Nature 子刊 | 几十张罕见样本训出SOTA:这套生成式数据扩张范式你必须抄
【行业误区 vs 真实问题】
长久以来,医疗AI圈存在一个巨大的幻觉:只要把ViT或者ResNet的架构魔改得足够深,模型的诊断准确率就能碾压人类。
但残酷的现实是,那些在公开数据集上刷到SOTA的模型,一进真实医院的超声室就原形毕露。真正卡住医疗AI咽喉的从来不是算法架构,而是“数据”本身。 隐私法规的巨墙、罕见病例的稀缺、医院之间的数据孤岛,让医疗深度学习模型永远在“吃不饱”的状态下疯狂过拟合。
这篇由北大、协和、斯坦福等顶尖机构联合发表于《Nature》子刊的论文,彻底掀桌子了。他们解决的不是某个具体的影像分类问题,而是跨越临床数据鸿沟的本质挑战:既然真实的医疗数据拿不到,为什么不直接利用AI“凭空捏造”一个无限大的、没有隐私争议的、连极其细微的病理特征都完美复刻的平行医疗宇宙?

这篇论文,本质上做了: 用350万张真实乳腺超声图像喂出了一台“医疗数据级光刻机”(BUSGen),通过零隐私风险地生成百万量级的超逼真合成数据,直接在早期癌症诊断上降维打击了拥有十几年经验的人类主任医师。
我整理了该论文完整架构与核心算法资料包,感兴趣的可以dd~
核心方法论拆解:不要试图穷尽数据,去生成数据
这篇论文抛弃了传统的“数据增强(翻转、裁剪)”小把戏,将解题思路拔高到了范式级别,整个过程分为两个极具统治力的阶段:
Stage 1:临床物理世界的全量压缩(解决常识匮乏的本质问题) 模型首先不带任何具体任务目的地去看了350万张超声图像。在这个阶段,扩散模型(Diffusion)被当作极其庞大的知识压缩器,它不仅记住了乳房的解剖结构(脂肪、腺体),甚至“理解”了不同超声探头在不同加压手法下产生的伪影和高频声学纹理。
Stage 2:特定病理知识的“按需引爆”与脱敏(解决稀缺与隐私的本质问题) 当你只需要诊断某种极其罕见的早期乳腺癌(如DCIS)时,无需重新收集十万张罕见病图像。只需给模型看几十张(Few-shot)罕见病历,利用轻量级微调,它就能瞬间生成出成千上万张病理特征正确、且在现实中绝对找不到对应患者原型(斩断隐私链)的特定合成数据,硬生生砸出一个用于训练下游模型的完美数据集。
关键技术翻译:不讲玄学,只看工程实现
-
Pixel-space 像素级扩散预训练:放着省算力的底层隐空间不用,非要在计算量极大的“像素级”死磕,为的是死死保住超声图像里最致命也是最微小的病理高频边缘纹理。
-
LoRA + Device Augmentation(设备级增强):给庞大的底层医学常识外挂一个极轻量的“指令包”,配合CycleGAN把一张图伪装成18种不同超声机器扫出来的结果,这叫直接在训练源头掐死设备的“域偏见”。
-
CPSampling 隐私灭绝采样:给生成过程加上了一道纯数字密码学层面的“绝育锁”,彻底斩断生成图像与原始训练病案的相似性连结,直接把医学数据脱敏推到了不需要打磨的绝对高度。
即插即用代码级思路:AI生成数据闭环
虽然论文公开的是一个大工程,但其核心的“生成式数据扩张(Generative Data Scaling)”极度适合被拿来做CV领域的比赛或落地项目。
你可以把这套逻辑放在哪里用? 当你手里只有50张罕见工业缺陷图或罕见病灶图,却面临老板要求训练高鲁棒性分类器的时候:
# 概念级伪代码:如何基于基础模型榨取任务特定数据
from diffusers import StableDiffusionPipeline
import torch
# 1. 加载医学/工业基础大模型
pipeline = StableDiffusionPipeline.from_pretrained("基础大模型权重").to("cuda")
# 2. 注入你的小样本任务LoRA权重 (比如极其罕见的肿瘤)
pipeline.load_lora_weights("你用50张图微调的罕见病LoRA")
# 3. 开启CPSampling(论文核心隐私保护逻辑)与高效求解器加速
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
# 4. 暴力产出:给下游分类器凭空制造1万张训练数据
synthetic_dataset = []
for i in range(10000):
image = pipeline(prompt="...", guidance_scale=7.5, cross_attention_kwargs={"scale": 0.8}).images[0]
synthetic_dataset.append(image)
# 结语:拿这1万张生成的图去训ResNet/ViT,这才是工业界发力的点
视觉冲击:这篇论文的图,懂行的人看一眼就发麻
我强烈建议你翻开原论文,重点看这三张图,图图致命:
-
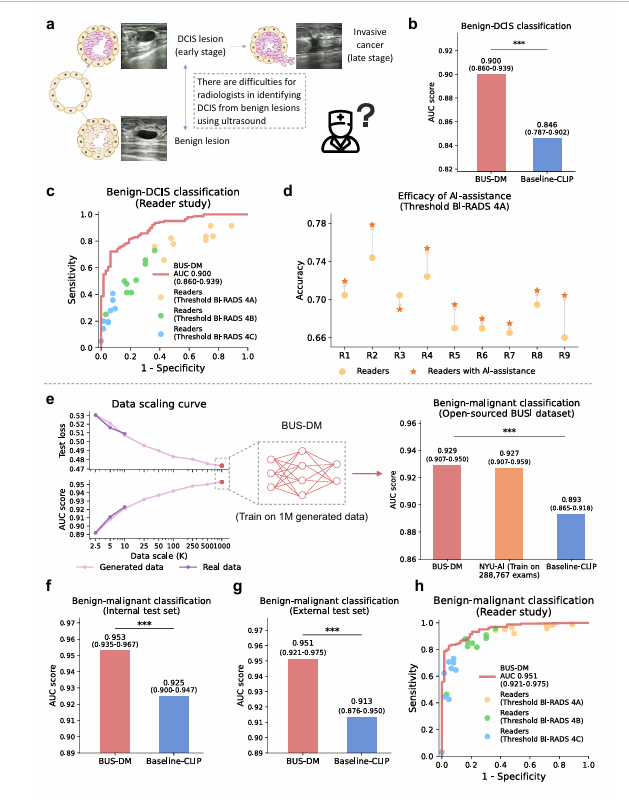
开屏雷击图 —— (见图4c):用于冲击读者认知。在这张散点图里,横轴特异性,纵轴敏感度。红色的平滑大曲线是依靠生成数据训出来的BUSGen下游模型,散落在模型曲线左下角下方的那一堆彩色点,是9名平均从业11年的主任医师。在早期癌症(DCIS)诊断上,**AI的敏感度赢了人类医生整整16.5%**。这就是纯粹的数据暴力美学。
-
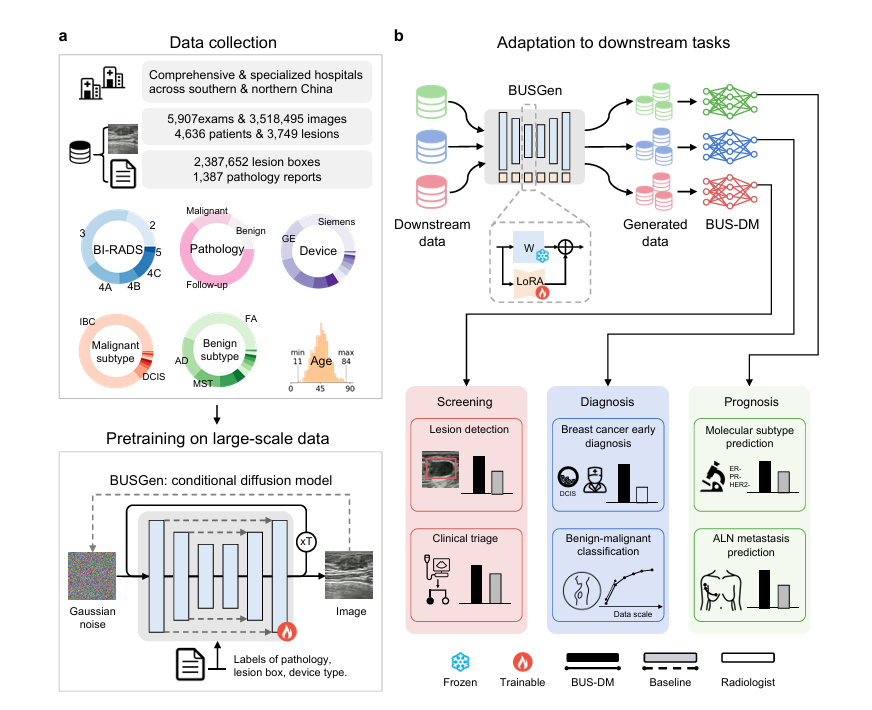
方法论结构图 —— (见图1):用于辅助技术理解。这张图极其直观地展现了左手吸纳350万张多中心数据提取规律,右手通过扩散模型无限吐出“假图”喂给检测算法的完整野心。
-
大一统效果图 —— (见图4e):这是全篇论文最毛骨悚然的一张Scaling Law图。图中展示了真实数据量(深紫色)和生成数据量(浅紫色)随规模扩大的性能提升轨迹。你会发现,这两条线完全重合了!这意味着在超声诊断这个任务上,模型靠想象生成的100万张图,和医生天天打B超真实收录的100万张图,对下游任务的价值等价。 数据采集中心可以宣告转行了。
思想升华:我们正在见证什么?
这篇论文真正重要的并不是做出了一个准确率极高的诊断系统,而是跑通了“用魔法打败魔法”的终极路径:当真实世界的分布存在偏差、涉及伦理、充满噪声时,直接用生成式大模型在旁边重开一个绝对干净、无限扩张的平行宇宙。
总结为一个“范式”:Generative Data Scaling(生成式数据扩张范式)。 下游识别模型不再直接从真实世界“喝水”,而是从生成大模型这座“水质极度纯净的水库”中直接接管知识。
你的延展方向(不管打比赛还是发顶会都用得上)
-
科研/发文方向:切断捷径学习(Shortcut Learning)的纯净剂 论文侧面证实了,多机构真实图像自带采集机器的“原罪偏见(Bias)”。利用这套框架,去验证生成数据是否能作为一种极其强悍的“数据级正则化手段”,定点清除医学模型里对设备和操作习惯的杂散相关性。
-
工程项目方向:多模态闭环预测 目前这篇还停留在从图到标签。如果在生成图的同时,生成对应的多模态探针文本(如BI-RADS描述),甚至反向根据预期的化疗反应去生成病灶演化的时序视频(4D超声生成),在临床决策辅助上将是下一个蓝海。
“医疗AI的终局,或许从来不是去穷尽世界上所有的真实病例,而是让机器在预训练里,提早梦见过所有的生与死。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)