最强开源代码模型来了!Qwen3.6-35B-A3B 私有化部署全攻略

前言:就在几天前,通义千问正式开源了新一代模型:Qwen3.6-35B-A3B。
只看参数规模,这似乎只是一次常规迭代。 但在实测之后,我意识到:风向彻底变了。
大模型正在从“回答问题的工具”,
演进为“执行任务的系统组件”。
尤其在代码生成、工具调用和多步任务中,它不再只是给答案,而是深度参与开发。
一、模型能力定位的变化
官方数据显示:
仅凭 30亿激活参数,
Qwen3.6-35B-A3B 在编程基准上就超越了 270亿参数的稠密模型 Qwen3.5-27B。
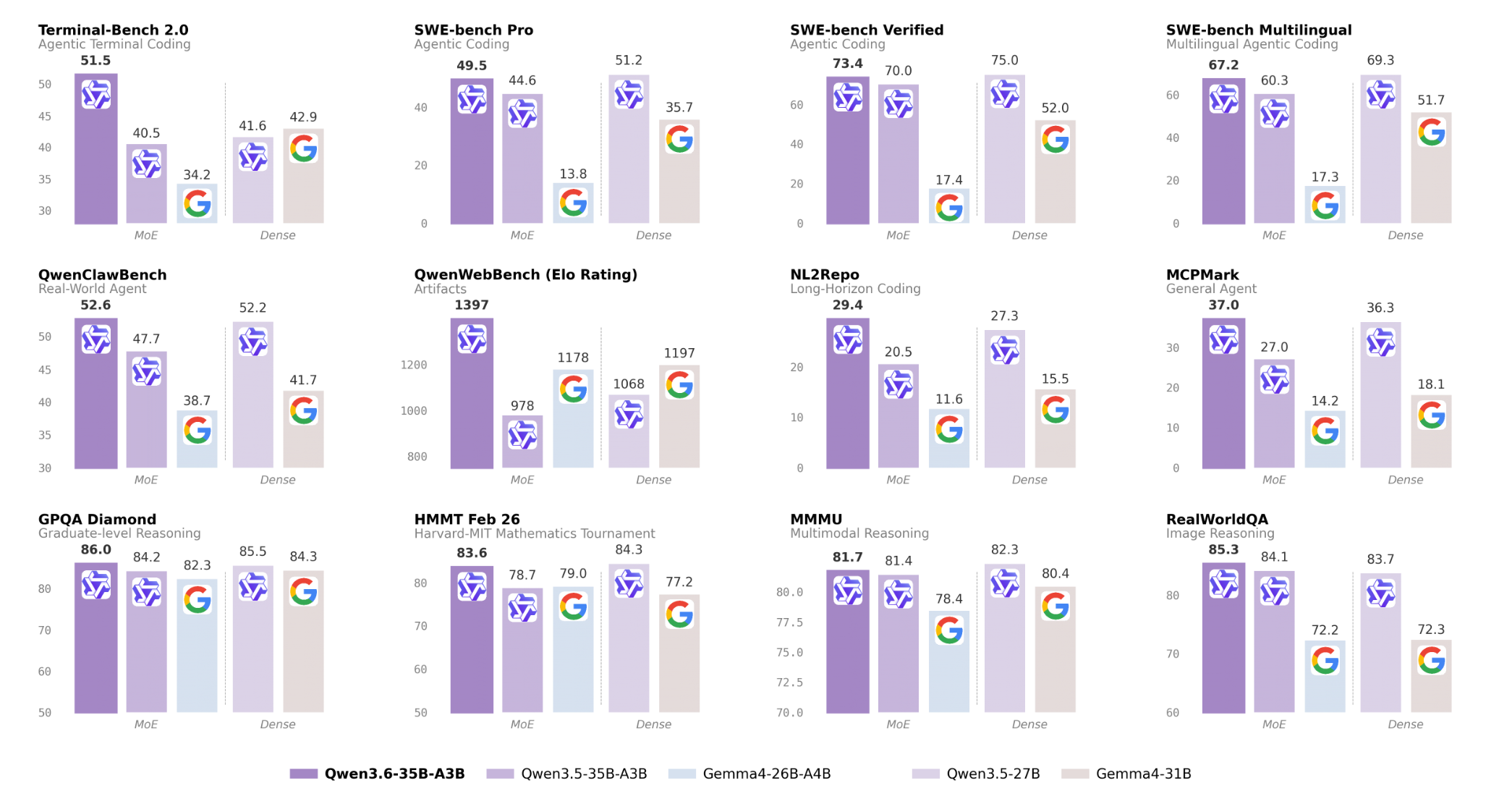
如果用一句更直观的话来描述这次变化,可以这样理解:
有些模型擅长“解释问题”, 而 Qwen3.6 更擅长“把事情做完”。
也正因为这一点,本次的目标不再只是简单地把模型跑起来,而是延续上一篇 **Gemma-4-31B-it **的思路,将 Qwen3.6 构建为一个可服务化的节点:通过 vLLM 提供 OpenAI-Compatible API,在局域网内稳定访问,并最终接入 OpenCode 等工具体系,进入真实开发流程中使用。
接下来不啰嗦、不绕弯,全程实战,将基于一台 A100 80G 单卡服务器,从模型准备、容器部署到服务接入,看完就能自己搭一套属于自己的私有化编程大模型。
二、部署目标与实验环境
本次实验目标并不只是“跑通模型”,而是构建一个完整可用的服务化链路:
- 使用 vLLM 提供 OpenAI-Compatible API
- 控制 GPU 资源分配(单卡运行)
- 在局域网提供稳定访问能力
- 接入 OpenCode 形成开发闭环
实验环境如下:
- GPU: NVIDIA A100 80GB
- OS:Ubuntu Server
- 推理框架:vLLM
- 部署方式:Docker + OpenAI API Server
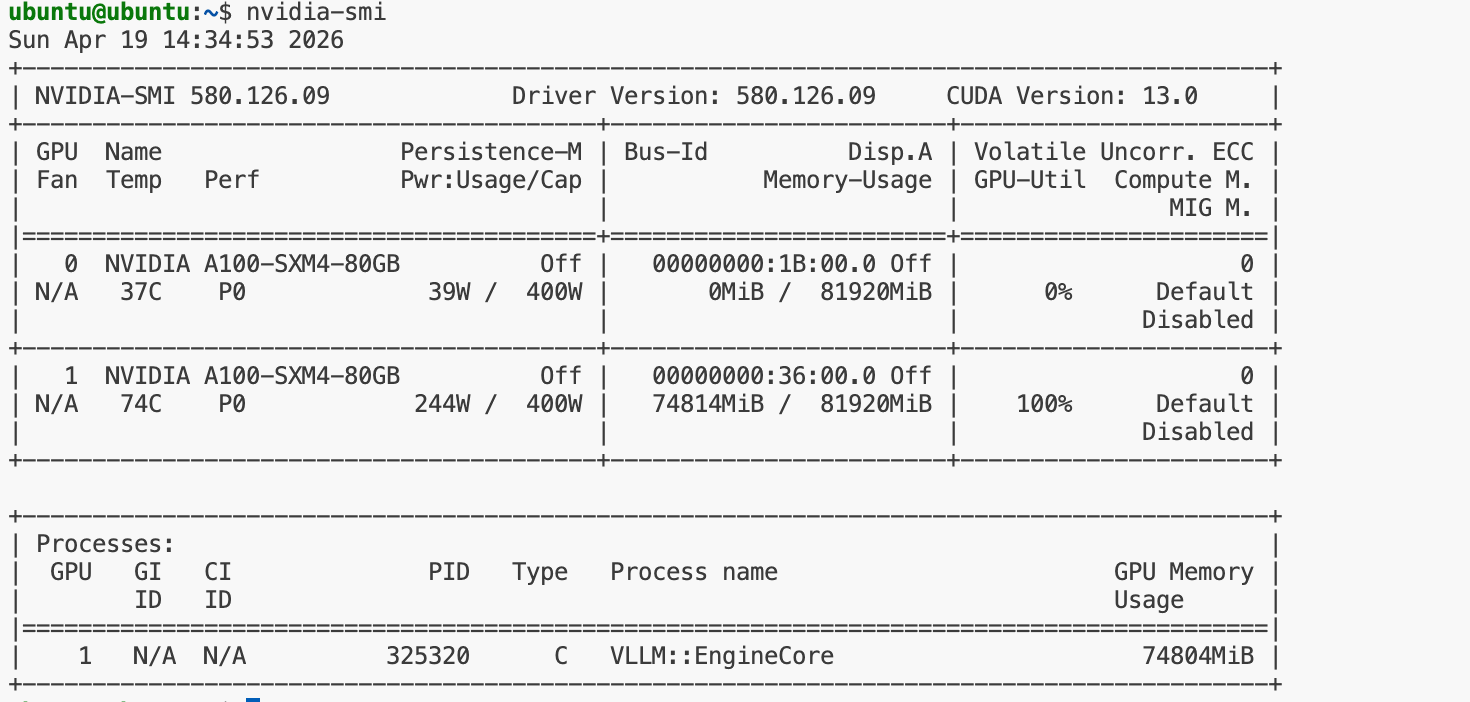
这里的第二张卡部署的是我们上一期文章提到的Gemma-4-31B-it,这里将Qwen3.6-35B-A3B部署到第一张卡上。
三、创建容器并启动 vLLM 服务
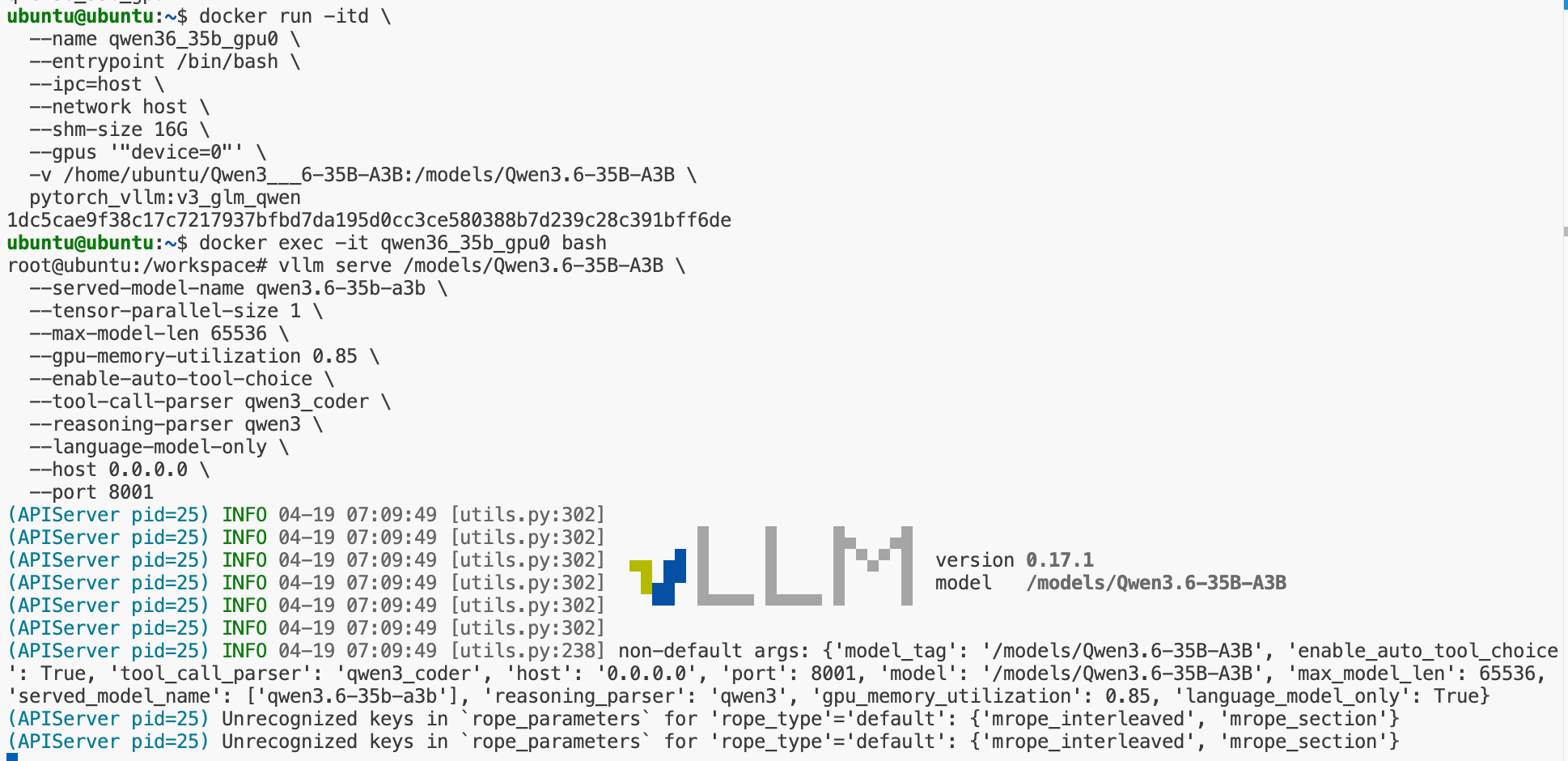
这里创建的容器名字是qwen36_35b_gpu0,device选择的是0,也就是第一块GPU,与Gemma-4-31B-it需要专属的镜像不同,Qwen3.6-35B-A3B使用通用的vllm镜像即可**:**
docker run-itd\
--name qwen36_35b_gpu0\
--entrypoint /bin/bash \
ipc=host \
--network host \
--shm-size 16G \
--gpus '"device=0"'\
-v /home/ubuntu/Qwen3___6-35B-A3B:/models/Qwen3.6-35B-A3B\
pytorch_vllm:v3_glm_qwen
同时在启动VLLM命令时,端口号一定要启用一个新的,因为8000之前已经被Gemma-4-31B-it占用了,这里我们选择使用8001:
当启动到一半的时候,模型权重已成功加载,但引擎初始化失败,服务无法启动:
ValueError: No available memory for the cache blocks.
Available KV cache memory: -10.25 GiB
我立马去查询了一下这个错误,该问题并非模型加载失败,而是:
KV Cache 显存分配失败(Key-Value Cache Allocation Failure)
KV Cache 随序列长度线性增长,是最主要的显存消耗来源,并且vLLM 默认只使用 70% 显存,进一步压缩了 KV Cache 可用空间。
最终采用如下调整策略:
vllm serve /models/Qwen3.6-35B-A3B \
--served-model-name qwen3.6-35b-a3b \
--tensor-parallel-size 1 \
--max-model-len 18192 \
--gpu-memory-utilization 0.92 \
--max-num-batched-tokens 512 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser qwen3 \
--language-model-only \
--host 0.0.0.0 \
--port 8001
降低上下文长度,32768 → 18192
显著降低 KV Cache 占用,释放约 15% 额外显存用于 KV Cache
这里给大家总结一下:在 vLLM 推理框架中,长上下文场景下的主要显存瓶颈并非模型参数本身,而是随序列长度线性增长的 KV Cache,其内存占用往往超过模型权重,是导致推理引擎初始化失败的关键因素。
四、验证服务
启动成功之后,直接另开一个终端进行测试:
curl http://127.0.0.1:8001/v1/models

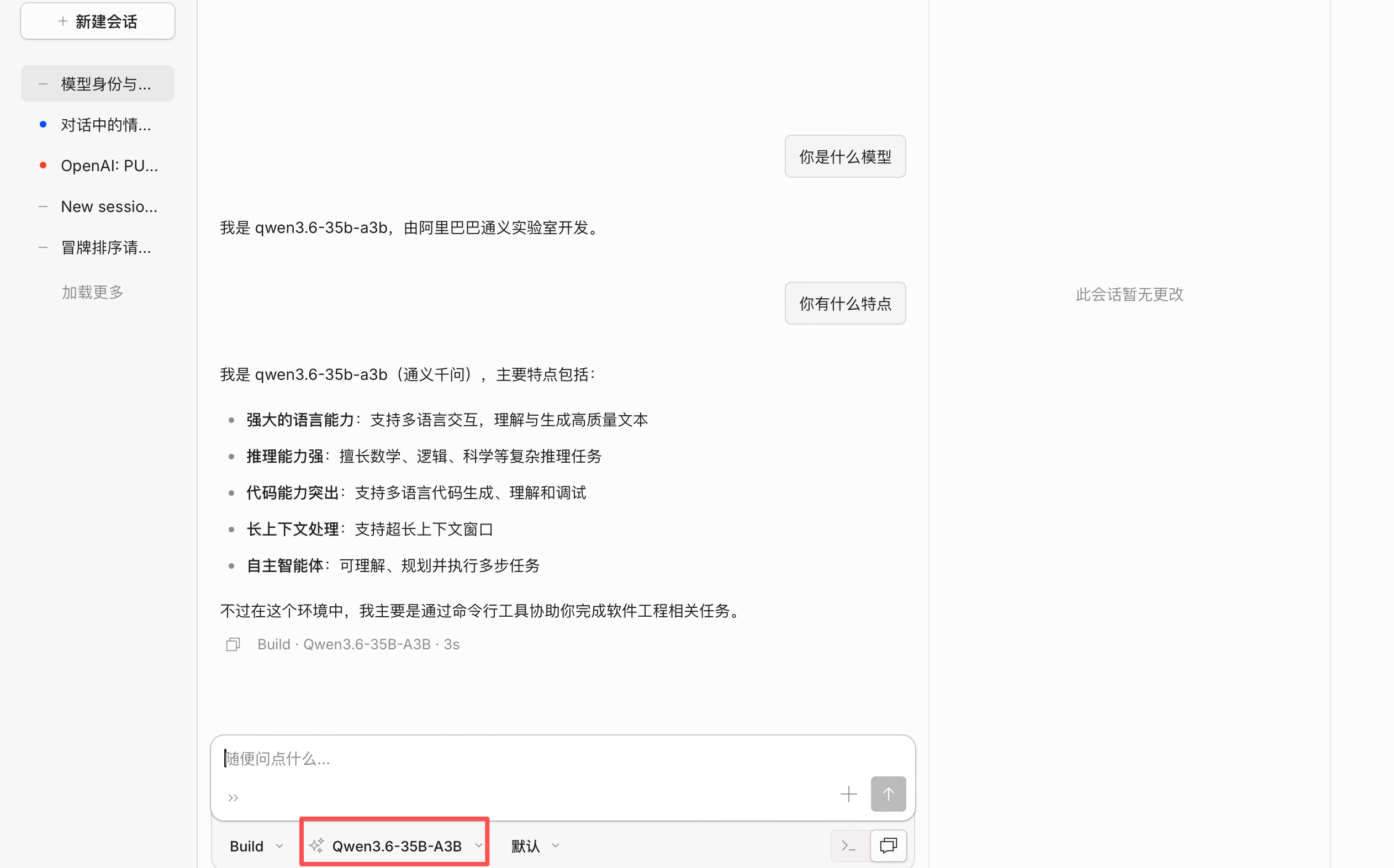
模型响应成功,通过返回结果来看,却给我们返回来了两个重复结果。这可不是报错,这是因为模型启动时,参数添加了 --reasoning-parser qwen3,vLLM 会同时返回答案 + 推理过程,属于 Qwen3 推理模式的正常表现。
OpenCode配置接入
模型服务跑通后,接入OpenCode实现智能体编程,配置文件一键生成,命令直接复制执行:
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"qwen_vllm": {
"npm": "@ai-sdk/openai-compatible",
"name": "Qwen3.6-35B-A3B LAN vLLM",
"options": {
"baseURL": "http://xxx.168.15.119:8001/v1",
"apiKey": "EMPTY"
},
"models": {
"qwen3.6-35b-a3b": {
"name": "Qwen3.6-35B-A3B",
"limit": {
"context": 18192,
"output": 2048
}
}
}
}
},
"model": "qwen_vllm/qwen3.6-35b-a3b"
}
EOF
响应结果如下所示:
五、模型能力测试分析
1.代码能力:
请用 Python 写一个快速排序函数,并满足以下要求:
-
代码可直接运行;
-
包含一个简单测试样例;
-
解释时间复杂度和空间复杂度;
4.不要使用任何第三方库。
Qwen3.6-35B-A3B 不仅生成了完整代码,还设计了基础测试和随机数据测试两个样例:
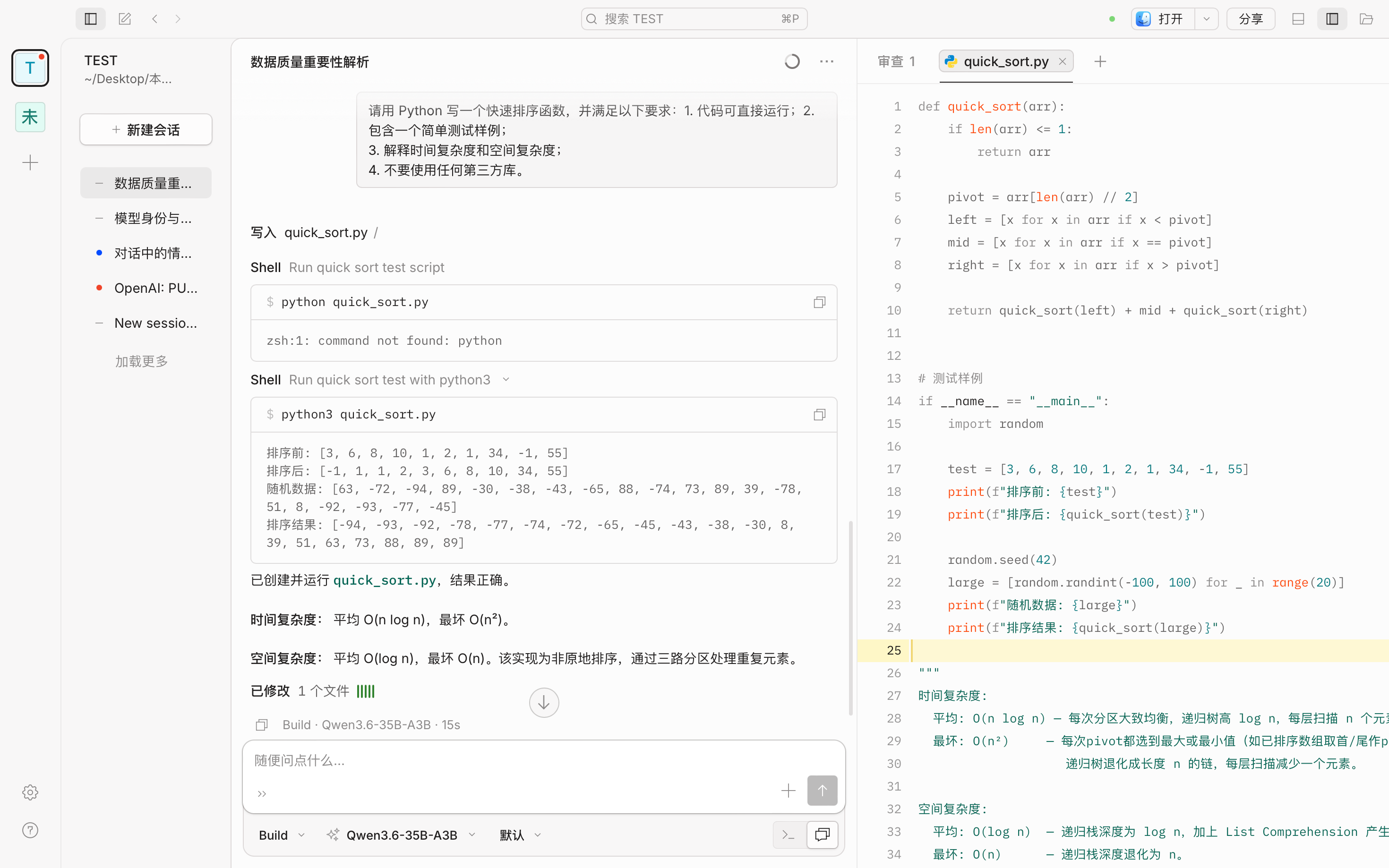
复杂度说明更、细致,补充了代码实现的策略、特点及注意事项:
时间复杂度:
平均: O(n log n) — 每次分区大致均衡,递归树高 log n,每层扫描 n 个元素。
最坏: O(n²) — 每次pivot都选到最大或最小值(如已排序数组取首/尾作pivot),
递归树退化成长度 n 的链,每层扫描减少一个元素。
空间复杂度:
平均: O(log n) — 递归栈深度为 log n,加上 List Comprehension 产生的临时列表。
最坏: O(n) — 递归栈深度退化为 n。
说明:
此实现使用"三路分区"策略(left / mid / right),天然去重,代码简洁。
注意:它不是原地排序,额外使用了与输入等大小的临时列表,因此空间开销
大于原地 In-place 版本,但胜在可读性和对重复元素的友好处理。
2.逻辑能力:
测试问题: 一个人要把一只狼、一只羊和一筐菜运到河对岸。船每次只能载他和一样东西。如果狼和羊单独在一起,狼会吃羊;如果羊和菜单独在一起,羊会吃菜。请说明步骤。
给出回答如下:
第一步:带羊过河,留下狼和菜。 原因:狼不吃菜,它们单独在一起是安全的。
第二步:独自返回,带狼过河。 原因:如果带菜,回来时狼会吃羊;带狼则羊独自在对岸等待。
第三步:到对岸后,把狼放下,把羊带回来。 原因:这是最关键的一步。不能留羊和狼在一起,所以把羊带回。
第四步:放下羊,带菜过河。 原因:狼和菜单独在一起,狼不吃菜,安全。
第五步:独自返回,带羊过河。 原因:此时狼和菜已在对岸,羊独自在此岸,全部安全到达。
Qwen3.6-35B-A3B不仅给出了正确步骤,还清晰地标注了“这是最关键的一步”,说明其对题目核心矛盾点的理解更为透彻,这种回答往往更接近于我们在复杂推理中的思维习惯。
3.工程能力:
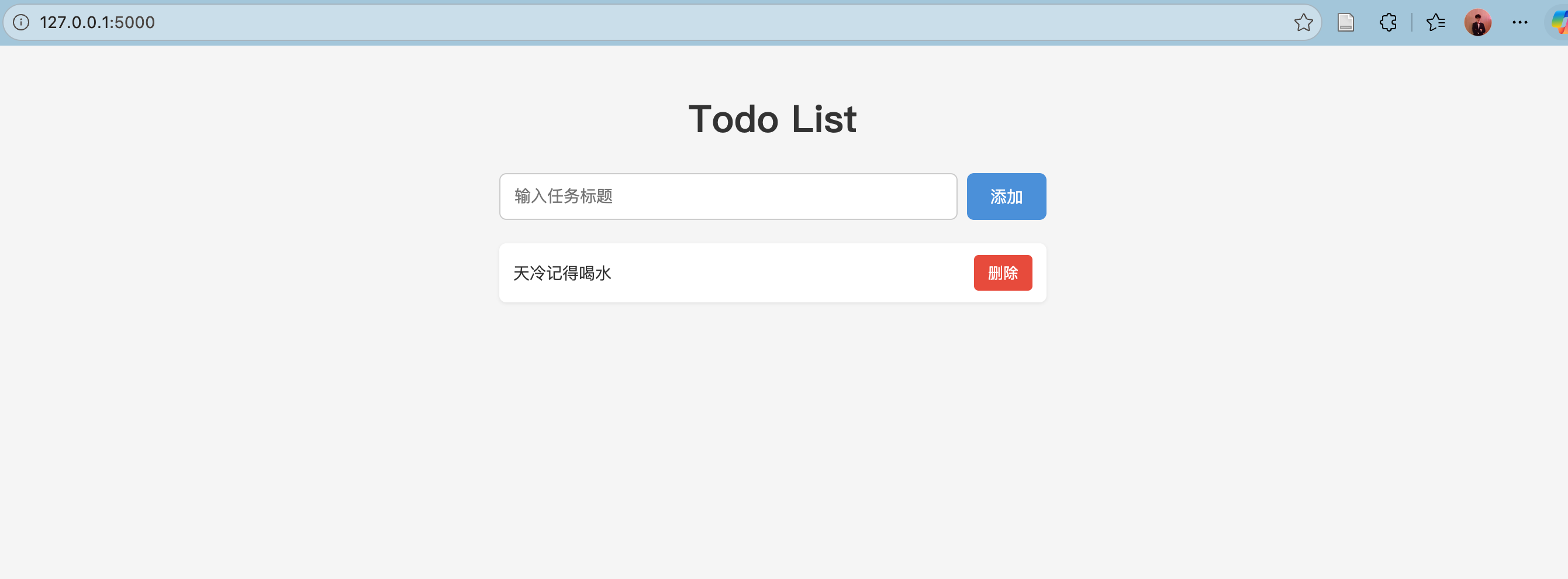
测试生成一个Todo前后端测试,从实际运行结果来看,该系统已经完成完整闭环验证:
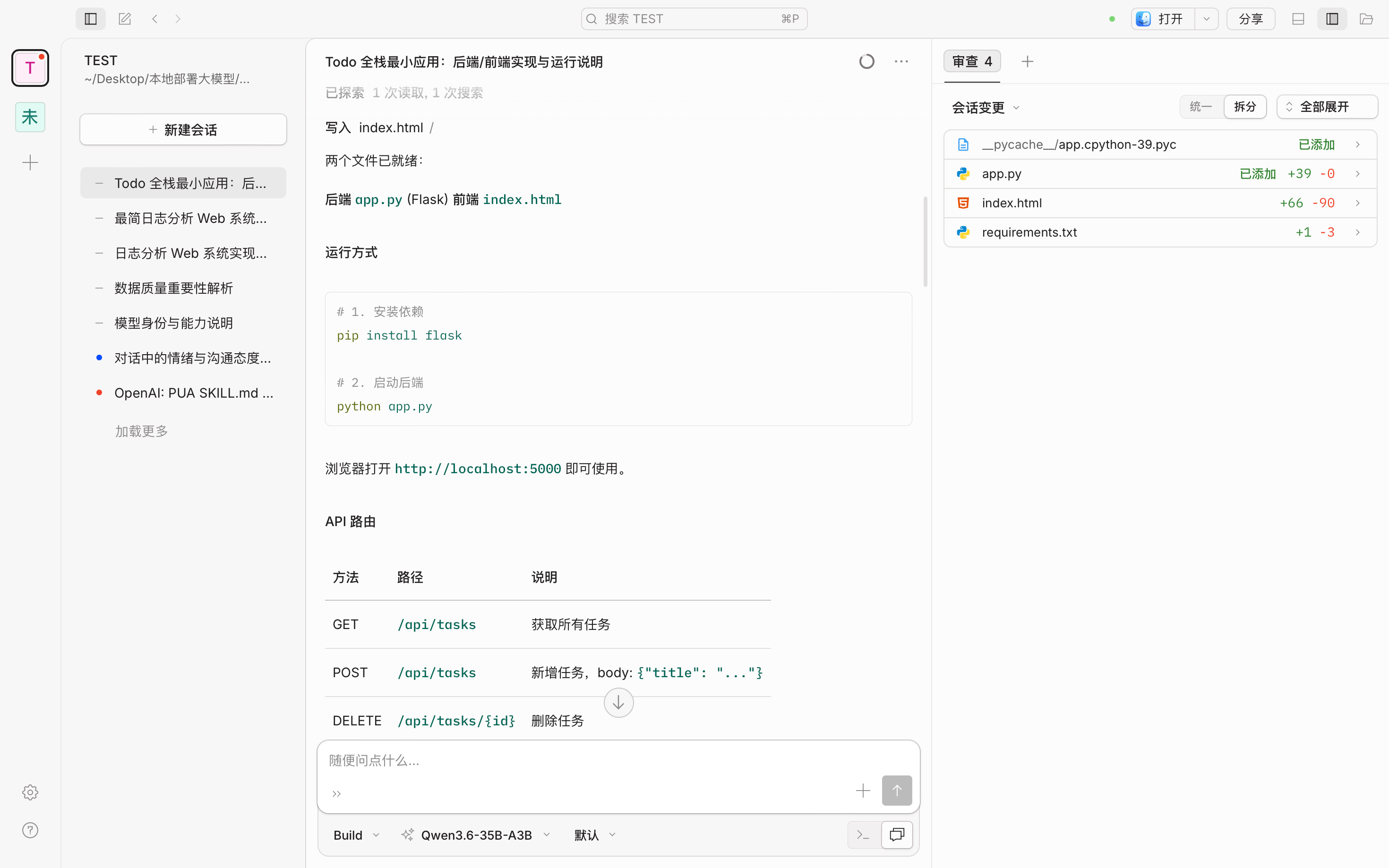
Flask 服务稳定启动 ,同时API 请求响应正常,前端页面可正常访问,在上面也可以进行任务增删改逻辑,这说明Qwen3.6-35B-A3B模型已经具备本地系统交付运行功能。
这一点在大模型评测中属于明显的分水岭能力。
4.速度能力
- 生成 token 数:2048 tokens
- 总耗时:36.36 秒
- 生成速度:≈ 56.3 token/s
这个速度在 35B 模型单卡 A100 推理里属于第一梯队,远超同级别开源模型,完全满足编程、长文本、智能体交互的流畅使用。
六、结语
随着最近的测试,我最直观的感受是:风向变了。 现在的各种AI模型和工具,都在转向一个更现实的问题——怎么把事情真正做完。
过去的大模型,更像是一个聊天窗口。
你问,它答。
逻辑成立,但边界清晰。
而Qwen3.6-35B-A3B的变化更明显:
它开始从回答者,转向执行者。
30B 这个“黄金档位”已经卷成了红海。
GLM-4.7-Flash、Gemma-4-31B-it、Qwen3.6-35B-A3B。
同一个任务流,谁更抗造?谁能接住球?
下一篇,我们将进入真正的“华山论剑”:
谁才是 30B 档位新霸主?
欢迎大家持续关注我们,
告别文字搬运,拥抱硬核实测,
在这里,看见 AI 最真实的生产力边界~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 43
43 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)