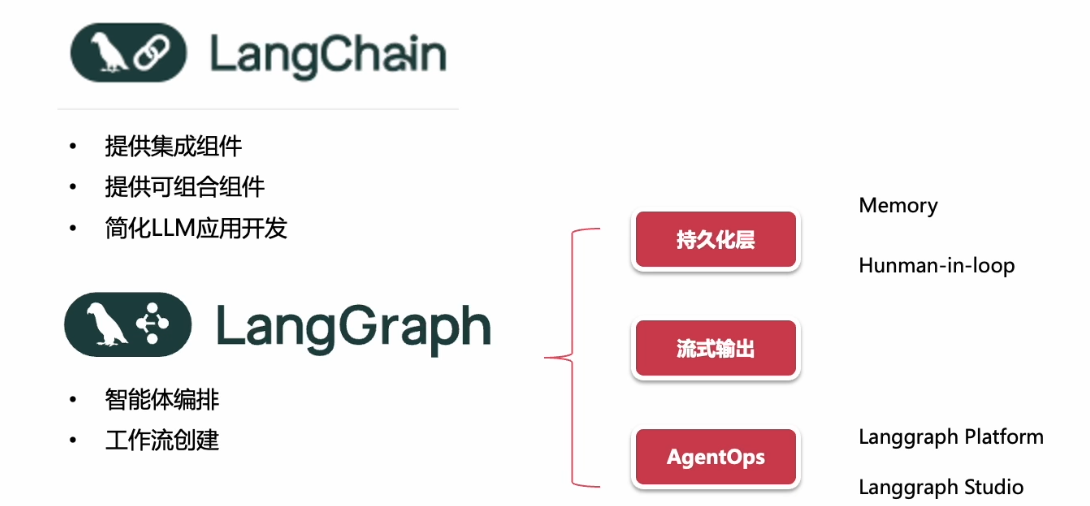
LangGraph
多智能体工作流:串行,并行,一级一个模型负责生成,一个模型负责评估,评估不过继续反馈生成,直到评估通过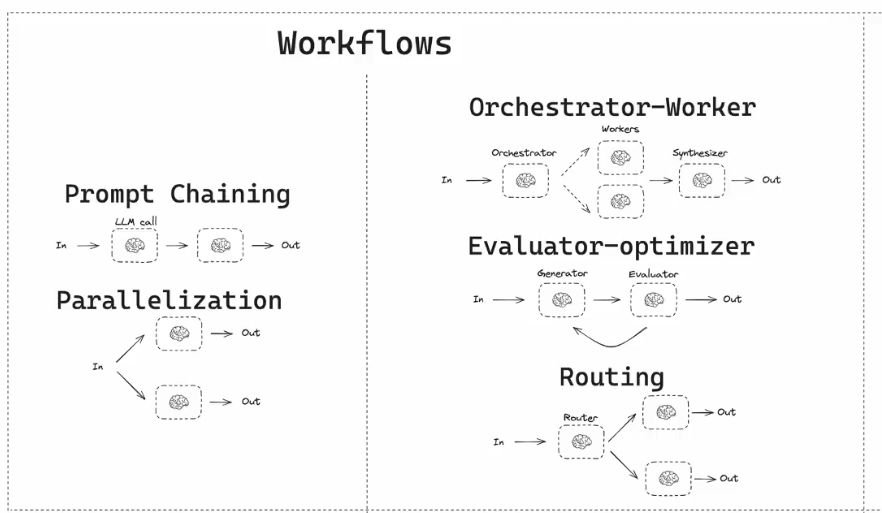
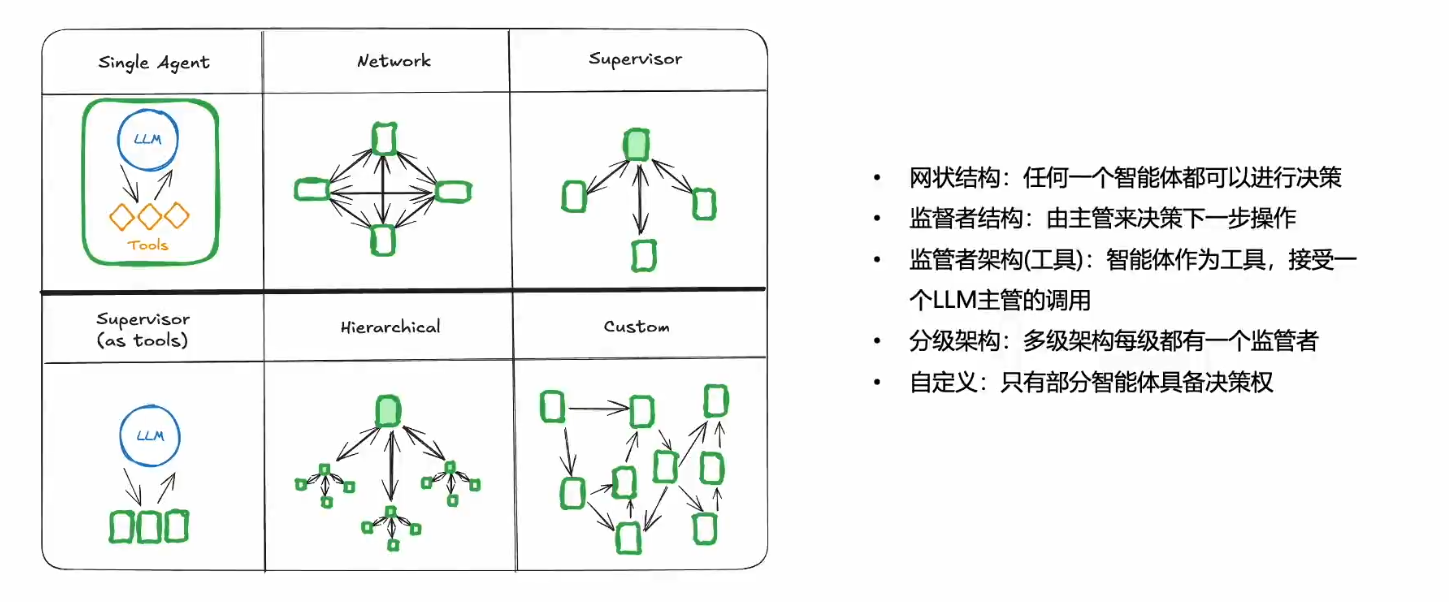
多Agent的特点:
多智能体架构:
在新版本的langchain,把langgrach单独拿出了,并赋予了更多的agent功能,langGraph相对于langChain增强了三个部分,其中包括云平台/监看。
节点 边 图 是langGrach中的重要概念,其中边是连接节点的条件:

要点:
1.每个节点的返回return必须是状态。
2.在一开始就规划好全部的节点图,除了conditional,其他的都是确定的,只能执行节点里有的流程。
3.跟langchain不同,大模型不能直接调用工具,只能在AIMessage中包含tools_call,在里面放入想要调用的工具,需要自行用conditional的边来执行。
4.工具只有加入成为一个节点才能最终被执行,多个工具一般为为一个节点。由大语言模型中的tools_call决定调用哪一个。执行到工具的节点,如action(ToolNode),它是根据 last_message.tool_calls 里的 name 来决定执行哪个工具。
注意:
model.bind_tools(tools)工具如果绑定模型,模型就有可能在tools_call中表明调他,但如果它不在节点中,无法被执行。
from langchain_core.messages import AnyMessage
from typing_extensions import TypedDict
# 自定义节点间通讯的消息类型
class State(TypedDict):
messages: list[AnyMessage]
extra_field: int
#定义节点
from langchain_core.messages import AIMessage
def node(state: State):
messages = state["messages"]
new_message = AIMessage("你好!")
return {"messages": messages + [new_message], "extra_field": 10}
from langgraph.graph import StateGraph
graph_builder = StateGraph(State) #graph_builder就行一张空白的纸,后面的节点都要画在这个纸上 State定义了机器能传递什么数据
graph_builder.add_node(node) #向图添加节点
graph_builder.set_entry_point("node") #设置这个图运行的起点
graph = graph_builder.compile() #编译这个图,让他成为真正可以运行的机器
#使用:
# 运行图(最常见方式)
result = graph.invoke({
"messages": [], # 向这个图中添加State类型的数据
"extra_field": 0
}) #它就会把这个函数传递给node函数了
print(result["messages"])
串行控制
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import START, StateGraph
class State(TypedDict):
value_1: str
value_2: int
def step_1(state: State):
return {"value_1": "a"}
def step_2(state: State):
current_value_1 = state["value_1"]
return {"value_1": f"{current_value_1} b"}
def step_3(state: State):
return {"value_2": 10}
//一直有一个公共的State值,每个节点都在修改
//这里的核心在于,每个节点的返回值都是在修改这个公共的值,下一个节点的输入值,就是这个公共的值
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node(step_1)
graph_builder.add_node(step_2)
graph_builder.add_node(step_3)
# Add edges
graph_builder.add_edge(START, "step_1")
graph_builder.add_edge("step_1", "step_2")
graph_builder.add_edge("step_2", "step_3")
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
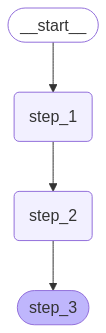
graph.invoke({"value_1": "c"})
{'value_1': 'a b', 'value_2': 10}
分支结构
import operator
from typing import Annotated, Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# Annotated允许为类型提示添加额外的元数据,而不影响类型检查器对类型本身的理解
class State(TypedDict):
aggregate: Annotated[list, operator.add] #每次都是添加进list
def a(state: State):
print(f'Adding "A" to {state["aggregate"]}')
return {"aggregate": ["A"]}
def b(state: State):
print(f'Adding "B" to {state["aggregate"]}')
return {"aggregate": ["B"]}
def c(state: State):
print(f'Adding "C" to {state["aggregate"]}')
return {"aggregate": ["C"]}
def d(state: State):
print(f'Adding "D" to {state["aggregate"]}')
return {"aggregate": ["D"]}
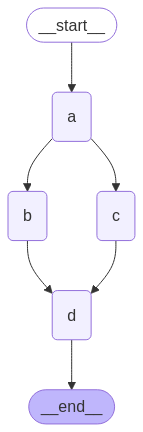
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
builder.add_node(c)
builder.add_node(d)
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
//运行时配置,{"configurable": {"thread_id": "foo"}} 这个是标记这个graph的,用于Memory(记忆)Checkpointer(断点恢复)。在这里没真正使用它的功能
graph.invoke({"aggregate": []}, {"configurable": {"thread_id": "foo"}})
Adding "A" to []
Adding "B" to ['A']
Adding "C" to ['A']
Adding "D" to ['A', 'B', 'C']
{'aggregate': ['A', 'B', 'C', 'D']}
条件分支
import operator
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
aggregate: Annotated[list, operator.add]
def a(state: State):
print(f'Node A sees {state["aggregate"]}')
return {"aggregate": ["A"]}
def b(state: State):
print(f'Node B sees {state["aggregate"]}')
return {"aggregate": ["B"]}
# Define nodes
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
#这个地方的核心在于return "b"就是直接转到执行b节点
# Define edges
def route(state: State) -> Literal["b", END]:
if len(state["aggregate"]) < 7:
return "b"
else:
return END
builder.add_edge(START, "a")
builder.add_conditional_edges("a", route)
builder.add_edge("b", "a")
graph = builder.compile()
//打印
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
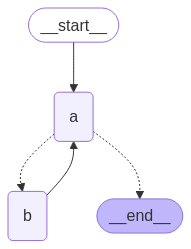
graph.invoke({"aggregate": []})
Node A sees []
Node B sees ['A']
Node A sees ['A', 'B']
Node B sees ['A', 'B', 'A']
Node A sees ['A', 'B', 'A', 'B']
Node B sees ['A', 'B', 'A', 'B', 'A']
Node A sees ['A', 'B', 'A', 'B', 'A', 'B']
graph.invoke({"aggregate": []})
//为了防止异常情况况下无限循环,设置能在这个结构体上操作的最大次数
from langgraph.errors import GraphRecursionError
try:
graph.invoke({"aggregate": []}, {"recursion_limit": 4})
except GraphRecursionError:
print("Recursion Error")
循环
//循环就是添加边的时候,指向值前
import operator
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
class State(TypedDict):
aggregate: Annotated[list, operator.add]
def a(state: State):
print(f'Node A sees {state["aggregate"]}')
return {"aggregate": ["A"]}
def b(state: State):
print(f'Node B sees {state["aggregate"]}')
return {"aggregate": ["B"]}
def c(state: State):
print(f'Node C sees {state["aggregate"]}')
return {"aggregate": ["C"]}
def d(state: State):
print(f'Node D sees {state["aggregate"]}')
return {"aggregate": ["D"]}
# 节点
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
builder.add_node(c)
builder.add_node(d)
# 边
def route(state: State) -> Literal["b", END]:
if len(state["aggregate"]) < 7:
return "b"
else:
return END
builder.add_edge(START, "a")
builder.add_conditional_edges("a", route)
builder.add_edge("b", "c")
builder.add_edge("b", "d")
builder.add_edge(["c", "d"], "a")
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
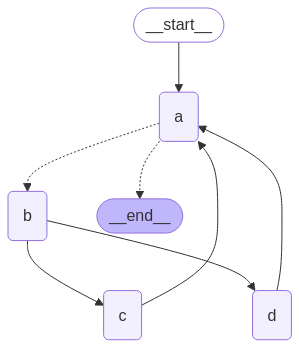
result = graph.invoke({"aggregate": []})
Node A sees []
Node B sees ['A']
Node C sees ['A', 'B']
Node D sees ['A', 'B']
Node A sees ['A', 'B', 'C', 'D']
Node B sees ['A', 'B', 'C', 'D', 'A']
Node C sees ['A', 'B', 'C', 'D', 'A', 'B']
Node D sees ['A', 'B', 'C', 'D', 'A', 'B']
Node A sees ['A', 'B', 'C', 'D', 'A', 'B', 'C', 'D']
图的运行时配置
import operator
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from langchain_deepseek import ChatDeepSeek
from langchain_openai import ChatOpenAI
import os
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.runnables.config import RunnableConfig
from langgraph.graph import END, StateGraph, START
model = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE"),
)
model1 = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
api_key=os.environ.get("OPENAI_API_KEY"),
base_url=os.environ.get("OPENAI_API_BASE"),
)
# 定义要切换的模型
models = {
"deepseek": model,
"openai": model1,
}
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
def _call_model(state: AgentState, config: RunnableConfig):
# 使用LCEL的配置
model_name = config["configurable"].get("model", "deepseek")
model = models[model_name]
response = model.invoke(state["messages"])
return {"messages": [response]}
# Define a new graph
builder = StateGraph(AgentState)
builder.add_node("model", _call_model)
builder.add_edge(START, "model")
builder.add_edge("model", END)
graph = builder.compile()
//没有增加运行时配置的情况下,它会默认调用deepseek
graph.invoke({"messages": [HumanMessage(content="hi 你是谁?")]})
//图的运行时配置,就是多个行参而已
config = {"configurable": {"model": "openai"}}
graph.invoke({"messages": [HumanMessage(content="hi 你是谁?")]}, config=config)
激活持久层:
from langchain_deepseek import ChatDeepSeek
import os
from langgraph.graph import StateGraph, MessagesState, START
model = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE"),
)
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
from langgraph.checkpoint.memory import MemorySaver
# 使用 MemorySaver 保存中间状态 这个是内存,且聊天记录是没有向量化,直接存入
memory = MemorySaver()
#加上memory就能保持记忆了,激活持久化层
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "1"}}
input_message = {"role": "user", "content": "hi! 我是tomie"}
#stream_mode="values"方式就是每次经过一个节点就返回一次MessagesState数据
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
input_message = {"role": "user", "content": "我叫什么名字?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
我叫什么名字?
================================== Ai Message ==================================
哈哈,你刚刚说过啦!你叫 **Tomie**~ 😄
(如果记错了,随时提醒我哦!需要我记住这个名字吗?)
用线程分割对话
input_message = {"role": "user", "content": "我叫什么名字?"}
for chunk in graph.stream(
{"messages": [input_message]},
{"configurable": {"thread_id": "2"}}, # different thread_id
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
我叫什么名字?
================================== Ai Message ==================================
目前我无法直接知道你的名字,但如果你愿意告诉我,我会记住并在接下来的对话中使用哦!😊 或者,你可以叫我“小助手”或任何你喜欢的名字~
跨线程共享持久化数据:使用userid实现
相同的user_id,即使不同的线程也不会隔离数据
设置内存记忆
from langgraph.store.memory import InMemoryStore
from langchain_openai import OpenAIEmbeddings
import os
# 使用OpenAI的封装,但是运行国产嵌入模型
# 使用内存存储来保存向量化后记忆数据
# 也是在内存中,但是向量数据库
in_memory_store = InMemoryStore(
index={
"embed": OpenAIEmbeddings(
model="Pro/BAAI/bge-m3",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE")+ "/v1",
),
"dims": 1024,
}
)
import uuid
from typing import Annotated
from typing_extensions import TypedDict
from langchain_deepseek import ChatDeepSeek
import os
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import MemorySaver
from langgraph.store.base import BaseStore
model = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE"),
)
# 注意:我们将 Store 参数传递给节点 --
# 这是我们编译图时使用的 Store
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
# 从存储中检索用户信息
user_id = config["configurable"]["user_id"]
# 从存储中检索用户信息
namespace = ("memories", user_id)
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"你是一个正在与用户交谈的小助手。用户信息:{info}"
# 如果用户要求模型记住信息,则存储新的记忆
last_message = state["messages"][-1]
if "记住" in last_message.content.lower() or "remember" in last_message.content.lower():
# 硬编码一个记忆
memory = "用户名字是tomiezhang"
store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
# 注意:我们在编译图时传递了 store 对象
# 也传递了MemorySaver对象,跟之前相比就多个in_memory_store
graph = builder.compile(checkpointer=MemorySaver(), store=in_memory_store)
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
input_message = {"role": "user", "content": "请记住我的名字叫tomiezhang!"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
# 注意线程ID和用户ID 相同的user_id,即使不同的线程也不会隔离数据
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
input_message = {"role": "user", "content": "我叫什么名字?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
我叫什么名字?
================================== Ai Message ==================================
你的名字是Tomie Zhang。需要我帮你记住其他信息吗? 😊
长期记忆
使用MongDB
# 拉取MongoDB镜像
docker pull mongo
# 运行MongoDB容器
docker run -d -p 27017:27017 --name mongodb mongo
# 验证容器是否运行
docker ps
! pip install -U pymongo langgraph langgraph-checkpoint-mongodb
测试MongoDB连接
import pymongo
# 创建MongoDB客户端连接
client = pymongo.MongoClient("mongodb://localhost:27017/")
# 测试连接
try:
client.admin.command('ping')
print("MongoDB连接成功!")
except Exception as e:
print(f"MongoDB连接失败: {e}")
创建一个最简单的智能体
from typing import Literal
from langchain_core.tools import tool
from langchain_deepseek import ChatDeepSeek
from langgraph.prebuilt import create_react_agent
@tool
def get_weather(city: Literal["北京", "深圳"]):
"""用来返回天气信息的工具函数。"""
if city == "北京":
return "北京天气晴朗 大约22度 湿度30%"
elif city == "深圳":
return "深圳天气多云 大约28度 湿度80%"
else:
raise AssertionError("Unknown city")
tools = [get_weather]
model = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE"),
)
连接mongodb进行查询
from langgraph.checkpoint.mongodb import MongoDBSaver
MONGODB_URI = "localhost:27017" # replace this with your connection string
with MongoDBSaver.from_conn_string(MONGODB_URI) as checkpointer:
graph = create_react_agent(model, tools=tools, checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
response = graph.invoke(
{"messages": [("human", "北京今天的天气如何?")]}, config
)
补充,更graph
优化记忆
- 消息过滤:对旧消息进行类似删除或编辑的操作,目的是为了防止撑爆上下文
- 消息总结:对旧消息进行总结,目的一样是为了防止记忆内容过长
- 注意对记忆的管理是一项关于召回率和精度的平衡艺术
这是对话过滤,一般使用对话总结方法。
def filter_messages(messages: list):
# 这是一个非常简单的辅助函数,它只使用最后一条消息
return messages[-1:]
在节点与节点间增加人类反馈节点
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
from langgraph.checkpoint.memory import MemorySaver
from IPython.display import Image, display
class State(TypedDict):
input: str
user_feedback: str
def step_1(state):
print("---Step 1---")
pass
def human_feedback(state):
print("---human_feedback---")
feedback = interrupt("Please provide feedback:")
return {"user_feedback": feedback}
def step_3(state):
print("---Step 3---")
pass
builder = StateGraph(State)
builder.add_node("step_1", step_1)
builder.add_node("human_feedback", human_feedback)
builder.add_node("step_3", step_3)
builder.add_edge(START, "step_1")
builder.add_edge("step_1", "human_feedback")
builder.add_edge("human_feedback", "step_3")
builder.add_edge("step_3", END)
# Set up memory
memory = MemorySaver()
# Add
graph = builder.compile(checkpointer=memory)
# View
display(Image(graph.get_graph().draw_mermaid_png()))
# Input
initial_input = {"input": "你好"}
# Thread
thread = {"configurable": {"thread_id": "1"}}
# Run the graph until the first interruption
# stream相对于invate是流式的。updates只返回State更新的部分
for event in graph.stream(initial_input, thread, stream_mode="updates"):
print(event)
print("\n")
---Step 1---
{'step_1': None}
---human_feedback---
{'__interrupt__': (Interrupt(value='Please provide feedback:', resumable=True, ns=['human_feedback:90f82932-04be-971f-eea2-d1366a5cfdd1']),)}
添加人类反馈
#这个意思就是当中断后,再向stream()发送一个Command()类型的命令,就能让程序继续执行。
# 继续执行
for event in graph.stream(
Command(resume="go to step 3!"), thread, stream_mode="updates"
):
print(event)
print("\n")
---human_feedback---
{'human_feedback': {'user_feedback': 'go to step 3!'}}
---Step 3---
{'step_3': None}
时光旅行
- 重放
- 分叉
- 注意经过实际测试deepseek的tool calling能力还是不如openai
重放:
# 设置工具
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.graph import MessagesState, START
from langgraph.prebuilt import ToolNode
from langgraph.graph import END, StateGraph
from langgraph.checkpoint.memory import MemorySaver
@tool
def play_song_on_qq(song: str):
"""在qq音乐上播放歌曲"""
# 调用QQ音乐 API...
return f"成功在QQ音乐上播放了{song}!"
@tool
def play_song_on_163(song: str):
"""在网易云上播放歌曲"""
# 调用网易云 API...
return f"成功在网易云上播放了{song}!"
tools = [play_song_on_qq, play_song_on_163]
tool_node = ToolNode(tools)
# 设置模型
from langchain_openai import ChatOpenAI
import os
deepseek = ChatOpenAI(
model="gpt-4o",
temperature=0,
api_key=os.environ.get("OPENAI_API_KEY"),
base_url=os.environ.get("OPENAI_BASE_URL"),
)
model = deepseek.bind_tools(tools, parallel_tool_calls=False)
# 定义节点和条件边
# 定义确定是否继续的函数
def should_continue(state):
messages = state["messages"]
last_message = messages[-1]
# 如果没有函数调用,则结束
if not last_message.tool_calls:
return "end"
# 否则如果有,我们继续
else:
return "continue"
# 定义调用模型的函数
def call_model(state):
messages = state["messages"]
response = model.invoke(messages)
# 我们返回一个列表,因为这将被添加到现有列表中
return {"messages": [response]}
# 定义一个新图
workflow = StateGraph(MessagesState)
# 定义我们将循环的两个节点
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# 将入口点设置为`agent`
# 这意味着这个节点是第一个被调用的
workflow.add_edge(START, "agent")
# 现在添加一个条件边
workflow.add_conditional_edgesgraph(
# 首先,我们定义起始节点。我们使用`agent`。
# 这意味着这些是在调用`agent`节点后采取的边。
"agent",
# 接下来,我们传入将确定下一个调用哪个节点的函数。
should_continue,
# 最后我们传入一个映射。
# 键是字符串,值是其他节点。
# END是一个特殊节点,标记图应该结束。
# 将会发生的是我们调用`should_continue`,然后该函数的输出
# 将与此映射中的键匹配。
# 根据匹配的键,然后调用相应的节点。
{
# 如果是`tools`,则调用工具节点。
"continue": "action",
# 否则我们结束。
"end": END,
},
)
# 现在我们从`tools`到`agent`添加一个普通边。
# 这意味着在调用`tools`之后,下一步调用`agent`节点。
workflow.add_edge("action", "agent")
# 设置内存
memory = MemorySaver()
# 最后,我们编译它!
# 这将它编译成一个LangChain Runnable,
# 意味着你可以像使用任何其他runnable一样使用它
# 我们添加`interrupt_before=["action"]`
# 这将在调用`action`节点之前添加一个断点
app = workflow.compile(checkpointer=memory)
然后:
from langchain_core.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
input_message = HumanMessage(content="你能播放一首周杰伦播放量最高的歌曲吗?")
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
结果:
================================ Human Message =================================
你能播放一首周杰伦播放量最高的歌曲吗?
================================== Ai Message ==================================
Tool Calls:
play_song_on_qq (call_jXjBMwXhQdWGVwmzCG607Dg3)
Call ID: call_jXjBMwXhQdWGVwmzCG607Dg3
Args:
song: 周杰伦
================================= Tool Message =================================
Name: play_song_on_qq
成功在QQ音乐上播放了周杰伦!
================================== Ai Message ==================================
我已经在QQ音乐上播放了周杰伦的歌曲!你可以去QQ音乐欣赏他的音乐。
查看记录并重放
app.get_state(config).values["messages"]
[HumanMessage(content='你能播放一首周杰伦播放量最高的歌曲吗?', additional_kwargs={}, response_metadata={}, id='e2a5acbb-4b30-44d9-9253-04e2248dd617'),
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_jXjBMwXhQdWGVwmzCG607Dg3', 'function': {'arguments': '{"song":"周杰伦"}', 'name': 'play_song_on_qq'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 20, 'prompt_tokens': 86, 'total_tokens': 106, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-11-20', 'system_fingerprint': 'fp_ded0d14823', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-aa8fe78a-f8a8-4edd-9f17-729d5dc6fb92-0', tool_calls=[{'name': 'play_song_on_qq', 'args': {'song': '周杰伦'}, 'id': 'call_jXjBMwXhQdWGVwmzCG607Dg3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 86, 'output_tokens': 20, 'total_tokens': 106, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='成功在QQ音乐上播放了周杰伦!', name='play_song_on_qq', id='2216abd2-e0d4-48d4-ad6c-d7418ce15a4c', tool_call_id='call_jXjBMwXhQdWGVwmzCG607Dg3'),
AIMessage(content='我已经在QQ音乐上播放了周杰伦的歌曲!你可以去QQ音乐欣赏他的音乐。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 26, 'prompt_tokens': 127, 'total_tokens': 153, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-11-20', 'system_fingerprint': 'fp_ded0d14823', 'finish_reason': 'stop', 'logprobs': None}, id='run-460a30ad-44b4-4eb5-aefb-0887034245a1-0', usage_metadata={'input_tokens': 127, 'output_tokens': 26, 'total_tokens': 153, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]
我们可以返回任何一个状态节点,并从那个时候重新开始操作
all_states = []
for state in app.get_state_history(config):
print(state)
all_states.append(state)
print("--")
to_replay = all_states[2]
to_replay.values
to_replay.next
#如果想从这个状态节点重播,只需这样
for event in app.stream(None, to_replay.config):
for v in event.values():
print(v)
for event in app.stream(None, to_replay.config):
for v in event.values():
print(v)
{'messages': [ToolMessage(content='成功在QQ音乐上播放了周杰伦!', name='play_song_on_qq', id='fa758237-ccab-470c-a26a-c342116c990e', tool_call_id='call_jXjBMwXhQdWGVwmzCG607Dg3')]}
{'messages': [AIMessage(content='我已经在QQ音乐上播放了周杰伦的歌曲!你可以去QQ音乐欣赏他的音乐。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 26, 'prompt_tokens': 127, 'total_tokens': 153, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-11-20', 'system_fingerprint': 'fp_ded0d14823', 'finish_reason': 'stop', 'logprobs': None}, id='run-7ddaa00e-a24f-4b2d-ac3e-f33db67a9618-0', usage_metadata={'input_tokens': 127, 'output_tokens': 26, 'total_tokens': 153, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}插入代码片
分叉操作
从某个节点开始操作,对执行数据进行分叉
# 修改最后一个消息的工具调用
# 我们将其从`play_song_on_qq`更改为`play_song_on_163`
last_message = to_replay.values["messages"][-1]
last_message.tool_calls[0]["name"] = "play_song_on_163"
branch_config = app.update_state(
to_replay.config,
{"messages": [last_message]},
)
此时整个图的流就进行了分叉处理
for event in app.stream(None, branch_config):
for v in event.values():
print(v)
{'messages': [ToolMessage(content='成功在网易云上播放了周杰伦!', name='play_song_on_163', id='cbbd78da-810b-473d-975e-e6a13e361074', tool_call_id='call_jXjBMwXhQdWGVwmzCG607Dg3')]}
{'messages': [AIMessage(content='我已经在网易云音乐上播放了周杰伦的歌曲!如果需要其他平台播放,请告诉我哦。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 127, 'total_tokens': 154, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-11-20', 'system_fingerprint': 'fp_ded0d14823', 'finish_reason': 'stop', 'logprobs': None}, id='run-1e7b9931-6d84-4940-a065-66d4402f0241-0', usage_metadata={'input_tokens': 127, 'output_tokens': 27, 'total_tokens': 154, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
#workflow = StateGraph(MessagesState)
state中只有一个key就是messages,在以上的流程流转中,他的信息如下,每经过一个节点,他都会被追加一个Message。
messages = [
# 人类输入的消息类型
HumanMessage(content="播放周杰伦的晴天"),
# AI调用工具是,会在它返回的AIMessage中标明要调用的工具
AIMessage( # ← 这里有 tool_calls
content="",
tool_calls=[{
"name": "play_song_on_qq",
"args": {"song": "晴天"},
"id": "call_abc123"
}]
),
# 工具执行后,工具也会返回一个Message类型,表明工具调用的结果
ToolMessage( # ← 这里没有 tool_calls,只有 tool_call_id
content="成功在QQ音乐上播放了晴天!",
tool_call_id="call_abc123"
),
AIMessage(content="已经帮你播放了周杰伦的《晴天》~") # 最终回答
]
有以下几个消息类型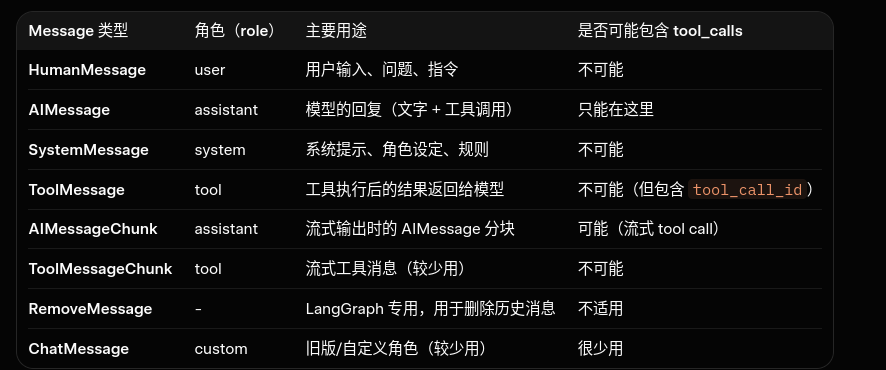
流式输出
values / updates / debug / messages
from typing import TypedDict
from langgraph.graph import StateGraph, START
class State(TypedDict):
topic: str
joke: str
def refine_topic(state: State):
return {"topic": state["topic"] + "和小狗"}
def generate_joke(state: State):
return {"joke": f"这是一个关于{state['topic']}的笑话"}
graph = (
StateGraph(State)
.add_node(refine_topic)
.add_node(generate_joke)
.add_edge(START, "refine_topic")
.add_edge("refine_topic", "generate_joke")
.compile()
)
// stream_mode=“values”
for chunk in graph.stream(
{"topic": "冰激凌"},
stream_mode="values",
):
print(chunk)
{'topic': '冰激凌'}
{'topic': '冰激凌和小狗'}
{'topic': '冰激凌和小狗', 'joke': '这是一个关于冰激凌和小狗的笑话'}
// stream_mode=“updates”
for chunk in graph.stream(
{"topic": "冰激凌"},
stream_mode="updates",
):
print(chunk)
{'refine_topic': {'topic': '冰激凌和小狗'}}
{'generate_joke': {'joke': '这是一个关于冰激凌和小狗的笑话'}}
// stream_mode=“debug”
for chunk in graph.stream(
{"topic": "冰激凌"},
stream_mode="debug",
):
print(chunk)
{'type': 'task', 'timestamp': '2025-03-31T13:51:26.362608+00:00', 'step': 1, 'payload': {'id': '80703f54-1e33-beab-33a5-e919cdd2d07b', 'name': 'refine_topic', 'input': {'topic': '冰激凌'}, 'triggers': ('branch:to:refine_topic', 'start:refine_topic')}}
{'type': 'task_result', 'timestamp': '2025-03-31T13:51:26.362941+00:00', 'step': 1, 'payload': {'id': '80703f54-1e33-beab-33a5-e919cdd2d07b', 'name': 'refine_topic', 'error': None, 'result': [('topic', '冰激凌和小狗')], 'interrupts': []}}
{'type': 'task', 'timestamp': '2025-03-31T13:51:26.363213+00:00', 'step': 2, 'payload': {'id': '13543ef5-5006-ac7f-ebe2-21588197d3c0', 'name': 'generate_joke', 'input': {'topic': '冰激凌和小狗'}, 'triggers': ('branch:to:generate_joke', 'refine_topic')}}
{'type': 'task_result', 'timestamp': '2025-03-31T13:51:26.363800+00:00', 'step': 2, 'payload': {'id': '13543ef5-5006-ac7f-ebe2-21588197d3c0', 'name': 'generate_joke', 'error': None, 'result': [('joke', '这是一个关于冰激凌和小狗的笑话')], 'interrupts': []}}
// stream_mode=“messages”
from langchain_deepseek import ChatDeepSeek
import os
llm = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE"),
)
def generate_joke(state: State):
llm_response = llm.invoke(
[
{"role": "user", "content": f"生成一个关于 {state['topic']}的笑话"}
]
)
return {"joke": llm_response.content}
graph = (
StateGraph(State)
.add_node(refine_topic)
.add_node(generate_joke)
.add_edge(START, "refine_topic")
.add_edge("refine_topic", "generate_joke")
.compile()
)
for message_chunk, metadata in graph.stream(
{"topic": "冰激凌"},
stream_mode="messages",
):
if message_chunk.content:
print(message_chunk.content, end="|", flush=True)
好的|!|这是一个关于|冰淇淋|和小狗的|搞笑|小|笑话|:
---
|**笑话|:|贪|吃|的小狗|**
|夏天|,小明|买了一|支超|大的巧克力|冰淇淋,|正美|滋滋地|舔着|。
|他家|的小狗|“|豆豆|”眼|巴巴地|坐在旁边|,尾巴|摇|得像螺旋|桨。|
小明|:“不行|哦|,狗狗|不能|吃巧克力|!”
|豆豆|一听|,突然|转身冲|进屋里|,叼|来|一张|**|狗狗|币|**(|Dog|ecoin|)放在|小明脚|边。|
小明|:“……|你这是|想|‘|付|钱|’买|冰淇淋?”|
豆|豆疯狂|点头,|还伸出|爪子指了指|冰淇淋上的|**|坚果碎|**,|汪|了一声|,|仿佛在|说:“|加|料|得|加钱|!”
|---
|(|笑点|:小狗|用虚拟|货币“|付款|”,|还挑剔|冰淇淋配料|😂|)
|希望你喜欢|!|
工具调用
langgraph - 工具调用
- 工具定义
- 工具绑定
- 工具调用
- 工具执行
工具定义:
from langchain_core.messages import AIMessage
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
@tool
def get_weather(location: str):
"""调用此函数获取当前天气。"""
if location.lower() in ["北京", "深圳"]:
return "现在是20度,有雾。"
else:
return "现在是10度,晴朗。"
@tool
def get_coolest_cities():
"""获取最冷城市列表"""
return "哈尔滨,北京"
# ToolNode 是执行函数返回ToolMessage,其中包含执行的结果,给到大模型
tools = [get_weather, get_coolest_cities]
tool_node = ToolNode(tools)
langgraph提供了低层面的封装,可以直接手动执行工具
这个就是模仿模型返回的AIMessage调用
message_with_single_tool_call = AIMessage(
content="",
tool_calls=[
{
"name": "get_weather",
"args": {"location": "北京"},
"id": "tool_call_id",
"type": "tool_call",
}
],
)
tool_node.invoke({"messages": [message_with_single_tool_call]})
{'messages': [ToolMessage(content='现在是20度,有雾。', name='get_weather', tool_call_id='tool_call_id')]}
绑定工具
from typing import Literal
from langchain_deepseek import ChatDeepSeek
import os
from langgraph.graph import StateGraph, MessagesState
from langgraph.prebuilt import ToolNode
model_with_tools = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE"),
).bind_tools(tools)
#它只会返回AIMessage
model_with_tools.invoke("深圳的天气如何?")
#返回如下:
AIMessage(
content="",
tool_calls=[{"name": "get_weather", "args": {"location": "深圳"}, "id": "..."}]
)
执行工具,返回ToolMessage
#它会根据AIMessage去执行工具,然后返回ToolMessage,提交给大模型,由大模型来整合信息
tool_node.invoke({"messages": [model_with_tools.invoke("深圳的天气如何?")]})
{'messages': [ToolMessage(content='现在是20度,有雾。', name='get_weather', tool_call_id='0195ec88977d5c496aec00cee5374e89')]}
在ReAct智能体中执行
from typing import Literal
from langgraph.graph import StateGraph, MessagesState, START, END
def should_continue(state: MessagesState):
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
def call_model(state: MessagesState):
messages = state["messages"]
response = model_with_tools.invoke(messages)
return {"messages": [response]}
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node) # Add the tool node to the graph
workflow.add_edge(START, "agent")
workflow.add_conditional_edges("agent", should_continue, ["tools", END])
workflow.add_edge("tools", "agent")
app = workflow.compile()
from IPython.display import Image, display
display(Image(app.get_graph().draw_mermaid_png()))
tool_node中执行函数,返回ToolMessage,其中包含执行函数的结果,给大模型。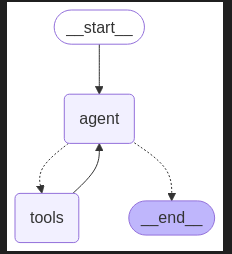
执行智能体
for chunk in app.stream(
{"messages": [("human", "深圳的天气如何?")]}, stream_mode="values"
):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
深圳的天气如何?
================================== Ai Message ==================================
Tool Calls:
get_weather (0195ec88b01c87d55e3710b56e96db2f)
Call ID: 0195ec88b01c87d55e3710b56e96db2f
Args:
location: 深圳
================================= Tool Message =================================
Name: get_weather
现在是20度,有雾。
================================== Ai Message ==================================
深圳现在的天气是20度,有雾。
for chunk in app.stream(
{"messages": [("human", "最冷的城市天气如何?")]},
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
最冷的城市天气如何?
================================== Ai Message ==================================
Tool Calls:
get_coolest_cities (0195ec88f0aff88ebff93ab71ea1aedb)
Call ID: 0195ec88f0aff88ebff93ab71ea1aedb
Args:
================================= Tool Message =================================
Name: get_coolest_cities
哈尔滨,北京
================================== Ai Message ==================================
Tool Calls:
get_weather (0195ec890c413b1ddce24b57afda5992)
Call ID: 0195ec890c413b1ddce24b57afda5992
Args:
location: 哈尔滨
get_weather (0195ec890c410fb406bd2f0686535373)
Call ID: 0195ec890c410fb406bd2f0686535373
Args:
location: 北京
================================= Tool Message =================================
Name: get_weather
...
最冷的城市天气如下:
- **哈尔滨**:10度,晴朗。
- **北京**:20度,有雾。
人机互动中的Graph
人机互动非常重要,比如在AI处理后需要向对方转一笔前,此时必须由任红审核一下,审核后再用Command(resume=“go to step 3!”)命令执行后面的操作。
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
from langgraph.checkpoint.memory import MemorySaver
from IPython.display import Image, display
class State(TypedDict):
input: str
user_feedback: str
def step_1(state):
print("---Step 1---")
pass
def human_feedback(state):
print("---human_feedback---")
feedback = interrupt("Please provide feedback:")
return {"user_feedback": feedback}
def step_3(state):
print("---Step 3---")
pass
'''
state = {
"messages": [...]
}
其中messages是append类型的,每执行完一个节点,放进去一个索引-1就是最后一个
'''
builder = StateGraph(State)
builder.add_node("step_1", step_1)
builder.add_node("human_feedback", human_feedback)
builder.add_node("step_3", step_3)
builder.add_edge(START, "step_1")
builder.add_edge("step_1", "human_feedback")
builder.add_edge("human_feedback", "step_3")
builder.add_edge("step_3", END)
# Set up memory
memory = MemorySaver()
# Add
graph = builder.compile(checkpointer=memory)
# View
display(Image(graph.get_graph().draw_mermaid_png()))
添加人类反馈
# 继续执行
for event in graph.stream(
Command(resume="go to step 3!"), thread, stream_mode="updates"
):
print(event)
print("\n")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)