Karpathy LLM-wiki 技术原理与个人知识库构建实践
目录
文章目录
传统 RAG 存在的问题
现在主流的知识库(如 ChatGPT 文件上传、NotebookLM)都是基于 RAG 技术的:上传文档,提问,AI 检索相关片段,生成回答。
Karpathy 觉得这个方式有个致命问题:没有积累。对于每次新的提问,LLM 都得从原始文档里重新找、重新拼。问完了,答案就没了,下次还得重新推导一遍。知识从来没有被真正沉淀下来。
Karpathy LLM-wiki 新方案的理念
Karpathy LLM-wiki 方案的核心思想是:不要把 LLM 当搜索引擎用,让它像程序员维护代码库一样帮你持续维护一个 Markdown Wiki —— 一个结构化的、互相链接的 Markdown 文件集合。
也就是说,让 LLM 不是每次从原始文档里检索,而是持续地、增量式地构建和维护一个 Wiki。当你往里面添加一个新的资料来源,LLM 不是简单地把它索引进去等着以后被检索。而是它会读这个资料,提取关键信息,然后把信息整合进已有的 Wiki 里,包括:更新相关实体的页面、修正主题摘要、标注新数据和旧结论的矛盾之处。
如此的,LLM-Wiki 成为了一个持久的、可复利增长的资产。交叉引用已经建好了,矛盾已经标记出来了,综合分析已经反映了你读过的所有内容。每加一个新来源、每问一个好问题,Wiki 都会变得更丰富。
Karpathy 的实践表明,在中等规模的数据集上,LLM 本身已经具备足够强的 “自检索” 与 “自组织” 能力。这意味着,一部分复杂的系统设计,可能正在被模型能力的提升所 “吞噬”。
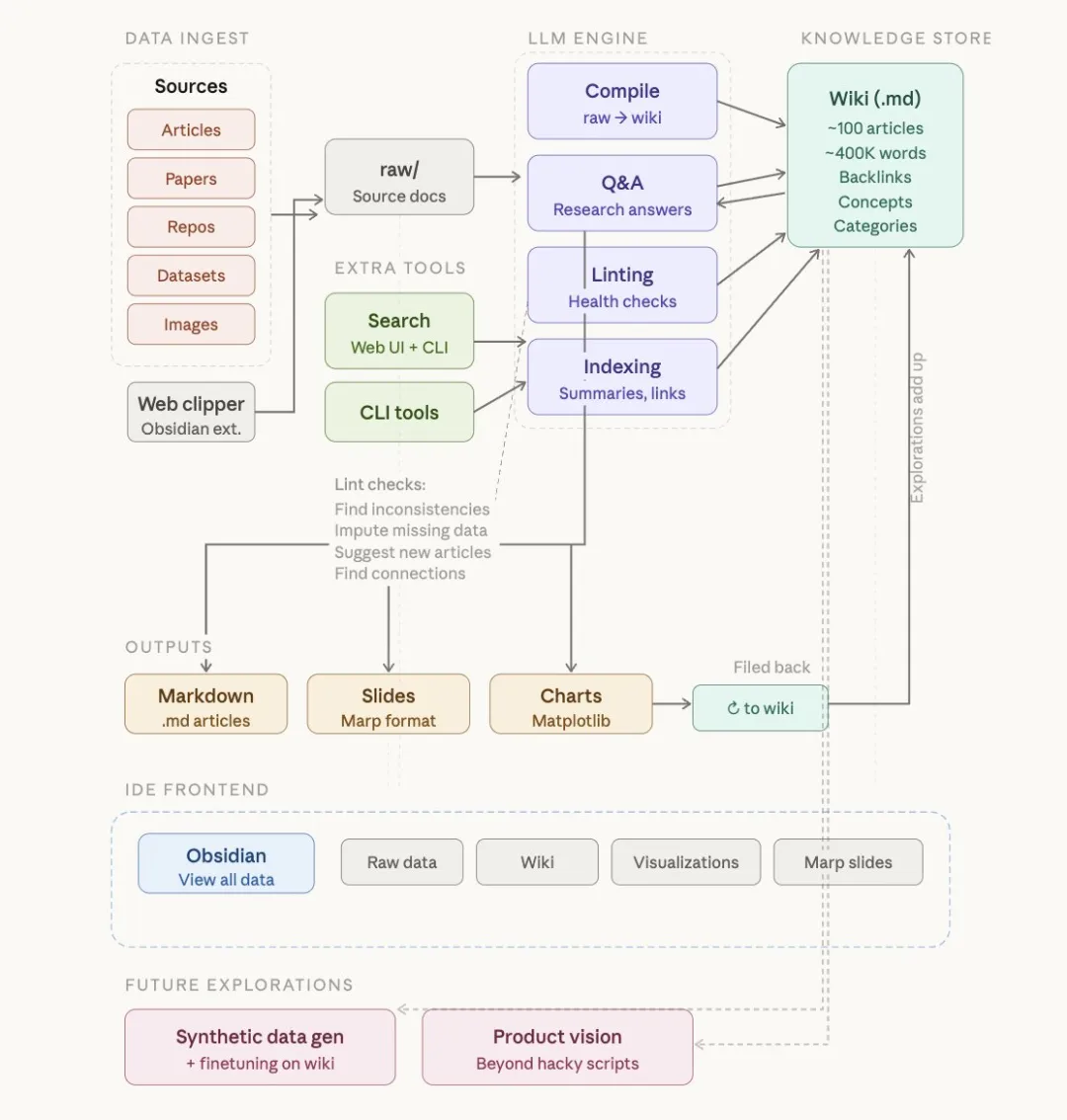
三层架构
- 第一层是 Raw Sources,原始资料层。你收集的论文、文章、图片、数据文件都放这儿。这层是不可变的,LLM 只读不写,这是你的搞到的原始数据来源。
- 第二层是 The Wiki,知识库层。这是 LLM 生成的 Markdown 文件目录,包括摘要、实体页面、概念页面、对比分析、综述等等。这层完全由 LLM 拥有和维护,你读它,LLM 写它。
- 第三层是 The Schema,规则文件。它告诉 LLM 这个 Wiki 怎么组织、用什么约定、录入来源和回答问题时遵循什么流程。对 Claude Code 来说就是 CLAUDE.md,对 Codex 来说就是 AGENTS.md。这是关键的配置文件,让你和 LLM 随着使用不断迭代优化。
三个核心操作
- 第一个是 Ingest,录入。你往原始资料目录里丢一个新文件,让 LLM 处理。LLM 会读这个资料、跟你讨论要点、在 Wiki 里写一个摘要页、更新索引、更新相关的实体和概念页面。一个来源可能牵动 10 到 15 个 Wiki 页面的更新。Karpathy 说他喜欢一个一个录入,边录边看,引导 LLM 重点关注意什么。
- 第二个是 Query,提问。你对着 Wiki 提问,LLM 搜索相关页面后综合回答。回答的形式可以很多样:Markdown 页面、对比表格、Marp 幻灯片、matplotlib 图表都行。好的回答可以回存到 Wiki 里,变成新的页面。这样你每次的探索和提问都在持续丰富知识库,知识在复利增长。
- 第三个是 Lint,体检。定期让 LLM 对 Wiki 做健康检查。找页面之间的矛盾、被新资料取代的过时信息、没有入链的孤儿页面、提到但没有独立页面的重要概念、缺失的交叉引用。LLM 还很擅长建议你应该去研究什么新问题、找什么新资料。这一步保证 Wiki 在增长过程中保持健康。
索引与日志
index.md 做内容目录,log.md 做时间线日志。
两个特殊文件帮助 LLM(和你)在 Wiki 扩大后依然能高效导航,二者用途不同:
-
index.md 是内容导向的。它是整个 Wiki 的目录。每个页面都附有链接、一句话摘要,以及可选的元数据(如日期、资料来源数量),按类别组织(实体、概念、来源等)。LLM 在每次录入时更新它。回答问题时,LLM 先读索引找到相关页面,再深入阅读。在中等规模(约 100 份资料、数百个页面)下,这套方式效果出奇地好,也无需搭建基于向量嵌入的 RAG 基础设施。
-
log.md 是时间导向的。它是一份只追加不修改的操作记录,记录发生了什么、发生在什么时候。包括录入、查询、检查等操作。一个实用技巧:如果每条记录以固定前缀开头(例如
## [2026-04-02] ingest | 文章标题),日志就变得可以用简单的 Unix 工具来处理,例如:grep "^## \[" log.md | tail -5就能列出最近 5 条记录。日志给你提供了 Wiki 演进的时间线,也帮助 LLM 了解最近做过什么。
实操构建自己的 LLM-wiki 知识库
LLM-Wiki 的实践很简单,因为 Karpathy LLM-wiki 的本质就是一个 “理念”,安装好 Claude Code 和 Obsidian 之后,创建一个新目录,再让 Claude Code 帮你自动构建即可。
- Gist 地址:gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
提示词如下:
基于 gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 的内容,帮我复现 Karpathy LLM-wiki 的效果,我这个个人wiki的研究主题是大模型相关的技术。
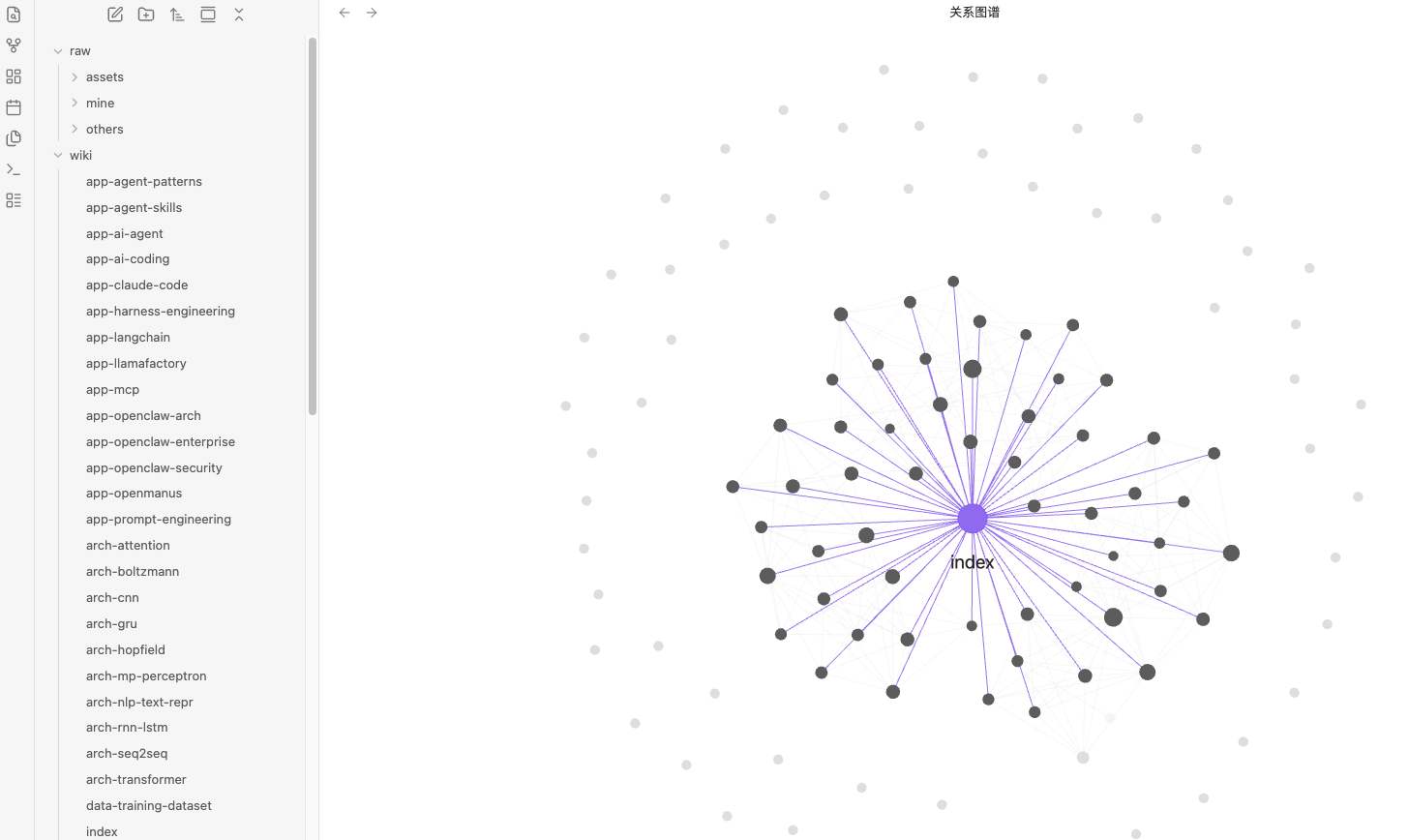
使用时,我们只需要一边开着 Claude Code、一边开着 Obsidian。然后把各种原始素材(文章、论文、代码库、数据集等)放入到 raw/ 目录下,再让 LLM 把这些素材 “编译” 成一个结构化的 Markdown Wiki。过程中,LLM 会根据 raw 素材实时更新 Wiki,人可以在 Obsidian 里实时浏览结果。打开 “关系图谱” 然后跟着图谱视图和链接点点看、读读更新后的 wiki 页面。
用 Karpathy 的话说:Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。
特别注意
特别需要注意的是,个人知识库是为了让知识有用,而不是为了画一张好看的 “知识图谱”。在 Karpathy 的理念里,人的学习和判断贯穿始终,如果仅仅是把文章丢进 Obsidian,那么和疯狂收藏文章却不阅读它没有区别。
所以在使用 LLM-wiki 的过程中,最重要的事掌握一种 “知识管理” 工具和方法论。而真正的知识管理是一个过程,是信息从输入到加工、再到内化的一整个闭环过程。需要人类来进行学习、判断、提问、提炼。
LLM-wiki 原文(中文)
一种使用 LLM 构建个人知识库的模式。
这是一份理念文档,设计用于直接复制粘贴给你的 LLM Agent(如 OpenAI Codex、Claude Code、OpenCode/Pi 等)。它的目标是传达高层次的核心思想,具体细节由你的 Agent 与你协作来落地。
核心思想
大多数人使用 LLM 处理文档的方式类似 RAG:上传一批文件,LLM 在查询时检索相关片段,然后生成答案。这种方式可用,但 LLM 每次回答问题时都在从零重新发现知识,没有任何积累。如果问一个需要综合五份文档的细微问题,LLM 每次都得重新找到并拼凑相关片段,什么都没有沉淀。NotebookLM、ChatGPT 文件上传以及大多数 RAG 系统都是这样工作的。
这里的思路不同。与其在查询时从原始文档中检索,LLM 会持续构建并维护一个永久性的 wiki —— 一组结构化、相互关联的 Markdown 文件,作为你和原始资料之间的知识中间层。当你添加一个新来源时,LLM 不只是为日后检索建立索引,而是读取它,提取关键信息,并将其整合进现有的 wiki —— 更新实体页面、修订主题摘要、标注新数据与旧论断的矛盾之处,不断强化或挑战已形成的知识综合体。知识只编译一次,然后保持持续更新,而不是每次查询时重新推导。
这是关键区别:wiki 是一个持久、复利积累的产物。 交叉引用已经建立好了。矛盾已经被标记出来了。知识综合体已经反映了你读过的一切。每添加一个来源、每提出一个问题,wiki 都会变得更丰富。
你从不(或很少)自己编写 wiki —— LLM 负责编写和维护所有内容。你负责来源的筛选、探索方向的把控以及提出有价值的问题。LLM 承担所有繁琐的工作 —— 摘要、交叉引用、归档,以及让知识库真正有价值的日常维护。在实践中,我会把 LLM Agent 和 Obsidian 并排打开:LLM 根据我们的对话做出修改,我实时浏览结果 —— 跟着链接跳转,查看知识图谱,阅读更新后的页面。Obsidian 是 IDE,LLM 是程序员,wiki 是代码库。
这种模式可以适用于很多不同的场景,举几个例子:
- 个人成长:追踪自己的目标、健康、心理、自我提升 —— 归档日记、文章、播客笔记,逐步构建出关于自己的结构化图景。
- 深度研究:在数周或数月内深入研究某个主题 —— 阅读论文、文章、报告,持续构建一个拥有不断演进核心论点的全面 wiki。
- 阅读一本书:边读边归档每一章,为人物、主题、情节线索及其关联建立页面。读完时,你已经拥有一个丰富的配套 wiki。想想 Tolkien Gateway 那样的粉丝 wiki —— 数千个相互关联的页面,覆盖人物、地点、事件、语言,由志愿者社区耗时多年建成。你可以在阅读时亲手打造类似的东西,由 LLM 处理所有交叉引用和维护工作。
- 商业/团队:由 LLM 维护的内部 wiki,以 Slack 讨论串、会议记录、项目文档、客户通话为输入,必要时有人工审核更新。wiki 之所以能保持最新,是因为 LLM 承担了团队中没人愿意做的维护工作。
- 竞品分析、尽职调查、旅行规划、课程笔记、兴趣深潜 —— 凡是需要随时间积累知识、并希望知识有条理而非零散的场景,都适用。
架构
共三层:
原始来源(Raw sources) —— 你精心筛选的原始文档集合:文章、论文、图片、数据文件。这一层不可变 —— LLM 只读不写。这是你的信息真实来源。
Wiki —— 一个存放 LLM 生成的 Markdown 文件的目录:摘要、实体页面、概念页面、对比分析、总览和综合论述。LLM 完全拥有这一层:创建页面、在新来源加入时更新页面、维护交叉引用、保持一致性。你来阅读,LLM 来书写。
Schema(纲要文件) —— 一份告诉 LLM wiki 结构、约定规范和工作流程的配置文档(如 Claude Code 用的 CLAUDE.md,或 Codex 用的 AGENTS.md)。这是核心配置文件 —— 正是它让 LLM 成为一个有纪律的 wiki 维护者,而不是泛用聊天机器人。你和 LLM 会随着实践的推进共同演进这份文档,找到最适合你的方式。
操作流程
Ingest(摄入):将新来源放入原始集合,告知 LLM 处理它。示例流程:LLM 读取来源,与你讨论关键收获,在 wiki 中撰写摘要页,更新索引,更新 wiki 中相关的实体和概念页面,并在日志中追加条目。一个来源可能触及 10-15 个 wiki 页面。我个人倾向于一次摄入一个来源并全程参与 —— 阅读摘要,检查更新,引导 LLM 侧重哪些内容。但你也可以一次批量摄入多个来源,较少介入。具体取决于你,把适合自己的工作流程记录在 schema 中供以后的会话参考。
Query(查询):对 wiki 提问。LLM 搜索相关页面,读取内容,综合生成带引用的回答。回答的形式可以多样,取决于问题 —— Markdown 页面、对比表格、幻灯片(Marp)、图表(matplotlib)、画布。重要的洞见:好的回答可以作为新页面归档回 wiki。 你询问的一次对比分析、一个发现的关联 —— 这些都有价值,不应消失在聊天记录里。这样,你的探索就像摄入的来源一样,在知识库中持续复利积累。
Lint(健康检查):定期让 LLM 对 wiki 做健康检查,寻找:页面间的矛盾之处、被新来源取代的过时论断、没有入站链接的孤立页面、被提及但缺乏专属页面的重要概念、缺失的交叉引用、可通过网络搜索填补的知识空白。LLM 很擅长建议值得深入调查的新问题和值得寻找的新来源,让 wiki 随增长保持健康。
索引与日志
两个特殊文件帮助 LLM(和你)在 wiki 增长时导航:
index.md 以内容为导向,是 wiki 中所有内容的目录 —— 每个页面都有链接、一句话摘要,以及可选的元数据(如日期或来源数量),按分类组织(实体、概念、来源等)。LLM 在每次摄入时更新它。回答查询时,LLM 先读索引定位相关页面,再深入阅读。这种方式在中等规模(约 100 个来源、数百个页面)下效果出奇地好,也避免了引入基于 Embedding 的 RAG 基础设施的需要。
log.md 以时间为导向,是所有操作(摄入、查询、健康检查)的只追加记录,记录发生了什么以及何时发生。一个实用技巧:如果每条记录以统一前缀开头(如 ## [2026-04-02] ingest | 文章标题),日志就可以用简单的 Unix 工具解析 —— grep "^## \[" log.md | tail -5 即可获取最近 5 条记录。日志为你呈现 wiki 演进的时间线,也帮助 LLM 了解最近做了什么。
可选:CLI 工具
到某个阶段,你可能想构建小工具帮助 LLM 更高效地操作 wiki。最显而易见的是 wiki 页面搜索引擎 —— 小规模时索引文件已够用,但随 wiki 增长你会需要真正的搜索能力。qmd 是一个不错的选择:它是针对 Markdown 文件的本地搜索引擎,支持 BM25/向量混合搜索和 LLM 重排序,完全本地运行,提供 CLI(LLM 可通过 shell 调用)和 MCP Server(LLM 可作为原生工具使用)两种接口。你也可以自己构建更简单的方案 —— LLM 可以帮你"随手写"一个简易搜索脚本,按需而为。
技巧与建议
- Obsidian Web Clipper 是一个浏览器扩展,可将网页文章转换为 Markdown,非常适合快速将来源纳入原始集合。
- 本地下载图片:在 Obsidian 设置 → 文件与链接中,将"附件文件夹路径"设为固定目录(如
raw/assets/);在设置 → 快捷键中搜索"Download",找到"下载当前文件的附件"并绑定快捷键(如 Ctrl+Shift+D)。剪藏文章后按快捷键,所有图片即下载到本地。这是可选的,但有用 —— 让 LLM 可直接查看和引用图片,而不必依赖可能失效的 URL。注意 LLM 无法一次性原生读取带内联图片的 Markdown —— 解决方案是先让 LLM 读取文本,再单独查看部分或全部引用的图片以获取额外上下文。这稍显繁琐,但效果足够好。 - Obsidian 的知识图谱视图是了解 wiki 整体形态的最佳方式 —— 什么与什么相连,哪些页面是枢纽,哪些是孤立节点。
- Marp 是基于 Markdown 的幻灯片格式,Obsidian 有对应插件,可直接从 wiki 内容生成演示文稿。
- Dataview 是 Obsidian 插件,可对页面的 YAML frontmatter 执行查询。如果 LLM 为 wiki 页面添加了 frontmatter(标签、日期、来源数量),Dataview 就能生成动态表格和列表。
- Wiki 本质上就是一个 Markdown 文件的 Git 仓库,版本历史、分支和协作能力开箱即用。
为什么这种方式有效
维护知识库最繁琐的部分不是阅读或思考,而是日常的管理维护工作:更新交叉引用、保持摘要的时效性、标注新数据与旧论断的矛盾、在数十个页面间保持一致性。人们放弃 wiki 是因为维护成本的增长速度超过了知识价值的增长速度。LLM 不会感到厌倦,不会忘记更新交叉引用,一次就能处理 15 个文件。wiki 得以持续维护,因为维护成本趋近于零。
人的工作是:筛选来源,引导分析,提出好问题,以及思考这一切意味着什么。LLM 的工作是:其他一切。
这个思路在精神上与 Vannevar Bush 的 Memex(1945 年)有相通之处 —— 一个带有文档间关联路径的个人知识储存系统。Bush 的构想比今天的 Web 更接近这里描述的东西:私密的、主动策管的,文档之间的连接与文档本身同等重要。他当年没能解决的问题是:谁来做这些维护工作。LLM 解决了这个问题。
说明
这份文档有意保持抽象,它描述的是理念,而非具体实现。确切的目录结构、schema 约定、页面格式、工具选择 —— 这一切都取决于你的研究领域、个人偏好以及所使用的 LLM。上述所有内容都是可选且模块化的 —— 取用有用的,忽略无关的。例如:你的来源可能纯文字,完全不需要图片处理;你的 wiki 可能足够小,索引文件已绰绰有余,无需搜索引擎;你可能对幻灯片毫无兴趣,只想要 Markdown 页面;你可能想要一套完全不同的输出格式。使用这份文档的正确方式,是把它分享给你的 LLM Agent,然后一起实例化出一个契合你需求的版本。这份文档唯一的工作,是传达这个模式。你的 LLM 会搞定其余的一切。
参考文档
- https://mp.weixin.qq.com/s/ueCIydLLACyqGP5SrAhpjQ

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)