Redis(非关系型数据库)
一、Redis简介
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
使用场景:
- 缓存:数据库之前加缓存,降低数据库读写压力
- 排行榜:按照热度排名、按照发布时间排名
- 计数器:播放数、浏览数
- 社交网络:赞、踩、粉丝、下拉刷新
- 消息队列:发布订阅
- 适合存储热点数据(热点商品、咨询、新闻)
简单理解:
- Redis是用C语言开发的一个开源的、高性能的键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化NoSql数据库
- NoSql(Not Only Sql),不仅仅是SQL,泛指非关系型数据库,NoSql数据库并不是要取代关系型数据库,而是关系型数据库的补充
关系型数据库(RDBMS):MySQL、Oracl、DB2、SQLServer
非关系型数据库(NoSql):Redis、Mongo DB、MemCached
二、Redis优势
Redis优势:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
三、Redis下载与启动
3.1 下载
window 5.x 版本 https://github.com/tporadowski/redis/releases
或者
3.2 启动
进入redis解压目录下cmd
redis-server.exe redis.windows.conf
四、Redis可视化
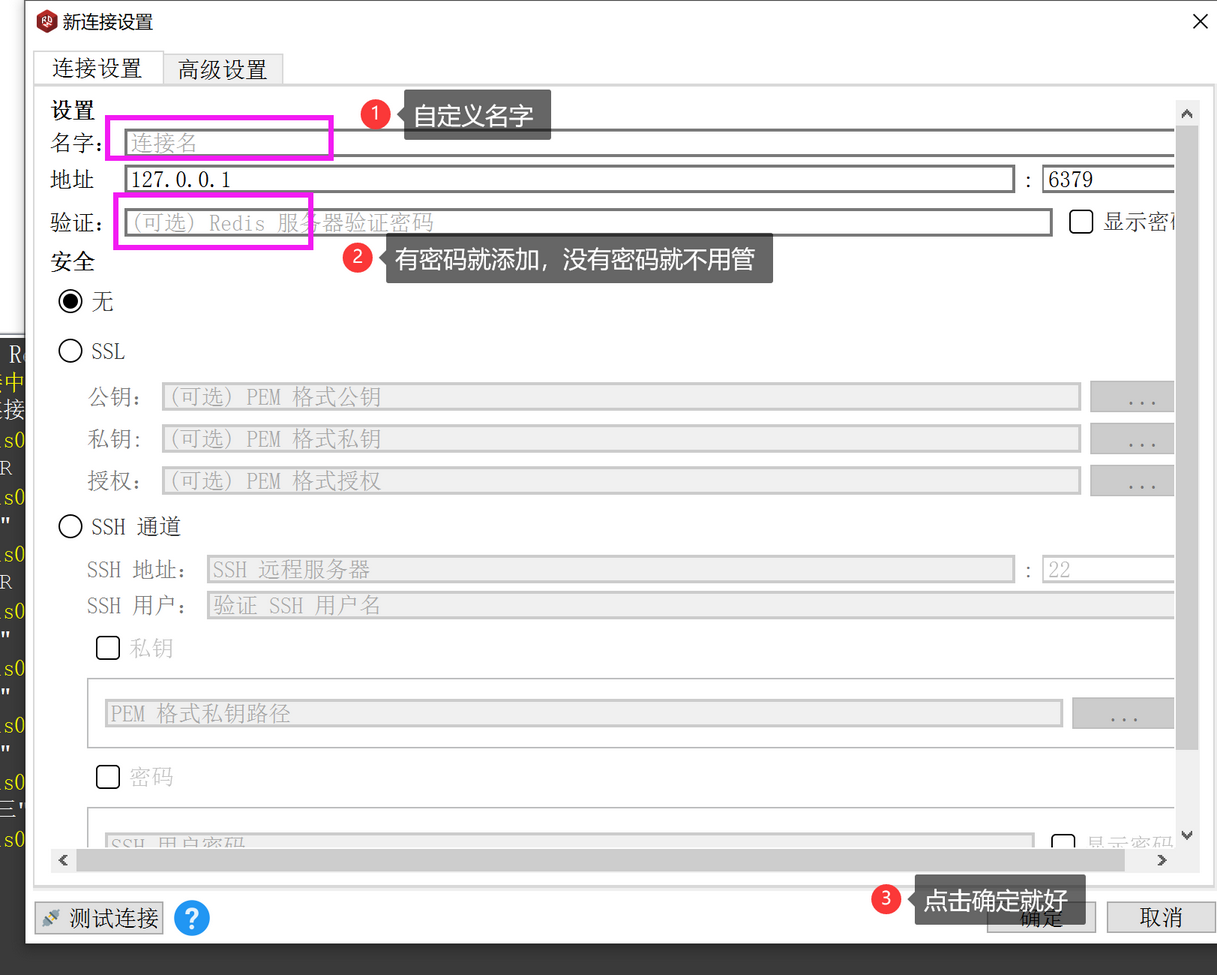
链接成功如下:
五、Redis数据类型
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5中常用的数据类型
- 字符串:String
- 哈希:Hash
- 列表:List
- 集合:Set
- 有序集合:Sorted Set 也叫zset
5.1 string
字符串(string)是redis最基本的类型;
增加、修改
1. set 键 值
如果键不存在就是添加,如果存在就是修改值
--添加键name值liuyan
localhost:0>set name liuyan
"OK"
localhost:0>get name
"liuyan"
localhost:0>set name liutao
"OK"
localhost:0>get name
"liutao"
localhost:0>2. 设置键值并添加过期时间
setex 键 过期时间 值
过期时间单位为秒
localhost:0>setex age 3 18
"OK"3. 设置多个键值对
mset 键1 值1 键2 值2 键3 值3
localhost:0>mset name2 aaa name3 bbb name4 ccc name5 ddd
"OK"
localhost:0>4. 追加值
append 键 值
5. 获取
获取值
- get 键
- 如果键不存在,显示null或者空行
6. 删除
删除键
- del 键
删除多个键
- del 键1 键2
7. 查找键
keys 键
keys *
-- 显示所有键
查看键的有效时间
以秒为单位
- 返回大于0,代表有效时间,单位为:秒;
- 返回-1为永远有效;
- 返回-2为键不存在;
5.2 哈希 hash
hash用于存“储键值”对集合;
每个hash中的键可以理解为字段(field),一个字段(field)对应一个值(value);
hash中的值(value)类型为字符串(string);
同一个hash中字段名(field)不可重复。
1. 增加,修改
添加
hset 键 字段 值
-- 设置一个键huser1,字段name,值tom
hset huser1 name tom// 设置多个值
hmset 键 字段1 值1 字段2 值2
hmset huser2 name marry sex female- hget 键 字段
127.0.0.1:6379[3]> hget huser2 name
获取字段获取多个字段
- hmget 键 字段1 字段2
-- hmget huser2 name sex
127.0.0.1:6379[3]> hmget huser2 name sex
marry
female
127.0.0.1:6379[3]> 获取所有字段
- hvals 键
hvals huser2
127.0.0.1:6379[3]> hvals huser2
marry
female
127.0.0.1:6379[3]>删除指定字段
- hdel 键 字段名
hdel huser2 sex
127.0.0.1:6379[3]> hgetall huser2 //查询所有的key
name
marry
sex
female
127.0.0.1:6379[3]> hdel huser2 sex
1
127.0.0.1:6379[3]> hgetall huser2
name
marry
127.0.0.1:6379[3]> 删除键
- del 键
127.0.0.1:6379[3]> hgetall huser2
name
marry
127.0.0.1:6379[3]> del huser2
1
127.0.0.1:6379[3]> hgetall huser2
127.0.0.1:6379[3]> 5.3 列表 list
列表中的值(value)为字符串(string);
列表中的每个值按照添加的顺序排列。
1. 增加
从列表左侧添加值
- lpush 键 值1 值2
lpush luser1 aa bb
127.0.0.1:6379[3]> select 4
OK
127.0.0.1:6379[4]> lpush luser1 aa bb cc
3
127.0.0.1:6379[4]> 从右侧添加值
- rpush 键 值1 值2
rpush luser1 dd
127.0.0.1:6379[4]> rpush luser1 dd
4
127.0.0.1:6379[4]> 2. 获取
返回列表里指定范围内的值
- 索引从左侧开始,第一个值的索引为0;
- 索引可以是负数,表示从尾部开始计数,如:-1表示最后一个值;
- start,stop为要获取值的索引。
获取所有值
lrange 键 start stop
lrange luser1 0 -1
127.0.0.1:6379[4]> lrange luser1 0 -1
11
cc
22
bb
aa
dd
127.0.0.1:6379[4]> 获取指定范围的值
-- 获取指定的值
127.0.0.1:6379[4]> lrange luser1 2 4
22
bb
aa
127.0.0.1:6379[4]>
127.0.0.1:6379[4]> lrange luser1 2 -1
22
bb
aa
dd
127.0.0.1:6379[4]> 3. 修改
修改指定索引的值
- lset 键 索引 值
127.0.0.1:6379[4]> lset luser1 0 ee
OK
127.0.0.1:6379[4]> lrange luser1 0 -1
ee
cc
22
bb
aa
dd
127.0.0.1:6379[4]> 5.4 集合 set
set介绍
无序集合中值(value)类型为字符串(string);
集合里不允许有重复的值;
说明:对于集合里的值只能添加与删除,不能修改。
1. 添加值
添加值
sadd 键 值1 值2 值3
127.0.0.1:6379[1]> sadd suser1 aa bb cc
32. 查询值
获取值
smembers 键
-- 获取集合中的值
-- smembers suser13. 删除值
srem 键 值
删除指定的值
127.0.0.1:6379[1]> smembers suser1
aa
bb
cc
127.0.0.1:6379[1]> srem suser1 aa
1
127.0.0.1:6379[1]> smembers suser1
bb
cc
127.0.0.1:6379[1]> 5.5 有序集合 zset
zset介绍
有序集合中值(value)类型为字符串(string);
集合里不允许有重复的值;
每个值都会关联一个分数(score),分数(score)可以为负数,通过分数(score)将值从小到大排序;
说明:对于有序集合里的值只能添加与删除不能修改。
1. 添加值
zadd 键 score1 值1 score2 值2 score3 值3
-添加值
-- 添加3个值,score分别为1,3,2
-- 添加的值会按照score从小到大排列
127.0.0.1:6379[1]> zadd zuser1 1 aa 3 dd 6 cc 2 ff
4
127.0.0.1:6379[1]> 2. 获取值
返回指定范围内的值
- start,stop为值的下标索引;
- 第一个值的索引为0;
- 索可以是负数,表示从尾部开始计数,-1表示最后一个值;
- withscore:同时获取值对应的分数(score)。
127.0.0.1:6379[1]> zrange zuser1 0 -1
aa
ff
dd
cc
127.0.0.1:6379[1]>
-- score显示
127.0.0.1:6379[1]> zrange zuser1 0 -1 withscores
aa
1
ff
2
dd
3
cc
6
127.0.0.1:6379[1]> 3. 删除值
删除指定的值
zrem 键 值
127.0.0.1:6379[1]> zrange zuser1 0 -1 withscores
aa
1
ff
2
dd
3
cc
6
127.0.0.1:6379[1]> zrem zuser1 aa
1
127.0.0.1:6379[1]> zrange zuser1 0 -1 withscores
ff
2
dd
3
cc
6
127.0.0.1:6379[1]> 六、Java中使用Redis
- Redis的Java客户端有很多,官方推荐的有三种
- Jedis
- Lettuce
- Redisson
- Spring对Redis客户端进行了整合,提供了SpringDataRedis,在Spring Boot项目中还提供了对应的Starter,即spring-boot-starter-data-redis
6.1 Jedis
使用Jedis的步骤
- 获取连接
- 执行操作
- 关闭连接
导入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.0</version>
</dependency>测试
@SpringBootTest
class RedisTestApplicationTests {
@Test
void contextLoads() {
//1. 获取连接
Jedis jedis = new Jedis("localhost", 6379);
//2. 执行具体操作
jedis.set("name", "Hades");
jedis.hset("stu", "name", "Jerry");
jedis.hset("stu", "age", "18");
jedis.hset("stu", "num", "4204000400");
Map<String, String> map = jedis.hgetAll("stu");
Set<String> keySet = map.keySet();
for (String key : keySet) {
String value = map.get(key);
System.out.println(key + ":" + value);
}
String name = jedis.get("name");
System.out.println(name);
//3. 关闭连接
jedis.close();
}
}Jedis我们了解一下即可,大多数情况下我们还是用SpringDataRedis
6.2 Spring Data Redis
SpringBoot项目中,可以使用SpringDataRedis来简化Redis(常用)Spring Data Redis中提供了一个高度封装的类:RedisTemplate,针对jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation接口。具体分类如下:ValueOperations:简单K-V操作 StrringSetOperations:set类型数据操作 setZSetOperations:zset类型数据操作 zsetHashOperations:针对map类型的数据操作 hashListOperations:针对list类型的数据操作 list
使用SpringDataRedis,我们首先需要导入它的maven坐标
<!--Spring Boot-redis的依赖包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>之后重新设置一下序列化器,防止出现乱码,在config包下创建RedisConfig配置类
@Configuration
public class RedisConfig {
// 更改默认的序列化方式
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
// 默认的Key序列化器为:JdkSerializationRedisSerializer
// 给字符串的key序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
// 给hash的key序列化
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 连接工厂
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}随后配置一下连接redis的相关配置
spring:
data:
redis:
host: localhost
port: 6379
password: 123456
database: 0 #操作的是0号数据库
jedis:
#Redis连接池配置
pool:
max-active: 8 #最大连接数
max-wait: 1ms #连接池最大阻塞等待时间
max-idle: 4 #连接池中的最大空闲连接
min-idle: 0 #连接池中的最小空闲连接String类型数据操作
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void stringTest() {
// 获取对象
ValueOperations valueOperations = redisTemplate.opsForValue();
// 设置name为Hades
valueOperations.set("name","Hades");
// 获取name
String name = (String) valueOperations.get("name");
System.out.println(name);
// 设置age为9527,有效时间10秒
valueOperations.set("age", "18", 10, TimeUnit.SECONDS);
String age = (String) valueOperations.get("age");
System.out.println(age);
// 如果不存在,则设置name为Kyle
/**
* setIfAbsent方法通过返回布尔值标识操作结果:
*
* true:键不存在且成功设置键值对
* false:键已存在且未执行任何操作
* 该方法封装了Redis的SETNX(SET if Not eXists)命令,确保"检查键存在性"与"设置值"的原子性操作。
* 传统非原子方案(先hasKey检查再set)在高并发场景下会导致竞态条件,
* 而setIfAbsent通过Redis内部机制彻底规避此问题。
*/
Boolean aBoolean = valueOperations.setIfAbsent("name", "Kyle");
System.out.println(aBoolean);
/**
* 防重复提交控制: 在订单提交等场景中,可通过setIfAbsent检查唯一标识是否存在:
* Boolean isNew = redisTemplate.opsForValue().setIfAbsent("order:123", "1");
* if (Boolean.TRUE.equals(isNew)) {
* // 首次提交,处理订单
* } else {
* // 重复提交,拒绝处理
* }
*/
}
}Hash类型数据操作
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void hashTest() {
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("1000001", "name", "Hades");
hashOperations.put("1000001", "age", "18");
hashOperations.put("1000001", "hobby", "Apex");
// 获取map集合
Map<String, String> map = hashOperations.entries("1000001");
Set<String> keySet = map.keySet();
for (String hashKey : keySet) {
System.out.println(hashKey + ":" + map.get(hashKey));
}
System.out.println("================================");
// 只获取keys
Set<String> keys = hashOperations.keys("1000001");
for (String key : keys) {
System.out.println(key);
}
System.out.println("================================");
// 只获取values
List<String> values = hashOperations.values("1000001");
for (String value : values) {
System.out.println(value);
}
}
}List类型数据操作
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void listTest() {
ListOperations listOperations = redisTemplate.opsForList();
// 存数据
listOperations.leftPush("testData", "A");
listOperations.leftPushAll("testData", "B", "C", "D");
// 获取所有数据
List<String> testDatas = listOperations.range("testData", 0, -1);
//遍历
for (String tableData : testDatas) {
System.out.print(tableData + " ");
}
System.out.println();
//获取当前list长度,用于遍历
Long size = listOperations.size("testData");
int value = size.intValue();
System.out.println(value);
System.out.println("================================");
//遍历输出并删除
for (int i = 0; i < value; i++) {
// 删除从左边获取一个元素
System.out.print(listOperations.leftPop("testData") + " ");
}
System.out.println();
//最后输出一下当前list长度
System.out.println(listOperations.size("testData"));
}
}
Set类型数据操作
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void setTest() {
SetOperations setOperations = redisTemplate.opsForSet();
// 存数据,这里存了两个a
setOperations.add("tmp", "a", "b", "c", "d", "a");
// 遍历输出 members()方法获取所有元素
Set<String> tmpData = setOperations.members("tmp");
for (String value : tmpData) {
System.out.print(value + " ");
}
System.out.println();
System.out.println("===========================================");
// 删除b和c
setOperations.remove("tmp", "b", "c");
// 再次遍历输出
tmpData = setOperations.members("tmp");
for (String value : tmpData) {
System.out.print(value + " ");
}
}
}
ZSet类型数据操作
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void zsetTest() {
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
//存值
zSetOperations.add("myZset", "a", 0.0);
zSetOperations.add("myZset", "b", 1.0);
zSetOperations.add("myZset", "c", 2.0);
zSetOperations.add("myZset", "a", 3.0);
// 取值
Set<String> myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
// 修改分数 incrementScore() 自增方法
zSetOperations.incrementScore("myZset", "b", 4.0);
// 取值
System.out.println("==================================");
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
// 删除成员
zSetOperations.remove("myZset", "a", "b");
System.out.println("==================================");
// 取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
}
}七、Redis两种持久化方式
为什么要持久化
Redis是内存数据库,宕机后数据会消失,Redis重启后快速恢复数据,要提供持久化机制。
Redis的两种持久化方式:RDB和AOF
Redis持久化不保证数据的完整性,有可能会丢数据。当Redis用作DB时,DB数据要完整,所以一定要有一个完整的数据源(文件、mysql),在系统启动时,从这个完整的数据源中将数据load到Redis中。
7.1 RDB
RDB(Redis DataBase),是redis默认的存储方式,RDB方式是通过快照( snapshotting )完成的。它保存的是某一时刻的数据并不关注过程。RDB保存redis某一时刻的数据的快照
RDB 有两种持久化方式:「手动触发」和「自动触发」,
「手动触发使用以下两个命令:」
- 「save」:会阻塞当前 Redis 服务器响应其他命令,直到 RDB 快照生成完成为止,对于内存 比较大的实例会造成长时间阻塞,所以线上环境不建议使用
- 「bgsave」:Redis 主进程会 fork 一个子进程,RDB 快照生成有子进程来负责,完成之后,子进程自动结束,bgsave 只会在 fork 子进程的时候短暂的阻塞,这个过程是非常短的,所以推荐使用该命令来手动触发
除了执行命令手动触发之外,Redis 内部还存在自动触发 RDB 的持久化机制,「在以下几种情况下 Redis 会自动触发 RDB 持久化」:
- 在配置中配置了 save 相关配置信息,如我们上面配置文件中的 save 60 10000 ,也可以把它归类为“save m n”格式的配置,表示 m 秒内数据集存在 n 次修改时,会自动触发 bgsave。
- 执行 debug reload 命令重新加载 Redis 时,也会自动触发 save 操作
- 默认情况下执行 shutdown(redis服务器关闭-->关闭redis) 命令时,如果没有开启 AOF 持久化功能则自动执行 bgsave
因此总结:
触发快照的方式
1. 符合自定义配置的快照规则;
2. 执行save或者bgsave命令;但是一般线上不使用save
3. 执行flushall命令;
4. 执行主从复制操作 (第一次)。配置:redis.windows.conf文件中可以设置
#save 900 1 ---->15分钟内至少一个key被修改就执行快照
#save 300 10---->5分钟内至少10个key被更改就执行快照
#save 60 10000---->1分钟内至少10000个key被更改就执行快照
我们也可以自己设定规则
原理如下:
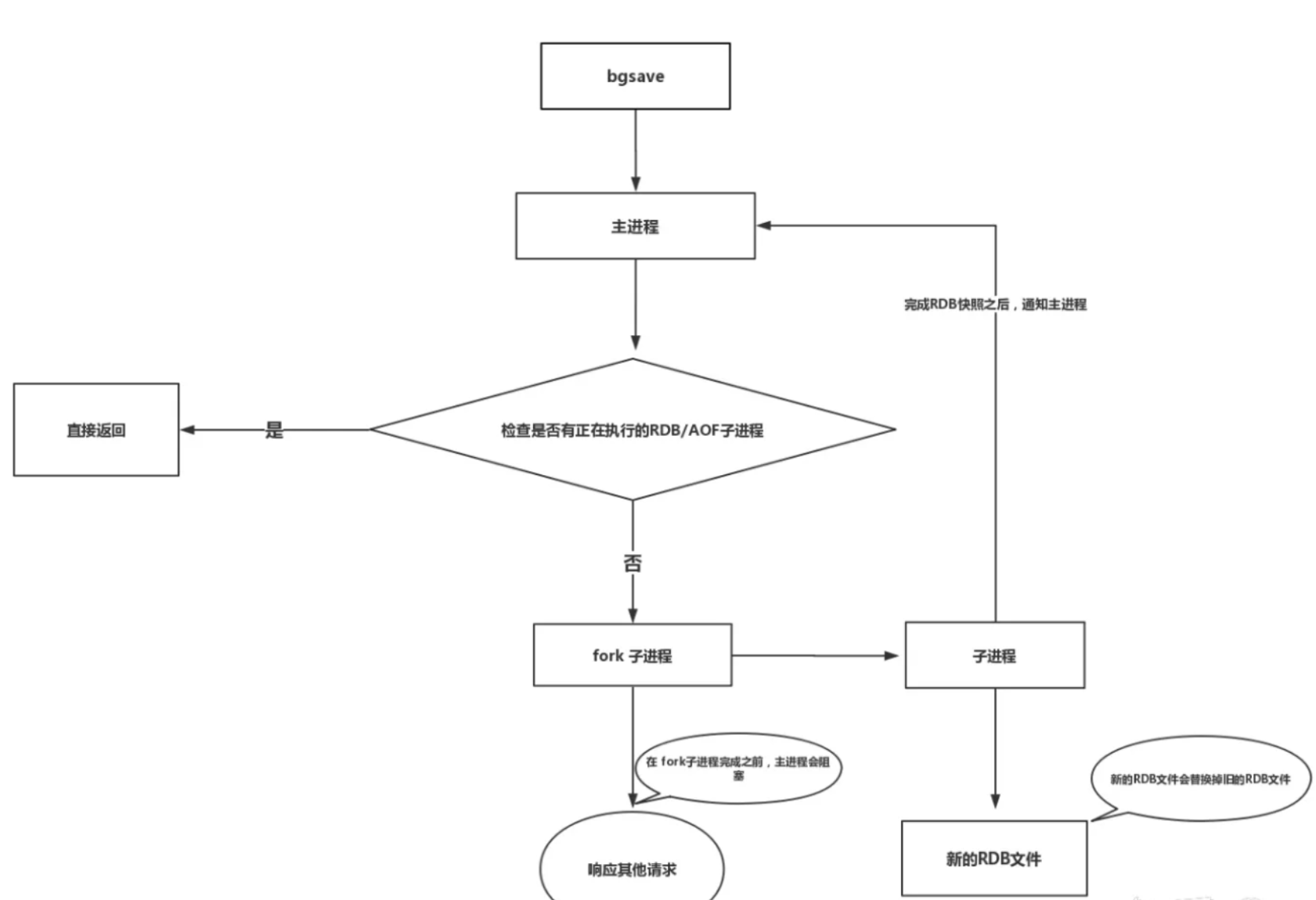
文字解析:
- 1、执行 bgsave 命令,Redis 主进程判断当前是否存在正在执行的(save/bgsave) RDB/AOF 子进程,如果存在, bgsave 命令直接返回不在往下执行。
- 2、父进程执行 fork 操作创建子进程,fork 操作过程中父进程会阻塞,fork 完成后父进程将不在阻塞可以接受其他命令。
- 3、子进程创建新的 RDB 文件,基于父进程当前内存数据生成临时快照文件,完成后用新的 RDB 文件替换原有的 RDB 文件,并且给父进程发送 RDB 快照生成完毕通知
总结RDB优缺点:
「RDB 方式的优点」:
- RDB 快照是某一时刻 Redis 节点内存数据,非常适合做备份,上传到远程服务器或者文件系统中,用于容灾备份
- 数据恢复时 RDB 要远远快于 AOF
「RDB 的缺点有」:
- RDB 持久化方式数据没办法做到实时持久化/秒级持久化。我们已经知道了 bgsave 命令每次运行都要执行 fork 操作创建子进程,属于重量级操作,频繁执行成本过高。
- RDB 文件使用特定二进制格式保存,Redis 版本演进过程中有多个格式 的 RDB 版本,存在老版本 Redis 服务无法兼容新版 RDB 格式的问题
如果我们对数据要求比较高,每一秒的数据都不能丢,RDB 持久化方式肯定是不能够满足要求的,那 Redis 有没有办法满足呢,答案是有的,那就是接下来的 AOF 持久化方式
7.2 AOF
Redis 默认并没有开启 AOF 持久化方式,需要我们自行开启,在 redis.windows.conf 配置文件中将 appendonly no 调整为appendonly yes,这样就开启了 AOF 持久化,与 RDB 不同的是 AOF 是以记录操作命令的形式来持久化数据的,我们可以查看以下 AOF 的持久化文件 appendonly.aof
修改开启AOF后需要重启服务器,比如执行select,set等命令的时候就可以触发了
AOF持久化流程:
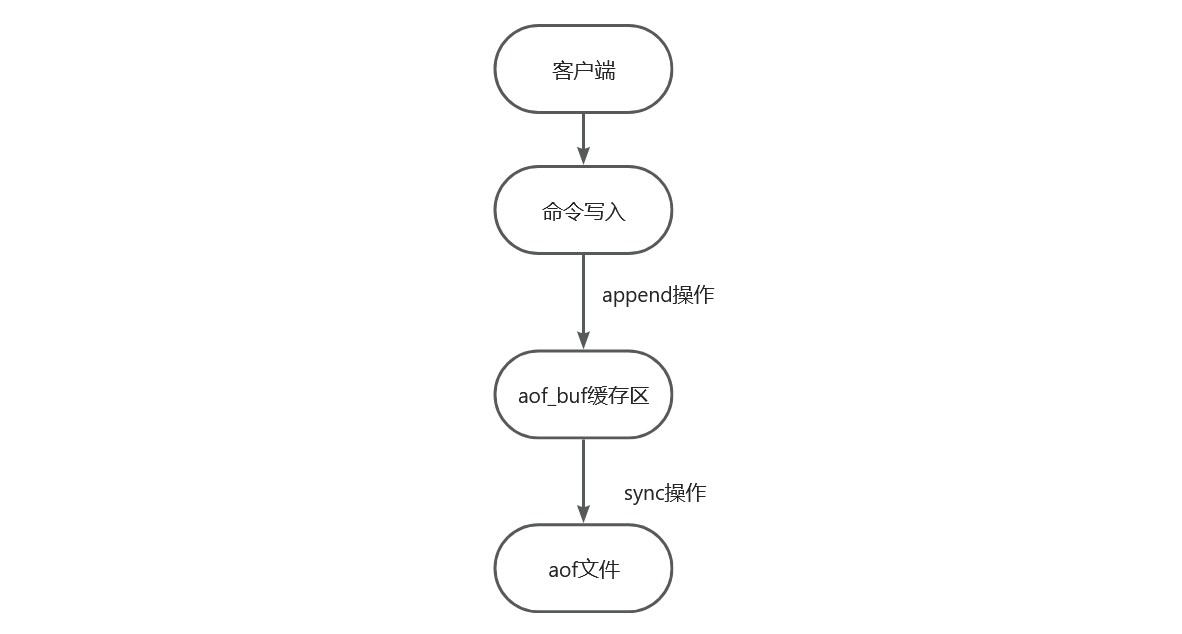
在 AOF 持久化过程中有两个非常重要的操作:「一个是将操作命令追加到 AOF_BUF 缓存区,另一个是 AOF_buf 缓存区数据同步到 AOF 文件」
「1、为什么要将命令写入到 aof_buf 缓存区而不是直接写入到 aof 文件?」
如果每次写入 AOF 命令都直接追加到磁盘上的 AOF 文件中,这样频繁的 IO 开销,Redis 的性能就完成取决于你的机器硬件了,为了提升 Redis 的响应效率就添加了一层 aof_buf 缓存层, 利用的是操作系统的 cache 技术,这样就提升了 Redis 的性能,虽然这样性能是解决了,但是同时也引入了一个问题,aof_buf 缓存区数据如何同步到 AOF 文件呢?由谁同步呢?这就是我们接下来要聊的一个操作:「fsync 操作」
「2、aof_buf 缓存区数据如何同步到 aof 文件中?」
aof_buf 缓存区数据写入到 aof 文件是有 linux /windows系统去完成的,由于 系统调度机制周期比较长,如果系统故障宕机了,意味着一个周期内的数据将全部丢失,这不是我们想要的,所以 系统提供了一个 fsync 命令,fsync 是针对单个文件操作(比如这里的 AOF 文件),做强制硬盘同步,fsync 将阻塞直到写入硬盘完成后返回,保证了数据持久化,正是由于有这个命令,所以 redis 提供了配置项让我们自行决定何时进行磁盘同步,redis 在 redis.conf 中提供了appendfsync 配置项,有如下三个选项:
- always:每次有写入命令都进行缓存区与磁盘数据同步,这样保证不会有数据丢失,但是这样会导致 redis 的吞吐量大大下降,下降到每秒只能支持几百的 TPS ,这违背了 redis 的设计,所以不推荐使用这种方式
- everysec:这是 redis 默认的同步机制,虽然每秒同步一次数据,看上去时间也很快的,但是它对 redis 的吞吐量没有任何影响,每秒同步一次的话意味着最坏的情况下我们只会丢失 1 秒的数据, 推荐使用这种同步机制,兼顾性能和数据安全
- no:不做任何处理,缓存区与 aof 文件同步交给系统去调度,操作系统同步调度的周期不固定,最长会有 30 秒的间隔,这样出故障了就会丢失比较多的数据。
另外一个问题
有没有注意到一个问题,AOF 文件都是追加的,随着服务器的运行 AOF 文件会越来越大,体积过大的 AOF 文件对 redis 服务器甚至是主机都会有影响,而且在 Redis 重启时加载过大的 AOF 文件需要过多的时间,这些都是不友好的,那 Redis 是如何解决这个问题的呢?Redis 引入了重写机制来解决 AOF 文件过大的问题。
「3、Redis 是如何进行 AOF 文件重写的?」
简单来说就是将就文件中的重复命令或者旧命令整合,比如set key val set key1 val --> mset key val key1 val
将无效的命令移除,将最新的结果整合到新aof文件中
AOF 文件重写跟 RDB 持久化一样分为「手动触发」和「自动触发」,手动触发直接调用 bgrewriteaof 命令就好了,我们后面会详细聊一聊这个命令,自动触发就需要我们在 redis.windows.conf 中修改以下几个配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb- auto-aof-rewrite-percentage:代表当前 AOF文件空间 (aof_current_size)和上一次重写后 AOF 文件空间(aof_base_size)的比值,默认是 100%,也就是一样大的时候
- auto-aof-rewrite-min-size:表示运行 AOF 重写时 AOF 文件最小体积,默认为 64MB,也就是说 AOF 文件最小为 64MB 才有可能触发重写
7.3 Redis持久化数据恢复
我们知道 Redis 是基于内存的,所有的数据都存放在内存中,由于机器宕机或者其他因素重启了就会导致我们的数据全部丢失,这也就是要做持久化的原因,当服务器重启时,Redis 会从持久化文件中加载数据,这样我们的数据就恢复到了重启前的数据,在数据恢复这一块Redis 是如何实现的?
我们先来看看数据恢复的流程图:
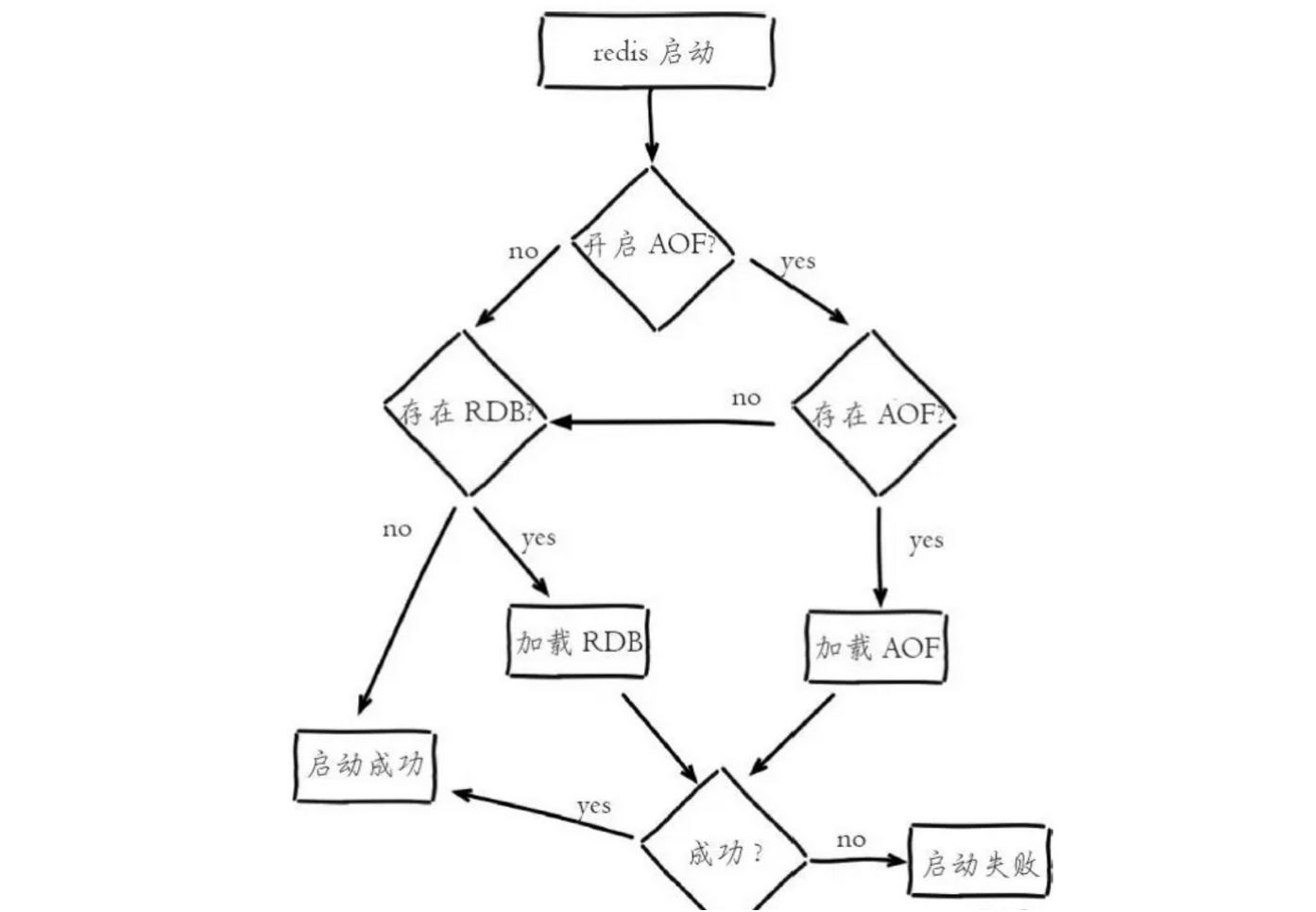
Redis 的数据恢复流程比较简单,优先恢复的是 AOF 文件,如果 AOF 文件不存在时则尝试加载 RDB 文件,为什么 RDB 的恢复速度比 AOF 文件快,需要注意的是当存在 RDB/AOF 时,如果数据加载不成功,Redis 服务启动会失败。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)