2.6 Python 装饰器与函数式编程:AI 开发必备技能
本文适合谁:理解 Java 注解(@Annotation)机制、想搞清楚 Python 装饰器如何工作的工程师。读完本篇,你能看懂 LangChain 的
@tool、FastAPI 的@app.get、LangSmith 的@traceable背后的原理。
LangChain 的工具定义代码如下:
@tool
def search_web(query: str) -> str:
"""在网上搜索信息,返回搜索结果摘要。"""
return tavily_client.search(query)
@tool 是什么?为什么加了一个 @tool,这个函数就变成了 Agent 可以调用的工具?docstring 又是怎么变成工具描述的?
对有 Java 背景的开发者来说,这种代码模式不陌生——Spring 的 @Service、@Transactional,MyBatis 的 @Select,到处都是注解。但 Python 的装饰器和 Java 注解是两种完全不同的东西。Java 注解是元数据,由框架在运行时用反射处理。Python 装饰器是函数调用,是在函数定义时就执行的代码。
理解这个区别,才能真正读懂 LangChain、LangSmith、FastAPI 的源码。
1.1 装饰器的本质:函数是一等公民
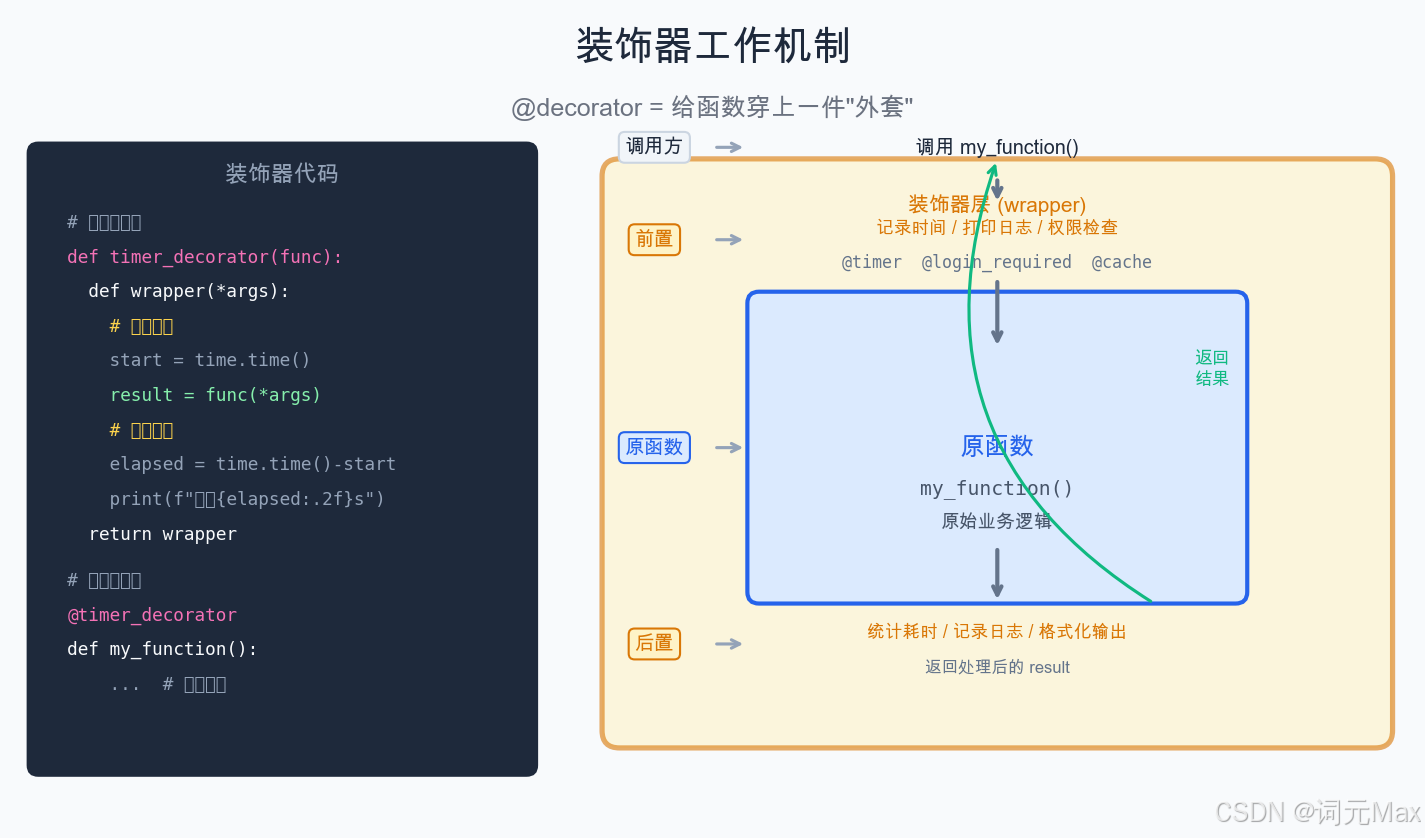
装饰器的包装机制与执行顺序
Python 里,函数是一等公民。这句话的意思是:函数和字符串、数字、列表一样,可以赋值给变量,可以作为参数传递,可以作为返回值。
def greet(name: str) -> str:
return f"你好,{name}"
# 函数可以赋值给变量
say_hello = greet
print(say_hello("张三")) # 你好,张三
# 函数可以作为参数传递
def apply(func, value):
return func(value)
print(apply(greet, "李四")) # 你好,李四
Java 里做不到这一点,至少不能这么直接。Java 8 之后有 Lambda 和函数式接口,但依然需要类型声明和包装。
装饰器就是接收函数、返回函数的高阶函数(高阶函数:把其他函数当作参数或返回值的函数)。
def my_decorator(func):
def wrapper(*args, **kwargs):
print("函数执行前")
result = func(*args, **kwargs)
print("函数执行后")
return result
return wrapper
@my_decorator
def say_hi():
print("Hi!")
say_hi()
# 输出:
# 函数执行前
# Hi!
# 函数执行后
@my_decorator 只是语法糖,等价于:
say_hi = my_decorator(say_hi)
装饰器在函数定义时就执行,不是在调用时。这和 Java 注解在运行时被反射处理是本质区别。
1.2 实现一个计时装饰器
用装饰器实现计时,对比一下 Java 的 AOP(Aspect-Oriented Programming,面向切面编程,一种把日志、事务等横切逻辑统一管理的编程方式)。
Java 做法是定义一个切面类,用 @Aspect 注解,再用 @Around 拦截目标方法。代码分散在两个地方,读起来需要在脑子里把切面和业务代码拼起来。
Python 的装饰器直接、内联:
import time
import functools
def timer(func):
@functools.wraps(func) # 保留原函数的元信息
def wrapper(*args, **kwargs):
start = time.perf_counter()
result = func(*args, **kwargs)
elapsed = time.perf_counter() - start
print(f"{func.__name__} 执行耗时:{elapsed:.4f}s")
return result
return wrapper
@timer
def call_llm(prompt: str) -> str:
time.sleep(0.1) # 模拟 LLM 调用
return f"response to: {prompt}"
call_llm("你好")
# call_llm 执行耗时:0.1012s
@functools.wraps(func) 这一行很重要。没有它,wrapper.__name__ 会是 "wrapper" 而不是 "call_llm",wrapper.__doc__(函数的文档字符串,即紧跟在函数定义后的那段注释字符串,用于说明函数用途)也会丢失。LangChain 的 @tool 装饰器依赖函数的 __doc__ 属性获取工具描述,如果不用 functools.wraps,工具描述就会丢失。
1.3 带参数的装饰器:三层嵌套
有时候装饰器本身需要接收参数。以给 @timer 加一个 prefix 参数为例:
def timer(prefix: str = ""):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter()
result = func(*args, **kwargs)
elapsed = time.perf_counter() - start
label = f"[{prefix}] " if prefix else ""
print(f"{label}{func.__name__} 耗时:{elapsed:.4f}s")
return result
return wrapper
return decorator
@timer(prefix="LLM调用")
def call_gpt(prompt: str) -> str:
time.sleep(0.05)
return "some response"
call_gpt("什么是 Agent")
# [LLM调用] call_gpt 耗时:0.0501s
三层嵌套是带参数装饰器的固定模式:最外层接收装饰器参数,中间层接收函数,最内层是实际执行逻辑。
理解这个模式的方法是从内往外读:最里面的 wrapper 是真正干活的函数,中间的 decorator 是标准装饰器结构,最外面的 timer 是"生产装饰器的工厂"。
1.4 类装饰器:用 __call__ 实现
除了函数,类也可以作为装饰器。用 __call__ 方法让类的实例变成可调用对象:
class RetryDecorator:
def __init__(self, max_retries: int = 3, delay: float = 1.0):
self.max_retries = max_retries
self.delay = delay
def __call__(self, func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(self.max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt == self.max_retries - 1:
raise
print(f"第 {attempt + 1} 次失败:{e},{self.delay}s 后重试")
time.sleep(self.delay)
return wrapper
@RetryDecorator(max_retries=3, delay=0.5)
def unstable_api_call(url: str) -> dict:
# 模拟不稳定的 API
import random
if random.random() < 0.7:
raise ConnectionError("网络超时")
return {"status": "ok"}
类装饰器比函数装饰器更适合有状态的场景,比如记录调用次数、管理连接池。
1.5 AI 开发中的常见装饰器
理解了原理,再看框架里的装饰器就清晰多了。
@tool(LangChain)
from langchain.tools import tool
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。city 参数是城市名称,如"北京"、"上海"。"""
# 实际调用天气 API
return f"{city}今天晴,气温 25°C"
LangChain 的 @tool 做了这几件事:从函数签名提取参数 schema,从 docstring 提取描述,把函数包装成 StructuredTool 对象。Agent 看到的不是函数,而是一个有 name、description、args_schema 属性的对象。
@traceable(LangSmith)
from langsmith import traceable
@traceable(name="llm-call", run_type="llm")
def call_openai(messages: list) -> str:
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response.choices[0].message.content
加了 @traceable,LangSmith 会自动记录函数的输入、输出、耗时,在 LangSmith 的 UI 里可以看到完整的调用链。这个装饰器的实现原理是在函数调用前后向 LangSmith 发送 trace 数据。
@cache(functools)
from functools import lru_cache
@lru_cache(maxsize=128)
def get_embedding(text: str) -> tuple:
# LLM 调用很贵,相同文本不要重复 embedding
response = openai_client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return tuple(response.data[0].embedding) # list 不可哈希,转成 tuple
@lru_cache 是标准库里的缓存装饰器,基于 LRU(Least Recently Used,最近最少使用)策略——当缓存满了,优先淘汰最久没被用到的结果。Embedding 调用有成本,缓存能减少重复请求。
1.6 函数式编程基础
装饰器是高阶函数的应用,函数式编程的基础知识同样值得掌握。
map、filter、reduce 是三个经典的高阶函数:
from functools import reduce
scores = [85, 92, 78, 96, 61, 88]
# filter:筛选及格分数
passed = list(filter(lambda x: x >= 60, scores))
# map:换算成百分比
percentages = list(map(lambda x: x / 100, scores))
# reduce:求总分
total = reduce(lambda acc, x: acc + x, scores)
在实际代码里,列表推导式比 map/filter 更 Pythonic,可读性更好:
# 比 filter + map 的写法更直观
passed_percentages = [x / 100 for x in scores if x >= 60]
map/filter 适合函数已经存在、不需要写 lambda 的情况:
import json
raw_data = ['{"name": "张三"}', '{"name": "李四"}']
parsed = list(map(json.loads, raw_data)) # 比列表推导式简洁
1.7 完整示例:实现工具注册装饰器
下面是一个模仿 LangChain @tool 实现的简化版工具注册系统,可以实际运行:
import inspect
import functools
from typing import Callable, Any
# 全局工具注册表
_tool_registry: dict[str, dict] = {}
def tool(func: Callable) -> Callable:
"""把函数注册为 Agent 工具,从函数签名和 docstring 提取元信息。"""
# 提取函数签名
sig = inspect.signature(func)
params = {}
for name, param in sig.parameters.items():
annotation = param.annotation
params[name] = {
"type": annotation.__name__ if annotation != inspect.Parameter.empty else "any",
"required": param.default == inspect.Parameter.empty
}
# 提取 docstring 作为工具描述
description = inspect.getdoc(func) or "无描述"
# 注册到全局工具表
_tool_registry[func.__name__] = {
"name": func.__name__,
"description": description,
"parameters": params,
"func": func
}
@functools.wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
wrapper.is_tool = True
wrapper.tool_info = _tool_registry[func.__name__]
return wrapper
def get_tools() -> list[dict]:
"""获取所有已注册的工具列表。"""
return [
{k: v for k, v in info.items() if k != "func"}
for info in _tool_registry.values()
]
# 使用示例
@tool
def search_web(query: str) -> str:
"""在互联网上搜索信息。query 是搜索关键词。"""
return f"搜索结果:关于 '{query}' 的信息..."
@tool
def calculate(expression: str) -> float:
"""计算数学表达式。expression 是合法的 Python 数学表达式,如 '2 + 3 * 4'。"""
return eval(expression)
@tool
def get_current_time() -> str:
"""获取当前系统时间。"""
from datetime import datetime
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if __name__ == "__main__":
import json
# 查看注册的工具
tools = get_tools()
print("已注册的工具:")
print(json.dumps(tools, ensure_ascii=False, indent=2))
# 直接调用工具
print("\n直接调用:")
print(search_web("Python 装饰器"))
print(calculate("2 ** 10"))
print(get_current_time())
# 模拟 Agent 根据工具名调用
print("\nAgent 调用:")
tool_name = "calculate"
tool_args = {"expression": "100 / 4 + 5"}
result = _tool_registry[tool_name]["func"](**tool_args)
print(f"调用 {tool_name},结果:{result}")
运行这段代码,工具的 name、description、parameters 会被自动提取出来,结构和 LangChain 工具的 schema 非常接近。
1.8 装饰器在 LangChain 中的实际应用
理解了装饰器原理,看 LangChain 的实际代码会更清晰。这里用三个真实场景演示:
1.8.1 场景1:@tool 定义 LangChain 工具
from langchain_core.tools import tool
from pydantic import BaseModel, Field
# 方式一:直接用 @tool(简单工具)
@tool
def get_weather(city: str) -> str:
"""获取指定城市的当前天气。city 是中文城市名,如"北京"。"""
# 这里 @tool 做了什么:
# 1. 从函数名提取工具名称:"get_weather"
# 2. 从 docstring 提取工具描述
# 3. 从类型注解生成参数 schema:{"city": {"type": "string"}}
# 4. 把函数包装成 StructuredTool 对象,Agent 可以调用
return f"{city}今天晴,气温 25°C"
# 查看工具的元信息(Agent 调用前会看这些)
print(get_weather.name) # "get_weather"
print(get_weather.description) # "获取指定城市的当前天气。..."
print(get_weather.args) # {"city": {"title": "City", "type": "string"}}
# 方式二:用 pydantic 定义复杂参数(推荐,参数描述更精确)
class SearchInput(BaseModel):
query: str = Field(description="搜索关键词,尽量简洁")
max_results: int = Field(default=5, ge=1, le=20, description="返回结果数量")
@tool(args_schema=SearchInput)
def search_web(query: str, max_results: int = 5) -> list[str]:
"""搜索互联网获取最新信息。当需要查询实时数据时使用。"""
# Field 的 description 会传给 LLM,帮助它理解如何填写参数
return [f"搜索结果 {i}: {query} 相关内容" for i in range(max_results)]
1.8.2 场景2:@traceable 追踪 LLM 调用链路
from langsmith import traceable
from openai import OpenAI
client = OpenAI()
@traceable(name="llm-call", run_type="llm")
def call_openai(messages: list[dict], model: str = "gpt-4o") -> str:
"""
@traceable 做了什么:
- 记录函数调用的输入(messages, model)
- 记录函数调用的输出(返回的文字)
- 记录耗时
- 上报到 LangSmith,在 UI 里可以看到完整链路
"""
response = client.chat.completions.create(
model=model,
messages=messages
)
return response.choices[0].message.content
@traceable(name="rag-pipeline")
def rag_pipeline(question: str) -> str:
"""整个 RAG 流程也可以追踪,LangSmith 会展示嵌套调用树"""
docs = retrieve_documents(question) # 内部调用,也可以加 @traceable
context = format_context(docs)
answer = call_openai([ # 这里会嵌套在 rag-pipeline 下
{"role": "system", "content": f"参考资料:{context}"},
{"role": "user", "content": question}
])
return answer
1.8.3 场景3:@app.post FastAPI 路由注册
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI()
class ChatRequest(BaseModel):
message: str
session_id: str | None = None
class ChatResponse(BaseModel):
reply: str
tokens_used: int
@app.post("/chat", response_model=ChatResponse)
async def chat_endpoint(request: ChatRequest) -> ChatResponse:
"""
@app.post("/chat") 做了什么:
- 注册 POST /chat 路由
- 从 ChatRequest 的类型注解自动生成请求 body 的 JSON Schema
- 从 ChatResponse 的类型注解自动生成响应的 JSON Schema
- 在 /docs 页面自动生成交互式 API 文档
"""
try:
reply = call_openai([{"role": "user", "content": request.message}])
return ChatResponse(reply=reply, tokens_used=100)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
1.9 总结
| 装饰器 | 来自 | 做了什么 | Java 等价 |
|---|---|---|---|
@tool |
LangChain | 提取元信息,注册为 Agent 工具 | @Service + XML 配置 |
@traceable |
LangSmith | 记录输入输出,上报链路追踪 | @Around 切面 |
@app.post |
FastAPI | 注册路由,生成 API 文档 | @PostMapping |
@lru_cache |
标准库 | 缓存函数返回值(按参数去重) | Spring @Cacheable |
@retry |
tenacity | 失败自动重试,支持指数退避 | Spring Retry |
装饰器的本质是:接收函数、返回函数的高阶函数,加上 @ 语法糖。
掌握这一点,再去看 LangChain 的 @tool、LangSmith 的 @traceable、FastAPI 的 @app.get,就能看清楚每个装饰器背后做了什么:这里用了 functools.wraps,那里用了三层嵌套,这里在函数定义时做了注册。
Python 框架大量使用装饰器,不是为了炫技,而是因为这种模式让调用侧极其简洁——一行 @tool 就完成了工具注册,而不需要像 Java 那样写一堆配置类。理解装饰器,是读懂 AI 框架源码的前提。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)