混音教学第六课|RVC WebUI 全界面逐功能深度详解
作者:龙沅可
(底层原理 + 调参逻辑 + 破音全套优化完整版・GTX1050Ti 真机专属)各位音乐编程圈的兄弟,我是深耕实战 3 年的地下程序员胡桃。上节课我们完成了RVC1006Nvidia 解压启动、端口打通、成功进入 WebUI 网页界面。很多人打开界面后满屏标签、滑块、路径框完全无从下手,只知道点转换,出现破音、电音、沙哑、音色奇怪也不知道改哪里。
本节课做到无死角全覆盖讲解,界面内每一个标签、每一个按钮、每一条路径、每一组参数滑块全部拆解,不止告诉你功能是什么,重点讲清:底层原理、数值上调 / 下调的音色变化、官方最优设定原因、出现破音 / 电音 / 杂音该怎么调、为什么要这么调。全程对应本机真机截图,衔接此前所有知识点:洛天依模型weights存放路径、索引logs存放规则、GTX1050Ti 显存限制、VOCALOID 性别值原理、人声分离前置流程、原版《水手》音色崩坏根源。
全篇总纲(界面六大模块定位)
- 模型推理:日常翻唱唯一核心界面,99% 的创作全部在此完成,附带全套破音、电音、沙哑应急调参手册
- 伴奏人声分离 & 去混响 & 去回声:软件内置分离工具,功能齐全但我们基本不用,附带原因详解
- 训练:从零自制新模型高阶界面,普通翻唱玩家全程无需触碰
- ckpt 处理:模型融合、精简提取、信息修改专用工具
- Onnx 导出:模型格式转换、跨平台 API 部署专用
- 常见问题解答:软件全报错根源 + 兜底解决方案
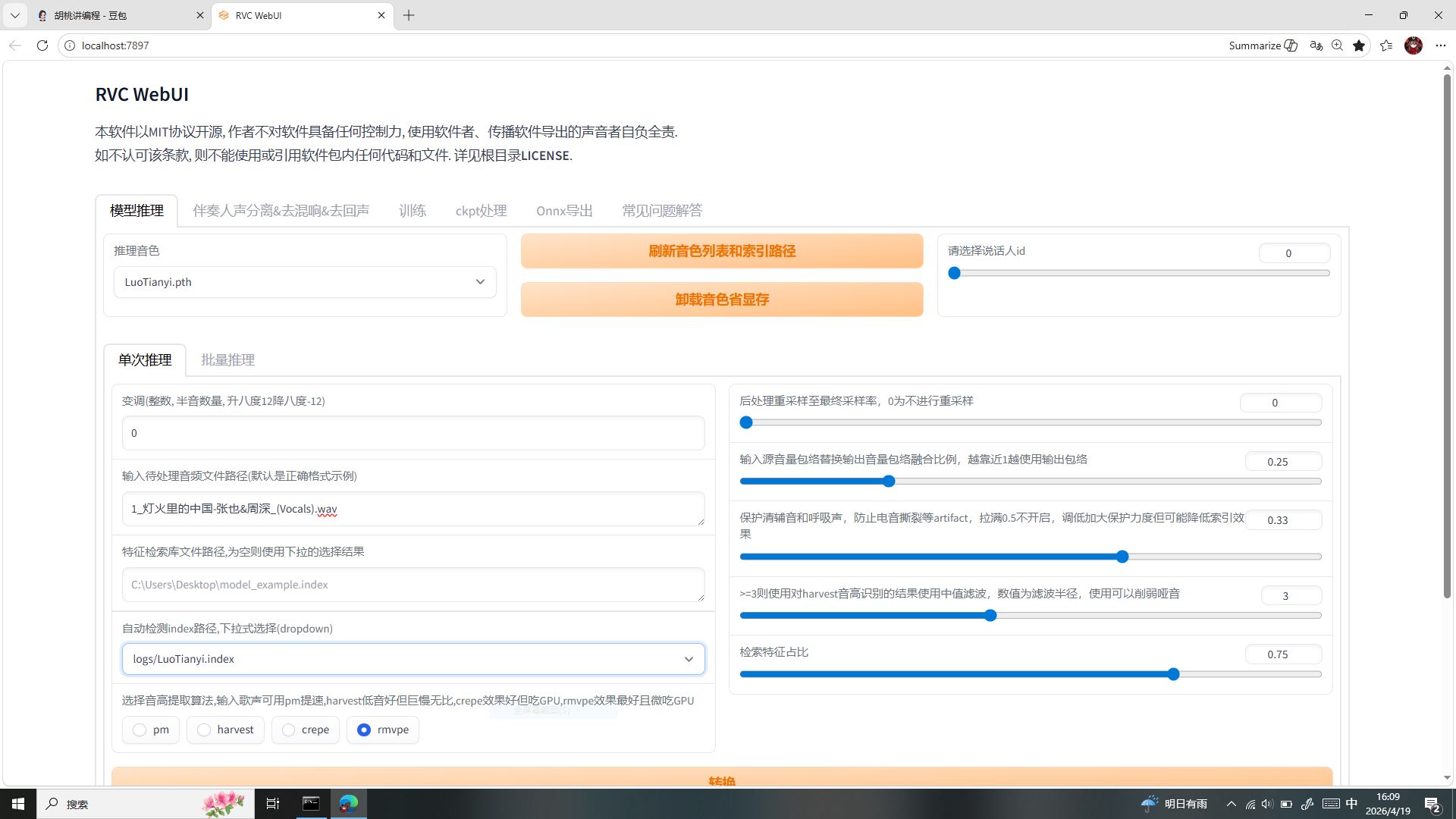
一、标签一:模型推理(翻唱核心主界面・全参数原理详解)
这是你之后做所有洛天依 AI 翻唱唯一需要常驻的界面,模型加载、人声转换、音色优化全部在此完成,下方所有控件逐行拆解,附带调参原理与破音修复逻辑。
顶部音色管理区域
- 刷新音色列表和索引路径
- 功能:扫描软件目录,加载模型与索引文件
- 底层原理:软件不会自动读取文件夹文件,必须手动触发扫描
- 为什么要点:我们放入
assets\weights的洛天依.pth模型、放入logs文件夹的.index索引,只有点击此按钮,WebUI 界面才能识别并加载到下拉选项中;更换模型、重装模型后必须重新点击刷新。
- 卸载音色省显存
- 功能:清空后台已加载的音色模型,释放显卡显存
- 底层原理:模型会常驻显卡显存,占用不释放会持续占用资源
- 为什么要用:你的显卡为GTX 1050Ti 4G 小显存,显存本身紧缺,切换音色、长时间运行软件时点击卸载,避免显存溢出、软件闪退崩溃,低配卡保命必备功能。
- 请选择说话人 id
- 功能:切换模型内的多音色人声
- 底层原理:多音色模型内置多个发声节点,用数字编号区分
- 为什么全程固定为 0:我们使用的洛天依 V4 萌专属模型为单声库模型,仅内置一个音色节点,无额外音色可切换,因此无需改动数值。
单次推理区域(翻唱转换核心参数区)
-
变调(整数,半音数量,对应 VOCALOID 性别值)
- 功能:整体偏移音频音高,改变声线粗细、男女音色偏向
- 底层原理:修改人声基频,拉高则声线偏尖细女声化,拉低则声线偏低沉厚重
- 数值变化影响数值上调:声线越尖、女声越强,过高会音色失真、机械感爆炸、极易破音;数值下调:声线越厚、越低沉,过低会闷糊、丢失洛天依原生音色。
- 为什么我们固定设置 ±1 以内轻微变调:对标官方洛天依《水手》无脑拉满变调导致音色崩坏、机械感拉满的问题,严格保留洛天依原本人设音色,不强行扭曲声线。
- 破音应急优化:出现破音、刺耳,第一时间降低变调数值原因:音高偏移超过模型拟合上限,基频溢出就会直接产生破音撕裂。
-
输入待处理音频文件路径
- 功能:导入需要转换声线的原始人声素材
- 底层原理:RVC 仅对导入音频进行声线替换,不处理伴奏
- 为什么只能导入纯净分离干声:必须使用此前 UVR5、万兴喵影分离完毕的无伴奏纯净人声;若直接导入带伴奏原曲,伴奏会被模型一同转换,产生底噪、杂讯、音色污染,成品全程杂音无法挽救。
-
特征检索库文件路径
- 功能:挂载模型配套的
.index索引文件 - 底层原理:
.pth模型是音色骨架,.index索引是音色血肉,存储咬字、泛音、细节特征数据库 - 为什么必须配对加载:缺少索引会导致音色空洞、沙哑、无辨识度、咬字模糊;模型与索引一一对应,缺一无法完成优质翻唱。
- 功能:挂载模型配套的
-
自动检测 index 路径下拉选择
- 功能:一键自动匹配对应模型的索引文件
- 原理:软件自动检索
logs文件夹,直接下拉选中洛天依专属索引即可,无需手动填写路径。
-
音高提取算法内置 pm、harvest、crepe、rmvpe 四种算法,负责提取原人声音高轨迹
- 为什么 GTX1050Ti 固定锁死
rmvpermvpe 音高提取精度最高、音色自然、对显卡显存占用最低,完美适配低配老卡;harvest 音质好但显存占用极高,低配卡直接爆显存;pm 速度快但精度差;crepe 显存开销大,均不适合本机使用。
- 为什么 GTX1050Ti 固定锁死
右侧后处理全套参数(每一项原理 + 调参 + 破音优化)
-
后处理重采样至最终采样率,0 为不进行重采样
- 功能:转换完成后统一音频采样率格式
- 为什么默认设置为 0:洛天依模型原生 40k 采样率,与我们前期分离的人声素材采样率完全匹配,无需二次重采样;重采样会损失音色细节、引入杂音,因此直接关闭不改动。
-
输入源音量包络替换输出音量包络融合比例
- 功能:平衡原人声气息起伏与 RVC 生成音色的音量动态
- 数值原理:越靠近 1,完全继承原人声气息、音量起伏;越靠近 0,完全使用 RVC 生成音色包络。
- 为什么固定 0.25:兼顾原人声自然的咬字、气息动态,同时不被原生人声音色污染,保留洛天依音色主体。
- 破音优化:适当加大数值,平滑音量突变点,压制尖锐破音。
-
保护清辅音和呼吸声,防止电音撕裂 artifact
- 功能:拦截高频齿音、气口溢出,避免转换产生电音、撕裂杂音
- 数值原理:滑块越往左,保护力度越强;拉满 0.5 则完全关闭保护。
- 为什么固定 0.33:平衡气口自然度与防电音效果,不会过度闷声也不会出现高频杂音。
- 电音 / 破音优化:往左调低数值,加强保护力度原因:电音本质是高频气息转换溢出,保护模块会直接拦截溢出频段。
-
>=3 则使用对 harvest 音高识别的结果使用中值滤波,数值为滤波半径
- 功能:平滑音色毛刺、哑音、断续卡顿的杂音
- 数值原理:数值越大,音色平滑效果越强;数值过高会导致音色糊掉。
- 为什么固定 3:刚好抹平哑音、断续瑕疵,同时不损失音色细节。
- 沙哑、卡顿优化:适当加大滤波半径,抹平音色毛刺与断续杂音。
-
检索特征占比
- 功能:控制索引音色权重占比,决定成品贴近洛天依音色的程度
- 数值原理:数值越高,越贴近目标模型(洛天依)音色;数值越低,越保留原人声原本音色。
- 为什么固定 0.75:最大程度还原洛天依原生音色,同时保留原曲旋律、咬字基底,不出现音色跑偏。
- 音色生硬、强行拟合破音优化:适当降低模型占比原因:占比过高会让模型强行扭曲人声,超出拟合范围就会产生破音、机械生硬。
底部【转换】按钮
- 功能:调用显卡 CUDA 算力,执行全套声线推理转换
- 原理:加载模型、索引、全部参数配置,读取人声轨迹,生成全新洛天依翻唱音频。
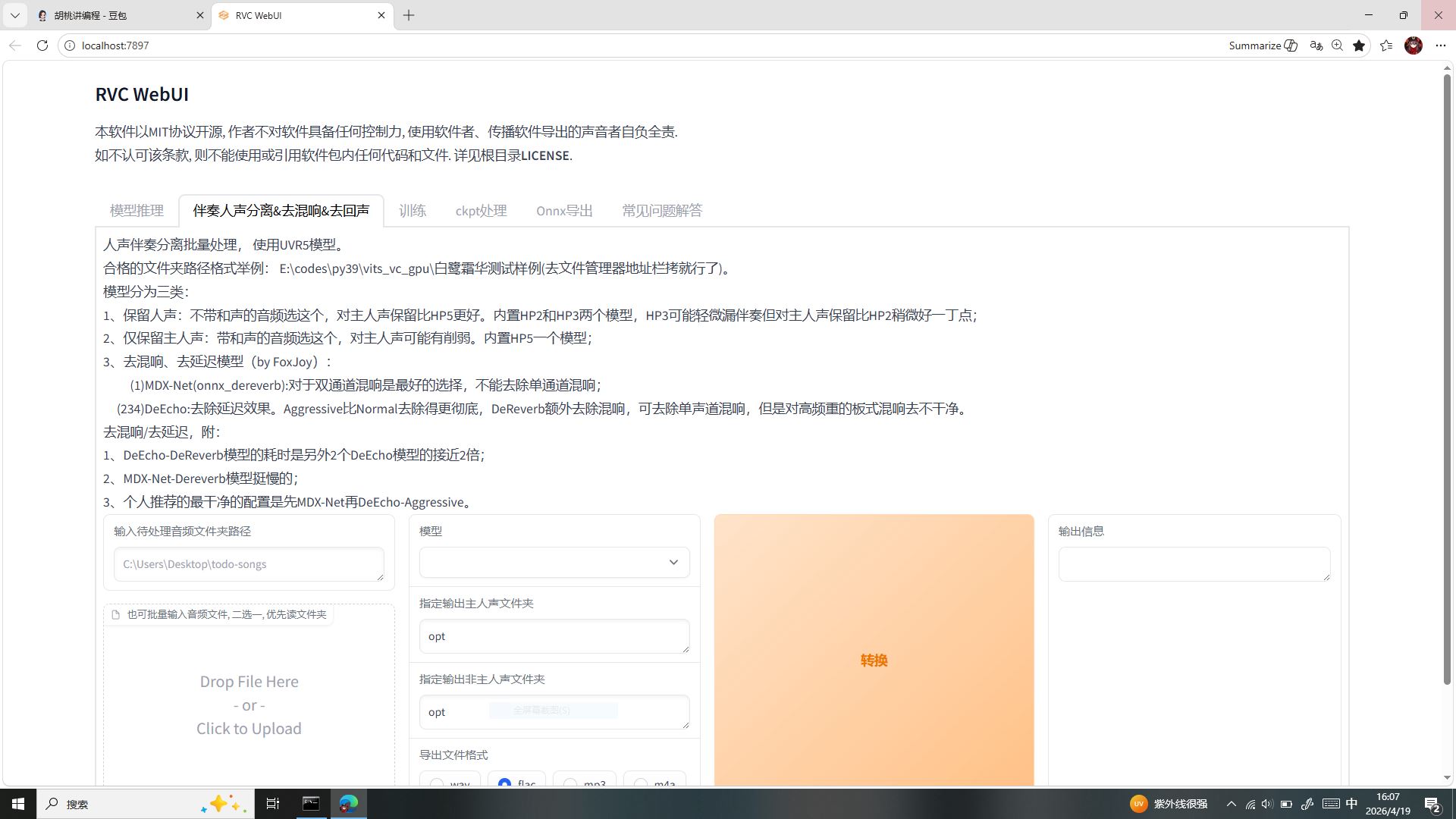
二、标签二:伴奏人声分离 & 去混响 & 去回声
界面全部功能详解
本模块为 RVC 内置的 UVR 系列音频分离工具,内置三类模型:
- HP2/HP3 保留人声模型:分离人声与伴奏,HP3 漏伴奏少、人声保留更好;
- 带和声专用分离模型:针对原曲和声素材单独提取人声;
- 去混响 / 去延迟模型:MDX-Net、DeEcho 系列,去除音频房间混响、后期回声。同时标注了官方最优处理流程:先 MDX-Net 去混响,再 DeEcho-Aggressive 深度去杂。
重点:为什么我们全程基本不用这个界面?
底层原因:前期教程我们已经固定使用万兴喵影 AI 分离 + UVR5 专业本地分离的双重流程,分离精度、去杂干净度远高于 RVC 内置工具;同时本模块运行会额外占用 GTX1050Ti 宝贵显存,老本算力有限,没必要重复进行分离操作,仅作为软件功能了解即可,日常创作完全闲置。
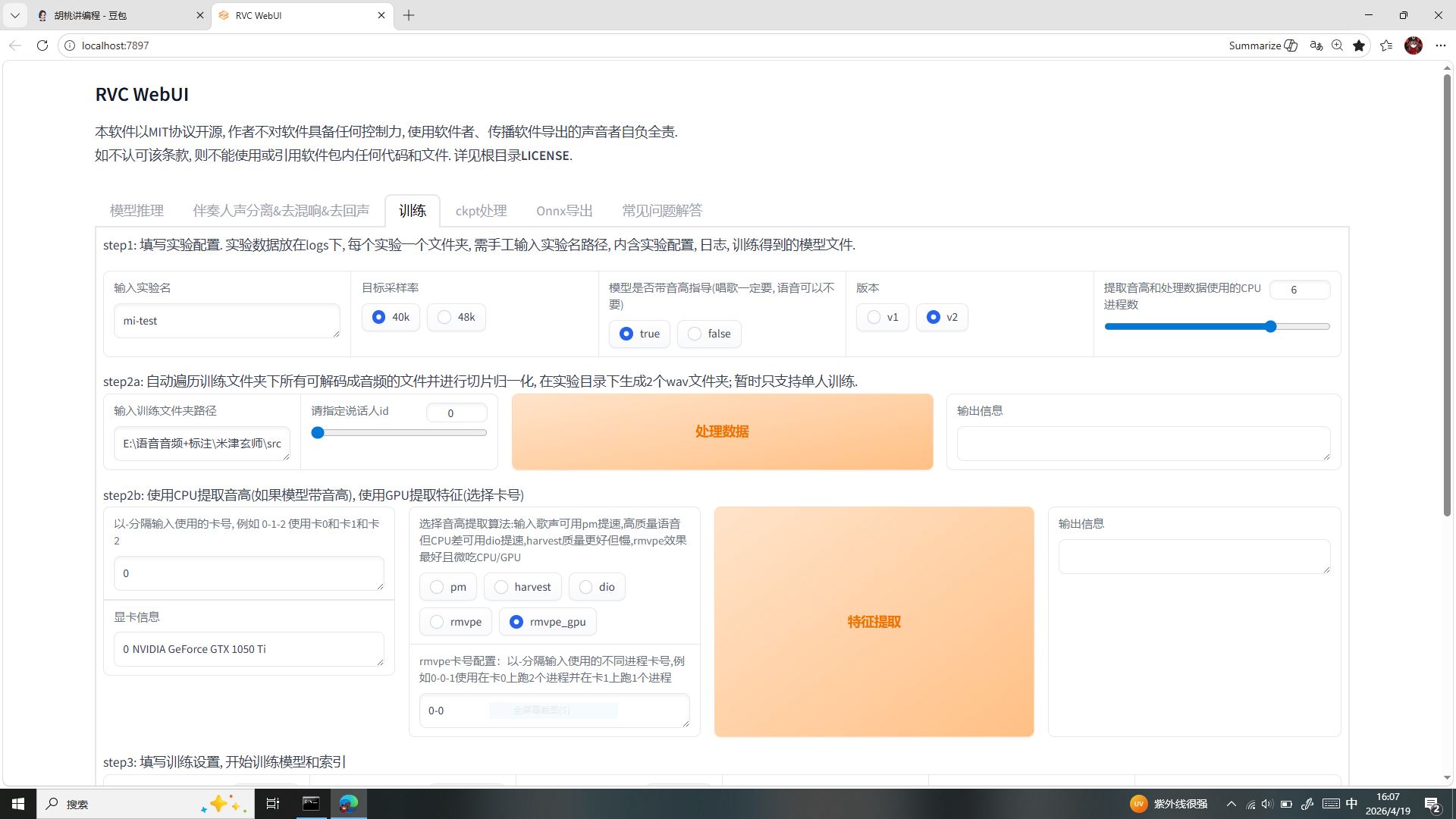
三、标签三:训练(高阶自制模型界面・普通玩家无需触碰)
从零训练全新专属 RVC 模型的完整流程界面,对应此前我用 GTX1050Ti “骗显卡配置训练模型” 的实操界面,分步拆解原理:
- step1 实验配置:填写实验命名、选择采样率、开启音高指导、选择模型 V2 版本、设置 CPU 进程数;原理:给本次训练建立独立文件夹,存储训练日志、模型文件、索引文件。
- step2a 处理数据:导入人声训练数据集,自动音频切片、归一化处理;原理:把长音频切割为模型可学习的短片段,统一音频格式。
- step2b 特征提取:CPU 提取音高、GPU 提取音色特征;原理:采集人声音色数据,为后续模型训练做数据准备。
- step3 开始训练:迭代训练神经网络,最终生成专属
.pth模型 +.index索引。
为什么普通翻唱玩家完全不用进入此界面?
底层原因:我们直接使用他人训练完毕、成熟优质的洛天依 V4 萌成品模型,无需从零自制声库;且 GTX1050Ti 仅能支撑极小数据集轻量化训练,大素材训练直接显存爆满死机,日常二创用不到训练功能。
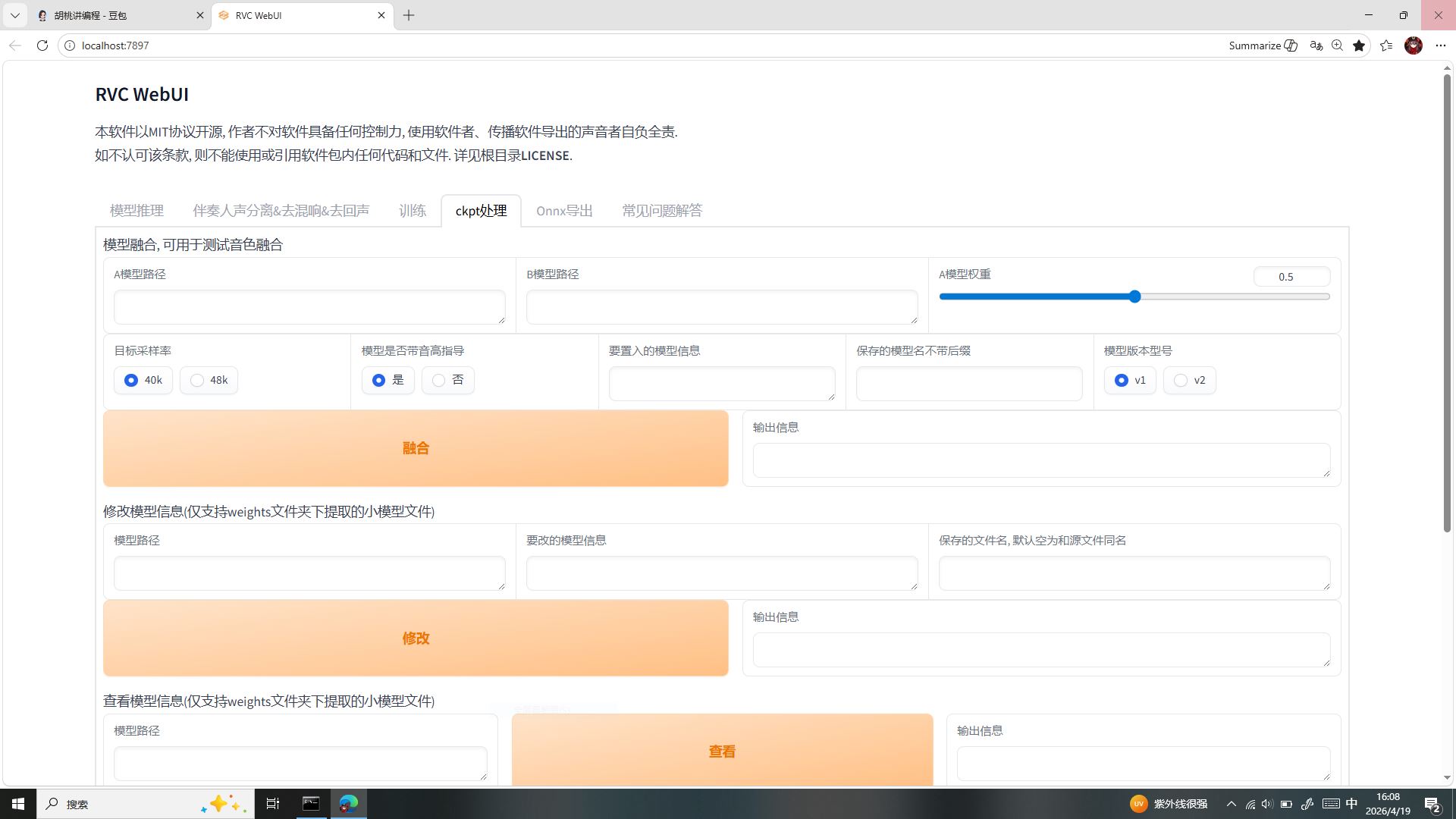
四、标签四:ckpt 处理(模型进阶管理界面)
两大功能模块全解
- 模型融合可导入 A、B 两个不同音色模型,通过权重滑块(默认 0.5)混合两个音色,创造全新融合声线;可设置采样率、是否带音高指导、模型 V1/V2 版本。为什么不用:我们仅使用纯净原版洛天依模型,不需要双音色混合改造。
- 修改模型信息、查看模型信息修改模型备注信息、从训练大包中提取轻量化推理小模型。底层原理:训练生成的大包文件无法直接分享使用,需要提取为 60MB 左右的精简推理模型。
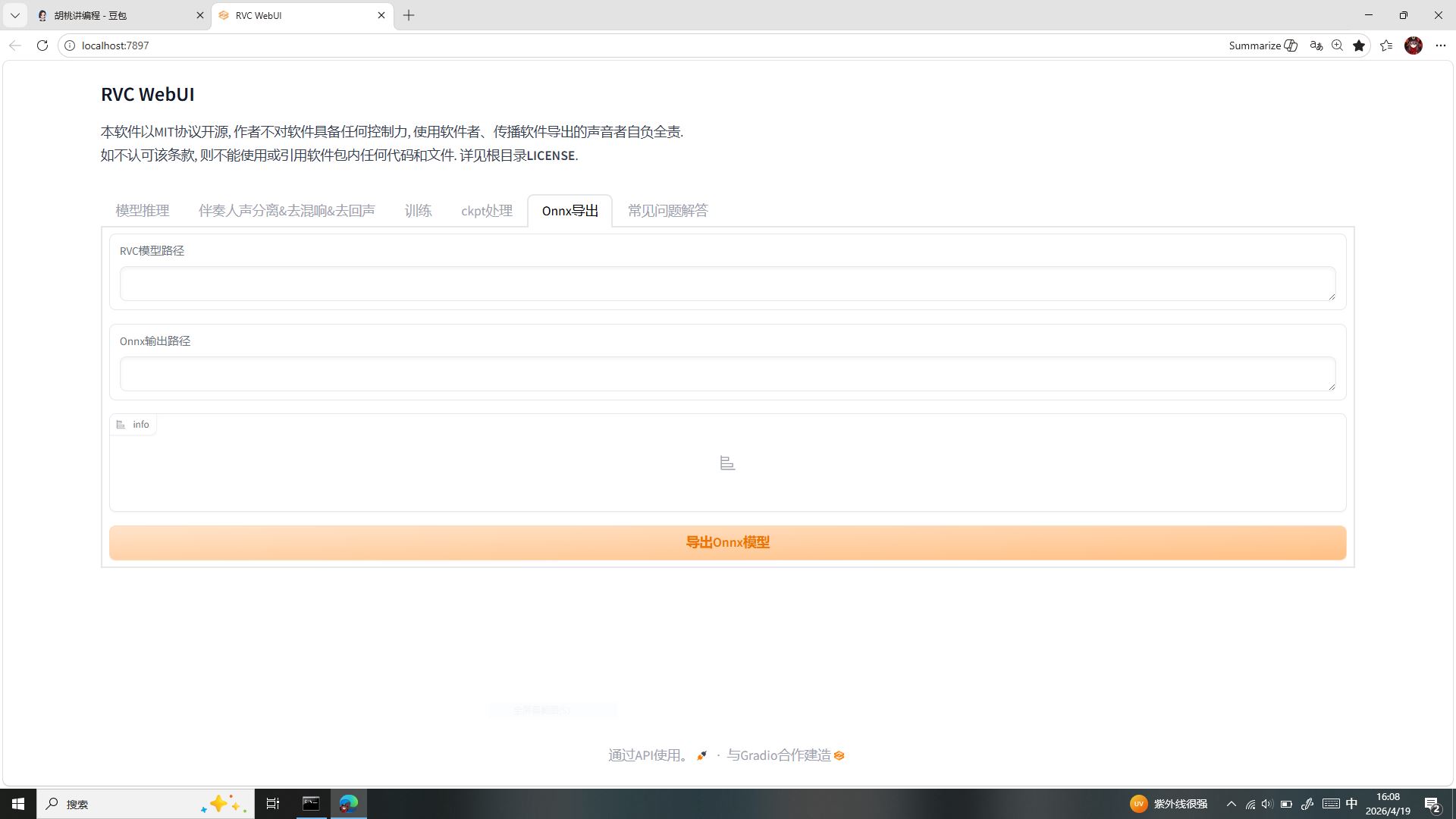
五、标签五:Onnx 导出
功能原理
将 RVC 专用.pth模型格式,导出为通用Onnx跨平台格式。用途:API 接口调用、第三方软件插件适配、多设备部署运行。
为什么普通玩家不用碰?
我们全程为本地网页端单机使用,无需跨软件、跨平台部署,格式转换毫无意义,仅开发者使用。
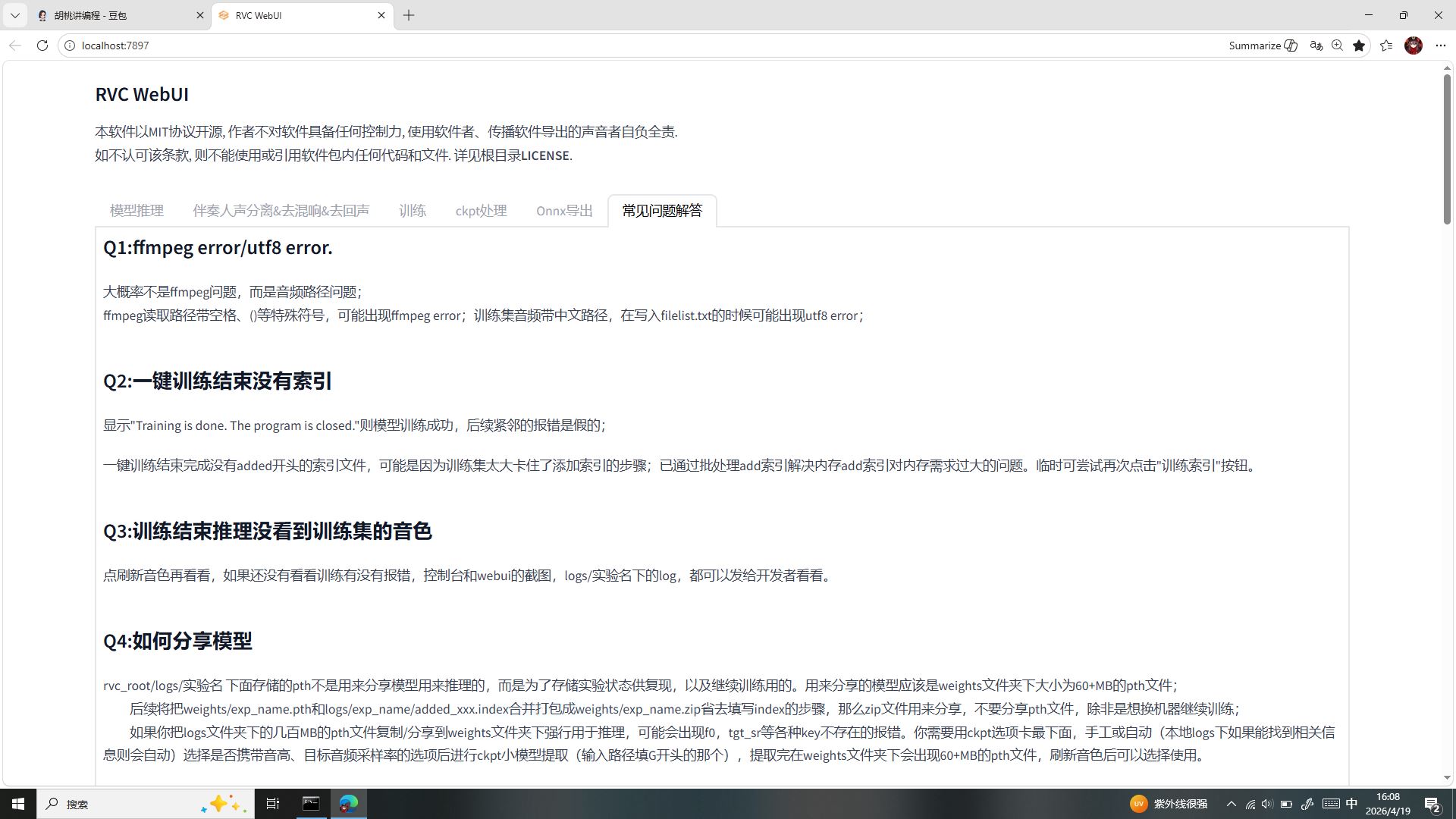
六、标签六:常见问题解答(内置报错兜底专区)
逐条拆解报错根本原因 + 解决原理,对应往期所有踩坑知识点:
- Q1:ffmpeg error / utf8 error原因:音频路径、软件解压路径包含中文、空格、特殊符号;原理:ffmpeg 音频库无法识别非英文路径,直接报错;对应我们全程强调的解压路径全英文铁律。
- Q2:一键训练结束没有索引文件原因:训练数据集过大,内存占用过高,软件自动跳过索引生成步骤;解决原理:重新点击训练索引按钮,补全缺失的音色特征库。
- Q3:训练结束推理界面看不到新音色原因:软件未自动扫描新模型;解决原理:回到模型推理界面,点击刷新音色列表和索引路径即可加载。
- Q4:模型正确分享方式(重中之重)原因:
logs文件夹内几百 MB 文件是训练缓存文件,强行使用会报音色缺失错误;正确规则:仅分享weights内精简.pth模型 +logs内对应.index索引文件打包分享,禁止分享训练大包文件。
全篇懒人速记口诀
日常翻唱只盯推理页,参数原理全记牢;破音电音调保护包络,降变调加滤波;内置分离基本闲置,训练导出全高阶;路径全程不能有中文,报错优先翻答疑。
至此 RVC 全界面所有功能、底层原理、调参逻辑、破音优化全部讲解完毕。下一期终极主线实操:加载洛天依专属模型,导入《灯火里的中国》纯净人声干声,套用本节课全部固定最优参数,一键生成完整无杂音、声线自然的洛天依 AI 翻唱成品!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)