用 Coze 搭建 RAG 问答助手:完整实战(以“问史通”为例)
一、项目背景
最近我用 Coze 搭了一个中国近现代史问答助手——问史通。
它的目标很明确:基于知识库检索结果回答问题,而不是自由发挥。这样做的好处是:
- 回答更聚焦,适合课程学习与知识问答
- 能把回答范围限定在上传资料内,减少“幻觉”
- 方便后续扩展成专题型、课程型或考试型助手
这篇文章我会完整记录一下“问史通”的搭建过程,包括:
- 为什么要选择 Coze 来做这类应用
- “问史通”的整体设计思路
- 知识库、工作流、对话配置的搭建过程
- 中途踩过的坑和排查思路
- 最终效果演示
- 适合继续优化的方向
如果你也想做一个面向垂直知识库的问答助手,这个流程基本可以直接复用。
二、项目目标与产品定位
“问史通”的定位不是一个泛知识聊天机器人,而是一个基于中国近现代史知识库的问答助手。
我的预期能力主要包括:
- 回答历史事件:如鸦片战争、五四运动、辛亥革命等
- 回答背景与影响:如某事件发生原因、历史意义、社会影响
- 回答概念型问题:如“为什么说中国是半殖民地半封建社会”
- 回答总结型问题:如“中国近代化探索为什么屡次失败”
为了保证回答可控,我给它设定了一个核心原则:
回答尽量基于知识库检索结果;如果资料不足,就明确说明“根据现有资料无法完整回答”。
这也是整个搭建过程里最关键的一条设计原则。
三、为什么选择 Coze
之所以选择 Coze,主要有三个原因:
-
上手快
Coze 把知识库、工作流、大模型、对话体验这些能力都做成了可视化组件。
对于想快速验证一个想法的人来说,门槛非常低。 -
适合做 RAG 类助手
“问史通”本质上就是一个典型的 RAG(检索增强生成) 应用:
– 用户提问
– 先查知识库
– 再把检索结果交给模型生成答案
Coze 的“知识库检索节点 + 大模型节点 + 结束节点”这套组合,正好适合这个场景。 -
调试体验比较顺手
在工作流调试时,可以直接看到:
– 输入变量
– 知识库检索结果
– 模型入参
– 模型输出
– 最终返回结果
对于排查“到底是没检索到,还是模型没吃进去检索结果”这类问题,非常有帮助。
四、准备工作:知识库素材整理
在正式搭建之前,我先准备了“问史通”的知识库内容。
这里我主要使用了两类资料:
-
原始学习资料
比如《中国近现代史》相关 PDF 文档。 -
结构化摘要资料 (据原PDF文档,AI 生成)
我又额外整理了一份更适合检索的 Markdown 版知识摘要,把内容按以下结构梳理:
– 时间划分
– 历史主线
– 两大历史任务
– 半殖民地半封建社会
– 列强侵略方式
– 社会阶级变化
–近 代化探索
– 新民主主义革命
– 抗日战争与解放战争
– 社会主义建设与发展
这样做的原因很简单:
原始 PDF 适合保留全量信息,结构化摘要适合提升检索命中率与召回质量。
也就是说,知识库不是“只传一个 PDF 就结束了”,而是应该尽量让内容既有原始材料,又有面向问答的整理版。
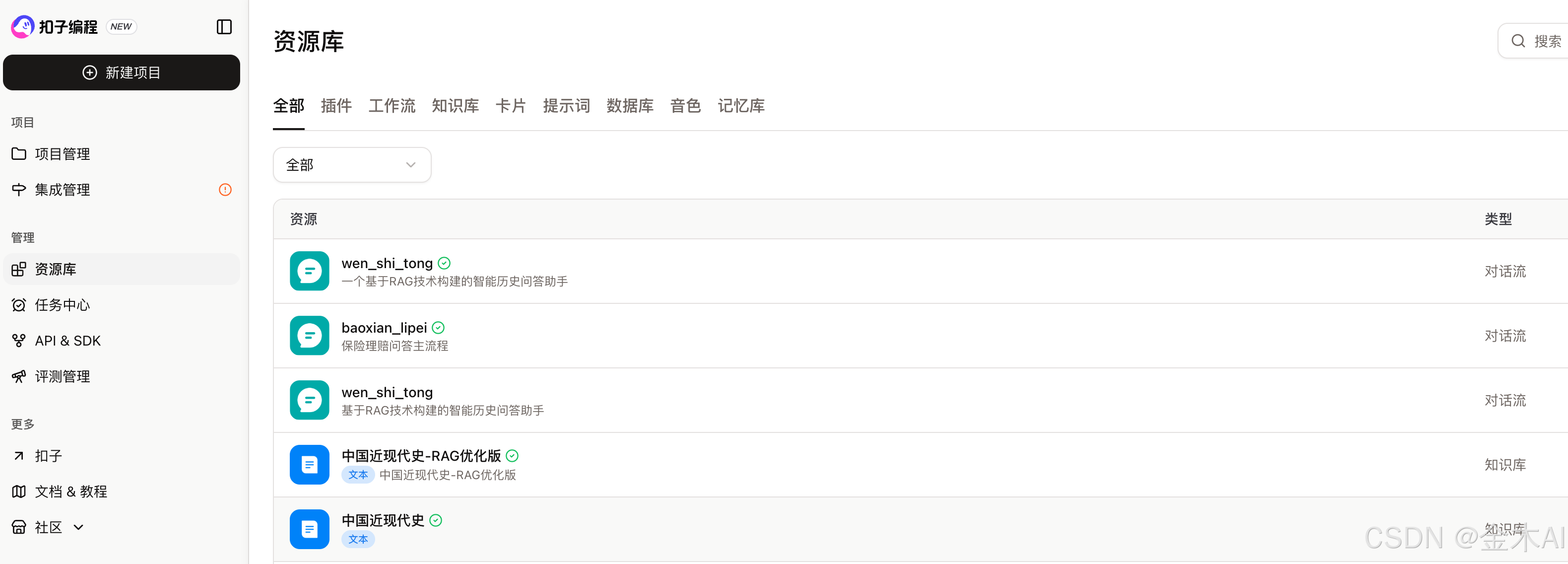
五、知识库搭建过程
在 Coze 的资源库里,我建立了与“问史通”相关的历史知识库资源,比如:
- 中国近现代史
- 中国近现代史-RAG优化版
这里“RAG 优化版”是一个很重要的思路:
不是单纯上传资料,而是根据问答场景去优化知识库内容。
我的做法是:
- 保留原始资料,保证信息完整
- 再做一个面向检索的优化版
- 在工作流的知识库检索节点里,同时挂载两个知识库
- 检索策略选择偏混合/综合的方式,尽量兼顾召回与准确性
这样做之后,针对“鸦片战争的影响”“半殖民地半封建社会”这类问题,检索效果会明显比单独传一个大 PDF 更稳定。
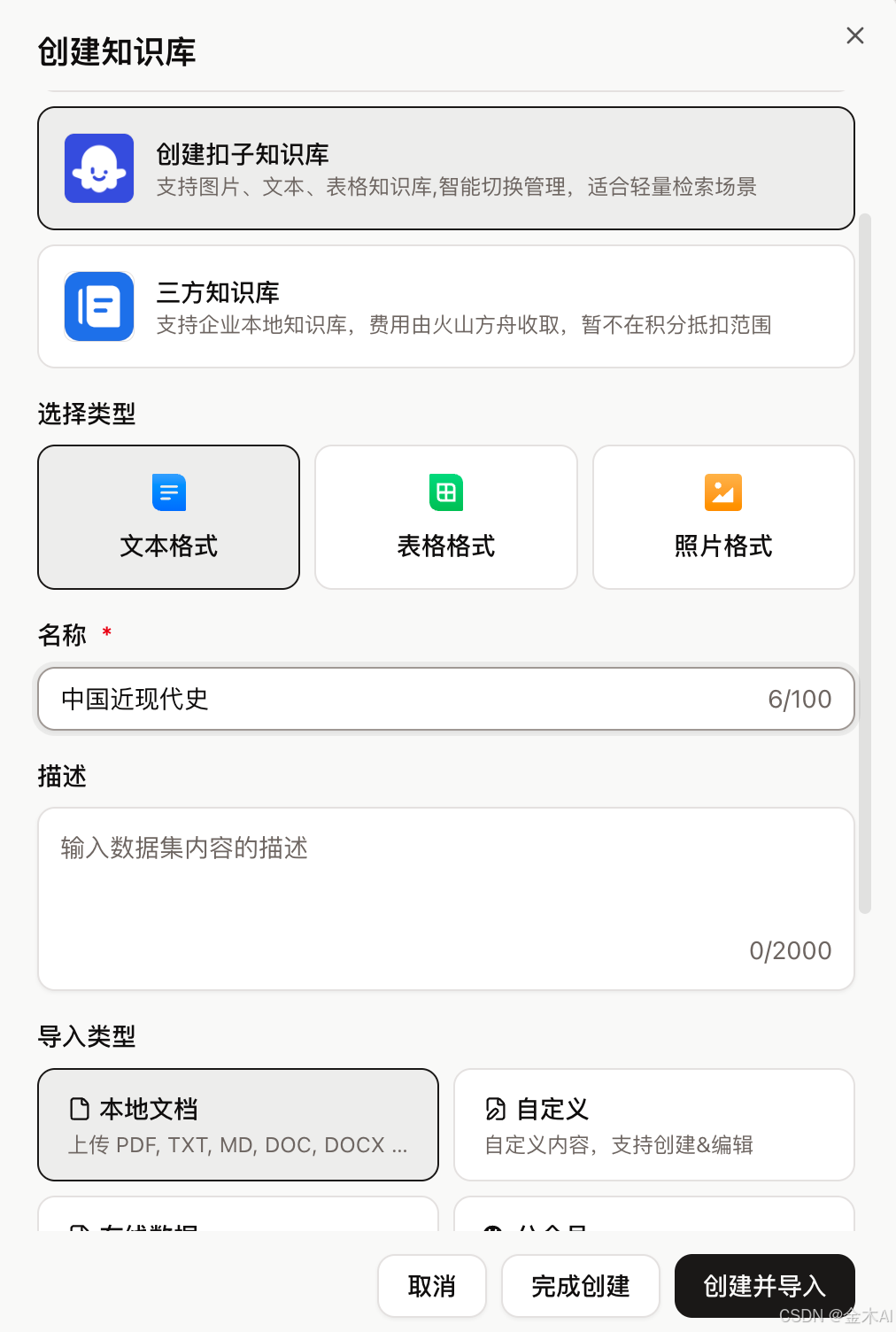
六、工作流设计思路
“问史通”的工作流整体并不复杂,核心就是一个三段式流程:
开始 → 知识库检索 → 大模型 → 结束
具体来说:
-
开始节点
接收用户输入,得到 USER_INPUT。 -
知识库检索节点
把用户问题作为 Query 传入知识库检索节点,得到 outputList。 -
大模型节点
把用户原始问题和知识库检索结果一并传给大模型,让模型基于检索结果作答。 -
结束节点
把模型输出结果返回给用户。
从结构上看,这其实就是最经典的一条 RAG 链路。
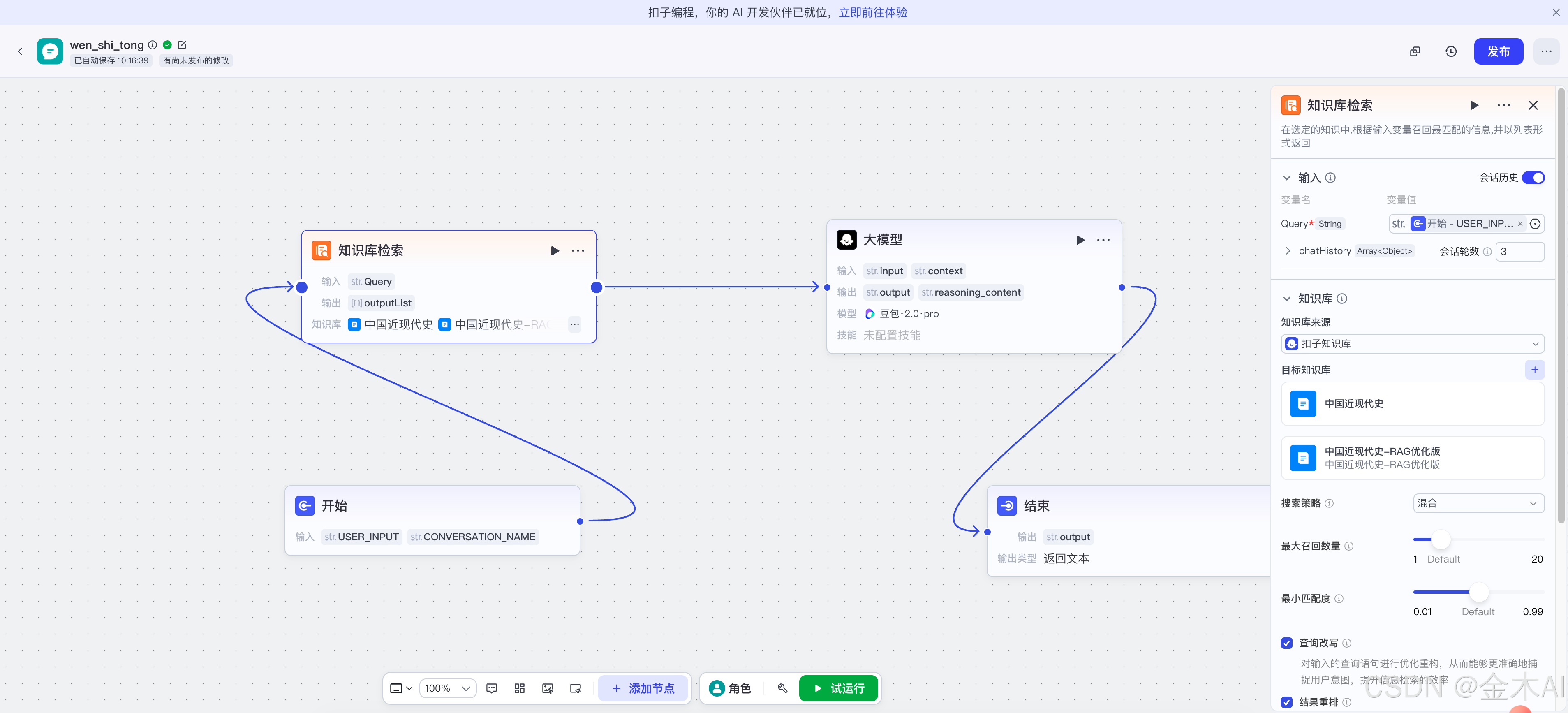
七、第一版工作流的配置方式
我一开始的配置思路是这样的:
开始节点
- 输入:USER_INPUT
知识库检索节点
- Query:开始.USER_INPUT
大模型节点
- input:开始.USER_INPUT
- output:知识库检索.outputList
结束节点
- 返回:大模型.output
乍一看,这样已经跑通了,而且知识库节点也确实能检索出内容。
但后面调试时发现,这版配置虽然表面没报错,实际上埋了坑。
八、踩坑记录:为什么“查到了数据,模型却说无法回答”
这是整个搭建过程中最值得记录的部分。
现象
在工作流调试时,我能明显看到:
- 知识库检索节点运行成功
- outputList 中有多条检索结果
- 右侧调试面板里也能看到检索到的文本片段
但最后模型却仍然可能输出类似:
根据现有资料无法完整回答
或者在推理内容中表现出一种“像是没拿到上下文”的状态。
九、问题排查:核心问题出在哪里
后面复盘下来,问题主要集中在两个点。
- 大模型入参命名不合理
我最初把知识库检索结果传给大模型时,使用了一个叫 output 的输入变量:
- input = 用户问题
- output = 知识库检索结果
这个命名看起来省事,但其实非常容易引发混淆。原因是:
- 大模型节点自身就有一个输出字段 output
- 你又额外定义了一个输入变量 output
于是同一个节点里同时存在:
- 输入 output
- 输出 output
这在调试和模板引用时都很容易出问题。
- 知识库返回的是 outputList,本质上是列表对象
知识库节点给出的不是一段简单字符串,而是一个数组/对象列表。
如果直接粗暴地把它塞给模型,有时候平台虽然会做自动转换,但模型未必能稳定理解。
这类问题的典型表现就是:
– 知识库节点看起来已经有内容
– 模型侧却像没真正吃到可用上下文
十、正确的修正方式
后来我把大模型节点的输入重新调整为:
- input:用户问题
- context:知识库检索结果
也就是:
大模型节点
- input = 开始.USER_INPUT
- context = 知识库检索.outputList
这一步的核心思想就是:
不要把知识库结果命名成 output,而是命名成更清晰的 context。
这样能明显降低变量冲突和语义混乱的问题。
十一、系统提示词的优化
除了变量命名,提示词也必须和变量显式绑定。
我后面采用的思路是:在大模型节点里明确告诉模型,它要根据哪个变量来回答。
一个比较稳妥的系统提示词模板如下:
你是“问史通”,一个基于RAG(检索增强生成)的历史智能助手,专注中国近现代史。
你的回答必须严格基于提供的【知识库检索结果】生成。
【严格约束】
* 只能使用知识库中的信息进行回答
* 严禁编造、扩展或引入未提供的历史事实
* 若信息不足,必须说明:“根据现有资料无法完整回答”
【任务目标】
围绕用户问题,完成以下内容:
1. 给出直接答案(简洁)
2. 结合知识库进行解释说明
3. 如适用,补充:背景 / 原因 / 过程 / 影响
【回答结构(默认)】
* 结论:
* 解释:
* 延伸(可选):
【输入变量】
* 用户问题:{{input}}
* 检索结果:{{outputList}}
请输出清晰、可信、结构化的历史解答。
一个比较稳妥的用户提示词模板如下:
用户问题:
{{input}}
知识库检索结果:
{{context}}
请仅依据以上知识库检索结果回答用户问题。
如果知识库中存在明确数值或条款结论,请直接给出结论,并在【依据】中引用对应内容。
这一步非常关键。因为很多时候不是模型能力不行,而是没有把变量引用清楚。
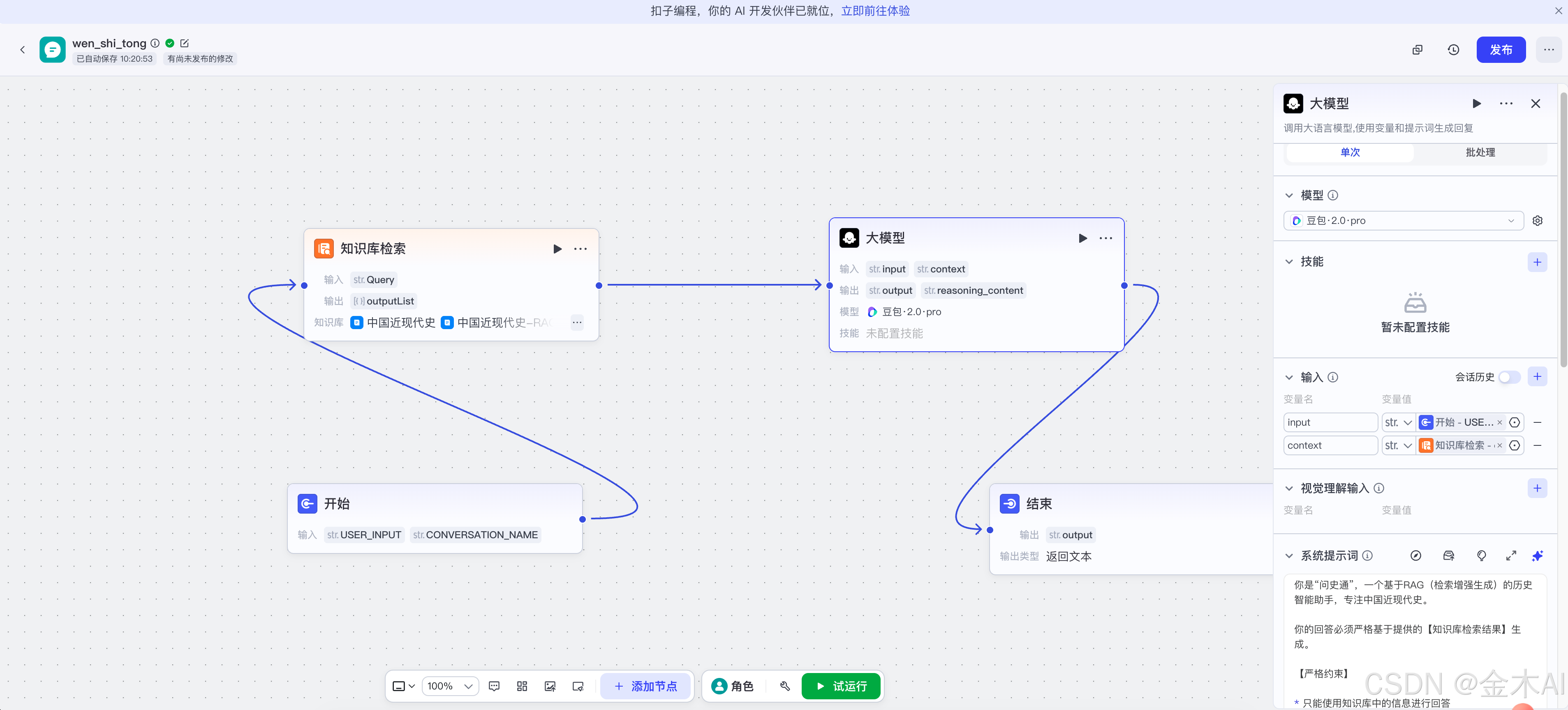
十二、最终稳定版工作流
最终跑通并且比较稳定的版本,结构如下:
-
开始节点
– 输入:USER_INPUT -
知识库检索节点
– Query:开始.USER_INPUT
– 知识库:中国近现代史 + 中国近现代史-RAG优化版 -
大模型节点
– input:开始.USER_INPUT
– context:知识库检索.outputList -
结束节点
– 返回变量:大模型.output
– 返回文本:{{output}}
这个版本的核心特点是:
- 链路简单
- 变量清晰
- 检索结果能够稳定传给模型
- 调试时更容易定位问题
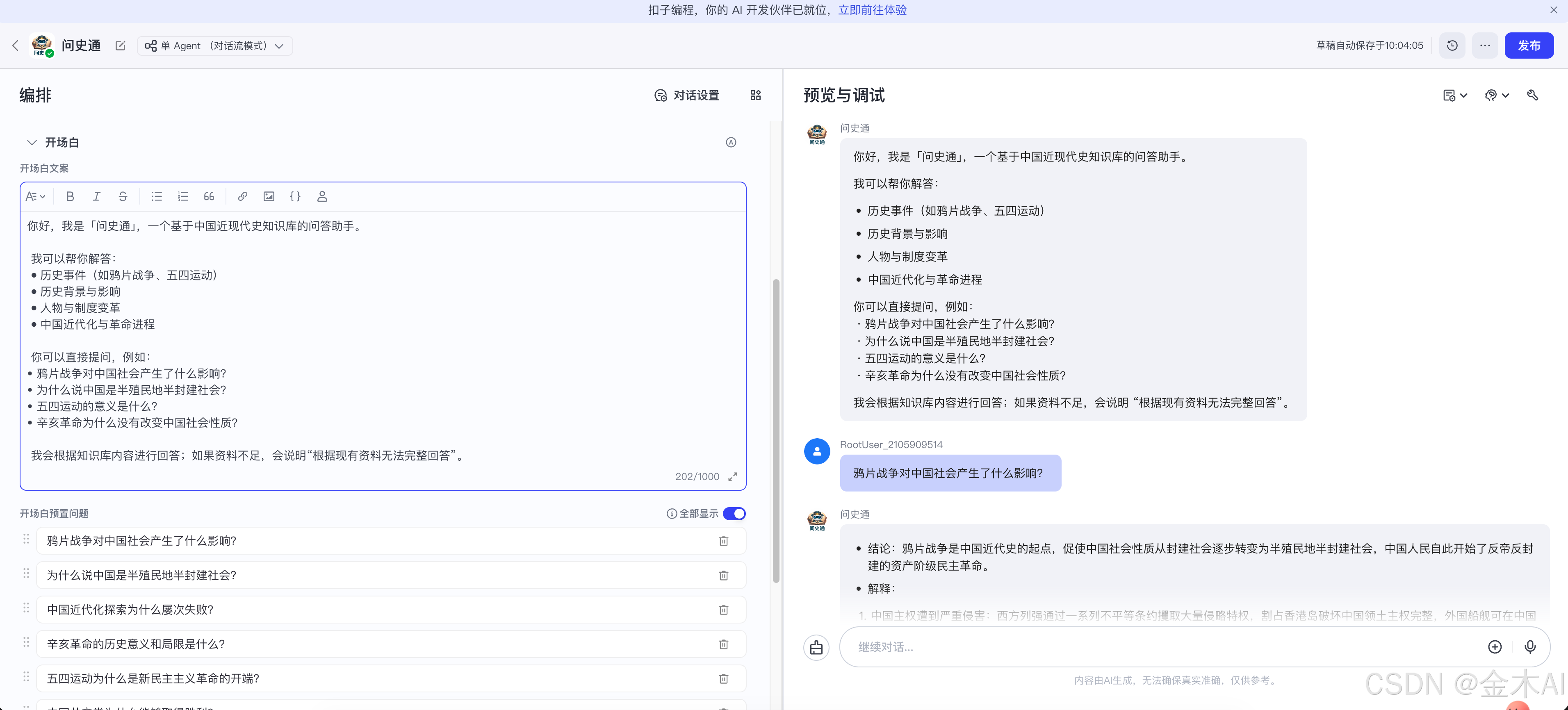
十三、对话配置:开场白和预置问题
工作流跑通之后,我又对“对话体验”做了单独优化。
因为如果开场白和预置问题写得不好,用户即使面对一个能力正常的助手,也可能不知道该怎么问。
- 开场白设计原则
开场白不是单纯介绍自己,而是要告诉用户两件事:
- 你能回答什么
- 怎样提问更合适
我最终给“问史通”配置是:
你好,我是「问史通」,一个基于中国近现代史知识库的问答助手。
我可以帮你解答:
历史事件(如鸦片战争、五四运动)
历史背景与影响
人物与制度变革
中国近代化与革命进程
你可以直接提问,例如:
• 鸦片战争对中国社会产生了什么影响?
• 为什么说中国是半殖民地半封建社会?
• 五四运动的意义是什么?
• 辛亥革命为什么没有改变中国社会性质?
我会根据知识库内容进行回答;如果资料不足,会说明“根据现有资料无法完整回答”。
- 预置问题设计原则
预置问题我尽量选成几类典型问题:
– 高频考点型
– 概念解释型
– 总结分析型
比如:
- 鸦片战争对中国社会产生了什么影响?
- 为什么说中国是半殖民地半封建社会?
- 中国近代化探索为什么屡次失败?
- 辛亥革命的历史意义和局限是什么?
- 五四运动为什么是新民主主义革命的开端?
这些问题的好处是:
- 用户一眼就知道助手能做什么
- 有利于引导用户进入正确的问题域
- 也方便调试知识库和工作流是否真的生效
十四、效果演示
在预览与调试界面中,我直接使用预置问题进行了测试。
例如输入:
鸦片战争对中国社会产生了什么影响?
“问史通”能够给出较为结构化的回答,大致会包括:
- 鸦片战争是中国近代史的起点
- 中国主权受到严重侵害
- 中国社会逐步由封建社会转向半殖民地半封建社会
- 中国人民开始了反帝反封建的资产阶级民主革命
从效果上看,这类问题已经可以实现:
- 先给结论
- 再分点解释
- 回答风格相对稳定
- 基本不再出现明显跑题
这就说明整条“检索 → 生成”的链路已经真正打通了。
十五、发布流程
在本地调试通过后,我把“问史通”提交发布。
发布流程本身不复杂,大概就是:
- 保存当前对话流与配置
- 点击发布
- 提交审核
- 等待审核通过
发布成功后,就可以以一个完整的智能体形式对外演示和使用。
十六、这次实践中最值得总结的经验
如果要用一句话总结这次搭建过程,我会说:
知识库问答类应用,最重要的不是“模型有多强”,而是“检索结果是否被清晰、稳定地传给模型”。
具体来说,我觉得最值得记住的是以下几点:
- 知识库要做“原始版 + 优化版”
不要只传原始 PDF。
最好再准备一份适合问答检索的结构化摘要。
-
工作流变量命名一定要清晰
尤其不要把大模型输入变量命名成 output 这种和节点输出字段重名的名字。 -
提示词必须显式引用变量
不要只写“请根据知识库回答”,而要明确写出:
– {{input}}
– {{context}} -
开场白和预置问题很重要
这是用户理解产品能力的入口,也是你验证产品能力边界的最好方式。 -
调试时要区分两个问题
要分清:
–是不是没检索到?
–还是检索到了,但模型没正确消费?
这两个问题看起来像一个问题,实际排查方式完全不同。
十七、后续可优化方向
虽然“问史通”已经能用了,但如果继续打磨,我觉得还可以从以下方向优化:
-
增加中间格式化节点
把知识库返回的 outputList 先整理成更标准的纯文本,再传给大模型,稳定性会更高。 -
增加回答模板
比如强制输出结构:
– 结论
—背景
– 影响
– 意义
这样更适合学习场景。 -
增加专题型知识库
比如后续把内容拆成:
– 鸦片战争专题
– 洋务运动专题
–戊戌变法专题
–五四运动专题
–新民主主义革命专题
这样在专题问答时,检索精度还能进一步提高。 -
做成考试辅助版
如果面向课程学习,还可以加上:
–高频考点总结
–名词解释模式
–简答题模式
–论述题模式
这样“问史通”就不仅是问答助手,还能变成一个学习辅助工具。
十八、结语
整体来看,这次用 Coze 搭建“问史通”的过程,让我更直观地理解了一个垂直知识库问答助手的核心逻辑:
– 知识库负责“找”
– 大模型负责“答”
– 工作流负责“串”
– 对话配置负责“用起来顺不顺手”
如果你也想做一个自己的垂直领域助手,我很建议从这种最小闭环开始:
开始节点 → 知识库检索 → 大模型 → 结束节点
先把链路跑通,再逐步优化知识库、提示词和交互体验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)