【ICLR 2025】学习引导式滚动时域优化(L-RHO)用于长周期组合优化问题
文章目录
摘要
这篇论文关注的是一类长周期组合优化问题(Long-Horizon Combinatorial Optimization Problems, long-horizon COPs)。这类问题的共同特点是:决策变量很多,变量之间有强依赖,而且决策需要沿时间轴逐步展开。柔性作业车间调度问题(Flexible Job-Shop Scheduling Problem, FJSP)就是一个典型例子。
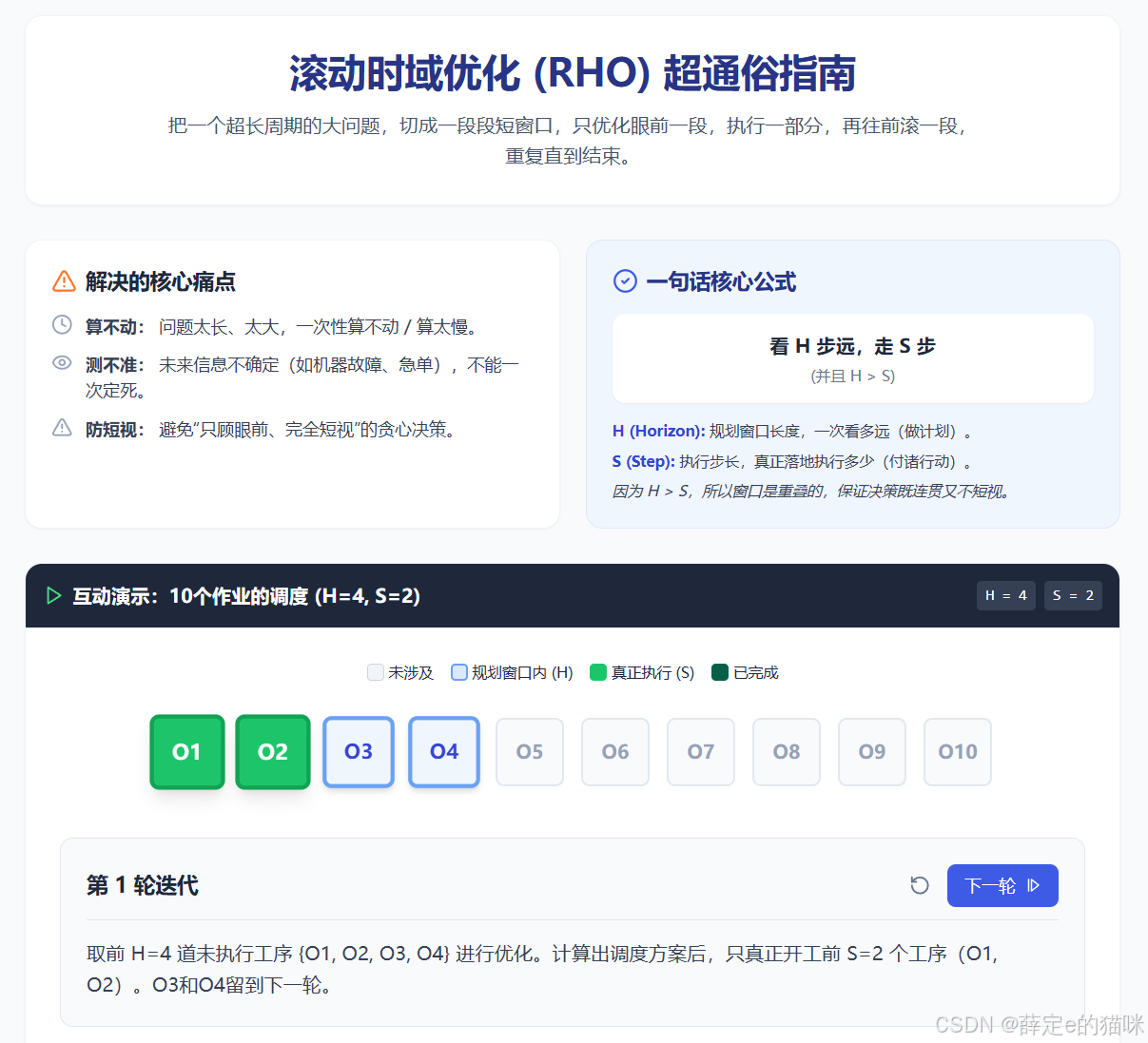
滚动时域优化(Rolling Horizon Optimization, RHO)是处理这类问题的一种自然思路:不一次性求解完整大问题,而是把问题切成多个带重叠窗口的短周期子问题,每次只执行其中一部分,再把窗口向前滚动。这样可以提升可扩展性,也能减少短视决策。
但 RHO 的问题也正来自这个“重叠窗口”:相邻窗口会反复优化一批相同工序,其中很多工序在前后两次求解中的机器分配其实不会变。重复优化这些稳定工序,会带来明显冗余。
L-RHO 的核心想法是:用学习模型预测哪些重叠工序可以沿用上一轮机器分配,然后把这些分配固定下来,只让求解器优化真正不稳定的部分。 在 FJSP 上,这相当于让神经网络帮助 RHO 缩小每个子问题的可变决策空间。
论文实验显示,L-RHO 相比 Default RHO 最高可获得 54% 的求解时间提升,同时解质量最高提升 21%。更重要的是,它在标准离线 FJSP、延迟目标、拥塞场景、观测噪声、机器故障和在线调度场景中都保持了较好的稳定性。
论文动机
组合优化问题(COP)通常具有 NP 难特性。实际场景中的 COP 还往往规模很大,例如制造调度、供应链、运输、医疗资源分配等问题,不仅变量数量多,而且变量之间有复杂约束。
已有方法中,很多分解策略侧重于空间分解或结构分解,例如按变量集合、路径片段、机器集合或局部邻域切分问题。这类方法在不少任务上有效,但面对长周期问题时并不总是合适,因为长周期 COP 的难点不仅在规模,还在时间维度上的依赖。
RHO 提供了一种更贴合时间结构的分解方式。它维护一个规划窗口,每次只求解窗口内的子问题,执行前若干个决策后再向前滚动窗口。窗口之间有重叠,重叠部分可以缓解边界处的短视决策。
问题是,重叠也会导致冗余。设当前窗口和上一个窗口共享一批工序,如果其中很多工序最终仍然被分配到同一台机器,那么重新把这些工序作为自由变量交给求解器,实际是在浪费搜索预算。
本文的切入点很直接:既然相邻 RHO 窗口中存在大量稳定决策,那么能不能学习这种稳定性,在求解前先固定一部分变量?L-RHO 就是这个思路的实现。
预备知识
- FJSP定义
柔性作业车间调度问题(FJSP)可以理解为 JSP 的扩展版。一个实例包含:
- 作业集合 T \mathcal{T} T;
- 机器集合 M \mathcal{M} M;
- 工序集合 O \mathcal{O} O。
每个作业 j j j 由若干道按顺序执行的工序组成:
O j , 1 → O j , 2 → ⋯ → O j , n j O_{j,1} \to O_{j,2} \to \dots \to O_{j,n_j} Oj,1→Oj,2→⋯→Oj,nj
每道工序 O j , k O_{j,k} Oj,k 可以在若干台兼容机器 M j , k \mathcal{M}_{j,k} Mj,k 上加工,不同机器的加工时长可能不同。一个 FJSP 解通常包括两部分:
-
机器分配: m : O → M m: \mathcal{O} \to \mathcal{M} m:O→M,表示每道工序的机器分配,满足 m ( O j , k ) ∈ M j , k m(O_{j,k}) \in \mathcal{M}_{j,k} m(Oj,k)∈Mj,k对所有 j , k j,k j,k成立;
-
调度方案: π : { O j , k ∣ ∀ j , k } → N \pi: \{O_{j,k} \mid \forall j,k\} \to \mathbb{N} π:{Oj,k∣∀j,k}→N,表示每道工序的加工开始时间。
工序 O j , k O_{j,k} Oj,k的加工结束时间记为 π t ( O j , k ) : = π ( O j , k ) + p j , k m ( O j , k ) \pi_t(O_{j,k}) := \pi(O_{j,k}) + p_{j,k}^{m(O_{j,k})} πt(Oj,k):=π(Oj,k)+pj,km(Oj,k)。文献中存在多种FJSP目标函数,本文在多种目标函数上测试方法,包括完工时间、总开始延迟、结束延迟。形式上,完工时间目标可表示为 max O j , k π t ( O j , k ) \max_{O_{j,k}} \pi_t(O_{j,k}) Oj,kmaxπt(Oj,k)对于基于延迟的目标,每道工序 O j , k O_{j,k} Oj,k可关联一个发布时间 s j , k s_{j,k} sj,k(约束为 π ( O j , k ) ≥ s j , k \pi(O_{j,k}) \geq s_{j,k} π(Oj,k)≥sj,k,即工序仅可在发布时间后开始加工)和目标结束时间 t j , k t_{j,k} tj,k,同一作业内工序需保持先后顺序,即对任意作业 j j j及工序 k 1 < k 2 k_1 < k_2 k1<k2,假设 s j , k 1 ≤ s j , k 2 s_{j,k_1} \leq s_{j,k_2} sj,k1≤sj,k2且 t j , k 1 ≤ t j , k 2 t_{j,k_1} \leq t_{j,k_2} tj,k1≤tj,k2。
总开始延迟目标为 ∑ O j , k ( π ( O j , k ) − s j , k ) \sum_{O_{j,k}} (\pi(O_{j,k}) - s_{j,k}) ∑Oj,k(π(Oj,k)−sj,k),总结束延迟目标为 ∑ O j , k max ( π t ( O j , k ) − t j , k , 0 ) \sum_{O_{j,k}} \max(\pi_t(O_{j,k}) - t_{j,k}, 0) ∑Oj,kmax(πt(Oj,k)−tj,k,0)。
附录A.1提供了详细的符号列表。
- 面向长周期FJSP的RHO
RHO 用三个关键参数控制滚动过程:
- H H H:规划窗口大小,即每次子问题包含多少道未执行工序;
- S S S:执行步长,即每次求解后真正提交多少道工序;
- T T T:每个子问题的求解时间限制。
第 r r r 次 RHO 迭代中,当前子问题 P r P_r Pr 包含窗口内的 H H H 道未执行工序,记为 O p l a n , r \mathcal{O}_{plan,r} Oplan,r。求解器在时间限制 T T T 内求解该子问题,得到:
Π r = ( m r , π r ) \Pi_r = (m_r, \pi_r) Πr=(mr,πr)
随后,系统只执行其中前 S S S 道工序,剩余 H − S H-S H−S 道工序会进入后续窗口继续被规划。因此,相邻两个窗口之间存在重叠部分:
O o v e r l a p , r = O p l a n , r ∩ O p l a n , r − 1 \mathcal{O}_{overlap,r} = \mathcal{O}_{plan,r} \cap \mathcal{O}_{plan,r-1} Ooverlap,r=Oplan,r∩Oplan,r−1
这部分重叠工序正是 L-RHO 要利用的对象。
详细算法见附录A.2。RHO也适用于可见度有限的在线场景,可求解早期工序,将其余工序推迟到下一次迭代的未来批次中处理。
学习引导式滚动时域优化(L-RHO)
标准 RHO 每次都会重新求解当前窗口中的所有工序,即使一部分重叠工序在上一轮已经得到过合理分配。论文发现,在连续 RHO 迭代中,很多重叠工序的机器分配保持不变。
可以把这些稳定工序定义为:
O f i x , r ∗ = { O ∈ O o v e r l a p , r ∣ m r ( O ) = m r − 1 ( O ) } \mathcal{O}_{fix,r}^* = \{O \in \mathcal{O}_{overlap,r} \mid m_r(O)=m_{r-1}(O)\} Ofix,r∗={O∈Ooverlap,r∣mr(O)=mr−1(O)}
如果我们事先知道 O f i x , r ∗ \mathcal{O}_{fix,r}^* Ofix,r∗,就可以在当前子问题中直接固定这些工序的机器分配,构造一个受限子问题 P ^ r \hat{P}_r P^r。这个子问题变量更少,搜索空间更小,求解速度通常更快。
真正的问题是:推理时并不知道哪些工序属于 O f i x , r ∗ \mathcal{O}_{fix,r}^* Ofix,r∗。L-RHO 用神经网络来预测它。
L-RHO流程
我们设计的L-RHO流程(如图1所示)如下:首先,通过前瞻预言器求解无约束子问题 P r P_r Pr,收集训练数据并识别 O f i x , r ∗ \mathcal{O}_{fix,r}^* Ofix,r∗(即重叠工序中在 m r m_r mr和 m r − 1 m_{r-1} mr−1中保持相同分配的工序集合)。随后,用收集到的标签训练神经网络 f θ f_\theta fθ。推理时, f θ f_\theta fθ预测 O f i x , r \mathcal{O}_{fix,r} Ofix,r的一个子集,基于该子集构建基于分配的受限子问题 P ^ r \hat{P}_r P^r。通过用更易求解的 P ^ r \hat{P}_r P^r替代昂贵的 P r P_r Pr,可大幅加快推理阶段的优化过程。
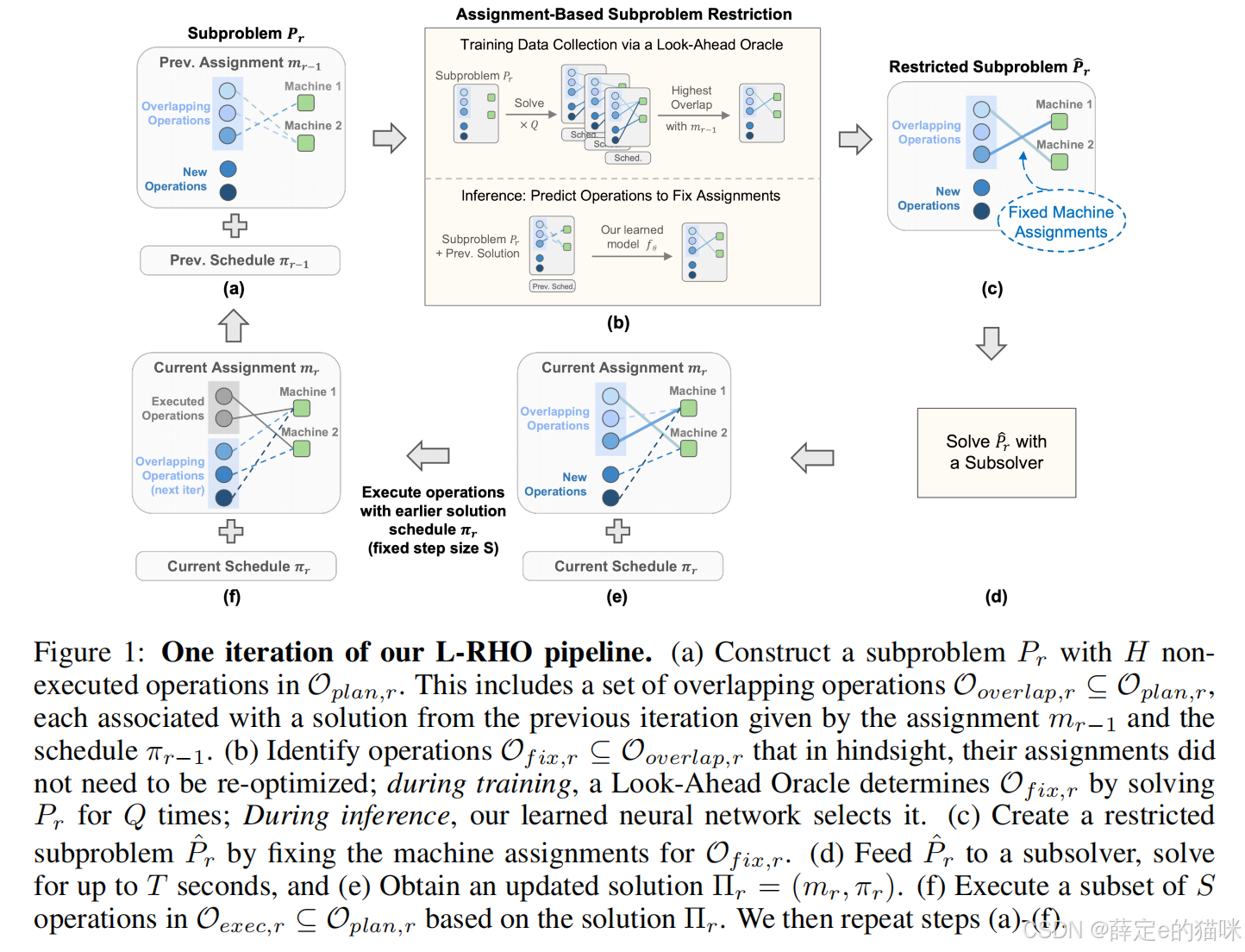
步骤(a):构建当前RHO子问题 P r P_r Pr
- 输入:
- 是当前迭代的未执行工序集合 O p l a n , r \mathcal{O}_{plan,r} Oplan,r
- 上一次迭代的解:机器分配 m r − 1 m_{r-1} mr−1和调度方案 π r − 1 \pi_{r-1} πr−1
- 其中重叠工序 O o v e r l a p , r ∈ O p l a n , r \mathcal{O}_{overlap,r} \in \mathcal{O}_{plan,r} Ooverlap,r∈Oplan,r:这些工序是当前子问题和上一次子问题共享的部分,它们的机器分配在上一轮迭代中已经确定。 — 这一步的本质是八长周期FJSP切分成短周期的子问题,准备进图下一轮优化。
步骤(b):识别“无需重新优化”的固定工序 O f i x , r \mathcal{O}_{fix,r} Ofix,r,这是区别于传统方法的核心创新点,分为“训练阶段”和“推理阶段”两种模式:
- 训练阶段:Look-Ahead Oracle收集数据 ---- 把当前子问题 P r P_r Pr求解Q次(时间限制内),得到Q组不同的机器分配方案。 ----- 统计每道重叠工序,在Q次求解中保持与上一轮分配一致的次数(这道工序在不同的优化结果里,越倾向于保持和上一轮一样的分配),选择“一致性最高”的分配方案,对应的工序集合就是 O f i x , r \mathcal{O}_{fix,r} Ofix,r。 ---- 生成训练标签,告诉模型“哪些工序的分配是稳定的,不需要重新优化的”(模型的目标就是预测这些工序,让它们不用再参与优化,直接沿用分配)
- 推理阶段:学习模型预测固定工序 ----- 用训练好的神经网络 f θ f_θ fθ,输入当前子问题 + 上一轮的解,直接预测 O o v e r l a p , r \mathcal{O}_{overlap,r} Ooverlap,r中哪些工序可以固定分配。 ----- 替换耗时的“前瞻求解”,用模型快速识别稳定分配,未后续子问题减负。
步骤(c):构建受限子问题 P ^ r \hat{P}_r P^r,基于步骤(b)得到的 O f i x , r \mathcal{O}_{fix,r} Ofix,r,强制固定这些工序的机器分配,生成一个新的,约束更强的子问题 P ^ r \hat{P}_r P^r。
- 子问题规模大幅缩小,需要优化的变量减少了,求解复杂度显著降低。
- 保留关键优化空间,只有那些分配不稳定的工序才会被重新优化,避免了不必要的冗余计算。
步骤(d):求解受限子问题 P ^ r \hat{P}_r P^r ,把受限子问题 P ^ r \hat{P}_r P^r交给求解器(比如CP-SAT),在时间限制T秒内求解。
- L-RHO求解的是受限的 P ^ r \hat{P}_r P^r,变量少,求解快,且接质量几乎不受影响。
步骤(e):得到当前迭代的完整解 Π r = ( m r , π r ) \Pi_{r} = (m_{r}, \pi_{r}) Πr=(mr,πr)
- 求解器输出当前迭代的机器分配 m r m_r mr和调度方案 π r \pi_r πr. (虽然子问题被固定了部分分配,但最终得到的解是完整的,包含所有工序的分配和时间安排)
步骤(f):执行部分工序,推进RHO迭代,按照调度方案 π r \pi_r πr,选择前S道工序(步长S≤H)实际执行,剩余H - S道工序推迟到下一次迭代重新规划。
- 已执行的工序被标记为 “完成”,不会再进入后续子问题(剩余工序会成为下一次迭代的“未执行工序”,流程回到(a),开启下一次迭代)。
Oracle 如何生成训练标签
在数据收集阶段,论文把无约束子问题 P r P_r Pr 在时间限制下求解 Q Q Q 次,得到:
{ Π r q = ( m r q , π r q ) } q = 1 Q \{\Pi_r^q=(m_r^q,\pi_r^q)\}_{q=1}^Q {Πrq=(mrq,πrq)}q=1Q
对每个重叠工序 O ∈ O o v e r l a p , r O \in \mathcal{O}_{overlap,r} O∈Ooverlap,r,检查它在第 q q q 次求解中的机器分配是否与上一轮一致:
y O q = 1 m r q ( O ) = m r − 1 ( O ) y_O^q = \mathbb{1}_{m_r^q(O)=m_{r-1}(O)} yOq=1mrq(O)=mr−1(O)
然后选择固定工序最多的一次求解结果作为标签来源:
q ∗ = arg max q ∑ O ∈ O o v e r l a p , r y O q q^* = \arg\max_q \sum_{O \in \mathcal{O}_{overlap,r}} y_O^q q∗=argqmaxO∈Ooverlap,r∑yOq
最终标签为:
y O ∗ = y O q ∗ y_O^* = y_O^{q^*} yO∗=yOq∗
Oracle 在训练阶段用更高计算成本判断“哪些分配稳定且值得固定”,模型则学习这种判断,在测试阶段用低成本预测替代 Oracle。
网络输入与结构
模型输入是当前 RHO 状态 s r s_r sr,由当前子问题 P r P_r Pr 和上一轮解 Π r − 1 \Pi_{r-1} Πr−1 组成。论文把输入拆成三类实体:

| 输入类型 | 含义 | 作用 |
|---|---|---|
| Overlapping Operations(重叠工序) | 当前子问题中,和上一轮子问题共享的工序(Ooverlap,r) | 核心预测对象,是我们要判断 “是否固定” 的目标 |
| New Operations(新工序) | 当前子问题中,上一轮没有的新工序(Onew,r) | 提供全局上下文:新工序的加入会影响整体调度压力,进而影响重叠工序的稳定性 |
| Machines(机器集合) | 所有可用机器的状态信息 | 提供机器负载、可用性等全局信息,帮助判断工序分配的合理性 |
网络结构并不复杂,主要包括:
- 对工序和机器分别使用 MLP 做输入嵌入;
- 对每个重叠工序,拼接该工序特征、上一轮分配机器的特征、全局池化特征;
- 通过最终 MLP 输出该工序被固定的概率。
论文提到,更复杂的注意力结构并没有带来明显收益。这一点值得注意:L-RHO 的优势不完全来自复杂模型,而来自“学习固定变量 + 约束求解器”的组合方式。
损失函数
模型使用加权二分类交叉熵:
l ( f θ ( s r ; O ) , y O ) = − [ w p o s y O log f θ ( s r ; O ) + ( 1 − y O ) log ( 1 − f θ ( s r ; O ) ) ] l(f_\theta(s_r;O), y_O) = -[w_{pos} y_O \log f_\theta(s_r;O) + (1 - y_O) \log(1 - f_\theta(s_r;O))] l(fθ(sr;O),yO)=−[wposyOlogfθ(sr;O)+(1−yO)log(1−fθ(sr;O))]
其中 w p o s w_{pos} wpos 用来平衡正负样本。这里最关键的是 FP/FN 的含义:
- 假阳性(FP):模型把不该固定的工序固定了。这样会减少变量、加快求解,但可能损害解质量。
- 假阴性(FN):模型没有固定本来可以固定的工序。这样通常不会直接破坏解质量,但会保留更多变量,降低加速效果。
因此,L-RHO 不是简单地“固定越多越好”。它需要在求解速度和目标质量之间找到平衡。
推理时如何构造受限子问题
推理时,对每个重叠工序 O O O,模型输出概率 f θ ( s r ; O ) f_\theta(s_r;O) fθ(sr;O)。若概率超过阈值,则固定该工序:
y ~ O = 1 f θ ( s r ; O ) ≥ 0.5 \tilde{y}_O = \mathbb{1}_{f_\theta(s_r;O) \geq 0.5} y~O=1fθ(sr;O)≥0.5
得到固定集合:
O f i x , r = { O ∈ O o v e r l a p , r ∣ y ~ O = 1 } \mathcal{O}_{fix,r} = \{O \in \mathcal{O}_{overlap,r} \mid \tilde{y}_O = 1\} Ofix,r={O∈Ooverlap,r∣y~O=1}
随后构造受限子问题 P ^ r \hat{P}_r P^r,其中这些工序的机器分配被强制设为上一轮结果 m r − 1 ( O ) m_{r-1}(O) mr−1(O)。其他工序仍由求解器重新优化。
这个设计保留了 RHO 的滚动结构,也保留了 CP-SAT 对局部子问题的优化能力,同时减少了每次求解的自由变量数量。
实验
论文使用大规模合成 FJSP 实例,工序规模约为 600 到 2000,明显大于许多既有学习式 FJSP 方法常用的小规模实例。子问题由 OR-Tools CP-SAT 求解。
对比方法包括:
- 无分解传统求解器:CP-SAT、遗传算法(GA);
- 无分解学习式求解器:DRL-20K、DRL-Echeverria、DRL-Ho;
- 传统分解方法:基于时间或机器的 ARD-LNS;
- 学习引导式分解近似上界:Oracle-LNS;
- RHO 变体:Default RHO、Warm-Start RHO、Random、First。
论文主要使用两个指标:
OI% = o b j 0 − o b j o b j 0 × 100 % , TI% = t 0 − t t 0 × 100 % \text{OI\%}=\frac{obj_0-obj}{obj_0}\times100\%, \quad \text{TI\%}=\frac{t_0-t}{t_0}\times100\% OI%=obj0obj0−obj×100%,TI%=t0t0−t×100%
其中 o b j 0 obj_0 obj0 和 t 0 t_0 t0 是 Default RHO 的目标值和求解时间。OI% 越高表示目标值改进越明显,TI% 越高表示时间节省越明显。
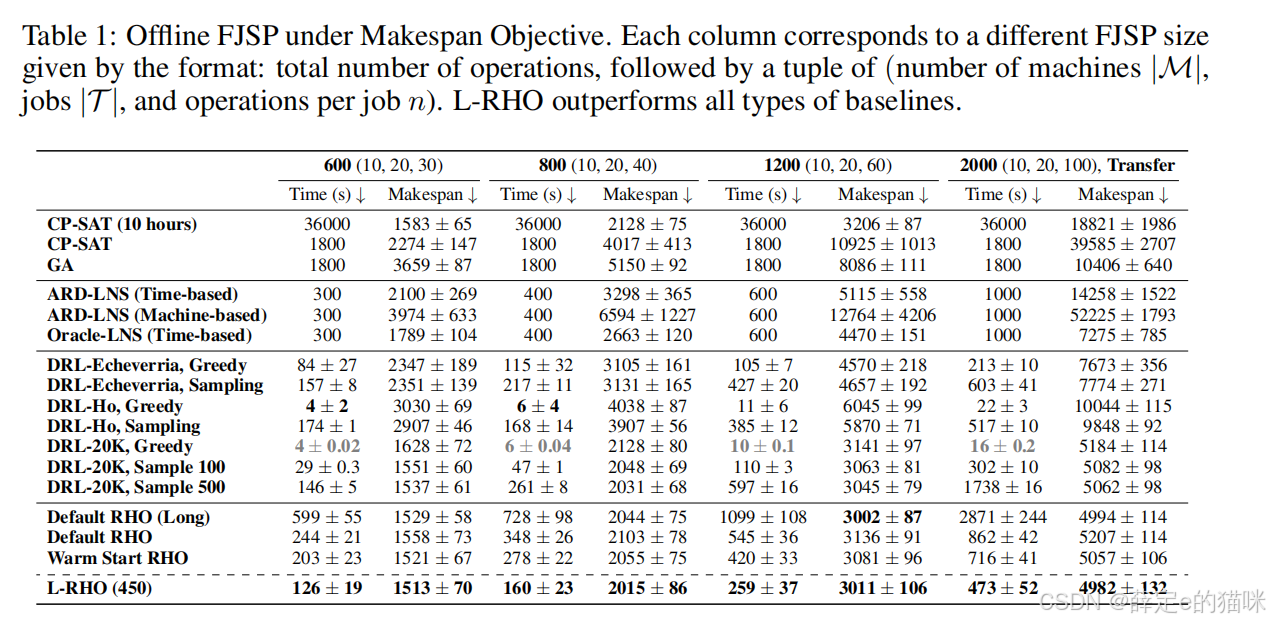
完工时间目标下的标准离线FJSP
在标准离线 FJSP 中,L-RHO 相比传统求解器、DRL 方法和其他分解方法都更有优势。主要结论如下:
- L-RHO 在域内测试和更大规模零样本迁移中都取得了更好的目标值。
- DRL Greedy 虽然速度快,但目标值不如 Default RHO。
- DRL 采样可以提升质量,但计算时间显著增加,且依赖 GPU 和批解码。
- ARD-LNS 和 Oracle-LNS 都不如 Default RHO,说明对长周期 FJSP 来说,沿时间滚动的 RHO 结构比一般 LNS 局部改进更贴合问题。
- L-RHO 相当于在 RHO 的时间分解基础上进一步减少冗余变量,因此比单纯的 RHO 更快,也比一般分解方法更稳定。
这里我认为最有价值的结论是:论文不是简单证明“学习方法比传统方法好”,而是证明了学习应该嵌入到合适的问题分解结构中。如果分解方式本身不贴合长周期时间依赖,学习式子问题选择也很难发挥效果。
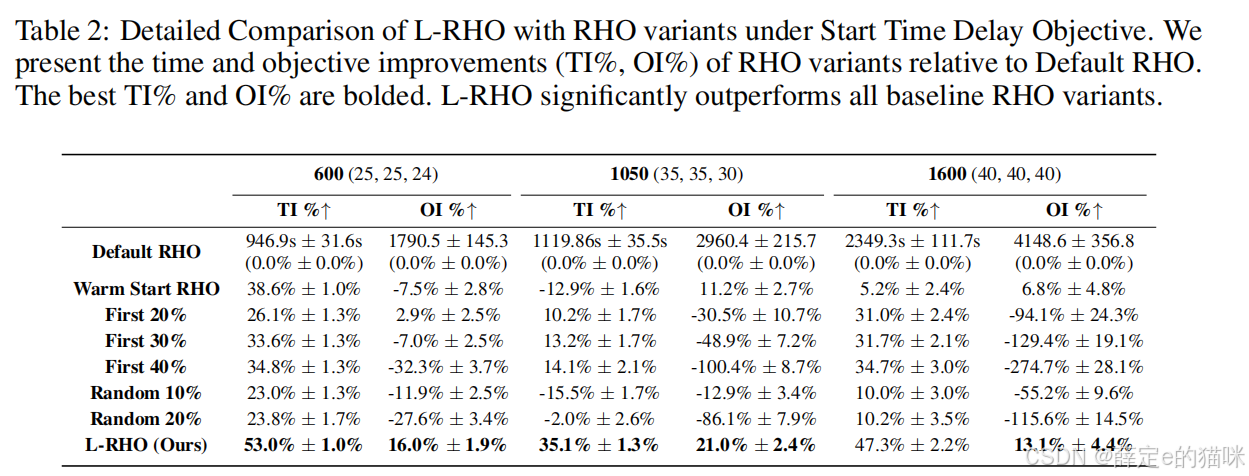
开始延迟目标
在开始延迟目标下,L-RHO 仍然优于各类 RHO 变体。论文报告,L-RHO 相比 Default RHO 可实现约 35%-53% 的加速,同时目标值提升约 13%-21%。
这说明 L-RHO 并不只适用于 makespan 目标。只要相邻窗口中存在可学习的稳定分配模式,固定重叠变量的思想就有迁移价值。
Warm-Start RHO 的效果不明显,说明只是把上一轮解作为提示交给 CP-SAT,并不足以可靠减少搜索空间。L-RHO 的关键在于显式固定一部分决策变量,这比普通热启动更强。
Random 与 First 为什么不够
论文还比较了两种简单启发式:
- Random:随机选择一部分重叠工序固定;
- First:按工序在 RHO 序列中的先后顺序,优先固定靠前的一部分工序。
它们有时能缩短求解时间,但容易牺牲目标值。原因是固定变量本身是一把双刃剑:固定得对,可以减少冗余;固定得错,会限制求解器修正错误分配。
First 通常比 Random 更好,因为越靠前的重叠工序越接近已执行区域,分配更可能稳定。但在观测噪声、机器故障等场景下,这种顺序规律会被削弱,First 的优势也会下降。
L-RHO 的优势在于它不是只依赖位置规则,而是利用当前子问题、新工序、机器状态和上一轮解来判断固定对象。
拥塞、噪声和机器故障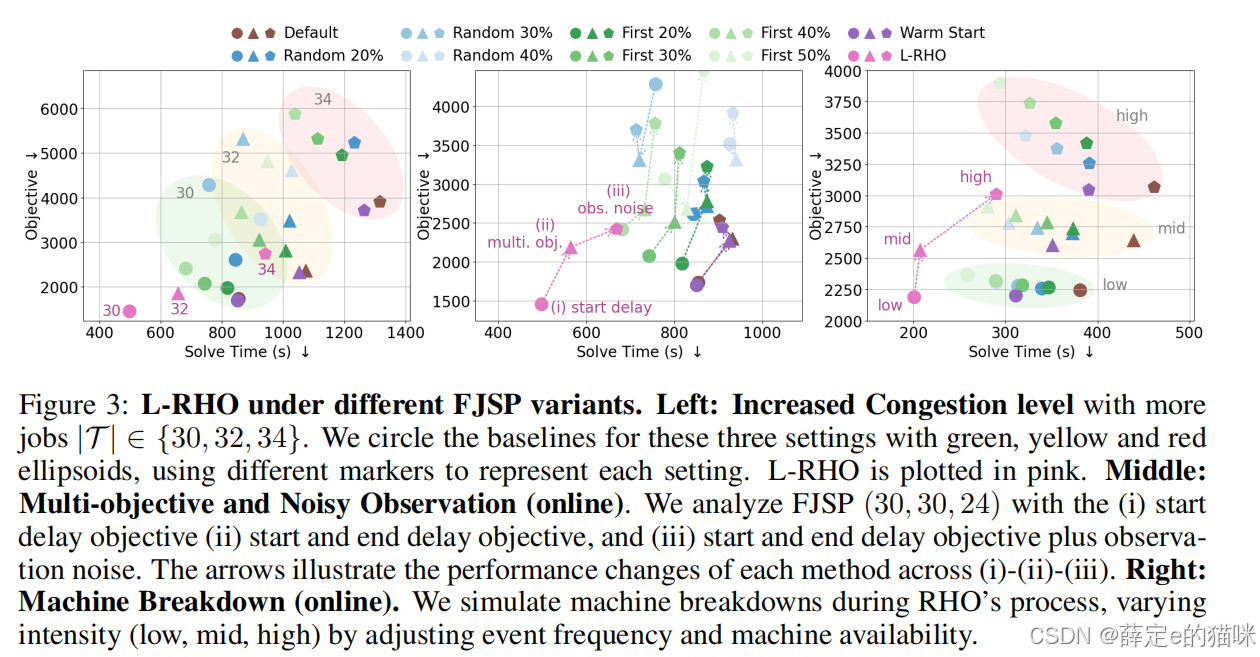
论文进一步测试了更贴近真实场景的变体:
- 更高拥塞:增加作业数,提高作业-机器比;
- 多目标延迟:同时考虑开始延迟和结束延迟;
- 观测噪声:部分工序时长只能看到带噪声估计;
- 机器故障:机器出现故障或恢复时触发重调度。
结果显示,L-RHO 在这些设置下仍能保持时间和目标值改进。例如在观测噪声下,相比 Default RHO 仍有约 25% 的时间改进和 4% 的目标值改进;在机器故障场景中,不同故障强度下也能保持显著时间改进。
这部分实验的意义在于:L-RHO 不只是静态 benchmark 上的加速技巧,而是更接近在线调度中的“持续重优化”需求。对实际系统来说,这比单次离线求解更重要。
理论概率分析
本节通过理论概率分析,确定机器学习能为RHO带来优势的条件。直观而言,可被固定的工序( O f i x , r ∗ \mathcal{O}_{fix,r}^* Ofix,r∗)越不规律,L-RHO的潜在优势越大。同时,L-RHO必须平衡假阳性(FP)和假阴性(FN)错误:固定不应被固定的工序(FP)会损害目标值,但有助于缩短求解时间;未能固定应被固定的工序(FN)会损害求解时间,也会间接损害目标值(在固定时间限制下)。因此,理想的L-RHO方法需平衡这两种错误(见图4)。
论文最后给出一个概率分析,用来解释什么时候学习方法会比 Random/First 更有优势。
核心变量是:
- O f i x ∗ \mathcal{O}_{fix}^* Ofix∗:Oracle 认为应该固定的工序集合;
- O f i x \mathcal{O}_{fix} Ofix:某个方法实际固定的工序集合;
- O f p \mathcal{O}_{fp} Ofp:假阳性,即错误固定的工序;
- O f n \mathcal{O}_{fn} Ofn:假阴性,即本该固定但没有固定的工序。
对 L-RHO 而言,假阳性率和假阴性率记为 ( α , β ) (\alpha,\beta) (α,β):
E [ n f n L − R H O ] = β E [ n f i x ∗ ] \mathbb{E}[n_{fn}^{L-RHO}] = \beta \mathbb{E}[n_{fix}^*] E[nfnL−RHO]=βE[nfix∗]
E [ n f p L − R H O ] = α ( W − E [ n f i x ∗ ] ) \mathbb{E}[n_{fp}^{L-RHO}] = \alpha(W-\mathbb{E}[n_{fix}^*]) E[nfpL−RHO]=α(W−E[nfix∗])
其中 W = H − S W=H-S W=H−S 是重叠窗口大小。
论文还提出一个线性衰减假设:在 RHO 序列中越靠后的工序,被固定的概率越低:
p f i x ∗ ( i ) = b − m ⋅ i W p_{fix}^*(i)=b-m\cdot\frac{i}{W} pfix∗(i)=b−m⋅Wi
这个假设解释了为什么 First 往往比 Random 更强:如果靠前工序确实更稳定,那么优先固定前面的工序会减少错误固定。
但当环境变复杂时,例如观测噪声或机器故障导致稳定性不再主要由顺序决定,First 的优势会下降。此时,如果模型能利用更多上下文信息降低 FP 和 FN,就会明显优于启发式方法。
我的理解是,这个理论分析的价值不在于精确预测每个实例的表现,而在于给出了一个部署判断标准:如果训练出的 L-RHO 模型在验证集上的 FP/FN 明显低于 Random/First,那么它更可能在真实推理中带来收益。
结论
L-RHO 的贡献可以概括为三点:
- 它把机器学习用于 RHO 的冗余识别,而不是直接替代求解器。
- 它通过固定稳定重叠工序,显式缩小子问题搜索空间。
- 它在多种 FJSP 目标和动态场景下都表现稳定。
这篇论文对我最有启发的地方是:学习模块没有试图“端到端求解调度问题”,而是嵌入到传统优化流程中,承担一个边界清晰的判断任务。模型只需要回答“这个变量该不该固定”,剩下的约束满足和局部优化仍交给 CP-SAT。
这种设计在工程上也更稳健。模型预测错了不一定导致系统崩溃,只是影响速度或目标值;而求解器仍然保证剩余子问题满足约束。相比完全依赖神经网络输出调度方案,这种混合式框架更容易落地。
它的局限也很明确:如果某个长周期 COP 中稳定变量模式不明显,或者模型的 FP/FN 无法低于简单启发式,那么 L-RHO 的收益就会下降。论文也指出,直接迁移到其他长周期 COP 未必自动达到最优效果,未来还需要结合具体问题设计特征、约束形式和训练分布。
openreview 审稿人评价
来源:OpenReview 页面 https://openreview.net/forum?id=Aly68Y5Es0。该论文最终被 ICLR 2025 接收为 Poster。论坛中包含 4 份官方审稿、Area Chair 的 Meta Review,以及 rebuttal 后的若干追评。
总体结论
审稿整体是偏正面的:评审认可 L-RHO 将学习方法引入滚动时域优化,用来判断相邻 RHO 子问题中哪些重叠工序的机器分配可以固定,从而缩小子问题规模。这一点被认为有原创性,也切中了长周期 FJSP 中重复优化的效率瓶颈。
最终分数大致为:
| 审稿人 | 评分 | 主要态度 |
|---|---|---|
| Reviewer S42P | 6 | 正面,但认为只在 FJSP 上验证限制了论文范围 |
| Reviewer qP8G | 5 | 认可思路和实验,但认为 novelty 有限、主文组织不够清楚 |
| Reviewer ppet | 8 | 强正面,认可问题重要性、方向新颖、理论和实验完整 |
| Reviewer PSPu | 8 | 初始质疑较多,rebuttal 后因补充 SOTA 比较与实验而提高分数 |
Area Chair 的 Meta Review 总结为:方法能减少 RHO 子问题规模和计算时间,实验结果充分,rebuttal 期间作者补充了有力实验并较好回应了问题,因此建议接收。
审稿人认可的贡献
- 问题重要且实际。 审稿人认为长周期生产计划、柔性作业车间调度、在线重优化等问题有明确工业价值,RHO 是合理且常用的时间分解框架。
- 把学习用于 RHO 的变量固定有新意。 多位审稿人认可“学习判断哪些重叠变量无需重新优化”这一切入点,认为它区别于传统启发式或纯求解器方法。
- 能处理更长 horizon。 S42P 特别肯定论文能求解比已有学习型调度方法更长的 FJSP 实例,PSPu 也注意到测试规模超过 600 个 operation,明显大于许多旧 benchmark。
- 实验覆盖面较宽。 审稿人认可论文测试了不同目标、分布、拥塞、观测噪声、机器故障和在线近似场景,并给出了较深入的分析。
- rebuttal 后说服力增强。 作者补充了更多基线、真实 benchmark、长时间 CP-SAT/RHO 对比、分类器指标和架构修正说明,最终使部分审稿人提高评分。
主要质疑与不足
- 只验证 FJSP,外推范围仍有限。 S42P 的核心担忧是:L-RHO 的思想看起来很通用,但论文只在 FJSP 及其变体上验证。若能再展示另一个长周期组合优化问题,例如其他调度或路径规划问题,贡献会更强。
- 学习模块的 novelty 有争议。 qP8G 认为学习过程更像对 RHO 的间接辅助,而不是直接参与求解,因此新颖性有限。PSPu 也质疑 L-RHO 相比 Default RHO 的结构差异主要在自定义模型上。
- 主文对学习框架解释不够集中。 qP8G 指出,让 RHO “learnable”的关键细节很多放在补充材料中,导致主文读者不易快速理解训练标签、oracle 和模型输入。
- 理论分析可读性不足。 S42P 和 PSPu 都提到理论部分的符号、命题和直觉连接不够清楚,部分变量定义和解释依赖附录,主文自洽性不足。
- 基线与公平比较需要加强。 PSPu 要求加入更多 FJSP/DRL 基线、传统 benchmark,以及解释 CP-SAT 和 GA 在固定 1800 秒下比较的意义。ppet 也追问 Default RHO 如果给足时间是否会优于 L-RHO。
- 模型指标和可解释性不足。 ppet 希望看到分类器的 accuracy、precision、recall,也追问哪些特征对判断变量固定最重要,以及 attention map 能否提供解释。
- 符号和表述细节有问题。 审稿人指出
m同时表示机器和 assignment,\Tau在不同章节含义不一致,部分图表应放入主文,若干公式和参数如q*、W_pos、时间预算T需要更直观解释。
Rebuttal 后的变化
rebuttal 是这篇论文被接收的重要转折点。作者补充了以下内容:
- 增加更多 SOTA 和学习型 FJSP baseline,对比后 PSPu 认为性能达到了 SOTA,并将分数提高到 8。
- 增加真实 benchmark 或更贴近真实场景的测试,ppet 认为这增强了实际泛化性的说服力,因此提高评分。
- 解释 Default RHO 与 L-RHO 的时间预算差异:在有限时间下,缩小子问题不仅能加速,也可能使求解器在同样预算内找到更优解。
- 补充分类器指标、oracle 标签直觉、
q*与W_pos的解释,并承认 attention 模块实现中存在需要澄清或修正的地方。 - 对“纯在线”场景作了边界说明:论文当前覆盖的是向在线设置迈进的若干动态情形,但完全逐个 operation 到达的在线问题还需要额外适配。
代码解读
https://github.com/mit-wu-lab/l-rho
将图神经网络的全局模式识别能力与约束规划求解器的局部最优性保证相结合。
核心思想:当 RHO 向前滑动其求解窗口时,许多重叠任务(已在前一个窗口中被调度)可以被固定——直接顺延而无需重新优化——从而大幅降低每个子问题的复杂度。问题在于:应该固定哪些任务?
L-RHO 利用图神经网络来回答这个问题,该网络基于从前瞻神谕收集的数据进行训练:
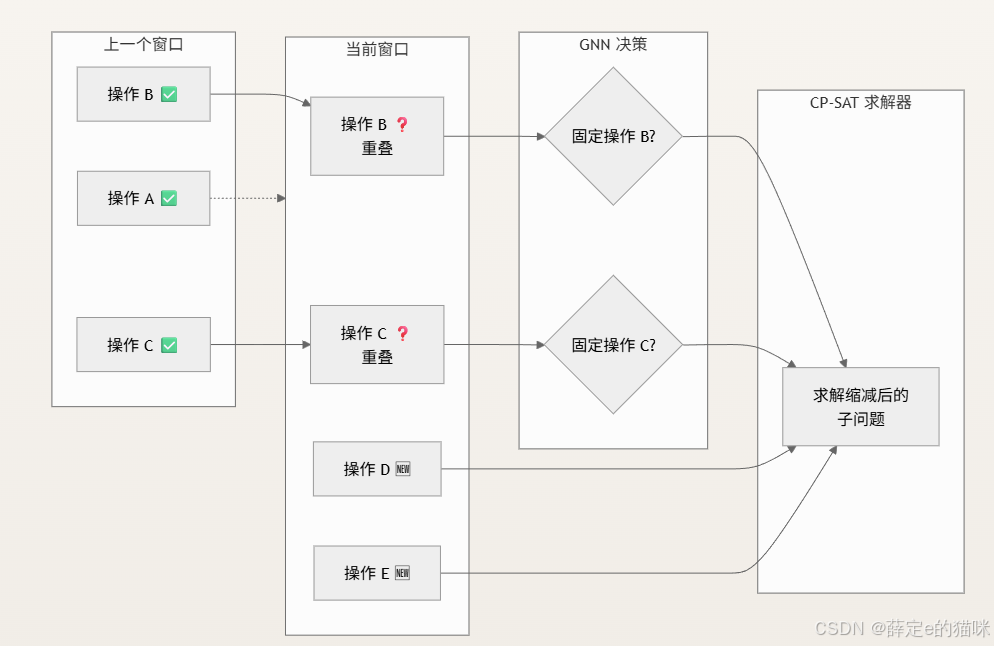
在训练期间,穷举求解重叠区域,以确定哪些固定决策能产生最佳的目标值。这会生成二值标签:固定(1)或重新优化(0)。GNN 学习从调度状态的二分图表示中预测这些标签。
在推理期间,GNN 预测重叠任务的固定决策,并且仅由 CP-SAT 重新求解未固定的任务——这缩减了子问题的规模,加快了求解速度,同时不会牺牲解的质量。
参考:flexible_jss_main.py, flexible_jss_data.py
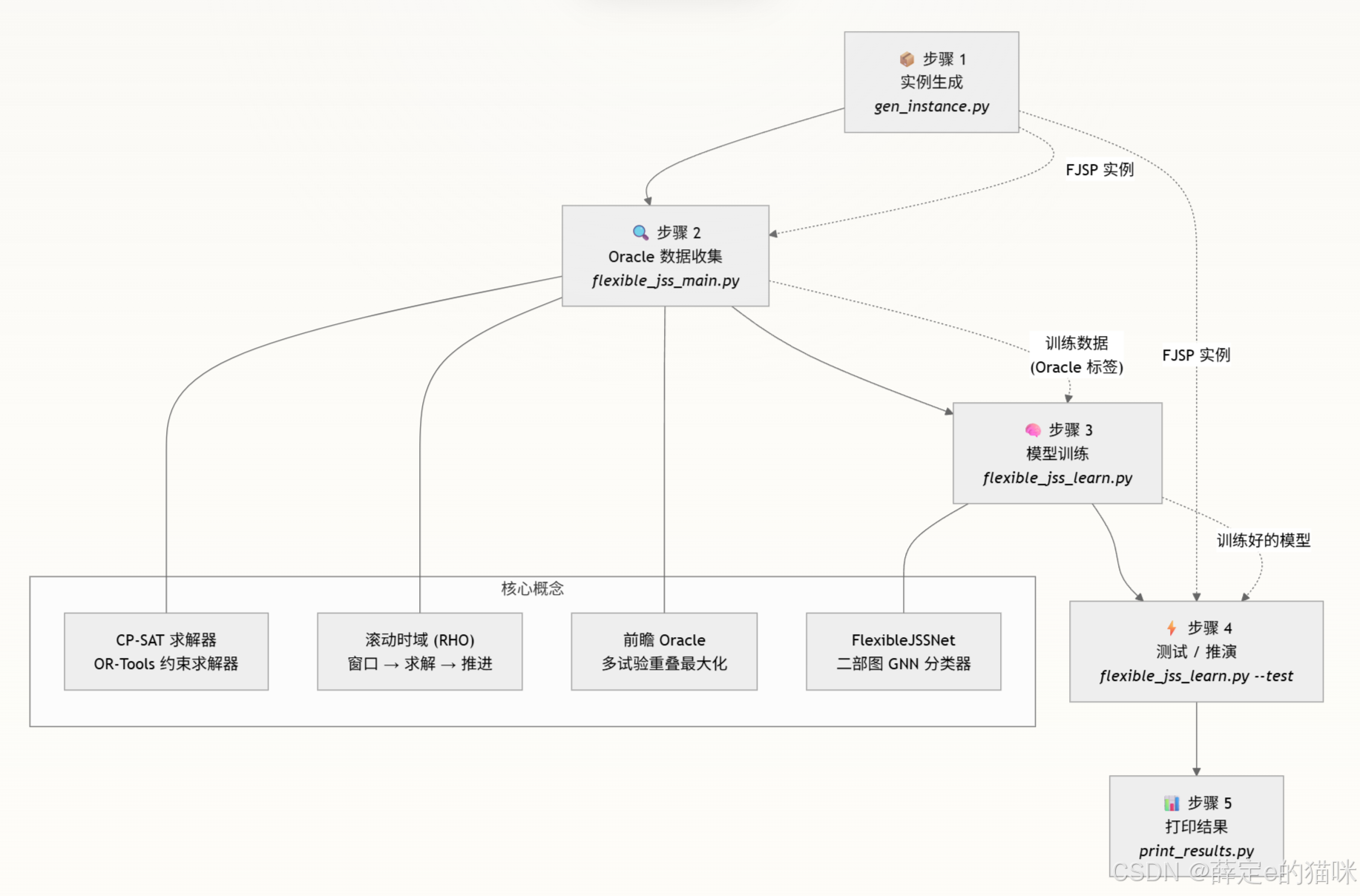
Oracle 训练数据(步骤 2)由图结构输入与二值标签组成,这些标签指明了在重叠窗口中哪些“工序-机器”分配应被“固定”。GNN 模型(步骤 3)用于学习预测这些标签。在测试阶段(步骤 4),训练好的模型取代开销高昂的 Oracle,实时对分配进行分类,从而加速滚动时域求解器。
项目结构
l-rho/
├── makespan/ │ ├── gen_instance.py # 阶段 1:FJSP 实例生成
│ ├── flexible_jss_main.py # 阶段 2:RHO 循环 + 数据收集
│ ├── flexible_jss_learn.py # 阶段 3 & 4:GNN 训练 + 推理展开测试
│ ├── flexible_jss_data.py # 图数据构建(最大完工时间)
│ ├── flexible_jss_data_common.py # 共享数据集类与推理展开预测
│ ├── flexible_jss_data_machine_breakdown.py # 图数据(机器故障变体)
│ ├── flexible_jss_main_common.py # 共享求解器 (CP-SAT) + 验证
│ ├── flexible_jss_main_machine_breakdown.py # 包含机器故障事件的 RHO 循环
│ ├── flexible_jss_instance.py # 实例数据结构与 SD2 生成器
│ ├── flexible_jss_util.py # IO、归一化、二分图 GNN 层
│ ├── flexible_jss_test_rollout_configs.py # 测试配置工厂
│ ├── gen_analysis.py # 事后分析工具
│ ├── print_results.py # 汇总与打印测试统计信息
│ └── scripts/j20-m10-t30/ # 可直接运行的 Shell 脚本
│ ├── makespan/ # 标准最大完工时间流水线
│ └── makespan+breakdown/ # 机器故障流水线
│
├── delay/ # 延迟最小化
│ ├── flexible_jss_main.py # 阶段 2:RHO 循环(延迟目标)
│ ├── flexible_jss_learn.py # 阶段 3 & 4:GNN 训练 + 推理展开测试
│ ├── flexible_jss_data_start.py # 图数据(仅开始延迟)
│ ├── flexible_jss_data_start_end.py # 图数据(开始 + 结束延迟)
│ ├── flexible_jss_data_start_end_perturb.py # 图数据(+ 观测噪声)
│ ├── flexible_jss_instance.py # 实例数据结构(延迟配置)
│ ├── flexible_jss_parameter_search.py # RHO 超参数网格搜索
│ ├── find_best_rho_param.py # 分析参数搜索结果
│ ├── print_results.py # 汇总与打印测试统计信息
│ └── scripts/j25-m25-t24/ # 可直接运行的 Shell 脚本
│ ├── start_delay/ # 开始延迟流水线(含参数搜索)
│ ├── start+end_delay/ # 开始 + 结束延迟流水线
│ └── start+end_delay+obs_noise/ # 包含扰动观测的流水线
│
└── requirements.txt # Python 依赖项
快速开始:
conda create --name lrho --file requirements.txt
conda activate lrho
使用的库:
| 类别 | 技术 | 版本 | 作用 |
|---|---|---|---|
| 语言 | Python | 3.9.16 | 核心运行时 |
| 求解器 | OR-Tools CP-SAT | 9.9.3963 | 用于 FJSP 子问题的约束规划 |
| 深度学习 | PyTorch | 2.0.0+cu117 | GNN 模型定义与训练 |
| 图学习 | PyTorch Geometric | 2.3.1+cu117 | 二分图数据处理与批处理 |
| 实验追踪 | TensorBoard | 2.12.3 | 训练损失与评估日志记录 |
| 数值计算 | NumPy | 1.24.3 | 实例生成与数据处理 |
生成 FJSP 实例:
进入 makespan 目录,生成 600 个包含 20 个作业、10 台机器以及每个作业 30 个工序的 FJSP 实例。实例将保存在 {DATA_DIR}/instance/j{NUM_JOBS}-m{NUM_MACHINES}-t{NUM_OPS_PER_JOB}_mix 目录下。
cd makespan
# 设置生成参数
export INSTANCE_TYPE=standard
export NUM_JOBS=20
export NUM_MACHINES=10
export NUM_OPS_PER_JOB=30
export DATA_DIR=train_data_dir
export NUM_DATA=600
# 运行实例生成
python -u gen_instance.py \
--instance_type $INSTANCE_TYPE \
--n_j $NUM_JOBS \
--n_m $NUM_MACHINES \
--op_per_job $NUM_OPS_PER_JOB \
--data_dir $DATA_DIR \
--n_data $NUM_DATA
这将生成 600 个遵循 SD2 生成方案的随机 FJSP 实例,其加工时间从 [1, 99] 中均匀采样,并具备灵活的机器分配。前 450 个实例(索引 0–449)作为训练数据,索引 450–499 作为验证数据,索引 500–599 作为保留的测试数据。
收集训练数据(前瞻 Oracle):
Oracle 数据收集步骤会结合多试验前瞻 Oracle 运行滚动时域循环。对于每个窗口的重叠区域,Oracle 会多次求解子问题,并识别出在多次试验中保持稳定的“工序-机器”分配——这些将成为用于训练的二值“固定”标签。这是计算开销最大的步骤。
针对单个实例(DATA_IDX=0),运行:
export DATA_IDX=0
export TRAIN_DATA_DIR=train_data_dir/train_data/j20-m10-t30_mix-w80-s30-t60-st3
export JSS_DATA_DIR=train_data_dir/instance/j20-m10-t30_mix
export STATS_DIR=train_data_dir/stats/j20-m10-t30_mix-w80-s30-t60-st3
export N_CPUS=3
export NUM_ORACLE_TRIALS=3
export WINDOW=80 # RHO 子问题大小(工序数)
export STEP=30 # RHO 执行步长(工序数)
export TIME_LIMIT=60 # 每个子问题的求解器时间限制(秒)
export STOP_SEARCH_TIME=3 # 目标值停滞后的提前停止时间(秒)
python -u flexible_jss_main.py \
--train_data_dir $TRAIN_DATA_DIR \
--jss_data_dir $JSS_DATA_DIR \
--stats_dir $STATS_DIR \
--data_idx $DATA_IDX \
--time_limit $TIME_LIMIT \
--stop_search_time $STOP_SEARCH_TIME \
--oracle_time_limit $TIME_LIMIT \
--oracle_stop_search_time $STOP_SEARCH_TIME \
--n_cpus $N_CPUS \
--num_oracle_trials $NUM_ORACLE_TRIALS \
--window $WINDOW --step $STEP
目录命名约定 j20-m10-t30_mix-w80-s30-t60-st3 编码了完整的实验配置:问题规模加上所有四个 RHO 超参数(Window、Step、Time limit、Stop-search time)。你必须对从 0 到 500 的每个 DATA_IDX 重复此命令(项目提供了用于并行执行的 Slurm 脚本)。
RHO 循环由四个关键超参数控制,用于平衡子问题规模与解的质量。这些参数可按实验进行配置,并可通过 delay 模块中的网格搜索工具进行自动调优:
| 参数 | CLI 标志 | 描述 | 示例 |
|---|---|---|---|
| 窗口 | –window | 每个 RHO 子问题中的操作数 | 80 |
| 步长 | –step | 每次求解后提交(执行)的操作数 | 30 |
| 时间限制 | –time_limit | 每个子问题的 CP-SAT 求解器挂钟时间限制(秒) | 60 |
| 提前终止 | –stop_search_time | 如果在 N 秒内没有改进,则提前停止求解器 | 3 |
步长 / 窗口的比值控制着连续窗口之间的重叠率。较小的比值(例如 30/80 = 37.5%)意味着每个窗口中有更多的重叠任务,这会放大学习模块“固定/重新优化”决策带来的收益。
训练 GNN 模型:
一旦你收集了实例 0–499 的 Oracle 数据,就可以训练 FlexibleJSSNet 二部图神经网络。该模型将由工序节点、机器节点及其边构成的图作为输入,并为每个“工序-机器”分配输出一个二值预测,指示其是否应在下一个重叠窗口中被固定。
export TRAIN_DATA_DIR=train_data_dir/train_data/j20-m10-t30_mix-w80-s30-t60-st3
export JSS_DATA_DIR=train_data_dir/instance/j20-m10-t30_mix
export LOG_DIR=train_test_dir/train_log/j20-m10-t30_mix-w80-s30-t60-st3
export TEST_STATS_DIR=train_test_dir/test_stats/j20-m10-t30_mix-w80-s30-t60-st3
export MODEL_DIR=train_test_dir/model/j20-m10-t30_mix-w80-s30-t60-st3
export DATA_INDEX_START=0
export DATA_INDEX_END=450
export VAL_INDEX_START=450
export VAL_INDEX_END=470
export EPOCH=200
export MODEL_NAME=model_pw0.5
export POS_WEIGHT=0.5
export WINDOW=80
export STEP=30
export TIME_LIMIT=60
export STOP_SEARCH_TIME=3
python -u flexible_jss_learn.py \
--train_data_dir $TRAIN_DATA_DIR \
--jss_data_dir $JSS_DATA_DIR \
--log_dir $LOG_DIR \
--test_stats_dir $TEST_STATS_DIR \
--model_dir $MODEL_DIR \
--data_index_start $DATA_INDEX_START \
--data_index_end $DATA_INDEX_END \
--val_index_start $VAL_INDEX_START \
--val_index_end $VAL_INDEX_END \
--num_epochs $EPOCH \
--model_name $MODEL_NAME \
--window $WINDOW --step $STEP \
--time_limit $TIME_LIMIT \
--stop_search_time $STOP_SEARCH_TIME \
--pos_weight $POS_WEIGHT
POS_WEIGHT 参数控制加权二元交叉熵损失中的类别平衡——值为 0.5 意味着正样本(固定)标签的权重是负样本标签的一半,这反映了可固定分配通常占比较低的情况。训练进度会记录到指定的 LOG_DIR 的 TensorBoard 中。模型及其输入归一化统计数据将保存到 MODEL_DIR。
验证集大小:本示例仅使用 20 个验证实例(索引 450–469)。如果验证准确率波动较大,建议将范围扩大到索引 450–499,以便在测试评估前进行更稳定的基于轮次的模型选择。
测试(推演评估):
训练完成后,在保留的测试实例上运行完整的 L-RHO 流水线以评估模型。–test 标志会将 flexible_jss_learn.py 从训练模式切换到推演推理模式。在测试阶段的每个重叠窗口中,模型会预测要固定的分配——预测概率高于 MODEL_TH 的分配将被提交,剩余的灵活性则由 CP-SAT 求解器在时间预算内解决。
export TEST_INDEX_START=500
export TEST_INDEX_END=501 # 递增此值以覆盖整个测试集
export DATA_INDEX_START=0
export DATA_INDEX_END=450
export JSS_DATA_DIR=train_data_dir/instance/j20-m10-t30_mix
export TRAIN_DATA_DIR=train_data_dir/train_data/j20-m10-t30_mix-w80-s30-t60-st3
export LOG_DIR=train_test_dir/train_log/j20-m10-t30_mix-w80-s30-t60-st3
export TEST_STATS_DIR=train_test_dir/test_stats/j20-m10-t30_mix-w80-s30-t60-st3
export MODEL_DIR=train_test_dir/model/j20-m10-t30_mix-w80-s30-t60-st3
export MODEL_NAME=model_pw0.5
export POS_WEIGHT=0.5
export LOAD_MODEL_EPOCH=120 # 要加载的检查点
export MODEL_TH=0.5 # “固定”决策的预测阈值
export WINDOW=80
export STEP=30
export TIME_LIMIT=60
export STOP_SEARCH_TIME=3
python -u flexible_jss_learn.py \
--train_data_dir $TRAIN_DATA_DIR \
--jss_data_dir $JSS_DATA_DIR \
--log_dir $LOG_DIR \
--test_stats_dir $TEST_STATS_DIR \
--model_dir $MODEL_DIR \
--data_index_start $DATA_INDEX_START \
--data_index_end $DATA_INDEX_END \
--val_index_start $TEST_INDEX_START \
--val_index_end $TEST_INDEX_END \
--num_epochs $EPOCH \
--model_name $MODEL_NAME \
--window $WINDOW --step $STEP \
--time_limit $TIME_LIMIT \
--stop_search_time $STOP_SEARCH_TIME \
--pos_weight $POS_WEIGHT \
--test \
--load_model_epoch $LOAD_MODEL_EPOCH \
--model_th $MODEL_TH
推演过程会在每个测试实例上并行评估五种方法:(1) Full FJSP(无分解)、(2) Default RHO、(3) Oracle RHO、(4) Random 基线以及 (5) L-RHO(你训练的模型)。每种方法的统计数据都会保存到 TEST_STATS_DIR,以便在下一步中进行汇总。
汇总与打印结果:
在所有测试索引(500–599)上运行测试推演后,使用 print_results.py 计算并显示汇总统计数据:
export INDEX_START=500
export INDEX_END=600
export TEST_STATS_DIR=train_test_dir/test_stats/j20-m10-t30_mix-w80-s30-t60-st3/model_pw0.5
export DATA_NAME=stats_e120th0.5 # 编码了轮次和阈值
python -u print_results.py \
--index_start $INDEX_START \
--index_end $INDEX_END \
--stats_dir $TEST_STATS_DIR \
--data_name $DATA_NAME
DATA_NAME 遵循 stats_e{EPOCH}th{THRESHOLD} 的约定——与测试期间使用的 LOAD_MODEL_EPOCH 和 MODEL_TH 相匹配。此脚本会读取所有单实例的统计文件,并打印五种方法中每种方法的 Makespan 目标均值和标准差,使你能够直接将 L-RHO 与基线进行对比。
故障排除:
如果 L-RHO 未能优于 Default RHO,README 提供了一个专用的调试模式。使用 --script_action debug 运行 flexible_jss_main.py,以便在同一实例上对比 Default RHO 与 Oracle RHO。这可以隔离问题出在 Oracle 加速求解的能力上(Oracle 本身必须优于 Default RHO,学习方法才能奏效),还是出在模型学习 Oracle 行为的能力上。
export SCRIPT_ACTION=debug
python -u flexible_jss_main.py \
--jss_data_dir $JSS_DATA_DIR \
--stats_dir $STATS_DIR \
--data_idx $DATA_IDX \
--time_limit $TIME_LIMIT \
--stop_search_time $STOP_SEARCH_TIME \
--oracle_time_limit $TIME_LIMIT \
--oracle_stop_search_time $STOP_SEARCH_TIME \
--n_cpus $N_CPUS \
--num_oracle_trials $NUM_ORACLE_TRIALS \
--window $WINDOW --step $STEP \
--script_action $SCRIPT_ACTION
如果 Oracle 未能稳定地优于 Default RHO,请考虑调整 RHO 超参数(Window、Step、Time Limit、Stop Search Time)——不同的问题规模可能需要不同的配置才能使 Oracle 发挥效用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)