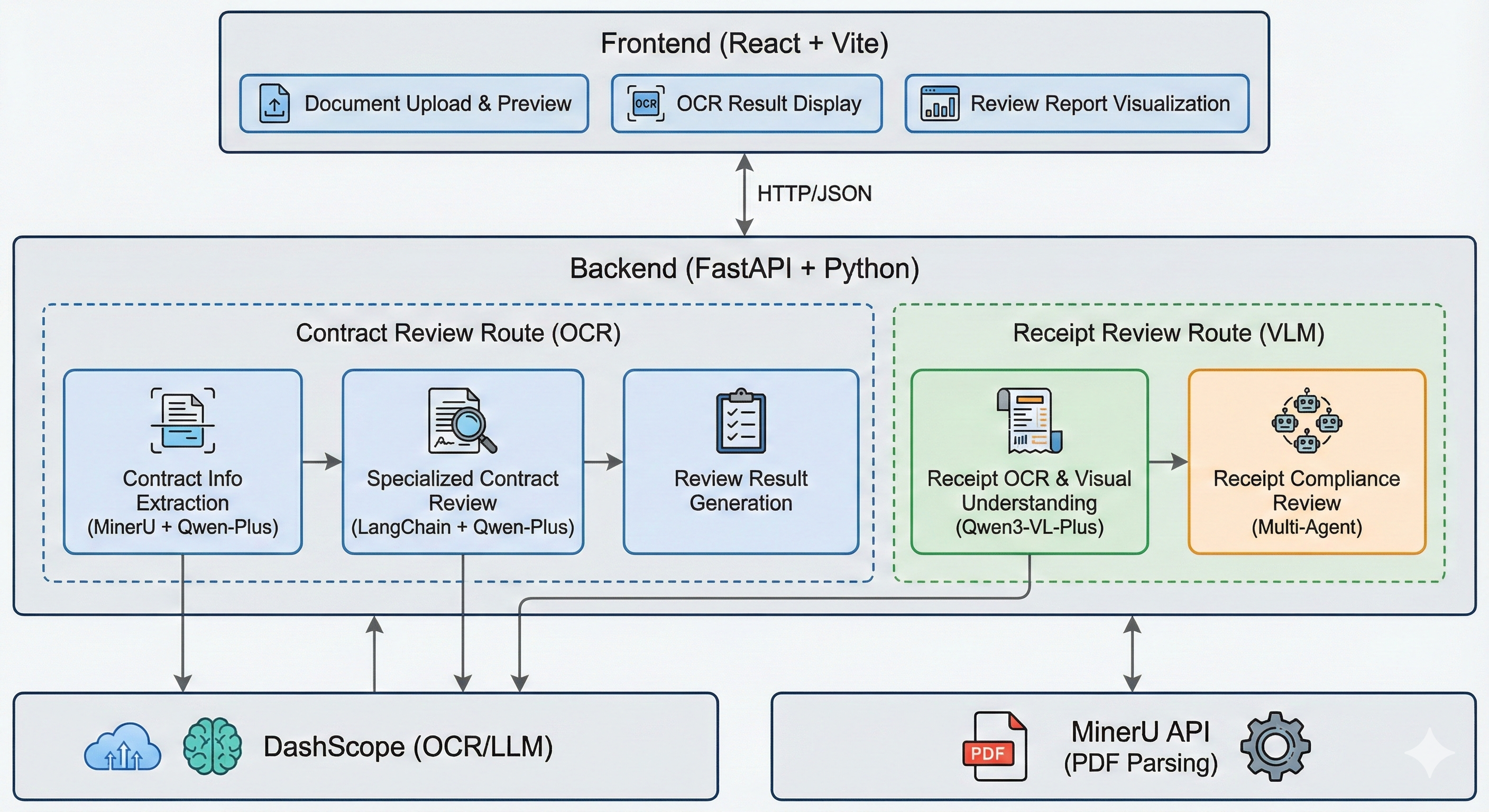
编辑本文详细介绍了如何使用 LangChain v1.0 搭建一个文档审核类 Agent 项目,包括票据识别审核、合同文档解析审核。项目整体用到了 Qwen3-VL-Plus 多模态大模型、LangChain、Pydantic、MinerU、FastAPI 和 React。简单来说,就是把以前人工审核发票、合同这种比较繁琐的工作,拆成“文档解析、结构化提取、规则校验、审核报告生成”几个步骤,然后交给 Agent 自动完成。
1、项目功能介绍
首先先看一下这个项目主要能做什么。DocumentAgent 是一个智能文档审核系统,主要包含两个核心功能:
第一个功能是票据审核。用户上传发票图片之后,系统会自动识别发票里面的发票代码、发票号码、购买方、销售方、金额、税额、商品明细等信息,然后再对这些字段进行完整性、格式、金额计算和业务规则校验。
第二个功能是合同审核。用户上传 PDF 合同之后,系统会先通过 MinerU 解析 PDF,把文本内容和坐标信息提取出来,然后进行文档切分,最后调用大模型按照合同审核规则逐段检查,并输出问题说明、修改建议和审核报告。
项目整体流程大概如下:
票据图片 / PDF文档
↓
多模态模型 / MinerU解析
↓
结构化字段提取
↓
LangChain Agent审核
↓
输出审核结果和修改建议
如下图所示:
2、安装项目环境
首先需要准备 Python 环境,建议使用 Python 3.10 以上版本。因为项目里面用到了 LangChain v1.0、Pydantic v2、FastAPI 等依赖,版本太低的话可能会出现一些兼容问题。
安装核心依赖:
pip install pydantic langchain langchain_openai
如果是运行完整后端项目,进入 backend 文件夹后执行:
cd backend
pip install -r requirements.txt
等待一会,依赖安装完成即可。
3、配置大模型 API Key
本项目里面票据识别使用的是阿里云百炼的 Qwen3-VL-Plus 模型,合同审核可以使用 Qwen-Plus 或 Qwen3-Max 等文本模型。这里需要提前去阿里云百炼控制台申请 API Key。
注册地址:
https://bailian.console.aliyun.com/#/home
配置环境变量:
export DASHSCOPE_API_KEY="your-api-key"
export OPENAI_API_KEY="your-api-key"
export OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
如果是在 Windows 的 cmd 里面运行,可以使用:
set DASHSCOPE_API_KEY=your-api-key
set OPENAI_API_KEY=your-api-key
set OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
注意:这里的 your-api-key 要替换成你自己的 Key,不要直接写别人的。
4、搭建票据识别 Agent
票据审核的第一步,就是先把发票图片里面的信息提取出来。这里使用 Qwen3-VL-Plus 多模态模型,因为它可以同时接收文本提示词和图片数据。
首先导入需要的库:
import os
import re
import json
import base64
import time
from datetime import datetime
from typing import List, Optional
from pydantic import BaseModel, Field, field_validator
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
接下来定义发票里面的商品明细模型。这个模型主要用来保存每一条商品或者服务明细,比如商品名称、数量、单价、金额、税率和税额。
class LineItem(BaseModel):
row: str = Field(..., description="行号")
name: str = Field(..., description="商品或服务名称")
specification: Optional[str] = Field(None, description="规格型号")
unit: Optional[str] = Field(None, description="单位")
quantity: Optional[float] = Field(None, description="数量")
unit_price: Optional[float] = Field(None, description="单价")
amount: float = Field(..., description="金额")
tax_rate: float = Field(..., description="税率")
tax_amount: float = Field(..., description="税额")
@field_validator("row", mode="before")
@classmethod
def convert_row_to_string(cls, v):
return str(v) if v is not None else v
然后再定义完整的发票模型:
class Invoice(BaseModel):
invoice_type: str = Field(..., description="发票类型")
province: Optional[str] = Field(None, description="省份")
invoice_code: str = Field(..., description="发票代码")
invoice_number: str = Field(..., description="发票号码")
issue_date: str = Field(..., description="开票日期")
check_code: Optional[str] = Field(None, description="校验码")
purchaser_name: str = Field(..., description="购买方名称")
purchaser_tax_id: str = Field(..., description="购买方纳税人识别号")
seller_name: str = Field(..., description="销售方名称")
seller_tax_id: str = Field(..., description="销售方纳税人识别号")
total_amount: float = Field(..., description="合计金额")
total_tax: float = Field(..., description="合计税额")
total_amount_with_tax: float = Field(..., description="价税合计")
line_items: List[LineItem] = Field(default_factory=list, description="商品明细")
@field_validator("issue_date")
@classmethod
def validate_date(cls, v):
match = re.search(r"(\d{4})年(\d{2})月(\d{2})日", str(v))
if match:
return f"{match.group(1)}-{match.group(2)}-{match.group(3)}"
return v
这里使用 Pydantic 的好处是,大模型返回 JSON 之后可以直接转换成标准对象。如果模型返回的字段类型不对,也可以提前发现问题。
5、初始化多模态大模型
接下来初始化 Qwen3-VL-Plus 模型:
llm = ChatOpenAI(
model="qwen3-vl-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.1,
)
这里 temperature 建议设置低一点,比如 0.1,这样模型输出会更稳定,比较适合做结构化信息提取。
然后把图片转成 base64:
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
return image_data
构建多模态消息:
def build_multimodal_message(prompt: str, image_base64: str) -> HumanMessage:
return HumanMessage(content=[
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_base64}"
}
}
])
到这里,发票图片就可以传给大模型了。
6、提取发票结构化数据
多模态模型识别完成之后,一般会返回一段 JSON 文本。我们需要把 JSON 提取出来,然后用 Invoice 模型进行验证。
def extract_json_from_response(text: str) -> dict:
try:
return json.loads(text)
except:
pass
json_match = re.search(r"```json\s*\n(.*?)\n```", text, re.DOTALL)
if json_match:
return json.loads(json_match.group(1))
json_match = re.search(r"\{.*\}", text, re.DOTALL)
if json_match:
return json.loads(json_match.group(0))
raise ValueError("无法从模型响应中提取 JSON")
完整流程如下:
def extract_invoice_from_image(image_path: str) -> Invoice:
image_base64 = encode_image(image_path)
message = build_multimodal_message(extraction_prompt, image_base64)
response = llm.invoke([message])
raw_json = extract_json_from_response(response.content)
invoice = Invoice.model_validate(raw_json)
return invoice
执行:
invoice = extract_invoice_from_image("./data/invoice_1.png")
print(invoice.to_json())
如果能正常打印出发票字段,说明票据识别 Agent 就搭建成功了。
7、搭建发票校验 Agent
仅仅把发票信息识别出来还不够,还需要继续校验这些字段是否正确。这里可以把校验逻辑拆成多个 Agent:
- 完整性校验 Agent:检查必填字段是否为空
- 格式校验 Agent:检查发票代码、发票号码、税号、日期格式是否正确
- 计算校验 Agent:检查金额、税额、价税合计是否匹配
- 业务规则校验 Agent:检查税率、发票类型等业务逻辑
先定义校验结果模型:
class ValidationResult(BaseModel):
level: str = Field(..., description="级别: error/warning/info")
field: str = Field(..., description="相关字段")
message: str = Field(..., description="问题描述")
expected: Optional[str] = Field(None, description="期望值")
actual: Optional[str] = Field(None, description="实际值")
suggestion: Optional[str] = Field(None, description="修复建议")
完整性校验示例:
REQUIRED_FIELDS_SPECIAL = {
"invoice_type": "发票类型",
"invoice_code": "发票代码",
"invoice_number": "发票号码",
"issue_date": "开票日期",
"purchaser_name": "购买方名称",
"purchaser_tax_id": "购买方纳税人识别号",
"seller_name": "销售方名称",
"seller_tax_id": "销售方纳税人识别号",
"total_amount": "合计金额",
"total_tax": "合计税额",
"total_amount_with_tax": "价税合计",
}
def validate_completeness(invoice_data: dict):
results = []
for field, desc in REQUIRED_FIELDS_SPECIAL.items():
value = invoice_data.get(field)
if value is None or value == "":
results.append({
"level": "error",
"field": field,
"message": f"必填字段 {desc} 缺失",
"suggestion": f"请补充 {desc} 信息"
})
return results
最后使用一个 Orchestrator 把所有校验 Agent 串起来:
def validate_invoice_complete(invoice_data: dict):
reports = []
reports.append(validate_completeness(invoice_data))
reports.append(validate_format(invoice_data))
reports.append(validate_calculation(invoice_data))
reports.append(validate_business_rules(invoice_data))
return reports
到这里,一个完整的发票审核流程就完成了。
8、为什么合同审核使用 OCR + RAG 方案
接下来再看合同审核。合同、标书、公文这类文档一般都比较长,如果直接把每一页都作为图片丢给多模态模型,token 成本会非常高,而且模型很难返回精确坐标。
所以这里更适合使用 OCR + RAG 的方式:
PDF文档 → MinerU解析 → 提取文本和坐标 → 智能切分 → LLM审核 → 精确定位问题
这样做有几个好处:
- 成本更低。PDF 解析成文本之后,token 数量比图片输入少很多。
- 定位更准。MinerU 可以返回文本块的 bbox 坐标,后面可以直接定位到 PDF 原文位置。
- 更适合长文档。合同可以按照标题、段落和 token 数切分,然后逐段审核。
如下图所示:
9、使用 MinerU 解析 PDF
首先需要启动 MinerU 的解析服务,然后配置服务地址:
export MINERU_API_URL="http://localhost:8080/parse"
解析 PDF 的核心代码如下:
import requests
import json
from pathlib import Path
def parse_pdf_with_mineru(pdf_path: str, output_dir: str = "./temp") -> str:
pdf_path = Path(pdf_path)
output_dir = Path(output_dir)
output_dir.mkdir(exist_ok=True)
with open(pdf_path, "rb") as f:
files = {"file": (pdf_path.name, f, "application/pdf")}
response = requests.post(
os.getenv("MINERU_API_URL", "http://localhost:8080/parse"),
files=files
)
response.raise_for_status()
result = response.json()
output_path = output_dir / f"{pdf_path.stem}.json"
with open(output_path, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
return str(output_path)
MinerU 返回的数据里面一般会包含:
md_content:Markdown 格式的正文内容content_list:每个文本块的坐标信息
其中坐标信息一般类似这样:
{
"text": "解除劳动合同通知书",
"bbox": [359, 95, 638, 120],
"page_idx": 0
}
这个坐标信息非常重要,后面审核出问题之后,就可以知道问题具体出现在第几页、哪个位置。
10、文档切分并保留坐标
长合同不能一次性全部丢给模型,最好先切成多个小片段。这里的切分策略可以是:
- 优先按照一级标题、二级标题、三级标题切分。
- 每个片段控制在 800 tokens 左右。
- 每个片段都保留对应的坐标信息。
大概代码如下:
def estimate_tokens(text: str) -> int:
return len(text) // 2
def split_document_with_coords(md_content: str, content_list: list, max_tokens: int = 800):
chunks = []
current_chunk = []
current_tokens = 0
for line in md_content.splitlines():
line_tokens = estimate_tokens(line)
if current_tokens + line_tokens > max_tokens and current_chunk:
chunks.append("\n".join(current_chunk))
current_chunk = []
current_tokens = 0
current_chunk.append(line)
current_tokens += line_tokens
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
实际项目里面还需要根据文本内容匹配对应的 bbox 坐标,这样审核结果才能回链到原 PDF。
11、构建合同审核 Agent
合同审核 Agent 的核心,是让模型按照固定审核规则输出结构化结果。比如问题描述、原文引用、修改建议、严重程度、法律风险等。
先定义审核结果模型:
class Issue(BaseModel):
rule_category: str = Field(description="规则类别")
description: str = Field(description="问题描述")
original: str = Field(default="", description="原文中有问题的部分")
suggestion: str = Field(default="", description="修改建议")
severity: str = Field(description="严重程度: high/medium/low")
legal_risk: str = Field(default="", description="法律风险说明")
class ModificationMapping(BaseModel):
original: str = Field(default="", description="原文片段")
modified: str = Field(default="", description="修改后的文本")
reason: str = Field(default="", description="修改原因")
rule_ref: str = Field(default="", description="规则编号")
class AuditResult(BaseModel):
has_issues: bool = Field(description="是否发现问题")
issues: List[Issue] = Field(default_factory=list)
modifications: List[ModificationMapping] = Field(default_factory=list)
corrected_text: str = Field(description="修正后的完整文本")
summary: str = Field(description="审核总结")
overall_risk_level: str = Field(description="整体风险等级")
然后初始化审核模型:
llm = ChatOpenAI(
model="qwen3-max",
temperature=0.1,
)
structured_llm = llm.with_structured_output(AuditResult)
再构建 Prompt:
from langchain_core.prompts import ChatPromptTemplate
audit_prompt = ChatPromptTemplate.from_messages([
("system", PROFESSIONAL_SYSTEM_PROMPT),
("user", PROFESSIONAL_USER_PROMPT)
])
audit_chain = audit_prompt | structured_llm
执行审核:
result = audit_chain.invoke({
"rules": PROFESSIONAL_CONTRACT_AUDIT_RULES,
"text": chunks[0]
})
print(result.summary)
print(result.overall_risk_level)
如果能正常输出 summary 和 risk level,说明合同审核 Agent 已经能跑通了。
12、总结
到这里,一个基于 LangChain v1.0 的文档审核类 Agent 项目就搭建完成了。整体来看,票据审核更适合使用多模态大模型直接识别图片,然后通过多个校验 Agent 做规则审核;合同审核更适合使用 OCR + 坐标解析 + 文档切分 + LLM 审核的方案,这样成本更低,也更容易定位原文问题。
这个项目的重点不是简单调用一次大模型,而是把文档审核拆成了多个可以落地的环节:解析、抽取、校验、审核、定位和报告生成。后面如果继续扩展,还可以加入更多企业内部规则、法务知识库、PDF 高亮批注和人工复核流程。
13、系统实现
用fastapi+react实现该智能文档审核系统,首先是主界面: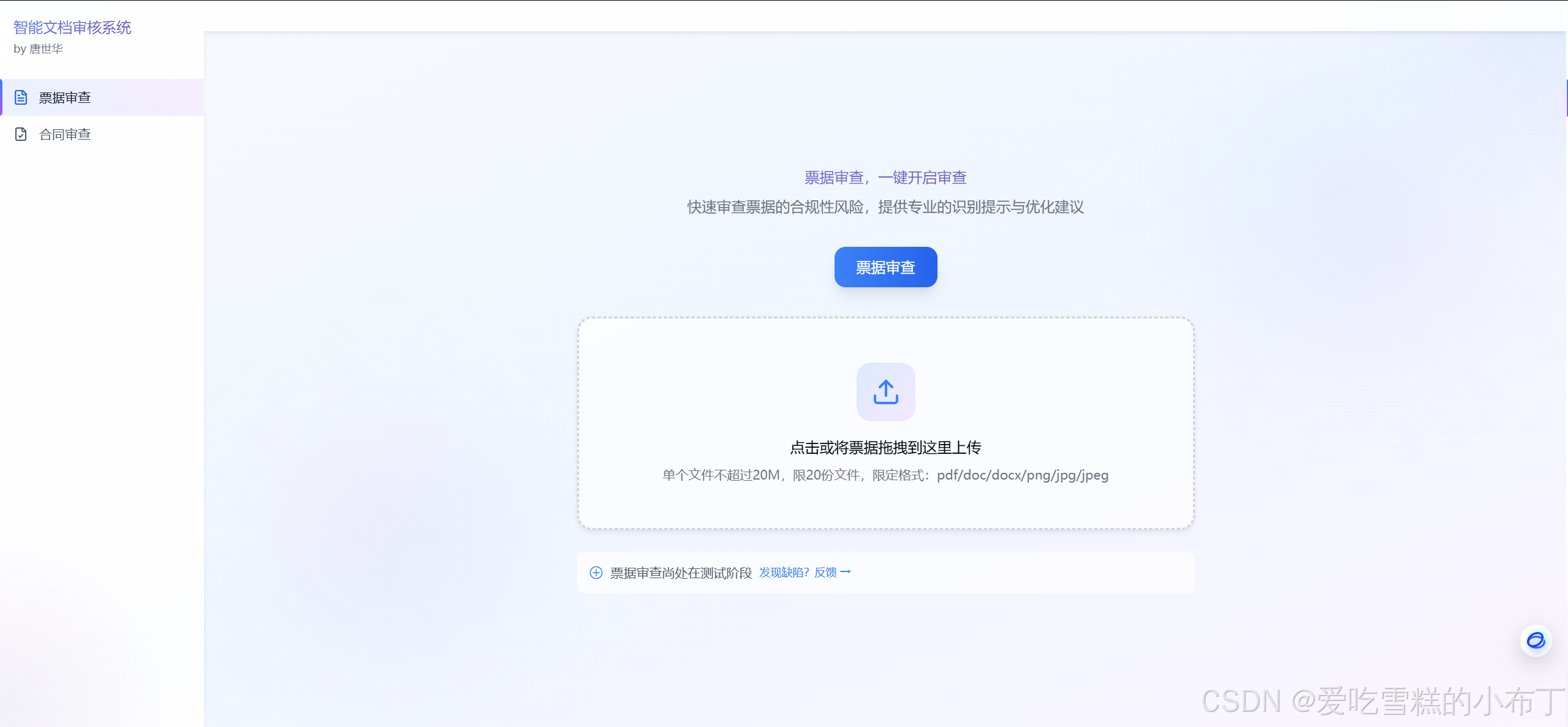
上传票据,识别中: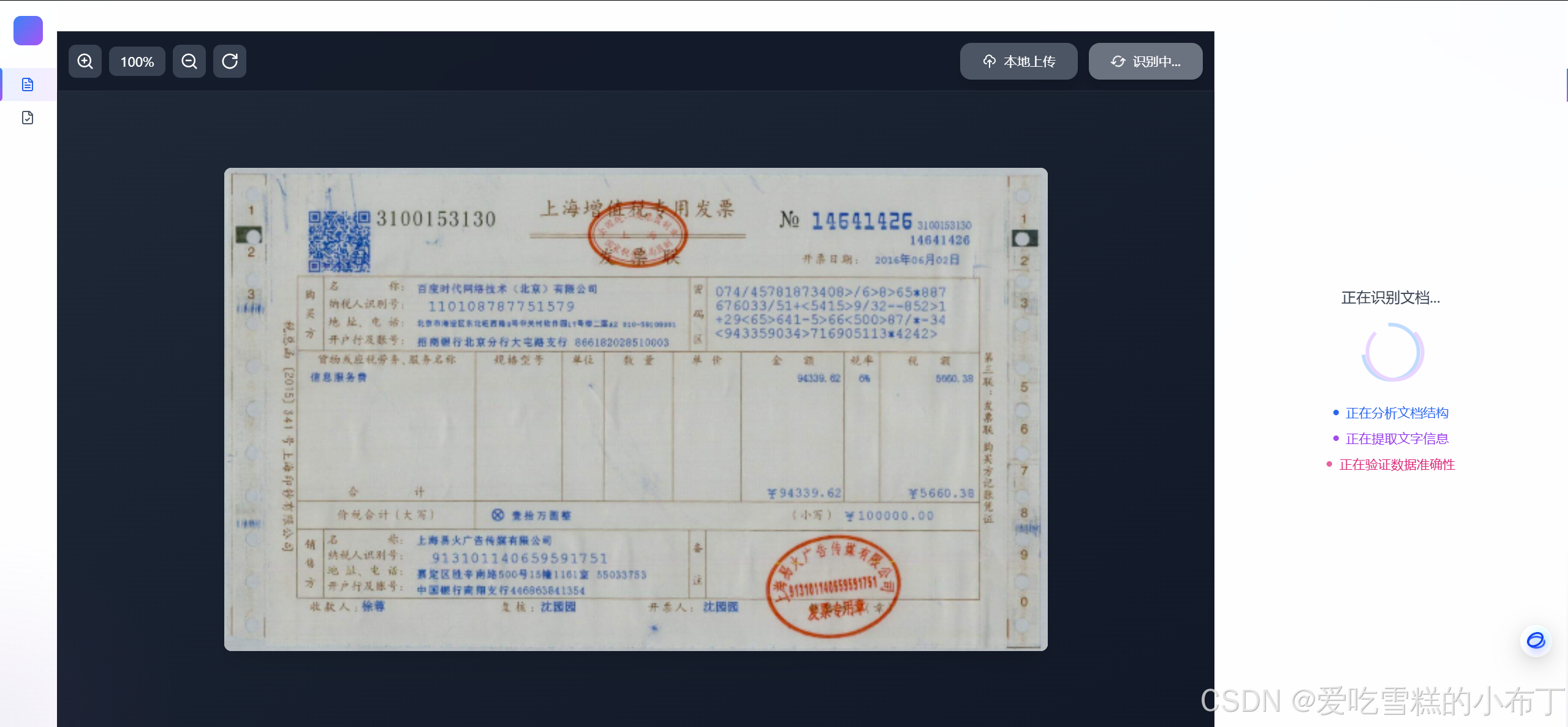
识别成功:
审查结果: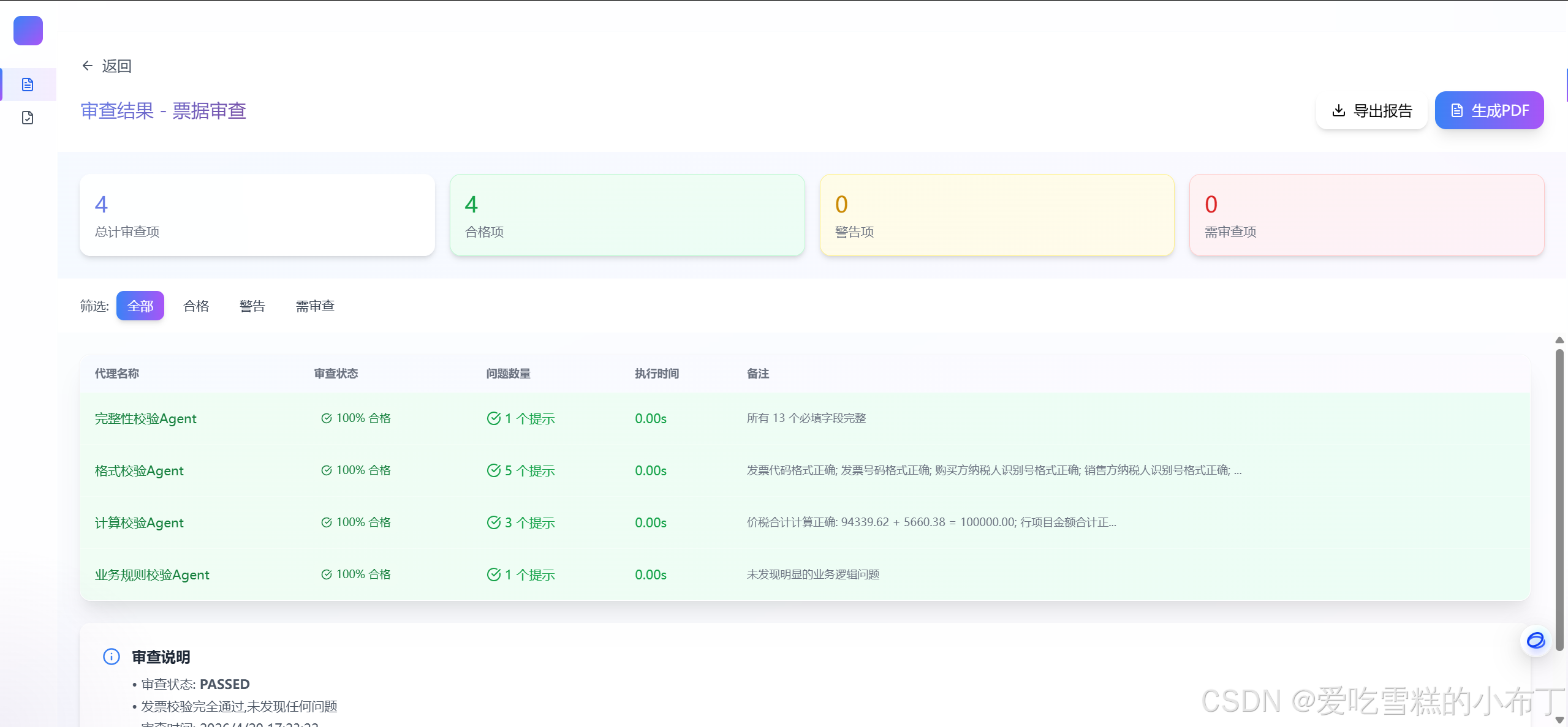

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)