LeWorldModel: Stable End-to-End Joint-EmbeddingPredictive Architecture from Pixels
Abstract
联合嵌入预测架构 (JEPA) 为在紧凑的潜在空间中学习世界模型提供了一个引人注目的框架,但现有方法仍然脆弱,依赖于复杂的多项损失、指数移动平均、预训练编码器或辅助监督来避免表征崩溃。本文提出了 LeWorldModel (LeWM),这是第一个仅使用两个损失项即可从原始像素稳定地进行端到端训练的 JEPA:一个用于预测下一嵌入的损失和一个用于强制潜在嵌入服从高斯分布的正则化项。与目前唯一的端到端替代方案相比,LeWM 将可调损失超参数从六个减少到一个。LeWM 可以在单个 GPU 上训练 1500 万个参数,只需几个小时即可完成训练,其规划速度比基于基础模型的世界模型快 48 倍,并且在各种 2D 和 3D 控制任务中保持竞争力。除了控制任务之外,我们还通过探测物理量证明了 LeWM 的潜在空间编码了有意义的物理结构。意外评估证实,该模型能够可靠地检测出物理上不合理的事件。
1 Introduction
人工智能的一个核心目标,是开发能够在多种任务和环境中获取技能的智能体,并通过一种统一的学习范式实现这一目标——该范式能够直接从环境的感知输入中进行学习,而无需依赖人工设计的状态表示或特定领域的校准。视觉在这一目标中尤为适合:摄像头成本低、易于扩展,而基于像素的学习使得从原始感知输入到动作输出的端到端训练成为可能。世界模型(World Models, WMs)是一类强大的方法,它通过学习预测在环境中采取动作所带来的结果来发挥作用。当世界模型足够有效时,智能体可以仅依赖其对世界的内部建模,在“想象空间”中进行规划和自我提升。这一点在离线场景中尤为重要,因为智能体必须从固定的数据集中学习,无法与环境进行交互,此时可以利用模型生成的合成经验,并对反事实的动作序列进行评估。
当前主流的世界模型学习方法是联合嵌入预测架构(JEPA)[5]。该方法不试图对环境的每个维度进行建模,而是专注于捕捉预测未来状态所需的最关键特征。具体而言, JEPA 通过将观测数据编码至紧凑的低维潜在空间,并通过预测未来观测数据的潜在表征来建模时序动态关系。
然而,尽管现有 JEPA 方法在概念上看似简单,却极易陷入崩溃困境。在这种故障模式下,模型会将所有输入映射为几乎完全相同的表征,仅为满足时间预测目标而产生平庸表现,最终导致表征结果无法使用。因此,防止模型崩溃成为训练 JEPA 模型的核心挑战之一。许多具有影响力的研究提出了应对方案,但这些方法通常依赖启发式正则化、多目标损失函数、外部信息源或预训练编码器等架构简化手段。实际应用中,这些策略往往会导致额外的不稳定性,或显著增加训练复杂度。
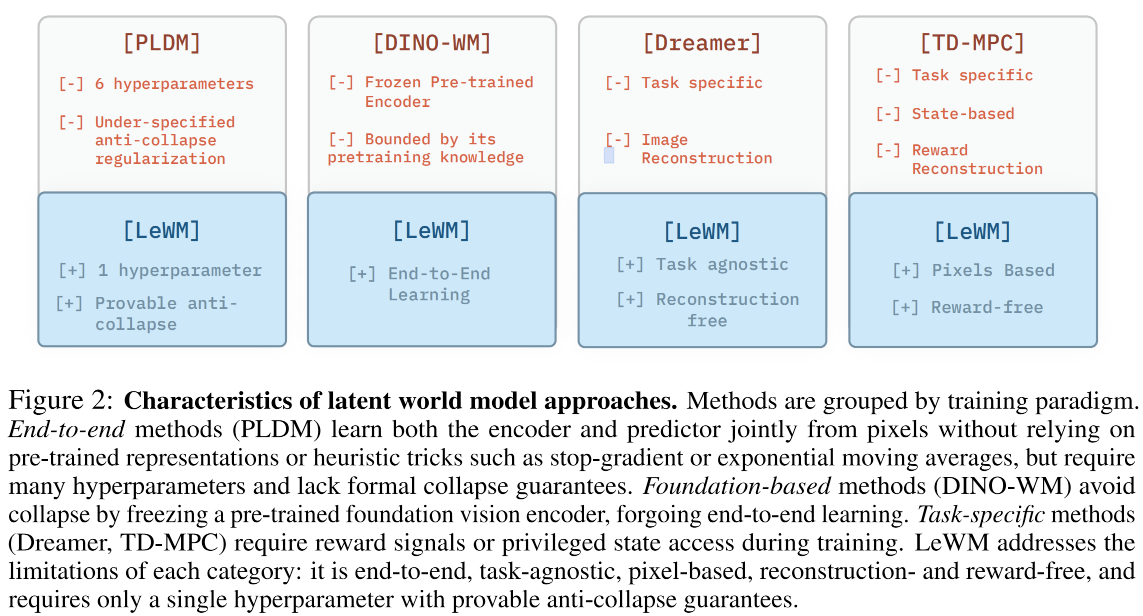
为克服这些局限性,我们提出LeWorldModel(LeWM)——首个无需启发式方法、基于原理且简洁的从原始像素端到端学习稳定 JEPA 的方法(参见图2)。此外,LeWM可在单个GPU上完成训练,显著降低了研究门槛。我们在二维和三维环境中对LeWM在多种操作、导航及运动任务中的表现进行了评估。同时,通过目标探测和潜在空间中的惊喜量化评估,深入探究了其直观的物理理解机制。总体而言,我们的核心发现与贡献包括:
- 我们提出了一种端到端 JEPA 方法,可在单个GPU上通过原始像素数据学习潜在世界模型。该方法采用简单稳定的双项目标函数,该函数在不同架构和超参数选择下均保持稳健性,同时支持对数时间复杂度的超参数搜索。
- LeWM凭借紧凑的1500万参数模型,在多种二维和三维任务中展现出卓越的控制性能,超越现有基于 JEPA 的端到端方法,同时以显著更低的成本与基于基础模型的世界模型保持竞争力,使规划速度提升高达48倍。
- 我们通过探测物理量及采用期望值违反检验来评估潜在空间中的物理理解能力,以检测非物理轨迹。
2 Related Work
世界模型旨在通过数据学习环境动态的预测模型,使智能体能够对未来状态进行想象性推理。其中一类典型的世界模型采用生成式方法,通过像素空间显式建模环境动态。这类基于动作条件的生成模型通过生成基于历史状态和动作的未来观测结果,充当学习型模拟器。生成式世界模型已成功应用于现有类游戏环境的模拟,例如IRIS[3]、Diamond[6]、∆-IRIS[7]、Oasis[8]和DreamerV4[4]等模型成功模拟了《我的世界》《反恐精英》和《造物者》等游戏环境,显著提升了强化学习中的策略采样效率。其他方法则开发了全新的交互式模拟器,如Genie[9]和HunyuanWorld[10],而学习型模拟器亦被应用于机器人策略评估[11]。值得注意的是,多数生成式世界模型需要依赖包含奖励信号的数据集,从而实现动力学特征与价值相关信息的联合建模,为后续强化学习提供基础。与之形成对比的是,本研究聚焦于无奖励场景——这与 JEPA 研究路线中采用的框架一致,其核心目标是从观测数据中学习通用且任务无关的世界模型,无需依赖奖励监督机制。
JEPA 是一个用于学习世界模型的框架,其核心思想是在紧凑的低维潜空间中对系统的动态演化进行预测。自 LeCun [5] 提出以来,JEPA 方法已有了显著发展,主要区别在于其目标任务以及用于学习非坍缩表示的策略。其中一条重要的研究方向是将 JEPA 应用于自监督表示学习,通过预测掩蔽输入块的潜嵌入来实现,代表性工作包括面向图像的 I-JEPA [12]、面向视频的 V-JEPA [13, 14],以及面向医学数据的 Echo-JEPA 和 Brain-JEPA [15, 16]。这些方法通常采用目标编码器的指数移动平均(EMA)并结合梯度停止(SG)技术,以稳定训练过程并防止表示坍缩。然而,目前对 EMA 和 SG 的理论认识仍较为有限,因为它们通常并不对应一个定义良好的目标函数的最小化过程 [17]。
另一条研究方向则将 JEPA 的思路用于基于动作的潜空间世界建模。部分方法依赖预训练编码器来获取表示 [14, 18–20],虽然避免了坍缩问题,但将表示的表达能力限制在了所使用的预训练编码器之内。相比之下,PLDM [21, 22] 采用 VICReg [23] 并结合额外的正则化项,以端到端的方式学习表示,但其代价是存在已知的训练不稳定性和可扩展性限制 [24]。有若干工作通过引入辅助信号或架构组件(如本体感觉输入或动作解码器)进一步提升了稳定性 [18, 19]。在本工作中,我们提出了一种稳定的端到端 JEPA 训练方法,该方法直接从原始像素出发,使用一个简单的两项损失函数:一项是面向未来嵌入的预测目标,另一项是用于强制嵌入服从高斯分布的正则化目标 [25]。
基于潜动态的规划。世界模型 [26] 开创了直接从高维观测数据的紧凑潜表示中学习策略的方法。一些工作利用学习到的潜动态模型,通过强化学习来训练策略 [27–29, 4]。在这些方法中,生成式世界模型充当一个模拟器,在其中通过想象来展开轨迹,使得策略优化主要在潜空间的想象中完成。训练完成后,策略可直接执行,而世界模型在测试时不再需要。
近期的部分工作则采用模型预测控制(MPC),在测试时直接在潜空间中进行规划 [30–33, 18, 22]。与基于想象力的策略学习不同,这些方法在线使用世界模型来预测候选动作序列的结果,并在执行过程中迭代优化这些序列。因此,该模型在运行时仍作为控制环路的一部分,虽然能够实现适应性决策,但也增加了计算需求。
3 Method: LeWorldModel
本节将介绍LeWorldModel(LeWM)。首先阐述基于离线数据学习潜在世界模型的优化训练流程,涵盖数据集、模型架构及训练目标等核心要素;随后详细说明如何通过模型预测控制(MPC)技术,利用所学模型进行潜在规划以辅助决策制定。
3.1 Learning the Latent World Model
离线数据集(Offline Dataset)。我们考虑的是一种完全离线且无奖励的设定。LeWorldModel 仅利用未标注的观测—动作轨迹数据进行训练,不使用任何奖励信号,也不依赖任务说明。这样的设定与 JEPA 系列工作一致 [18, 14],其目标是从观测数据中学习通用的、与具体任务无关的世界模型。我们的目标不是针对某一个特定任务优化行为,而是学习能够表征环境动态的表示,并使其后续能够被控制或适配到多种不同任务中。


- 编码器回答:“现在是什么状态?”
- 预测器回答:“如果现在做这个动作,下一步会变成什么状态?”
编码器采用 Vision Transformer(ViT) [34] 来实现。除非另有说明,我们使用的是 tiny 配置(约 5M 参数),其设置为:patch size 为 14、12 层、3 个注意力头、隐藏维度为 192。观测嵌入 zt 由最后一层的 [CLS] token嵌入构成,并在此之后再经过一个投影步骤(projection step)。该投影步骤使用一个带有 Batch Normalization[35] 的 1 层 MLP,将 [CLS] token 嵌入映射到一个新的表示空间中。之所以需要这一步,是因为 ViT 的最后一层会施加 Layer Normalization [36],而这会使得我们的**防塌缩目标(anti-collapse objective)**难以被有效优化。
ViT 里通常会额外加一个特殊 token,叫 [CLS] token。
它的作用类似于:用一个专门的 token 去汇总整张图的信息所以最后一层的 [CLS] token embedding,通常就被拿来当作“整张图的全局表示”。
预测器(predictor) 是一个 Transformer,包含 6 层、16 个注意力头以及 10% 的 dropout(约 10M 参数)。动作信息通过 Adaptive Layer Normalization(AdaLN) [37] 被注入到预测器中,并作用于每一层。AdaLN 的参数被初始化为 0,以稳定训练,并确保动作条件对预测器训练的影响是逐步增强的。预测器以长度为 N 的历史帧表示作为输入,并通过自回归的方式预测下一帧表示;同时使用时间因果掩码(temporal causal masking) 来避免看到未来时刻的嵌入表示。预测器后面同样接有一个 projector 网络,其实现方式与编码器后使用的 projector 相同。我们世界模型的所有组成部分都通过下一段描述的损失函数进行联合学习。
训练目标(Training Objective)。我们的目标是学习对未来预测有用的潜在表示,也就是能够表征环境动态的表示。LeWorldModel 的训练目标由两部分组成:预测损失(prediction loss) 和 正则化损失(regularization loss)。其中,预测损失 Lpred(采用 teacher-forcing)用于计算相邻时间步之间,预测嵌入与真实嵌入之间的误差:
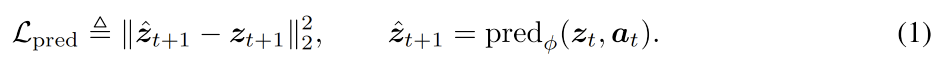
通过预测损失,编码器被激励学习预测器的可预测表示。
teacher-forcing:训练时,模型是拿“真实的当前表示” zt 去预测下一步,而不是拿自己上一步预测出来的东西继续往后滚。


然而,仅使用这一损失会导致表示塌缩(representation collapse),产生一种平凡解:即编码器把所有输入都映射为一个恒定不变的表示。为了防止这种情况,我们引入了一个防塌缩正则项(anti-collapse regularization term),以促进嵌入空间中的特征多样性。具体来说,我们采用了 Sketched-Isotropic-Gaussian Regularizer(SIGReg) [25],因为它具有简单、可扩展和稳定的优点。SIGReg鼓励潜在嵌入向量与各向同性高斯目标分布相匹配。



3.2 Latent Planning


我们使用交叉熵方法(Cross-Entropy Method, CEM) [40] 来求解该问题。CEM 是一种采样方法,它通过迭代地选择最优计划,并利用这些最优计划的统计信息来更新采样分布参数。规划视野 HH 在“更长远的前瞻能力”和“更高的计算代价及模型偏差”之间进行权衡。特别地,随着规划视野变长,自回归 rollout 会不断累积预测误差,从而可能降低优化得到的动作序列质量。为缓解这一问题,我们采用**模型预测控制(Model Predictive Control, MPC)**策略:每次只执行规划出的前 KK 个动作,然后基于更新后的观测重新进行规划。关于规划策略的更多细节见附录 D。
4 Latent Planning Performance
4.1 Planning evaluation setup
Environments. 我们在多种任务中评估了LeWM,包括二维和三维环境中的导航、运动规划及机械操作,所有实验结果均展示于图5。关于数据集生成及实验环境的更多细节详见附录E。
Baselines.我们将 LeWM 的性能与多个基线方法进行了比较:DINO-WM 和 PLDM(两种当前先进的基于 JEPA 的方法);一个目标条件行为克隆策略(GCBC);以及两种目标条件离线强化学习算法,即 GCIVL 和 GCIQL。在这些基线中,PLDM 与我们的设定最为接近,因为它同样是直接从像素观测端到端学习世界模型。然而,PLDM 依赖于一个基于 VICReg 准则构建的七项训练目标,这会带来训练不稳定性,并增加超参数调节的复杂度。相比之下,DINO-WM 使用 DINOv2 [41] 作为特征编码器来建模动态,以缓解表示塌缩问题,但其原始形式还额外结合了其他模态信息,例如本体感觉输入(proprioceptive inputs);为了公平比较,除非另有说明,否则我们在 DINO-WM 中去除了本体感觉信息。关于基线方法的更多实现细节(附录 C)以及评估设置(附录 F.1),见附录。对于每一种方法,我们都在所有环境中保持相同的超参数设置不变。
4.2 Towards Efficient Planning with WMs
我们在图6中展示了规划性能对比结果。LeWM在更具挑战性的规划任务中表现优于 PLDM ,其在PushT任务上的成功率提升了18%,同时与DINO-WM保持竞争力。值得注意的是,在PushT任务中,仅使用像素数据的LeWM甚至超越了具备额外本体感觉信息的DINO-WM,这充分证明了LeWM对任务关键参数的精准捕捉能力。通过规划加速比对比(图3)可见,LeWM的规划速度提升达48倍——完整规划过程仅需不到1秒即可完成,且在各类任务中保持优异性能。在固定规划参数下,该规划时间在不同环境中保持稳定,有效缩小了与实时控制系统的性能差距。
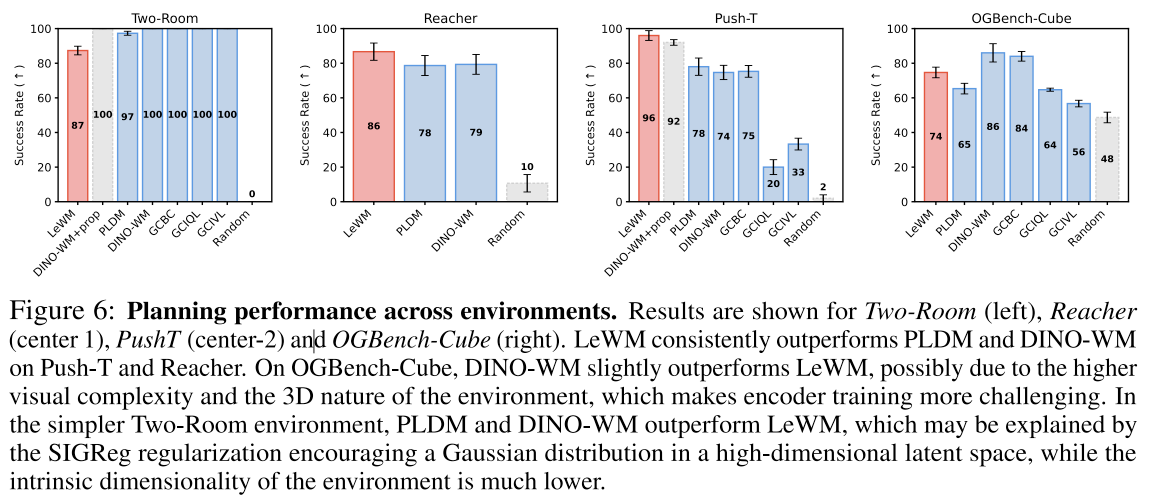
我们在图 6 中报告了规划性能。LeWM 在更具挑战性的规划任务上优于 PLDM,在 PushT 任务上取得了高出 18% 的成功率,同时与 DINO-WM 保持了竞争力。值得注意的是,在 PushT 上,即使 DINO-WM 可以访问额外的本体感觉信息(proprioceptive information),仅使用像素输入的 LeWM 仍然超过了它,这表明 LeWM 具有捕捉潜在任务相关量的能力。有趣的是,LeWM 在最简单的环境 Two-Room 上表现反而更差。一种可能的解释是:该数据集的多样性较低且内在维度较低,这使得编码器在高维潜在空间中难以匹配 SIGReg 所施加的各向同性高斯先验,从而可能导致潜在表示结构不够理想。这也揭示了 SIGReg 正则化 在非常低复杂度环境中的一个潜在局限性。
此外,在规划加速效果对比中(图3),LeWM算法实现了48倍的规划速度提升——完整规划过程耗时不足一秒,同时在各类任务中保持竞争力。在固定规划配置下,该规划时间在不同环境中保持稳定,有效缩小了与实时控制系统的差距。
4.3 Towards Stable Training of World Models
消融实验(Ablations)。我们对 LeWM 的若干设计选择进行了消融研究。首先,我们分析了 SIGReg 对其内部参数的敏感性,即随机投影数量和积分节点数量。实验结果表明,性能基本不受这些参数的影响,这说明它们不需要仔细调节。因此,正则化权重 λ仍然是唯一真正有效的超参数。由于只需要调节一个超参数,因此可以通过简单的二分搜索策略以 O(logn)O(logn) 的复杂度高效完成搜索,而 PLDM 则需要在多项式时间 O(n6)下进行搜索。我们还研究了嵌入维度的影响。结果表明,表示维度需要足够大,方法才能取得较好性能;但一旦超过某个阈值,性能会很快趋于饱和,这说明该方法对编码器容量的精确选择并不敏感。此外,我们还考察了编码器结构的影响,将默认的 ViT 编码器替换为 ResNet-18 骨干网络(表 8)。LeWM 在这两种架构下都取得了有竞争力的表现,这表明它对视觉编码器的选择基本不敏感。所有消融实验的细节见附录 G。
训练曲线(Training Curves)。我们在图 18 中给出了 LeWM 在 PushT 上的训练损失曲线,在图 19 中给出了 PLDM 的训练损失曲线。LeWM 的两项训练目标表现出平滑且单调的收敛趋势:预测损失稳步下降,而 SIGReg 正则项在训练早期快速下降,随后进入平台期,这表明 latent 分布迅速接近了各向同性高斯目标分布。相比之下,PLDM 的七项训练目标在多个损失分量上表现出噪声较大且非单调的行为。这些现象突出了 LeWM 的一个关键优势:由于训练目标被简化为仅由两个表现良好的项组成,训练过程显著更加稳定,也不再需要在多个正则项之间平衡彼此竞争的梯度。
5 Quantifying Physical Understanding in LeWM
在本节中,我们通过两种方式评估LeWM潜在空间所捕捉的动力学质量:一是学习从潜在嵌入中提取物理量,二是测量世界模型检测物理变化的能力。
5.1 Physical Structure of the Latent Space
Probing physical quantities.作为物理理解能力的初步评估指标,我们分析了哪些物理量可从LeWM的潜在表征中提取。我们训练了线性和非线性探测器,使其能够从给定嵌入向量预测目标物理量。Push-T环境的实验结果见表1。我们的方法始终优于 PLDM ,同时与DINOv2等大型预训练模型生成的表征具有可比性。其他环境的探测结果详见附录F.2。
潜在空间解码(Decoding Latent Space)。为了进一步评估潜在表示中所包含的信息,我们在图 8 中展示了由一个解码器生成的图像。该解码器在训练过程中被训练为:从单个潜在嵌入(192 维)重建像素观测。尽管在 LeWM 的训练过程中从未使用重建目标,这个解码器仍然能够从学习到的表示中恢复出视觉场景,这表明这个低维且紧凑的潜在空间仍然保留了关于底层物理状态的足够信息。关于解码器结构的更多细节见附录 D。
潜在空间可视化(Visualizing Latent Space)。我们进一步使用 t-SNE 对潜在空间的结构进行可视化。图 9 给出了 PushT 环境中潜在空间的一个定性可视化结果。该可视化结果表明,学习到的表示能够捕捉环境的空间结构,在潜在空间中保留了邻域关系和相对位置关系。
5.2 Violation-of-expectation Framework
另一种量化物理理解能力的方法,是考察模型是否能够检测到对其已学习世界模型的违背。受发展心理学中的**违背预期(violation-of-expectation, VoE)**范式启发,并参考其在机器学习中的近期应用 [43–45],该框架用于评估:当事件违背了已学习的物理规律时,模型是否会对这些事件赋予更高的“惊讶度”。
按照已有工作,我们通过测量模型预测的未来观测与实际观察到的未来之间的差异来量化这种惊讶度。我们在三个环境中评估了这一框架:TwoRoom、PushT 和 OGBench Cube。对于每个环境,我们引入两类扰动。第一类是视觉扰动,即在轨迹过程中某个物体的颜色突然发生变化。第二类是物理扰动,即将一个或多个物体瞬移到随机位置,从而破坏场景中预期的物理连续性。图 10 显示,相比未扰动的对应帧,LeWM 会持续对包含物理违背的帧赋予更高的惊讶度。关于 VoE 的更多细节见附录 F.3。
6 Conclusion

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)