微软M*:自进化的记忆Harness

你有没有想过:为什么AI聊天时用向量检索记忆就够了,但让它规划家务时,它需要的竟然是SQL数据库?
这不是脑洞。香港城市大学和微软的最新论文M★给出了硬证据——不同任务最优的记忆架构Harness完全不同,而让AI自己"进化"出最适合的记忆代码,比人类手工设计的效果好得多。
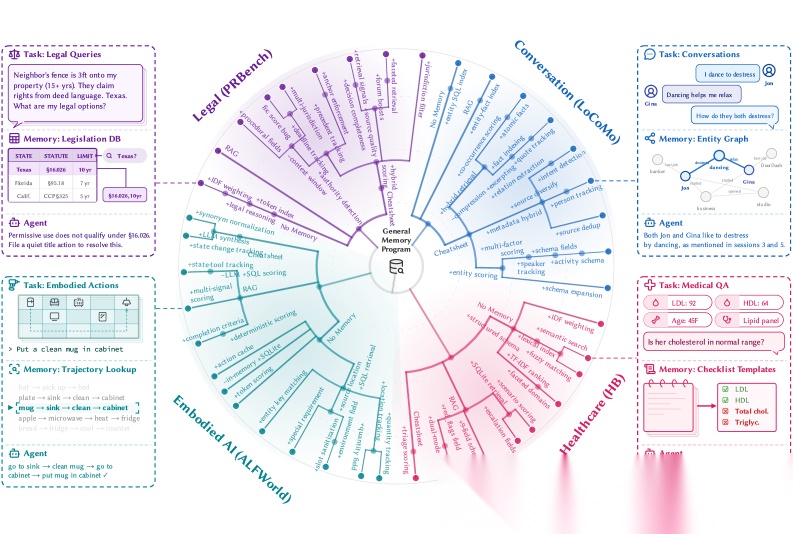
一刀切的记忆模块是错的
当前主流做法是给AI配一个固定的记忆系统——通常是向量数据库,存文本、取文本。但论文发现,这种"万能记忆"在7/8个测试配置上都被M★击败了。
原因很简单:不同任务对记忆的需求根本不一样。
聊天场景需要语义搜索,向量检索刚好合适。但做家务规划时,AI需要精确追踪"哪个房间的灯已经关了"——这时候SQL的结构化查询远比模糊的向量匹配管用。医疗问答又不一样,它需要从对话中提取结构化字段(症状、药物、剂量),然后按字段做精确比对。
M★怎么做到的
M★的核心思路是:不让人类设计记忆系统,让AI自己写代码。
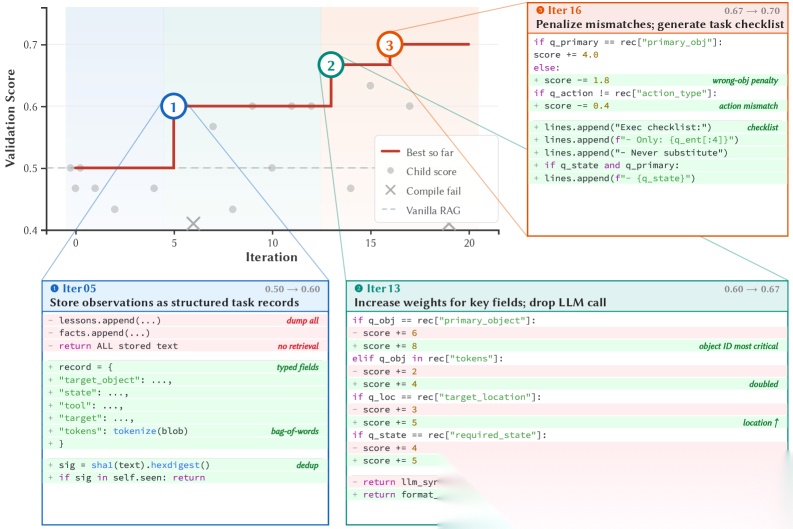
具体来说,它把记忆管理表达成Python程序——包含记忆的读写接口、存储结构和检索逻辑。然后通过"进化循环"不断改写:先在训练任务上跑一遍,看哪里出错了,再反思哪里不好,修改代码,重新测试。
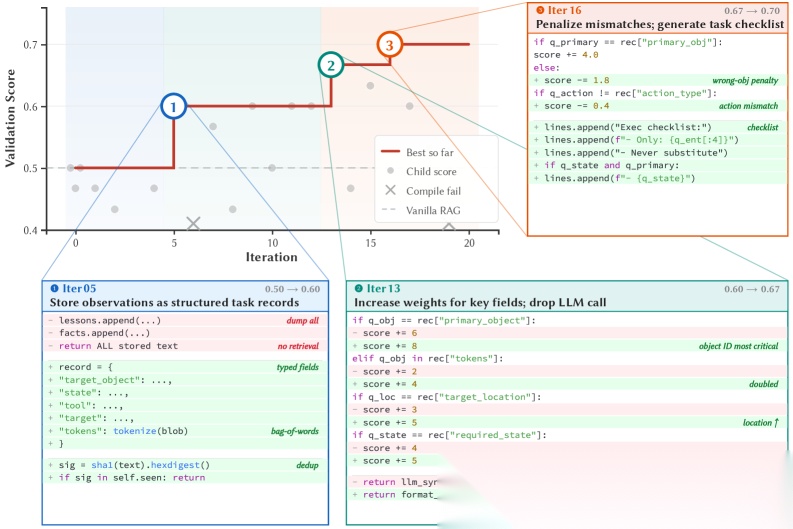
几轮下来,每个任务都进化出了完全不同的记忆程序。ALFWorld(家务任务)进化出了带缓存的SQL读写器,LoCoMo(长对话)进化出了向量+关系表的混合架构,HealthBench(医疗问答)进化出了结构化信息提取+字段匹配器。
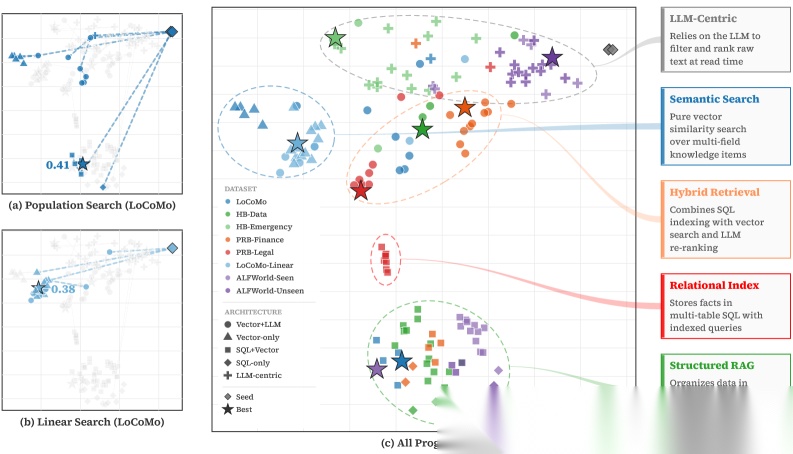
效果有多好
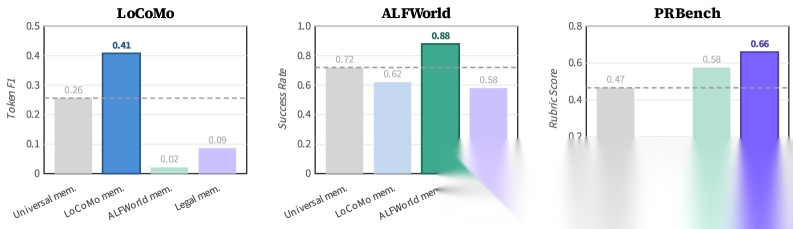
在四个基准上,M★在7/8个配置中超越了所有基线。特别注意,这些基线包括人类精心设计的记忆方案。M★没有使用任何特定领域的先验知识——它只是被要求"写一个记忆管理程序",然后通过反思和迭代自己找到了最优解。
这意味着什么
这篇论文真正有价值的不是M★本身,而是它揭示的事实:通用记忆是一个伪命题。
我们一直在寻找一个"万能"的记忆架构,但证据表明,最优解永远是任务定制的。好消息是,不需要人类一个个去设计——AI可以通过代码进化自己找到最适合的方案。
这对所有做AI Agent的人来说都是一个提醒:与其纠结"用什么向量数据库",不如想想"我的任务到底需要什么样的记忆结构"。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)