论文精读-基于注意力机制的 U⁃Net 叶片缺陷图像分割
1. 研究背景

能源重要性:风能作为清洁可再生能源具有巨大的商业价值,而叶片是捕获风能的关键且易损部件 现状与痛点:叶片损伤占所有风机部件故障的7%,若不及时检测会导致结构失效和重大经济损失 检测方式演进:传统的检测方法如人工检测(风险高)和传感器监测(稳定性差)存在局限;基于深度学习的机器视觉技术已成为结构健康监测的热点 。
2. 科学问题
检测难点:虽然现有模型在局部缺陷识别上效果较好,但面对不同缺陷类型尺寸差异大(如裂纹等微小缺陷)的情况,模型往往缺乏反映结构整体损伤的能力,且对微小缺陷的分割边缘较为模糊 研究目标:如何构建一个能够兼顾复杂缺陷和微小缺陷,实现准确分类与精确分割的语义分割网络。
3. 主要方法

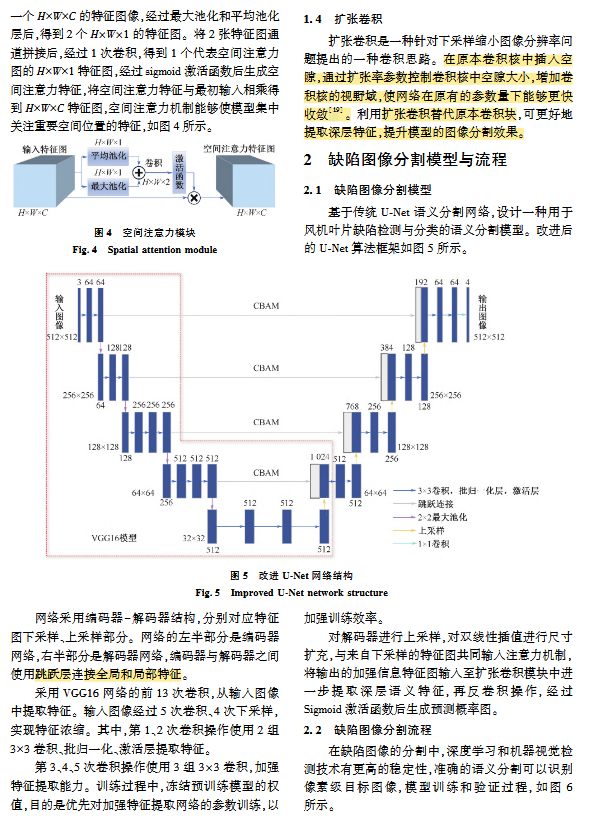
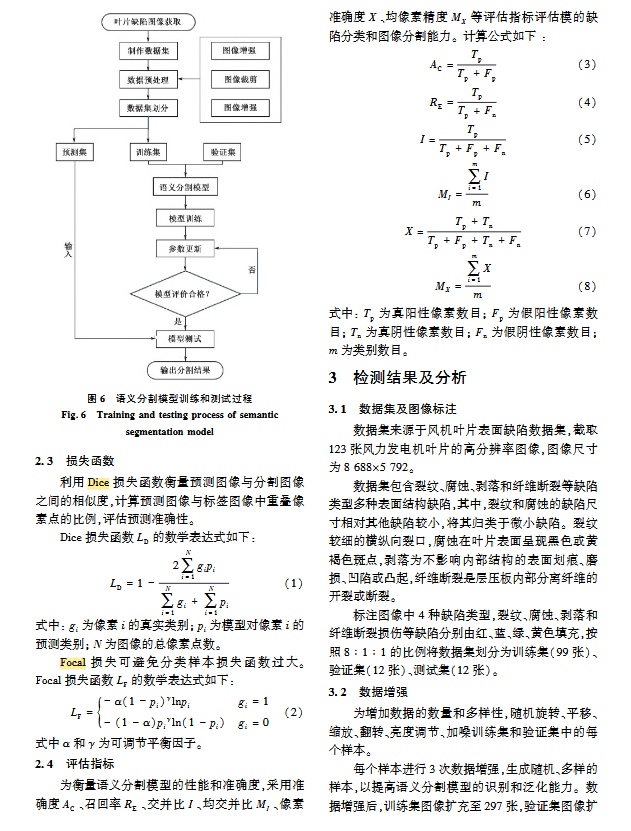
该研究构建了一种基于扩张卷积和卷积注意力模块的改进 U-Net 网络 :
编码器改进:使用可迁移的 VGG16 特征提取层代替原始 U-Net 的编码部分,并采用在 ImageNet 上预训练的模型实现迁移学习,以解决风机叶片缺陷小样本数据集训练困难的问题 。
注意力机制(CBAM):在编码器与解码器之间的跳跃连接部分加入卷积块注意力模块(CBAM),通过通道注意力和空间注意力机制,使网络集中关注重要区域并减少无关特征干扰。
扩张卷积:在解码阶段使用**扩张卷积(Dilated Convolution)**代替标准卷积,在不增加参数量的前提下增大感受野,增强深层特征提取能力 。
损失函数:采用 Focal Loss 与 Dice Loss 结合的混合损失函数,平衡分类样本不均并衡量预测图像与标签的相似度 。
4. 核心发现
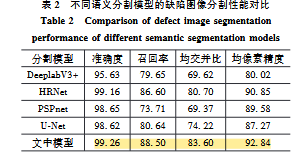
性能优异:改进后的 U-Net 在叶片缺陷数据集上的均交并比(mIoU)达到 83.60%,均像素精度(MPA)为 92.84%,召回率(Recall)为 88.50% 。
对比优势:该模型的 mIoU 值比 DeepLabV3+ 模型高 13.98%,比标准 U-Net 模型高 9.38%,在 5 种缺陷类别(背景、裂纹、剥落、纤维断裂、腐蚀)上的分割效果均优于 PSPnet、HRNet 等主流算法 。
消融实验验证
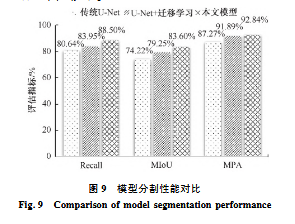
- 添加迁移学习策略后,mIoU 提升了 5.03% 。
- 在迁移学习基础上增加注意力机制和改进卷积块,mIoU 进一步提升了 4.35% 。
5. 主要结论
-
改进的 U-Net 模型能有效识别和分割风机叶片缺陷,显著提升了对裂纹等微小缺陷检测的灵敏度,并降低了误报警率 。
-
通过结合迁移学习、注意力机制和扩张卷积,模型在处理小样本、多尺度缺陷任务中表现出较强的鲁棒性和实用性 。
6. 亮点与不足
-
亮点:
结构创新:巧妙地将 CBAM 引入跳跃连接,并利用 VGG16 优化特征提取,精准解决了微小缺陷“定位难、分割糊”的问题 。实用性强:论文不仅进行了算法对比,还通过消融实验清晰展示了各组件的贡献,对工业场景下的缺陷检测具有实际指导意义 。 - 不足(基于文献内容推导):
-
样本限制:研究使用的数据集相对较小(原始图像 123 张),虽然通过数据增强和迁移学习缓解了问题,但在更复杂真实环境下的泛化能力仍有待验证 。
极小目标挑战:尽管性能提升显著,但从实验数据看,裂纹(IoU: 66.58%)和腐蚀(IoU: 73.66%)的分割精度依然明显低于纤维断裂(IoU: 91.50%),对于极细微缺陷的分割仍有提升空间 。
-
7.阅读过程中查阅的名词意义
mIoU 的全称是 Mean Intersection over Union,中文译为 平均交并比。它是衡量语义分割(Semantic Segmentation)模型性能最核心、最通用的评价指标。
要理解 mIoU,可以将其拆解为 IoU 和 Mean 两个部分:
1. 什么是 IoU (Intersection over Union)?
IoU 衡量的是“预测区域”与“真实区域(Ground Truth)”之间的重叠程度。
想象图像中有两个像素集合:
-
预测区域 (A):模型算法认为属于某一类(如“叶片裂纹”)的像素。
-
真实区域 (B):标注员手动标出的该类像素的真实范围。
IoU 的计算公式为:
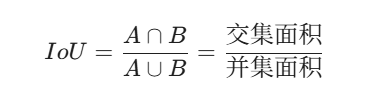
-
分子(交集):模型预测正确且确实属于该类别的部分。
-
分母(并集):模型预测出的区域与真实区域的总和(重叠部分只算一次)。
-
取值范围:0 到 1 之间。1 表示完美重合,0 表示完全没有重合。
2. 什么是 mIoU (Mean IoU)?
在实际的图像分割任务中,通常有多个类别(比如背景、裂纹、剥落、腐蚀等)。
mIoU 就是先计算出每一个类别的 IoU,然后将它们相加,再取平均值。
假设有 $k$ 个类别(加上背景共 $k+1$ 类),计算方式如下:
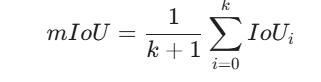
3. 为什么要用 mIoU?
在计算机视觉中,单纯使用“准确率”(Accuracy)有时会产生误导。例如:
-
如果一张图中 99% 的像素都是背景,只有 1% 是裂纹,模型即便把整张图都预测为背景,准确率也有 99%,但这对检测裂纹毫无意义。
-
mIoU 的优势:它对预测区域的“形状”和“位置”要求更高。它不仅要求模型找对地方,还要求分割的边缘尽量贴合。它能更客观地反映模型对各个类别的分割能力,尤其是对微小目标的捕捉能力。
4. 实际案例参考
在深度学习论文中,mIoU 的数值通常以百分比表示:
-
mIoU 较低(如 50% 以下):说明模型分割效果一般,边缘模糊或存在大量误报/漏报。
-
mIoU 较高(如 80% 以上):说明模型在大多数类别上都能实现非常精准的分割。
例如在风机叶片缺陷检测的场景中,达到 83.60% 的 mIoU 意味着模型不仅能准确区分背景和叶片,还能在复杂的背景干扰下,将裂纹、剥落等不同尺度的缺陷边界勾勒得非常接近真实情况。
简单来说,标准卷积和扩张卷积(也叫空洞卷积)的主要区别在于卷积核(Kernel)抓取图像信息时的“跨度”和“覆盖范围”。
以下是详细对比:
1. 标准卷积 (Standard Convolution)
标准卷积是深度学习中最基础的操作。卷积核在输入图像上逐像素滑动,计算核内参数与对应像素值的加权和。
-
工作方式:卷积核的每一个元素都是紧挨着的。例如一个 $3 \times 3$ 的卷积核,它覆盖的就是图像上连续的 $3 \times 3$ 区域。
-
感受野:感受野(Receptive Field)较小。如果要扩大感受野(看更全的图),通常需要增加卷积层的深度,或者使用池化层(Pooling)来缩小图片尺寸。
-
缺点:在需要保留高分辨率信息(如医疗影像分割、叶片缺陷检测)的任务中,频繁使用池化层会导致空间细节丢失,难以恢复。
2. 扩张卷积 (Dilated Convolution)
扩张卷积在标准卷积核的元素之间插入了“空洞”(即填充 0,但实际计算时不增加参数量)。
-
扩张率 (Dilation Rate):这是它的核心参数。
-
Rate = 1:等同于标准卷积。
-
Rate = 2:卷积核元素之间跳过一个像素。一个 $3 \times 3$ 的卷积核在图像上覆盖的范围会变成 $5 \times 5$,但参与计算的参数依然只有 9 个。
-
Rate = 3:覆盖范围进一步扩大到 $7 \times 7$。
-
-
感受野:它能在不增加参数量、不降低图像分辨率的情况下,成倍地增大感受野。
3. 核心对比总结
| 特性 | 标准卷积 | 扩张卷积 |
| 核元素排列 | 紧密相连 | 存在间隙(由 Dilation Rate 决定) |
| 感受野 | 较小 | 较大(随扩张率指数增长) |
| 分辨率 | 若配合下采样会丢失细节 | 可以保持原图分辨率提取全局特征 |
| 参数量 | 基础参数量 | 相同核尺寸下,参数量与标准卷积一致 |
4. 为什么要用扩张卷积?(结合你的文献背景)
在你阅读的这篇关于叶片缺陷分割的论文中,使用扩张卷积主要是为了解决以下矛盾:
-
捕捉大尺度特征:有些缺陷(如长条状的裂纹或大面积腐蚀)需要较大的感受野才能理解其整体结构。
-
保留微小细节:传统的池化操作(Max Pooling)虽然能增大感受野,但会把微小的裂纹像素“糊掉”。
-
平衡性能:扩张卷积让网络既能“看得广”(理解宏观缺陷),又能“看得清”(保留像素级的位置信息),这对于提高微小缺陷的分割精度(mIoU)至关重要。
形象比喻:
-
标准卷积像是拿着一个小放大镜紧贴着书本看,一次只能看清一个字。
-
扩张卷积像是把小放大镜抬高了,虽然还是只用那几个透镜在看,但视野变大了,能一次看清半个句子,而且不需要把书本裁小。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)