LLM、Agent 和 transformer 学习笔记
相关最基础AI名词
- 人工智能 AI artificial intelligence
- 生成式人工智能 GAI generative artificial intelligence eg:chatgpt\deepseek
- 机器学习 ML machine learning 监督学习(supervised learning)(给机器-有标注(labeled)数据(有答案))、非监督学习(给机器-无标注数据-期望机器补全答案)
- 深度学习 DL deep learning 正反馈、负反馈
- 神经网络(分层模型) NN neural network
- transformer 一种架构
- 大语言模型 LLM large langugae mode
- 智能体 Agent

应用场景
自然语言处理 NLP Natural Language Processing
NLP is a branch of AI.
NLP的应用场景:
- 情感分析
- 文本归类
- 信息抽取 语义聚类
- 数学问题
- 角色扮演
- 编程问题
- 创作问题
语音处理 SLP Speech language processing
图像处理 Image Processing
hugging face ai届的github
包含 数据集、模型、工具包
gradio web界面直观展示函数、API和模型
提示工程 prompt engeering
通过优化 提示词和生成策略,从而获得更好的 返回结果的 技术。
prompt -> LLM -> completion
提示词的构成
提示 instruction
上下文 context
例子 example 样本学习 shot learning
输入 input
输出 output
query
思维链-逐步思考 思维树-分类思考
Chain of Throught/ Tree of Throught
RAG
为什么需要
- 知识过时
- 幻觉问题
- 缺乏特定领域知识(公司内部,加密文档(医疗、保险))
数据脱敏有时候,依然无法公开
含义:检索增强生成
是一种 信息检索和生成模型 的新型架构
核心思想:利用外部知识库,为大模型提供 实时、准确的背景信息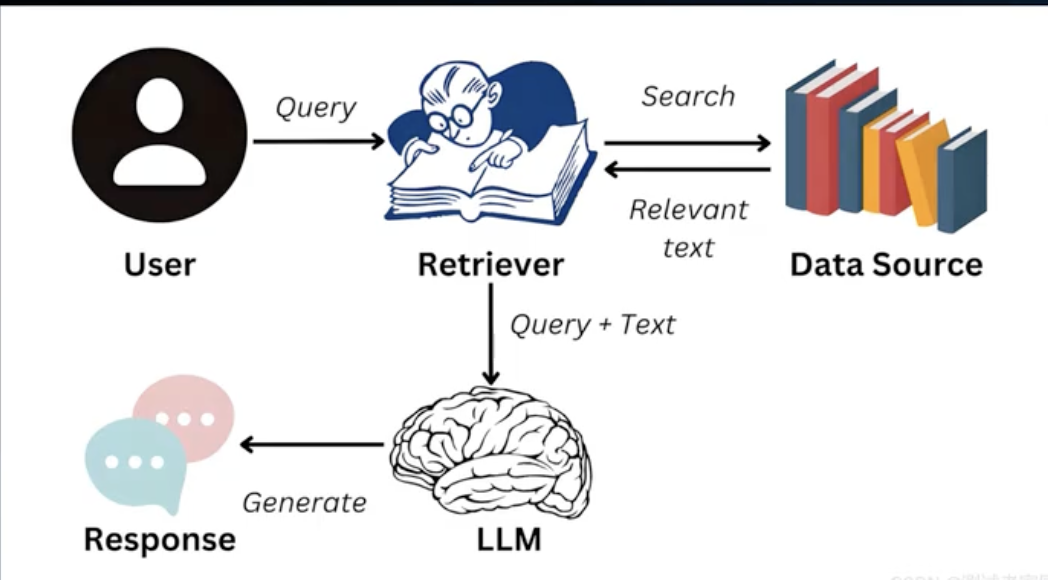
组成
- 检索模块:知识库中检索 输入问题相关 的文档或片段
- 生成模块:基于检索结果和原始输入,通过大模型 生成 准确、丰富的回答。
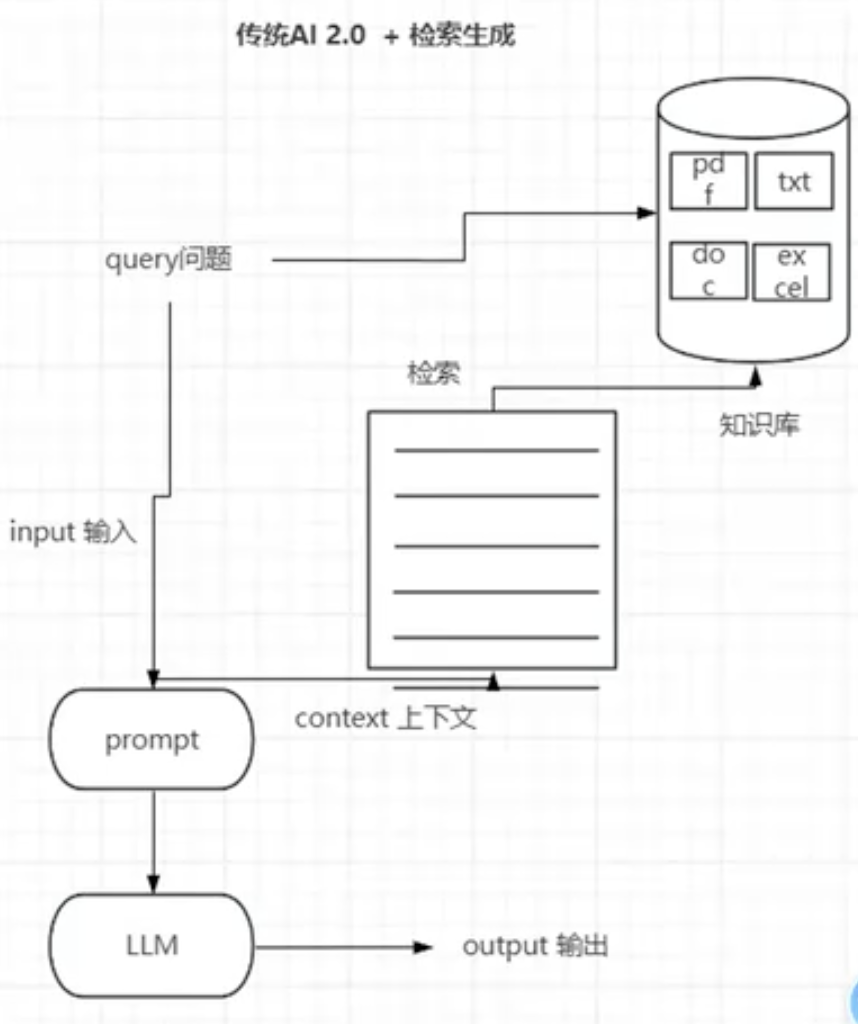
文本分割
- 句子
- 字符数:不连贯
- 固定字符:
- 递归
- 语义
文本向量化
向量(embedding)
视频中选择的是:阿里的 通义千问的向量模型
记着用完了,关闭免费额度
向量相似度计算
余弦距离cosine :基于两个向量夹角的 余弦值 来衡量 向量相似度。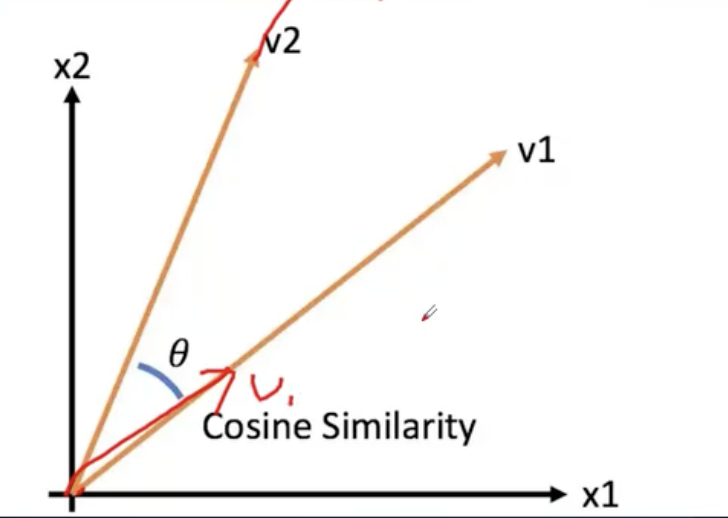
对于两个 二维向量 a=(a1,a2), b=(b1,b2) 的余弦相似度 计算公式:
余弦相似度的取值范围:-1 ~ 1
- 1: 相同,0度,越接近1 相似度越高
- 0: 正交(约等于直角),无相关性
- -1: 相反,180度,完全相反
向量数据库 vector database 矢量数据库
用来储存 和 检索 数据
作用:
- 单独比较
- 索引
- 近似搜索 approximate search/approximate nearest neighbor search
- LSH 局部敏感哈希
- LVF 倒排文档 + PQ 乘积量化
- HNSW
- DiskANN
索引方法
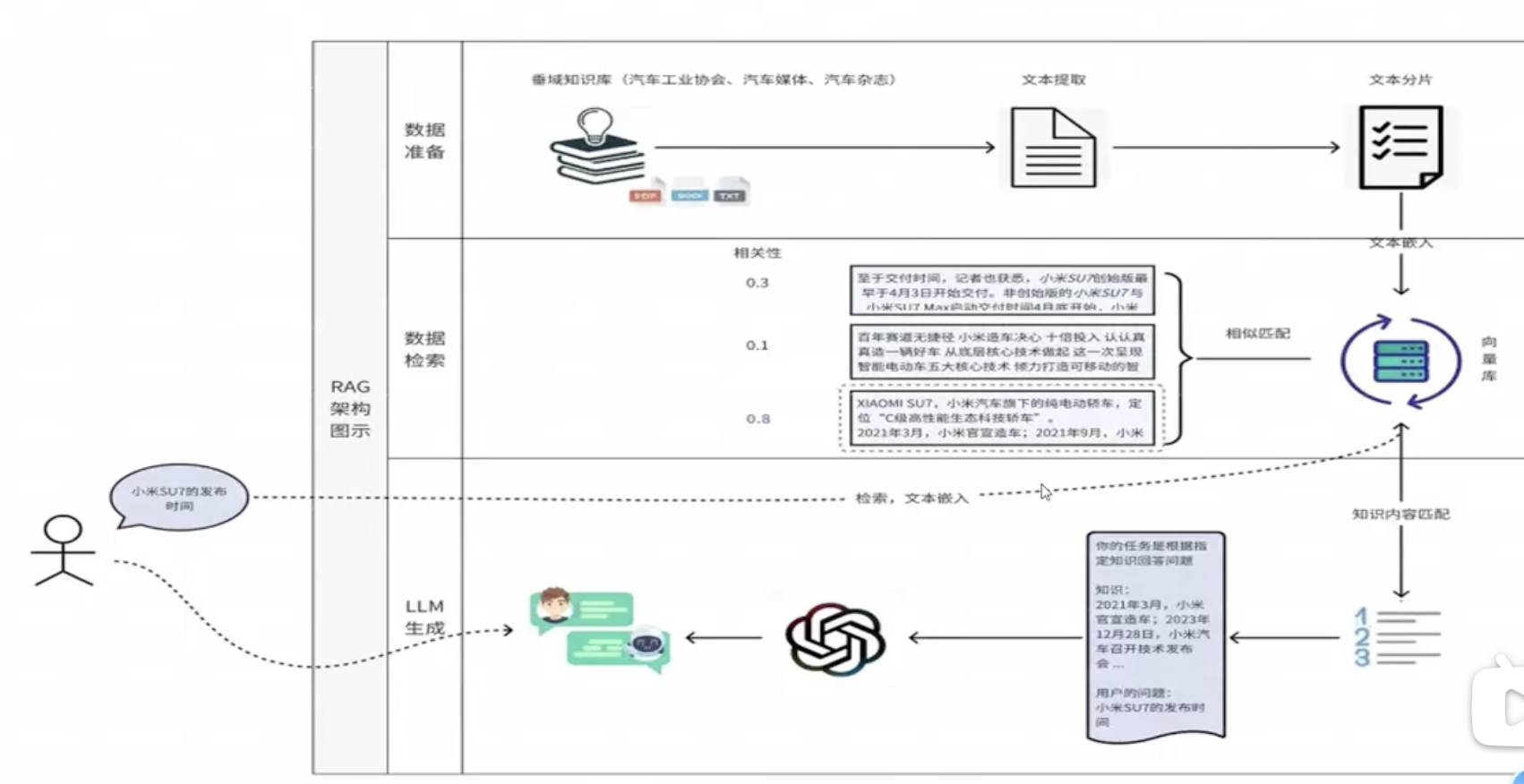
RAG 搜索技术
之前是向量相似度查询
倒排索引–文本快速搜索
是常见的 向量数据库 索引结构
用于快速定位 和 查询 向量相似度 的数据项
通过构建一个映射,将每个向量的特征值 与 包含该特征值的向量 关联起来
当查询一个向量时,可以通过 倒排索引 快速找到 包含相似特征值的向量。
向量化之前,需要tokenization(分词:将文本分割成离散单元的过程)
KNN 近邻搜索 K Nearest Neighbor
K 近邻搜索,将查询语句 转换为向量,然后再求 该向量与数据库中的 向量相似度最高,向量距离最近的向量集。
brute forece search
暴力搜索/穷举搜索,是最简单直接的方法。
通过计算 查询向量 与 数据库中每一个向量的距离,来 评估 向量之间的相似度,最终,算法会 选择 最近的 k 个数据,作为 查询向量 的最近k个邻居,简称 KNN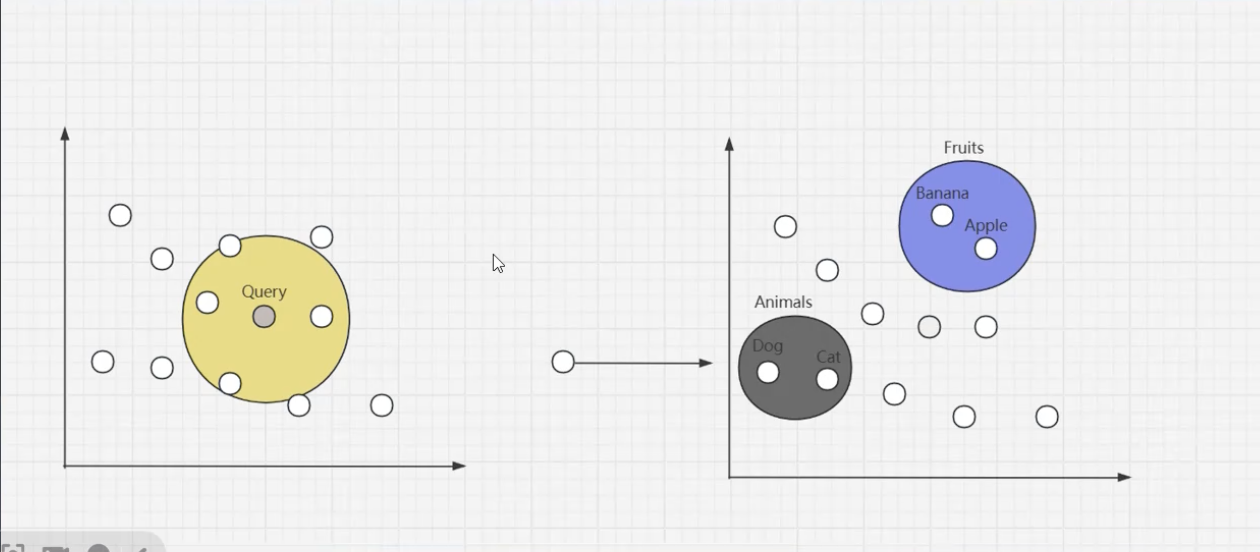
ANN是KNN的增强版 左K右A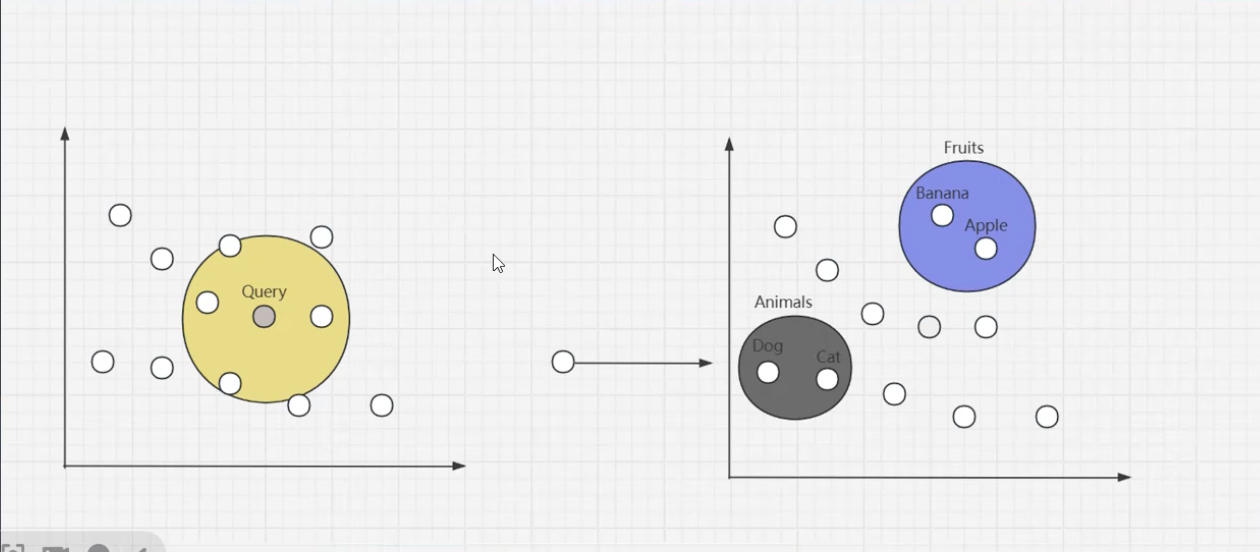
ANN 近似近邻算法 Approximate Nearest Neighbor
算法核心是 权衡 检索的 精度和效率,
通过牺牲 一小部分精度, 来显著 提升效率
通过构建 专门的索引结构,ANN能 有效 缩小 搜索空间,而不是 对整个数据库 进行比较,从而快速 定位到 与 查询向量 近似的结果
ANN算法实现
- Tree-based index 基于 树的索引
- Cluster-based index 基于 聚类的索引----空间分块
- Graph-based index 基于 图的索引

Cluster-based index 聚类索引
step 1: 空间分块
step2: 边缘问题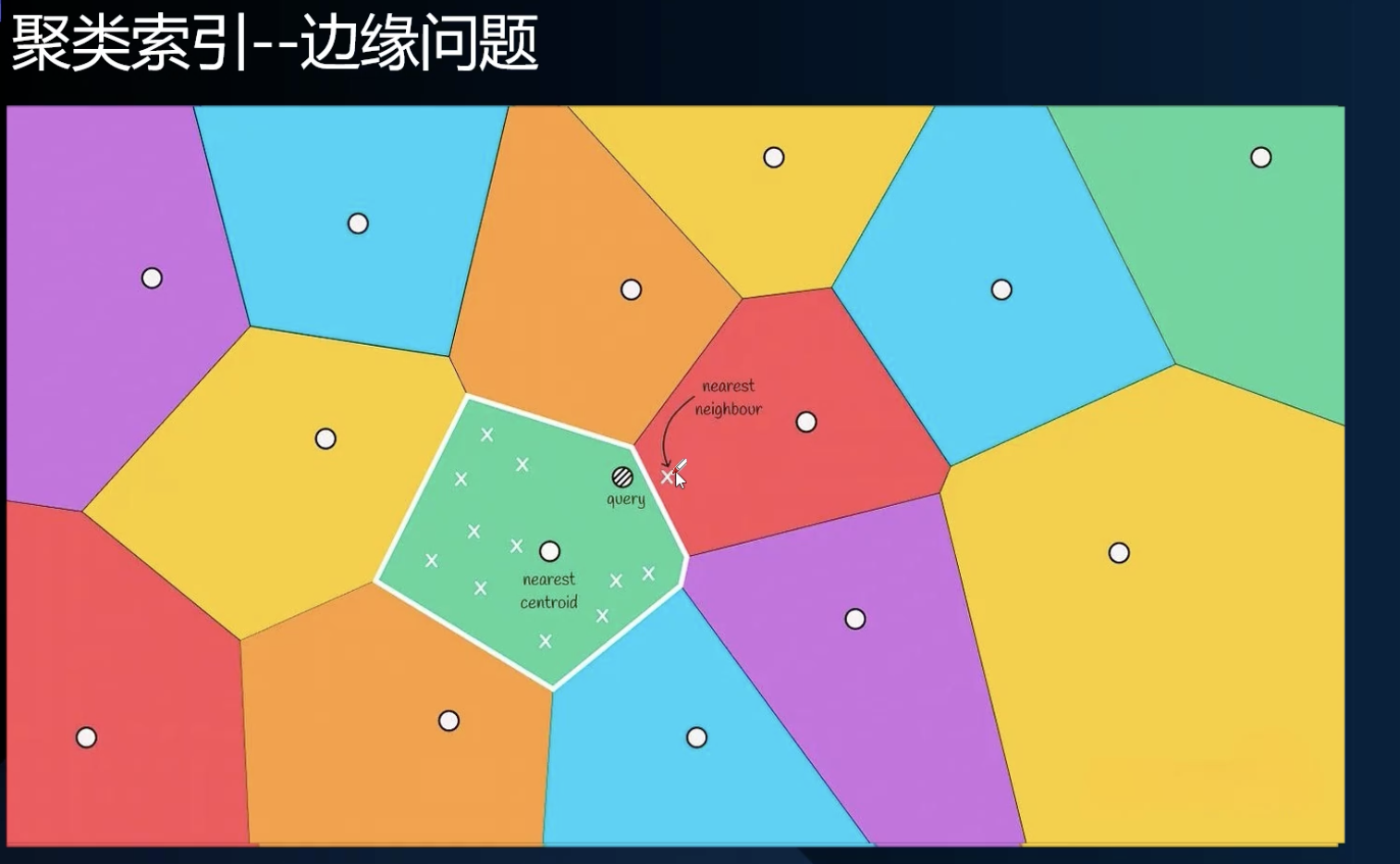
step3:扩大搜索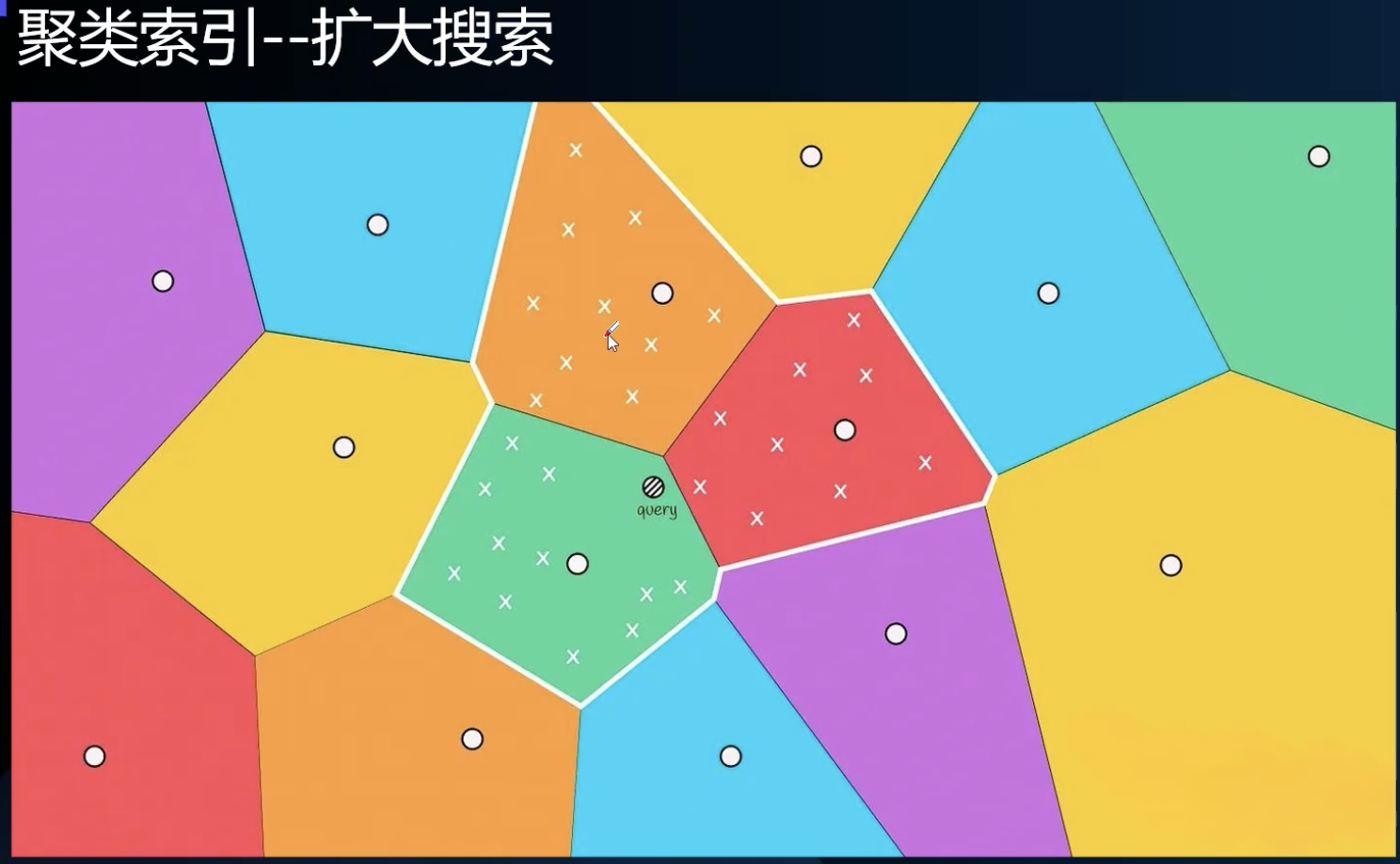
欧式距离 欧几里德距离 Euclidean distance
最常见的距离度量,
衡量的是 多维空间中的两个点的 绝对距离
公式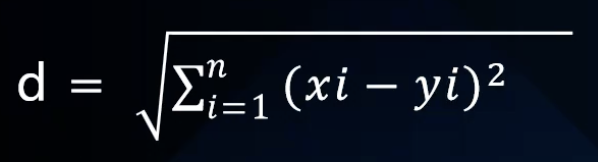
倒排索引 vs KNN 的应用

PQ 乘积量化 Product Quantization
PQ 属于 ANN
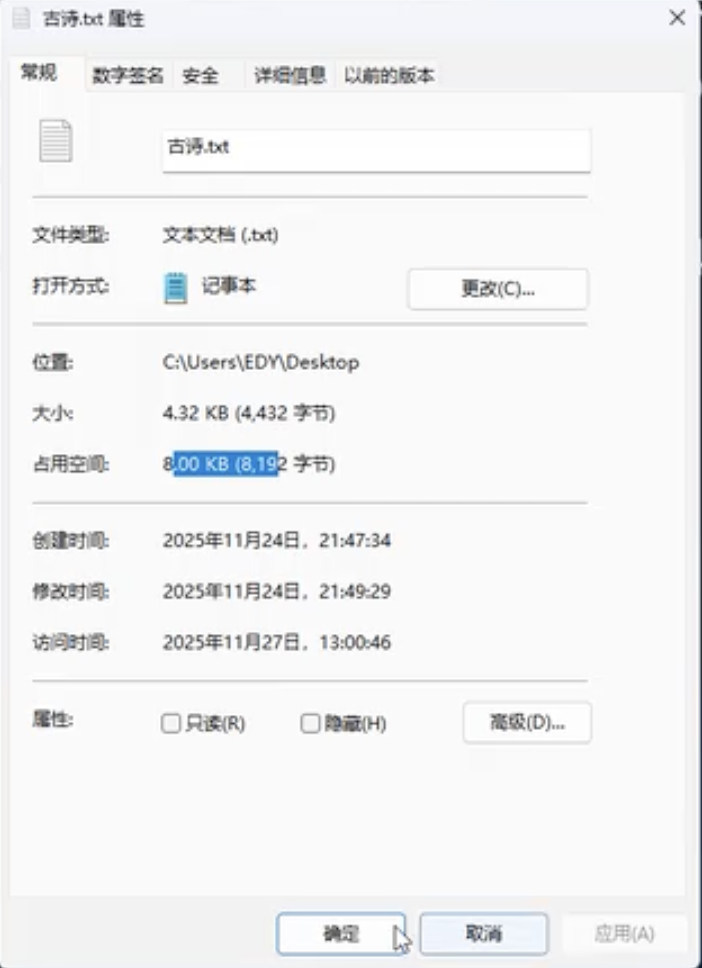
一般默认的向量维度 是 1024维。
那么,一个1024维度的向量有多大? 一般4KB
- 向量一般用 单精度浮点数 表示
- 单精度浮点数 占 32bit
- 1024 * 32 / 8 = 4096 byte 字节= 4KB
4KB 读写:不足 4KB,按4KB占用空间,如下图: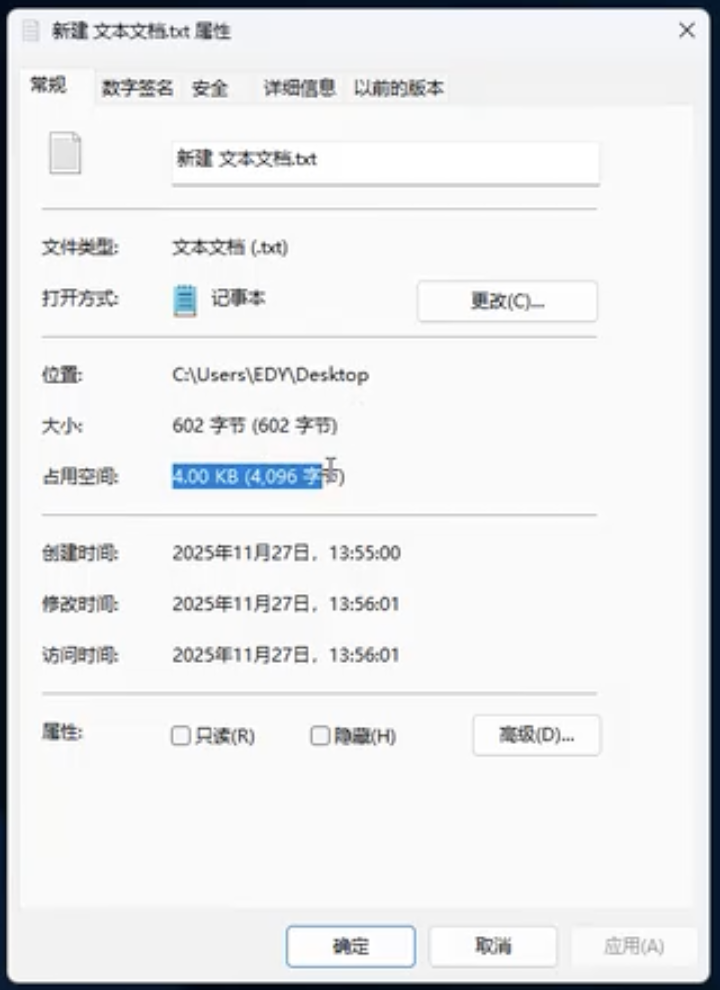
PQ向量压缩过程
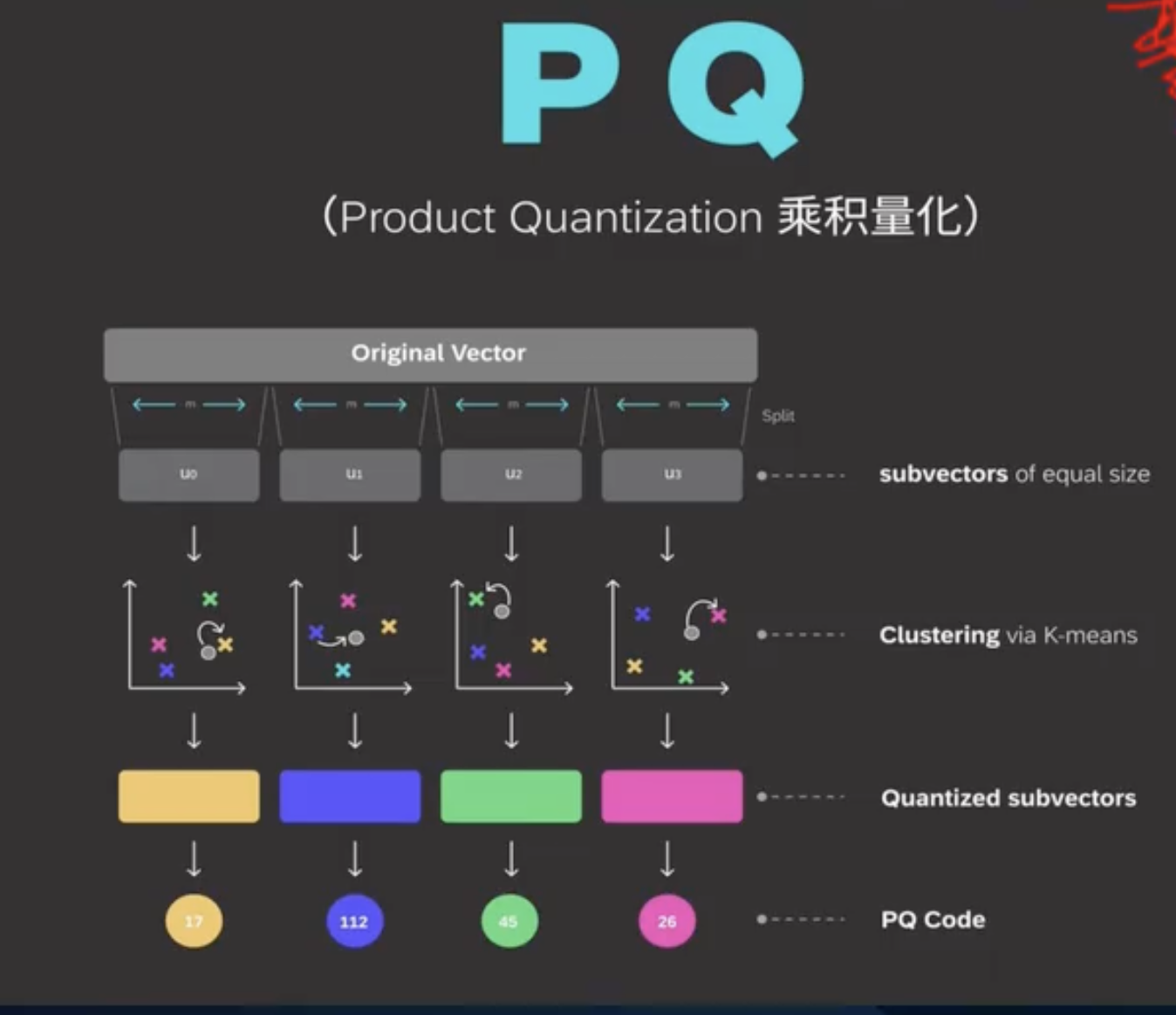
乘积量化(Product Quantization, PQ)的技术,核心作用是:
把一个又长又占空间的高维向量,压缩成一个又短又省空间的短码(PQ Code),方便在海量数据里快速检索。
它的核心思路就是 分而治之
- 原始向量拆分(Original Vector → Split)
先把一个又长又复杂的高维向量,像切蛋糕一样,均匀地切成好几段等长的子向量。这样一来,一个大问题就变成了好几个简单的小问题。
想象一下,你有一个很长的数字串,比如 [0.1, 0.3, 0.5, 0.7, …],这就是原始向量。
图里把它均匀地切成了 4 段,每一段长度都一样,分别叫 u0, u1, u2, u3,这些就是子向量。
这一步的目的:把一个复杂的大问题,拆成 4 个简单的小问题。 - 子向量聚类(Clustering via K-means)
对每一段子向量,我们都做一次聚类(图里用的是 K-means 算法)。
比如,把所有 u0 子向量聚成几类,每一类找一个 “代表”(聚类中心 / 质心);u1、u2、u3 也各自做同样的事。
这一步的目的:用 “代表” 来代替一堆相似的向量,实现初步压缩。 - 子向量量化(Quantized subvectors)
每个子向量,都会被替换成它所在那一类的 “代表”(质心)。
比如,原来的 u0 子向量,现在就用黄色块里的那个质心来表示;u1 就用蓝色块里的质心来表示,以此类推。
这一步的目的:用质心近似原始子向量,进一步压缩数据。 - 生成 PQ 码(PQ Code)
最后,我们不用再存那个长长的原始向量了,只需要存每个子向量对应的 “代表” 在码本里的编号(ID)组合起来,就得到了一个又短又紧凑的PQ 码。
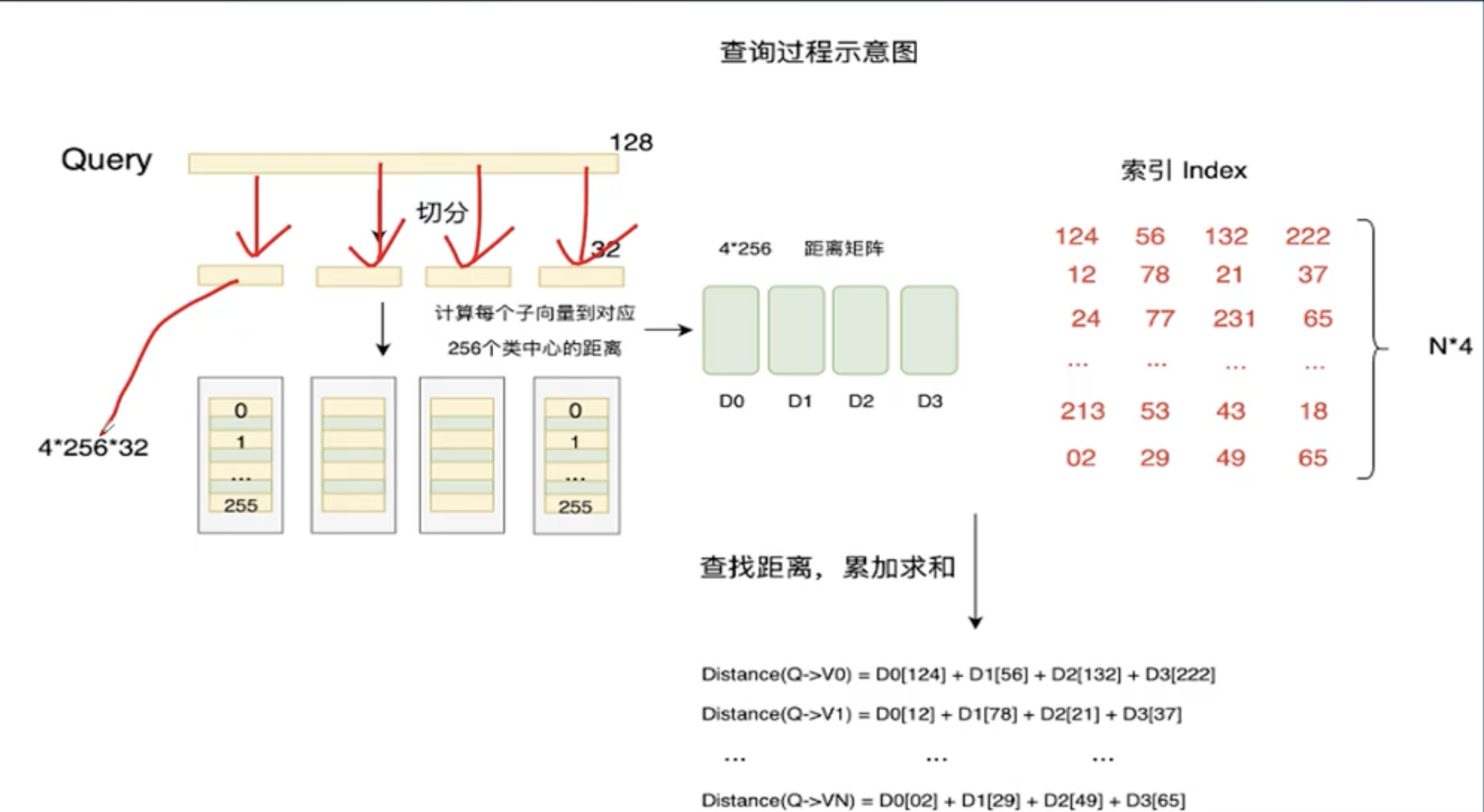
这张图展示的是乘积量化(PQ)在向量检索时的查询过程
1. 先看左边:处理查询向量(Query)
-
切分向量
- 我们有一个 128 维的查询向量
Q,先把它均匀切分成 4 段,每段 32 维的子向量:q0, q1, q2, q3。 - 这和我们之前讲的 PQ 编码时的切分规则是完全一样的。
- 我们有一个 128 维的查询向量
-
预计算距离
- 对每一段子向量,我们都预先计算它到对应码本里 256 个聚类中心的距离。
- 比如:
q0到u0码本里 256 个质心的距离,得到D0数组(长度 256)q1到u1码本里 256 个质心的距离,得到D1数组(长度 256)q2到u2码本里 256 个质心的距离,得到D2数组(长度 256)q3到u3码本里 256 个质心的距离,得到D3数组(长度 256)
- 这 4 个数组就构成了一个 4×256 的距离矩阵。
2. 再看右边:索引库(Index)
- 索引库中存储的是所有向量的 PQ 码,也就是每个向量 4 段子向量对应的聚类中心 ID。
- 比如:
- 向量
V0的 PQ 码是[124, 56, 132, 222] - 向量
V1的 PQ 码是[12, 78, 21, 37] - …
- 向量
VN的 PQ 码是[02, 29, 49, 65]
- 向量
3. 核心:查找距离并累加求和
这一步是 PQ 查询的精髓:
- 我们不需要再去计算查询向量
Q和库中每个向量V的完整距离,而是:- 从距离矩阵
D0中,取出索引为124的值(q0到V0第一段质心的距离) - 从距离矩阵
D1中,取出索引为56的值(q1到V0第二段质心的距离) - 从距离矩阵
D2中,取出索引为132的值(q2到V0第三段质心的距离) - 从距离矩阵
D3中,取出索引为222的值(q3到V0第四段质心的距离) - 把这 4 个距离加起来,就是
Q和V0的近似距离:
[
\text{Distance}(Q \to V0) = D0[124] + D1[56] + D2[132] + D3[222]
]
- 从距离矩阵
- 对库中所有向量都重复这个“查表+求和”的操作,就能快速得到所有向量与查询向量的近似距离,然后按距离排序,找到最近邻。
为什么这么做?
- 快:只需要做 4×256 次距离计算,然后对所有向量做 4 次查表和 3 次加法,复杂度从 O(N×D) 降到了 O(N×M)(M 是子向量段数)。
- 省:不需要存储原始高维向量,只存紧凑的 PQ 码。
- 准:虽然是近似距离,但在大多数场景下精度足够,能满足检索需求。
Agent
Agent 与 普通智能体 区别
普通智能体:你问一句,它答一句,不会主动做事。
ai agent: 能自己干活,自己思考,不需要用户一步步指挥的智能体。有目标,会思考,用工具,能循环(思考-> 行动 -> 结果 -> 再调整)
核心原理
让大模型不再只是 “回答”,而是能 “思考→行动→观察→再思考”,循环完成复杂任务。
本质就是:
LLM(大脑) + 工具(手脚) + 记忆(记性) + 规划(逻辑) = Agent
标准/通用框架
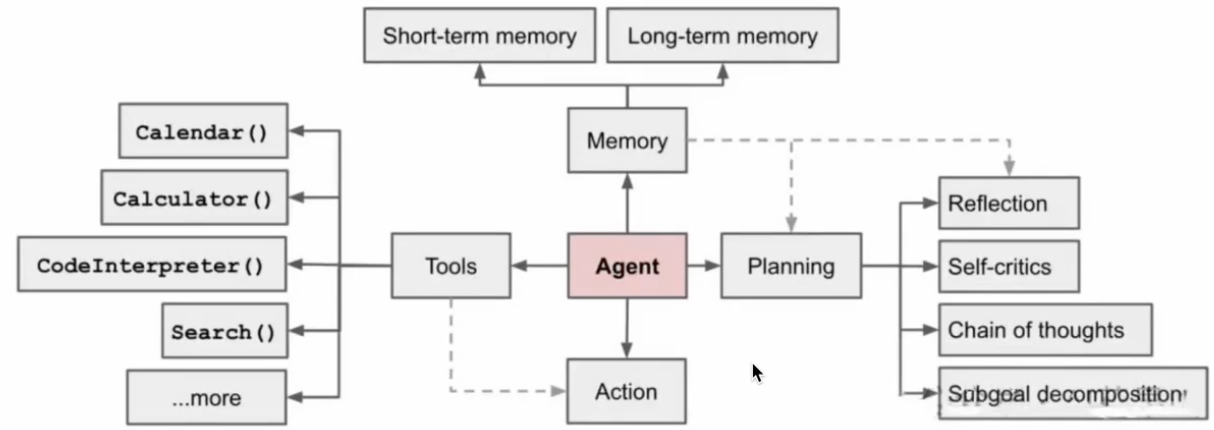
1. 感知模块(Perception)
接收用户指令
接收环境 / 工具返回结果
理解当前状态
作用:知道现在发生了什么。
2. 记忆模块(Memory)
短期记忆:上下文对话
长期记忆:历史任务、知识库、文档
经验记忆:之前怎么做成功 / 失败
作用:不会做着做着忘事。
3. 决策 / 规划模块(Planning)
这是 Agent 最灵魂的部分。
把大任务拆成小步骤
判断下一步做什么
决定要不要调用工具
决定是否完成任务
主流范式:
ReAct(Reason + Act)
CoT(思维链)
Reflexion(自我反思)
作用:像人一样思考、规划、反思。
4. 执行 / 工具模块(Action / Tool Use)
让 AI 能 “动手”:
搜索
查数据库
调用 API
写代码、运行代码
操作浏览器、操作软件
作用:把思考变成实际结果。
5. 控制循环(Agent Loop)
不断循环:
思考(Think)
行动(Act)
观察(Observe)
再思考(Re-think)
直到任务完成或停止。
核心框架:ReAct
标准 Agent 是整体结构,ReAct 是它的核心运行逻辑,本质属于同一套体系。
你只要记住这个,就懂 80% Agent 原理:
Thought → Action → Observation → Repeat
示例流程:
Thought:我需要先查资料
Action:调用搜索工具
Observation:得到搜索结果
Thought:现在可以总结答案
Action:输出最终结果
两者对应关系:
Thought 对应感知、记忆、规划模块;
Action 对应执行与工具调用模块;
Observation 对应结果感知与记忆更新,并驱动下一轮循环。
围绕 感知、规划、行动、观察 的 场景决策和 过程拆分
代码开发智能体
1)感知
用户需求:写一个登录接口
读取已有代码、框架、数据库结构
2)规划
理解需求
设计表结构
写代码
写单元测试
运行验证
3)行动
生成代码、调用解释器运行
执行测试、查报错信息
4)观察
编译报错 → 回去改代码
测试不通过 → 修正逻辑
全部通过 → 输出最终代码
子任务分解
面试官最爱听的总结句(必背)
子任务分解不是固定拆法,而是根据任务复杂度、是否需要工具、是否需要回溯,选择不同的思考策略
1. 线性分解(对应:思维链 CoT)
思路:一步接一步,顺序执行,单一路径。
特点:简单、直接、无分支、不回溯。
适用:步骤固定、流程清晰的简单任务。
例子:查天气 → 取数据 → 生成回答
2. 树状分解(对应:思维树 ToT)
思路:任务拆成多条可能路径,尝试→回溯→剪枝→择优。
特点:多分支、可重试、有回溯、会自我修正。
适用:数学题、逻辑推理、多解问题、复杂决策。
3. 目标驱动分解(Goal-Oriented)
思路:从最终目标倒推,反向拆步骤。
特点:以结果为导向,不做多余步骤。
适用:规划类任务(出行、日程、方案生成)。
4. 工具驱动分解(Tool-Aware)
对应:ReAct 框架
思路:先看有哪些工具,再按 “需要用什么工具” 来拆任务。
特点:每一步都围绕调用工具展开。
适用:搜索、API、数据库、代码执行、浏览器操作。
ReAct: Synergizing Reasoning and Acting in Language Model
Tools / Toolkits
Tools: Agent 能调用的单个功能 / 接口,是智能体能 “动手做事” 的最小单元。
Toolkits: 一组面向同一类场景的工具集合,是多个相关 Tool 打包在一起的套件。
Tool 是单个功能,Toolkit 是功能包;
Tool 是零件,Toolkit 是工具箱。
Agent 代码初体验
第一个 Agent
使用 Tools/ Toolkits
给 Agent 添加记忆
Langchain
LangChain 是一个开源开发框架,用来快速搭建基于大模型的 AI 应用和 AI Agent,
提供模型接入、工具调用、记忆、规划、流程调度等核心能力。
LangChain 是一个用来快速开发 AI Agent 应用的开源开发框架。
它把大模型、工具、记忆、规划、流程调度等能力封装好,让开发者不用从零写代码,就能快速搭建出能思考、能用工具的 LLM 应用与智能体。
核心作用(面试必说)
- 统一对接各种大模型
GPT、文心、通义、Llama 等,切换模型方便。 - 提供标准化工具体系
搜索、计算器、代码解释器、数据库、API 等。 - 内置 Agent 执行逻辑
ReAct、工具调用、多步规划、记忆管理。 - 简化流程编排
把 “感知→规划→行动→观察” 封装成可直接运行的链路。
框架 的选择以及流程
- 简单工具调用 → ReAct
- 长流程、复杂任务 → Plan and Execute
- 推理题、数学题 → ToT /多路径、回溯、择优
- 需要纠错、迭代 → Reflexion
- 多工具、固定流程 → ReWOO /先规划所有工具调用,再批量执行
ReAct
用户问题
↓
【1. Reason 思考】
我要做什么?
要不要调用工具?
调用什么工具?
↓
【2. Act 行动】
调用工具 / 执行操作
↓
【3. Observation 观察】
工具返回了什么?
对不对?够不够?
↓
【循环:回到 Reason】
↓
信息足够 → 输出最终答案
plan and execute 规划-执行框架
用户问题
↓
【规划器 Planner】
↓
生成【完整步骤列表】:
步骤1:xxx
步骤2:xxx
步骤3:xxx
...
↓
【执行器 Executor】
按顺序一步一步执行:
→ 步骤1
→ 步骤2
→ 步骤3
↓
【汇总结果】
↓
输出最终答案
self-ask
用户问题
↓
【主问题太难 → 不直接答】
↓
Self-Ask:提出第 1 个小问题
↓
去查/去推理 → 得到答案1
↓
再提出第 2 个小问题(依赖答案1)
↓
得到答案2
↓
……(一直追问到足够信息)
↓
汇总所有答案 → 给出最终回答
Refection 反思框架
用户问题
↓
【1. 规划 / 思考】
↓
【2. 行动 / 执行】
↓
【3. 观察结果】
↓
【4. 反思 Reflexion】
✅ 对了?→ 继续下一步
❌ 错了?→ 总结错误原因
↓
【带着反思重新规划】
↓
循环……直到任务完成
ToT Tree of Through 思维树
用户问题
↓
【Planner 规划器】
一次性生成:
步骤1:调用工具A → 存结果到 #1
步骤2:调用工具B,用 #1 → 存 #2
步骤3:调用工具C,用 #2 → 存 #3
↓
【Executor 执行器】
批量执行所有工具调用,不思考、不规划
↓
【Solver 汇总器】
用所有结果 #1 #2 #3 → 生成最终答案
ReWoo Reasoning without Observation
用户问题
↓
产生多条思路:
├─ 思路A → 执行 → 不行 → 剪枝(丢弃)
├─ 思路B → 执行 → 卡住 → 回溯(退回去)
└─ 思路C → 执行 → 可行 → 继续
↓
继续往下分支思考
↓
找到最优路径 → 得出答案
LangGraph (vs LangChain vs LangSmith)
| 工具 | 类型 | 核心定位 | 开源 / 商业 |
|---|---|---|---|
| LangChain | 开发框架 | 构建 LLM 应用、链式流程 | ✅ 开源 |
| LangGraph | 编排引擎 | 复杂图流程、状态、循环、多 Agent | ✅ 开源 |
| LangSmith | 运维平台 | 追踪、调试、评估、生产监控 | ❌ 商业 SaaS |
- LangChain 是做 LLM/Agent 的基础开发框架,适合简单线性流程;简单问答、RAG、基础 Agent、快速原型
- LangGraph 是基于图结构的工作流编排框架,适合复杂状态、循环、多 Agent 协作。
- LangSmith:所有 LLM 应用的调试、测试、优化、生产监控(必用)
- LangChain + LangGraph(开发) + LangSmith(运维) =** 完整 LLM 应用栈**
LangChain
用户输入 → Chain → LLM/工具 → 输出
(单向、顺序、无循环)
LangChain 是开发 LLM/Agent 应用最主流的「开发框架 / 工具库」。
- 帮你快速对接大模型
- 提供 Tools、Prompt、记忆、检索、Agent 逻辑
- 内置:ReAct、Plan&Execute、Self-Ask 等
LangGraph
┌→ NodeA → NodeB ──┐
开始 → ┤ ├→ 结束
└→ NodeC ←--------┘
↑ 循环/重试
(状态共享、分支、循环、多 Agent)
LangGraph 是 LangChain 官方推出的、专门做「多智能体、复杂状态、循环工作流」的图结构编排框架。
- 用 图(Graph) 来定义 Agent 流程
- 支持:状态管理、多节点、循环、跳转、多 Agent 协作
- 适合超复杂、多步骤、可中断、可重试的业务
- 特点:图结构、状态持久、支持循环与多 Agent。
LangSmith
LangChain / LangGraph 运行
↓
LangSmith 全链路追踪
↓
可视化 → 调试 → 评估 → 监控
(上帝视角,看每一步)
stream_mode 的选项
updates:流式返回 Agent 状态增量(键值对),适配流程监控;
message:标准化对话消息(role+content),适配聊天场景;
value:纯值流式输出,轻量化,适配简单结果返回;
custom:自定义结构,适配复杂业务 / 评测场景;
Tools 工具的调用步骤
ChatMessageHistory
in LangChain
in LangGraph
Short-term memory
Checkpoint: thread-id
Sumarization总结方法:
Trimming删除方法“
Long-term memory
Humen-in-the-Loop 人类监督
在Agent进行工具调用的过程中,允许用户进行监督。这就需要在任务执行过程中,执行中断任务,等待用户输入完成后,再重新恢复工作。
interrupt
LangGraph 构建Agent
LangGraph核心-Graph图
Graph图是LangGraph的基本建模块。有向无环图(DAG),用于描述任务之间的依赖关系。
主要包含3个基本元素:
- State(状态):全局共享数据(记忆、结果、进度)
- Node(节点):每个节点是一个函数 / LLM / 工具
- Edge(边):节点之间的跳转规则(条件判断)
- Graph:把节点和边组装成工作流
开始 → 节点1(思考)
↓ ↗️ ↘️
节点2 ← 节点3(工具/反思)
↓
结束
state
全局共享的数据中心,所有节点都能读、能写。所有节点共用一份记忆。
存什么:
- 用户问题
- 历史对话
- 工具返回结果
- 执行进度、步骤、反思日志
- 所有需要 “记住” 的东西
node
流程里的一个步骤、一个函数、一个任务。真正干活的地方。
可以是:
- LLM 思考
- 工具调用
- 数据处理
条件判断
另一个 Agent
Huggingface 模型训练利器
- 官网:www.huggingface.co
- 面向 NLP 模型 的 github
- 基于 transformer 的开源模型 非常全
- 封装了模型、数据集、训练器等。使得模型的下载、使用和训练都非常方便
什么是模型
模型 = 从数据里学到的 “规律 / 知识”,封装成一套可计算的数学函数 + 参数
什么是模型训练
训练过程就是不断调整参数,让输出越来越准
训练好后,只需要输入,就能快速得到结果
模型训练/预训练pre-train vs 微调fine-tuning vs 推理 inference
pre-train -> 通用大模型 eg:LLM
fine-tune -> 垂直领域专用模型
在已经训练好的模型上,再学一点专用知识
比如:
让通用模型 → 变成客服机器人
让通用模型 → 变成代码助手
数据量小、速度快、成本低
inference -> 用户使用模型的过程
一个神经元
一个人工神经元(也称为感知机 Perceptron)是神经网络的基本计算单元。它接收多个输入,并产生一个输出。
步骤 1:线性组合
计算所有输入的加权和,再加上偏置: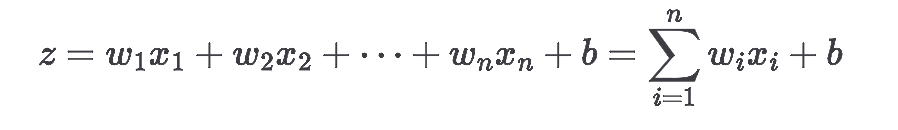
用向量形式表示更简洁: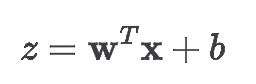
其中 ,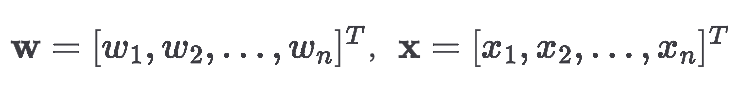
步骤 2:激活函数
将线性组合的结果通过一个非线性函数 进行转换: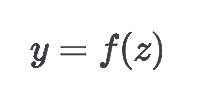
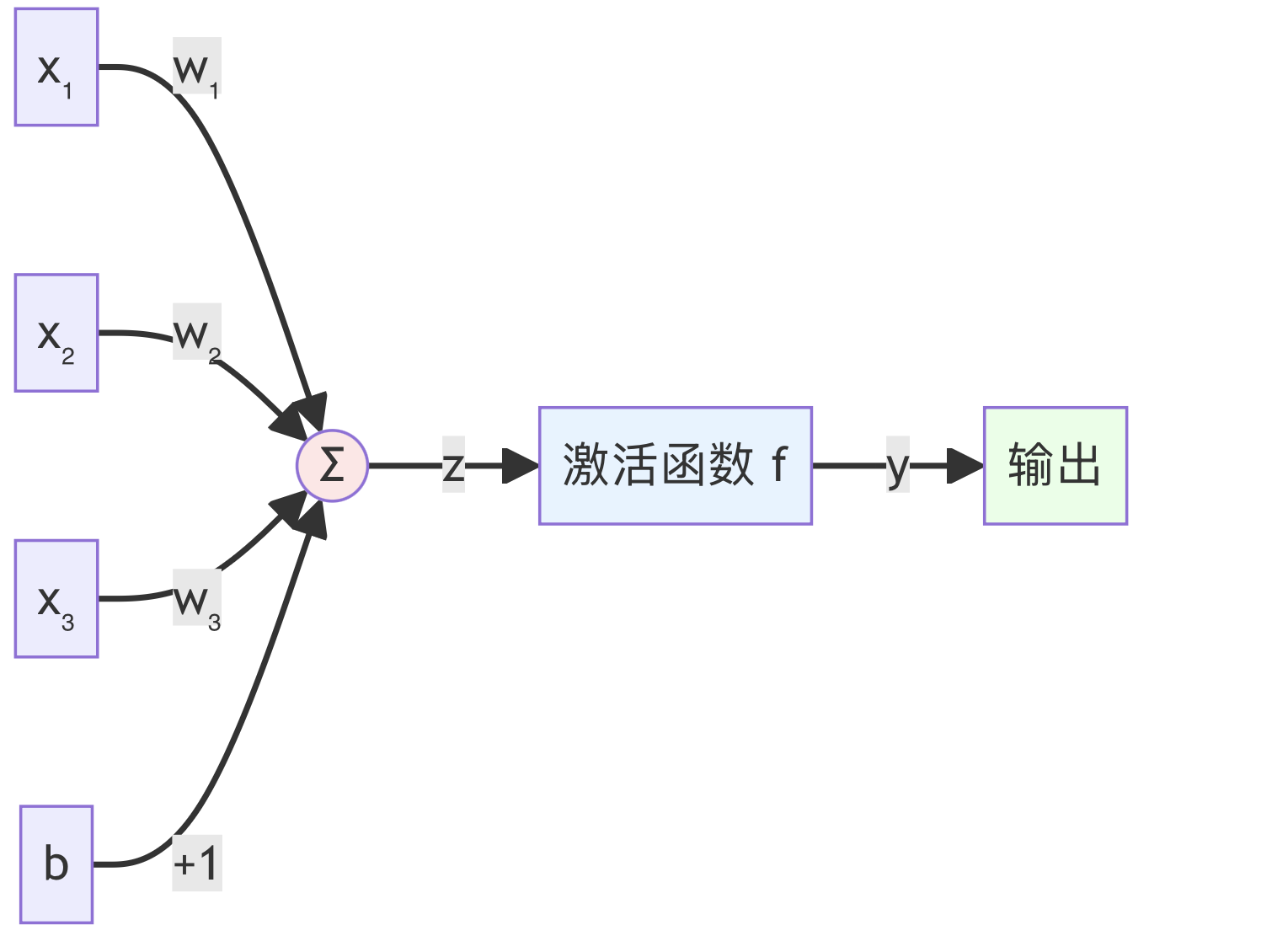
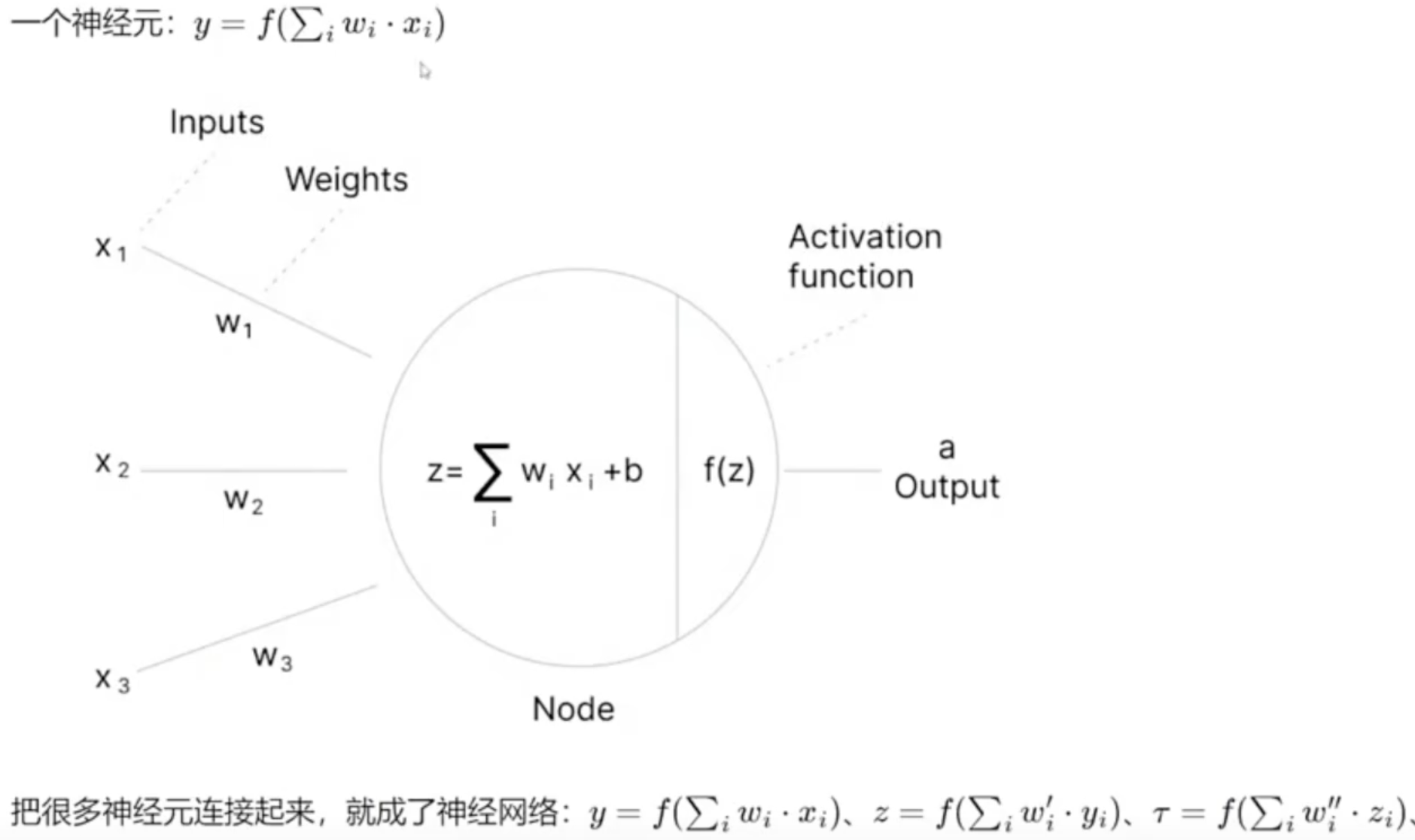
把 多个神经元 连接起来 形成了 神经网络
input layer 输入层
hidden layer 隐藏层
output layer 输出层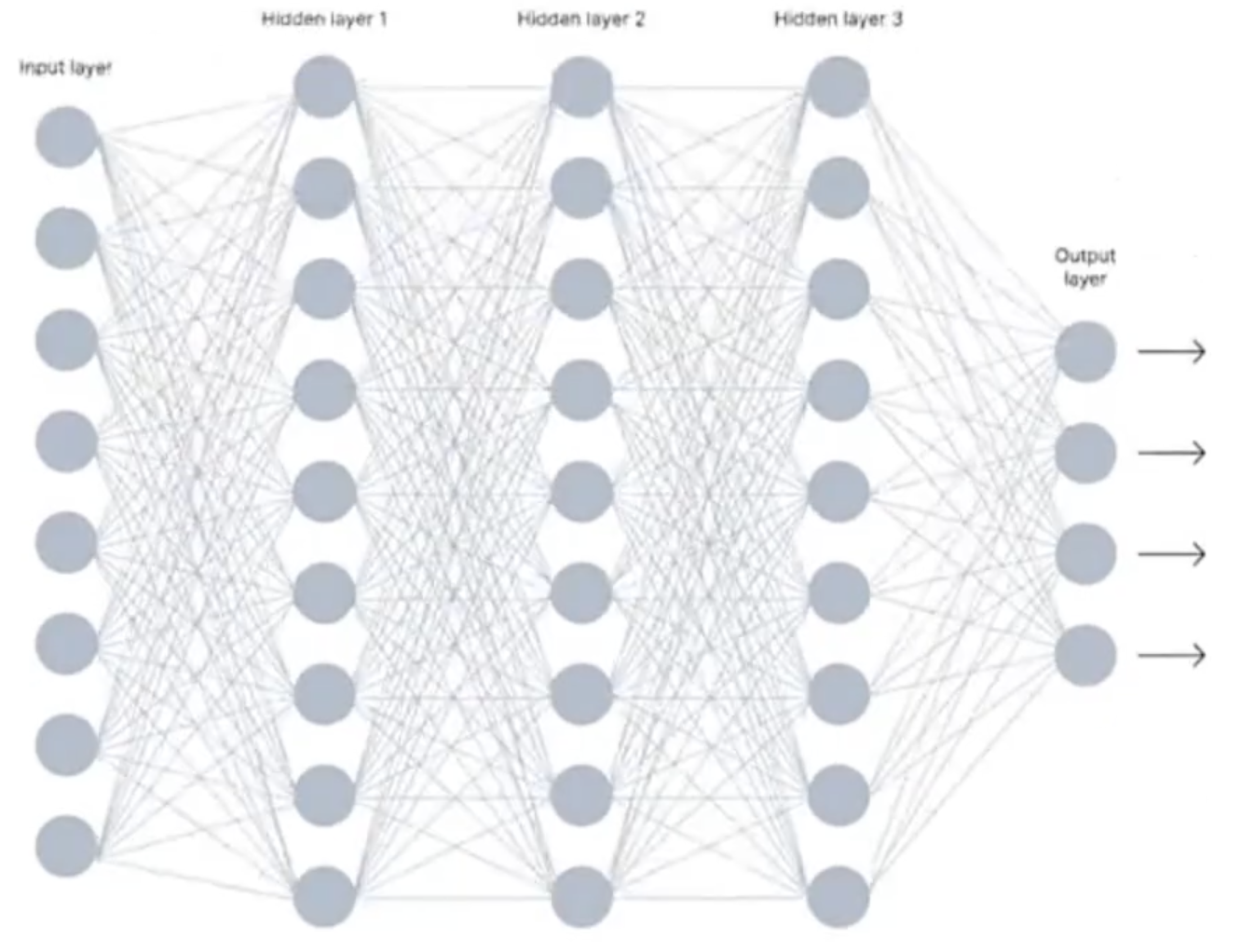

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)