辣椒酱购买决策分析——逻辑回归
逻辑回归分类案例
3.2.2 逻辑回归应用举例
例3-1 辣椒酱购买决策分析
一、题目描述
某超市为了分析顾客是否要购买新引进的辣椒酱,以辣椒酱的辣度 x1x_1x1 与保质期 x2x_2x2 两个因素对购买决定的影响为研究主题,随机对24名顾客开展调查。
利用调查数据构建逻辑回归二分类模型,并判断新辣椒酱参数 x1=3,x2=7x_1=3,x_2=7x1=3,x2=7 时,顾客是否会选择购买。
二、原始数据集
表3-4 顾客是否购买辣椒酱数据集
| 顾客 | x1x_1x1(辣度) | x2x_2x2(保质期) | yyy(是否购买) | 顾客 | x1x_1x1(辣度) | x2x_2x2(保质期) | yyy(是否购买) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 13 | 3 | 5 | 1 |
| 2 | 3 | 4 | 1 | 14 | 2 | 4 | 1 |
| 3 | 6 | 5 | 1 | 15 | 5 | 6 | 1 |
| 4 | 4 | 4 | 1 | 16 | 3 | 6 | 1 |
| 5 | 3 | 2 | 1 | 17 | 3 | 3 | 1 |
| 6 | 4 | 7 | 1 | 18 | 4 | 5 | 1 |
| 7 | 5 | 4 | 0 | 19 | 4 | 2 | 0 |
| 8 | 4 | 3 | 0 | 20 | 5 | 5 | 0 |
| 9 | 7 | 5 | 0 | 21 | 6 | 7 | 0 |
| 10 | 3 | 3 | 0 | 22 | 5 | 3 | 0 |
| 11 | 4 | 4 | 0 | 23 | 6 | 4 | 0 |
| 12 | 5 | 2 | 0 | 24 | 6 | 6 | 0 |
说明:
y=1y=1y=1 代表顾客购买辣椒酱;
y=0y=0y=0 代表顾客不购买辣椒酱;
1~12号为训练集,13~24号为测试集。
三、算法原理讲解
本题为二分类问题,选用逻辑回归算法。
逻辑回归依托 Sigmoid 函数,将线性组合结果映射为 0~1 之间的概率值。
模型公式:
f(x)=11+e−(w1x1+w2x2+b) f(x) = \frac{1}{1+e^{-(w_1x_1 + w_2x_2 + b)}} f(x)=1+e−(w1x1+w2x2+b)1
- w1、w2w_1、w_2w1、w2:特征权重,代表辣度、保质期对购买行为的影响大小
- bbb:模型截距项
- 分类规则:
预测概率 ≥0.5\ge 0.5≥0.5 → 判定为正类 y=1y=1y=1(购买)
预测概率 <0.5< 0.5<0.5 → 判定为负类 y=0y=0y=0(不购买)
四、解题实现
# 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# 1. 划分训练集、测试集
# 训练集:1~12号顾客
X_train = np.array([
[2,3],[3,4],[6,5],[4,4],[3,2],[4,7],
[5,4],[4,3],[7,5],[3,3],[4,4],[5,2]
])
y_train = np.array([1,1,1,1,1,1,0,0,0,0,0,0])
# 测试集:13~24号顾客
X_test = np.array([
[3,5],[2,4],[5,6],[3,6],[3,3],[4,5],
[4,2],[5,5],[6,7],[5,3],[6,4],[6,6]
])
y_test = np.array([1,1,1,1,1,1,0,0,0,0,0,0])
# 2. 构建并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 3. 输出模型参数
w1, w2 = model.coef_[0][0], model.coef_[0][1]
b = model.intercept_[0]
print("—————————— 模型参数 ——————————")
print(f"权重 w1(辣度) = {w1:.6f}")
print(f"权重 w2(保质期) = {w2:.6f}")
print(f"截距 b = {b:.6f}")
print(f"逻辑回归模型:y = 1/(1+exp^(-({w1:.6f}x1+{w2:.6f}x2+{b:.6f})))")
# 4. 模型准确率评估
acc = model.score(X_test, y_test)
print("\n—————————— 模型评估 ——————————")
print(f"测试集预测准确率:{acc:.2f}")
# 5. 新样本预测 x1=3 , x2=7
new_data = np.array([[3, 7]])
pre = model.predict(new_data)[0]
pre_prob = model.predict_proba(new_data)[0][1]
print("\n—————————— 新样本预测 ——————————")
print(f"输入:辣度=3,保质期=7")
print(f"预测标签:{pre}")
print(f"购买概率:{pre_prob:.4f}")
print(f"最终结论:{'顾客会购买辣椒酱' if pre==1 else '顾客不会购买辣椒酱'}")
# 6. 数据可视化 + 决策边界绘制
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 生成网格区域
x1_min, x1_max = X_train[:,0].min()-1, X_train[:,0].max()+1
x2_min, x2_max = X_train[:,1].min()-1, X_train[:,1].max()+1
xx, yy = np.meshgrid(np.linspace(x1_min,x1_max,100),
np.linspace(x2_min,x2_max,100))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制分类区域
plt.contourf(xx, yy, Z, alpha=0.3, cmap="coolwarm")
# 绘制训练集数据点
plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1],
c="red", s=70, label="训练集-购买", edgecolors="k")
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1],
c="blue", s=70, label="训练集-不购买", edgecolors="k")
# 绘制新样本
plt.scatter(3, 7, c="gold", marker="*", s=400,
label="待预测新样本(3,7)", edgecolors="black")
plt.xlabel("辣度 x1")
plt.ylabel("保质期 x2")
plt.title("辣椒酱购买决策 逻辑回归分类结果")
plt.legend()
plt.grid(alpha=0.25)
plt.show()
五、运行结果与详细讲解
1. 模型参数
权重w1(辣度)=−0.711955 权重 w1(辣度) = -0.711955 权重w1(辣度)=−0.711955
权重w2(保质期)=0.623597 权重 w2(保质期) = 0.623597 权重w2(保质期)=0.623597
截距b=0.591984截距 b = 0.591984截距b=0.591984
逻辑回归模型:f(x)=11+e−(−0.711955x1+0.623597x2+0.591984)逻辑回归模型: f(x) = \frac{1}{1+e^{-(-0.711955x1+0.623597x2+0.591984)}}逻辑回归模型:f(x)=1+e−(−0.711955x1+0.623597x2+0.591984)1
2.结果分析
- 辣度权重为负数:辣度越高,顾客购买意愿越低;
- 保质期权重为正数:保质期越长,顾客购买意愿越高;
- 测试集准确率:0.75小样本条件下,模型分类效果良好,具备实际预测能力。
3. 新样本结论
- 输入条件:辣度 x1=3x1=3x1=3,保质期x2=7 x2=7x2=7
- 预测标签:111
- 最终判定:顾客会购买该款新辣椒酱
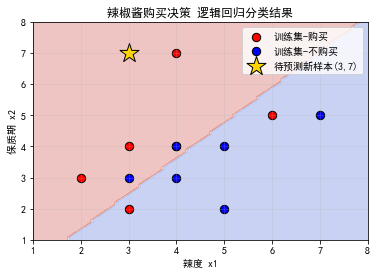
六、图像分析
- 背景深浅分区:代表逻辑回归的决策边界,划分购买 / 不购买两大区域;
- 红色点:历史购买顾客数据;蓝色点:历史不购买顾客数据;
- 金色星号:本次需要判断的新样本,落在红色购买区域,与计算结果一致。
七、知识点总结
- 逻辑回归多用于二分类任务,不用于连续值预测;
- 利用训练集拟合模型,测试集检验模型泛化能力;
- 依靠特征权重,可以直观分析各因素对结果的影响方向;
- 结合决策边界绘图,可直观理解算法分类逻辑。
- 回归VS分类回归VS分类回归VS分类

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)