深度学习周报(4.13~4.19)
目录
摘要
本节主要对上周论文中的数据预处理方法,即三重指数平滑、自回归模型与小波去噪进行补充学习,了解了它们的核心思想、算法流程、数学公式与适用场景,并尝试使用代码进行实践观察处理结果。
Abstract
This section mainly focused on supplementary study of the data preprocessing methods from last week’s paper, namely triple exponential smoothing, autoregressive models, and wavelet denoising. I learned their core ideas, algorithmic procedures, mathematical formulas, and applicable scenarios, and also tried implementing them in code to observe the processing results.
1 缺失值处理
时间序列中的缺失值会影响模型估计效果,尤其是需要连续观测值的递推算法,因此需要对缺失值进行处理。
常见的处理方法包括删除、简单填补等。其中删除是把整条数据删去,容易破坏时间顺序;简单填补则包括前向填充,均值填充等方法,分别有不同的适用场景与缺陷。除此之外,之前学习过的一些插值方法也可用于缺失值的处理,如线性插值与样条插值。
1.1 三重指数平滑
论文中提到的三重指数平滑由 Holt 和 Winters 提出,主要用于同时含有趋势和季节性的时间序列预测。
它将序列分解为水平、趋势与季节,并用指数加权移动平均的方式递推更新,其中水平 代表序列在 t 时刻的基准值,趋势
代表序列的增长或下降速率,季节
则代表周期性的波动幅度。
其算法流程就是先得到初始 、
与完整的季节因子,再进行更新与预测。
初始化流程大致是,将前 2m(m 为周期长度) 个观测值按季节周期分两组,计算各季节的平均偏差或平均比率作为季节因子,前若干个完整周期的平均值作为 ,用第二个周期均值减去第一个周期均值除以 m 作为
。
随后根据季节效应与水平的关系进行更新与预测,主要分为两种形式。一种是加法模型,其季节性波动幅度不随时间变化(比如,在冬季每月会比其他季节固定多支出供暖费用),其递推公式如下:
向前 k 步的预测公式如下:
另一种是乘法模型,更适用于季节性波动幅度随水平成比例变化的情况(比如商家生意越来越好,每年的销售额都有一定比例的增长),其递推公式如下:
向前 k 步的预测公式如下:
上述公式中,m 为周期长度,可根据数据具体设定; 为 t 时刻的观测值;
、
与
是对应成分的平滑参数,分别控制对新观测值的响应速度、对趋势变化的适应速度以及季节模式的更新速度。
这种方法比较适合具有明确季节性周期(即月度、季度等),趋势为线性且量比较够的数据,但对结构性断点(异常情况)反应较慢,若用于长期预测还可能出现不合理的外推。
1.2 代码
生成的原始数据图如下,红叉代表异常值,蓝虚线代表缺失值,整体叠加高斯白噪声:
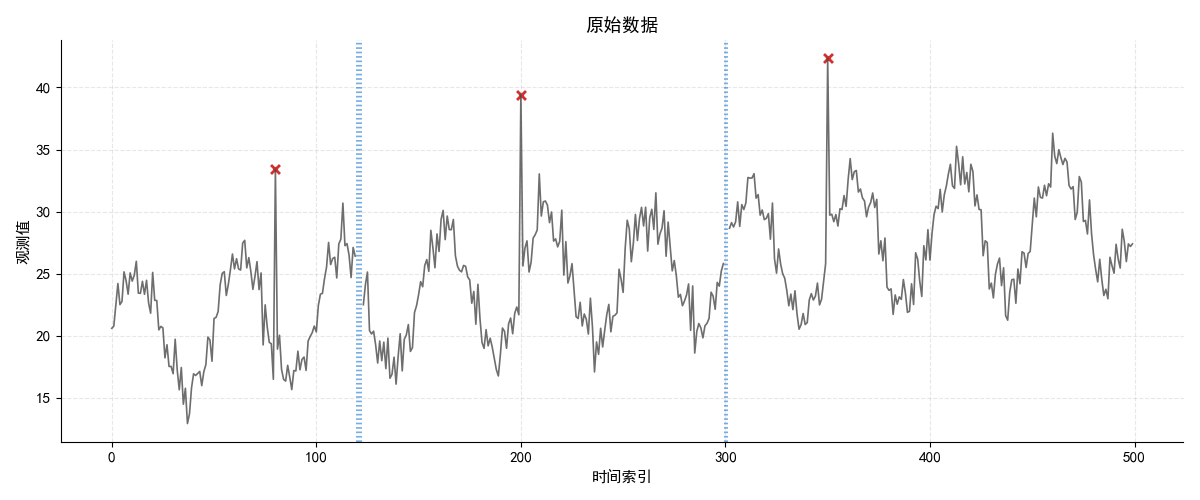
虽然上周论文中利用三重指数平滑处理缺失值,但它需要完整的时间序列作为输入,显然不能直接处理缺失值。故实际应用中通常会对含缺失的数据先线性插值,再利用其进行调整。
代码如下:
# 填充缺失值
data_filled = pd.Series(data).interpolate(method='linear').values
# 三重指数平滑
model = ExponentialSmoothing(
data_filled,
seasonal_periods=50, # 周期设为50
trend='add', # 加法模型
seasonal='add',
use_boxcox=False,
initialization_method='estimated'
)
fit = model.fit() # 参数优化
data_hw = fit.fittedvalues # 平滑后的值结果如下:
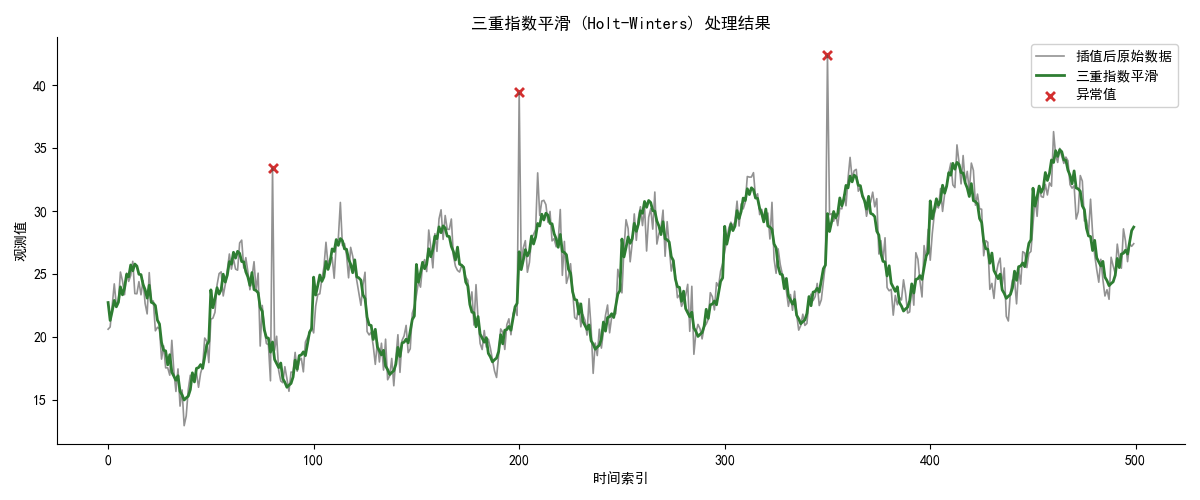
2 异常值处理
在时间序列分析中,异常值是指那些明显偏离数据正常模式或预期范围的观测点或数据段,它们可能源于数据录入错误、传感器故障、外部突发事件或系统本身的偶发波动,会严重干扰数据分析,导致统计量的偏差并降低预测模型的准确性。
异常值处理的第一步通常都是检测,在识别出异常值后,就可根据业务逻辑和分析目标来选择处理策略,策略主要包括删除、替换和模型调整等。
2.1 AR-自回归模型
自回归(AR)模型是时间序列预测中最基础、最经典的模型之一。其核心思想是,一个变量在 t 时刻的值,可以由其自身在过去若干时刻的值(滞后项)的线性组合,加上一个随机的意外(白噪声)来解释。
一个阶数为 p 的 AR 模型的数学表达式为:
其中, 是自回归系数,用于衡量历史值对当前值的影响程度;
表示白噪声,即序列中无法用历史信息解释的、完全随机的新部分。
想让 AR 模型有效有两个关键点。
其中之一就是时间序列的平稳性,即要求序列的统计特性不随时间推移而发生系统性变化。 因为 AR 模型本质上是基于历史观测的线性回归,如果序列的平稳性无法保证,历史数据与未来数据之间的关系就不再稳定,模型的预测也将不可靠。
另一个关键点则在于阶数 p 的确定,这决定了用多少过去的信息来预测未来。它主要利用偏自相关函数 (PACF)来完成,相对自相关函数剔除了中间滞后项的间接影响,对于一个自回归模型,其 PACF 图会在滞后阶数之后出现截尾,即之后的 PACF 值迅速衰减至 0 附近,不再显著,也因此,通过观察 PACF 图中最后一个显著超出置信区间的滞后阶数,即可确定 p 值。
确定了 p 后,模型参数通常通过最大似然估计或最小二乘法来估计。
AR 模型仅适用于平稳的单变量时间序列,对于有明显季节性或长期趋势的序列,其效果有限,预测值可能会逐渐趋向于序列均值。
2.2 代码
首先先通过偏自相关函数确定阶数:
#通过PACF图确定阶数 p
plot_pacf(data_filled, lags=20)
plt.show()结果如下:
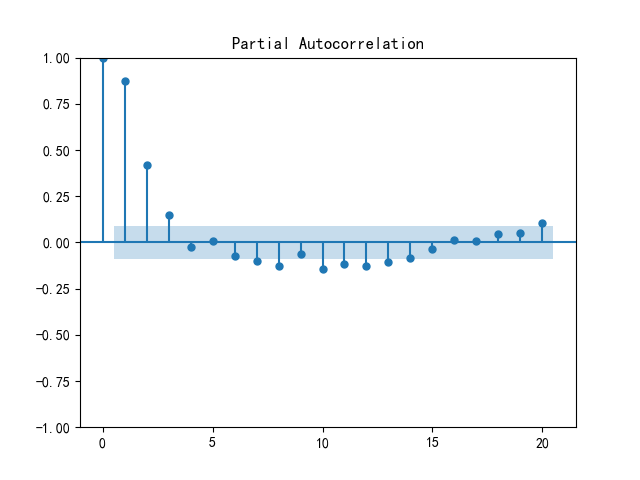
定阶数为 4,同样先进行插值,再拟合自回归模型,代码如下:
# 填充缺失值
data_filled = pd.Series(data).interpolate(method='linear').values
# 手动拟合 AR(5) 模型
lags = 4
N = len(data_filled)
# 构建滞后矩阵 Y 和 X
Y = data_filled[lags:]
X = np.column_stack([data_filled[i:i+N-lags] for i in range(lags)])
# 最小二乘求解系数
phi = np.linalg.lstsq(X, Y, rcond=None)[0]
# 计算拟合值和残差
pred = np.zeros(N)
pred[:lags] = data_filled[:lags] # 前 lags 个点保留原值或设为 NaN,这里保留原值
for i in range(lags, N):
pred[i] = np.dot(phi, data_filled[i-lags:i][::-1])
residuals = data_filled[lags:] - pred[lags:]
# 识别异常值
threshold = 3 * np.std(residuals)
is_outlier = np.abs(residuals) > threshold
# 修正异常值
data_ar_clean = data_filled.copy()
# 替换被标记为异常的点
outlier_indices = np.where(is_outlier)[0] + lags
data_ar_clean[outlier_indices] = pred[outlier_indices]结果如下:
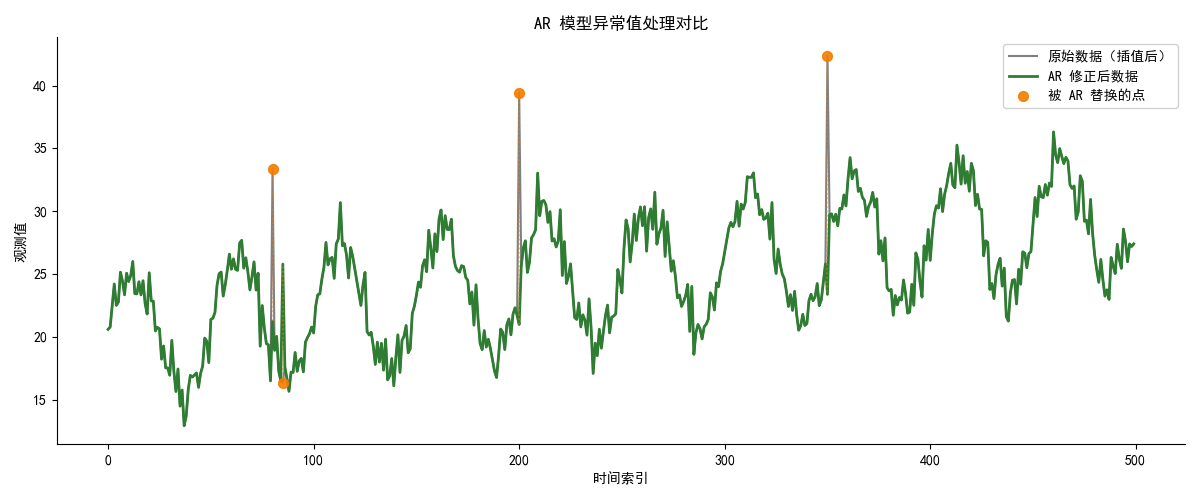
3 去噪
在时间序列分析中,噪声会掩盖真实的趋势和周期,影响建模精度。传统的去噪方法通常会在时域或频域二选一,前者能定位时间点,但难以分离特定频率的噪声;后者能精确滤除高频噪声,但完全丧失了时间定位能力
3.1 小波去噪
小波去噪是最经典的阈值去噪法,它能在看清信号在不同时刻的频域构成的同时保留突变点和边缘信息,因此特别适合非平稳、含突变或奇异点的时间序列。
小波(Wavelet)是一种长度有限、均值为零的振荡波形,与无限延伸的正弦波不同,它会在时域上快速衰减。真实信号的能量通常集中在少数大幅值的小波系数上,随机噪声的则均匀散布在所有小波系数上,且幅值较小,小波去噪的本质就是设定一个门槛(阈值),将小于该门槛的系数视为噪声置零,保留大幅值系数,最后用处理后的系数重构信号。
去噪的标准流程如下:
首先,选择合适的小波基函数和分解层数,对含噪信号进行多层离散小波变换,得到各层近似系数和细节系数,以捕捉低频趋势及高频噪声突变。
其次,对每一层的细节系数应用阈值函数,主要分为硬阈值与软阈值。前者强制将小系数置零,能很好地保留信号边缘和峰值,但可能引入人为抖动;后者不仅置零,还会将保留的系数向零收缩,信号更加平滑,但突变点会轻微模糊。在时间序列上更常使用软阈值,因为其产生的重构信号视觉更干净、统计性质更好。
最后,利用最后一层的近似系数以及阈值处理后的所有细节系数,进行逆小波变换,得到去噪后的时间序列。
总的来说,它比较适合处理信噪比较低、突变点多、非平稳的数据,对于信噪比极高或噪声是特定低频有色噪声则可能需要更复杂的小波包或自适应阈值。
3.2 代码
代码如下:
# 填充缺失值
data_filled = pd.Series(data).interpolate(method='linear').values
# 小波去噪函数
def wavelet_denoise(signal, wavelet='db4', level=None, threshold_mode='soft'):
# 小波分解
coeffs = pywt.wavedec(signal, wavelet, level=level)
# 估计噪声标准差
sigma = np.median(np.abs(coeffs[-1])) / 0.6745
# 全局阈值
threshold = sigma * np.sqrt(2 * np.log(len(signal)))
# 对细节系数进行阈值处理
coeffs_thresh = [coeffs[0]] # 保留近似系数
for i in range(1, len(coeffs)):
coeffs_thresh.append(pywt.threshold(coeffs[i], threshold, mode=threshold_mode))
# 小波重构
denoised = pywt.waverec(coeffs_thresh, wavelet)
# 保证长度一致
return denoised[:len(signal)]
# 去噪
data_wavelet = wavelet_denoise(data_filled, wavelet='db4', level=4, threshold_mode='soft')效果如下:
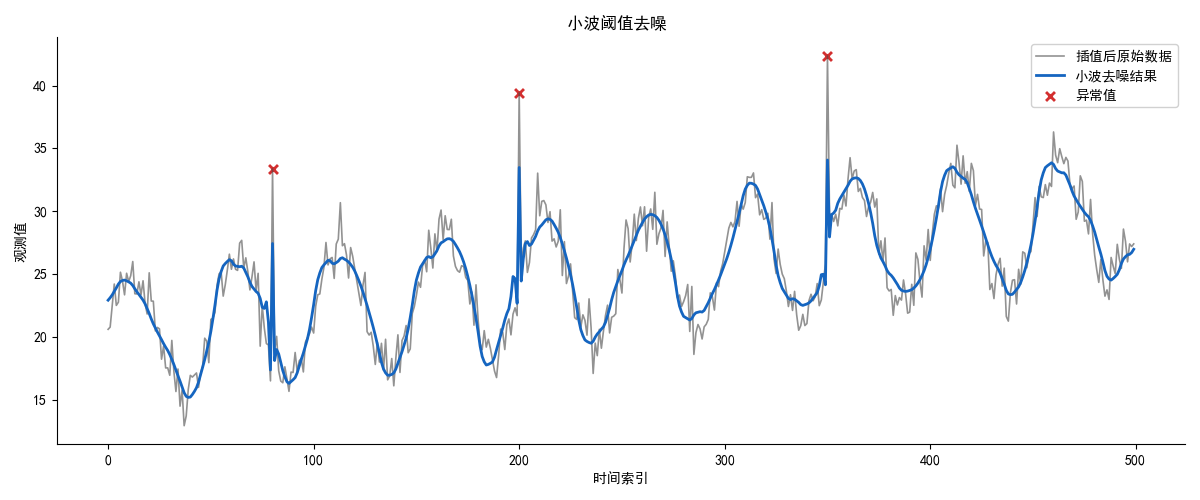
可以观察到,相比前两种方法,小波去噪后更加平滑,但对异常值处理效果较差。
4 总结
本周三种方法都只大致了解了算法思想、流程与适用场景,并对比了其效果,个人感觉学习的广度和深度都不算太够,但对上周的论文加深了理解,除此之外对 API 和 vibe coding 也有了一定接触,感觉对后面的学习也有一定帮助。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)