2026山东大学软件学院项目实训-宠物情绪识别(三)
一、代码仓库与环境
1.在 Gitee 建好仓库
按照项目任务书要求,完成团队代码仓库的搭建与配置工作:
-
创建项目主仓库
-
建立分支规范:主分支+开发分支,明确分支用途与合并规则
-
完善仓库基础文件:
-
编写
README.md,说明项目介绍、运行步骤、分工说明 -
配置
.gitignore,过滤缓存文件、虚拟环境、日志等
-
-
将另外两位团队成员添加为仓库开发者,配置读写权限,保证三人都能正常拉取、提交、合并代码。
至此,团队统一代码仓库搭建完成,可支持多人协作开发,确保所有人都能正常拉取代码、搭建环境、运行项目,等待后端同学完成基础框架搭建。
二、拉取后端框架代码
后端负责人完成了 Flask基础框架搭建并提交到仓库。我及时拉取最新代码到本地,检查目录结构、路由配置、接口返回格式等内容,确认后端框架可正常启动、接口可访问。
再打开项目文件已经有后端框架:
拉取代码后,我本地运行后端服务,测试基础路由,确保后端服务稳定可用,为后续音频模块、大模型接口模块与后端对接做好准备。
三、连接到项目云数据库
前一周团队已完成云数据库(腾讯云 MySQL)的申请与基础表搭建。本周我首先完成个人开发环境与云数据库的连接配置:
- 在MySQL Workbench中新建连接
- 填写云数据库主机、端口、用户名、密码
- 测试连接,确保成功连接到远程数据库
- 查看已建好的数据表结构,理解表与表之间的关系
连接成功后,我可以正常查看、操作数据库,为后续音频信息存储、情绪识别结果存储、数据查询等功能开发做好数据层准备。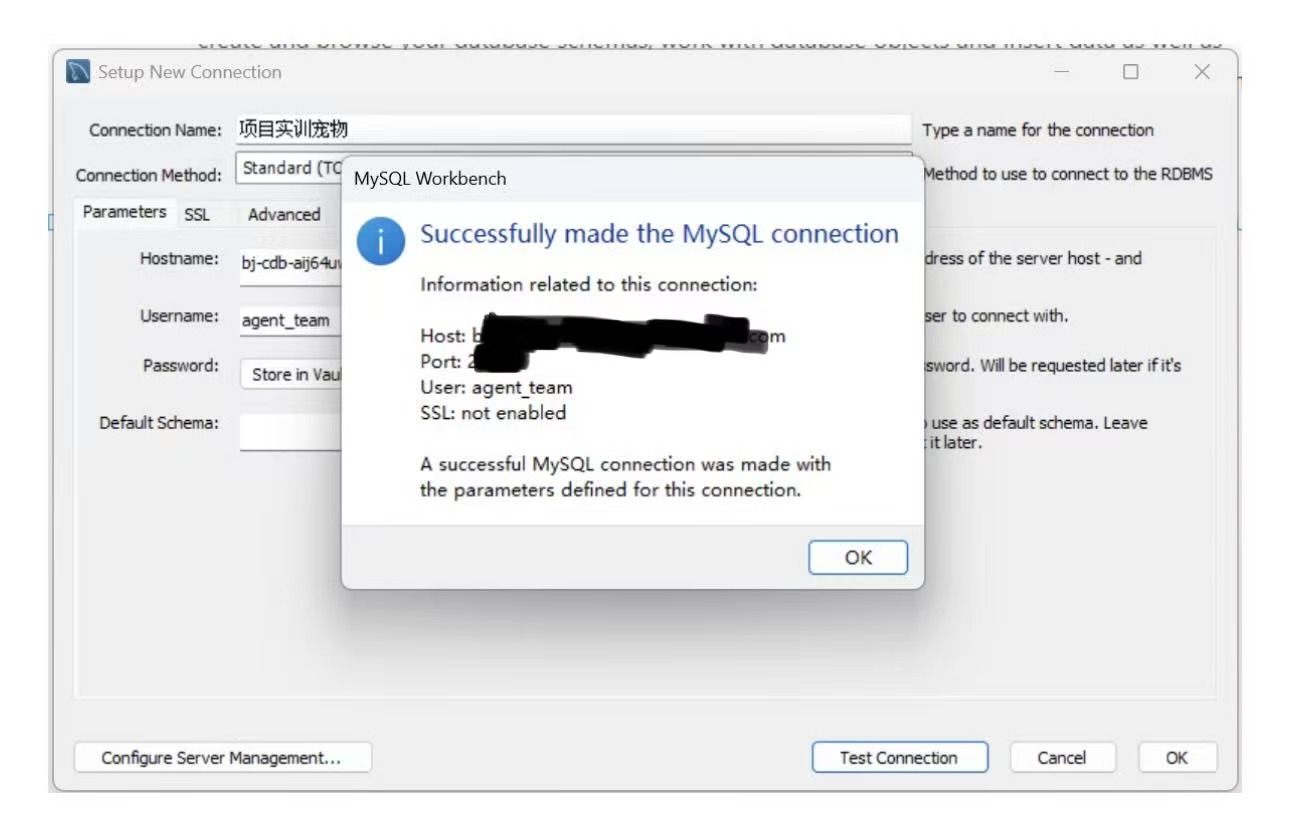
四、音频识别模块准备与 Librosa 工具类封装
本周我继续推进音频模块的开发准备工作:
-
完成音频特征提取库Librosa的环境安装与测试
-
封装音频特征提取函数,统一处理逻辑:
-
固定采样率16000Hz
-
限制音频最长10秒
-
提取 MFCC、能量、过零率、频谱质心四大特征
-
-
对不同格式(MP3/WAV)音频做兼容处理
-
添加异常捕获,避免文件损坏、格式不支持导致程序崩溃
代码:
# backend/utils/audio_feature_extractor.py
import librosa
import numpy as np
class AudioFeatureExtractor:
def __init__(self, sr=16000, max_duration=10):
"""
初始化音频特征提取器
:param sr: 统一采样率
:param max_duration: 最长处理时长(秒)
"""
self.sr = sr
self.max_duration = max_duration
def extract_features(self, audio_path):
"""
提取宠物音频的核心声学特征
:param audio_path: 音频文件路径(wav/mp3)
:return: 结构化特征文本(给大模型用)
"""
try:
# 1. 加载音频并标准化
y, sr = librosa.load(audio_path, sr=self.sr, duration=self.max_duration)
duration = librosa.get_duration(y=y, sr=sr)
# 2. 提取核心特征
# MFCC梅尔频率倒谱系数(最核心的音色特征)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
mfcc_mean = np.mean(mfcc.T, axis=0)
# 能量均值(反映响度)
rms = librosa.feature.rms(y=y)
energy_mean = np.mean(rms)
# 过零率(反映频率变化,焦虑/痛苦时更高)
zcr = librosa.feature.zero_crossing_rate(y)
zcr_mean = np.mean(zcr)
# 频谱质心(反映声音尖锐程度)
spectral_centroid = librosa.feature.spectral_centroid(y=y, sr=sr)
centroid_mean = np.mean(spectral_centroid)
# 3. 生成结构化特征文本
feature_desc = f"""
宠物音频声学特征(采样率{sr}Hz,时长{duration:.1f}秒):
- MFCC前5维均值:{[round(x, 4) for x in mfcc_mean[:5]]}
- 能量均值:{round(energy_mean, 4)}
- 过零率均值:{round(zcr_mean, 4)}
- 频谱质心均值:{round(centroid_mean, 2)}
"""
return feature_desc.strip()
except Exception as e:
raise RuntimeError(f"音频特征提取失败:{str(e)}")
# 测试用例
if __name__ == "__main__":
extractor = AudioFeatureExtractor()
test_audio = "test_cat.wav"
features = extractor.extract_features(test_audio)
print("特征提取结果:")
print(features)完成特征提取工具类后,本地多次测试,确保特征输出稳定、格式统一,可直接传入大模型进行情绪分析。
五、大模型情绪分析工具类封装
为实现宠物情绪分析与健康评估,我完成大模型接口封装:
-
已经确定使用通义千问qwen-turbo作为项目大模型
-
完成API Key配置与鉴权测试
-
优化Prompt模板,严格限定输出为标准JSON格式,包含:
-
情绪类型(兴奋 / 焦虑 / 痛苦 / 应激)
-
置信度
-
分析依据
-
-
封装调用函数,添加异常捕获、超时处理、JSON 解析容错
-
本地多次调用测试,确保接口稳定、返回格式正确
代码:
# backend/utils/qwen_emotion_analyzer.py
import json
import dashscope
from dashscope import Generation
from config import Config
dashscope.api_key = Config.DASHSCOPE_API_KEY
class PetEmotionAnalyzer:
def __init__(self, model="qwen-turbo"):
"""
初始化情绪分析器
:param model: 使用的通义千问模型
"""
self.model = model
self.prompt_template = """
你是专业的宠物行为与健康分析专家。
下面是一段宠物(猫/狗)音频的声学特征数据:
{features}
请你基于这些特征,严格按照以下要求分析宠物的情绪状态:
1. 必须从【兴奋、焦虑、痛苦、应激】4类中选择1个最符合的情绪
2. 给出情绪置信度(0-1之间的小数,越接近1越确定)
3. 用100字以内的文字,结合特征说明分析依据
4. 必须用标准JSON格式返回,格式如下:
{{
"emotion": "情绪类型",
"confidence": 置信度,
"analysis": "分析依据"
}}
禁止输出任何额外内容,只返回JSON。
""".strip()
def analyze(self, audio_features):
"""
基于音频特征分析宠物情绪
:param audio_features: 音频特征文本(来自AudioFeatureExtractor)
:return: 解析后的情绪结果字典
"""
prompt = self.prompt_template.format(features=audio_features)
try:
# 调用通义千问API
response = Generation.call(
model=self.model,
messages=[{"role": "user", "content": prompt}],
result_format="message"
)
if response.status_code != 200:
raise RuntimeError(f"API调用失败:{response.message}")
# 解析返回结果
content = response.output.choices[0]["message"]["content"]
result = json.loads(content)
# 校验结果格式
required_keys = ["emotion", "confidence", "analysis"]
for key in required_keys:
if key not in result:
raise ValueError(f"返回结果缺少字段:{key}")
return result
except json.JSONDecodeError:
raise RuntimeError("模型返回非标准JSON格式")
except Exception as e:
raise RuntimeError(f"情绪分析失败:{str(e)}")
# 测试用例
if __name__ == "__main__":
# 测试用的特征文本
test_features = """
宠物音频声学特征(采样率16000Hz,时长5.2秒):
- MFCC前5维均值:[-120.34, 15.23, -5.67, 8.91, -3.45]
- 能量均值:0.045
- 过零率均值:0.12
- 频谱质心均值:2500.5
"""
analyzer = PetEmotionAnalyzer()
result = analyzer.analyze(test_features)
print("情绪分析结果:")
print(json.dumps(result, indent=2, ensure_ascii=False))本周已实现:音频特征 → 大模型 → 情绪结果 全流程可稳定运行。
之后添加了依赖,保证团队成员安装后能顺利运行:
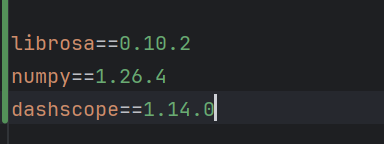
六、下周工作计划
-
完成音频识别模块与后端 Flask 框架的整合,将已封装好的音频特征提取工具类、大模型情绪分析工具类接入项目主流程。
-
开发音频上传接口,实现音频文件接收、临时存储、特征提取、情绪分析的完整业务逻辑。
-
完成接口封装与路由注册,实现标准化接口返回格式,确保与前端、数据库模块正常对接。
-
进行接口单元测试,验证接口功能正确性、稳定性与异常处理能力。
-
配合团队完成前后端联调,为Demo演示与功能测试做好准备。
七、本周总结
本周我按照项目整体进度安排,顺利完成了开发环境统一、云数据库连接、核心工具类封装等多项关键任务。成功搭建并配置团队代码仓库,确保团队协作开发规范统一;拉取并验证后端基础框架,完成云数据库连接与表结构确认,为后续数据存储与查询功能奠定基础。
在功能开发方面,我独立完成了音频特征提取工具类与大模型情绪分析工具类的封装与调试,实现了从音频文件到声学特征提取、再到通义千问大模型情绪分析的全流程能力。两个工具类均实现独立运行、结构清晰、异常处理完善,可直接接入后端接口使用。同时完成依赖配置与环境验证,确保团队成员可快速搭建环境并运行项目。
本周解决了音频库依赖、模型调用格式、返回结果解析、路径与导入等多项问题,模块功能稳定、输出规范,已完全满足下一阶段接口开发与系统集成的需求。整体进度符合计划,代码质量与模块设计达到预期,下周将继续推进接口开发与功能联调工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)