从零构建一个AI聊天App:1天复刻1个mini豆包
前言
像千问、豆包、ChatGPT这样的AI聊天应用已经普及到千家万户,AI Coding能力也日新月异,我想验证下让AI来开发AI聊天应用需要多久,同时也是温故知新。
验证下来,发现一天左右的时间就能开发出一个具备主要功能的AI聊天应用,具体代码见:https://github.com/seizethemoment/hi-my-ai-chat
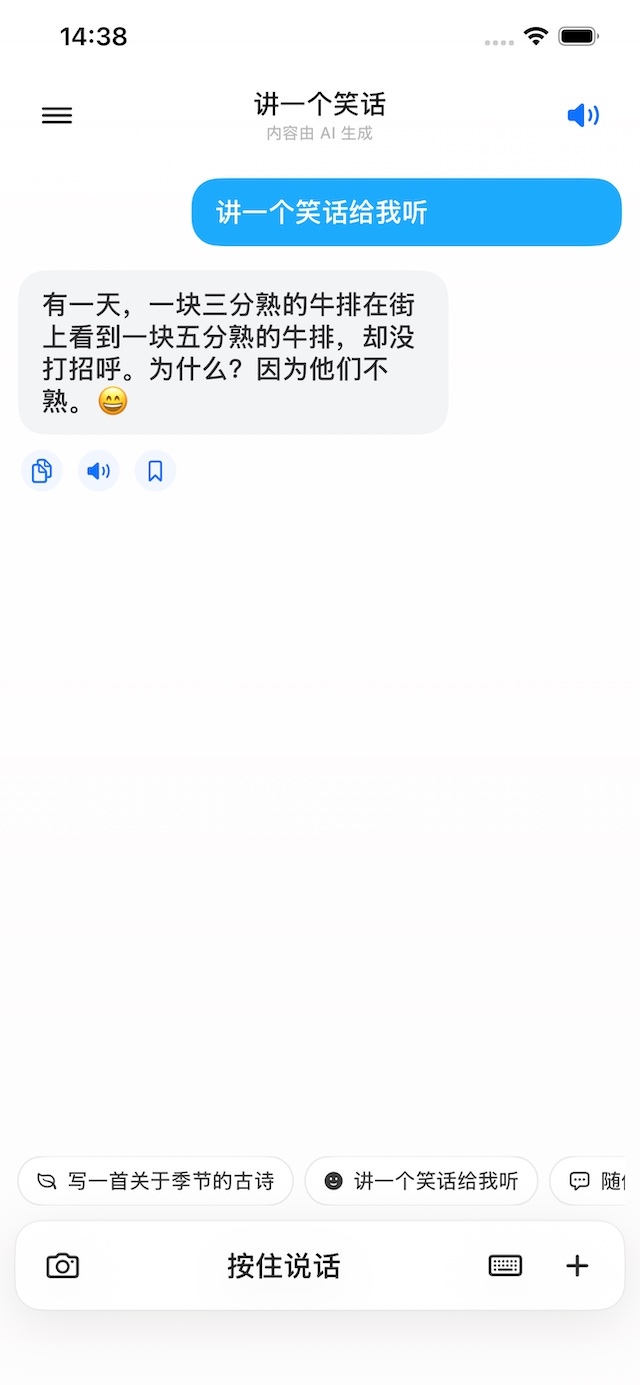
以下是实现效果,支持文本聊天、图片理解、语音输入和播放、流式回复、多会话管理、搜索和收藏等功能,后面持续更新。
HiChat-Usecase
一、环境准备
目标:创建一个App。
验收标准:成功运行App,看到“Hello, world!”输出。
选择移动任意端或者桌面端App来作为落地场景都可以,因为对AI来说都差不多,只不过最新版Xcode自带AI Coding能力,不用登录都能匿名使用ChatGPT能力,所以这里选择用iOS端来开发。
更新Xcode到最新版本,将官方Xcode MCP配置到AI IDE,便于AI在写完代码后进行自动化验收。
这一步只要点几下鼠标:打开Xcode -> File -> New -> Project,一路点击下一步,再点击Run,就能编译运行到模拟器,看到 Hello, world,就算达成目标。
BTW,在AI时代,苹果的产品越发吃香,下单一台Mac mini都要等几个月才有货,💻运行也更省电,以及安全性相对更高。
二、聊天页面创建
目标:创建一个聊天页面。
验收标准:运行App,展示聊天页面
输入:豆包或千问的一张聊天页面截图 + 需求描述,比如“根据图片把App首页改成聊天页面,主要包括顶部导航栏、中间消息展示区域、底部输入区域”。
不同水平的AI会根据你的截图和描述,生成一致度有所差别的效果。高水平的AI甚至会自己调用Xcode MCP来完成消息的发送和展示验收。针对这种水平的AI,你可以额外加一句:开发完成后,你输入一句文本进行发送,并且mock文本作为返回数据并上屏展示。
三、模型服务调通
目标:让AI模型进行消息回复,而不是mock。
验收标准:运行App,发送多条不同的消息,收到真实的模型回复。
上一步是使用mock数据来作为消息回复,这里是跑通真实场景。
需要准备好你自己的模型调用信息(Base Url 和 API Key),比如OpenAI、阿里云百炼平台、智谱或Kimi等平台订阅,容易封号的Anthropic就不推荐了。
- 开发阶段可以先把这些信息硬编码便于调用。
- 我在HiChat中是提供了一个设置页让用户一次性配置这些信息。
调用模型服务,这里使用的最常见通用、兼容性最强的是OpenAI的核心接口 —— Chat Completions API —— 通过 POST /v1/chat/completions 端点,基于一组角色消息(system / user / assistant)生成模型回复。
基本用法
POST https://api.openai.com/v1/chat/completions
{
"model": "gpt-5.4",
"messages": [
{"role": "system", "content": "你是一个有用的助手"},
{"role": "user", "content": "你好!"}
]
}
核心参数
- model — 指定使用的模型(如 gpt-5.4、qwen3.6-plus 等)
- messages — 对话消息列表,每条消息包含 role 和 content
- temperature — 控制输出随机性(0~1)
- max_tokens — 限制最大输出长度
- stream — 是否启用流式输出
- tools — 工具调用(function calling)定义
- top_p / frequency_penalty / presence_penalty — 采样控制
不过,现在模型都在向上生长、内置工具,OpenAI也推出了新的Responses API,建议大家迁移:https://developers.openai.com/api/docs/guides/migrate-to-responses ,阿里云百炼也有相应支持:https://help.aliyun.com/zh/model-studio/compatibility-with-openai-responses-api ,具体可以参见:深入理解 OpenAI 的三代 API:从 Completions 到 Responses 的演进之路。
在HiChat中,是由OpenAIChatService这个类来承接这个功能。
四、流式回复的打字机效果
目标:让AI回复具备打字机效果。
验收标准:运行App,发送多条消息,观察消息回复上屏是逐字更新的,而不是完整一次性上屏。
AI聊天应用的一个经典交互就是AI回复的内容是逐字或逐token展示出来的,大大提升了交互体验:
- 低延迟,用户不用等所有内容思考生成完才看到内容。
- 模拟了一边思考一边打字的拟人交,让用户也可以一边等待一边消费内容。
首先,通过设置stream=true开启流式,让服务端发你SSE增量文本。
func streamReply(
for conversation: [OpenAIChatTurn],
timeoutInterval: TimeInterval = 45,
maxRetryCount: Int = 1,
onRetry: (@Sendable (Int) async -> Void)? = nil,
onDelta: @escaping @Sendable (String) async -> Void
) async throws -> String {
let request = try makeRequest(for: conversation, stream: true, timeoutInterval: timeoutInterval)
当用户发送一条消息后,先立刻插入一条空的 assistant 消息,状态设为 streaming,这样 UI 有一个固定占位可持续更新。
随后 generateAssistantReply 做两件并行的事:
- 启一个
typewriterTask消费本地字符流。 - 调
service.streamReply(...)去读 OpenAI 的 SSE 增量,每拿到一段文本就回调onDelta(delta)。
真正的“打字机”效果是由端侧本地加工实现的:
- 由
TypewriterBuffer来处理每次的增量文本,拆成单个字符。 - 由
playTypewriter一个字符一个字符消费,切到主线程调用appendText(...)更新消息文本,然后 sleep 一小段时间。 - 延时是按字符类型区分的:普通字符 18ms,换行 34ms,标点 42ms,所以视觉上会比纯匀速更像人在打字。
这种方案比较简单直接,适用于普通文本场景,但面对富文本场景就不适合了,需要另外实现。
更多功能:语音输入和播放、图片理解、多会话管理、搜索和收藏……
当完成了上面的步骤之后,已经具备了基本的AI聊天App的雏形,只不过局限于文本交流,接下来就要扩展到语音、图片、工具调用等场景,甚至还需要考虑上下文窗口大小和压缩,如果有想法也可以进一步引入记忆系统。这里就不完全展开了,只提一下语音输入和播放。
当你选择了使用原生代码开发后,AI对主流平台系统库是很了解的。
比如语音输入和播放,输入部分采用的是AVAudioEngine + SFSpeechRecognizer(iOS 原生语音识别),
流程:1. 权限请求 → 2. 音频引擎启动 → 3. 实时语音识别 → 4. 输出文字
1. 权限申请 — 分别请求麦克风权限(AVAudioApplication.requestRecordPermission)
和语音识别权限(SFSpeechRecognizer.requestAuthorization)
2. 音频采集 — AVAudioEngine 的 inputNode 安装 tap,每 1024 buffer
将麦克风音频数据送入识别引擎:
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) {
buffer, _ in
recognitionRequest?.append(buffer)
}
3. 实时识别 — SFSpeechAudioBufferRecognitionRequest 配置为
shouldReportPartialResults = true,边说边返回中间结果,通过
speechRecognizer.recognitionTask 的回调持续更新 transcript
4. 结束处理 — 用户松手后 endAudio() 停止输入,设置 1.5s
超时兜底(scheduleRecognitionFallback),等 isFinal 回调或超时后将文字写入
finalTranscript
输出部分采用的是AVSpeechSynthesizer(iOS 原生 TTS 文字转语音)。
流程: 1. 用户点击播放 → 2. 语言检测 → 3. 配置语音 → 4. 播放音频
1. 语言自动检测 — 用 NLLanguageRecognizer
分析消息文本的语种,按优先级匹配语音:检测到的语言 → 用户首选语言 → zh-CN →
en-US
2. 创建语音片段 — AVSpeechUtterance(string: text) 包装文本,设置参数:
utterance.rate = 0.45 // 中文语速
utterance.pitchMultiplier = 1.0
utterance.postUtteranceDelay = 0.05
3. 播放 — synthesizer.speak(utterance) 开始播放,通过
AVSpeechSynthesizerDelegate 监听完成/取消事件来清理状态
4. 切换控制 — togglePlayback(for:) 实现播放/暂停切换,同一消息再次点击则
stop()
音频会话配置: .playback 类别 + .spokenAudio 模式 +
.duckOthers(降低其他音频音量)
TTS全称是Text-to-Speech,通常包含三个主要组件:语言分析器、声学模型和语音声码器。豆包、千问的声音就是这个领域。如果你经常用iPhone的图书app在看书,比如看一些英文书籍,很大概率会使用到。
之前我在使用AVSpeechSynthesizer时,要吭哧吭哧看官方文档、API接口和说明来调用,现在根本不需要,只需要告诉AI我要实现什么功能 —— 体验大大提升。
踩坑和回顾
这是一个周末间隙让AI开发的应用,累计加起来若干个小时,没有具体统计。
因为周六上午我带娃出去户外,周六下午去西溪湿地逛到晚饭时间才回,周天也类似早上、下午都出门。以下是一些做到目前的感受:
在使用AI时,我们给AI的输入以 目标 和 验收标准 为主,用来指导AI自主完成长程任务。
开发好某个功能,到达一定阶段,要做git记录,避免AI改坏代码很难修。
AI写代码容易一味堆积,需要适当把握方向和引导它进行重构优化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)