Linux线程同步与互斥(一):互斥量与锁的理解
在多线程编程中,线程之间的协作和数据共享是常态,但也是问题的根源。问题:多个线程同时卖票,结果卖出了负数?或者某个线程“饿死”一直得不到执行?这些问题都源于资源共享 和执行顺序的不可控。
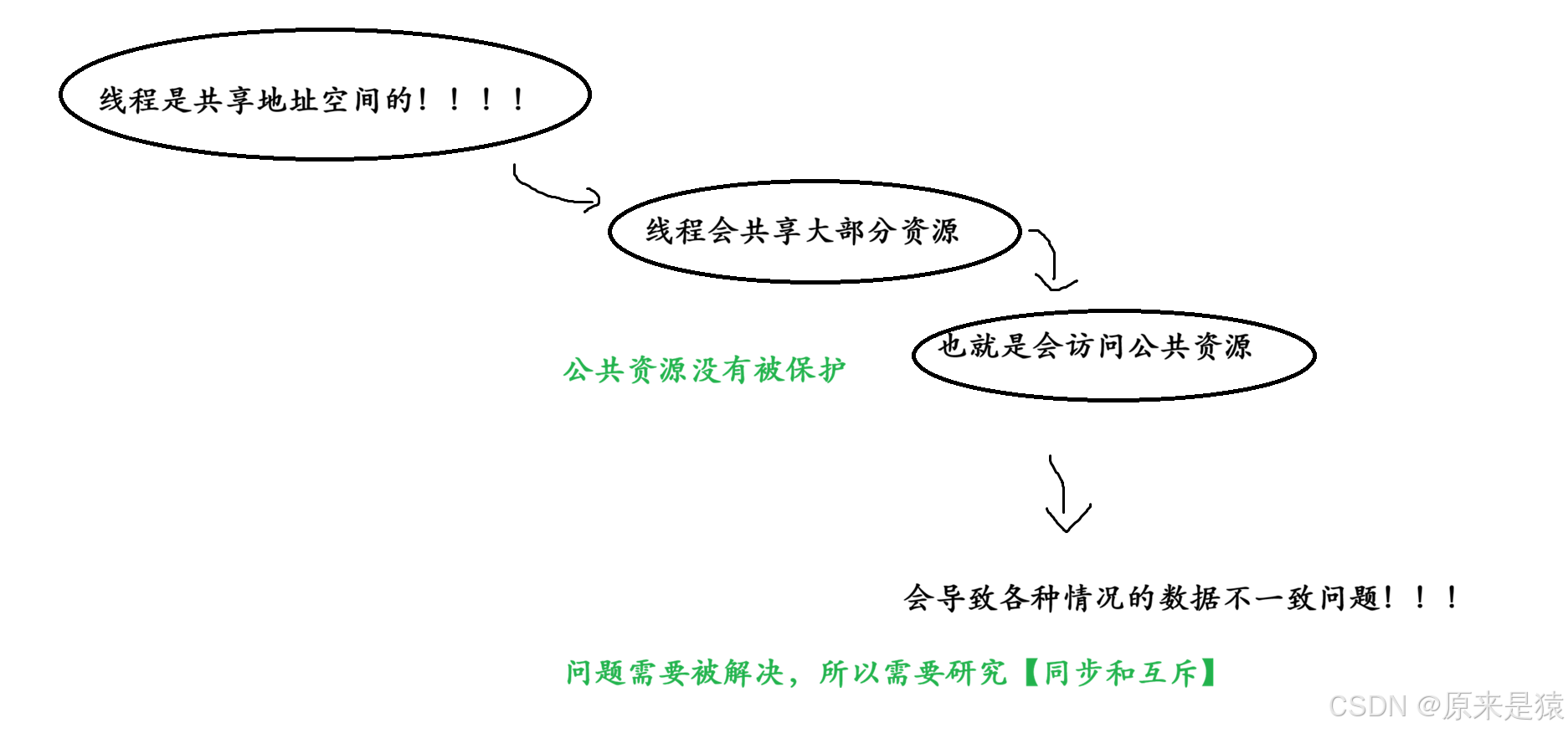
一、进程线程间互斥相关背景概念
临界资源(Critical Resource)
多个线程共享的资源(如全局变量、文件、设备等)称为临界资源。多个线程同时访问它可能会导致数据不一致。
被保护起来的共享资源 --> 临界资源
临界区(Critical Section)
访问临界资源的代码段称为临界区。为了保证数据安全,我们需要保证同一时刻只有一个线程进入临界区。
互斥(Mutex)
互斥是指:同一时刻,只允许一个线程进入临界区。互斥是对临界资源的保护机制。
原子性(Atomic)
一个操作如果不可被中断,要么完全执行,要么完全不执行,就称为原子操作。
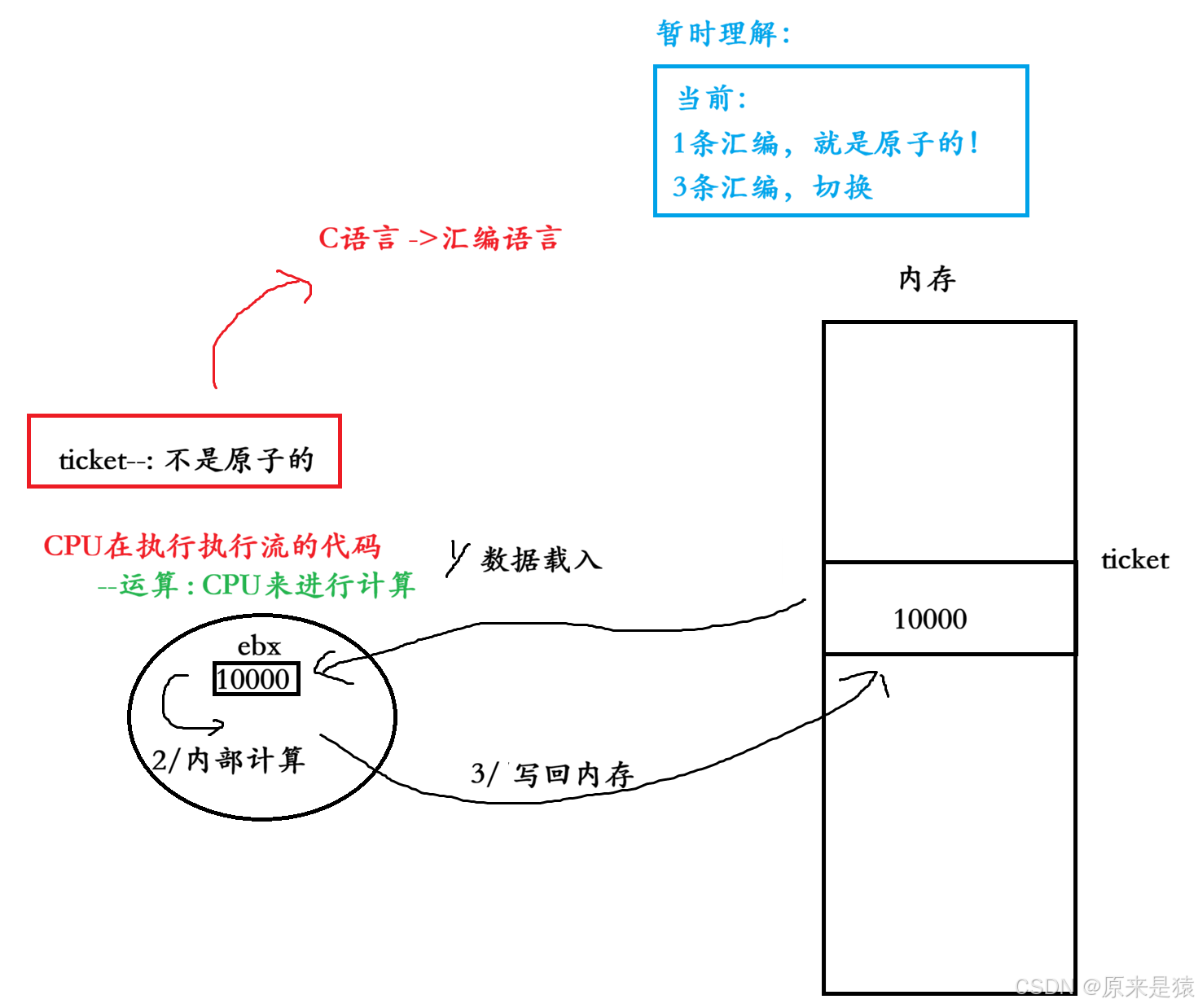
例如:ticket-- 在C语言中看起来是一条语句,但在CPU层面是多条指令,不是原子的。
二、互斥量mutex
- 大部分情况,线程使用的数据都是局部变量 , 变量的地址空间在线程栈空间内,这种情况 , 变量归属当个线程,其他线程无法获得这种变量
- 但有的时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互
- 多个线程并发的操作共享变量,会带来一些问题 。
2.1 现象/解决
无法获得争取结果的原因:
- if 语句判断条件为真以后 , 代码可以并发的切换到其他线程
- usleep 这个模拟漫长业务的过程,在这个漫长的业务过程中,可能会有很多线程进入该代码段
- --ticket操作本身就不是一个原子操作
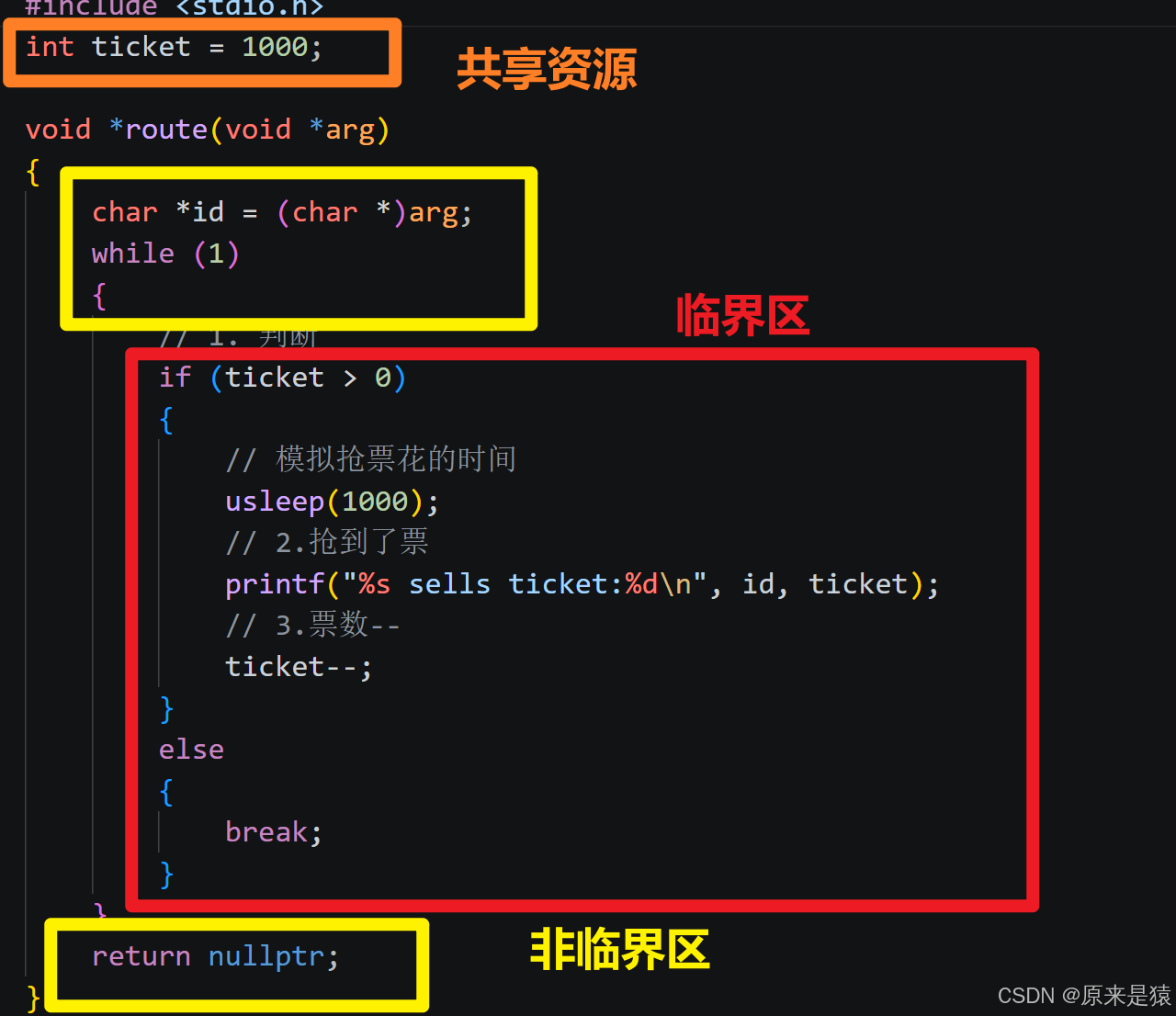
// 操作共享变量会有问题的售票系统代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
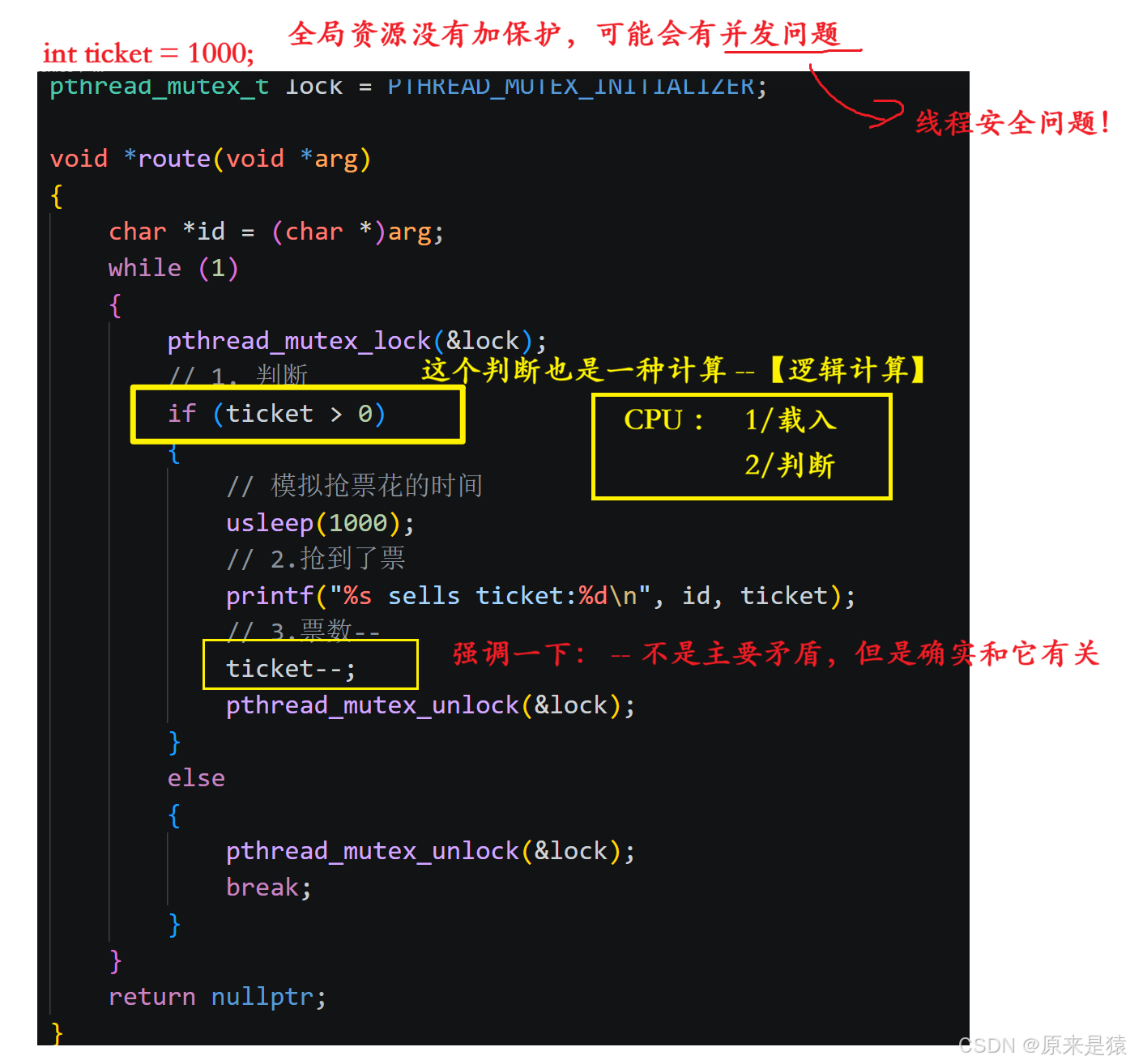
int ticket = 1000;
void *route(void *arg)
{
char *id = (char *)arg;
while (1)
{
// 1. 判断
if (ticket > 0)
{
// 模拟抢票花的时间
usleep(1000);
// 2.抢到了票
printf("%s sells ticket:%d\n", id, ticket);
// 3.票数--
ticket--;
}
else
{
break;
}
}
return nullptr;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (char *)"thread 1");
pthread_create(&t2, NULL, route, (char *)"thread 2");
pthread_create(&t3, NULL, route, (char *)"thread 3");
pthread_create(&t4, NULL, route, (char *)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
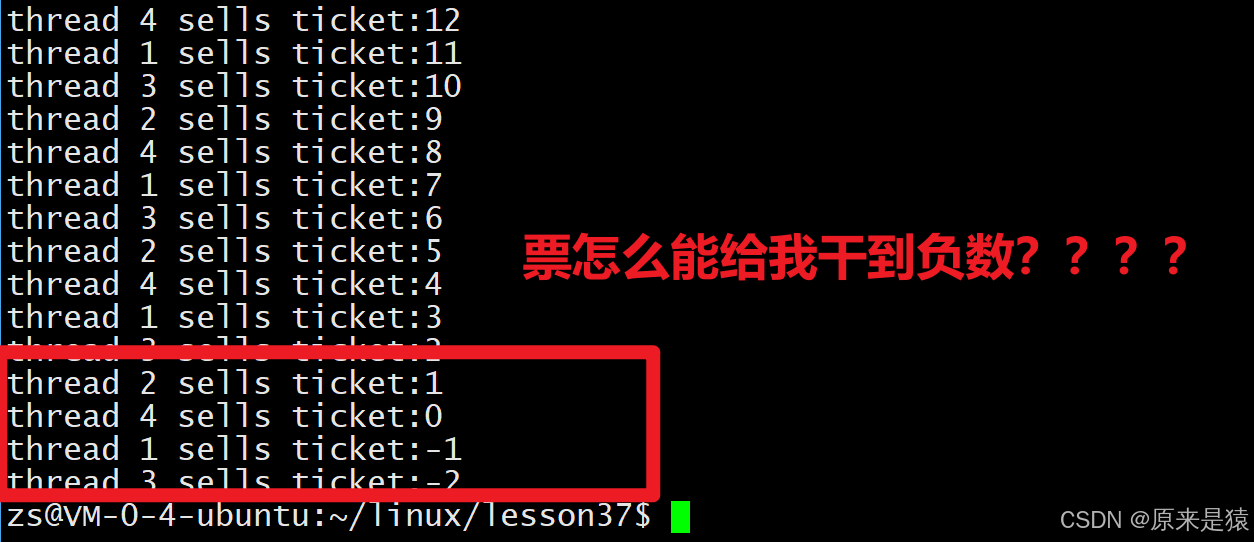
}
通过加锁来解决这个问题 :
#include <pthread.h>
// 1. 定义并初始化互斥锁
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
// 2. 加锁(阻塞直到获取锁)
int pthread_mutex_lock(pthread_mutex_t *mutex);
// 3. 解锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);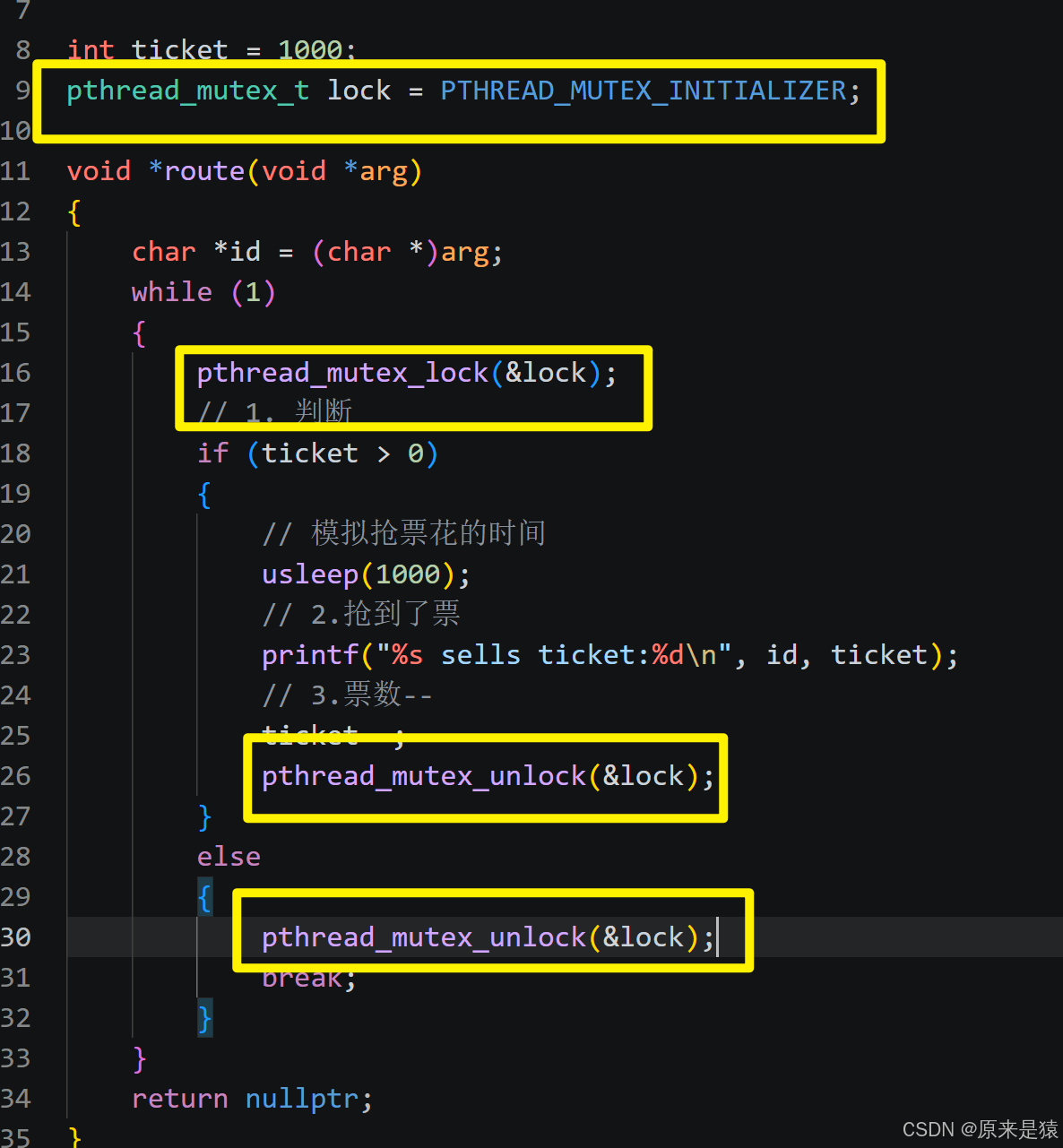
2.2 为什么会减到负数
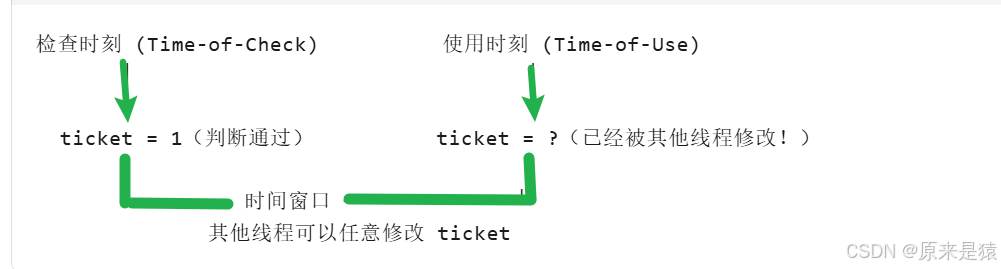
核心问题:不是
ticket--的问题,是if (ticket > 0)和ticket--之间的时间窗口
ticket -- : 不是原子
任意操作之后,线程会被切换 , 导致数据不一致的问题
2.2.1 票数为1时,场景介绍
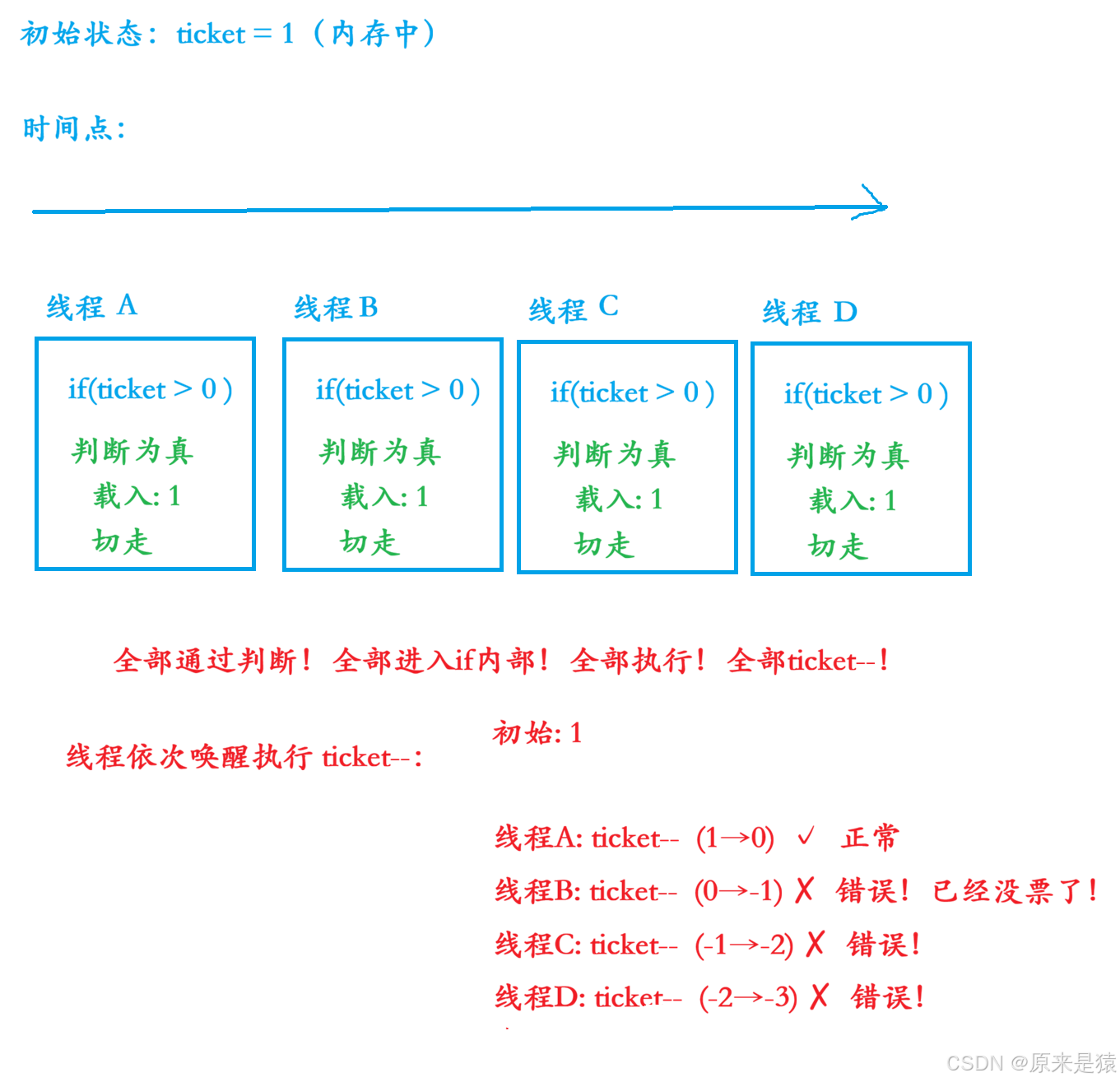
2.2.2 根本原因:判断和修改是两个独立的操作
if (ticket > 0) { // ←── 操作1:判断(只读,不修改内存)
// 中间可能有任意长时间的延迟,任意多次线程切换!
ticket--; // ←── 操作2:修改(此时判断结果可能已经失效)
}--操作并不是原子操作,而是对应三条汇编指令:
- load : 将共享变量 ticket 从内存加载到寄存器中
- upload : 更新寄存器里面的值,执行 -1 操作
- store : 将新值 ,从寄存器里写回共享变量 ticket 的内存地址
注意:CPU能够识别指令的长度
关键洞察:
-
if (ticket > 0)只是读取内存值,不会改变内存中的 ticket -
四个线程读取时,ticket 都是 1,所以四个都判断为真
-
等到它们依次执行
ticket--时,已经没有保护了

2.2.3汇编级别的拆解

更糟的情况:线程A在 if 判断后、ticket-- 前被切走,其他线程修改了 ticket,但A恢复后仍然执行减操作!
2.3 线程切换的关键时机
线程切换发生在什么时候?
-
时间片耗尽 — 操作系统调度
-
阻塞式 I/O — 如
printf、read等 -
主动休眠 —
sleep、usleep等 -
陷入内核 — 系统调用时
什么时候选择新的?
从内核态返回到用户态的时候,进行检查
重要机制:操作系统在从内核态返回用户态时,会检查是否需要调度(时间片是否用完、是否有更高优先级线程等),决定是否进行线程切换。
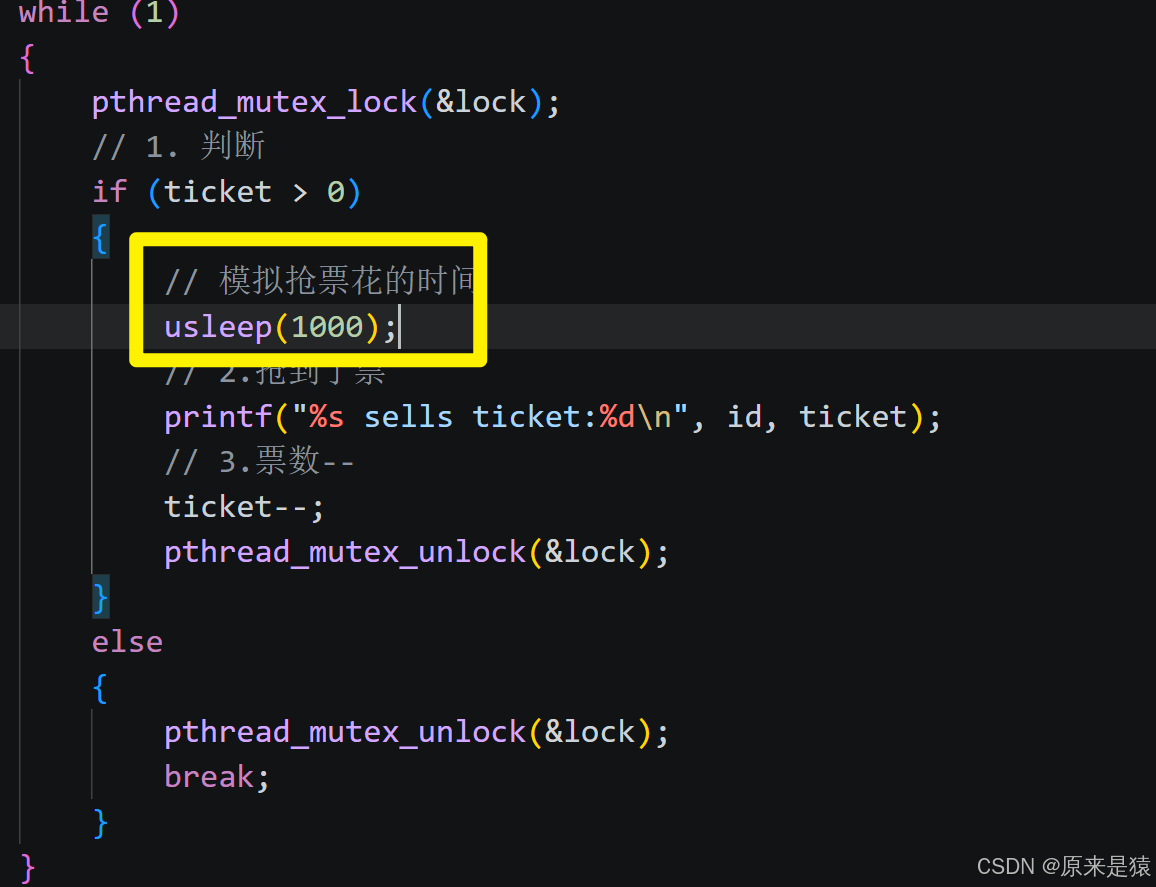
usleep 让线程主动放弃 CPU,增加了线程切换的概率,使得 ticket-- 的三条汇编指令之间更容易被中断,从而更容易观察到数据不一致。
原子操作 vs 互斥锁
-
原子操作:硬件级别的支持(如 x86 的
LOCK前缀),适用于简单操作(计数器增减) -
互斥锁:操作系统级别的同步机制,适用于复杂的临界区保护
2.4 互斥锁(Mutex)

互斥量(mutex)是一种锁机制,用于保护临界区,确保同一时刻只有一个线程进入。
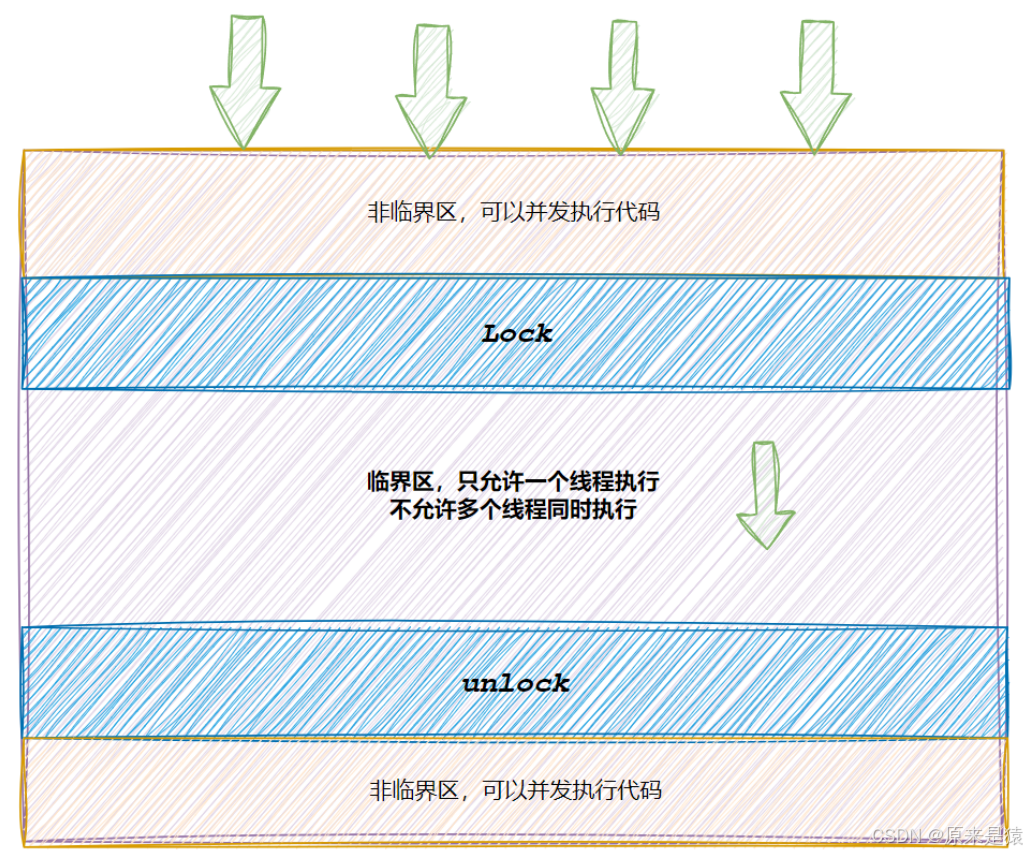
要解决问题,必须做到:
- 临界区同时只能有一个线程进入
- 线程进入后不被干扰
- 退出后其他线程才能进入
Linux 提供的解决方案:互斥量 mutex(一把锁)。、
1. 竞争申请锁 , 多线程都先看到锁,锁本身就是临界资源!!!申请锁的过程,必须是原子的
2.

2.4.1 初始化互斥量
注意:用 PTHREAD_MUTEX_INITIALIZER 初始化的互斥量不需要销毁 , 程序运行结束,会自动释放
初始化互斥量有两种方法:
- 静态分配:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 静态初始化- 动态初始化:
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);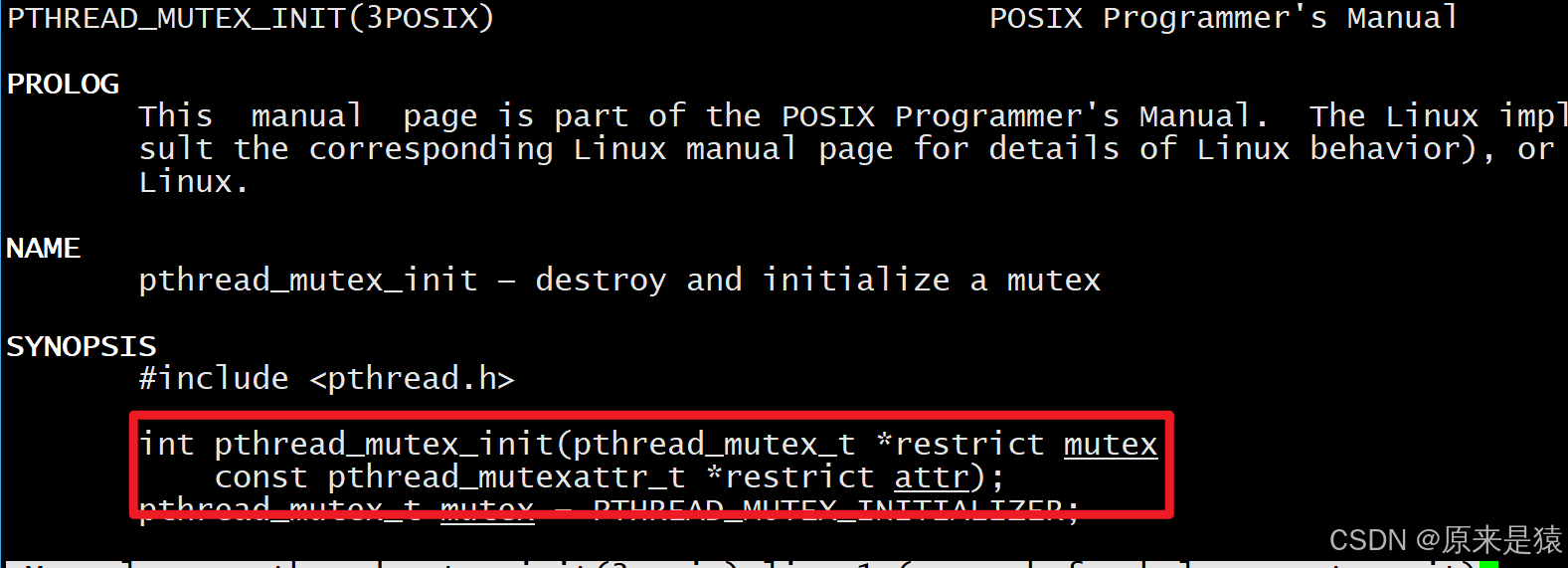
- mutex : 要初始化的互斥量
- attr : NULL
如果锁是空闲的,当前线程获得锁
如果锁被占用,线程阻塞等待
2.4.2 解锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);释放锁,唤醒等待的线程
2.4.3 销毁锁
int pthread_mutex_destroy(pthread_mutex_t *mutex);注意:
- 静态初始化的锁不用销毁
- 不能销毁正在加锁的锁
2.5 代码
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <mutex>
#include <pthread.h>
int ticket = 1000;
pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER; //全局的锁
class ThreadData
{
public:
ThreadData(const std::string &n, pthread_mutex_t &lock)
: name(n),
lockp(&lock) {};
~ThreadData() {};
std::string name;
pthread_mutex_t *lockp;
};
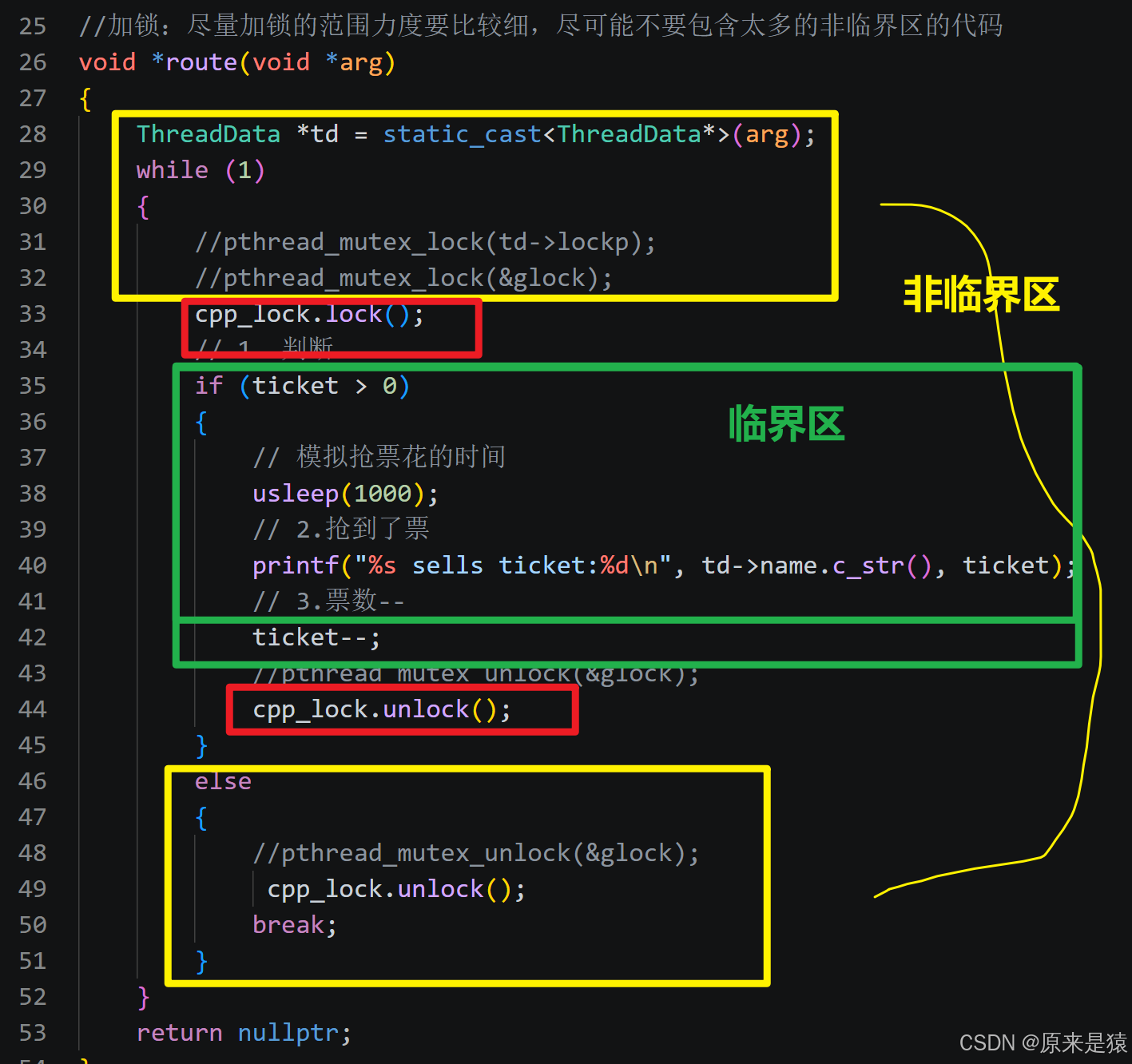
//加锁:尽量加锁的范围力度要比较细,尽可能不要包含太多的非临界区的代码
void *route(void *arg)
{
ThreadData *td = static_cast<ThreadData*>(arg);
while (1)
{
//pthread_mutex_lock(td->lockp);
pthread_mutex_lock(&glock);
cpp_lock.lock();
// 1. 判断
if (ticket > 0)
{
// 模拟抢票花的时间
usleep(1000);
// 2.抢到了票
printf("%s sells ticket:%d\n", td->name.c_str(), ticket);
// 3.票数--
ticket--;
pthread_mutex_unlock(&glock);
}
else
{
pthread_mutex_unlock(&glock);
break;
}
}
return nullptr;
}
int main(void)
{
pthread_mutex_t lock;
pthread_mutex_init(&lock,nullptr);//初始化锁
pthread_t t1, t2, t3, t4;
ThreadData *td1 = new ThreadData("thread 1", lock);
pthread_create(&t1, NULL, route, td1);
ThreadData *td2 = new ThreadData("thread 2", lock);
pthread_create(&t2, NULL, route, td2);
ThreadData *td3 = new ThreadData("thread 3", lock);
pthread_create(&t3, NULL, route, td3);
ThreadData *td4 = new ThreadData("thread 4", lock);
pthread_create(&t4, NULL, route, td4);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
pthread_mutex_destroy(&lock);//回收锁
return 0;
}
pthread_mutex_lock(&mutex);
尝试加锁,如果锁已被占用,当前线程会阻塞在这里。
if (ticket > 0)
进入临界区后再次检查票数,确保安全。
printf(...)和ticket--
这些操作现在都在锁的保护下,不会被其他线程打断。
pthread_mutex_unlock(&mutex);
释放锁,让其他线程有机会进入临界区。⚠️ 注意:
usleep(1000)仍在锁内,虽然是模拟耗时操作,但会导致其他线程等待时间变长。实际开发中应尽量减少锁内耗时。
使用C++的mutex
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <mutex>
#include <pthread.h>
int ticket = 1000;
pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER; //全局的锁
std::mutex cpp_lock;
class ThreadData
{
public:
ThreadData(const std::string &n, pthread_mutex_t &lock)
: name(n),
lockp(&lock) {};
~ThreadData() {};
std::string name;
pthread_mutex_t *lockp;
};
//加锁:尽量加锁的范围力度要比较细,尽可能不要包含太多的非临界区的代码
void *route(void *arg)
{
ThreadData *td = static_cast<ThreadData*>(arg);
while (1)
{
//pthread_mutex_lock(td->lockp);
//pthread_mutex_lock(&glock);
cpp_lock.lock();
// 1. 判断
if (ticket > 0)
{
// 模拟抢票花的时间
usleep(1000);
// 2.抢到了票
printf("%s sells ticket:%d\n", td->name.c_str(), ticket);
// 3.票数--
ticket--;
//pthread_mutex_unlock(&glock);
cpp_lock.unlock();
}
else
{
//pthread_mutex_unlock(&glock);
cpp_lock.unlock();
break;
}
}
return nullptr;
}
int main(void)
{
pthread_mutex_t lock;
pthread_mutex_init(&lock,nullptr);//初始化锁
pthread_t t1, t2, t3, t4;
ThreadData *td1 = new ThreadData("thread 1", lock);
pthread_create(&t1, NULL, route, td1);
ThreadData *td2 = new ThreadData("thread 2", lock);
pthread_create(&t2, NULL, route, td2);
ThreadData *td3 = new ThreadData("thread 3", lock);
pthread_create(&t3, NULL, route, td3);
ThreadData *td4 = new ThreadData("thread 4", lock);
pthread_create(&t4, NULL, route, td4);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
pthread_mutex_destroy(&lock);//回收锁
return 0;
}
- 对临界资源进行保护,本质其实就是用锁,来对临界区代码进行保护
- 锁 --- 原子性

三、互斥量实现原理探究
- 经过上面的例子,已经意识到 单纯的 i++ 或者 ++i 都不是原子的 , 有可能会有数据一致性的问题
- 为了实现互斥锁操作,大多数体系结构都提供了swap 或 exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后 , 一个处理器上的交换指令执行时另一个处理器的交换指令智能等待总线周期 。
锁的实现靠CPU 原子指令(如 xchg、swap),整条指令不可打断

核心:交换指令是原子的,保证同一时间只有一个线程能拿到锁。
四、互斥量的封装
4.1 Mutext.hpp
#pragma once
#include <iostream>
#include <pthread.h>
namespace MutextModule
{
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_mutex, nullptr);
}
void Lock()
{
int n = pthread_mutex_lock(&_mutex);
(void)n;
}
void Unlock()
{
int n = pthread_mutex_unlock(&_mutex);
(void)n;
}
~Mutex()
{
pthread_mutex_destroy(&_mutex);
}
private:
pthread_mutex_t _mutex;
};
class LockGuard
{
public:
LockGuard(Mutex &mutex) : _mutex(mutex)
{
_mutex.Lock();
};
~LockGuard()
{
_mutex.Unlock();
};
private:
Mutex &_mutex;
};
}
4.2 testMutex.cc
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include "Mutex.hpp"
using namespace MutextModule;
int ticket = 1000;
class ThreadData
{
public:
ThreadData(const std::string &n, Mutex &lock)
: name(n),
lockp(&lock) {};
~ThreadData() {};
std::string name;
Mutex *lockp;
};
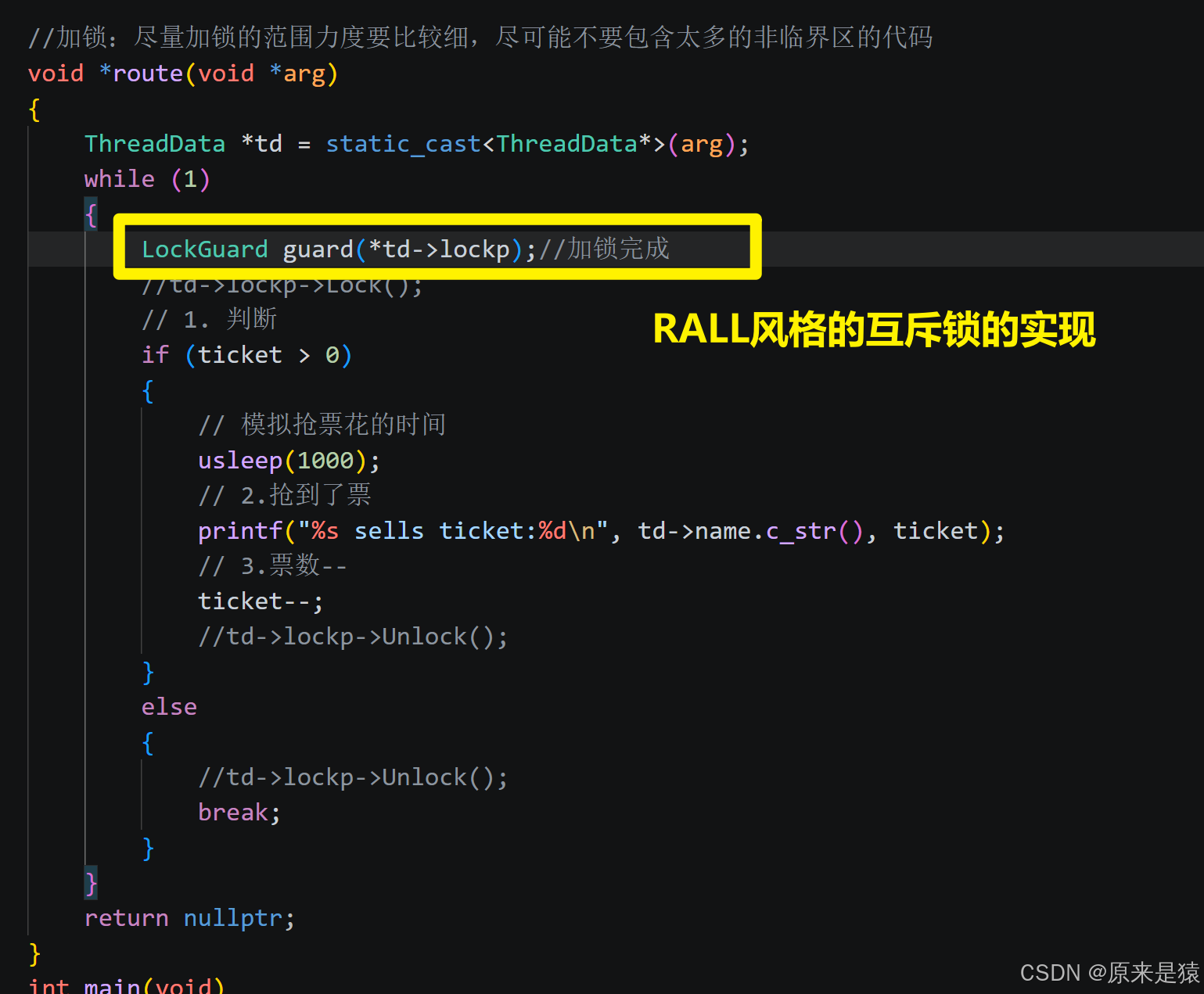
//加锁:尽量加锁的范围力度要比较细,尽可能不要包含太多的非临界区的代码
void *route(void *arg)
{
ThreadData *td = static_cast<ThreadData*>(arg);
while (1)
{
LockGuard guard(*td->lockp);//加锁完成
//td->lockp->Lock();
// 1. 判断
if (ticket > 0)
{
// 模拟抢票花的时间
usleep(1000);
// 2.抢到了票
printf("%s sells ticket:%d\n", td->name.c_str(), ticket);
// 3.票数--
ticket--;
//td->lockp->Unlock();
}
else
{
//td->lockp->Unlock();
break;
}
}
return nullptr;
}
int main(void)
{
Mutex lock;
pthread_t t1, t2, t3, t4;
ThreadData *td1 = new ThreadData("thread 1", lock);
pthread_create(&t1, NULL, route, td1);
ThreadData *td2 = new ThreadData("thread 2", lock);
pthread_create(&t2, NULL, route, td2);
ThreadData *td3 = new ThreadData("thread 3", lock);
pthread_create(&t3, NULL, route, td3);
ThreadData *td4 = new ThreadData("thread 4", lock);
pthread_create(&t4, NULL, route, td4);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
return 0;
}
4.3 Makefile
TestMutex:TestMutex.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f TestMutex
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)