【第8篇】玩透RAG之LangGraph Custom RAG
📋 一、项目概述
开源项目镜像地址:langgraph-custom-rag-example
这是一个基于 Spring AI Alibaba 实现的具备自我校正能力的 RAG(检索增强生成)系统,参考 LangGraph 的 Agentic RAG 架构。与传统 RAG 的单次检索模式不同,该系统引入了"智能体思维"——当检索结果不理想时,系统会主动重写查询并重新检索,直到获得满意的结果。
1.1 核心能力
能力 说明 技术实现
查询优化 将用户自然语言问题转换为更适合向量检索的查询语句 LLM + 知识库工具调用
文档评分 评估检索到的文档与用户问题的相关性 独立 LLM 评分节点
自我校正 当相关性不足时,自动重写问题并重新检索 条件分支 + 循环边
生成回答 基于高质量文档生成简洁准确的最终答案 上下文注入 + 提示工程
🧠 二、系统架构与原理
2.1 整体流程图
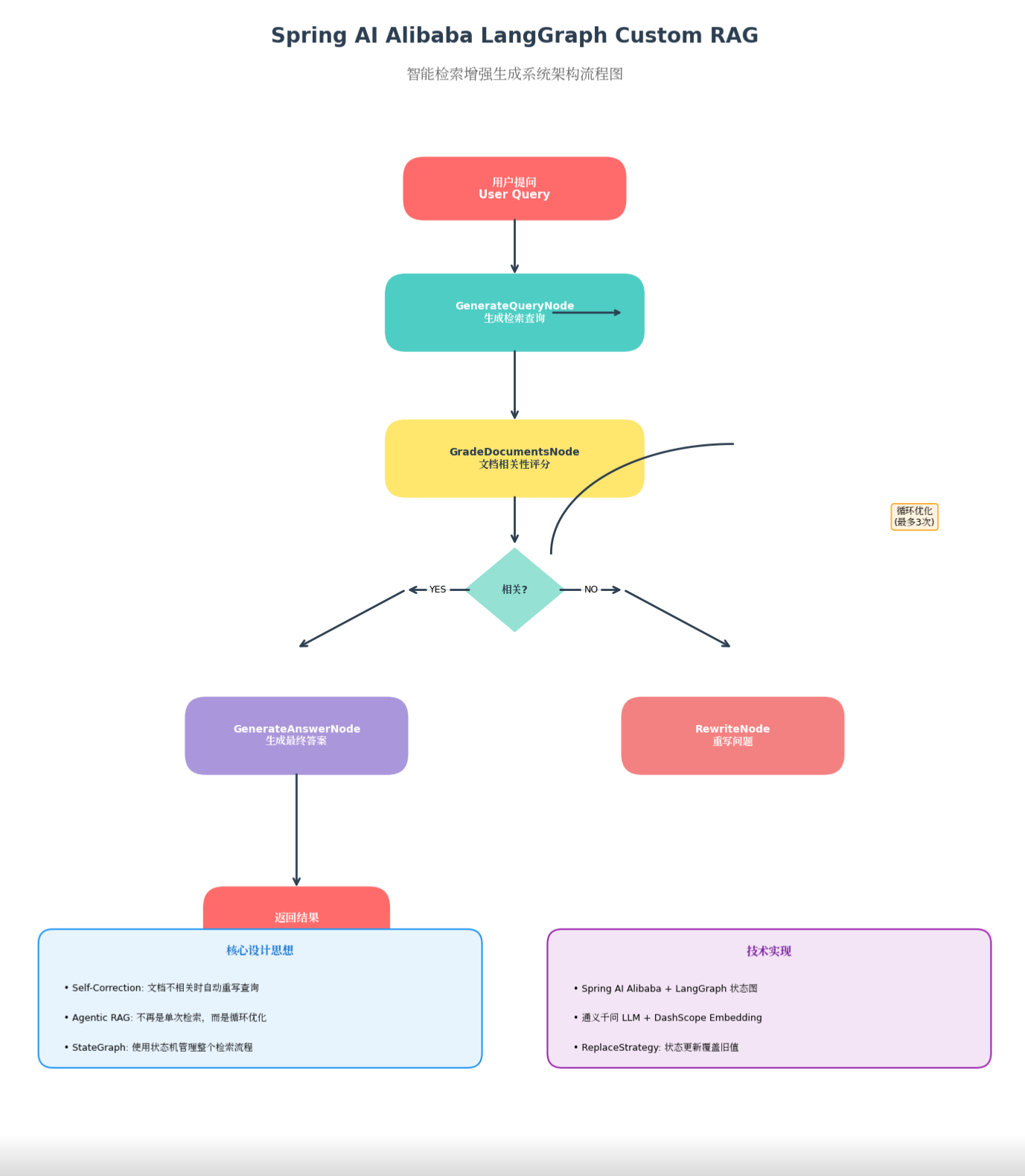
流程解读:
- 用户提问 → 接收原始问题
- GenerateQueryNode → LLM 将问题转换为检索查询(调用知识库工具)
- GradeDocumentsNode → 评估检索结果的相关性
- 条件判断 → 文档是否相关?
- YES → 进入 GenerateAnswerNode 生成答案 → 结束
- NO → 进入 RewriteNode 重写问题 → 循环回到 GenerateQueryNode(最多3次)
关键设计: 这个循环结构是 Agentic RAG 的核心——系统不再是"一锤子买卖"的单次检索,而是具备自我反思和优化能力的智能体。
2.2 状态图配置(RagGraphConfiguration)
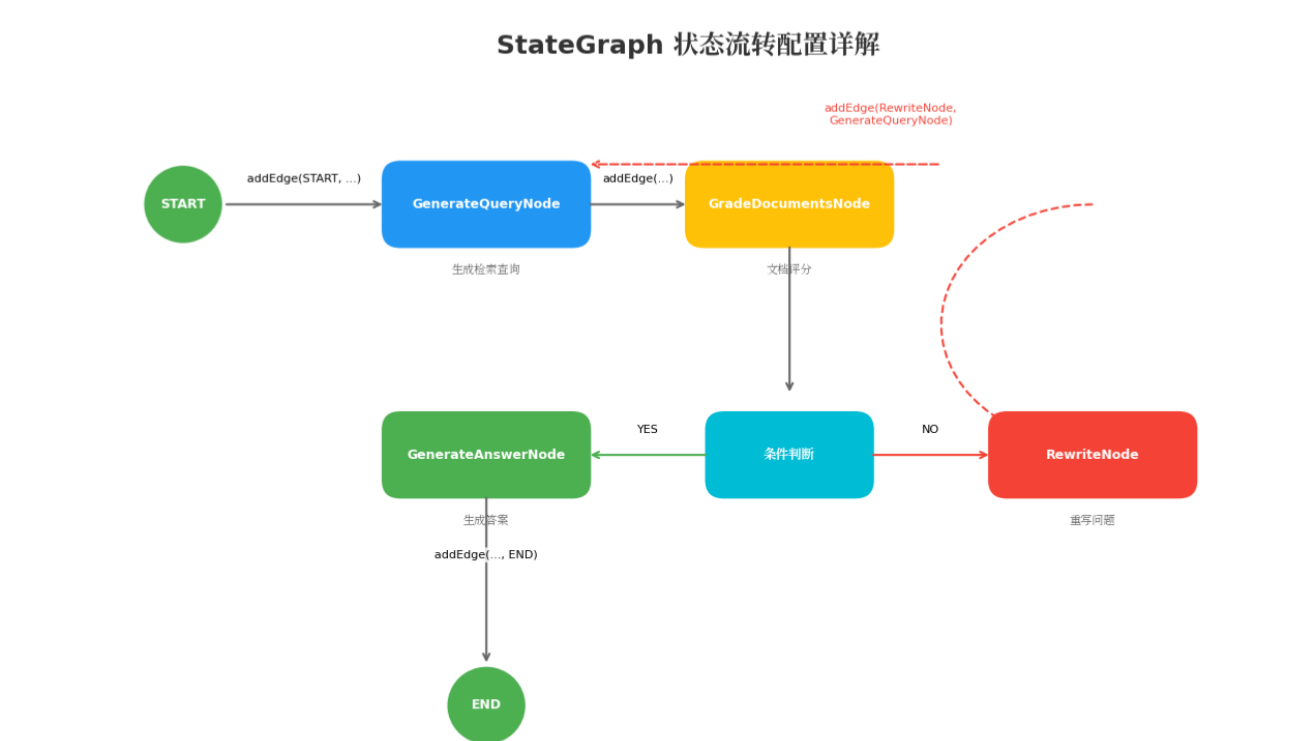
StateGraph stateGraph = new StateGraph(keyStrategyFactory)
// 添加4个处理节点
.addNode("GenerateQueryNode", node_async(generateQueryNode))
.addNode("GradeDocumentsNode", node_async(gradeDocumentsNode))
.addNode("RewriteNode", node_async(rewriteNode))
.addNode("GenerateAnswerNode", node_async(generateAnswerNode))
// 设置状态流转边
.addEdge(START, "GenerateQueryNode") // 起点 → 生成查询
.addEdge("GenerateQueryNode", "GradeDocumentsNode") // 生成查询 → 文档评分
.addConditionalEdges("GradeDocumentsNode", decideGradeResult) // 条件分支
.addEdge("GenerateAnswerNode", END) // 生成答案 → 结束
.addEdge("RewriteNode", "GenerateQueryNode"); // 重写 → 重新查询(循环边)
状态策略说明: 使用 ReplaceStrategy,每次状态更新会覆盖旧值。这意味着:
- 重写后的新问题会替换原始问题
- 重新检索的文档会替换之前的文档
- 系统始终基于最新状态进行决策
2.3 核心节点详解
1️⃣ GenerateQueryNode(生成查询节点)
作用: 让 LLM 调用知识库工具检索相关文档
核心代码:
// 关键点:internalToolExecutionEnabled(false)
// 作用:让 AI 只输出调用参数,不自动执行工具调用
chatClient.prompt(query)
.options(ToolCallingChatOptions.builder()
.internalToolExecutionEnabled(false) // 禁止自动执行
.build())
.call();
原理解释:
为什么要设置 internalToolExecutionEnabled(false)?
设置 行为 适用场景 true(默认) LLM 自动调用工具并返回结果 简单工具调用,无需干预 false LLM 只生成调用参数,需手动执行 需要获取中间结果进行额外处理
在本系统中,我们需要:
- 先获取检索结果
- 对结果进行评分(GradeDocumentsNode)
- 根据评分决定下一步
因此必须设置为 false,让 LLM 只生成调用参数,然后我们在代码中手动执行工具,获取原始检索结果供后续节点使用。
2️⃣ GradeDocumentsNode(文档评分节点)
作用: 判断检索到的文档是否与用户问题相关
实现逻辑:
String systemPrompt = """
你是一个评分员,评估检索到的文档与用户问题的相关性。
评分标准:
- 如果文档包含与问题相关的关键词或语义信息 → 返回 'yes'
- 如果文档与问题无关或信息不足 → 返回 'no'
文档:{content}
问题:{query}
只返回 'yes' 或 'no',不要其他解释。
""";
工作机制:
- 对每个检索到的文档单独评分
- 只要有一个文档被标记为
yes,就认为检索成功 - 如果全部文档都是
no,触发重写流程
3️⃣ RewriteNode(问题重写节点)
作用: 当文档不相关时,重新理解用户意图并改写查询
实现逻辑:
String systemPrompt = """
你是一个查询优化专家。请分析用户的原始问题,理解其潜在的语义意图,
然后提出一个更清晰、更具体、更适合检索的问题版本。
原始问题:{query}
请输出优化后的问题,要求:
1. 保留原始问题的核心意图
2. 使用更精确的关键词
3. 补充可能缺失的上下文信息
4. 更适合向量数据库检索
""";
为什么需要重写?
用户的问题往往:
- 口语化:“怎么用啊?” → 需要明确具体功能
- 模糊:“性能怎么样?” → 需要指明具体场景
- 缺少关键词:“报错怎么办?” → 需要知道具体错误类型
通过 LLM 重写,可以将模糊的自然语言转换为结构化的检索查询,显著提高检索准确率。
4️⃣ GenerateAnswerNode(答案生成节点)
作用: 基于相关文档生成最终答案
实现逻辑:
String systemPrompt = """
你是一个专业的技术文档助手。请使用以下检索到的上下文来回答用户问题。
回答要求:
1. 最多使用三个句子,保持答案简洁
2. 仅基于提供的上下文,不要添加外部知识
3. 如果上下文不足以回答问题,明确说明"信息不足"
4. 使用中文回答
问题:{query}
上下文:{content}
""";
设计考量:
- 简洁性:限制句子数量防止 LLM 幻觉
- 可追溯性:明确告知基于提供的上下文,便于溯源
- 诚实性:承认信息不足比编造答案更好
🚀 三、部署实操指南
3.1 环境准备
# 1. 克隆 Spring AI Alibaba 官方示例项目
git clone https://github.com/alibaba/spring-ai-alibaba.git
cd spring-ai-alibaba/examples/langgraph-custom-rag-example
# 2. 配置通义千问 API Key(从阿里云百炼控制台获取)
export AI_DASHSCOPE_API_KEY=your_api_key_here
# 验证环境变量
echo $AI_DASHSCOPE_API_KEY
获取百炼API Key ,参考前面博文吧。
3.2 配置文件(application.yml)
spring:
application:
name: langgraph-custom-rag-example
ai:
dashscope:
api-key: ${AI_DASHSCOPE_API_KEY:} # 从环境变量读取,避免硬编码
chat:
options:
model: qwen-turbo # 可根据需求更换为 qwen-plus/qwen-max
embedding:
options:
model: text-embedding-v3 # 向量嵌入模型
server:
port: 8080
# 日志级别(调试用)
logging:
level:
com.alibaba.cloud.ai: DEBUG
3.3 构建与启动
# 方式1:Maven 构建后运行
mvn clean package -DskipTests
java -jar target/langgraph-custom-rag-example-*.jar
# 方式2:直接 Maven 运行
mvn spring-boot:run
# 方式3:IDE 中运行主类
# 主类位置:com.alibaba.cloud.ai.example.langgraph.LanggraphCustomRagApplication
启动成功标志:
Started LanggraphCustomRagApplication in X.XXX seconds
Tomcat started on port(s): 8080 (http)
3.4 测试接口
# 测试1:使用默认问题
curl "http://localhost:8080/ai/rag/graph/call"
# 测试2:自定义问题(URL 编码)
curl "http://localhost:8080/ai/rag/graph/call?message=Spring+AI+Alibaba+环境要求"
# 测试3:复杂问题(观察重写效果)
curl "http://localhost:8080/ai/rag/graph/call?message=怎么配置向量数据库"
# 使用 jq 美化输出
curl "http://localhost:8080/ai/rag/graph/call" | jq .
预期响应格式:
{
"answer": "Spring AI Alibaba 需要 Java 17+ 和 Maven 3.6+...",
"retrievedDocuments": 3,
"rewriteCount": 0,
"executionTimeMs": 2500
}
⚠️ 四、问题发现与替代方案
❌ 问题1:KnowledgeTool 硬编码 URL
原代码问题:
private final List<String> urls = List.of(
"https://java2ai.com/docs/quick-start" // 硬编码,且可能失效
);
问题分析:
- 文档 URL 写死在代码中,修改需重新编译
- URL 失效会导致知识库为空
- 不支持动态添加新文档源
替代方案:支持外部配置 + 动态加载
# application.yml
rag:
knowledge:
urls:
- https://java2ai.com/docs/quick-start
- https://docs.spring.io/spring-ai/reference/
- https://help.aliyun.com/document_detail/xxx.html
refresh-interval: 86400 # 刷新间隔(秒)
@Component
public class ConfigurableKnowledgeTool {
@Value("${rag.knowledge.urls}")
private List<String> urls;
// 支持动态更新 URL 列表
public void updateUrls(List<String> newUrls) {
this.urls = newUrls;
refreshKnowledgeBase();
}
}
❌ 问题2:文档只在启动时加载一次
原代码问题:
@PostConstruct
void init() {
// 启动时加载,之后不再更新
simpleVectorStore.add(splitDocuments);
}
问题分析:
- 知识库内容不会随源文档更新而更新
- 需要重启应用才能加载新文档
- 长时间运行后知识库可能过时
替代方案:支持热更新或定时刷新
@Component
public class KnowledgeRefreshScheduler {
@Scheduled(cron = "0 0 2 * * ?") // 每天凌晨2点刷新
public void scheduledRefresh() {
log.info("开始定时刷新知识库...");
refreshKnowledge();
}
// 手动刷新接口(供管理员调用)
@GetMapping("/admin/refresh-knowledge")
public ResponseEntity<String> manualRefresh() {
refreshKnowledge();
return ResponseEntity.ok("知识库已刷新");
}
private void refreshKnowledge() {
// 1. 清空旧向量
vectorStore.clear();
// 2. 重新下载文档
List<Document> newDocs = fetchDocuments();
// 3. 重新分词和向量化
vectorStore.add(documentSplitter.split(newDocs));
log.info("知识库刷新完成,共加载 {} 条文档", newDocs.size());
}
}
❌ 问题3:文档评分依赖简单字符串匹配
原代码:
if (content.contains("yes")) { ... }
if (content.contains("no")) { ... }
问题分析:
- LLM 输出格式不固定,可能返回 “YES”、“Yes”、“yes”、“是”、“相关” 等
- 简单字符串匹配容易误判
- 无法处理模糊回答(如 “部分相关”)
替代方案:更健壮的解析逻辑
private boolean parseRelevance(String response) {
if (response == null || response.trim().isEmpty()) {
return false;
}
String lower = response.toLowerCase().trim();
// 正向关键词匹配(支持多种表达)
boolean isRelevant = lower.matches(".*\\b(yes|y|true|1|relevant|相关|是|肯定)\\b.*");
// 负向关键词匹配(排除否定情况)
boolean isIrrelevant = lower.matches(".*\\b(no|n|false|0|irrelevant|不相关|否|否定)\\b.*");
// 如果同时包含正负向词,根据位置判断(取最后的判断)
if (isRelevant && isIrrelevant) {
int lastYes = Math.max(
lower.lastIndexOf("yes"),
lower.lastIndexOf("相关")
);
int lastNo = Math.max(
lower.lastIndexOf("no"),
lower.lastIndexOf("不")
);
return lastYes > lastNo;
}
return isRelevant;
}
❌ 问题4:缺少重试循环保护
问题分析:
- 如果文档一直不相关,系统会无限循环(Rewrite → Query → Grade → Rewrite…)
- 可能导致:
- API 费用激增
- 响应时间无限延长
- 系统资源耗尽
替代方案:添加最大重试次数
@Component
public class RagStateManager {
private static final int MAX_RETRIES = 3;
private static final String RETRY_COUNT_KEY = "retry_count";
public Map<String, Object> decideNextStep(State state) {
Map<String, Object> result = new HashMap<>();
int retryCount = state.value(RETRY_COUNT_KEY, 0);
boolean isRelevant = gradeDocuments(state);
if (isRelevant) {
// 文档相关,生成答案
result.put("next_node", "GenerateAnswerNode");
result.put(RETRY_COUNT_KEY, 0); // 重置计数
} else if (retryCount >= MAX_RETRIES) {
// 超过最大重试次数,强制生成答案(可能质量较低)
log.warn("达到最大重试次数 {},放弃优化直接生成答案", MAX_RETRIES);
result.put("next_node", "GenerateAnswerNode");
result.put("fallback", true); // 标记为降级回答
} else {
// 继续重写优化
result.put("next_node", "RewriteNode");
result.put(RETRY_COUNT_KEY, retryCount + 1);
log.info("文档不相关,第 {} 次重写优化", retryCount + 1);
}
return result;
}
}
❌ 问题5:SimpleVectorStore 是内存存储
问题分析:
SimpleVectorStore基于内存的 HashMap 实现- 应用重启后所有向量数据丢失
- 无法支持多实例部署(每个实例数据不一致)
- 不适合生产环境
替代方案:使用云端向量存储
Maven 依赖:
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-vector-store</artifactId>
<version>1.0.0</version>
</dependency>
配置代码:
@Configuration
public class VectorStoreConfig {
@Bean
public VectorStore vectorStore(DashScopeApi dashScopeApi) {
// 使用阿里云 DashScope 向量存储服务
return DashScopeVectorStore.builder(dashScopeApi)
.initializeSchema(true) // 自动创建索引
.build();
}
// 或者使用 Redis 向量存储(需额外配置)
@Bean
@Profile("redis")
public VectorStore redisVectorStore(RedisTemplate<String, String> redisTemplate) {
return RedisVectorStore.builder(redisTemplate)
.initializeSchema(true)
.build();
}
}
对比:
| 存储方式 | 数据持久化 | 多实例共享 | 生产适用 | 复杂度 |
|---|---|---|---|---|
| SimpleVectorStore | ❌ | ❌ | ❌ | 低 |
| DashScopeVectorStore | ✅ | ✅ | ✅ | 中 |
| RedisVectorStore | ✅ | ✅ | ✅ | 中 |
| PostgreSQL/PGVector | ✅ | ✅ | ✅ | 高 |
📝 五、关键配置汇总
| 配置项 | 说明 | 示例值 | 必填 |
|---|---|---|---|
AI_DASHSCOPE_API_KEY |
通义千问 API Key | sk-xxxxxx |
✅ |
server.port |
服务端口 | 8080 |
❌ |
spring.ai.dashscope.chat.options.model |
对话模型 | qwen-turbo |
❌ |
spring.ai.dashscope.embedding.options.model |
嵌入模型 | text-embedding-v3 |
❌ |
rag.knowledge.urls |
知识库 URL 列表 | 见上文 | ❌ |
rag.max-retries |
最大重写次数 | 3 |
❌ |
logging.level.com.alibaba.cloud.ai |
日志级别 | DEBUG |
❌ |
✅ 六、完整启动命令
# 一键启动(Linux/Mac)
export AI_DASHSCOPE_API_KEY=your_key_here && \
cd spring-ai-alibaba/examples/langgraph-custom-rag-example && \
mvn clean spring-boot:run
# Windows PowerShell
$env:AI_DASHSCOPE_API_KEY="your_key_here"
cd spring-ai-alibaba/examples/langgraph-custom-rag-example
mvn clean spring-boot:run
# 测试验证
curl "http://localhost:8080/ai/rag/graph/call?message=Spring+AI+Alibaba+环境要求"
🎯 总结
阿里巴巴的这个项目是一个优秀的 Agentic RAG 示例,通过 LangGraph 状态图 实现了自我校正能力。相比传统 RAG 的单次检索模式,它的核心亮点在于:
- 智能循环优化:通过
GradeDocumentsNode的条件分支决策,让系统能够自我反思和优化 - 查询重写策略:当检索失败时,不是简单放弃,而是通过 LLM 重写查询,用不同角度再次尝试
- 状态机管理:使用
StateGraph清晰定义整个流程,便于扩展和维护
适用场景:
- 企业知识库问答(文档质量参差不齐)
- 技术文档助手(需要精确检索)
- 智能客服(需要高准确率回答)
生产环境建议:
- 替换内存向量存储为持久化存储
- 添加重试次数保护
- 实现知识库热更新机制
- 增加评分解析的健壮性

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)