理解、感知、规划三位一体!华科大&小米发布UniDriveVLA,打造统一自动驾驶新范式

「全新VLA框架,构建智驾认知闭环」
One expert to understand them all, one expert to perceive them all, one expert to act for all.
目录
2.1 UniDriveVLA结构:理解、感知与动作的专家化协同
2.2 稀疏空间感知范式:从 2D 视觉特征中提取 3D 先验
最近,自动驾驶 VLA 领域迎来新的进展。来自华中科技大学、小米汽车与澳门大学的研究团队提出 UniDriveVLA,一种统一理解、感知与规划的自动驾驶 VLA 新范式。针对传统端到端模型“感知强、语义弱”以及现有 VLA 方法“语义增强但空间感知受限、且两者存在冲突”的问题,该方法在统一框架下实现了 理解、感知与规划的协同建模与优化。
效果演示
该视频展示了 UniDriveVLA 在驾驶场景中的统一推理能力:在同一前向过程中同时完成语义理解、目标检测与车道线等空间感知任务。
在此基础上,模型进一步输出连续的轨迹规划结果,实现理解、感知与规划的端到端统一闭环。
01 从人类驾驶到自动驾驶:感知与理解的统一难题
图1| 人类驾驶认知模拟
驾驶行为的复杂性,并不来自“看见道路”本身,而来自一个更本质的问题:同一时刻,大脑需要在物理空间与语义空间之间同时做推断,并让两者在时间维度上保持一致。
在真实驾驶过程中,存在两类完全不同的信息处理机制。
其一是对空间结构的连续估计,包括车辆距离、相对速度、道路边界、自车状态等,这一部分决定系统是否“看得准”;
其二是对交通语义与交互意图的理解,例如其他车辆是否在变道博弈、行人是否存在横穿倾向、信号与规则在当前情境下的约束强度等,这一部分决定系统是否“看得懂”。驾驶决策本质上并不是这两类信息的简单叠加,而是一个持续 融合、相互约束的动态过程。
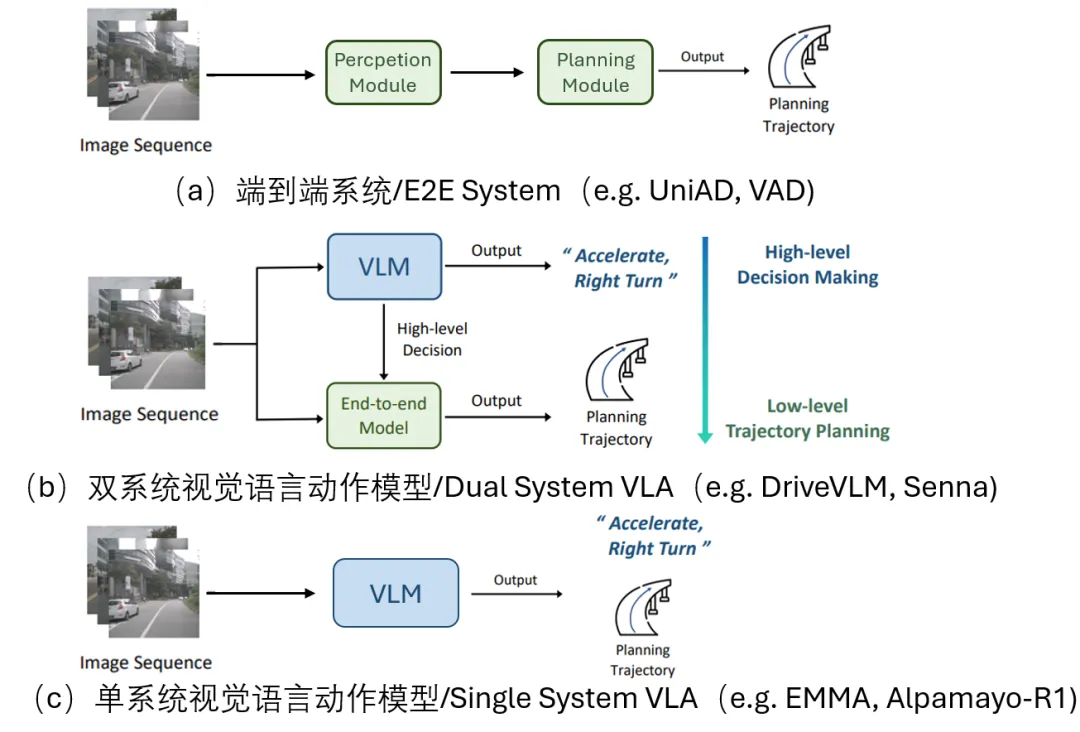
图2| 自动驾驶架构的演进(改编自 Senna 相关工作)
自动驾驶系统的发展,本质上是在尝试复现这种“感知-理解-决策”的统一机制。早期的模块化方法将系统拆解为感知、预测、规划等独立阶段,每一阶段分别优化各自目标。这种方式虽然结构清晰,但信息在模块之间逐级传递时不可避免地产生损耗,尤其是语境信息与交互关系难以被完整保留,导致整体决策缺乏全局一致性。
端到端方法随后成为主流方向之一(如 UniAD、VAD)。这类方法通过统一网络直接从多视角图像学习到轨迹输出,将感知与规划纳入同一优化目标,从结构上减少了信息断层,使模型能够更好地捕捉运动规律与空间几何关系。然而,这类方法的能力边界仍然主要由视觉模式学习决定,当面对复杂交互、隐式规则或长尾场景时,其对高层语义的表达能力仍然有限,本质上仍偏向“几何驱动”的决策系统。
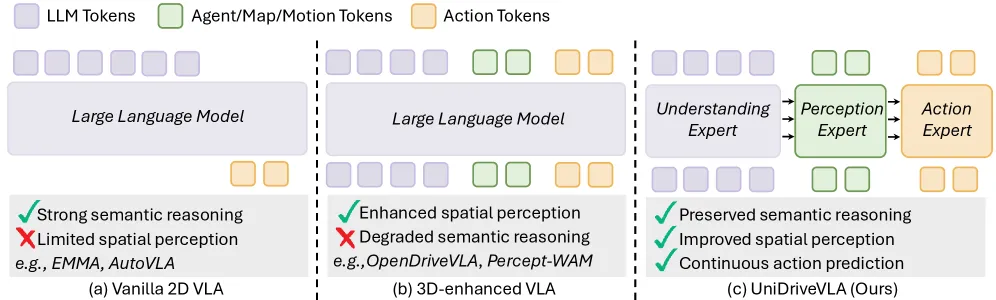
图3| 自动驾驶 VLA 范式对比。(a)2D VLA 侧重语义但空间不足;(b)3D增强 VLA 提升感知但损伤语义;(c)统一 VLA 试图同时建模两者但引入冲突。
随着视觉-语言大模型(VLM)的发展,自动驾驶开始进入VLA范式阶段,即将语义理解能力显式引入驾驶决策过程。这一方向通常演化为两类结构:一类是双系统架构,将VLM作为高层语义决策模块,由独立的规划器执行低层控制;另一类是单系统架构,尝试用统一模型直接完成图像理解、语义推理与轨迹生成,实现真正端到端的视觉-语言-动作闭环。
然而,这两种路线在实践中都暴露出结构性矛盾。双系统方法虽然缓解了能力解耦问题,但系统内部仍存在语义与控制之间的接口鸿沟;单系统方法虽然形式统一,但在共享参数空间中同时优化语义推理与空间建模时,会引发明显的能力冲突。
具体而言,VLM本身主要在2D图文数据上预训练,其优势在于语义关联与知识推理,而非精确的三维几何建模。当直接引入3D空间表征以增强感知能力时,模型往往会出现语义能力退化的问题;反之,如果保持原生结构以维持语义能力,则空间感知又显不足。这种“语义-空间”之间的此消彼长,成为单系统VLA的核心瓶颈。
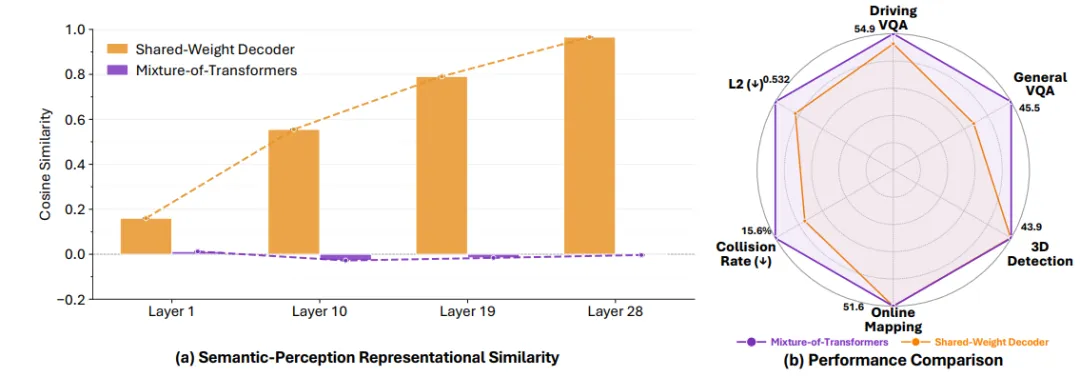
图4| 表征冲突分析。(a)共享参数导致语义与空间特征逐层趋同;(b)解耦结构显著缓解特征坍缩并提升整体性能。
更深层的原因在于共享参数空间中的表征干扰问题。在统一解码结构中,不同类型的token(语义token与空间token)被迫通过同一组参数进行建模与更新,从而导致优化目标发生冲突。随着网络加深,这种干扰会逐渐累积,使不同模态的特征空间发生塌缩,表现为语义与空间表示之间的相似度不断升高,最终削弱模型原有的功能分工。
因此,问题的关键不在于是否引入3D信息,也不在于是否使用语言模型,而在于如何在统一框架中避免不同认知能力之间的相互干扰,使空间感知与语义理解能够在不共享冲突梯度的情况下协同工作。这一矛盾构成了当前自动驾驶VLA发展的核心瓶颈,也正是后续方法设计的出发点。
02 UniDriveVLA:专家解耦,各尽其才
2.1 UniDriveVLA结构:理解、感知与动作的专家化协同
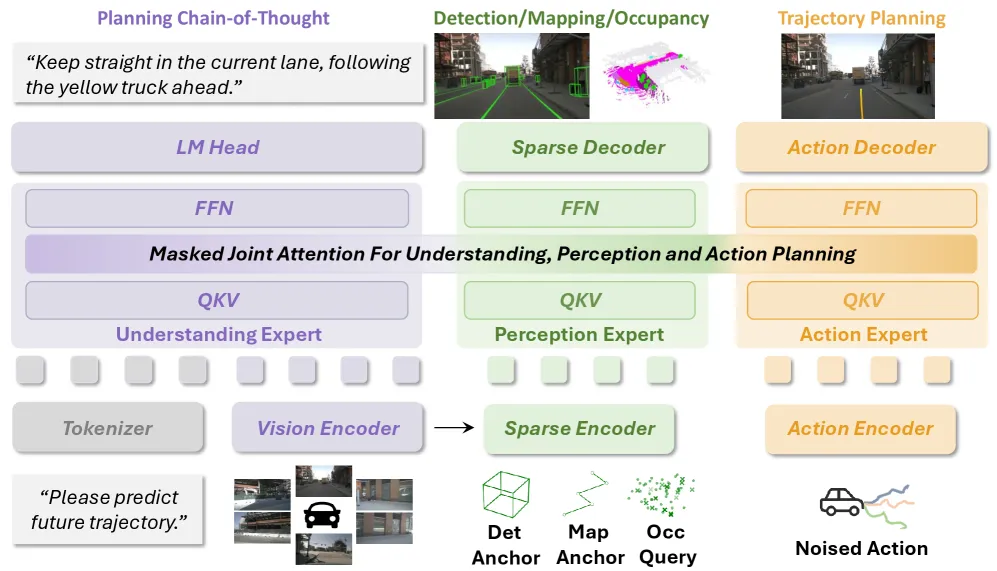
图5| UniDriveVLA 整体架构。模型由理解、感知与动作三个专属专家组成,并通过掩码联合注意力实现跨专家协同。
UniDriveVLA 的出发点,并不是把更多任务继续堆进同一个 Transformer,而是先承认一件事:理解、感知和动作虽然共同服务于驾驶,但它们面对的输入、依赖的表征以及优化目标并不相同。如果仍然让它们共享同一条参数路径,就很容易再次出现前文所说的表征干扰,导致语义能力、空间能力和规划能力彼此拉扯。为此,UniDriveVLA采用 Mixture-of-Transformers(MoT)作为整体骨架,把系统明确拆分为三个专家分支,分别对应理解、感知和动作规划,让每一类能力先在自己的路径中完成建模,再在受控机制下进行信息交换。
在输入侧,多视角图像 、历史轨迹
和导航指令
会被编码为三类异构 token,并分别送入对应的专家分支。理解专家接收理解 token
,负责场景描述、驾驶意图推断以及高层语义建模;感知专家接收感知 token
,负责从视觉信息中恢复空间结构与 3D 几何先验;动作专家接收动作 token
,该 token 通过高斯噪声与目标速度序列之间的流匹配插值得到,用于生成连续轨迹。三类 token 的职责不同,因此它们不应再被迫进入同一套共享参数空间,而应先各自完成专门建模。
为了让这种分工真正落到结构上,每个专家都会把自己的 token 投影到独立的 Query、Key、Value 子空间中:
其中 。这一设计的关键作用,是把不同任务的更新轨迹从机制上切开,使理解、感知与动作在进入交互环节之前,就已经处于不同的参数子空间中。换句话说,模型不是先混合再补救,而是先分路,再协同。
但如果只有解耦而没有交互,系统又会失去统一驾驶所需要的协作能力。因此,UniDriveVLA 进一步引入 Masked Joint Attention,对专家之间的信息流动进行显式控制。具体而言,UniDriveVLA将三组专家表征按“理解—感知—动作”的顺序拼接为全局矩阵:
这里的掩码并不是为了简单限制信息,而是为了定义信息流的方向。理解分支遵循严格的因果约束,不能看到后续的感知和动作 token,这样才能尽可能保留 VLM 原生的语义推理顺序;感知分支可以读取前序理解信息,从而获得更强的语义上下文,用来修正空间表征;动作分支则聚合前面所有语义与空间信息,形成最终的规划输入。注意力交互完成后,各专家再通过自己的输出投影、归一化和前馈网络继续更新:
这样,UniDriveVLA 最终形成的是一种“先分工、再协同”的结构:每个专家保留自己的优化边界,但又能在需要时获得其他专家提供的必要信息。
2.2 稀疏空间感知范式:从 2D 视觉特征中提取 3D 先验
在空间感知部分,UniDriveVLA 没有沿用将密集 BEV 特征直接注入大模型的常见路线。原因很直接:密集 3D 表征虽然信息丰富,但计算成本高,而且与 VLM 在 2D 图文数据上形成的预训练分布差异过大,直接硬塞进统一框架里,很容易再次引发表征不适配。相比之下,UniDriveVLA选择从多尺度 2D 视觉特 征中构建稀疏的空间先验,让模型以更轻量、更稳定的方式学习 3D 场景。
具体而言,感知分支采用统一的 query-based 框架,将 3D 目标检测、在线建图、自车状态估计和运动预测纳入同一个空间建模流程,而不是为每个任务设置彼此孤立的预测头。不同任务的稀疏查询先通过数据集级别的 K-Means 初始化,再依次经过 temporal interaction、intra-task reasoning、inter-task communication、deformable feature aggregation 和 task-wise refinement 等更新步骤,使感知分支能够同时捕获时间动态、任务结构和跨任务依赖。
占据栅格(Occupancy)则被作为一个辅助分支单独处理。UniDriveVLA引入专门的 Occ query,这些 query 在经过感知专家交互之后,再由专门的 Occ VAE decoder 解码为最终的 3D occupancy 输出。这样一来,感知分支不再只是输出几个离散任务结果,而是形成了一个能够覆盖检测、建图、运动和占据 预测的统一空间表征体系。
更重要的是,这一感知模块并不是单向工作的。UniDriveVLA还设计了一个“语义回流”的过程:先把检测、建图、自车、运动和占据等 first-pass 结果提升到感知专家的隐藏空间,再通过前述的 Masked Joint Attention 选择性吸收理解专家的语义上下文,最后重新投影回稀疏感知空间进行二次细化。
这样得到的感知输出不再只是几何层面的结果,而是带有语义约束的结构化表征,既保留空间精度,也保留场景理解能力,并最终为动作规划提供更可靠的输入。
2.3 三阶段渐进训练:稳住语义,再注入空间,再强化规划
这样一个包含三个专家、多个任务和跨域交互的系统,不能用粗暴的方式从头一起训练,否则最容易出现的问题就是语义能力被冲掉,或者感知分支和动作分支还没学稳就互相拉扯。为了解决这个问题,UniDriveVLA 采用了三阶段渐进训练策略。
第一阶段的目标,是先把 VLM 的语义底盘稳住。UniDriveVLA用驾驶相关 VQA 数据和通用多模态数据混合训练,并且刻意让通用数据占更高比例,目的不是让模型“更杂”,而是让它先保留原有的认知泛化能力,避免一上来就被驾驶领域的结构化监督带偏。
第二阶段开始引入 3D 检测、在线建图、占据预测和轨迹生成等任务,模型进入真正的联合优化阶段。
为了避免这一阶段的监督信号过强地破坏语言能力,UniDriveVLA对语言主干使用 LoRA,并显著降低基础学习率,让空间能力以更温和的方式逐步注入,而不是用激进更新直接把语义结构冲散。
第三阶段则进一步把重点转向感知专家和动作专家。此时UniDriveVLA冻结 VLM 主干,只对后两部分进行专门强化,同时加入运动预测目标,帮助模型更好地理解时序动态和交通演化趋势。这样训练下来,模型不是在某一个阶段“学会全部”,而是先守住语义,再补足空间,最后把规划能力打磨到稳定可用。
03 实验结果
为了验证 UniDriveVLA 在统一框架下同时建模理解、感知与规划的有效性,作者分别在闭环驾驶、开环规划、3D 感知、场景理解以及通用多模态任务上进行了评测。实验结果表明,UniDriveVLA 并不是只在单一任务上取得提升,而是在理解、感知与规划三个层面都表现出了较强的协同能力。
3.1 理解能力:驾驶场景语义与通用认知能力兼顾
在驾驶场景理解方面,UniDriveVLA 在 DriveBench 上取得了 51.97 的平均分,其中行为推理(Behavior)子项达到 60.97,说明模型不仅能够识别场景内容,还能够进一步推断交通参与者的意图与交互关系。
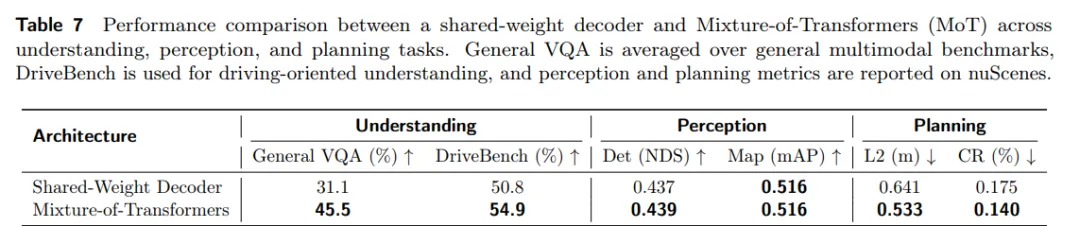
表7| DriveBench 驾驶场景理解能力对比
除了驾驶专用理解任务之外,作者还测试了模型在通用视觉问答基准上的泛化表现。结果显示,经过驾驶领域微调后,UniDriveVLA 在 RealWorldQA、AI2D 和 ChartQA 等非驾驶数据集上仍然保留了较为稳定的性能,说明训练策略在增强驾驶能力的同时,也较好地抑制了对基础视觉语言能力的灾难性遗忘。
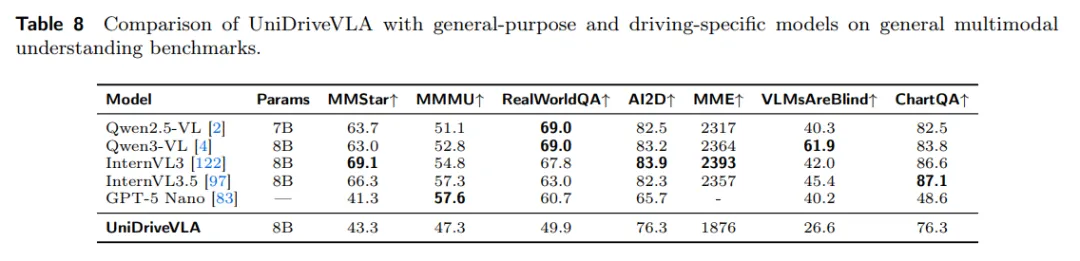
表8| 模型在通用多模态理解基准上的表现
3.2 感知能力:从 3D 检测到在线建图的统一空间建模
在 nuScenes 上,UniDriveVLA 不仅要完成轨迹规划,还需要同时输出高质量的 3D 感知结果。实验表明,UniDriveVLA-Large 在 3D 目标检测上取得了 0.460 的 NDS,在在线地图构建上取得了 0.535 的 mAP,说明模型能够从稀疏空间表征中恢复出稳定的几何结构,并为后续规划提供有效的空间先验。
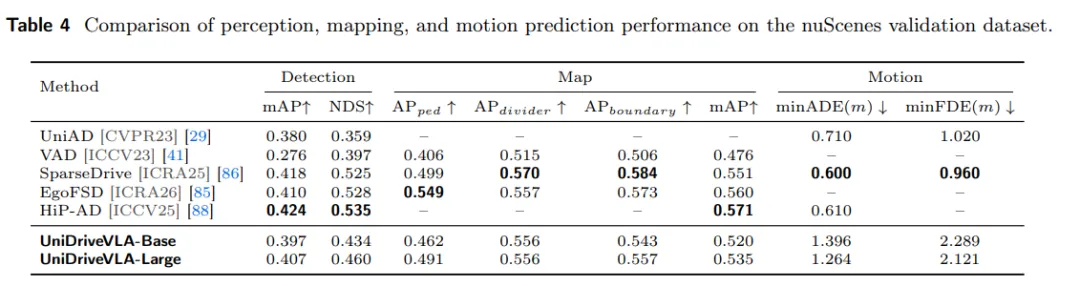
表4| nuScenes 验证集上的感知、建图与运动预测表现
这一结果也说明,UniDriveVLA 的感知分支并不是一个孤立的检测头,而是一个能够统一处理目标、地图、自车状态与运动预测的空间建模模块。它既保留了空间精度,也为后续的规划分支提供了更完整的场景表示。
3.3 规划能力:闭环控制与开环轨迹预测同步提升
在规划任务上,UniDriveVLA 在 Bench2Drive 和 nuScenes 上都表现出了较强的驾驶决策能力。
在 Bench2Drive 闭环评测中,模型在未使用 PDM-Lite 的条件下,驾驶得分达到 78.37,通行效率达到 198.86,路线完成率为 51.82%。这表明UniDriveVLA 不仅能够生成合理轨迹,也具备较强的闭环控制能力。
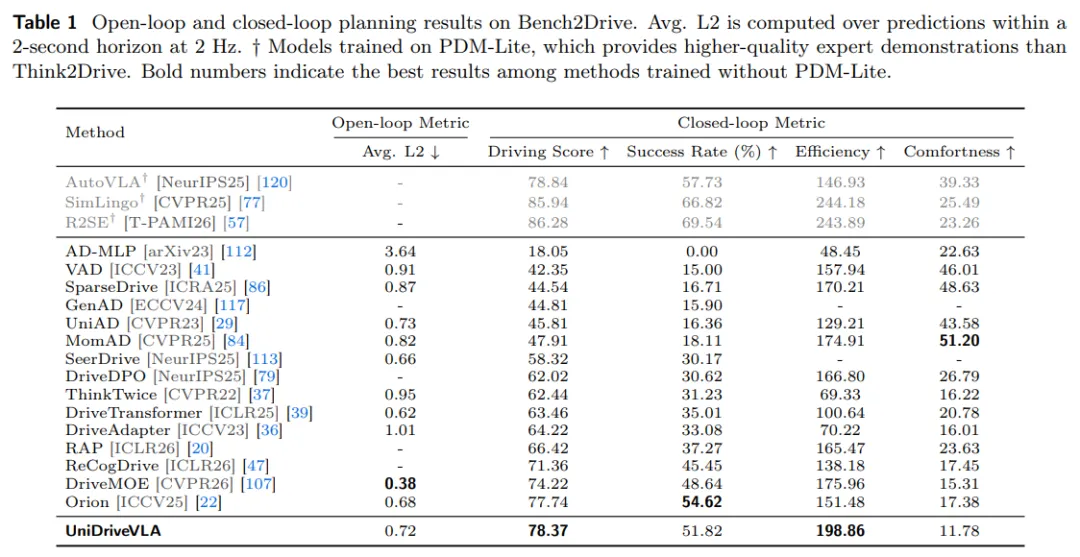
表1| Bench2Drive 闭环规划与开环能力对比
在更细粒度的交互场景中,模型在车辆汇入(Merging)和超车(Overtaking)任务上分别取得了 38.75% 和 80.00% 的成功率,说明它对复杂交通博弈场景具有一定的适应能力。
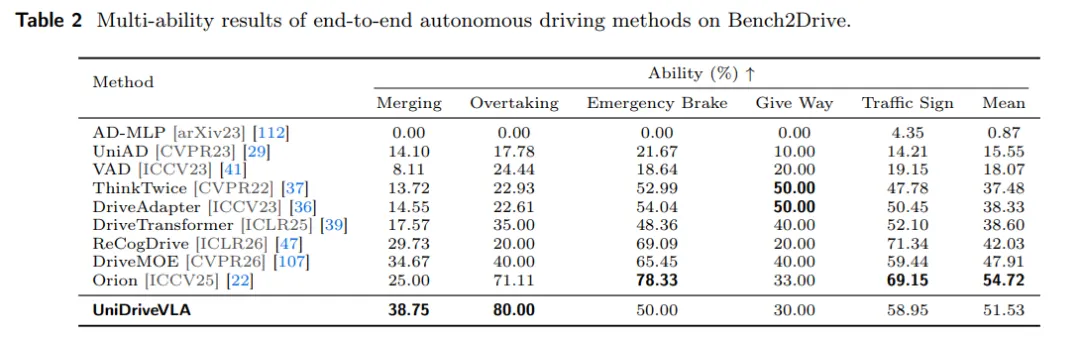
表2| Bench2Drive 多能力场景评测表现
在 nuScenes 的开环轨迹规划设置下,UniDriveVLA-Large 在 ST-P3 和 UniAD 评估协议下都表现出了较好的轨迹预测能力。尤其是在不输入自车状态的设定中,模型仍然保持了较低的平均 L2 误差,说明它能够仅依赖视觉输入完成稳定的驾驶推理;在加入自车状态之后,模型依然维持了竞争力。
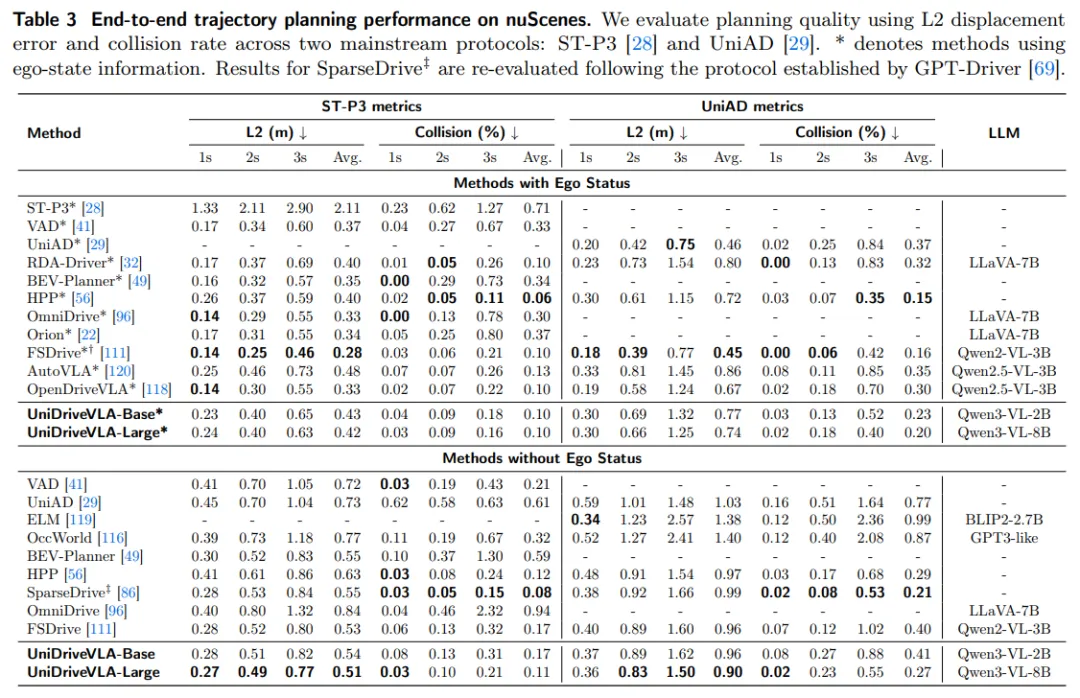
表3| nuScenes 端到端轨迹规划性能
3.4 架构对比与消融实验:专家解耦带来的协同收益
为了验证 MoT 专家解耦的作用,作者将 UniDriveVLA 与共享权重解码器进行了对比。结果显示,采用 MoT 之后,规划任务的平均 L2 误差从 0.641 降至 0.533,碰撞率从 17.5% 降至 14.0%。同时,模型在 DriveBench 和通用 VQA 上的表现也有所提升,说明专家解耦不仅缓解了任务间的优化冲突,也没有牺牲原有的语义理解能力。
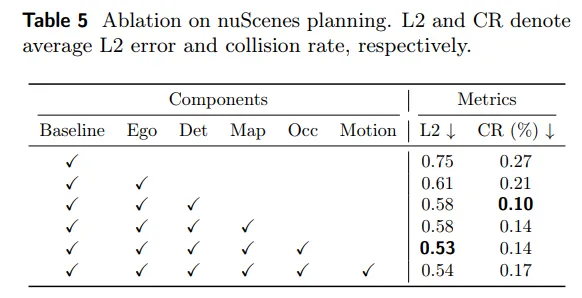
表5| 共享权重解码器与 MoT 架构在理解、感知与规划任务上的对比
进一步的消融实验表明,感知模块的逐步引入会持续改善规划性能。在基线模型上加入 3D 目标检测后,碰撞率明显下降;继续加入占据栅格建模后,模型获得了最优的 L2 误差 0.53。这个结果说明,空间感知并不是对规划的附加项,而是提升驾驶决策质量的关键输入。
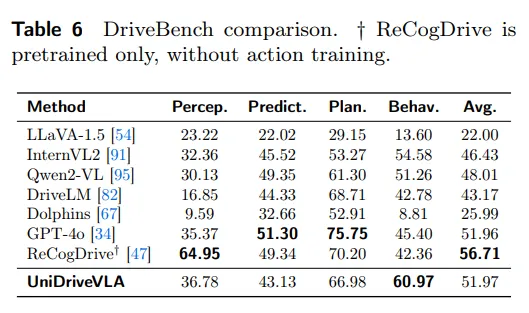
表6| nuScenes 规划组件消融实验
整体来看,UniDriveVLA 的实验结果清晰说明了一点:理解、感知与规划并不是三条彼此独立的性能曲线,而是可以在统一框架下相互支撑、共同提升的三种能力。它既能理解驾驶语义,也能建模空间结构,还能据此生成稳定轨迹,这正是其作为统一驾驶 VLA 框架的核心价值。
04 结论
UniDriveVLA 的核心贡献并不在于提出某个全新的模块,而在于揭示并解决了一个被忽视的结构性问题:在统一 VLA 框架中,语义理解与空间感知会因共享参数而产生表征冲突,导致两者此消彼长。
针对这一瓶颈,UniDriveVLA 采用 Mixture-of-Transformers 架构,将理解、感知与规划分别交由独立的专家子空间建模,并通过掩码联合注意力实现受控的信息交互。同时,稀疏空间感知范式与三阶段渐进训练策略,进一步降低了语义漂移与任务干扰的风险。
实验结果表明,UniDriveVLA 在理解、感知与规划三个维度上均取得一致性提升,验证了“先分工、再协同”这一设计思路的有效性。该框架不仅适用于自动驾驶,也为机器人操作、具身智能等需要紧密耦合感知、理解与行动的场景,提供了一种可扩展的建模思路。
论文标题:UniDriveVLA: Unifying Understanding, Perception, and Action Planning for Autonomous Driving
作者:Yongkang Li, Lijun Zhou, Sixu Yan, Bencheng Liao, Tianyi Yan, Kaixin Xiong, Long Chen, Hongwei Xie, Bing Wang, Guang Chen, Hangjun Ye, Wenyu Liu, Haiyang Sun, Xinggang Wang(华中科技大学 & 小米汽车 & 澳门大学)
论文链接: https://arxiv.org/abs/2604.02190
代码链接: https://github.com/xiaomi-research/unidrivevla

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)