友猫社区源码解析:基于 WebSocket 的 IM 高并发架构拆解
社交系统里最容易被低估的模块是 IM。表面看只是聊天,实际牵扯连接管理、消息可靠性、在线状态、离线补偿、存储模型,一旦用户规模上来,问题会集中爆发。结合 友猫社区 的实现,直接拆核心架构和踩坑点。
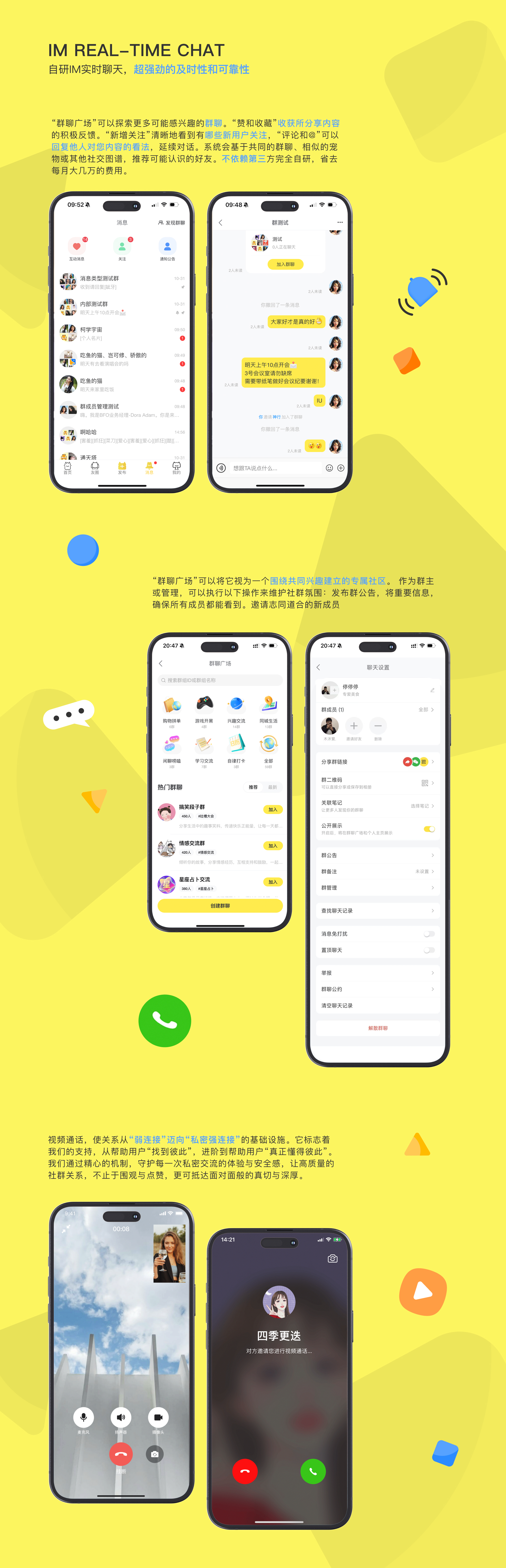
一、IM长连接设计:为什么必须上 WebSocket
传统 HTTP 轮询在低并发阶段还能凑合,一旦进入千级在线,服务器会被请求洪峰拖垮。友猫社区在 IM 模块里直接使用 WebSocket,核心原因只有一个:减少连接成本 + 实时性稳定
实际落地里,连接模型不是“一个用户一个连接”这么简单,而是:
- 用户ID → 多终端连接(APP / H5 / 小程序)
- 每个连接 → 唯一 session 标识
- session → 绑定心跳 + 最后活跃时间
服务端核心结构类似:
// 简化版连接管理
ConcurrentHashMap<Long, List<Session>> userSessions = new ConcurrentHashMap<>();
public void addSession(Long userId, Session session) {
userSessions.computeIfAbsent(userId, k -> new CopyOnWriteArrayList<>()).add(session);
}这里踩过一个坑:
如果用普通 List,在高并发读写下直接炸,必须用并发容器。
二、消息发送链路:从发送到落库的真实路径
用户发一条消息,不是简单“发出去就完事”,而是至少经过这几步:
- 客户端发送 WebSocket 消息
- 服务端解析协议(JSON / 自定义协议)
- 写入消息队列(解耦)
- 落库(消息持久化)
- 推送给接收方(在线直推 / 离线补偿)
关键点在第 3 步:必须引入异步机制
如果同步写库:
- 高并发直接拖慢发送接口
- 用户会感觉“消息卡顿”
一个常见实现:
// 伪代码:发送消息入队
public void sendMessage(Message msg) {
messageQueue.offer(msg); // 内存队列或MQ
}实际优化点:
- 队列要限流(防止内存打爆)
- 消息要带唯一ID(防重复)
三、离线消息机制:不是简单查数据库
友猫社区支持“离线消息 + 历史消息漫游”
很多实现会犯一个错误:
用户上线 → 查数据库 → 全量拉取
问题:
- 数据量大时直接慢查询
- 用户体验极差
更合理的方式是:
- 使用“最后拉取时间”或“最后消息ID”
- 增量拉取
SQL思路:
SELECT * FROM message
WHERE receiver_id = ?
AND msg_id > last_msg_id
ORDER BY msg_id ASC
LIMIT 100;踩坑点:
- 必须建立
(receiver_id, msg_id)索引 - 否则高并发直接拖垮数据库
四、在线状态同步:别用数据库做实时状态
很多初期项目会把在线状态写数据库:
- 登录 → update online=1
- 退出 → update online=0
问题:
- 高频写入数据库
- 状态不实时(异常断线无法更新)
友猫社区的做法更合理:内存 + 心跳机制
核心逻辑:
- 客户端每 30 秒发送心跳
- 服务端更新 lastActiveTime
- 定时任务扫描超时连接
// 心跳检测
if (currentTime - session.getLastActiveTime() > TIMEOUT) {
closeSession(session);
}这类设计能解决:
- 假在线问题
- 异常断网问题
五、群聊扩散策略:性能瓶颈的真正来源
群聊不是“for循环发消息”这么简单。
如果一个群 500 人:
for (User user : groupUsers) {
send(user, msg);
}问题:
- 单线程阻塞
- 推送耗时不可控
更合理方案:
- 批量拆分
- 异步线程池
- 分片推送
例如:
- 每批 50 人
- 多线程并发发送
隐藏坑:
- 线程池不能无限扩张
- 必须限流 + 队列长度控制

六、消息可靠性:防丢失 + 防重复
IM系统最怕两件事:
- 消息丢失
- 消息重复
友猫社区在协议层会带:
- messageId(唯一)
- timestamp(时间戳)
处理策略:
- 服务端去重(缓存最近消息ID)
- 客户端ACK确认机制
典型流程:
- 服务端发送消息
- 客户端返回 ACK
- 未ACK → 重试
如果不做:
- 网络抖动直接丢消息
- 用户投诉概率极高
七、内容安全与审核插入点
社交产品绕不开内容审核,友猫社区在后台支持内容审核、敏感词过滤等机制
IM层的处理方式不是“发完再审”,而是:
- 发送前拦截
- 发送后异步复检
常见策略:
- 文本:关键词过滤
- 图片:异步审核
- 视频:延迟处理
踩坑点:
- 审核接口阻塞会拖慢发送链路
- 必须异步化
八、缓存设计:IM系统的核心加速器
Redis 在这里的作用不是简单缓存,而是:
- 在线用户集合
- 最近消息缓存
- 未读计数
典型结构:
user:online→ Setmsg:recent:{userId}→ Listmsg:unread:{userId}→ Counter
如果全部走数据库:
- IO直接打满
- 延迟明显
九、架构演进经验:从单体到拆分
友猫社区底层是 Spring Boot + Redis + WebSocket 架构
实际演进路径通常是:
- 单体应用(快速上线)
- IM模块拆分独立服务
- 引入消息队列
- 多节点部署 + 连接路由
关键问题:
- WebSocket如何负载均衡?
解决方案:
- 用户ID取模路由
- 或通过网关层做连接分发
十、容易忽略的细节问题
这些问题上线后才会暴露:
- APP切后台,连接断开但未清理
- 网络切换(WiFi → 4G)导致重复连接
- 同一用户多设备消息同步问题
- 大群消息顺序错乱
处理思路:
- session唯一标识
- 消息按ID排序而不是时间
- 多端同步基于消息游标
十一、为什么很多IM系统做不起来
不是技术不会写,而是忽略了几个关键点:
- 没有异步队列,接口直接被拖死
- 在线状态依赖数据库,性能崩盘
- 群聊用循环发送,CPU飙升
- 没有ACK机制,消息丢失
这些问题在低用户量阶段完全看不出来,一旦放量直接暴露。
这套 IM 架构在社交系统里属于“基础设施级别”的存在,写得越简单,上线越容易出问题。友猫社区这类实现已经把核心链路跑通,但真正难的是后续的稳定性优化和极端场景处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)