深度学习 —— Pytorch实践
一、自动微分模块
是Pytorch内部的自动求导模块 自动微分:自动求导
作用:自动精确求导,无需手动计算
自动微分模型在神经网络训练中的作用:计算损失梯度
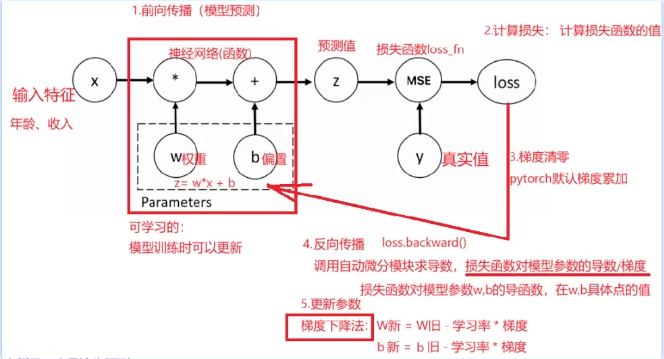
1.定义模型权重参数. (输入特征)
2.前向传播
3.定义一个损失函数
4.把前向传播的函数 或者是说 神经网络层,和 预测值 带入损失函数,计算损失值
5.梯度清零 (Pytorch 默认梯度累加)
6.backward(). 反向传播计算导数/梯度
7.w.grad 获取导数值/梯度
8.更新参数: W新 = W旧 - 学习率 * 梯度
9.多次训练 -> 把W新和B新 重复带入 步骤2
例子:自动微分的真实应用场景 (代码)
# 1.准备数据集
# 随机种子
torch.manual_seed(5)
# 创建样本 2行 5列
x = torch.ones(2,5)
# 创建真实预测值 2行 1列
y = torch.zeros(2,1)
# 2.定义模型权重参数
# 构建初始化模型 权重w 偏置b 开启梯度计算
w = torch.rand(5,1, requires_grad=True)
b = torch.rand(1, requires_grad=True)
# 3.前向传播
z = x @ w + b
# z = [w1+w2+w3+w4+w5+b,w1+w2+w3+w4+w5+b] = [z1,z2]
# 4.计算损失函数 MSE 默认 (default ``'mean'``)
loss_fn = torch.nn.MSELoss()
loss = loss_fn(z, y)
# 5.梯度清零
if w.grad is not None:
w.grad.zero_()
if b.grad is not None:
b.grad.zero_()
# 6.反向传播
loss.backward()
# 7.梯度值
print(f"w.grad:{w.grad} \n"
f"b.grad:{b.grad} \n")
# 8.更新权重 - 打印前后 W值
print(f"旧 w:{w.data} \n"
f"旧 b:{b.data} \n")
w.data -= 0.01 * w.grad.data
b.data -= 0.01 * b.grad.data
print(f"新 w:{w.data} \n"
f"新 b:{b.data} \n")
# 9.单次训练。。。多次循环
print('结束')二、梯度下降法
针对损失函数,沿着损失函数导数的反方向更新模型参数,使得损失函数降低
目标:获取 损失函数的最小值,对应的模型参数,也就是最优模型
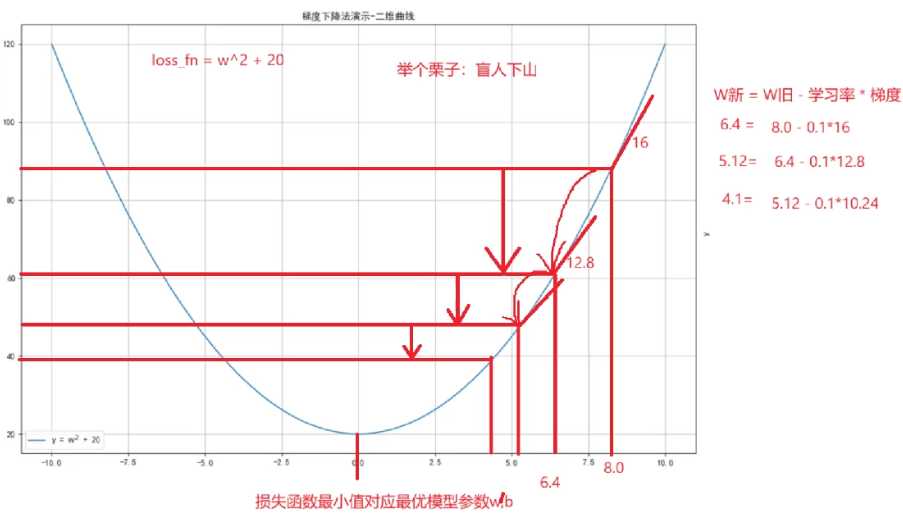
梯度下降法 求损失函数的最小值
如:求 loss = w**2 + 20 的极小值点 并打印loss是最小值时 w的值(梯度)
计算过程:
1 定义点 w=10, requires_grad=True, dtype=torch.float32
2 定义函数 loss = w**2 + 20
3 利用梯度下降法 循环迭代 求最优解/最小值
3.1 前向传播,计算损失
3.2 梯度清零 w.grad.zero_()
3.3 反向传播 loss.backward()
3.4 更新参数 w.data = w.data - 0.01 * w.grad
1-3
# 1 定义点 w=10, requires_grad=True, dtype=torch.float32
w = torch.tensor([10.0,20.0],requires_grad=True,dtype=torch.float32)
# 2 定义函数 loss = w**2 + 20
loss = w**2 + 20 # 120.0
# 3 利用梯度下降法 循环迭代 求最优解/最小值
print(f"初始值:w:{w.data}, w.grad: {w.grad}, loss.mean():{loss.mean()}")3.1-3.4
# 记录损失均值
loss_list = []
for i in range(500):
# 3.1 前向传播, 计算损失
loss = w**2 + 20
# 3.2 梯度清零 w.grad.zero_()
if w.grad is not None:
w.grad.zero_()
# 3.3 反向传播 loss.backward()
loss.mean().backward()
# loss_mean' = 2*w
# 3.4 更新参数 w.data = w.data - 0.01 * w.grad
w.data = w.data - 0.01 * w.grad
# loss_mean' =1/2* 2*w = w = [w1,w2]
print(f"第{i+1}次迭代:w:{w.data}, w.grad:{w.grad.data}, loss.mean():{loss.mean()}")
# 添加到loss_list
loss_list.append(loss.mean().item())绘制损失曲线
iterations = range(500)
plt.figure(figsize=(12,8))
plt.plot(iterations,loss_list)
plt.xlabel("迭代次数")
plt.ylabel("损失均值loss.mean")
plt.grid()
plt.show()三、detch() 函数
detach() 函数的功能,
解决 开启梯度计算 requires_grad=True 的张量,无法转为numpy对象的问题
1.定义张量,开启梯度计算requires_grad = True
w = torch.tensor([1.0,2.0,3.0], requires_grad=True, dtype=torch.float32)
print(f"w:{w}, shape: {w.shape}, requires_grad: {w.requires_grad}")2.直接转为numpy数组 (无法转)
# 2.直接转为numpy数组
# n1 = w.numpy()
# print(f"n1:{n1}, shape: {n1.shape}")3.使用detach().numpy()来转数组
t1 = w.detach()
print(f"t1:{t1}, shape: {t1.shape}, type: {type(t1)}, requires_grad: {t1.requires_grad}")
n2 = w.detach().numpy()
print(f"n2:{n2}, shape: {n2.shape}")4.查看是否共享内存/浅拷贝 (浅拷贝)
n2[0]=28.0
print(f"w:{w}, shape: {w.shape}")
print(f"n2:{n2}, shape: {n2.shape}")四、Pytorch框架_模型线性回归
1.准备数据集
2.构建模型
3.设置损失函数和优化器
4.模型训练
<1> 张量 -> 数据集
<2> 数据加载器
<3> 构建模型 - 这里是模拟线性回归
<4> 损失函数 - MSE损失函数
<5> 优化器 - 随机梯度 SGD
<6> 模型开始循环训练
# 定义梯度训练的轮次
# 记录 每个轮次的平均损失
# 开始遍历轮次 训练
<6.1> 初始化 当前轮次的训练总损失
<6.2> 初始化 当前轮次的总样本数. 总共是100个样本
<6.3> 根据批次 遍历数据 加载器,分批训练
向前传播->计算预测值->计算损失->梯度清零->反向传播->
更新参数w新=w旧-学习率*梯度
记录 -> 批次的损失值 * 样本数 (可视化绘图用)
<6.4> 计算当前批次的平均损失
<6.5> 将每一批次的损失值 存到数组
<7> 可视化训练过程
"""
Pytorch 框架 模型线性回归
1.准备数据集
numpy数组 -> 张量 -> 数据集对象Dataset -> 数据加载器DataLoader(分批次加载)
2.构建神经网络模型
nn.Linear()
3.设置损失函数和优化器
nn.MESLoss, optiom.SGD
4.模型训练
1.前向传播
2.计算损失
3.梯度清零
4.反向传播
5.更新参数 W新 = W旧 - 学习率*梯度
5.模型测试
"""
import torch
#构造数据集对象
from torch.utils.data import TensorDataset
#数据加载器,按批次加载数据
from torch.utils.data import DataLoader
#提供 MSE 损失函数 和 线性层,线性用来模拟线性回归模型
from torch import nn
#提供各种优化器,用于更新模型参数,公司为 W新 = W旧 - 学习率lr * 梯度 grad
from torch import optim
#创建线性回归的示例数据集
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
# 1.准备数据集
def create_dataset():
x, y, coef = make_regression(
n_samples=100, #样本数
n_features=1, #特征数
n_targets=1, #目标数
noise= 10, #噪声
bias= 13.9, #偏移
coef=True, #是否返回系数 真实的权重 w(斜率)
random_state=5 #随机种子
)
# 转化为 张量
x = torch.tensor(x,dtype=torch.float)
y = torch.tensor(y,dtype=torch.float)
return x, y, coef
# 2.模型训练
def train_model(x,y,coef):
# <1> 张量 -> 数据集
dataset = TensorDataset(x,y)
# <2> 数据加载器
dataloader = DataLoader(
dataset, #数据集
batch_size=16, #一次加载数量 批次大小 一般 64、32
shuffle=True, #是否打乱数据,训练时打乱,测试时不打乱
drop_last=False #是否删除最后一个数量不够的批次,一般是False
)
# <3> 构建模型 - 这里是模拟线性回归
model = nn.Linear(1, 1)
# <4> 损失函数 - MSE损失函数
loss_fn = nn.MSELoss()
# <5> 优化器 - 随机梯度 SGD
optimizer = optim.SGD(model.parameters(), lr=0.01)
# <6> 模型训练
# 定义梯度训练的轮次
count = 100
# 记录 每个轮次的平均损失
total_losses = []
# 开始遍历轮次 训练
for epoch in range(count):
# 1.初始化 当前轮次的训练总损失
total_loss = 0.0
# 2.初始化 当前轮次的总样本数. 总共是100个样本
total_samples = 0
# 3.根据批次 遍历数据 加载器,分批训练
for x_train, y_train in dataloader:
# 3.1 前向传播,计算预测值
y_pred = model(x_train)
# 3.2 计算损失
# reshped(-1,1) 因为标签 y 只有1个,是标量 => 要升维度 (1,1)
loss = loss_fn(y_pred, y_train.reshape(-1,1))
# 3.3 梯度清零 - 因为在pytorch 中,梯度会自动累加
optimizer.zero_grad()
# 3.4 反向传播
loss.backward()
# 3.5 更新参数 W新 = W旧 - 学习率 lr * 梯度 grad
optimizer.step()
# 3.6 统计 训练损失 和 样本数.
# 这批次的损失值 * 样本数
total_loss += loss.item() * x_train.shape[0]
total_samples += x_train.shape[0]
# 4.计算当前批次的平均损失
train_loss = total_loss / total_samples
# 5.将每一批次的损失值 存到数组
total_losses.append(train_loss)
# 6.打印本轮训练的平均损失
print(f"{epoch + 1}/{count}': | "
f"{train_loss:.4f}")
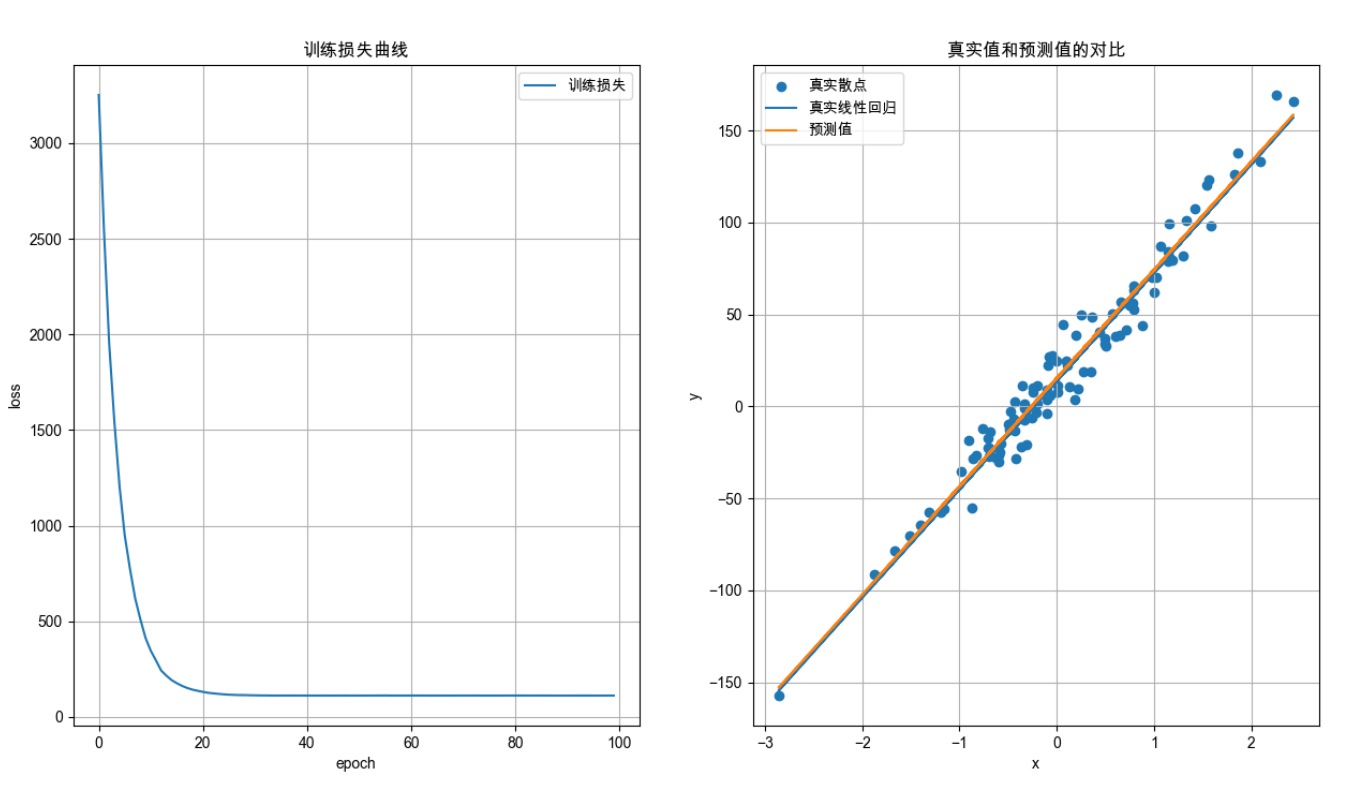
# <7> 可视化训练过程
# 图 1
plt.rcParams['font.family'] = 'Arial Unicode MS'
print(f"损失列表:{total_losses}")
plt.figure(figsize=(15,8))
# 绘制第一个子图:训练损失曲线图
plt.subplot(1,2,1)
plt.title("训练损失曲线")
x_epoch = range(count)
plt.plot(x_epoch, total_losses, label="训练损失")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.grid()
plt.legend()
# 图 2 -------
# 真实值和预测值的对比
plt.subplot(1, 2, 2)
plt.title("真实值和预测值的对比")
plt.scatter(x, y, label="真实散点")
# 计算理论的真实线性回归直线 codf.item() 是真实斜率 13.9 是截距 B
y_true = [v*coef.item()+13.9 for v in x]
plt.plot(x, y_true, label="真实线性回归")
# 计算模型预测值
with torch.no_grad(): # 关闭梯度计算
"""
model(x) 得到的预测张量,原本连着梯度计算图(和模型权重、输入 x 绑定)
.detach():强制断开和梯度图的所有联系,得到一个纯数值、无梯度、叶子张量
.numpy():把断开后的张量转成 numpy 数组
"""
y_pred = model(x).detach().numpy()
# 绘制模型预测的线性回归直线
plt.plot(x, y_pred, label="预测值")
plt.xlabel("x")
plt.ylabel("y")
plt.grid()
plt.legend()
plt.show()
if __name__ == '__main__':
x, y, coef = create_dataset()
train_model(x,y,coef)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)