Python数据分析和数据处理库Pandas(DataFrame基础篇)
目录
一.DataFrame是什么
DataFrame是Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表。它是一个表格型的数据结构,它含有一组有序的列(列有固定从 0 开始的数字索引,顺序不乱),每列可以是不同的值类型(数值、字符串、布尔型值),既有行索引也有列索引。
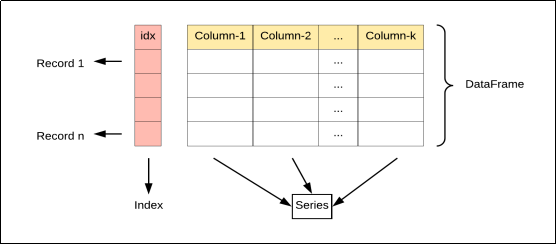
简单说就是与sql表的结构极为相似。
DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。它可以被看做由Series组成的字典(共同用一个索引)。提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作,广泛用于数据分析、清洗、转换、可视化等任务。
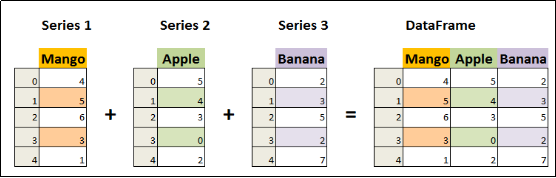
二.DataFrame的创建
1.直接通过字典创建DataFrame
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103], "name": ["张三", "李四", "王五"],
"age": [15, 16, 17]})
print(df)运行结果:

2.通过字典创建时指定列的顺序和行索引
import pandas as pd
df = pd.DataFrame({"name": ["张三", "李四", "王五"], "age": [15, 16, 17]},
columns= ["age", "name"], index= [101, 102, 103])
print(df)运行结果:

三.DataFrame的常用属性
|
属性 |
说明 |
|
index |
DataFrame的行索引 |
|
columns |
DataFrame的列标签 |
|
values |
DataFrame的值 |
|
ndim |
DataFrame的维度 |
|
shape |
DataFrame的形状 |
|
size |
DataFrame的元素个数 |
|
dtypes |
DataFrame的元素类型 |
|
T |
行列转置 |
|
loc[] |
显式索引,按行列标签索引或切片 |
|
iloc[] |
隐式索引,按行列位置索引或切片 |
|
at[] |
使用行列标签访问单个元素 |
|
iat[] |
使用行列位置访问单个元素 |
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的行索引
print(df.index)![]()
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的列标签
print(df.columns)![]()
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的值
print(df.values)
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的维度
print(df.ndim)![]()
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的形状
print(df.shape)![]()
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的元素个数
print(df.size)![]()
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# DataFrame的元素类型
print(df.dtypes)
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# 行列转置
print(df.T)
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# 显式索引,按行列标签索引或切片
print(df.loc["bb":"cc", :"name"])
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# 隐式索引,按行列位置索引或切片
print(df.iloc[1:3, 0:1])
注意:位置索引都是含左不含右的。
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# 使用行列标签访问单个元素
print(df.at["aa", "name"])![]()
import pandas as pd
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [15, 16, 17]}, index=["aa", "bb", "cc"])
# 使用行列位置访问单个元素
print(df.iat[1, 1])![]()
四.DataFrame的常用方法
|
方法 |
说明 |
|
head() |
查看前n行数据,默认5行 |
|
tail() |
查看后n行数据,默认5行 |
|
isin() |
元素是否包含在参数集合中 |
|
isna() |
元素是否为缺失值 |
|
sum() |
求和 |
|
mean() |
平均值 |
|
min() |
最小值 |
|
max() |
最大值 |
|
var() |
方差 |
|
std() |
标准差 |
|
median() |
中位数 |
|
mode() |
众数 |
|
quantile() |
指定位置的分位数,如quantile(0.5) |
|
describe() |
常见统计信息 |
|
info() |
基本信息 |
|
value_counts() |
每个元素的个数 |
|
count() |
非空元素的个数 |
|
drop_duplicates() |
去重 |
|
sample() |
随机采样 |
|
replace() |
用指定值代替原有值 |
|
equals() |
判断两个DataFrame是否相同 |
|
cummax() |
累计最大值 |
|
cummin() |
累计最小值 |
|
cumsum() |
累计和 |
|
cumprod() |
累计积 |
|
diff() |
一阶差分,对序列中的元素进行差分运算,也就是用当前元素减去前一个元素得到差值,默认情况下,它会计算一阶差分,即相邻元素之间的差值。参数: periods:整数,默认为 1。表示要向前或向后移动的周期数,用于计算差值。正数表示向前移动,负数表示向后移动。 axis:指定计算的轴方向。0 或 'index' 表示按列计算,1 或 'columns' 表示按行计算,默认值为 0。 |
|
sort_index() |
按行索引排序 |
|
sort_values() |
按某列的值排序,可传入列表来按多列排序,并通过ascending参数设置升序或降序 |
|
nlargest() |
返回某列最大的n条数据 |
|
nsmallest() |
返回某列最小的n条数据 |
在Pandas的 DataFrame 方法里,axis 是一个非常重要的参数,它用于指定操作的方向。
axis 参数可以取两个主要的值,即 0 或 'index',以及 1 或 'columns' ,其含义如下:
- axis=0 或 axis='index':表示操作沿着行的方向进行,也就是对每一列的数据进行处理。例如,当计算每列的均值时,就是对每列中的所有行数据进行计算。
- axis=1 或 axis='columns':表示操作沿着列的方向进行,也就是对每行的数据进行处理。例如,当计算每行的总和时,就是对每行中的所有列数据进行计算。
其实和numpy中的概念相同。
import pandas as pd
df = pd.DataFrame(data={"id": [101, 102, 103,104,105,106,101],
"name": ["张三", "李四", "王五","赵六","冯七","周八","张三"],
"age": [10, 20, 30, 40, None, 60,10]},
index=["aa", "bb", "cc", "dd", "ee", "ff","aa"])
# head() 查看前n行数据,默认5行
print(df.head())
import pandas as pd
df = pd.DataFrame(data={"id": [101, 102, 103,104,105,106,101],
"name": ["张三", "李四", "王五","赵六","冯七","周八","张三"],
"age": [10, 20, 30, 40, None, 60,10]},
index=["aa", "bb", "cc", "dd", "ee", "ff","aa"])
# tail() 查看后n行数据,默认5行
print(df.tail(3))
import pandas as pd
df = pd.DataFrame(data={"id": [101, 102, 103,104,105,106,101],
"name": ["张三", "李四", "王五","赵六","冯七","周八","张三"],
"age": [10, 20, 30, 40, None, 60,10]},
index=["aa", "bb", "cc", "dd", "ee", "ff","aa"])
# isin() 元素是否包含在参数集合中
print(df.isin(["王五"]))
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# isna() 元素是否为缺失值
print(df.isna())
还是那句话,None会在Pandas数据结构里转化为np.nan。
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# sum() 求和
print(df["age"].sum())![]()
df[列标签名]取出来的就是这个列。换言之,对一个列求和是合理的,对一行求和就不合理了,因为一行里的数据一般不是一种数据类型,也不会有这种需求。
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# mean() 平均值
print(df["age"].mean())![]()
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# min() 最小值
print(df["age"].min())![]()
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# max() 最大值
print(df["age"].max())![]()
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# var() 方差
print(df["age"].var())![]()
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# std() 标准差
print(df["age"].std())![]()
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# median() 中位数
print(df["age"].median())![]()
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# mode() 众数
print(df["age"].mode())
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# quantile() 指定位置的分位数
print(df["age"].quantile(0.5, interpolation="linear"))![]()
这在Series篇详细介绍过,不再介绍。
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# describe() 常见统计信息
print(df["age"].describe())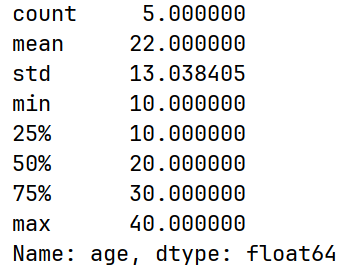
也可查看整个df的describe(),而不是只能看单独一列Series的。
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# info() 基本信息
print(df["age"].info())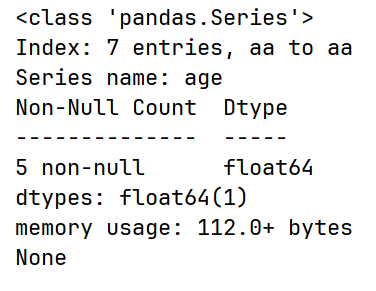
也可查看整个df的info(),而不是只能看单独一列Series的。
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# value_counts() 每个元素的个数
print(df.value_counts())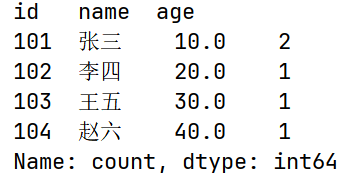
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# count() 非空元素的个数
print(df.count())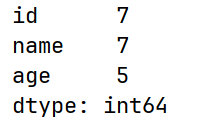
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# drop_duplicates()
print(df.drop_duplicates())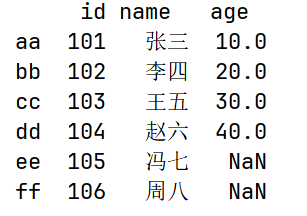
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# sample()
print(df.sample())
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# replace() 用指定值代替原有值
print(df.replace(20, "haha"))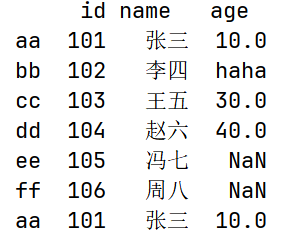
import pandas as pd
import numpy as np
# equals() 判断两个DataFrame是否相同
df1 = pd.DataFrame(data={"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [10, 20, 30]})
df2 = pd.DataFrame(data={"id": [101, 102, 103],
"name": ["张三", "李四", "王五"],
"age": [10, 20, 30]})
print(df1.equals(df2))![]()
import pandas as pd
import numpy as np
# cummax() 累计最大值
df3 = pd.DataFrame(data={'A': [2, 5, 3, 7, 4],
'B': [1, 6, 2, 8, 3]})
# 按列 等价于 axis=0 默认
print(df3.cummax(axis="index"))
print("----------------------------------")
# 按行 等价于 axis=1
print(df3.cummax(axis="columns"))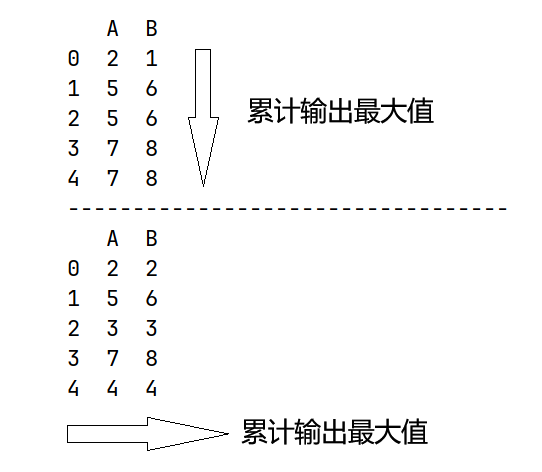
import pandas as pd
import numpy as np
df3 = pd.DataFrame(data={'A': [2, 5, 3, 7, 4],
'B': [1, 6, 2, 8, 3]})
# cummin() 累计最小值
print(df3.cummin())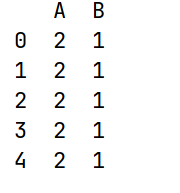
import pandas as pd
import numpy as np
df3 = pd.DataFrame(data={'A': [2, 5, 3, 7, 4],
'B': [1, 6, 2, 8, 3]})
# cumsum() 累计和
print(df3.cumsum())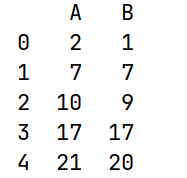
import pandas as pd
import numpy as np
df3 = pd.DataFrame(data={'A': [2, 5, 3, 7, 4],
'B': [1, 6, 2, 8, 3]})
# cumprod()累计积
print(df3.cumprod())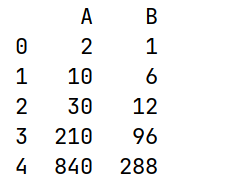
import pandas as pd
import numpy as np
df3 = pd.DataFrame(data={'A': [2, 5, 3, 7, 4],
'B': [1, 6, 2, 8, 3]})
# diff() 一阶积分
print(df3.diff())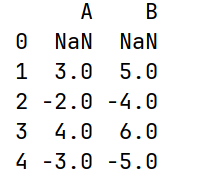
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# sort_index() 按行索引排序
print(df.sort_index())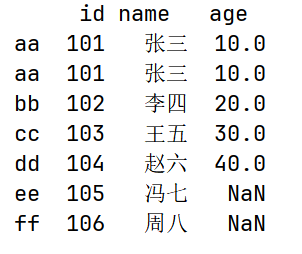
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# sort_values() 按某列的值排序,可传入列表来按多列排序,并通过ascending参数设置升序或降序
print(df.sort_values(by = ["age"]))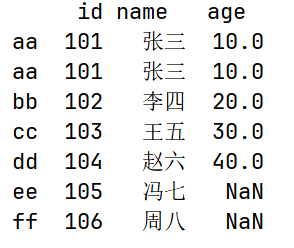
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# nlargest() 返回某列最大的n条数据
print(df.nlargest(n=2, columns="age"))
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": [101, 102, 103, 104, 105, 106, 101],
"name": ["张三", "李四", "王五", "赵六", "冯七", "周八", "张三"],
"age": [10, 20, 30, 40, None, np.nan, 10]},
index=["aa", "bb", "cc", "dd", "ee", "ff", "aa"])
# nsmallest() 返回某列最小的n条数据
print(df.nsmallest(n=1, columns="age"))
五.DataFrame的布尔索引
可以使用布尔索引从DataFrame中筛选满足某些条件的行。
import pandas as pd
df = pd.DataFrame(data={"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 104, 103, 102])
print(df["age"] > 25)
print("---------------")
print(df[df["age"] > 25])
六.DataFrame的运算
1.DataFrame与标量运算
import pandas as pd
df = pd.DataFrame(data={"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 104, 103, 102],)
print(df * 2)
2.DataFrame与DataFrame运算
根据标签索引进行对位计算,索引没有匹配上的用NaN填充。
import pandas as pd
import numpy as np
df1 = pd.DataFrame(data={"age": [10, 20, 30, 40],
"name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 102, 103, 104],)
df2 = pd.DataFrame(data={"age": [10, 20, 30, 40],
"name": ["张三", "李四", "王五", "田七"]},
columns=["name", "age"],
index=[102, 103, 104, 105],)
print(df1 + df2)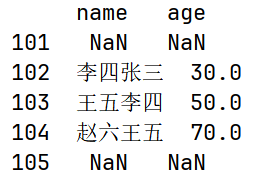
七.DataFrame的更改操作
1.设置行索引
创建DataFrame时如果不指定行索引,pandas会自动添加从0开始的索引。
import pandas as pd
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
print(df)
通过set_index()设置行索引:
import pandas as pd
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
# inplace=True:这是一个布尔类型的参数。当设为 True 时,会直接在原
# DataFrame上进行修改;若设为 False(默认值),则会返回一个新的
# DataFrame,原DataFrame 保持不变
df.set_index("id", inplace=True)
print(df)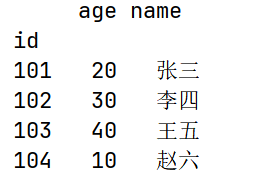
通过reset_index()重置行索引:
import pandas as pd
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
# inplace=True:这是一个布尔类型的参数。当设为 True 时,会直接在原
# DataFrame上进行修改;若设为 False(默认值),则会返回一个新的
# DataFrame,原DataFrame 保持不变
df.set_index("id", inplace=True)
print(df)
df.reset_index(inplace=True)
print("---------------")
print(df)
2.修改行索引名和列名
通过rename()修改行索引名和列名:
import pandas as pd
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
print(df)
print("------------------")
df.rename(index={101: "一", 102: "二", 103: "三", 104: "四"},
columns={"age": "年龄", "name": "姓名"}, inplace=True)
print(df)
将index和columns重新赋值:
import pandas as pd
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
# print(df)
# print("------------------")
df.rename(index={101: "一", 102: "二", 103: "三", 104: "四"},
columns={"age": "年龄", "name": "姓名"}, inplace=True)
# print(df)
df.index= ["I", "II", "III", "IV"]
df.columns = ["年齡", "名稱"]
print(df)
添加列:
通过 df[“列名”] 添加列。
import pandas as pd
import numpy as np
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
df["phone"] = ["13333333333", "14444444444",
"15555555555", "16666666666"]
print(df)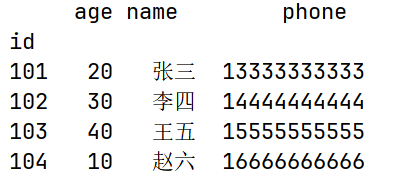
删除列:
通过 df.drop(“列名”, axis=1) 删除,也可是删除行 axis=0。
import pandas as pd
import numpy as np
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
df["phone"] = ["13333333333", "14444444444",
"15555555555", "16666666666"]
# print(df)
df.drop("phone", axis=1, inplace=True)
print(df)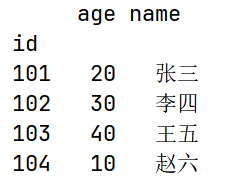
import pandas as pd
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
df["phone"] = ["13333333333", "14444444444",
"15555555555", "16666666666"]
del df["phone"]
print(df)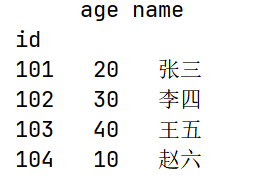
插入列:
通过 insert(loc, column, value) 插入。该方法没有inplace参数,直接在原数据上修改。
import pandas as pd
import numpy as np
df = pd.DataFrame({"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
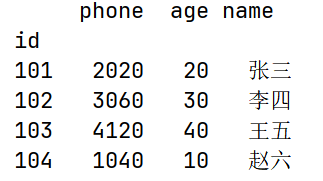
df.insert(loc=0, column="phone", value=df["age"] * df.index)
print(df)
八.DataFrame数据的导入与导出
1.导出数据
|
方法 |
说明 |
|
to_csv() |
将数据保存为csv格式文件,数据之间以逗号分隔,可通过sep参数设置使用其他分隔符,可通过index参数设置是否保存行标签,可通过header参数设置是否保存列标签。 |
|
to_pickle() |
如要保存的对象是计算的中间结果,或者保存的对象以后会在Python中复用,可把对象保存为.pickle文件。如果保存成pickle文件,只能在python中使用。文件的扩展名可以是.p、.pkl、.pickle。 |
|
to_excel() |
保存为Excel文件,需安装openpyxl包。 |
|
to_clipboard() |
保存到剪切板。 |
|
to_dict() |
保存为字典。 |
|
to_hdf() |
保存为HDF格式,需安装tables包。HDF(Hierarchical Data Format)是一种面向科学与工程的分层二进制数据格式,核心用于存储、组织和共享海量、多维、复杂结构的数据,常见后缀为 |
|
to_html() |
保存为HTML格式,需安装lxml、html5lib、beautifulsoup4包。 |
|
to_json() |
保存为JSON格式。 |
|
to_feather() |
feather是一种文件格式,用于存储二进制对象。feather对象也可以加载到R语言中使用。feather格式的主要优点是在Python和R语言之间的读写速度要比csv文件快。feather数据格式通常只用中间数据格式,用于Python和R之间传递数据,一般不用做保存最终数据。需安装pyarrow包。 |
|
to_sql() |
保存到数据库。 |
import os
import pandas as pd
os.makedirs("data", exist_ok=True)
df = pd.DataFrame({"age": [20, 30, 40, 10], "name": ["张三", "李四", "王五", "赵六"], "id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
df.to_csv("data/df.csv")
df.to_csv("data/df.tsv", sep="\t") # 设置分隔符为 \t
df.to_csv("data/df_noindex.csv", index=False) # index=False 不保存行索引
df.to_pickle("data/df.pkl")
df.to_excel("data/df.xlsx")
df.to_clipboard()
df_dict = df.to_dict()
df.to_hdf("data/df.h5", key="df")
df.to_html("data/df.html")
df.to_json("data/df.json")
df.to_feather("data/df.feather")2.导入数据
|
方法 |
说明 |
|
read_csv() |
加载csv格式的数据。可通过sep参数指定分隔符,可通过index_col参数指定行索引。 |
|
read_pickle() |
加载pickle格式的数据。 |
|
read_excel() |
加载Excel格式的数据。 |
|
read_clipboard() |
加载剪切板中的数据。 |
|
read_hdf() |
加载HDF格式的数据。 |
|
read_html() |
加载HTML格式的数据。 |
|
read_json() |
加载JSON格式的数据。 |
|
read_feather() |
加载feather格式的数据。 |
|
read_sql() |
加载数据库中的数据。 |
df_csv = pd.read_csv("data/df.csv", index_col="id") # 指定行索引
df_tsv = pd.read_csv("data/df.tsv", sep="\t") # 指定分隔符
df_pkl = pd.read_pickle("data/df.pkl")
df_excel = pd.read_excel("data/df.xlsx", index_col="id")
df_clipboard = pd.read_clipboard(index_col="id")
df_from_dict = pd.DataFrame(df_dict)
df_hdf = pd.read_hdf("data/df.h5", key="df")
df_html = pd.read_html("data/df.html", index_col=0)[0]
df_json = pd.read_json("data/df.json")
df_feather = pd.read_feather("data/df.feather")
print(df_csv)
print(df_tsv)
print(df_pkl)
print(df_excel)
print(df_clipboard)
print(df_from_dict)
print(df_hdf)
print(df_html)
print(df_json)
print(df_feather)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)