Karpathy 提出的 LLM Wiki:让知识真正复利增长的革命性方法
传统 Wiki 死于维护成本,LLM Wiki 生于自动化。当 AI 开始为你"记账",知识积累第一次变得可持续。
为了方便大家快速用起来,我创建了一个 llm-wiki skill 已上传到了 clawhub,可以自然语言直接下达指令管理你的 LLM Wiki,文章中有介绍。

(本文基于 Andrej Karpathy 的 LLM Wiki 概念撰写,核心思想归原作者所有)
一个让所有知识管理者共鸣的痛点
你有没有过这样的经历?
兴冲冲地开始搭建个人知识库,语雀、Notion、Obsidian、Roam Research 试了个遍。刚开始几周热情满满,每条笔记都精心分类、打标签、做双向链接。
然后……生活来了。
项目要赶工,孩子要照顾,周末想休息。等终于有空回到知识库时,发现上次整理的内容已经有些陌生,想补充新想法却要先花半小时回忆之前的结构。
更别提那些繁琐的维护工作:更新交叉引用、检查一致性、修复断链、合并重复内容……
这就是传统 Wiki 的宿命——维护成本的增长速度,永远超过它创造价值的速度。
大多数人最终回到了最原始的状态:收藏夹里躺着几百篇"稍后阅读"的文章,笔记软件里散落着零散的片段,知识依旧是大脑里的模糊印象。
直到 Andrej Karpathy 提出了一个完全不同的思路。
(当然,我用 LLM Wiki 主要是用来深度理解我的代码结构,辅助编程,后文也有ji)
Karpathy 的洞见:让 LLM 当图书管理员
2026 年初,前 OpenAI 研究副总裁、特斯拉 AI 总监 Andrej Karpathy 在一篇博客中提出了 LLM Wiki 的概念。
这个想法简单到让人拍大腿:
为什么不让 LLM 来维护 Wiki 呢?
传统 Wiki 需要人类做的那些繁琐工作——总结摘要、交叉引用、一致性检查、内容更新——恰恰是 LLM 最擅长且不会感到厌倦的事情。
而人类真正擅长的——筛选资料、提出好问题、判断价值、思考意义——LLM 反而做不了。
⛳️ 角色互换,各司其职
在 Karpathy 的架构里,LLM 是那个不知疲倦的图书管理员(他称之为"MLS"——Master of Library Science),负责所有"记账"工作。而你,是知识的策展人,负责决定什么值得进入知识库。
这个看似简单的角色转换,解决了一个困扰知识管理领域几十年的根本问题。
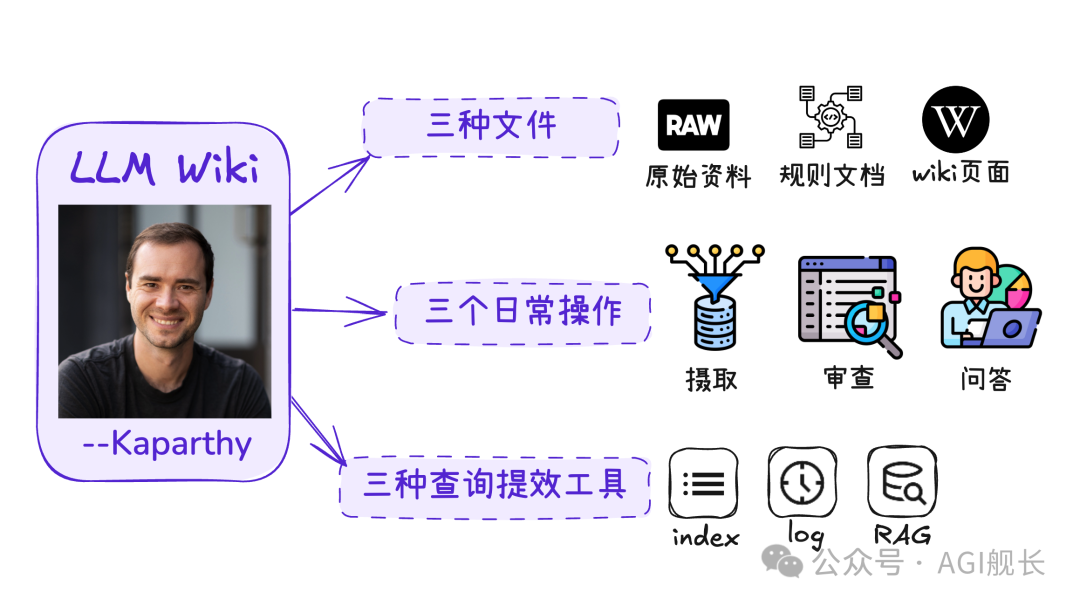
三层架构:原始资料、知识层、配置层
Karpathy 的 LLM Wiki 采用清晰的三层架构:
📁 第一层:原始资料(Raw Sources)
这是你的"事实来源",包括:
-
论文、文章、博客
-
书籍摘录
-
视频、播客笔记
-
会议记录、对话
关键规则:只读,不可变。
LLM 可以读取它们,但绝不修改。这保证了知识体系有一个可靠的事实基础,不会因为 LLM 的"幻觉"而污染原始信息。
📄 第二层:知识层(Wiki Pages)
这是 LLM 生成和维护的结构化知识库,包含:
-
来源摘要页:每个资料的要点总结
-
实体页:人物、项目、书籍等
-
概念页:方法、理论、模型等
-
比较分析页:不同观点的对比
-
总览页:主题综述和综合
关键规则:LLM 全权负责。
你几乎不亲手写 Wiki 内容。LLM 创建页面、更新交叉引用、维护一致性。你只负责阅读、提问、指导方向。
⚙️ 第三层:配置层(Schema)
这是一个元文件(如 TheSchema.md),告诉 LLM:
-
Wiki 的结构和命名规范
-
导入新资料的工作流程
-
回答问题的检索策略
-
定期健康检查的规则
关键规则:人机共同进化。
你和 LLM 在实践中不断优化这个配置文件,让它越来越适合你的领域和习惯。
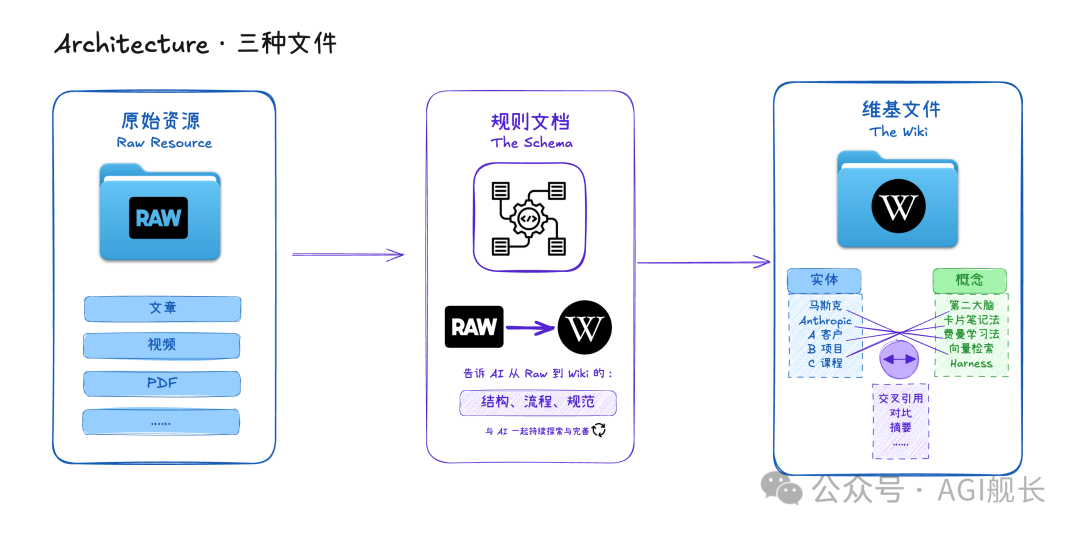
三个核心操作:Ingest、Query、Lint
使用 LLM Wiki 的日常操作极其简单:
1️⃣ Ingest(导入)
你把新资料放进 raw/ 目录,然后告诉 LLM:"请处理这个。"
LLM 会:
-
阅读并总结核心要点
-
创建来源摘要页
-
更新相关的实体和概念页
-
建立交叉引用
-
记录到操作日志
一个来源可能影响 10-15 个 Wiki 页面。 这些工作如果让人类做,可能需要几小时;LLM 几分钟完成,而且不会抱怨。
2️⃣ Query(查询)
你在 Wiki 中提问,LLM 会:
-
搜索相关页面
-
综合整理答案
-
附上来源引用
-
可选:将有价值的问答写回为新页面
关键洞察:优秀的问答本身就是知识资产。
你提出的对比分析、发现的关联、总结的模式——这些不应该消失在聊天记录里,而应该成为 Wiki 的一部分,像导入的资料一样持续积累。
3️⃣ Lint(健康检查)
定期请 LLM 对 Wiki 做体检:
-
发现页面之间的矛盾
-
识别被新资料取代的过时内容
-
找出没有外部链接的"孤立页面"
-
建议补充缺失的交叉引用
-
提出可以进一步研究的问题
这就像代码仓库的 linter,防止知识库在扩张过程中腐化。
为什么这次不一样:复利效应的关键
RAG 系统和 NotebookLM 这类工具,每次查询都是从原始文档重新检索、重新拼凑。知识没有积累,每次都是零启动。
LLM Wiki 的核心差异在于:
The wiki is a persistent, compounding artifact.(Wiki 是持久的、可复利的产物。)
知识只需要"编译"一次,之后保持更新。你添加的每一个来源、提出的每一个问题,都让 Wiki 更丰富。交叉引用已经存在,矛盾已经被标记,综合信息已经反映了你读过的所有内容。
这就是复利。
想象一下,如果你坚持使用这个方法一年:
-
你有几百个来源的摘要
-
数百个相互链接的概念和实体页面
-
完整的知识演化日志
-
一个可以随时提问的"第二大脑"
而且,维护成本几乎为零——因为 LLM 在做那些繁琐的工作。
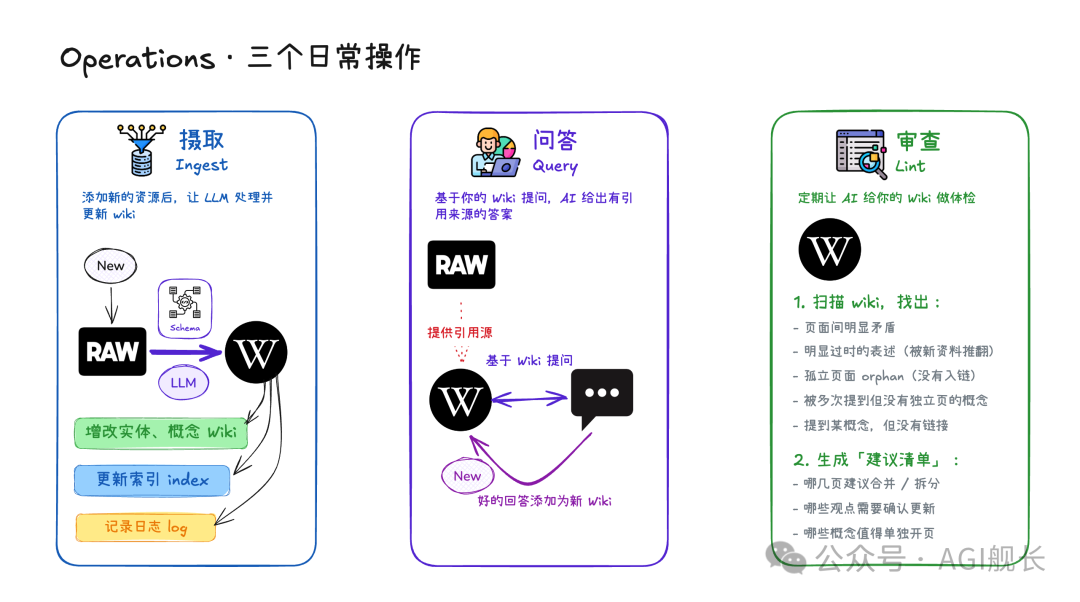
从理论到实践:一个中国开发者的技能实现
Karpathy 的博客虽然提出了完整的概念框架,但具体的实现细节需要每个用户自己去摸索。
这正是技术大佬展现价值的地方。
国内 AI 全栈知识博主 AGI 舰长 在深入研究 Karpathy 的博客后,不仅搭建了自己的 LLM Wiki,还将其封装成一个可复用的 Skill,发布到了 Clawhub 平台上,无论你在 claude code 编程领域、还是 openclaw 日常办公领域都可以使用。
这个名为 llm-wiki 的技能,让任何使用 OpenClaw 或类似 AI 代理系统的用户,都能快速部署自己的 LLM Wiki。
🔗 Clawhub 链接:
https://clawhub.ai/javastarboy/llm-wiki-obsidian
🔗 AGI 舰长的其他开源 Skill 仓库(含 llm wiki 示例)
https://github.com/javastarboy/open-skills
(图:clawhub 上的 skill 介绍)
在你的工程目录下,给 claude code 发送消息,让它基于 llm-wiki 技能生成代码仓库的 wiki 👇
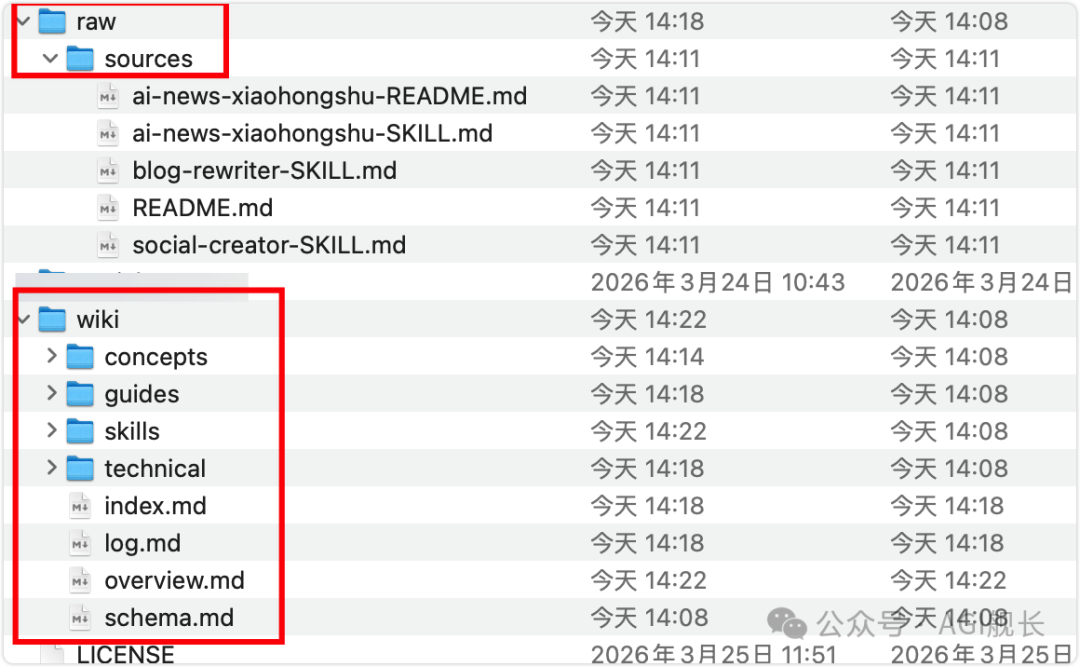
(图:skill 生成的 wiki 目录结构)
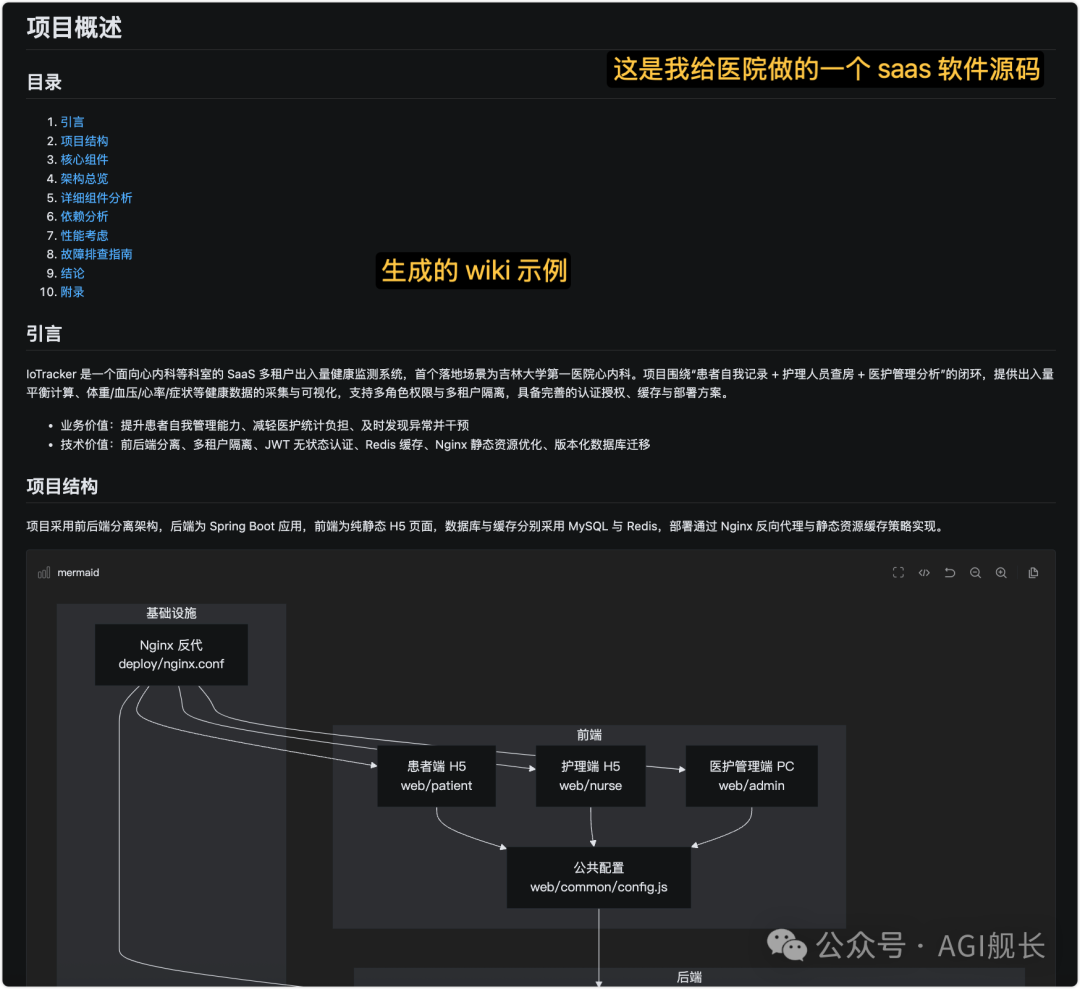
(图:llm-wiki skill 生成的文件示例)
⛳️ 技术亮点
-
Obsidian 原生集成
-
充分利用双向链接、标签、图谱视图
-
本地 Markdown 文件,版本控制友好
-
丰富的插件生态(Marp 幻灯片、Dataview 查询等)
-
-
结构化页面示例
├── raw/ # 原始资料(只读)
│ ├── sources/ # 来源摘要
├── wiki/
│ ├── entities/ # 人物、项目等实体
│ ├── concepts/ # 方法、理论等概念
│ ├── comparisons/ # 对比分析
│ ├── overview/ # 主题综述
│ ├── index.md # 内容索引
│ └── log.md # 操作日志
│ └── schema.md # 元文件,Wiki 的结构和命名规范-
自动化工作流
-
导入时自动创建/更新相关页面
-
查询时自动检索索引并附引用
-
定期 Lint 保持健康度
-
-
可追溯性设计
-
log.md记录所有操作的时间序列 -
每个 Wiki 页面都有来源引用
-
Git 版本历史免费获得
-
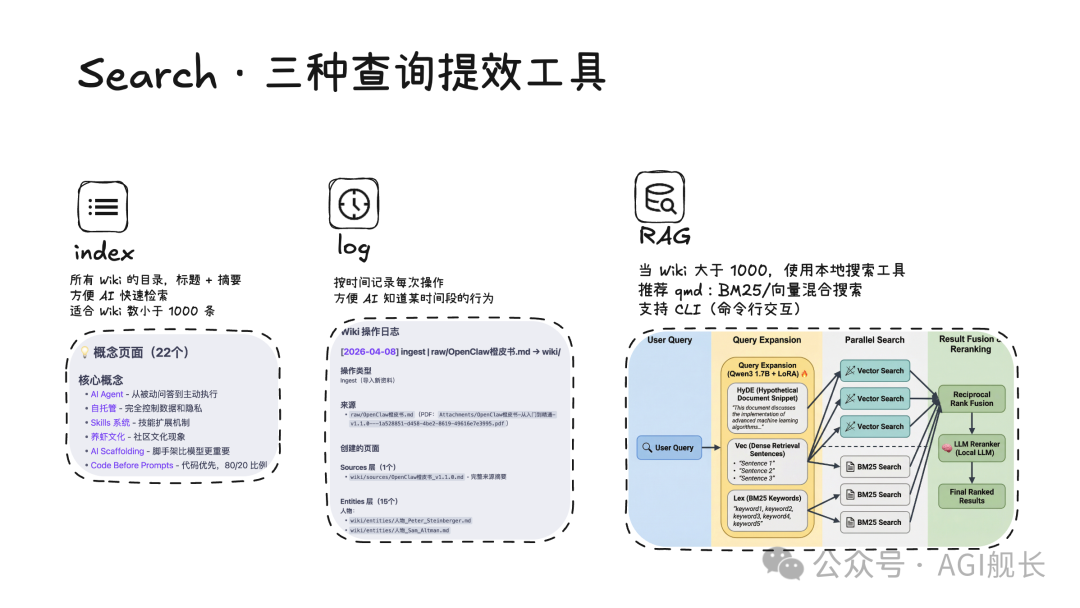
使用示例
# 导入新资料
"请基于 raw/xxx.pdf 进行 Ingest"
# 查询知识
"XXX 和 YYY 有什么区别?"
# 健康检查
"请对 wiki 做一次 Lint"这个技能的价值在于:把 Karpathy 的抽象概念,变成了可执行的具体工具。
任何人都可以:
-
从 Clawhub 安装
llm-wiki技能 -
在自己的项目目录下运行
-
几分钟内获得一个完整的 LLM Wiki 系统
无需自己摸索目录结构、页面格式、工作流程——所有最佳实践都已经封装好了。
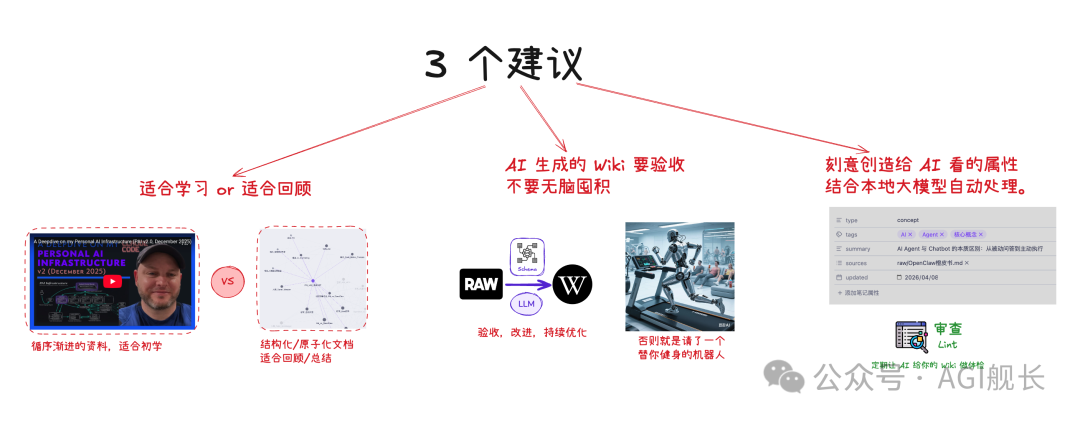
适用场景:远不止个人知识管理
Karpathy 在博客中列举了多个应用场景:
🎯 个人成长
跟踪自己的目标、健康、心理状态。记录日记、文章、播客笔记,构建一个结构化的自我认知体系。
📚 深度学习
对某个主题进行数周或数月的深入研究。阅读论文、文章、报告,逐步构建一个包含不断演进论点的综合 Wiki。
📖 读书笔记
边读边整理章节,创建人物、主题、情节线索的页面。读完一本书,你拥有一个配套的粉丝 Wiki。
🏢 团队知识库
由 LLM 维护的内部 Wiki,内容来源于 Slack 讨论、会议记录、项目文档。Wiki 之所以能保持最新,是因为 LLM 在做团队中其他人都不愿意做的维护工作。
📊 竞争分析、尽职调查、旅行计划、课程笔记……
任何需要你随时间积累知识,并且希望将其整理成册而非散乱无章的场景,都适用。
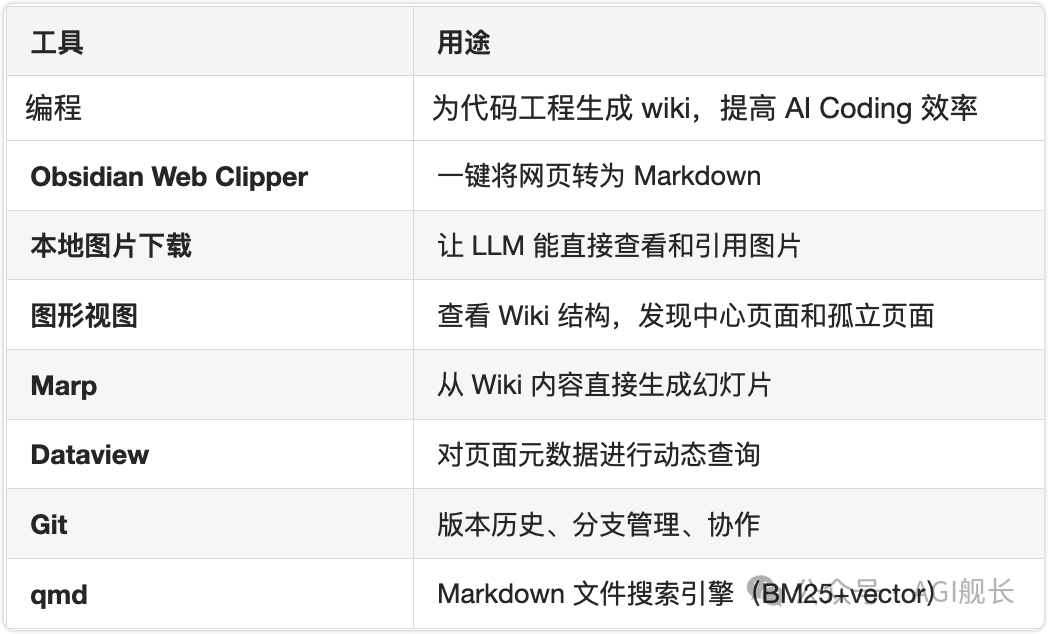
工具与技巧:让体验更流畅
Karpathy 和实践者们总结了一些实用技巧:
思想渊源:从 Memex 到 LLM Wiki
Karpathy 在博客结尾提到了一个有趣的历史脉络:
这个想法在精神上与范内瓦·布什的 Memex(1945) 一脉相承。
1945 年,布什在《大西洋月刊》发表《诚如所思》(As We May Think),描述了一个名为 Memex 的设备:一个个人化的、精心维护的知识库,文档之间存在关联。
布什的设想比后来的互联网更接近 LLM Wiki:
-
私密的,而非公开的
-
主动维护的,而非被动浏览的
-
文档之间的关联与文档本身同样重要
但布什没能解决的问题是:谁来维护?
手动维护一个庞大的关联知识库,对人类来说负担太重。这正是维基百科(Wikipedia)需要成千上万志愿者、而个人 Wiki 往往半途而废的原因。
LLM 解决了这个维护成本问题。
75 年后,技术终于让布什的愿景成为普通人可及的现实。
结语:开始构建你的复利知识库
LLM Wiki 不是一个产品,而是一个模式。
你不需要等待某个完美的工具。你可以:
-
创建一个文件夹
-
定义你的三层结构
-
写一个 Schema 文件告诉 LLM 规则
-
开始导入第一个资料
或者,直接用 AGI 舰长已经封装好的 llm-wiki 技能,几分钟内启动。
重要的是开始。
知识复利的奇迹,只发生在那些持续积累的人身上。而这一次,你不再孤单——你有一个不知疲倦的图书管理员,帮你处理所有繁琐的维护工作。
你只需要做人类最擅长的事:
-
寻找有价值的资料
-
提出深刻的问题
-
思考这一切的意义
剩下的,交给 LLM。
📌 延伸阅读与资源
-
Karpathy 博客原文:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94
-
LLM Wiki 教程:
-
llm-wiki 技能源码:
https://github.com/javastarboy/open-skills/tree/main/llm-wiki
-
从 Claw hub 安装 llm-wiki 技能:
🎯 往期推荐👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)