大模型RAG (二)
一、RAG核心
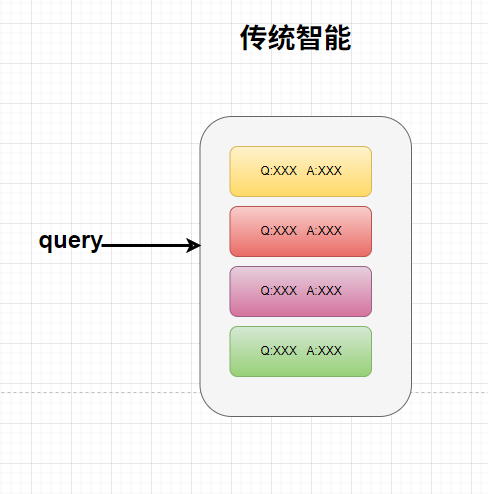
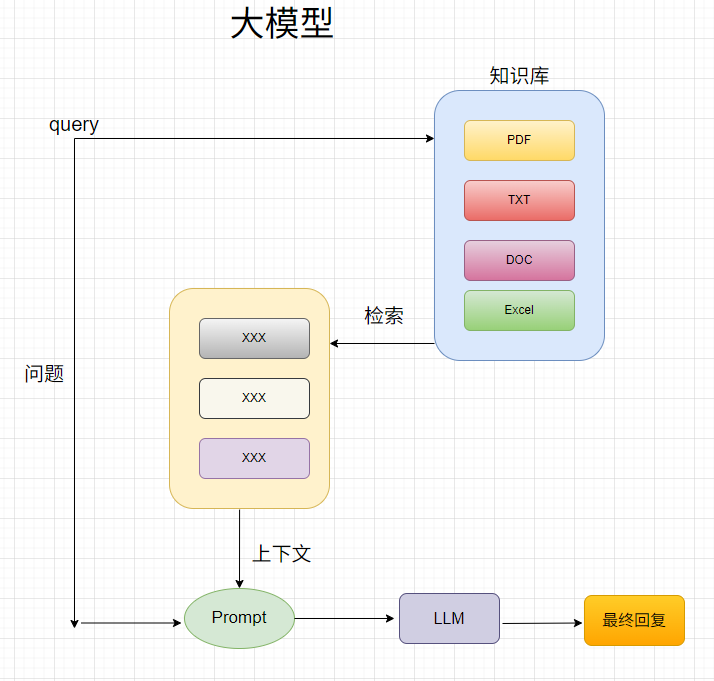
1、传统 VS 大模型
智能客服系统下面是两则设计的原理:
2、向量与Embeddings嵌入向量
2.1. 向量(Vector)
由一组有序数字排成的一维数组,用来表示一个对象在某个空间中的位置或特征。
- 形式:
[x₁, x₂, x₃, ..., xₙ] - 维度:数字的个数 n 就是向量的维度
- 作用:用来量化事物,让计算机能计算、比较、处理
例子:
- 二维向量:
[2, 3] - 三维向量:
[0.1, 0.5, 0.9]
2.2. Embeddings(嵌入向量)
把文字、图片、声音、用户行为等非结构化信息,通过模型(如 Word2Vec、BERT、Transformer)转化成的低维稠密向量。
核心特点:
- 语义相近 → 向量距离近
- 语义无关 → 向量距离远
- 可用于:搜索、推荐、分类、聚类、相似度计算
简单理解:
Embeddings = 把现实世界的东西翻译成计算机能懂的 “语义向量”
举个最经典的例子(词向量)
假设模型训练后得到:
- 国王:
[0.9, 0.1, 0.3, ...] - 王后:
[0.88, 0.12, 0.31, ...] - 苹果:
[0.05, 0.8, 0.02, ...]
你会发现:
- 国王 ↔ 王后:向量很接近
- 国王 ↔ 苹果:向量离得很远
2.3、两者关系
- 向量:是数学基础,是通用工具。
- Embedding:是带有语义信息的特殊向量,专门给 AI 用。
2.4、典型应用
- 搜索:把问题转 embedding,找最相似的文档
- 推荐:把用户、商品转 embedding,匹配相似兴趣
- 聊天 AI:把你的话转 embedding,理解你想表达什么
- 人脸识别:把人脸转 embedding,比对相似度
3、向量间的相似度计算
核心就是:用数学方法衡量两个向量像不像,在 Embedding 里就等于衡量语义 / 特征近不近。
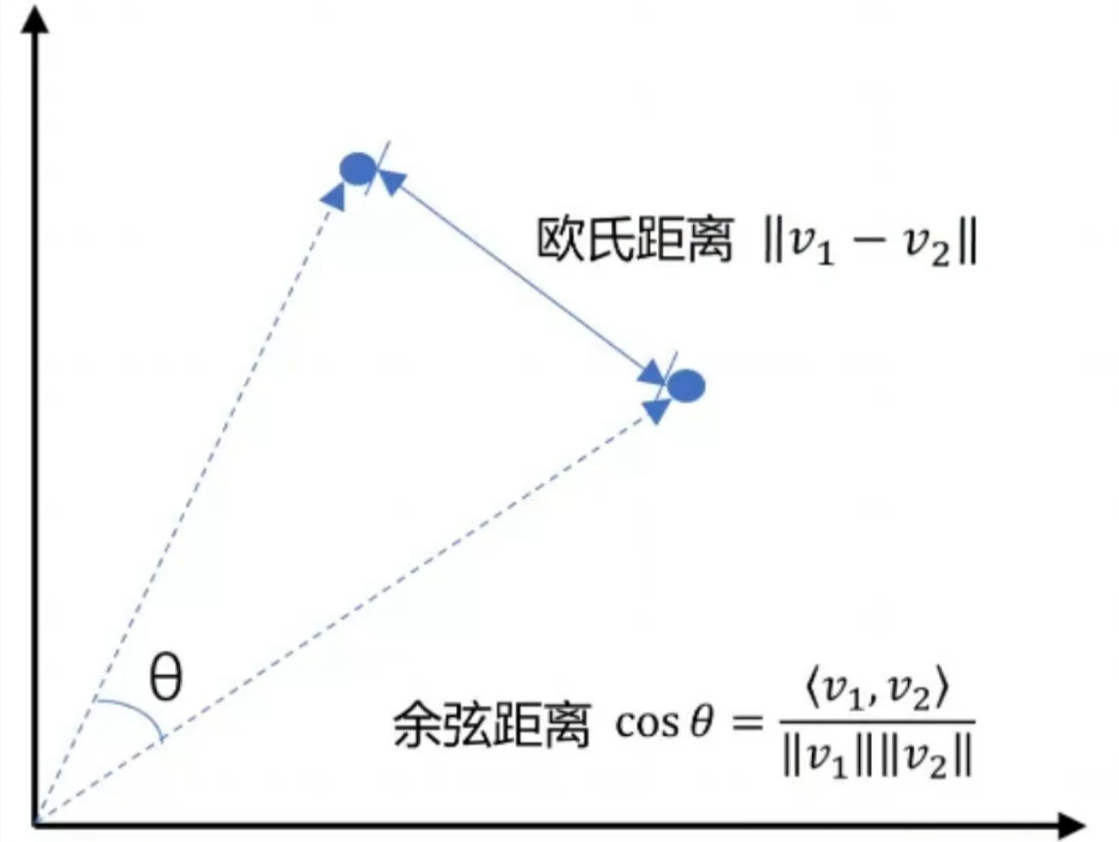
1. 欧式距离(Euclidean Distance)
定义:空间中两点的直线距离。
公式: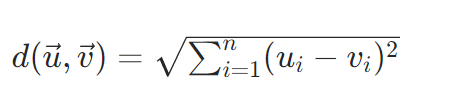
- 距离 越小 → 越相似
- 距离 越大 → 越不相似
适用:坐标类、位置类、低维特征。
2. 余弦相似度(Cosine Similarity)
最常用在 Embedding、文本、推荐里
定义:两个向量夹角的余弦值,只关心方向,不关心长度。
公式: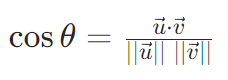
- 结果范围:[-1, 1]
- 越接近 1 → 方向越一致 → 越相似
- 接近 0 → 不相关
- 接近 -1 → 相反
适用:文本 Embedding、语义相似度、推荐、搜索(几乎所有 NLP 场景)。
3. 点积(Dot Product)
公式:![]()
- 值 越大 越相似
- 但受向量长度影响,一般不如余弦相似度稳定
欧式距离与余弦距离图
案例1:文本向量化(Embedding)模型
from openai import OpenAI
from dotenv import load_dotenv
import os
# 默认加载项目根目录下的 .env 文件
load_dotenv()
# 会自动读取环境变量
client=OpenAI()
# 生成文本的嵌入
def get_embeddings(texts,model="text-embedding-v4"):
data=client.embeddings.create(input=texts,model=model).data
print(data)
return [x.embedding for x in data]
test_query=['大模型']
vec=get_embeddings(test_query)
print(vec)
print(vec[0])
print(len(vec[0]))
案例2:「聊天、回答问题、写内容、思考推理」的超强大模型
from openai import OpenAI
from dotenv import load_dotenv
# 默认加载项目根目录下的 .env 文件
load_dotenv()
# 会自动读取环境变量
# 1. 获取client对象,OpenAI类对象
client = OpenAI()
# 若直接通过 阿里云百炼平台 调用 Qwen3-Max 的标准 API(非免费版)
#阿里云Qwen3-Max是通义千问系列的旗舰级推理大模型
# 2. 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role":"system","content":"你是AI助理,回答很简洁"},
{"role":"user","content":"小明有2条宠物狗"},
{"role":"assistant","content":"好的"},
{"role":"user","content":"小红有3只宠物猫"},
{"role":"assistant","content":"好的"},
{"role":"user","content":"总共有几个宠物"}
],
stream=True # 开启了流式输出的功能
)
# 3. 处理结果
for chunk in response:
print(chunk.choices[0].delta.content,end=' ',flush=True) # end=' '每一段之间以空格分隔, # flush=True立刻刷新缓冲区说明:
调用模型传入的参数messages,是list对象,即表明其支持非常多的消息在内。
我们可以将历史消息填入,让模型知晓对话的上下文,更好的回答。
当前的历史消息是一次性的,如果是生产系统可以将消息保存到文件、数据库等持久化工具内,需要的时候提取使用 后续学习LangChain库,会学习短期记忆和长期记忆的使用方法。
案例3:文本向量化(Embedding)模型-(余弦距离和欧式距离)
from openai import OpenAI
from dotenv import load_dotenv
import numpy as np
#该函数用于计算两个数组的点积(内积)。
from numpy import dot
#该函数用于计算向量的范数(模),默认为2范数(欧几里得范数)。
from numpy.linalg import norm
import os
# 默认加载项目根目录下的 .env 文件
load_dotenv()
# 会自动读取环境变量
client = OpenAI()
def cos_sim(vec1, vec2):
'''余弦距离,越大越相似'''
return dot(vec1, vec2) / (norm(vec1)*norm(vec2))
def os_line(vec1,vec2):
'''欧式距离,越小越相似'''
x=np.asarray(vec1)-np.asarray(vec2)
return norm(x)
def get_embeddings(texts,model='text-embedding-v4'):
'''获取文本的向量表示'''
data=client.embeddings.create(input=texts,model=model).data
#返回一个包含所以嵌入表示的列表
return [d.embedding for d in data]
query = "科技前沿"
documents = [
"OpenAI 发布 GPT-5 模型,推理与代码能力实现重大突破",
"中国自研量子计算机“九章三号”刷新光量子计算世界纪录",
"俄乌冲突持续,欧盟宣布新一轮对俄能源制裁",
"华为发布全新鸿蒙OS 5.0,实现全场景设备无缝互联",
"联合国安理会上,俄罗斯与美国,伊朗与以色列“吵”起来了"
]
# 获取查询向量
query_vec = get_embeddings([query])[0];
# 获取文档向量
doc_vecs = get_embeddings(documents);
print("余弦距离:")
print(cos_sim(query_vec,query_vec))
for ve in doc_vecs:
print(cos_sim(query_vec,ve))
print("\n 欧式距离:")
print(os_line(query_vec,query_vec))
for ve in doc_vecs:
print(os_line(query_vec,ve))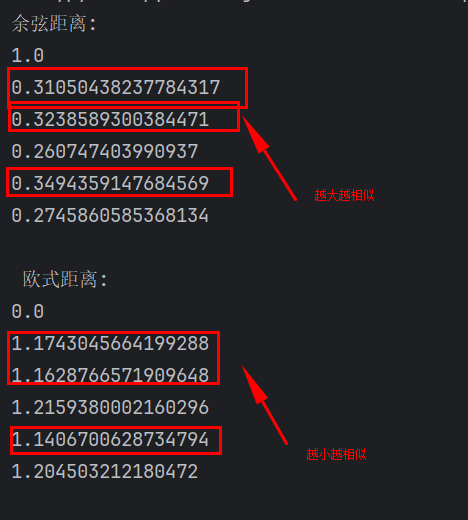

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)