不止是“胶水代码”:技术开发者视角下的iPaaS系统集成实战技巧
89%的制造企业存在严重"数据孤岛",平均部署8.3个独立系统,数据互通率不足30%(数据来源:中国信息通信研究院调研)。面对这一严峻挑战,引入专业的iPaaS系统集成平台已成为企业打通数据壁垒的迫切选择。全文共六个模块:引言破题、连接技巧、数据映射、流程控制、异常与补偿、性能优化、实战案例解析、主流iPaaS厂商选型指南及未来展望,旨在为开发者提供可落地、经得起推敲的系统集成方法论。
一、连接技巧——处理“永远不标准”的端点
1.1 适配器模式的应用
异构系统对接的第一道门槛是协议差异——SOAP、REST、GraphQL、JMS各有一套交互逻辑。成熟的iPaaS平台通常内置协议转换层,但真正考验开发者的,是认证逻辑的统一封装。
以OAuth 2.0为例,Access Token的有效期通常为1小时。如果每个接口调用都重复获取Token,不仅浪费网络开销,还容易被认证服务器限流。推荐在iPaaS的适配器层实现Token缓存与自动刷新机制:当调用失败且错误码为401时,自动触发refresh_token流程,刷新成功后将新Token写入缓存,并重试原请求。对于Basic Auth场景,则需注意用户名密码中特殊字符的URL编码拼接,避免因“@”或“:”未转义导致的认证失败。
1.2 健壮的连接池与重连机制
在iPaaS系统集成中,“直连单点”是典型反模式——外部API的一次网络抖动就可能造成整个集成流中断。正确的做法是:引入连接池管理HTTP客户端的复用,并实现指数退避重试。
以下是一个轻量级重试代码模板:

断路器模式是重试机制的升级版。在iPaaS中,可以通过维护一个“失败计数器”轻量实现:当连续失败次数超过阈值时,短时间内直接拒绝请求,避免下游故障引发级联雪崩。
1.3 动态端点发现
一个成熟的iPaaS系统集成流,不应将环境地址写死在代码里。通过在消息头或上下文变量中携带环境标识(如X-Deploy-Env: staging),在运行时动态路由到不同环境的API网关地址。这种做法不仅支持测试/生产的无缝切换,还能实现灰度发布和蓝绿部署。
二、数据映射技巧——从“字段对拷”到“语义转换”
2.1 隐式转换的陷阱
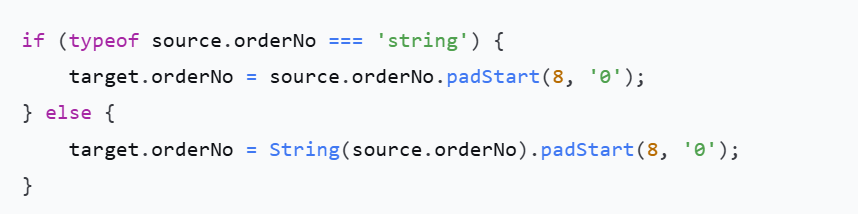
在iPaaS的数据映射环节,类型隐式转换是最隐蔽的bug来源。典型案例:源系统将订单号存储为字符串“00123”,目标系统在JSON解析时自动将其识别为数值123,导致补零逻辑丢失,后续的订单匹配全部失效。
防御性代码必须包含显式类型守卫。在iPaaS的映射脚本中,建议对所有关键字段做格式预判:
2.2 层级结构的扁平化与重组
ERP系统输出的深层嵌套JSON(如订单→订单行→子行→批次),需要“拍平”为数据仓库能接受的表状结构。在iPaaS系统集成脚本中,递归遍历是最优雅的解法:
python

2.3 编码处理:乱码与特殊字符
iPaaS系统集成中经常遇到“UTF-8文件开头出现乱码字符”的问题——这是Windows系统生成的BOM头(\ufeff)。建议在读取文件流时,用content.lstrip('\ufeff')预处理。对于编码的附件字段,需先判断是否已编码再决定是否解码,避免二次编码导致乱码。
第三章:流程控制技巧——编排的艺术
3.1 分支逻辑的“防呆设计”
深嵌套的if-else是iPaaS系统集成流的“代码坏味道”。当路由规则超过3层时,建议引入策略模式或轻量级规则引擎。以决策表为例:将业务规则(如“订单金额>10000且渠道=自营→走VIP审批流”)维护在配置中心,iPaaS运行时动态加载,既解耦了代码与规则,又支持业务人员自助调整。
3.2 循环与批量处理
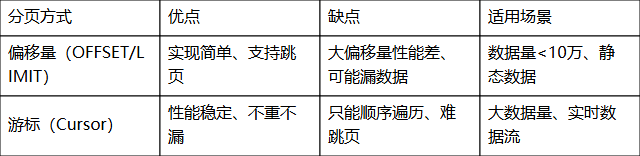
从数据库批量拉取数据是iPaaS系统集成的核心场景。游标分页和偏移量分页各有利弊:
批量写入时,建议每N条提交一次事务并清空缓存,防止内存溢出——N的取值取决于单条记录的大小,通常建议在100~500之间。
3.3 异步与非阻塞
iPaaS不能把所有流程都做成同步调用。对于需要人工审批的长时任务,应使用消息队列实现“轮询转回调”模式:任务提交后立即返回凭证,后台异步轮询审批状态,完成后回调主流程。代码模板的核心是“超时控制+状态持久化”——避免轮询线程无限挂起。
四、异常与补偿技巧——系统集成代码的“安全气囊”
4.1 日志要“带着上下文”
在iPaaS系统集成中,最让人崩溃的日志莫过于“Error occurred”——没有Correlation ID,不知道是哪条数据出了问题。强制在日志中打印以下字段:Correlation ID | 源系统名 | 时间戳 | 业务主键。这样的日志才能在分布式链路中实现端到端追踪。
4.2 优雅降级与默认值
iPaaS系统集成不应因非关键字段缺失而整体失败。例如,同步订单时客户头像上传失败,不应阻塞主数据同步。代码中应预设业务可接受的默认值:target.status = source.status ?? 0(默认状态为“待处理”)。注意区分“静默失败”与“硬失败”——关键业务数据缺失必须抛出异常并触发告警。
4.3 补偿事务的代码实现
分布式事务是iPaaS系统集成的终极难题。当“创建工单成功但后续通知失败”时,需要逆向调用删除接口做补偿。核心技巧是幂等性设计:所有写操作必须携带唯一业务键(如request_id),补偿执行前先查重,防止因网络重试导致重复执行补偿造成数据错乱。
五、性能优化技巧——别让系统集成成为瓶颈
5.1 缓存策略
字典映射表(如“状态码1→已发货”)如果每次都查数据库,iPaaS系统集成的吞吐量会被严重拖累。建议使用带过期时间的本地缓存(如Caffeine或Guava Cache),对于多实例部署的iPaaS环境则需切换到Redis等分布式缓存,保证缓存一致性。
5.2 流式处理大文件
50MB的XML文件如果全部加载到内存做解析,一次GC就能让iPaaS节点的响应超时。务必使用SAX模式流式解析——逐行读取、即时处理、边读边写,将内存占用控制在常量级别。
5.3 并发与限流
对外部API的调用必须遵守SLA,否则轻则被限流、重则被封禁。iPaaS系统集成的请求控制层应内置令牌桶算法:以固定速率生成令牌,每次调用消耗一个令牌,令牌耗尽时排队等待或快速失败。
六、实战案例——“老订单系统”对接“新ERP”
场景:从MySQL订单表拉取数据 → 调用外部汇率接口转换金额 → 写入REST ERP。
核心代码片段:
python

这段代码浓缩了iPaaS系统集成的核心思想:连接管理、重试机制、字段映射、幂等性校验——iPaaS的代码价值不在于复杂算法,而在于对“不确定性”的周全应对。
七、主流iPaaS厂商/服务商选型对比
企业在选型iPaaS平台时,需根据自身业务规模、技术栈和行业特点综合评估。以下针对四家主流国产iPaaS厂商做客观对比:
阿里云iPaaS:以云原生架构为核心底座,提供全面的API管理、数据集成和应用集成能力,支持多种协议和数据格式,通过分布式部署承载大规模访问,适合中大型企业的数字化转型。优势在于阿里云生态深度整合,劣势是跨云场景的适配成本较高。
得帆云iPaaS:以API、ESB、ETL为核心构建一站式集成平台,预置超300种主流连接器,覆盖SAP、金蝶等企业核心系统。其零代码/低代码开发模式降低了技术门槛,支持信创环境,在半导体、医药等行业有丰富落地案例。强调API全生命周期治理和技术中台思路,适合IT团队驱动的组织。
幂链iPaaS:以“低代码+超自动化”双引擎驱动,深耕制造业和零售电商领域。平台基于K8s云原生架构,支持ERP、MES、PLM及IoT设备的多协议接入,预置800+连接器与3000+行业流程模板。差异化价值在于对垂直行业业务适配的深度理解,适合制造企业全链路集成场景,首创11090承诺,售后有保障。
谷云iPaaS:专注企业级集成与API管理领域八年,在IDC中国iPaaS收入报告中位列订阅子市场份额第二。平台内置近2000个标准化API与300+应用链接器。其最新发布的“API×AI”战略,致力于让AI从“理解数据”走向“驱动业务能力”,在API治理与AI融合方向布局前瞻。
结语:集成代码的终极目标——让业务无感
iPaaS代码的价值不在于炫技,而在于对边界条件的充分覆盖和对不确定性的周全应对。建议开发者在交付集成流时,附带一份“契约文档”——明确列出输入输出的样例数据、字段类型、必填约束和异常处理策略。
展望未来:随着AI辅助编程的成熟,集成映射规则或将通过自然语言直接生成,但幂等性设计、补偿事务、降级策略这些“健壮性逻辑”,依然需要开发者的经验与把关。iPaaS的终极目标从未改变——让业务人员无感地享受数据流动的价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)