最新抖音评论数据分析系统5000字实战笔记:踩坑、选型、落地全过程
前言
做短视频运营的人,大概都有一个共同的痛点:评论数据太难用了。
在上一篇文章中,我用了《近万字详细拆解如何开发一套抖音短视频解析工具》。
而现在,抖音后台给的数据很有限,你想批量看同类型视频的评论趋势、对比不同视频的热度、把评论跑一遍 AI 分析看看正面负面各占多少——这些需求,靠后台导出那点数据根本满足不了。
我当时的痛点很具体:
- 想批量分析用户关注点,找到内容优化方向
- 想对比不同视频的评论热度,验证内容策略是否有效
- 想把评论自动化分析,不用一条条手动翻
带着这些需求,我开始琢磨怎么做一个评论数据分析系统。
一、系统要解决什么问题
在动手之前,我先想清楚了这个系统要具备哪些能力:
- 评论数据管理 —— 能存储、查询历史评论数据,方便做跨时间对比
- 多维分析 —— 情感倾向、热点词汇、用户话题分布、高频问题提取
- 热度分析 —— 找到评论最集中的时间段,判断最佳发布时机
- 报告导出 —— 生成可视化报告,方便汇报和存档
整个系统的核心价值就一句话:把散乱的评论数据,变成可行动的洞察。
二、技术方案选型
我不是技术出身,选型的思路跟程序员不一样——我不关心用什么框架、什么语言,我关心的是:这个东西能不能稳定跑起来、出了问题我能不能自己解决。
最终的技术栈是这样的:
- 后端:Python + FastAPI,轻量、文档清晰、部署简单
- 前端:React + TypeScript,团队用的是这套,我也跟着用
- 数据库:MySQL,够用就好
- 分析能力:本地词频统计 + 大模型语义理解,两条腿走路
这里有个经验:能用成熟方案的就不用自己造轮子。比如情感分析,与其自己训练模型,不如直接接大模型 API,效果好、迭代快。
三、数据怎么存
评论数据存到数据库里,是整个系统的基础。
这一步有几个关键设计:
1. 主键设计
每条评论用 detail_id + cid 组成联合主键。
detail_id是视频ID,同一个视频的评论都有相同的 detail_idcid是评论ID,全局唯一
这样设计的好处是:同一个视频、同一条评论不会出现重复记录。
2. 增量更新机制
用户第一次分析一个视频,采集全部历史评论;之后每次分析,只拉取新增的评论。
实现思路是:每次采集前先查一下数据库里这个视频最新评论的时间戳,接口翻页时只拿时间戳更大的数据,遇到旧评论就停止。
这个逻辑说起来简单,实际实现的时候踩了不少坑,下面会细说。
3. 数据过滤
接口返回的评论里,有些是广告、推广、引流内容,需要过滤掉。
过滤规则包括:
- 包含"广告"、“推广”、“引流”、“vx”、"微信"等关键词的评论
- 纯表情包评论(用正则匹配
[.+\]格式的内容)
过滤之后的数据才进入分析流程,保证分析结果不被垃圾数据污染。
四、踩过的几个坑
接下来聊聊实际开发过程中踩过的坑。这些坑不大,但每个都让我卡了挺久。
坑一:增量更新,怎么判断"遇到旧数据就停"
增量更新的核心逻辑是:翻页遍历,遇到数据库里已有的旧评论就停止。
理论逻辑很简单:
for page in range(max_pages):
batch = fetch_page(page)
valid_batch = filter_spam(batch)
# 找出这页里真正的新评论(时间戳大于数据库最新值)
new_in_batch = [c for c in valid_batch if c['create_timestamp'] > last_timestamp]
# 如果这页出现了旧评论,说明翻到头了
old_in_batch = len(valid_batch) - len(new_in_batch)
if old_in_batch > 0:
break
但实际操作中遇到了几种边界情况:
- 评论时间戳精度不够:两个不同时间发的评论可能显示同一个时间戳,导致判断出错
- 评论顺序不固定:新评论不一定出现在最前面,偶尔会夹在老评论中间
- 接口有频率限制:翻页太快会被限速,不能无限循环
后来我在每一步都加了日志记录,确保翻页过程可追溯、可调试。
坑二:JSON 解析失败
评论分析用了大模型的 API,让它告诉我每条评论是正面的、负面的还是中立的。
大模型返回的是 JSON 格式的数据,但偶尔会遇到返回内容被截断的情况——可能少了一个 },可能少了一个 ],直接解析会报错。
一开始我的处理方式是直接重试,但重试几次还是失败,浪费了不少 API 调用额度。
后来写了一个修复函数,专门处理 JSON 被截断的情况:
def fix_incomplete_json(text: str):
# 去掉末尾可能多余的逗号
text = text.rstrip(',')
# 统计括号是否配对,补全缺失的
open_brackets = text.count('[')
close_brackets = text.count(']')
text += ']' * (open_brackets - close_brackets)
open_braces = text.count('{')
close_braces = text.count('}')
text += '}' * (open_braces - close_braces)
return text
这个函数不能保证 100% 修复成功,但能解决大部分被截断的情况,API 调用失败率明显下降了。
坑三:字段名和预期不一致
接数据接口的时候,文档上写的字段名和实际返回的字段名,有时候不一样。
比如文档里写的是 comment_id,实际返回的是 cid;文档里写的是 user_name,实际返回的是 nickname。
一开始不知道这个问题,按文档写的字段名去取值,结果全是 None。
排查了很久才发现问题所在。解决方案也很土:先把原始数据打印出来看一遍,知道实际字段长什么样,再用实际字段名去处理。
这个习惯后来成了我接任何新接口的标准动作:先打印、后处理。
坑四:LLM 分析结果,字段对不上
给大模型喂了一堆评论,让它做情感分析和话题聚类。
Prompt 写好之后跑了一遍,发现返回的结果里少了几个字段——我明明在 Prompt 里要求输出 hot_topics 和 role_insights,但实际结果里这两个字段是空的。
排查了一圈,发现问题出在代码逻辑上:
# 原来的代码
if "hot_topics" in required_fields:
result["hot_topics"] = ...
这里 required_fields 存的是英文字段名(比如 "hot_topics"),但判断条件用的是中文分析目的名(比如 "热点话题" in required_fields)。条件永远为 false,字段就永远不输出。
改成英文字段名判断之后,问题解决了。
这是一个很低级的错误,但因为 Prompt 和代码是我分别写的,调试的时候没有把它们对应起来看。教训是:Prompt 里的字段名和代码里的字段名要保持一致。
坑五:波峰检测,阈值设不对
我想知道视频在哪些时间段评论最集中,用来判断"什么时候发视频效果最好"。
实现思路是:统计每小时/每天的评论数量,找出异常高的波峰。
一开始我设置的波峰阈值很低,100多条评论分散在3个月里,系统硬是识别出了好几个"波峰"——每个波峰实际上只有2-4条评论,毫无参考价值。
后来我把最低阈值调高到 10 条评论,才过滤掉了那些伪波峰。
另外还加了一个兜底逻辑:如果某个时间段评论太少,就从整体分布里找相对活跃的时间段,至少能给出一些参考建议,而不是直接显示"无波峰"。
五、评论分析怎么做
这是系统的核心功能部分。
分析维度
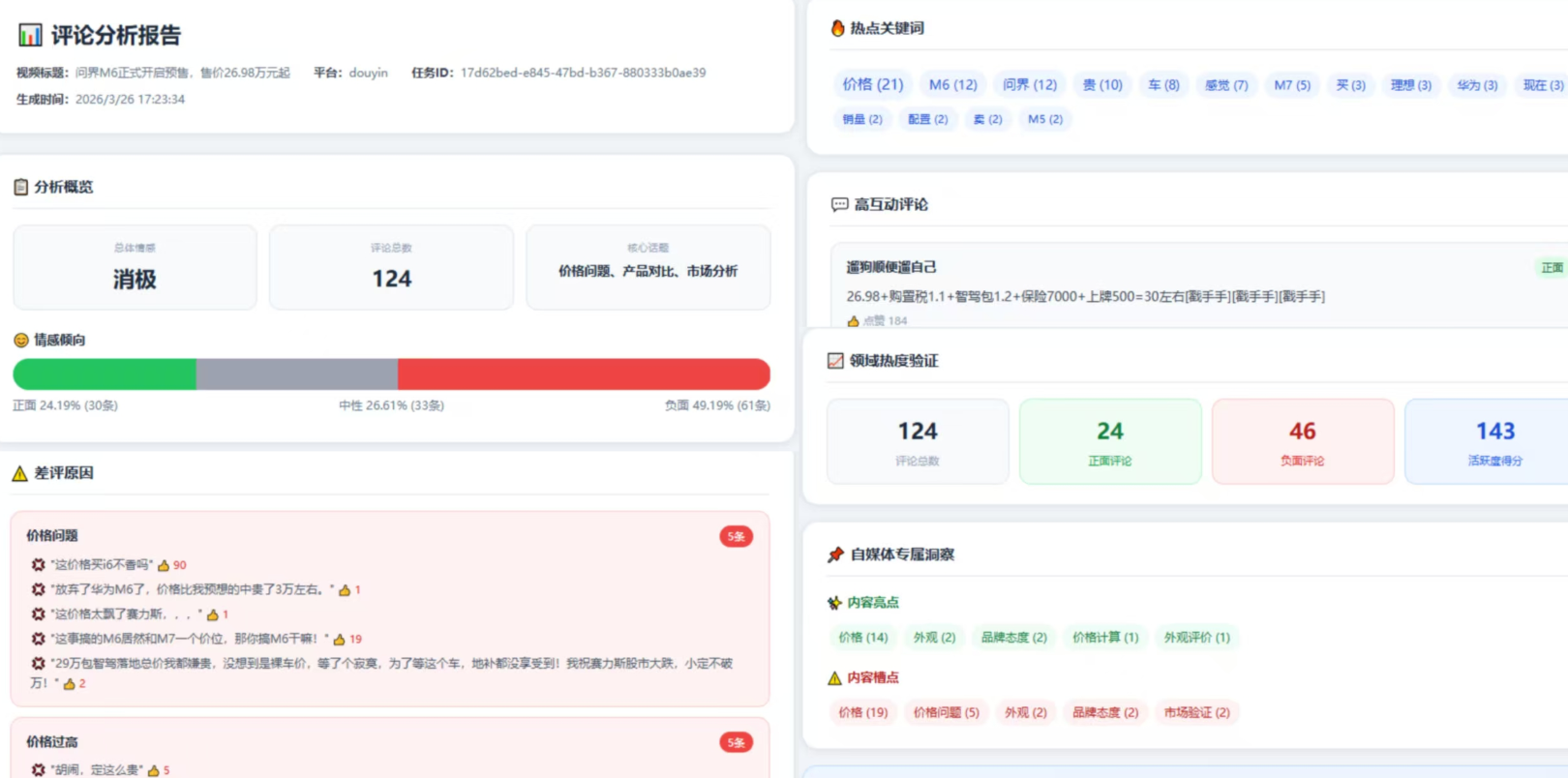
目前系统支持的分析维度包括:
- 情感分析 —— 正面/负面/中立比例,附带正面评论Top5和负面评论Top5
- 热点关键词 —— 出现频率最高的词汇,生成词云
- 主题聚类 —— 把评论按话题分组,比如"询问价格"、“询问合作”、"表达情感"等
- 问答汇总 —— 把用户问题收集起来,统计各类型问题的数量
- 热度峰值 —— 找到评论最集中的时间段
这些分析分两条路:
- 本地词频统计:用 jieba 分词 + 词频统计,速度快、成本低,适合基础分析
- 大模型语义理解:把评论发给大模型,让它做深度语义聚合,适合需要理解上下文的高阶分析
两条路结合起来用,基础指标秒级出,高阶洞察等几秒也能出来。
Prompt 调优
用大模型做分析,Prompt 怎么写很关键。
一开始我的 Prompt 很简洁,结果 LLM 输出很飘,同一个问题可能归到不同的分类里,同一个分类下面也有语义完全不相关的评论。
后来加了大量示例(Few-shot),让 LLM 知道"这类评论应该归到哪个分类"、“这类评论应该排除在外”。
调 Prompt 的过程是反复的:跑一批数据看结果,感觉哪里不对就改 Prompt,再跑一批、再改……直到结果比较稳定为止。
六、踩坑心得
回头看整个过程,有几个心得可以分享:
1. 边界情况要提前想清楚
增量更新里"遇到旧评论就停止"这个逻辑,听起来简单,但实际处理的时候有太多边界情况要考虑:时间戳精度、评论顺序、频率限制……好的系统设计,不是在理想情况下能跑,而是各种边界情况下都能正常运转。
2. 日志是最好的调试工具
很多问题,靠打印日志就能解决。把每一步的输入输出都记录下来,错误在哪、哪一步出了问题,一目了然。
3. 不要过度依赖文档
任何接口的文档都不一定完全准确,接入之前最好自己先跑一遍、打印一遍,把实际情况摸清楚。文档是参考,不是圣经。
4. 分步验证,小步快跑
整个系统功能很多,不要想着一次性全部搞定。每加一个功能就验证一个功能,发现问题立刻回退,不要等到最后才发现整体都有问题。
七、系统展示
经过这段时间的迭代,这套系统已经从"能跑"变成了"好用"。需要的可以体验一下umind酉脑短视频解析平台
写在最后
做这个系统的过程中,我踩了很多坑,也学到了很多东西。
最大的感受是:非技术出身不代表做不了技术的事。
关键是你愿不愿意学、愿不愿意试、愿不愿意在被坑了之后继续折腾。
当然,有个好的工具也很重要。我全程用的是 WorkBuddy,一个 AI 编程助手。它帮我读代码、写代码、改 bug,让我一个不懂代码的人也能做完整的技术项目。
如果你也有类似的想法——想做一个工具、提升某个流程的效率——不妨试试看。
有时候,最难的不是开始做,而是迈出第一步。
相关阅读:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)