【内涵】VIT解读
[内涵]VIT源码解读
前言
VIT现在几乎已经取代了reset在AI1.0时代的地位,成为了llm/vllm领域中大家默认使用的backbone。本篇文章是通过源码的角度,来对vit这一部件的梳理。这篇文章是由google的研究团队发表在ICLR2021会议上,虽然论文附带了源码链接vision_transformer,但是这里并没有基于该源码进行学习,而是选择了另外一个非官方的开源版本vit-pytorch。原因是官方的版本是基于jax并非pytorch,从star和fork数量来看,后者的pytorch版本也是都2倍于前者。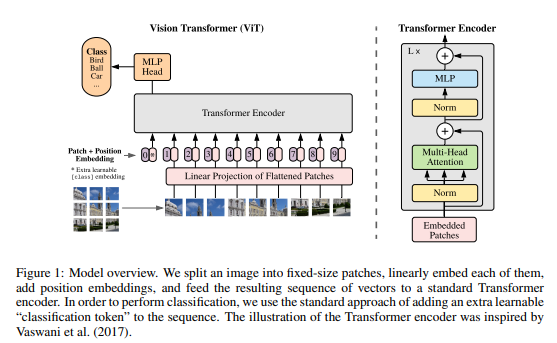
vit的motivation很简单:通过已经在nlp领域大放光彩的transformer来做视觉领域的分类任务。
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
而vit的源码位于vit.py
带着问题来阅读源码
问题1:这里的learnable cls token是如何做的?
self.cls_token = nn.Parameter(torch.randn(num_cls_tokens, dim))
论文中提到learnable,在代码的层面实现就是一个nn.Parameter的tensor变量。关于nn.Parameter和普通tensor的对比,可以看【内涵】你所需要的三种变量及pytorch中对应的三种tensor
问题2:这里的position encoding是如何做的?
self.pos_embedding = nn.Parameter(torch.randn(num_patches + num_cls_tokens, dim))
同样的,vit中对于position encoding也是通过一个nn.Parameter变量来实现的。一方面,也就是说,这里没有使用transformer论文中提到的sine and cosine functions of different frequencies,而是用了这种可学习的方式;另一方面这里可以看到,此处的pos_embedding是一种非常hard的方式,无法处理超过num_patches的序列,因此这是一个原版本的弊端,后续有很多关于此点的改进,且当前vllm中也都是对这部分进行特别的处理。
问题3:transformer encoder的tensor流是如何的?
# 输入
[1, 3, 256, 256]
↓
# Patch Embedding
[1, 64, 3072] # Rearrange切块
[1, 64, 3072] # LayerNorm (3072)
[1, 64, 1024] # Linear(3072→1024)
[1, 64, 1024] # LayerNorm (1024)
↓
# 添加 CLS Token
[1, 65, 1024] # cat([cls_token, patches])
↓
# 位置编码
[1, 65, 1024] + pos_embedding
[1, 65, 1024] Dropout(0.1)
↓
# Transformer Layer 1 (共6层)
## Attention模块
[1, 65, 1024] # 输入
[1, 65, 1024] LayerNorm
[1, 65, 3072] Linear(1024→3072) to_qkv
[1, 65, 1024] chunk → q,k,v 各[1,65,1024]
[1, 16, 65, 64] reshape+transpose (16 heads, 64 dim)
[1, 16, 65, 65] q @ k.transpose
[1, 16, 65, 65] /√64 + softmax + dropout
[1, 16, 65, 64] attn @ v
[1, 65, 1024] transpose+reshape
[1, 65, 1024] Linear(1024→1024) to_out + dropout
[1, 65, 1024] + input (残差)
## FeedForward模块
[1, 65, 1024] LayerNorm
[1, 65, 2048] Linear(1024→2048)
[1, 65, 2048] GELU + dropout
[1, 65, 1024] Linear(2048→1024) + dropout
[1, 65, 1024] + input (残差)
↓
# Transformer Layer 2-6 (重复上述)
[1, 65, 1024] # 每层输入输出相同
↓
# 最终输出
[1, 65, 1024] LayerNorm
[1, 1024] x[:, 0, :] 提取CLS token
[1, 1000] Linear(1024→1000) 分类头
这里比较有意思的是,它最后是提取cls_token来做分类的。(这个蛮有意思的,如果不要cls token,直接接一个linear层,把所有token降维可以吗?)
问题4:vit的loss是如何做的?
因为最后一部分的是一个B*CLS_NUM的tensor,那么显然接一个softmax loss即可。
这里有一个疑惑:我们为什么需要cls token来做class head,似乎必要性不大。因为我也可以用[1, 64, 1024], 然后接一个linear层,降维到[1, 1000], 然后送入softmaxloss层。事实上,这是一个确实的点,因为作者在附录D.3 HEAD TYPE AND CLASS TOKEN中讨论了这一点,只不过他对比的做法是[1, 64, 1024], 然后接一个global average pooling层,降维到[1, 1, 1024], 然后接一个[1, 1000], 这样做的好处是不需要额外的参数量。实验下来,两者的指标是一致的。但是,要说明的是如果用GAP(Global average pooling)这种方法,使用原始的学习率是指标很低的(对应下图中的黄色线),可以理解为,通过调参学习率,两种做法无差别。(注意:这里在之前的对齐公司的自研的检测库指标的时候,最终发现也是学习率和学习方法这样不被人注意的点起了大头作用,大概有6~7个mAP这样的差距,所以深度学习真的是一个实验的学科)
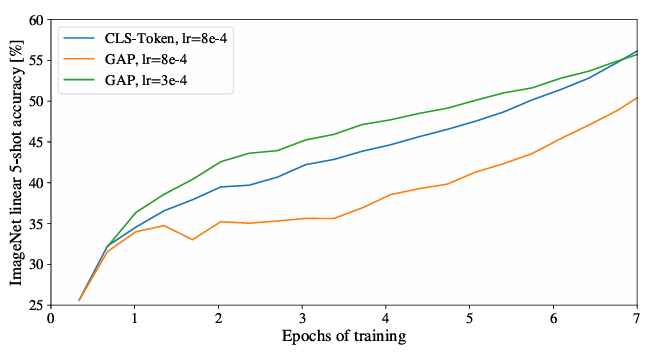
如果是自己想,可能大概率是没有cls token,然后[1, 64, 1024]接一个linear层降维到[1, 1000]。这样做应该也可以,但是这样有一个缺点就是参数量会多60+M左右。所以对比下来,cls-token就显得更加新奇和优雅了,而global average pool层也是一种比自己的直觉跟家节省参数的方法。这里记录下来,可以扩展自己的思路。
这里突然想到,如果使用了global average pool层,那么的话,就可以消除不同h,w分辨率的影响,那么在CNN时代,resnet这种网络岂不是可以在训练的时候,以一种可变的分辨率来训练(就像yolo的多尺度训练一样)。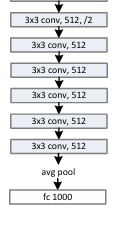
回头再去看resnet论文种的网络图,确实是avg pool层来做衔接的。再在网上查阅了相关说法,发现resnet这种CNN网络确实可以多尺度训练的(一种做法是适用global average pool层;另外一种做法是使用AdaptiveAveragePool层,它的做法是将不同分辨率的h,w,池化到固定的特征维度),算是加深了一下认知了吧。但是resnet在imagenet上的pretrain的时候,确实是使用了固定的分辨率(224*224),所以这可能是一个历史遗留问题,并非想象的那么严谨。
问题5:vit的缺陷由哪些?
缺陷也很明显,对于图像分辨率的限定太固定啦。例如当前QWenvl在其vit部分用的是一个改良版本的NaViT。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)