MNIST数字手写体识别
目录
1.图像数据的处理
图像数据可以通过图像处理库Pillow读取,首先安装:
pip install pillow
pip install torchvision
pip install tensorboard
from PIL import Image
import numpy as np
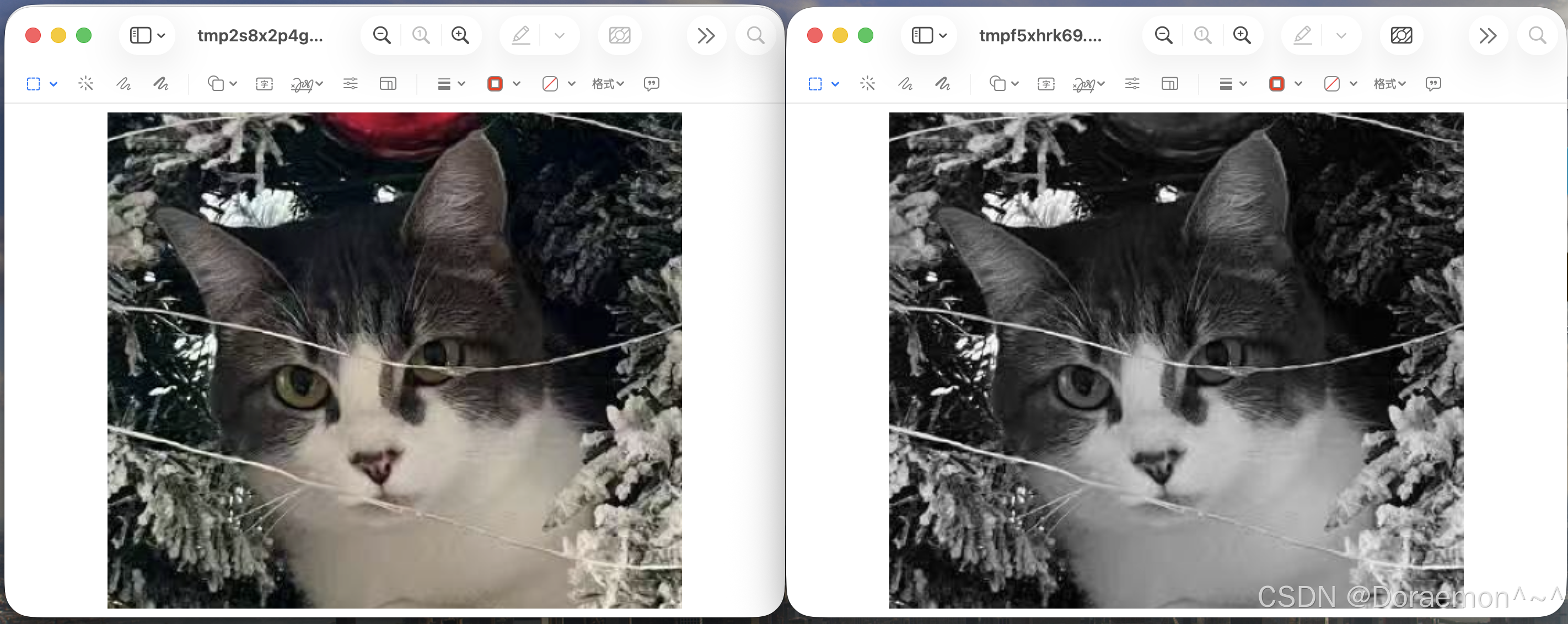
# 打开图像文件
image_path = './cat.png'
image = Image.open(image_path)
# 显示图像
image.show()
# 转换为灰度图
image_grey = image.convert('L')
image_grey.show()
# 将 PIL 图像转换为 NumPy array
# 原图
image_np = np.array(image)
# 灰度图
image_grey_np = np.array(image_grey)
# 打印 NumPy 数组的形状
print("原图 NumPy 数组的形状:", image_np.shape) # (height, width, channel)
print("灰度图 NumPy 数组的形状:", image_grey_np.shape) # (height, width)
# 打印 NumPy 数组的类型
print("原图 NumPy 数组的数据类型:", image_np.dtype) # uint8: [0, 255]
print("灰度图 NumPy 数组的数据类型:", image_grey_np.dtype) # uint8: [0, 255]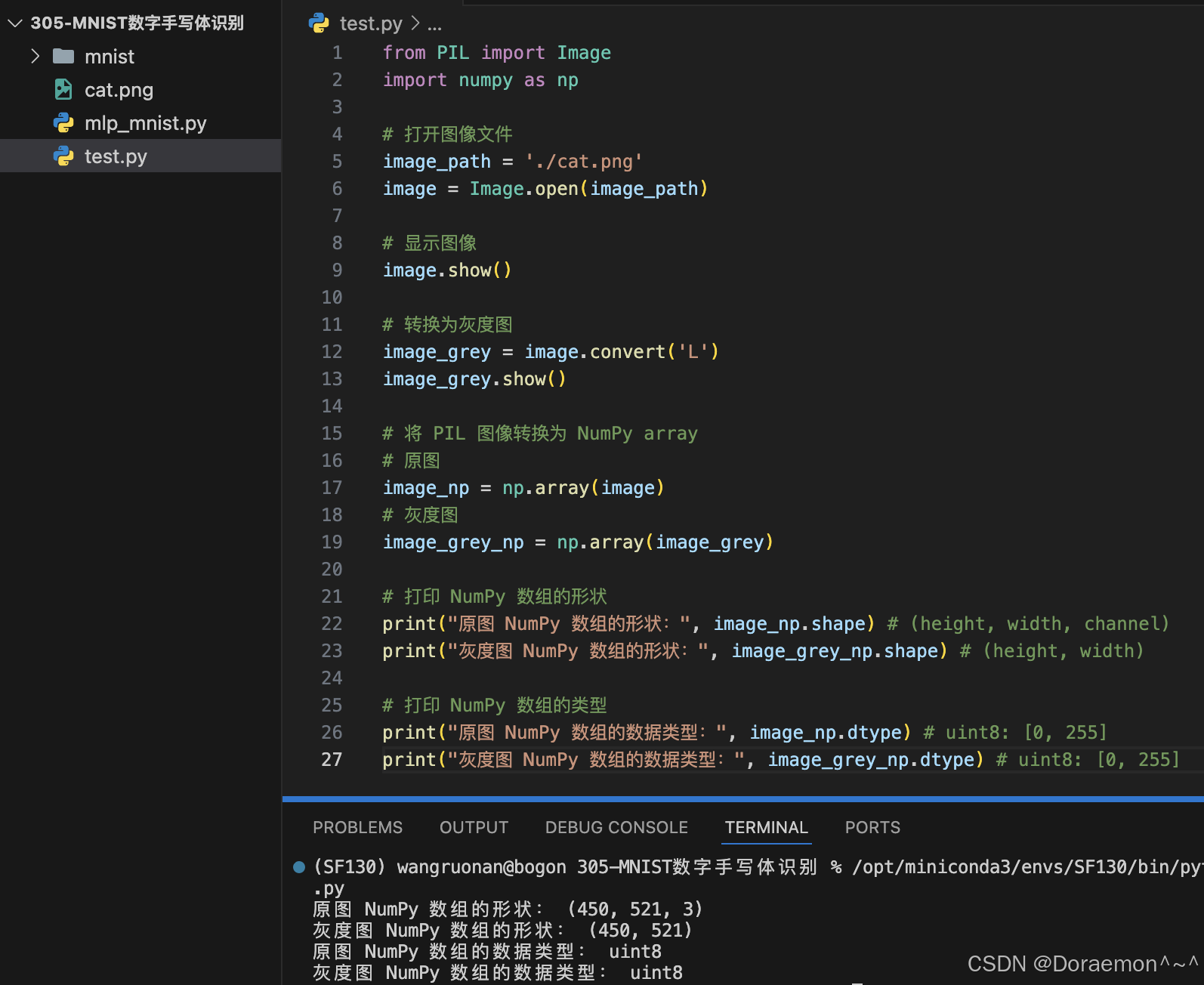
我们在代码中直接使用了torchvision内置的dataset:
# 从 torchvision 库中导入 datasets(用于加载经典数据集)和 transforms(用于数据预处理/增强)
from torchvision import datasets, transforms
# 使用 Compose 将多个图像预处理操作组合成一个流水线,后续会按顺序依次执行
transform = transforms.Compose([
# ToTensor() 变换:
# 1. 将输入的 PIL 图像或 NumPy 数组 (形状为 H x W x C, 像素值 0-255) 转换为 PyTorch 的 FloatTensor
# 2. 将张量的形状调整为 (C x H x W),符合 PyTorch 处理图像的格式
# 3. 将像素值从 [0, 255] (黑-0,白-255)归一化缩放到 [0.0, 1.0] 之间
transforms.ToTensor(),
# Normalize() 变换:对张量进行标准化 (Z-score normalization)
# 公式:output[channel] = (input[channel] - mean[channel]) / std[channel]
# 这里传入的 (0.5,) 是均值 (mean),第二个 (0.5,) 是标准差 (std)
# 由于前面 ToTensor 已经把数据缩放到 [0, 1],经过 (x - 0.5) / 0.5 计算后,
# 数据范围会被进一步映射到 [-1.0, 1.0] 之间,这有助于模型更快收敛
transforms.Normalize((0.5,), (0.5,))
])
# 加载 MNIST 手写数字数据集的训练集
# root='./mnist/': 指定数据集下载/读取的根目录文件夹
# train=True: 设置为 True 表示加载训练集 (training set),False 则加载测试集
# download=True: 如果 root 指定的路径下没有数据集文件,则自动从互联网下载
# transform=transform: 指定前面定义的预处理流水线,数据加载时会自动对图像进行变换
train_dataset = datasets.MNIST(root='./mnist/', train=True, download=True, transform=transform)2.多分类问题的输出层
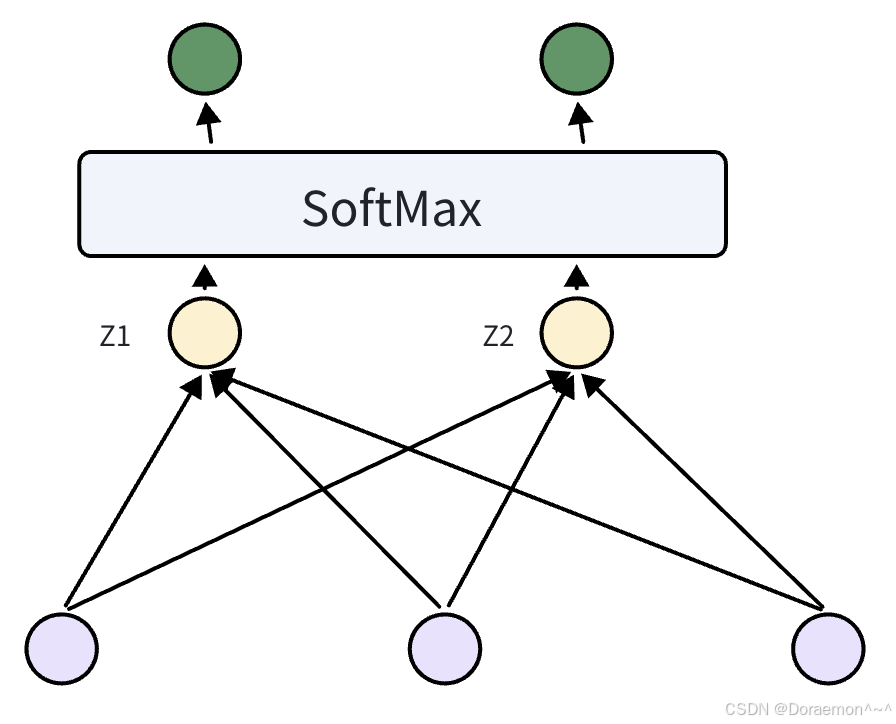
数字手写体识别是一个多分类任务,"0" ~ "9"的每个数字分别对应于一类,一共有10类。多分类问题的输出层节点数量等于类别数,输出层的非线性函数为Softmax,每个节点预测的是样本属于对应类别的条件概率。
设输出层的输入为![]() ,输出为
,输出为![]() ,权重矩阵为
,权重矩阵为![]() (其中第i列
(其中第i列![]() 对应于第i个输出节点的权重向量),偏置向量为
对应于第i个输出节点的权重向量),偏置向量为![]() ,则:
,则:
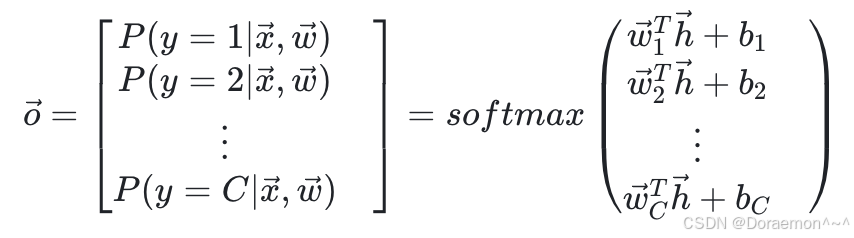
设![]() ,则:
,则:
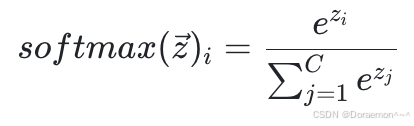
👆是判别式模型。
- 判别式模型:直接基于输入数据学习条件概率分布 P(Y∣X),以此对输入样本完成分类或回归预测。如:逻辑回归。
- 生成式模型:先对输入与标签的联合概率分布 P(X,Y) 建模,再通过贝叶斯定理推导得到条件概率 P(Y∣X) 完成预测,同时具备生成新样本的能力。如:朴素贝叶斯。


注意:由于softmax输出的是概率,因此需要保证各节点输出的总和为1.0(各个结点之间存在竞争关系),分母对应的是归一化项。经过softmax之后,每个节点的输出不仅与对应的![]() 有关,而且与所有节点的线性输出
有关,而且与所有节点的线性输出![]() 都有关系,这一点与其他的激活函数不同。
都有关系,这一点与其他的激活函数不同。
多分类问题的损失函数一般为交叉熵 (CE, Cross Entropy),定义为:
![]()
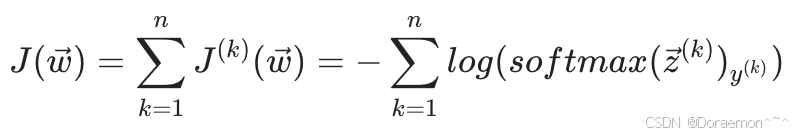
其中k表示第几个样本,![]() 是一个整数,表示样本实际属于的类别标签。交叉熵损失函数可以从两个角度进行理解。
是一个整数,表示样本实际属于的类别标签。交叉熵损失函数可以从两个角度进行理解。
(1)从对数似然函数的角度,可以看出![]() 实际上是负对数似然函数。极小化
实际上是负对数似然函数。极小化![]() 等价于极大化对数似然函数。
等价于极大化对数似然函数。
(2)从信息论的角度,交叉熵衡量的是两个概率分布之间的差异,两者之间的差异越小,则交叉熵越小。假设我们有两个概率分布P和Q,其中P是真实分布,Q是模型预测的分布,那么交叉熵定义为:
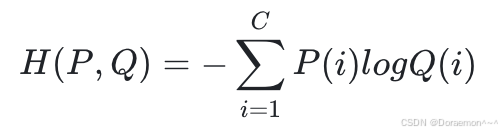
其中模型预测的分布Q为softmax的输出,即:
![]()
而真实分布P是一个1-0分布,即真实类别的概率为1.0, 其余类别的概率为0.0:
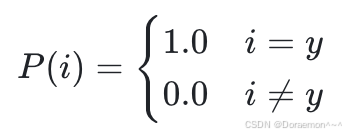
因此,交叉熵 H(P , Q) 可以转化为:
![]()
给数据加上表示样本序号的上标,可以看出和![]() 的公式是一致的。
的公式是一致的。
当真实分布是1-0分布时,交叉墒损失和负对数似然损失是等价的。
补充工程细节:PyTorch 中
nn.CrossEntropyLoss()=nn.LogSoftmax()+nn.NLLLoss(),正是基于该等价性,为 1-0 硬标签分类任务设计的封装接口,也是常规分类任务的标准用法。

知识蒸馏经典范式:用强模型拟合的分布作为准真实分布。
- 「更强大的模型」:知识蒸馏中的教师模型(Teacher Model),通常是参数量大、训练充分、拟合能力极强的预训练大模型,已充分学习到数据的深层规律。
- 「猜的真实分布」:教师模型输出的软标签(Soft Label),不是 1-0 的 one-hot 硬标签,而是完整的类别概率分布(如 3 分类任务中输出
[0.98, 0.015, 0.005]),是对数据真实分布的最优工程逼近。人工标注的 1-0 硬标签仅包含 “非黑即白的对错”,无额外信息;而教师模型输出的软分布,包含了硬标签完全缺失的暗知识(Dark Knowledge)—— 比如类别间的关联信息(“猫和老虎的相似度远高于猫和汽车”)、数据的细粒度规律,这正是轻量小模型很难从稀疏硬标签中学到的核心知识。
知识蒸馏的核心逻辑,就是把教师模型输出的软分布,当作训练学生模型的「准真实分布」,让小模型通过拟合该分布,迁移大模型的深层知识,最终用极小的参数量达到接近大模型的效果。
当我们改用教师模型的软分布作为真实分布时,该分布不再是 1-0 的 one-hot 分布,所有类别都有非零概率值,此时交叉熵与负对数似然的等价性被完全打破:
- 交叉熵损失:会计算完整概率分布的拟合误差,完整保留教师模型的暗知识,是知识蒸馏训练的标准损失函数;
- 负对数似然损失:仅关注单一真实类别的预测概率,会完全丢弃软分布中的类别关联信息,无法实现知识迁移。
- 常规硬标签分类任务中,真实分布为 1-0 的 one-hot 分布,交叉熵损失与负对数似然损失完全等价,可直接使用封装好的交叉熵损失完成训练;
- 知识蒸馏的经典范式中,会放弃人工 1-0 硬标签,改用强教师模型输出的软概率分布作为准真实分布,这一做法既实现了大模型到小模型的知识迁移,也打破了两类损失的等价性,必须使用完整交叉熵损失完成训练。
Softmax 函数的求导
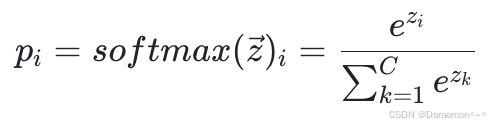
softmax 函数的输入和输出是向量,设其长度为 C 。梯度矩阵 J 的尺寸为(C,C),![]()
- 输入是Zj,j是输入结点的下标
- 输出是Pi,i是输出结点的下标
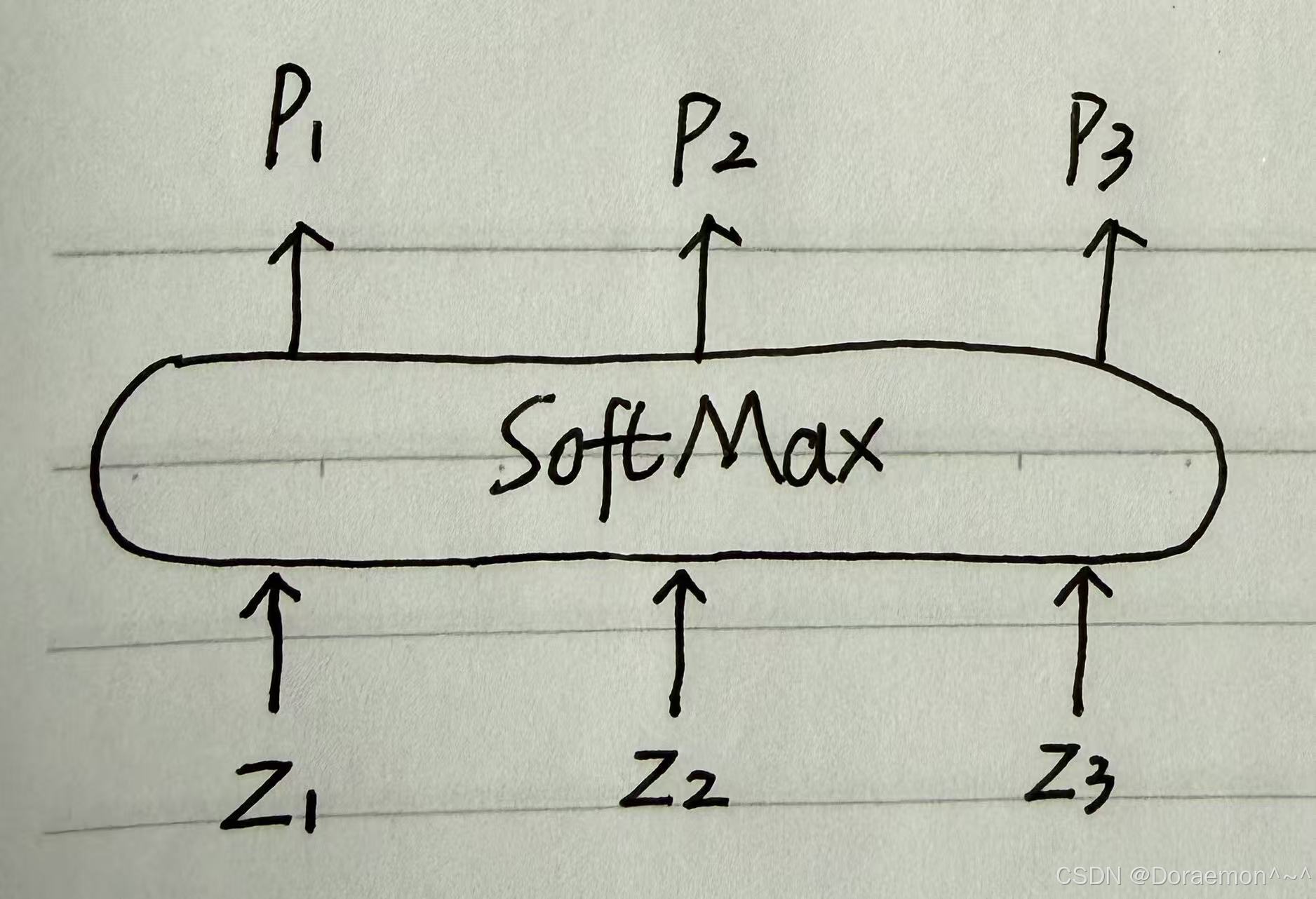
(1)当 i, j 相等时:
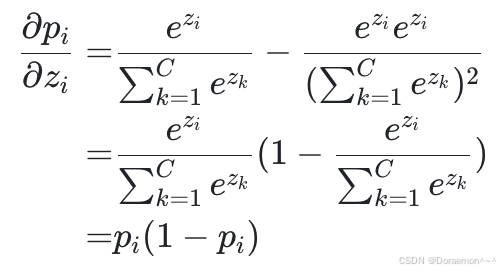
(和Sigmoid类似)
(2)当 i, j 不等时:
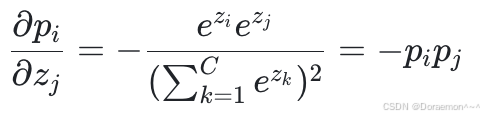
3.基于MLP进行数字手写体识别
数据集:
"""
基于 PyTorch 实现的 MNIST 手写数字识别多层感知机(MLP)训练脚本
功能包含:
- 自定义 MLP 模型构建
- 训练循环与验证
- TensorBoard 可视化训练过程
- 早停(Early Stopping)机制
- 模型保存与加载
- 测试集最终评估
"""
import torch # PyTorch 核心库
import torch.nn as nn # 神经网络模块,包含层、损失函数等
from torch.utils.data import DataLoader, Dataset, random_split # 数据加载工具:DataLoader、Dataset基类、数据集拆分
from torch.optim import SGD # 随机梯度下降优化器
from torchvision import datasets, transforms # 计算机视觉工具:常用数据集、图像变换
from typing import Union # 类型提示:联合类型
import os # 操作系统接口:路径操作、目录管理
from torch.utils.tensorboard import SummaryWriter # TensorBoard 可视化写入器
class MLP(nn.Module):
"""
多层感知机(Multi-Layer Perceptron, MLP)模型
使用 nn.Sequential 顺序构建隐藏层(带 ReLU 激活)和输出层
"""
def __init__(self, dims):
"""
初始化 MLP 模型
参数:
dims (list): 维度列表,依次为 [输入层维度, 隐藏层1维度, ..., 隐藏层n维度, 输出层维度]
"""
super().__init__()
self.hidden_layer_num = len(dims) - 2 # 计算隐藏层数量(总层数减输入输出层)
self.layers = nn.Sequential() # 顺序容器,用于堆叠网络层
# 循环添加隐藏层(线性层 + ReLU激活)
for i in range(self.hidden_layer_num):
self.layers.add_module("linear_"+str(i), nn.Linear(in_features=dims[i], out_features=dims[i+1]))
self.layers.add_module("relu_"+str(i), nn.ReLU())
self.layers.add_module("output", nn.Linear(in_features=dims[-2], out_features=dims[-1])) # 添加输出层(无激活)
def forward(self, x):
"""
前向传播函数
参数:
x (torch.Tensor): 输入张量
返回:
torch.Tensor: 模型输出张量
"""
return self.layers(x)
def train(model : nn.Module,
train_dataset : Dataset,
valid_dataset : Dataset,
loss_fn : nn.Module,
optimizer : torch.optim.Optimizer,
config : dict) -> None:
"""
模型训练主函数
包含训练循环、验证、TensorBoard 记录、早停判断及最佳模型保存
参数:
model (nn.Module): 待训练的模型
train_dataset (Dataset): 训练数据集
valid_dataset (Dataset): 验证数据集
loss_fn (nn.Module): 损失函数
optimizer (torch.optim.Optimizer): 优化器
config (dict): 配置字典,包含训练超参数、设备、保存路径等
"""
# 创建数据加载器:训练集打乱、验证集不打乱
train_dataloader = DataLoader(train_dataset, batch_size=config['train_batch_size'], shuffle=True, drop_last=True)
eval_dataloader = DataLoader(valid_dataset, batch_size=config['eval_batch_size'], shuffle=False, drop_last=False)
# 将模型移动到指定设备(CPU/GPU)
model = model.to(config['device'])
# 训练主流程初始化
best_valid_loss = 1e10 # 初始化最佳验证损失为极大值
no_improve_epochs = 0 # 验证损失未改善的轮数计数
step = 0 # 全局训练步数(用于 TensorBoard 记录)
for epoch in range(config['epochs']):
model.train() # 将模型设置为训练模式(启用 Dropout、BatchNorm 等训练专用层)
train_loss = [] # 记录当前 epoch 每个 batch 的训练损失
for batch_x, batch_y in train_dataloader:
# 将 batch 数据移动到指定设备
batch_x = batch_x.to(config['device'])
batch_y = batch_y.to(config['device'])
# 前向传播:计算模型预测和损失
preds = model(batch_x)
loss = loss_fn(preds, batch_y)
train_loss.append(loss)
# TensorBoard 可视化:记录每个 mini-batch 的损失
writer.add_scalar('minibatch loss', loss, step)
# 反向传播:计算梯度
loss.backward()
# 优化器更新:更新模型参数
optimizer.step()
step += 1 # 更新全局步数
# 梯度清零:避免梯度累积
optimizer.zero_grad()
# 计算当前 epoch 的平均训练损失
train_mean_loss = sum(train_loss) / len(train_loss)
# 在验证集上评估模型
valid_mean_loss, valid_mean_accuracy = test(model, eval_dataloader, loss_fn, config)
# 打印当前 epoch 的训练和验证指标
print(f'epoch: {epoch}, train_loss: {train_mean_loss:.5f}, valid_loss: {valid_mean_loss:.5f}, valid_accuracy: {valid_mean_accuracy:.5f}')
# TensorBoard 可视化:记录训练和验证的 epoch 损失
writer.add_scalars('epoch loss', {'train': train_mean_loss, 'valid': valid_mean_loss}, epoch)
# 检查验证损失是否改善,更新最佳模型
if valid_mean_loss < best_valid_loss:
best_valid_loss = valid_mean_loss # 更新最佳验证损失
no_improve_epochs = 0 # 重置未改善计数
torch.save(model.state_dict(), config['save_path']) # 保存当前最佳模型参数
else:
no_improve_epochs += 1 # 未改善,计数加1
# 触发早停机制:超过最大未改善轮数则停止训练
if no_improve_epochs > config['max_no_improve_epochs']:
print(f'early stop at epoch: {epoch}')
break
def test(model : nn.Module, data : Union[DataLoader, Dataset], loss_fn : nn.Module, config : dict) -> list:
"""
在验证集或测试集上评估模型性能
计算平均损失和平均准确率
参数:
model (nn.Module): 待评估的模型
data (Union[DataLoader, Dataset]): 评估数据,可为 DataLoader 或 Dataset
loss_fn (nn.Module): 损失函数
config (dict): 配置字典,包含设备、batch size 等
返回:
list: [平均损失, 平均准确率]
"""
# 检查模型是否在指定设备上,不在则移动
if next(iter(model.parameters())).device.type != config['device']:
model = model.to(config['device'])
model.eval() # 将模型设置为评估模式(禁用 Dropout、BatchNorm 等训练专用层)
# 根据输入类型创建 DataLoader
if isinstance(data, DataLoader):
dataloader = data
else:
dataloader = DataLoader(data, batch_size=config['eval_batch_size'], shuffle=False, drop_last=False)
loss = [] # 记录每个 batch 的损失
accuracy = [] # 记录每个 batch 的准确率
batch_num = [] # 记录每个 batch 的样本数(用于加权平均)
# 禁用梯度计算,节省内存和计算资源
with torch.no_grad():
for batch_x, batch_y in dataloader:
# 将 batch 数据移动到指定设备
batch_x = batch_x.to(config['device'])
batch_y = batch_y.to(config['device'])
# 前向传播:计算预测
preds = model(batch_x)
# 计算损失并记录
loss.append(loss_fn(preds, batch_y.to(config['device'])))
# 计算准确率:预测类别与真实类别比较,取平均后记录
accuracy.append((torch.argmax(preds, dim=-1).reshape(-1) == batch_y).float().mean())
batch_num.append(len(batch_x)) # 记录当前 batch 的样本数
# 计算加权平均损失(考虑不同 batch 大小)
mean_loss = sum([loss[i] * batch_num[i] for i in range(len(loss))]) / sum(batch_num)
# 计算加权平均准确率
mean_accuracy = sum([accuracy[i] * batch_num[i] for i in range(len(accuracy))]) / sum(batch_num)
return mean_loss, mean_accuracy
def same_seed(seed):
"""
设置随机种子,确保 PyTorch 实验结果的可复现性
固定 CPU、GPU(单卡/多卡)的随机种子,并禁用 CuDNN 的非确定性算法
参数:
seed (int): 随机种子值
"""
torch.manual_seed(seed) # 固定 CPU 随机种子
torch.cuda.manual_seed(seed) # 固定当前 GPU 随机种子
torch.cuda.manual_seed_all(seed) # 固定所有 GPU 随机种子(多卡场景)
torch.backends.cudnn.deterministic = True # 禁用 CuDNN 的非确定性算法
torch.backends.cudnn.benchmark = False # 禁用 CuDNN 的自动优化(避免非确定性)
if __name__ == '__main__':
do_training = True # 训练标志:True 执行训练,False 仅加载模型测试
# 配置字典:包含所有超参数、路径、设备等设置
config = {
"seed": 0, # 随机种子
"lr": 0.01, # 学习率
"weight_decay": 0.001, # 权重衰减(L2 正则化)
'train_batch_size': 32, # 训练 batch 大小
'eval_batch_size': 32, # 评估 batch 大小
"epochs": 1000, # 最大训练轮数
"max_no_improve_epochs": 10, # 早停阈值:验证损失连续未改善的最大轮数
"valid_ratio": 0.1, # 验证集占训练集的比例
"save_path": "./model/mlp.ckpt", # 模型保存路径
"device": 'cuda' if torch.cuda.is_available() else 'cpu', # 设备:优先 GPU,否则 CPU
'log_dir': './log/' # TensorBoard 日志保存目录
}
# 清理旧的 TensorBoard 日志目录(若存在则删除所有内容)
if os.path.isdir(config['log_dir']):
os.system(f"rm -fr {config['log_dir'] + os.sep + '*'}")
writer = SummaryWriter("./log/") # 创建 TensorBoard 写入器
# 设置随机种子,保证可复现性
same_seed(config['seed'])
# 检查模型保存目录是否存在,不存在则创建
model_dir = os.path.split(config['save_path'])[0]
if not os.path.isdir(model_dir):
os.makedirs(model_dir)
# 定义图像预处理变换:转为张量 + 标准化(均值0.5,标准差0.5)
transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载 MNIST 训练集和测试集(若本地不存在则自动下载)
train_dataset = datasets.MNIST("./mnist", train=True, download=True, transform=transforms)
test_dataset = datasets.MNIST("./mnist", train=False, download=True, transform=transforms)
# 拆分训练集为新的训练集和验证集
train_size = int(len(train_dataset) * (1 -config['valid_ratio'])) # 新训练集大小
valid_size = len(train_dataset) - train_size # 验证集大小
train_dataset, valid_dataset = random_split(train_dataset, [train_size, valid_size]) # 随机拆分
# 创建模型:先 Flatten 将 28x28 图像展平为 784 维向量,再接入自定义 MLP
model = nn.Sequential(nn.Flatten(), MLP([28*28, 128, 10]))
# 定义损失函数:交叉熵损失(适用于多分类任务)
loss_fn = nn.CrossEntropyLoss(reduction='mean')
# 定义优化器:随机梯度下降(SGD),包含学习率和权重衰减
optimizer = SGD(model.parameters(), lr=config['lr'], weight_decay=config['weight_decay'])
# 执行训练流程
if do_training:
train(model, train_dataset, valid_dataset, loss_fn, optimizer, config)
torch.save(model.state_dict(), config['save_path']) # 训练结束后再次保存模型(确保最终状态保存)
# 加载最佳模型参数
model.load_state_dict(torch.load(config['save_path'], weights_only =True))
# 在测试集上评估最终模型性能
test_loss, test_accuracy = test(model, test_dataset, loss_fn, config)
print(f'test_loss: {test_loss:.5f}, test_accuracy: {test_accuracy:.5f}')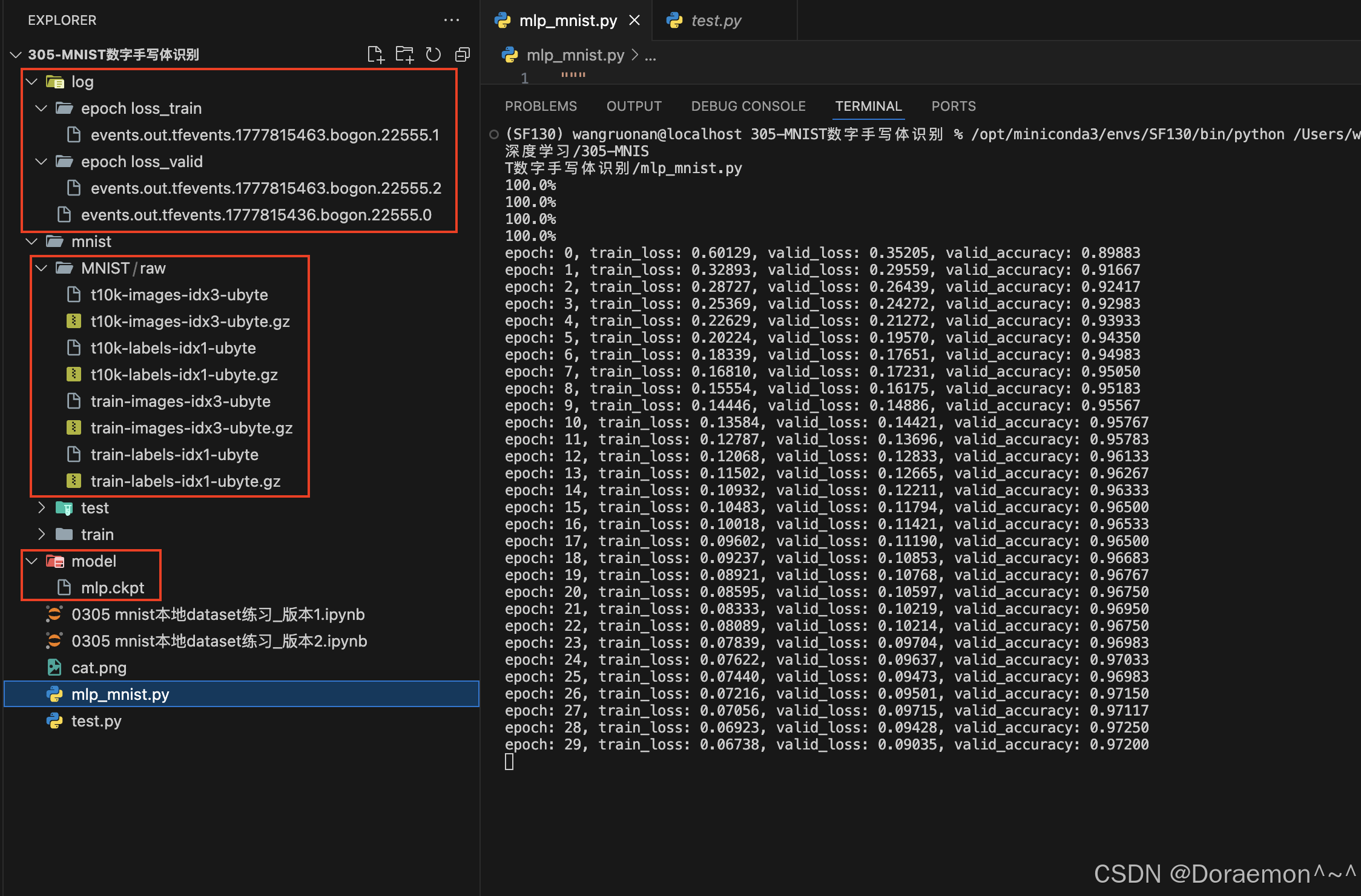
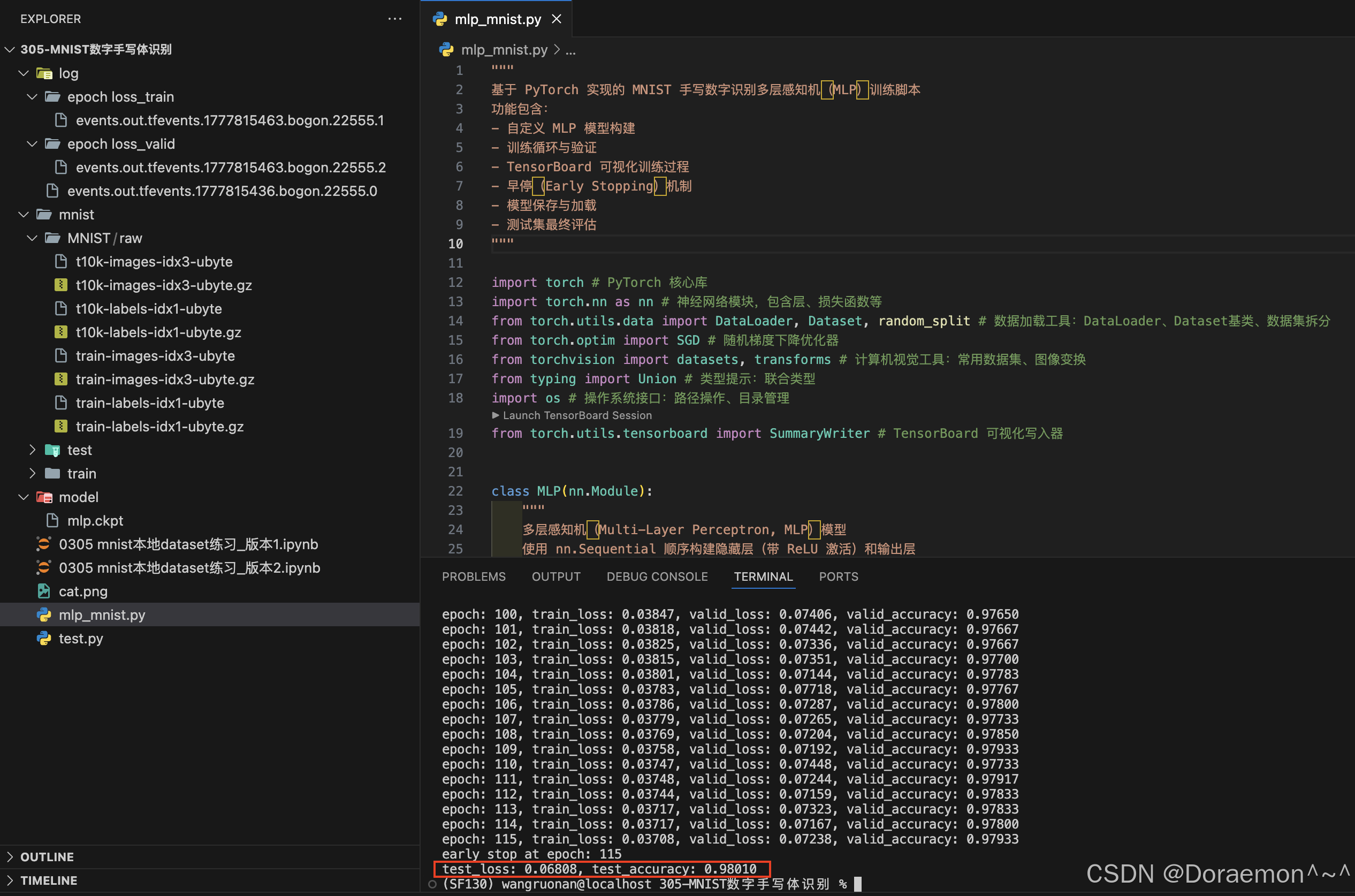
“断点续训”
这是为了解决 AI 模型长周期训练的风险与灵活性问题,形成的「存档 - 验档 - 读档续跑」完整流程:检查点是存档、检查校验是验档、断点续训是读档接着跑。
一、检查点(Check Point,常简称 ckpt)
它的本质,是模型训练过程中,对某一个时间点的完整训练状态,做的全量、可恢复的快照存档。
我们用马拉松做类比,你可以把模型训练理解成一场长达几十、上百公里的马拉松:
模型训练不是一蹴而就的,需要对着海量数据反复学习、调整自身的 “知识参数”,整个过程短则数小时,长则数天甚至数周,是一个连续推进的过程。
检查点,就是这场马拉松里,你每隔一段距离设置的「打卡存档点」。它不只是记录 “跑了多少公里”,还会完整记录当前的配速节奏、体能状态、跑步姿势等所有能让你无缝接着跑的信息。
对应到训练里,一个完整的检查点,会存档三类核心信息:一是模型当前已经学到的全部知识(模型参数);二是训练的推进进度(已经学完了多少轮完整数据);三是训练的 “节奏状态”(比如当前的学习速率、优化器的运行状态等),确保后续能完全承接之前的训练节奏,不会跑偏。
常规训练中,会按固定周期生成检查点,同时会单独保留训练效果最好的那个存档,避免意外覆盖。
二、检查 Check Point(检查点校验)
这是接续训练前的关键保障步骤,本质是验证你要用来续训的检查点存档,是否完整、可用、匹配当前的训练环境。
就像你读游戏存档前,要先确认这个存档没损坏、和你当前的游戏版本匹配,不然读档会报错、闪退。这个校验环节,核心就是确认:存档文件有没有损坏、里面的核心训练信息是否完整、存档的模型结构和你当前要用的模型是否匹配、训练进度信息是否正常,确保这个检查点能正常加载,不会导致续训失败。
三、断点续训(下次接着训)
它的本质,是基于校验通过的检查点存档,在训练中断后,无缝接续之前的进度,继续完成剩余训练的操作。
这里的 “断点”,就是训练停止的节点 —— 不管是意外中断(比如断电、程序报错、服务器宕机),还是你主动暂停训练(比如要关机、想调整训练参数、先验证下当前的训练效果),只要有对应断点的、校验通过的检查点,你就完全不用从头开始重新训练。
加载检查点后,模型和训练环境会被完全恢复到中断那一刻的状态,你可以直接接着之前的进度继续训练,完整承接之前所有的训练成果,不会重复劳动,也不会丢失之前模型学到的内容。
🌟 核心逻辑与价值
三者是强绑定的配套流程:检查点是基础,检查校验是安全保障,断点续训是最终目的。它的核心价值有两点:一是抗风险,避免长周期训练因为意外前功尽弃,大幅节省时间和算力成本;二是灵活性,支持训练的随时暂停、重启,也支持基于已有训练成果调整优化策略后继续训练,不用从零起步。
4.TensorBoard可视化工具
TensorBoard是一款用于观察神经网络训练过程的可视化工具。
首先,需要安装tensorboard: pip install tensorboard
然后在代码里记录tensorboard日志,示例:
from torch.utils.tensorboard import SummaryWriter
# 创建SummaryWriter对象
writer = SummaryWriter('logs')
# 记录计算图
model = Linear(10, 5)
x = torch.rand(32, 10)
writer.add_graph(model, x)
# 开始训练模型
# ......
# 记录标量数据,如loss、accuracy等
writer.add_scalar("train loss", loss, global_step=step, walltime=None)
# 同时记录多个标量数据
writer.add_scalar("train", {"loss": loss, "accuracy": accuracy}, global_step=step)
# 记录直方图数据 (如模型参数、特征输入、中间层的输出、梯度等)
writer.add_histogram("model weight", model.weight, global_step=step, bins='tensorflow')有两种方式查看可视化图表:
(1) 基于vscode,安装Tensorboard插件,即可在vscode内查看tensorboard的可视化图表。

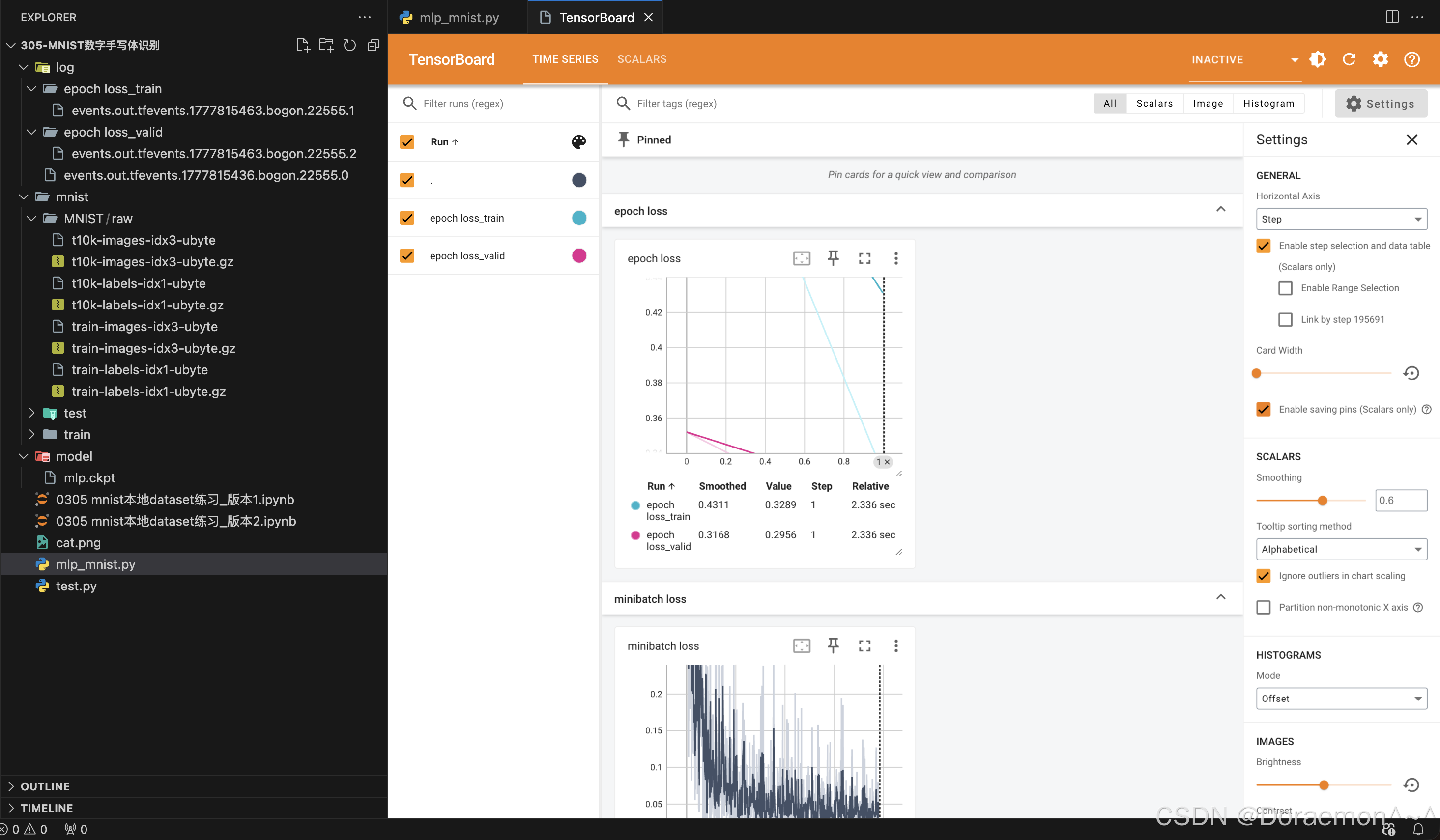
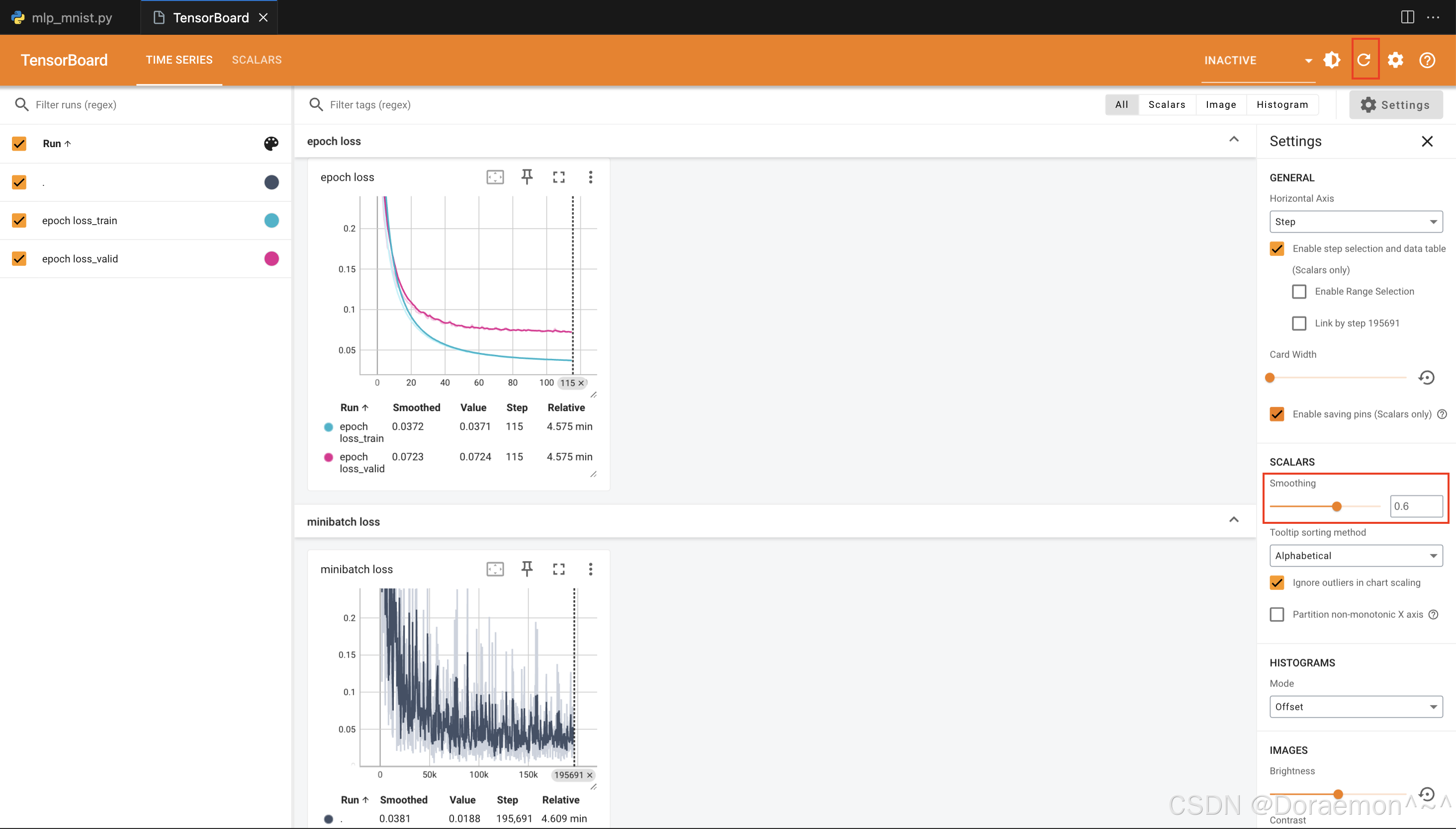
(2)基于浏览器。
- a、在终端启动tensorboard:tensorboard --logdir=logs --port=6006
- b、打开浏览器,访问地址 http://localhost:6006 即可查看
当训练程序在远端server运行时,可以在server启动tensorboard服务,通过端口映射的方式访问。此时,在服务器启动tensorboard服务的命令需要增加 --host 参数:
tensorboard --logdir=logs --host=0.0.0.0 --port=6006之后在本地终端进行端口映射:
ssh -L 6006:localhost:6006 username@YOUR_SERVER_IP然后就可以通过在本地浏览器访问 http://localhost:6006 ,看到服务器上运行的TensorBoard界面。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)