世界动作验证器:通过前向-逆向不对称性实现自我改进的世界模型
26年4月来自Stanford、UCSD、CMU、Google DeepMind和Harvard的论文“World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry”。
通用世界模型有望实现可扩展的策略评估、优化和规划,但要达到所需的鲁棒性水平仍然充满挑战。与主要关注最优动作的策略学习不同,世界模型需要在更广泛的次优动作范围内保持可靠性,而这些次优动作往往无法被动作标注的交互数据充分覆盖。为了应对这一挑战,提出世界动作验证器(WAV),该框架使世界模型能够识别自身的预测误差并进行自我改进。其核心思想是将基于动作的状态预测分解为两个因素——状态合理性和动作可达性——并分别进行验证。
由于两个潜在的不对称性,这些验证问题比预测未来状态要容易得多:动作相关数据的可用性更高,以及动作相关特征的维度更低。利用这些不对称性,通过以下方式增强世界模型:(i)从视频语料库中获得的多样化子目标生成器;(ii)从状态特征子集中推断动作的稀疏逆模型。通过强制执行生成的子目标、推断的动作和前向展开之间的循环一致性,WAV 为现有方法通常失效的、探索不足的领域提供一种有效的验证机制。在涵盖 MiniGrid、RoboMimic 和 ManiSkill 的九项任务中,该方法实现了两倍的样本效率提升,同时将下游策略性能提高了 18%。
世界动作验证器(WAV),该框架使世界模型能够验证自身的预测误差,并通过非对称的前向-逆向循环进行自我改进。其核心思想是将验证问题分解为更易于处理的子问题。具体而言,将动作条件状态预测分解为两个互补的组成部分:状态合理性,即预测状态在视觉和物理上是否合理;以及动作可达性,即在给定动作下预测状态转换是否可行。这种分解不仅允许分别验证每个因素,而且还揭示了两个关键的不对称性:(i)更广泛的无动作数据可用性:状态合理性可以使用不带动作标签的互联网视频进行验证,这些视频远比用于训练世界模型的带动作标签的机器人交互数据丰富得多;(ii)动作相关特征的维度更低:动作可达性可以基于与动作相关的状态特征子集进行验证,这些特征的维度远低于世界模型必须预测的完整状态。受这些不对称性的启发,为世界模型添加两个额外的组件:一个是从视频语料库中获取的多样化子目标生成器,以及一个稀疏逆模型,该模型经过训练可以从学习到的状态特征子集中推断动作。这两个组件共同构成一个自改进循环,该循环围绕着提出的子目标、推断出的动作和前向展开展开,其中提出的子目标与预测状态之间的一致性提供一种有效的验证机制(如图 1所示)。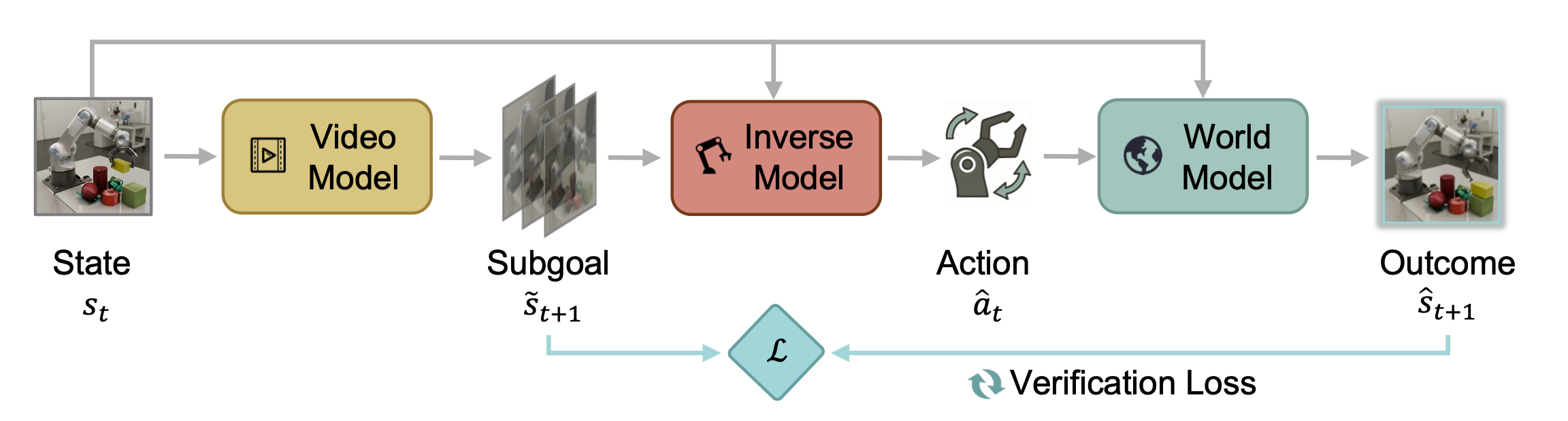
理论上,通过稀疏逆过程进行验证比密集的前向生成更容易,尤其是在高维随机环境中。实证上,在涵盖 MiniGrid [18]、RoboMimic [122] 和 ManiSkill [78] 的九个任务上评估 WAV。与现有方法相比,WAV 将世界模型的样本效率提高 2 倍,并将下游策略性能提升 18% 以上。结果表明,利用前向和逆向动态之间的不对称性可能是实现自改进世界模型的一种很有前景的方法。
世界模型在基于动作标注的交互数据时表现出色,然而大规模收集此类数据的成本往往高得令人望而却步。世界动作验证器(WAV),是一个自改进框架,它使世界模型能够识别自身的预测误差,并优先探索最具信息量的交互。首先在半监督设置下形式化验证问题,然后将其分解为两个更易于处理的子问题,最后将它们耦合到一个自改进循环中。
初步研究:世界模型的半监督验证
将世界模型 𝑓_𝜃 视为一个动作条件的前向动力学模型 𝑠ˆt+1 = 𝑓_𝜃 (𝑠t , 𝑎t ),其中 𝑠t 和 𝑎t 分别表示 𝑡 时刻的状态和动作(或动作块),而 𝑠ˆt+1 表示预测的后继状态。
根据近期的训练方法[28, 48],研究一个包含两个数据源的半监督学习场景:一个小型带动作标签的机器人交互数据集𝒟_act = {(𝑠𝑡, 𝑎𝑡, 𝑠𝑡+1)}和一个大型无动作视频数据集𝒟_vid = {(𝑠𝑡, 𝑠𝑡+1, . . .)}。通常,𝒟_vid涵盖的状态转换范围比𝒟_act要广得多。
目标不仅是在𝒟_act所代表的狭窄动作分布上改进𝑓_𝜃,还要在𝒟_vid所反映的更广泛的状态转换支持上改进𝑓_𝜃。由于视频数据中缺乏动作标签,这极具挑战性。在实践中,先在 𝒟_vid 上预训练,再在 𝒟_act 上后训练的世界模型,在动作跟随方面常常表现不佳,预测的未来状态与给定的动作不符 [75, 91]。一个自然的解决方法是收集更多带有动作标注的交互数据。然而,由于获取此类标注通常成本高昂,一个关键问题是:应该查询哪些新的交互数据才能最有效地改进世界模型?
直观来看,并非所有交互数据都具有相同的信息价值。有些交互数据已经建模良好,几乎没有新增价值。理想情况下,应该将数据预算用于当前世界模型最有可能出现较大预测误差的转换,因为在这些情况下,额外的数据可以带来最大的改进。更正式地说,对于给定的状态 st 和候选动作 at,世界模型的预测误差为:
𝜀(st,at) := l (stt+1^, stt+1^) = l(𝑓_𝜃(st,at), stt+1^)
其中 l (·, ·) 是状态空间中的偏差度量。由于在执行之前无法获得真实状态 stt+1^,目标是构建一个验证机制,生成一个验证器 𝜀ˆ 来估计此误差,或者至少保持其在候选交互中的相对顺序。
具体来说,给定两个候选动作 𝑎𝑡_i 和 𝑎𝑡_j,希望验证器 𝜀ˆ 能够正确地对它们的难度进行排序:
𝜀(𝑠t, 𝑎t_𝑖) < 𝜀(𝑠t, 𝑎t_𝑗) ⇒ 𝜀ˆ(𝑠t, 𝑎t_𝑖, 𝑠ˆt_𝑖) < 𝜀ˆ(𝑠t, 𝑎t_𝑗, 𝑠ˆt_𝑗).
两种互补的验证因素
一种常用的策略是,为了近似构建一个用于优先处理信息交互的验证器,直接从当前世界模型估计难度,例如通过认知不确定性[82]、集成分歧[90]或学习进度[54]。然而,这些方法通常会继承已学习世界模型本身的缺陷:在探索充分的范围内,由于当前世界模型已经准确,无需过多探索,这些方法能够提供相对可靠的估计;但在探索不足的范围内,这些估计却变得非常不可靠,而此时此类估计恰恰至关重要。
为了克服这个问题,采取了不同的视角:并非直接使用预测误差来估计难度,而是围绕验证任何正确的基于动作预测都应满足的两个更简单的条件来构建本方法。
验证过程并非直接估计模型误差,而是可以分解为两个互补的因素:
• 状态合理性:预测的下一个状态在环境动态下是否合理。
• 动作可达性:从状态 st 到状态 st+1 的转换是否与给定的动作一致。
正确的预测应同时满足这两个条件:它应保持在合理未来状态的流形上,并且应在预期动作下可达。更重要的是,每个因素都存在一种比直接预测前向动态更容易的验证策略:
通过分布不对称性进行状态验证。一个关键的不对称性在于,无动作的视频数据比带动作标签的交互数据丰富几个数量级,从而提供了更广泛的合理转换先验分布。在探索不足的领域中,常见的失效模式是离开这个数据流形:展开操作变得不切实际或不符合物理规律。为了检测此类故障,在 𝒟_vid 上训练一个子目标生成器 𝑝_𝜑,并将其用作对可能的未来状态的先验。
基于维度不对称性的动作验证。仅凭状态合理性并不能保证前向预测的正确性:对于下游策略应用,预测的状态转移必须在指定的动作或动作块下可达。第二个不对称性在于,在许多机器人任务中,动作可以从一小部分状态特征中识别出来,例如末端执行器姿态或被操纵物体的运动,这使得逆向验证的维度远低于前向预测。通过在 𝒟_act 上学习一个稀疏逆动力学模型 h_𝜓 来实现这一点,该模型使用学习的掩码 𝑀 来选择与动作相关的状态特征。
如图 2 所示,子目标生成器 𝑝_𝜑 和逆模型 h_𝜓 提供两个互补的验证组件:前者检查候选未来是否合理,后者检查是否可以通过推断的动作达到。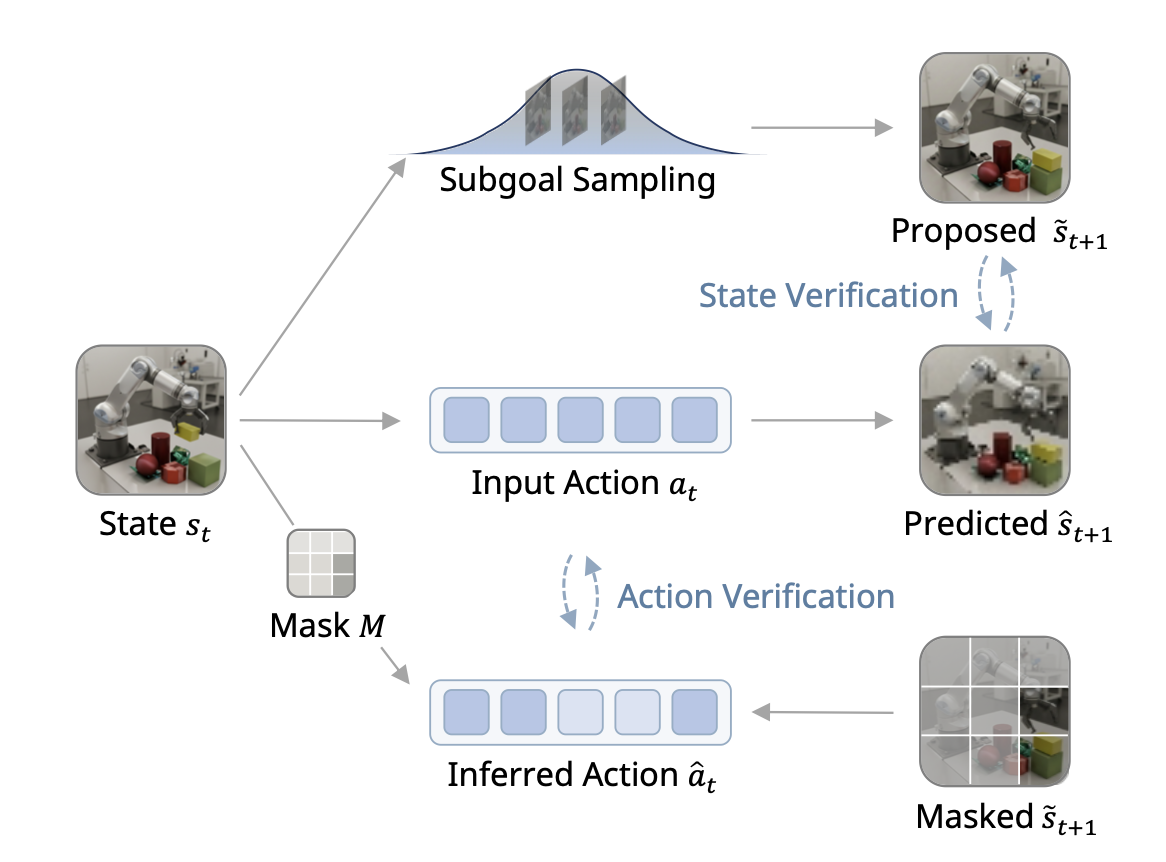
基于验证的自改进循环
鉴于上述两个验证准则,接下来将它们连接成一个用于探索的自改进循环。在该循环中,当前模型集(即世界模型和逆模型)自主生成验证信号,以优先考虑信息丰富的交互,并将生成的数据反馈给世界模型,以在固定的训练方案下进行更新,无需额外的人工干预。一种自然的设计是前向优先循环:采样动作,展开 𝑓_𝜃,然后应用 h_𝜓 从生成的状态对中恢复动作 [112]。然而,这种设计在实践中可能比较脆弱,因为 𝑓_𝜃 中的早期错误会导致展开结果偏离流形,而逆模型在这些流形上是不可靠的。
本文转而使用反向循环,将验证锚定在无动作状态流形上。给定当前状态 st,按顺序应用子目标先验、逆模型和世界模型。这种排序方法首先提出一个合理的目标状态,然后测试动作条件世界模型是否能够实现它。通过估计误差 𝜀ˆ(𝑠t, 𝑎ˆt, 𝑠ˆt+1) = l(𝑠 ̃^(t+1), 𝑠ˆ^(t+1)) 来衡量它们之间的差异,以优先考虑信息交互,如算法 1 中所述。
WAV利用两种不对称性——更广泛的无动作数据覆盖范围和更低的动作相关特征维度——通过稀疏逆动力学模型验证世界模型预测。现在,将形式化这些不对称性使得稀疏逆验证在分布偏移下比正向动力学更具鲁棒性且学习效率更高。重点关注两个问题:
- 在什么条件下,稀疏逆验证器可以推广到token转移的训练分布之外?
- 哪些因素会影响正向和逆向动力学模型之间的不对称性?
分布层面的鲁棒性
为了形式化第一个问题,将观测状态 𝑠𝑡 建模为源自潜向量 z𝑡 = (z𝑡_1, . . . , z𝑡_𝑘)。学习的掩码 𝑀 选择该潜空间中与动作相关的块 𝒮;直观地说,𝒮 捕获以主体为中心的变量(例如,本体感觉或末端执行器运动),并且在很大程度上与场景的其余部分隔离。因此,稀疏逆模型 h_𝜓 作用于 (z𝑡_𝒮, z𝑡+1_𝒮将验证器写为 aˆ𝑡 = h_𝜓(zˆ𝑡_𝒮, zˆ𝑡+1_𝒮),其中 zˆ𝑡 表示编码器对 z𝑡 的潜估计。
令 𝑃_seed 表示由 𝒟_act 诱导的分布;当 (z𝑡, a𝑡) ∈ / supp(𝑃_seed) 时,称状态-动作对为无支持 (Out-of-support,OOS)。关键的结构条件是存在生成-验证差距:完整的状态-动作对 (z𝑡, a𝑡) 可能为 OOS,而受限状态-动作对 (z𝑡_𝒮 , a𝑡) 则仍然在支持范围内。这描述这样一种情况:场景层面的后果是新的,但编码该动作的主体端运动仍然是熟悉的。
命题 3.1(非正式)。假设存在一个可识别的验证子集 𝒮,使得:(i) z𝑡+1_𝒮 仅依赖于 (z𝑡_𝒮, a𝑡),而不依赖于场景的其余部分;(ii) 即使 (z𝑡, a𝑡) 处于 OOS 状态,(z𝑡_𝒮, a𝑡) 仍然处于支持域内;以及 (iii) 动作可从子集转换 (z𝑡, z𝑡+1) 中识别出来。那么,基于种子数据训练的逆模型可以从这种组合式 OOS 转换的 (zˆ𝑡_𝒮, zˆ𝑡+1_𝒮) 中恢复出正确的动作。因此,WAV 使用的正向-反向不匹配定位的是正向模型误差,而非动作标签歧义。
解释。命题 3.1 保证,只要在训练过程中观察到智体自身的运动模式(例如,关节角度轨迹),即使场景转换是全新的,稀疏逆模型 h_𝜓 也能生成正确的伪标签。这比要求整个转换都在支持区域内的要求要弱得多,而后者正是密集正向模型或全观测逆模型所需要的。对于自改进循环,直接结果是子目标与正向展开之间的差异 l(𝑠 ̃t+1, 𝑠ˆt+1) 反映的是真实的世界模型误差,而非动作标签噪声,因此每一轮探索都会增加可信数据,从而扩展世界模型的有效覆盖范围。
样本效率优势
命题 3.1 阐述稀疏验证何时能够迁移。现在,刻画决定逆向验证和正向预测之间不对称性的因素。为了分离关键因素,将学习的逐元素掩码 𝑀 理想化为一个固定秩的 𝑑_𝑧 线性投影 𝑧 := 𝑀𝑠,并分析一个简化的线性高斯模型。这种设置清晰地分离正向-逆向不对称性的三个来源:维度、随机性和样本大小。
为了便于处理,直接使用观测状态 𝑠 和动作 𝑎,并注意到,当 𝑠 存在因子化的潜表示时,结果可以推广到定理 3.1 的潜设置。假设单步动力学
𝑠′ = 𝐴𝑠+𝐵𝑎+𝜉, 𝜉∼𝒩(0, 𝜎2_𝑠 I_𝑑_𝑠),
其中 𝜎_𝑠 表示转移随机性。进一步假设动作可以从低维动作-相关切片 𝑧 := 𝑀𝑠 中恢复,其中 𝑑_𝑧 l 𝑑_𝑠:
𝑎=h(𝑧,𝑧’)+𝜂, h(𝑧,𝑧’):=𝐻 [z 𝑧′]T, 𝜂∼𝒩(0,𝜎2_𝑎 I_𝑑_𝑎),
其中 𝑧′ := 𝑀𝑠′,𝜎_𝑎 衡量从 (𝑧, 𝑧′) 中恢复动作的不可约歧义。
将基于 [𝑠; 𝑎] 与在 [𝑧; 𝑧′] 上训练的稀疏逆模型 h_𝜓 进行比较,两者均通过 OLS 对来自 𝒟_act 的 𝑛 次转移进行拟合。为了在相同的单位下进行比较,在状态空间中进行评估:
E_𝐹 := E ‖𝑓_𝜃(𝑠, 𝑎)−𝑓*(𝑠,𝑎)‖2_2 / d_s, E_𝐼 := E ‖𝑓*(𝑠, h_𝜓(𝑧, 𝑧’))−𝑓*(𝑠, h(𝑧,𝑧’))‖2_2/d_s,
其中 𝑓*(𝑠,𝑎) 表示真实动力学,𝜆 := ‖𝐵‖_op 将动作误差转换为状态空间误差。
命题 3.2(非正式)。在上述简化的设置下,如果两个模型都使用 𝑛 个标记的转换通过 OLS 进行拟合,则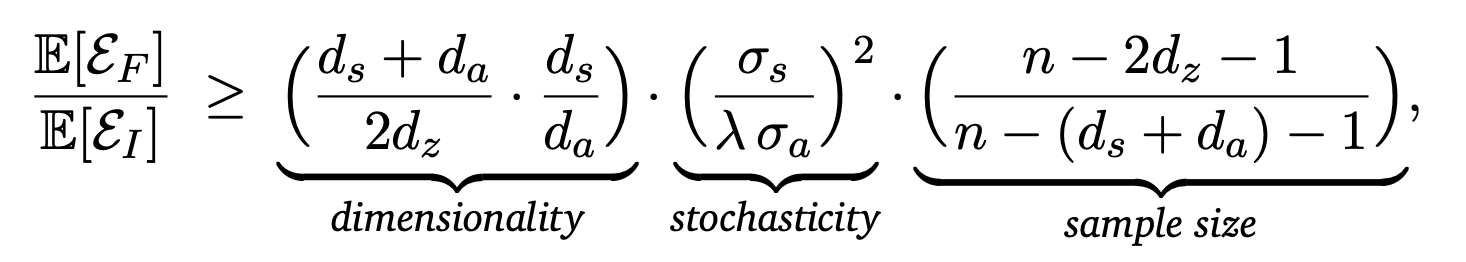
满足 𝑛 > 𝑑_𝑠 + 𝑑_𝑎 + 1 且 𝑛 > 2𝑑_𝑧 + 1。
解释。该比率可以分解为三项。维度:前向模型必须根据 𝑑_𝑠 + 𝑑_𝑎 输入估计映射,而稀疏逆模型仅使用 2𝑑_𝑧。随机性:前向预测会受到环境噪声 𝜎_𝑠 的影响,而逆向验证仅受到动作恢复歧义 𝜎_𝑎(按 𝜆 缩放)的影响。样本大小:当 𝑛 仅略大于 𝑑_𝑠 +𝑑_𝑎 时,前向估计器的稳定性要差得多。在实践中,当 (i) 验证器只需要一个以小智体为中心的子集,而世界模型预测一个大场景(较大的 𝑑_𝑠/𝑑_𝑧)时,WAV 最有帮助; (ii) 不受控制的动态变化会使 𝜎_𝑠 增大,而动作印记(imprint)的保持清晰(大 𝜎_𝑠/𝜎_𝑎 值);(iii) 动作标注的数据有限(小 𝑛 值)。对每个因素进行实证验证:改变数据预算可以分离出样本大小项,增加对象数量会提高有效状态维度 𝑑_𝑠,而添加噪声底限会使 𝜎_𝑠 增大,但 𝜎_𝑎 保持不变。
实验方法介绍如下。
基线方法。将方法与以下探索策略进行比较:
• 随机:从未标记的示例中均匀抽取候选对象(下限)。
• 不确定性:选择预测不确定性最高的候选对象 [90]。
• 进步:选择学习进步最大的候选对象,进步的衡量标准是候选集上模型损失在两轮迭代之间的变化 [54]。
• 原始 IDM:不带稀疏性约束的方法。
• 预言机:选择使用真实动作标签计算的世界模型预测损失最大的候选对象(上限)。
在合成 MiniGrid 数据集上的实验
从三个 MiniGrid 任务(钥匙递送、球递送和物体匹配)中收集了 5 万个交互序列。其中一半序列用于训练无动作子目标生成器,作为视频先验。剩余数据构成一个探索池,包含一个 200 个已标记动作的种子集和一个 2 万个未标记的候选集,用于采集。
为了进行可控评估,构建额外的随机游戏数据集,通过改变物体数量和环境随机性来实现。具体来说,改变物体数量以研究在场景复杂性增加的情况下模型的泛化能力,并引入每次动作后颜色都会改变的噪声地板砖来模拟随机观测。这些噪声环境中的数据专门用于鲁棒性评估。
世界动作验证的鲁棒性
设置。改变在包含 6 个物体环境中收集的标记训练数据量 {400, 800, 1200, 1600, 2000},并在包含 {6, 8, 10, 12, 14} 个物体的环境中评估测试转换。此外,为了检验对观测噪声的鲁棒性,在包含 6 个物体的环境中构建了包含 {0, 1, 2, 3, 4} 个噪声地板砖的训练数据集。为了进行直接比较,将逆模型预测转换为下一状态预测:对于每个测试对,IDM 预测一个动作,然后在模拟器中执行该动作以获得诱导的下一状态。报告世界模型和 IDM 诱导转换的相同动力学精度。此外,计算每种方法的数据选择得分与 Oracle 方法的数据选择得分之间的 Spearman 等级相关系数 [93] 和 Kendall 等级相关系数 [53]。
世界模型学习的有效性
设置。首先使用 200 个均匀采样的带标签转换训练一个基础模型,然后进行三轮探索,每轮探索中每种策略获得 100 个转换的预算。报告五个随机种子上的平均预测误差,重点关注第二轮,因为在第二轮中差异最为显著,以便进行更清晰的比较。
模拟机器人操作实验
数据集和设置。考虑来自 Roboverse [30] 中两个评估套件的一系列具有挑战性的机器人操作任务:RoboMimic [122](举起、罐装、方形)和 ManiSkill [78](拉动立方体、戳立方体、举起钉子)。对于这两个套件,采用两阶段流程,利用专家演示数据来整理训练数据。首先,针对不同训练步数预训练扩散策略 [19],从而获得一系列具有不同最优程度的多样化行为轨迹。基于这些轨迹,将数据划分为两个子集:(1)世界模型预热数据集,其中包含专家演示数据以及从基于这些演示数据训练的最佳扩散策略检查点收集的策略内轨迹;(2)探索数据集,其中包含由不完善的扩散策略检查点生成的轨迹,捕捉了多样化的探索行为。
模型选择。对于世界模型,采用 Dreamer-v3 [39],它学习一个潜循环状态空间模型(RSSM)。对于稀疏IDM,采用CLAM [65] 的模型骨干,并进一步对该潜动作空间施加稀疏性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献111条内容
已为社区贡献111条内容

所有评论(0)