NLP学习笔记11:序列到序列模型——从 Encoder-Decoder 到 Attention
NLP学习笔记11:序列到序列模型——从 Encoder-Decoder 到 Attention
作者:Ye Shun
日期:2026-04-19
一、前言
在自然语言处理任务中,我们经常会遇到这样一类问题:
- 输入是一段序列
- 输出也是一段序列
- 输入和输出的长度还不一定相同
例如:
- 机器翻译:中文句子 → 英文句子
- 文本摘要:长文本 → 短摘要
- 对话生成:用户输入 → 系统回复
- 问题生成:文章片段 → 问题
这类任务最经典的建模方式之一,就是序列到序列模型(Sequence-to-Sequence, Seq2Seq)。
Seq2Seq 的核心思想非常直观:
先把输入序列“读懂”,再把它“写出来”。
也就是说:
- 前半部分负责理解输入
- 后半部分负责生成输出
这篇笔记将围绕以下几个问题展开:
- 什么是 Seq2Seq 模型
- 编码器和解码器分别在做什么
- 为什么基础 Seq2Seq 会遇到瓶颈
- Attention 是如何改进 Seq2Seq 的
- Seq2Seq 在机器翻译、摘要和对话中的典型应用
- 如何用代码实现一个最小 Seq2Seq 模型
二、什么是序列到序列模型
Seq2Seq 模型是一种把一个输入序列映射为另一个输出序列的神经网络架构。
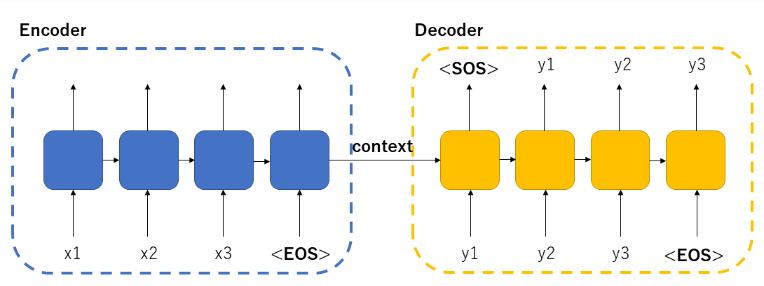
它通常采用 Encoder-Decoder(编码器-解码器) 结构:
- 编码器(Encoder):读取输入序列,并将其编码成内部表示
- 解码器(Decoder):根据编码结果逐步生成输出序列
如果以机器翻译为例:
- 输入序列:
我 喜欢 自然语言处理 - 输出序列:
I love natural language processing
这里输入和输出:
- 长度不同
- 词汇空间不同
- 语序可能不同
因此,普通的分类模型并不适合,而 Seq2Seq 天然适合这种“序列到序列”的转换任务。
三、Seq2Seq 的基础架构
1. 编码器(Encoder)
编码器的任务是按顺序读取输入 token,并逐步更新隐藏状态。
在早期 Seq2Seq 模型中,编码器通常由:
- RNN
- LSTM
- GRU
来实现。
假设输入序列为:
x1,x2,x3,...,xTx_1, x_2, x_3, ..., x_Tx1,x2,x3,...,xT
那么编码器在每个时间步都会更新隐藏状态:
ht=f(xt,ht−1)h_t = f(x_t, h_{t-1})ht=f(xt,ht−1)
最终,最后一个隐藏状态会被视作整个输入序列的语义表示,也就是所谓的 上下文向量(context vector)。
2. 解码器(Decoder)
解码器的任务是根据上下文向量,逐步生成输出序列:
y1,y2,y3,...,yNy_1, y_2, y_3, ..., y_Ny1,y2,y3,...,yN
解码器在每一步通常会接收:
- 上一步生成的 token
- 上一步的隐藏状态
- 编码器提供的上下文信息
然后预测当前时刻最可能的输出 token。
3. 基本流程
一个标准的 Seq2Seq 工作过程如下:
- 编码器读取整个输入序列
- 得到上下文向量
- 解码器以该向量初始化状态
- 从起始标记
<SOS>开始逐步生成输出 - 当生成结束标记
<EOS>时停止
这就是最基础的 Encoder-Decoder 思路。
四、基础 Seq2Seq 的问题:固定长度上下文瓶颈
早期 Seq2Seq 最大的问题在于:
整个输入序列的信息,要被压缩进一个固定长度向量中。
这在短句上也许还行,但当输入很长时,就会出现明显问题:
- 前面的信息容易被遗忘
- 长距离依赖难以保留
- 输入越长,压缩越困难
例如在长句翻译中,句尾的信息可能还能保留,但句首的细节很容易丢失。
这个问题通常被称为:
- 信息瓶颈
- 固定上下文向量问题
这也是为什么 Seq2Seq 很快引入了一个关键改进:Attention 机制。
五、Attention 如何改进 Seq2Seq
Attention 的核心思想是:
解码器在生成每个输出词时,不必只依赖一个固定的上下文向量,而是可以动态地“回头看”输入序列中的不同位置。
也就是说,解码器在生成第 ttt 个词时,会对编码器所有隐藏状态:
h1,h2,...,hTh_1, h_2, ..., h_Th1,h2,...,hT
计算一组权重:
αt,1,αt,2,...,αt,T\alpha_{t,1}, \alpha_{t,2}, ..., \alpha_{t,T}αt,1,αt,2,...,αt,T
这些权重表示:
- 当前输出更应该关注输入序列中的哪些位置
然后得到一个动态上下文向量:
ct=∑i=1Tαt,ihic_t = \sum_{i=1}^{T}\alpha_{t,i} h_ict=i=1∑Tαt,ihi
这样带来的好处非常明显:
- 不再只依赖单个固定向量
- 长句性能显著提升
- 模型更容易建立输入和输出之间的对齐关系
例如在机器翻译中,当模型生成“processing”时,它可以重点关注中文中的“处理”。
六、Seq2Seq 中常见的关键技术
1. Teacher Forcing
在训练解码器时,常用 Teacher Forcing(教师强制) 技术。
它的做法是:
- 训练时,把真实的上一个输出词作为当前步输入
- 而不是把模型自己预测的词再喂回去
好处是训练更稳定、收敛更快。
但也会带来一个问题:
- 训练时看到的是真实历史
- 测试时只能依赖自己生成的历史
这会造成 训练与推理不一致,也叫 曝光偏差(Exposure Bias)。
2. Greedy Search 与 Beam Search
在生成时,最简单的方法是:
- 每一步都选概率最高的 token
这叫 贪心解码(Greedy Search)。
但贪心策略并不一定能得到全局最优结果,因此常用 Beam Search:
- 同时保留多个候选序列
- 每一步扩展这些候选
- 最后选择整体概率更高的输出
Beam Search 往往可以显著提升机器翻译和摘要生成质量。
3. 双向编码器
为了更好地理解输入序列,编码器常常使用 双向 RNN(BiRNN / BiLSTM / BiGRU)。
它会同时考虑:
- 从左到右的上下文
- 从右到左的上下文
从而让每个输入位置的表示更完整。
七、Seq2Seq 的典型应用场景
1. 机器翻译
机器翻译是 Seq2Seq 最经典的应用场景之一。
特点:
- 输入输出都为文本序列
- 两种语言长度不一致
- 需要处理语义、语法和词序变化
常见改进包括:
- Attention
- 子词切分(BPE、WordPiece)
- Beam Search
- Transformer 编码器-解码器
2. 文本摘要
文本摘要中的生成式摘要,本质上也是 Seq2Seq:
- 输入:原文
- 输出:摘要
与翻译不同的是,摘要要求模型:
- 压缩信息
- 保留核心内容
- 避免重复
因此常见扩展包括:
- Pointer-Generator(指针生成网络)
- Coverage Mechanism(覆盖机制)
3. 对话生成
对话系统中,模型需要根据用户输入生成回复:
- 输入:当前对话上下文
- 输出:回复文本
这同样属于 Seq2Seq 范式。
不过对话生成比翻译更难,因为它通常:
- 开放性更强
- 标准答案不唯一
- 更容易生成空泛回答,如“好的”“我明白了”
因此很多对话系统会加入:
- 人设信息
- 对话状态
- 情感控制
- 检索增强
八、Seq2Seq 与 Transformer 的关系
很多初学者会误以为:
- Seq2Seq 是一种具体模型
- Transformer 是另一种完全不同的东西
其实更准确地说:
- Seq2Seq 是任务建模范式
- Transformer 是实现 Seq2Seq 的一种更强架构
早期 Seq2Seq 常用:
- RNN 编码器
- RNN 解码器
后来发展为:
- Attention-based Seq2Seq
- Transformer Encoder-Decoder
因此,Transformer 可以看作是 Seq2Seq 思想在注意力框架下的现代化实现。
例如:
- 原始机器翻译模型:RNN Seq2Seq
- 现代翻译模型:Transformer Seq2Seq
- T5:典型的文本到文本 Seq2Seq Transformer
九、Seq2Seq 的训练与评估
1. 训练步骤
Seq2Seq 的训练通常包括以下流程:
- 构造输入序列和目标序列
- 对文本进行 tokenization
- 构建词表或子词表
- 编码器得到输入表示
- 解码器逐步预测输出
- 使用交叉熵损失计算误差
- 反向传播更新参数
2. 常见评估指标
不同任务会使用不同指标:
| 任务 | 常见指标 |
|---|---|
| 机器翻译 | BLEU |
| 文本摘要 | ROUGE |
| 对话生成 | BLEU、Distinct、人工评估 |
需要注意的是,生成任务仅靠自动指标往往不够,因此人工评估仍然很重要。
十、一个最小 Seq2Seq 模型应该包含什么
如果我们要自己写一个最小可理解版 Seq2Seq,通常需要这些组件:
- 输入嵌入层
Embedding - 编码器
Encoder - 注意力模块
Attention - 解码器
Decoder - 输出层
Linear
如果是训练模式,还需要:
<SOS>起始标记<EOS>结束标记- Teacher Forcing
下面是一个极简示意:
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt):
encoder_outputs, hidden = self.encoder(src)
outputs = self.decoder(tgt, hidden, encoder_outputs)
return outputs
真正可用的版本还会进一步处理:
- mask
- padding
- batch
- beam search
- attention weights
十一、实践理解:为什么 Seq2Seq 很重要
Seq2Seq 的意义不只是“能做翻译”。
更重要的是,它建立了一种统一视角:
- 把很多 NLP 任务都看成“输入文本序列 → 输出文本序列”
这个思路后来影响了很多模型设计,例如:
- 机器翻译
- 摘要生成
- 问答生成
- 语法纠错
- 文本改写
- T5 的 Text-to-Text 范式
也就是说,Seq2Seq 不只是一个早期模型,而是一种非常核心的建模思想。
十二、总结
Seq2Seq 模型是自然语言处理中非常重要的一类架构,它的核心思想可以概括为:
- 用编码器理解输入序列
- 用解码器生成输出序列
- 用 Attention 改善长序列建模能力
它的发展路径大致是:
- 基础 RNN Seq2Seq
- Attention-based Seq2Seq
- Transformer Seq2Seq
理解 Seq2Seq 的价值在于:
- 它帮助我们真正理解“生成任务”是如何建模的
- 它是理解机器翻译、摘要、对话系统和 T5 等模型的重要基础
如果说前面的 RNN、Attention、Transformer 是“零件”,
那么 Seq2Seq 就是在告诉我们:这些零件如何组合起来,完成一个从输入到输出的完整生成过程。
十三、参考学习方向
如果你想继续深入,可以接着学习这些主题:
- Bahdanau Attention 与 Luong Attention 的区别
- Beam Search 的具体实现
- Pointer-Generator 在摘要中的作用
- Transformer Encoder-Decoder 结构
- T5/BART 这类现代 Seq2Seq 预训练模型

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)