Claude Code 源码深度解析:拆解上下文的组成与缓存
Hi,大家好,欢迎来到维元码簿。
本文属于 《Claude Code 源码 Deep Dive》 系列。如果你对整体模块地图感兴趣,可以先看Claude Code 源码架构概览:51万行代码的模块地图。
本文聚焦一件事:模型的上下文到底是什么,由什么组成,怎么组装出来的。
为什么这件事重要?因为 Agent 的每一次决策都只看得到上下文。模型不知道你的项目结构、不知道你刚才改了什么文件、不知道有哪些工具可以用——除非你在上下文里告诉它。上下文质量直接决定行为质量,上下文编排就是 Claude Code 工程体系里最精密的部分。
读完全文,你将能回答这几个问题:
- 模型是怎么“看到”你的对话的?你的项目信息呢? 你的文字、项目结构、工具能力,是怎么混在一起送到模型眼前的?
- Claude Code 专业沉稳的“人设”是谁写的? 没有一个人定义了它,那它是怎么被塑造出来的?
- 你只打了一句话,模型实际收到了多少信息? 工具描述、CLAUDE.md、系统提醒……这些内容是怎么和你的文字混在一起的?
- 同一个项目聊了50轮,每一轮的 API 费用都一样吗? 系统在背后做了什么,让你感觉不到成本在翻倍?
我们会从一条真实的 API 调用出发,拆开请求参数,反推出上下文的三大板块,然后逐章深入每个板块的内部结构。至于上下文的优化——缓存、压缩、记忆——那些是后续文章的主题,本文只在必要的地方点到为止。
好,让我们开始。
本篇覆盖的源码范围
在看细节之前,先给一个全局地图。本篇涉及的源码分布和代码量:
| 模块 | 核心文件 | 代码行 | 职责 |
|---|---|---|---|
| System Prompt 组装 | src/constants/prompts.ts |
~915 行 | 静态/动态区段组装、所有 section 定义 |
| System Prompt 优先级 | src/utils/systemPrompt.ts |
~124 行 | Override > Coordinator > Agent > Custom > Default |
| System Prompt Sections 缓存 | src/constants/systemPromptSections.ts |
~69 行 | Memoized vs DANGEROUS_uncached 两种缓存策略 |
| 上下文获取 | src/context.ts |
~190 行 | UserContext(CLAUDE.md + 日期)、SystemContext(Git 状态) |
| 上下文拼装 | src/utils/queryContext.ts |
~180 行 | fetchSystemPromptParts 并行获取三大片段 |
| 消息处理 | src/utils/messages.ts |
~5500 行 | 消息规范化、API 映射、Attachments 展开 |
| API 请求构建 | src/services/api/claude.ts |
~3420 行 | queryModel() 核心函数、paramsFromContext() 最终组装 |
| 缓存切分 | src/utils/api.ts |
~719 行 | splitSysPromptPrefix()、缓存控制标记 |
| 工具 Schema 缓存 | src/utils/toolSchemaCache.ts |
~27 行 | 会话级 Schema 字节锁定 |
总计约 7000+ 行核心代码,横跨 9 个文件。本篇会逐层拆解这些代码做了什么。
从一条 API 调用出发——上下文全景图
我们这篇文章的定位是上下文工程——拆解模型每次调用时 Claude Code 到底组装了什么。那最自然的起点,就是找到那个组装的终点:实际发给 Anthropic API 的请求参数。
从 callModel 到 paramsFromContext
一切从 src/query.ts 第 659 行开始。当你输入一条消息后,Agent 循环最终会走到这里:
// src/query.ts L659
const result = await deps.callModel({
messages: prependUserContext(messagesForQuery, userContext),
systemPrompt: fullSystemPrompt,
tools,
...options,
})
追踪链:deps.callModel → queryModel() → paramsFromContext()(src/services/api/claude.ts L1538-1729)。最终由 paramsFromContext() 返回发给 API 的完整参数,拆开看看:
// src/services/api/claude.ts L1699-1729(简化)
return {
model: normalizeModelStringForAPI(options.model), // 用哪个模型
messages: addCacheBreakpoints(messagesForAPI, ...), // ← 模型上下文
system, // ← 模型上下文
tools: allTools, // ← 模型上下文
tool_choice: options.toolChoice, // 限制工具选择
betas: betasParams, // 启用哪些实验功能
metadata: getAPIMetadata(), // 计费/追踪元数据
max_tokens: maxOutputTokens, // 最大输出长度
thinking, // 思维链配置
temperature, // 采样温度
context_management: contextManagement, // cache editing 指令
output_config: outputConfig, // 输出格式/effort
speed, // 快模式开关
}
这么多字段,模型到底能看到什么?
模型的上下文输入:System Prompt、Messages、Tools
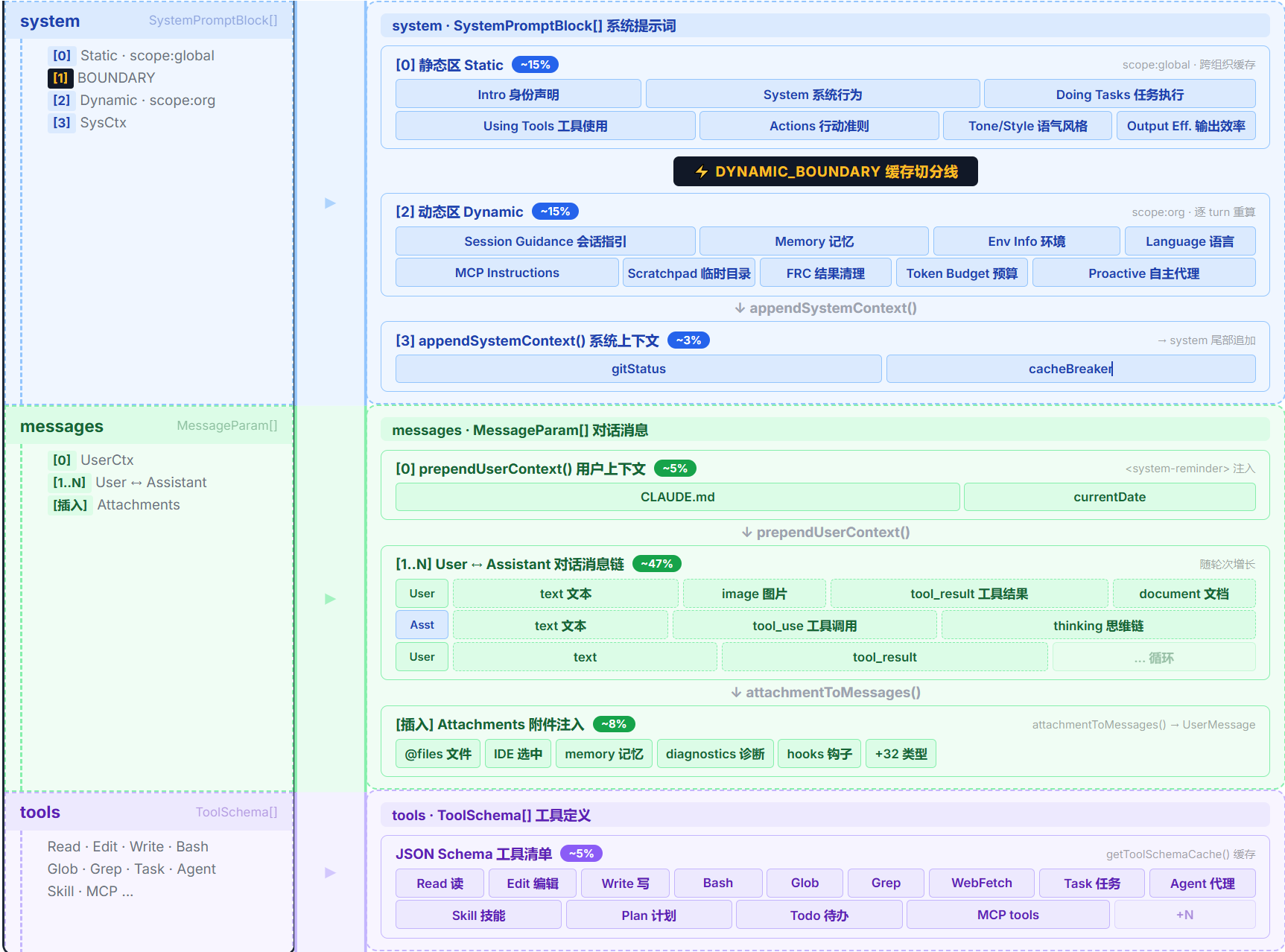
结论先行:模型能看到的上下文只有三个板块——System Prompt、Messages、Tools。
paramsFromContext() 返回的 JSON 中,真正变成 token 喂给模型的只有这三个字段:
| 字段 | 作用 | 预估占比 |
|---|---|---|
system |
告诉模型"你是谁、怎么做事"的指令集 | ~30% |
messages |
对话历史:用户输入、模型回复、工具调用结果 | ~60% |
tools |
工具 Schema:告诉模型可以调用哪些工具 | ~10% |
其余字段(model、max_tokens、thinking、betas 等)都是服务端配置,控制模型怎么回答而非看到什么,不进入 token 序列。
把三个板块合在一起,模型看到的上下文全景如下:
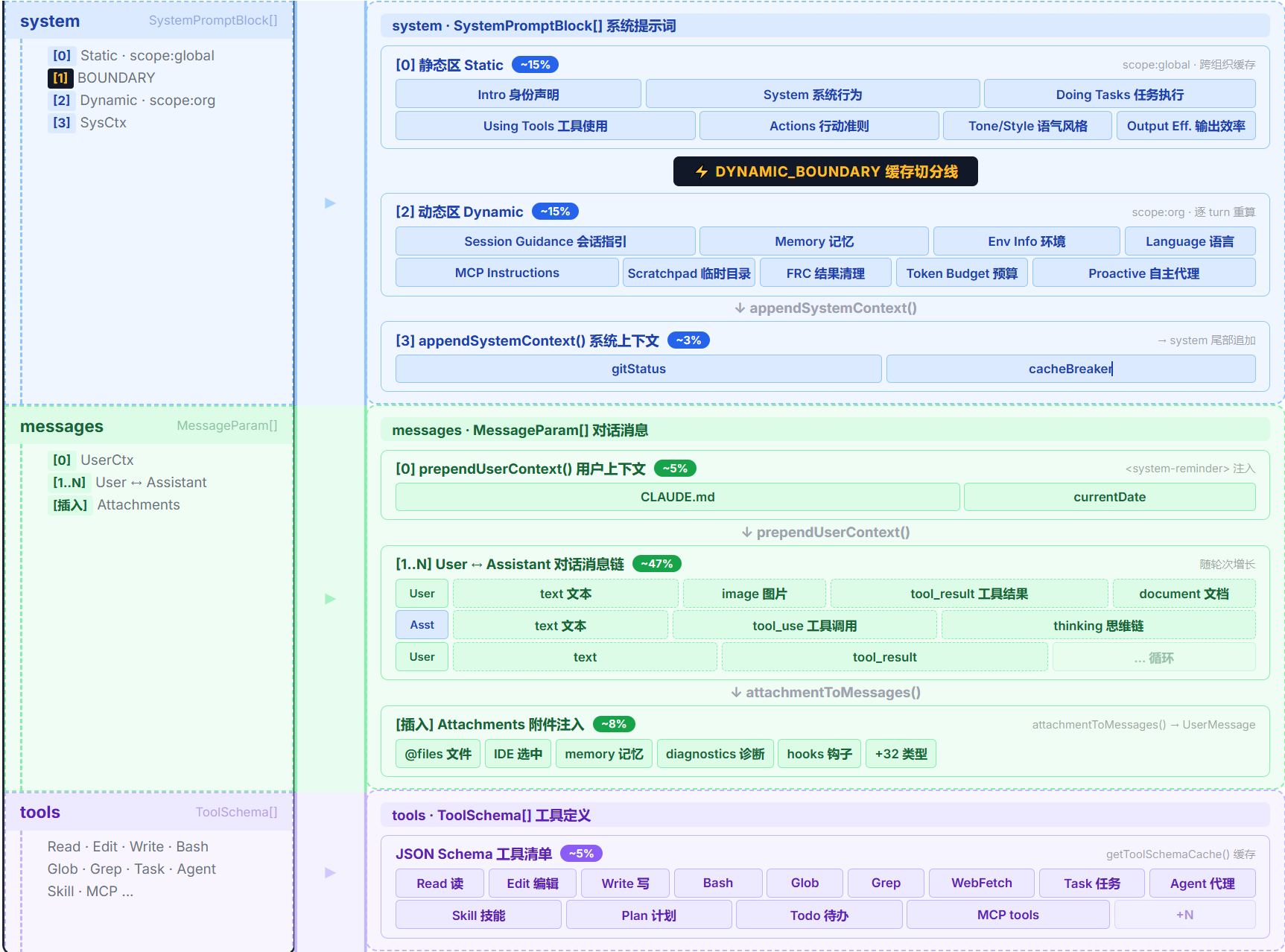
三个板块各是什么:
- System Prompt(
system,~30%):模型的“身份设定与环境感知”,由 7 个静态模块 + 11+ 个动态模块组装成string[]。静态区所有用户共享,可命中全局缓存;动态区因会话变化,以DYNAMIC_BOUNDARY为分界线。总入口getSystemPrompt(),但可能被优先级链(Override > Coordinator > Agent > Custom > Default)替换。 - Messages(
messages,~60%):模型的“对话与上下文记忆”,承载用户输入、工具结果、附件展开、隐藏注入等全部对话信息。内部维护 5 种类型,经normalizeMessagesForAPI()清洗后只留 user/assistant 两种。关键注入点:UserContext(CLAUDE.md+日期)注入 messages[0]、Attachments 展开为 UserMessage、tool_use/tool_result 精确配对。 - Tools(
tools,~10%):30+ 内置工具 + MCP 外部工具的 JSON Schema。支持延迟加载(defer_loading),不常用工具只发精简描述。有 MCP 工具时 System Prompt 跳过全局缓存,避免不同用户的工具 Schema 冲突。
接下来四章分别深入拆解 System Prompt、Messages、Tools 和上下文缓存。
System Prompt——模型的“身份设定与环境感知”
全景图告诉我们 System Prompt 大约占模型上下文的 30%。但 30% 背后的工程量,远比数字显示的更精密。System Prompt 不是一段写死的文本,而是一个动态组装的指令集——根据用户类型、运行模式、工具配置、MCP 连接状态实时拼装。
这一章我们从源码出发,拆开 System Prompt 的每一个零件。
本章拆解约 1200 行核心代码:src/constants/prompts.ts(~915 行,7 静态 + 11+ 动态模块组装)、src/utils/systemPrompt.ts(~124 行,优先级链决策)、src/constants/systemPromptSections.ts(~69 行,Section 缓存框架),外加 src/utils/api.ts 中的缓存切分和上下文追加。
总入口是 getSystemPrompt()(src/constants/prompts.ts L444),返回 string[]——数组而非大字符串,目的是让后续缓存切分逻辑按元素粒度标记边界。标准模式下的组成结构如下:
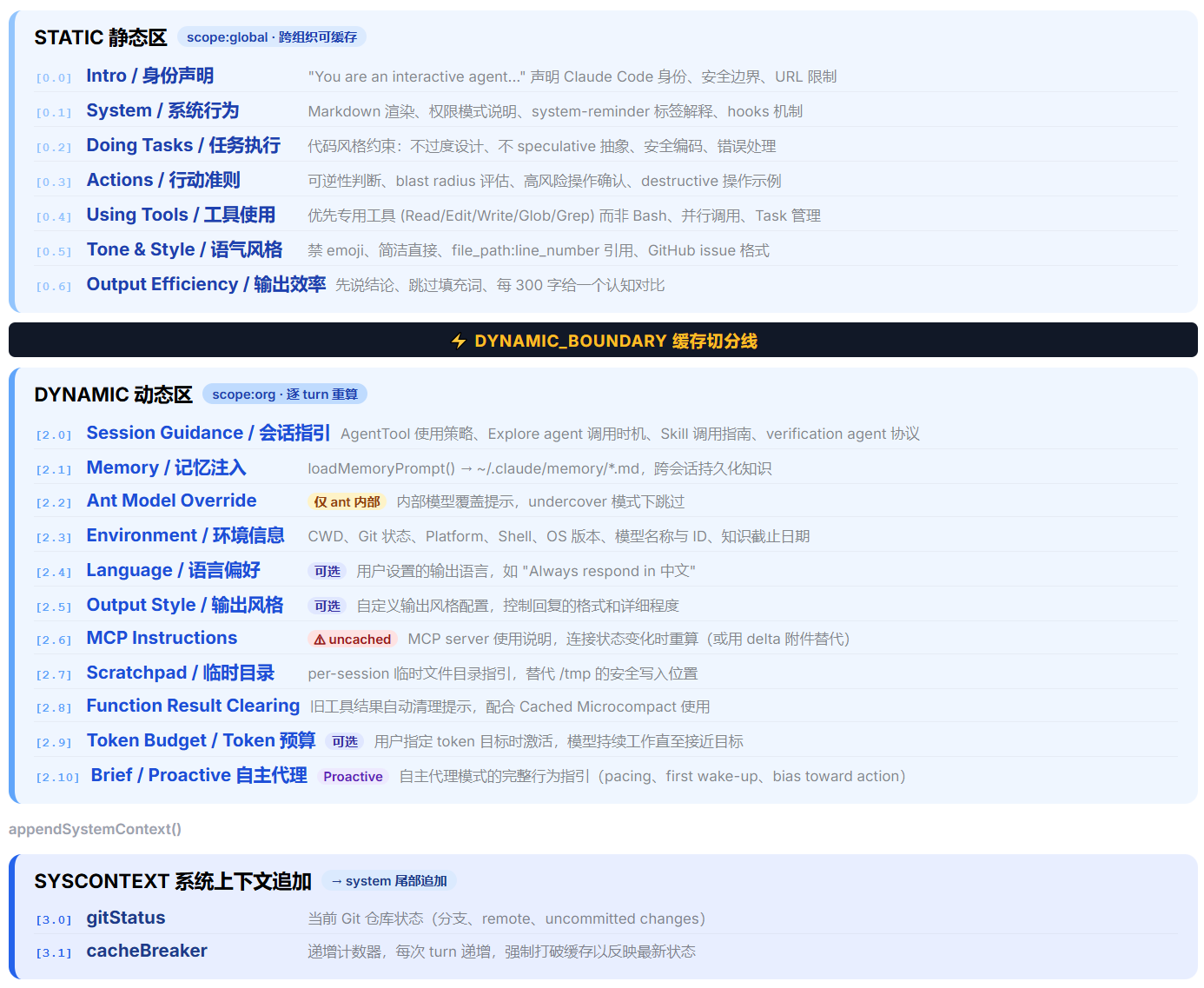
如上图所示,中间的 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 把 prompt 分为静态区和动态区。静态区对所有用户完全相同,可用 scope: 'global' 跨组织缓存;动态区因会话而异,只能用 scope: 'org' 或逐 turn 重算。团队在设计 prompt 时就把缓存作为一等公民:每个新 section 都必须回答“放在边界之前还是之后?”。
静态区——7 个不变的模块
静态区的内容对所有用户完全相同——你可以和地球另一端的用户共享同一份 KV cache,只要字节一致。这 7 个模块构成了 Claude Code 的“人格基础”。

如上图所示,7 个模块按功能分层排列,从身份声明到输出效率逐层递进。其中 Doing Tasks 和 Actions 是最重要的两个模块——前者定义了模型“怎么写代码”,后者定义了模型“什么时候该慢下来”。
| 模块 | 核心原文 | 工程洞察 |
|---|---|---|
| Intro / 身份声明 | You must NEVER generate or guess URLs |
“安全壳”设计——编程场景中模型编造 URL 可导致访问恶意网站。内部版有额外 CYBER_RISK_INSTRUCTION,外部构建时被 DCE 移除 |
| System / 系统行为 | Your conversation is not limited by the context window |
告诉模型有自动压缩兆底,不会因“怕用完 token”而拒绝复杂任务。<system-reminder> 标签解释让模型区分系统注入和用户消息 |
| Doing Tasks / 任务执行 | Don't speculate. Three lines of similar code are fine |
最长的静态模块。“不过度设计”贯穿始终:不 speculative 抽象、不提前加 error handling、不创建一次性 helper。先读后改:没读过的代码不要提修改建议 |
| Actions / 行动准则 | Consider the reversibility and blast radius of actions |
如果只读一个模块就读这个。可逆操作自由执行,不可逆/影响他人(push、删分支)必须确认。授权范围必须与请求匹配——批准一次 push 不等于永久授权 |
| Using Tools / 工具使用 | Prefer dedicated tools over Bash |
Bash 最不透明,用户难以审查。Read>cat、Edit>sed、Write>echo。支持并行调用——读 3 个文件并行比顺序快得多 |
| Tone & Style / 语气 | 不用 emoji、代码引用用 file:line、issue 用 owner/repo#123 |
“不在工具调用前加冒号”解决了真实 UX 问题——工具调用可能不显示,加冒号会变成“让我读一下:”后面空白 |
| Output Efficiency | Go straight to the point. Don't be unnecessarily terse |
外部版偏向简洁,内部 ant 版偏向可理解。过度追求简洁反而增加整体成本——用户需要追问来理解回复 |
几个值得单独展开的点:
Doing Tasks 的“不过度设计”。这四条规则每条背后都有模型曾犯过的真实错误:加了一个没人要求的特性、为三行相似代码抽了个 helper、在系统边界外加了不必要的 validation。Claude Code 团队选择在 prompt 层面显式禁止这些行为,而不是靠模型“自觉”——这是 prompt 工程的务实态度。
Actions 的“可逆性分级”。Claude Code 对 AI 安全的理解不是限制能力,而是让 AI 在高风险场景下主动慢下来。本地可逆操作自由执行,不可逆操作必须确认——简单但极其有效。更有意思的是“授权范围匹配”:用户批准一次 git push 不等于在所有上下文都批准,这防止了模型把单次授权泛化为永久权限。
Output Efficiency 的“简洁 vs 可理解”博弈。原文 What's most important is the reader understanding your output without mental overhead or follow-ups, not how terse you are——这句话本身就是两个优化目标的平衡。外部版偏简洁,内部版偏可理解,因为内部用户更频繁使用,追问成本更高。
动态区——11+ 个条件模块与 Section 缓存框架
如果说静态区是“所有员工共享的基本守则”,那动态区就是“针对每个岗位的个性化指引”。动态区的每个模块在首次计算后被缓存,直到 /clear 或 /compact 才重置。

如上图所示,动态区模块按重要级 P0→P3 排列。P0 的三个模块(session_guidance、memory、mcp_instructions)几乎每次会话都会激活;P3 的模块只在特定条件下生效。每个模块都通过 Section 缓存框架包装:
先看缓存框架。动态区的每个模块都用 systemPromptSection() 或 DANGEROUS_uncachedSystemPromptSection() 包装,这两个函数来自 src/constants/systemPromptSections.ts(仅 69 行):
// src/constants/systemPromptSections.ts
// 创建一个带缓存的 section —— 计算一次,缓存到 /clear 或 /compact
export function systemPromptSection(name: string, compute: ComputeFn): SystemPromptSection {
return { name, compute, cacheBreak: false }
}
// 创建一个不缓存的 section —— 每 turn 重算,会破坏 prompt cache
export function DANGEROUS_uncachedSystemPromptSection(
name: string, compute: ComputeFn, _reason: string
): SystemPromptSection {
return { name, compute, cacheBreak: true }
}
解析时(resolveSystemPromptSections()),逻辑很简单:
// L43-58(简化)
export async function resolveSystemPromptSections(sections) {
const cache = getSystemPromptSectionCache()
return Promise.all(sections.map(async s => {
if (!s.cacheBreak && cache.has(s.name)) {
return cache.get(s.name) ?? null // 命中缓存,直接返回
}
const value = await s.compute() // 未命中,调用 compute()
setSystemPromptSectionCacheEntry(s.name, value)
return value
}))
}
| 方法 | 缓存策略 | 何时重算 | 对缓存的影响 |
|---|---|---|---|
systemPromptSection() |
计算一次,缓存到 /clear 或 /compact |
会话重置时 | 不影响缓存 |
DANGEROUS_uncachedSystemPromptSection() |
每 turn 重算 | 每次 API 调用前 | 可能破坏 prompt cache |
有了缓存框架的认知,现在逐个看动态区的模块:
| 模块 | 重要级 | 缓存类型 | 核心职责 | 关联模块 |
|---|---|---|---|---|
| session_guidance | P0 | memoized | 基于工具集生成使用策略(Agent / Explore / Skill / Verification) | 工具与扩展系统 |
| memory | P0 | memoized | 加载 ~/.claude/memory/*.md,跨会话持久知识 |
上下文系统 > 会话记忆管理 |
| mcp_instructions | P0 | DANGEROUS_uncached | MCP Server 使用说明 | 工具与扩展系统 > MCP 协议实现 |
| env_info_simple | P1 | memoized | 环境信息(CWD / 平台 / Shell / 模型名 / 知识截止日期) | 无 |
| output_style | P1 | memoized | 自定义输出风格 | 无 |
| frc | P1 | memoized | 告知模型旧工具结果可能被清除 | 上下文系统 > 上下文压缩 |
| summarize_tool_results | P1 | memoized | 提醒模型处理工具结果时记录重要信息 | 上下文系统 > 上下文压缩 |
| language | P2 | memoized | 用户语言偏好 | 无 |
| scratchpad | P2 | memoized | per-session 临时文件目录指引 | 无 |
| token_budget | P2 | memoized | 用户指定 token 目标时激活 | 无 |
| ant_model_override | P2 | memoized | 内部 ant 用户额外指令覆盖 | 无 |
| numeric_length_anchors | P3 | memoized | ant-only,数字化长度锚点(~1.2% 输出 token 减少) | 无 |
| brief | P3 | memoized | 自主代理模式行为指引(Kairos / Proactive) | 无 |
缓存策略的演进:从“破坏缓存”到“保护缓存”
动态区模块的缓存策略并非一成不变——核心思路只有一个:尽量不重算,万不得已才重算。
- session_guidance 是动态区最复杂的模块。内容取决于“这个会话有哪些工具可用”——AgentTool 使用策略(fork vs subagent)、Explore agent 调用时机、Skill 调用指南、Verification agent 协议。因为涉及具体工具列表,不能放静态区,但 memoized 后会话内只算一次。
- mcp_instructions 是目前唯一使用
DANGEROUS_uncached的模块——MCP Server 可能随时连接/断开,必须每 turn 重算。但启用mcp_instructions_delta后,这个 section 返回null,改用附件方式注入增量。MCP 状态稳定时不注入任何内容,缓存完全命中。这是从“破坏缓存”到“保护缓存”的典型演进。

上图展示了 systemPromptSection() 和 DANGEROUS_uncachedSystemPromptSection() 两条路径的区别:前者通过 session 级闭包缓存结果,整个会话只计算一次;后者每 turn 都重新调用工厂函数。绝大多数模块走缓存路径,只有 MCP 指令等少数场景走 uncached 路径。
- token_budget 曾是
DANGEROUS_uncached(每次 budget 翻转触发重算),后来改为memoized——因为措辞用了条件句"When the user specifies...",没有 budget 激活时就是 no-op。这一改节省了约 20K tokens/次的缓存断裂。 - numeric_length_anchors 只对 ant 用户启用,内部 A/B 测试发现数字化锚点(“保持 25 字以内”)比定性描述(“保持简洁”)减少约 1.2% 的输出 token——小优化但跨用户累积效果可观。
上图的 Section 缓存框架是整个缓存策略的基石。下面讲到的优先级链和缓存切分,都建立在 memoized/uncached 的区分之上。
优先级链:System Prompt 的完整决策树
前面看到的 getSystemPrompt() 返回的是“默认”System Prompt。但实际运行中,它只是决策树的一个叶子节点。外层的 buildEffectiveSystemPrompt()(src/utils/systemPrompt.ts L41-123)决定了最终使用哪个 prompt:
| 分支 | 开启条件 | 行为 | 频率 |
|---|---|---|---|
| Override | REPL loop 模式,由内部框架设置 | 直接返回 overrideSystemPrompt,跳过所有默认逻辑 |
极低,内部测试用 |
| Coordinator | Feature gate COORDINATOR_MODE + 环境变量 |
用协调者 prompt 替换默认,用于多 Agent 编排 | 极低,实验功能 |
| Agent + Proactive | 配置了 Agent prompt + 自主代理模式激活 | Default 追加 Agent prompt,保留基础行为指引 | 低,Kairos/Proactive 用户 |
| Agent / Custom | 配置了 Agent prompt 或 Custom prompt | Agent/Custom 替换 Default,完全接管 | 低,自定义 Agent 用户 |
| Default(标准模式) | 以上条件均不满足 | 使用 getSystemPrompt() 的 7+11 模块 |
绝大多数用户 |
Default 分支内部还有两条罕见路径:极简模式(CLAUDE_CODE_SIMPLE 环境变量,只返回一行身份声明)和自主代理精简模式(Proactive / Kairos,跳过静态区组装精简指令集)——绝大多数用户不会遇到。
源码逻辑(简化):
// src/utils/systemPrompt.ts L41-123
export function buildEffectiveSystemPrompt({...}): SystemPrompt {
// 0. Override —— 最高优先级,直接返回
if (overrideSystemPrompt) {
return asSystemPrompt([overrideSystemPrompt])
}
// 1. Coordinator —— 协调者模式替换默认 prompt
if (feature('COORDINATOR_MODE') && isEnvTruthy(process.env.CLAUDE_CODE_COORDINATOR_MODE)) {
return asSystemPrompt([getCoordinatorSystemPrompt(), ...append])
}
// 2. Agent + Proactive —— Agent 追加到 Default 之后
if (agentSystemPrompt && isProactiveActive()) {
return asSystemPrompt([...defaultSystemPrompt, agentSystemPrompt, ...append])
}
// 3. Agent / Custom / Default —— 三选一
return asSystemPrompt([
...(agentSystemPrompt ? [agentSystemPrompt] // Agent 替换 Default
: customSystemPrompt ? [customSystemPrompt] // Custom 替换 Default
: defaultSystemPrompt), // 使用 Default
...append])
}
两个关键设计点:
- Proactive 是追加,标准 Agent 是替换:Proactive 模式下 Agent prompt 追加到 Default 之后,因为自主代理仍需要基础行为指引,只是叠加领域特定指令。标准模式下 Agent 完全接管,用自己的指令体系替代默认的。源码注释:
The proactive default prompt is already lean...and agents add domain-specific behavior on top — same pattern as teammates. - appendSystemPrompt 总是追加(Override 除外),确保额外内容不遗漏。
缓存边界:SYSTEM_PROMPT_DYNAMIC_BOUNDARY
回到 getSystemPrompt() 的返回结构:
return [
// --- 静态区(scope: global) ---
getSimpleIntroSection(outputStyleConfig),
getSimpleSystemSection(),
getSimpleDoingTasksSection(),
getActionsSection(),
getUsingYourToolsSection(enabledTools),
getSimpleToneAndStyleSection(),
getOutputEfficiencySection(),
// === 边界标记 ===
...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []),
// --- 动态区(scope: org) ---
...resolvedDynamicSections,
].filter(s => s !== null)
SYSTEM_PROMPT_DYNAMIC_BOUNDARY 是一个特殊字符串 '__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__'。它不在模型的"人格指令"中——模型看到的是一个被替换后的分隔。它的真正作用是在 splitSysPromptPrefix()(src/utils/api.ts L321-435)中作为缓存切分锚点:
splitSysPromptPrefix()扫描string[],找到边界标记的位置- 边界标记之前的所有元素合并为一个 TextBlock,标记
cache_control: { type: 'ephemeral' },scope 为global - 边界标记之后的所有元素合并为另一个 TextBlock,scope 为
org - 两个 TextBlock 分开发送,API 的 KV cache 就能按不同 scope 缓存
这意味着:静态区可以被全球所有用户共享同一份 KV cache(因为内容完全相同),而动态区只按组织缓存(因为内容因用户/会话而异)。
还有一个条件:shouldUseGlobalCacheScope() 返回 false 时,边界标记不会被插入,所有内容使用同一个 scope。这通常在调试模式下使用。
关联模块:缓存切分的完整实现——
splitSysPromptPrefix()的三种场景、addCacheBreakpoints()的 Messages 缓存断点标记——详见第四章。
SystemContext:追加在 System Prompt 尾部
System Prompt 的主体是模块化组装的指令集,但还有一类信息不适合放在指令里——环境状态。当前 Git 分支、是否有未提交变更、工作目录结构……这些信息每轮都可能变化,但对模型来说更像是“身份背景”而非“对话内容”。

如上图所示,SystemContext 作为环境状态追加在 System Prompt 尾部,与 UserContext(项目知识注入到 Messages)形成互补。两者的设计分工是:SystemContext 回答“你当前在哪”,UserContext 回答“这个项目是什么”。
Claude Code 的做法是把这类信息作为 SystemContext 追加在 System Prompt 尾部(src/utils/api.ts 的 appendSystemContext()),格式是简单的键值对。放 System Prompt 而非 Messages,是因为它的语义是“你当前所处的环境”,不是用户说的话。
与之对应的是 UserContext,它注入到 Messages[0] 的位置,包裹在 <system-reminder> 标签中。两者都叫“Context”,但设计意图完全不同:SystemContext 是环境状态(身份层面),UserContext 是项目知识(对话层面,包含 CLAUDE.md + 日期等)——详见Message 章节。
本章小结
System Prompt 看起来只是一段文本,但背后的工程体系非常精密:
- 三条路径:极简 / 自主代理 / 标准,根据运行模式动态选择
- 静态区 7 模块:对所有用户相同,共享 global KV cache
- 动态区 11+ 模块:通过 Section 缓存框架管理,memoized 或 DANGEROUS_uncached
- 优先级链:Override > Coordinator > Agent(proactive追加) > Custom > Default
- 边界标记:静态区和动态区的缓存切分锚点
- SystemContext:追加在 System Prompt 尾部的环境状态信息
下一章我们进入 Messages——承载对话与隐藏注入的“消息管道”。
Message——承载对话与隐藏注入的“消息管道”
System Prompt 设定了“你是谁”和“你在什么环境里”,Messages 承载“发生了什么”。Messages 是上下文中占比最大的板块(约 60%),也是变化最频繁的部分——每个 turn 都会追加新消息。但 Messages 里不只有用户的键盘输入,还有工具结果、附件展开、系统提醒等大量隐藏注入。
理解 Messages 的关键在于三个问题:
- 为什么内部用 5 种类型,API 只认 2 种? Claude Code 内部需要区分用户输入、工具结果、附件、系统标记、进度展示——但 Anthropic API 只接受
user和assistant两种 role。中间需要一个清洗管道做 5→2 的映射。 - 为什么每条消息内部还有更小的单元? 每条消息的
content不是一段文本,而是一个 Content Part 数组——文本、图片、工具调用、工具结果、思维链,每个都是独立的 Part。tool_use和tool_result通过tool_use_id精确配对,这是 Agent 循环的驱动机制:模型发出tool_use→ 系统执行工具 → 返回tool_result→ 模型继续推理,直到end_turn。 - 除了用户主动输入,还有哪些信息悄悄注入了 Messages? 有两个隐藏注入点:UserContext(CLAUDE.md + 日期,注入到 messages[0])和 Attachments(40+ 种系统自动收集的补充信息,如 IDE 选中的代码、Hook 结果、压缩恢复数据,每 turn 以“信封”形式转为 UserMessage 注入)。它们不来自用户的键盘,但模型每次调用都能看到。
所以这一章的结构是:先看内部 5 种类型和它们的映射关系,再看 Content Part 和清洗管道如何把内部结构转为 API 格式,最后看 UserContext 和 Attachments 这两个隐藏注入点。
内部 5 种类型 vs API 2 种类型

如上图所示,Claude Code 内部维护 5 种消息类型,经过清洗管道后只保留 API 认识的 2 种。其中 UserMessage 和 AssistantMessage 直接映射,AttachmentMessage 中转后映射,SystemMessage 和 ProgressMessage 在管道中被过滤。
| 内部类型 | API 映射 | 是否持久化 | 核心职责 |
|---|---|---|---|
| UserMessage | role: 'user' |
是 | 最忙的类型——用户输入、工具结果、附件、系统提醒 |
| AssistantMessage | role: 'assistant' |
是 | 模型回复——唯一由模型“创造”的类型 |
| AttachmentMessage | 先转为 UserMessage → 再映射 | 是 | 上下文补充信封——不直接发 API |
| SystemMessage | 不发给 API | 是 | 内部状态标记(压缩边界、系统通知) |
| ProgressMessage | 不发给 API | 否 | 工具执行进度——仅 UI 展示 |
UserMessage 是“最忙”的类型,它承载的信息远不止用户的键盘输入:
- 工具执行结果——每个
tool_resultContent Part 都以 UserMessage 形式存在 - 附件转换后的内容——AttachmentMessage 展开后注入为 UserMessage
- 系统提醒——包裹在
<system-reminder>标签中,通过isMeta标记对用户隐藏但模型可见 - 压缩摘要——上下文压缩后的关键信息以 UserMessage 形式恢复到对话中
isMeta 标记是这里的关键设计:它让系统可以向模型传递额外信息(如 CLAUDE.md 内容、Git 状态),而不干扰用户的终端阅读体验——用户不会在终端里看到这些“隐藏消息”。
AssistantMessage 是 Agent 循环的“发动机”。每次模型返回 stop_reason: 'tool_use',系统就执行对应工具、把结果作为 UserMessage 追加、再调用模型——这个循环持续到 end_turn 或达到停止条件。AssistantMessage 的 content 数组中可能包含多个 tool_use Part(模型在一个回复中并行调用多个工具),每个都会触发独立的工具执行。
AttachmentMessage 是中转类型——它通过 attachmentToMessages() 转为 UserMessage 后注入对话,模型永远不会直接看到 AttachmentMessage。40+ 种子类型的展开策略在Attachments 章节展开。
Content Parts 与清洗管道
上面讲了消息的“类型”层面(5→2 映射),现在看消息的“内容”层面——每条消息的 content 是一个 Content Part 数组,每个 Part 是 API 层面最小的信息单元:
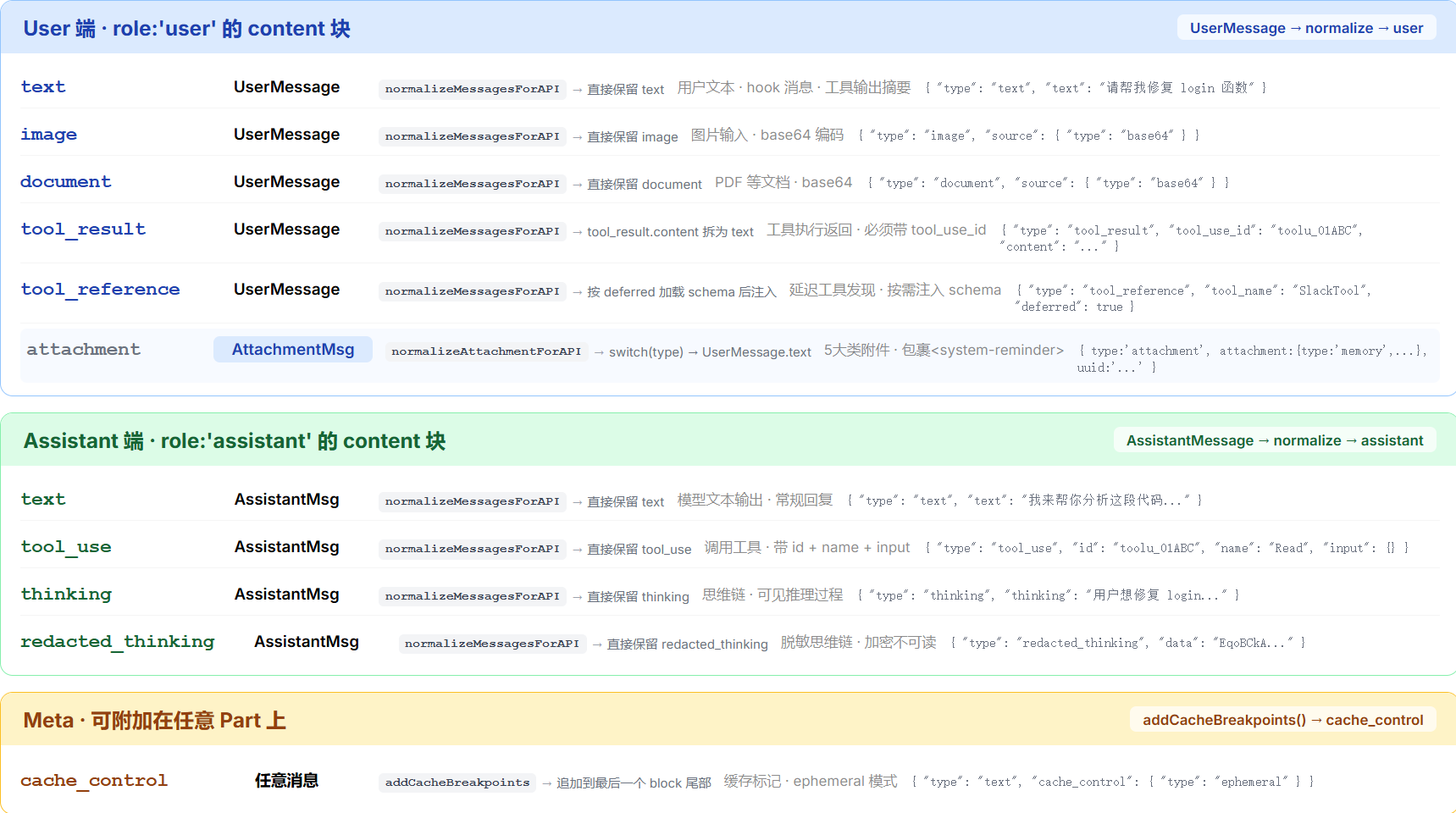
如上图所示,Content Part 分为双向(text)、User→API(image/document/tool_result)、Assistant→API(tool_use/thinking)三个方向。其中 tool_use 和 tool_result 的配对是 Agent 循环的核心驱动机制。
| 类型 | 方向 | 说明 |
|---|---|---|
text |
双向 | 文本内容,最基础的类型 |
image / document |
User → API | 图片和 PDF,base64 编码 |
tool_use |
Assistant → API | 模型决策调用工具,包含 id、name、input |
tool_result |
User → API | 工具执行结果,通过 tool_use_id 与 tool_use 配对 |
thinking / redacted_thinking |
Assistant → API | Extended Thinking 的思维链 |
tool_reference |
User → API | 延迟工具发现——按需加载 MCP 工具 |
tool_use 和 tool_result 的配对是 Agent 循环的核心机制——配对通过 tool_use_id 保证,如果压缩导致配对断开,ensureToolResultPairing() 会自动修复。
这些内部结构(5 种消息类型 × 多种 Content Part)最终都要通过 normalizeMessagesForAPI() 清洗为 API 能理解的格式。这个约 380 行的管道(src/utils/messages.ts L1989-2370)处理以下步骤:
- 过滤:移除 SystemMessage 和 ProgressMessage——它们对 API 没有意义
- 展开:AttachmentMessage 通过
attachmentToMessages()转为 UserMessage - 配对修复:
ensureToolResultPairing()确保每个tool_use后面都有tool_result - 字段清理:移除
tool_reference(延迟加载模式)、advisor相关字段等内部标记 - 不完整消息处理:如果最后一条 AssistantMessage 的
stop_reason是null(模型还没回复完),这条消息不能发给 API - 缓存断点标记:
addCacheBreakpoints()在每条消息的最后一个 Content Block 上附加cache_control
理解这个管道的意义在于:当你遇到“模型为什么看不到某个信息”或“为什么某个工具结果没传给模型”时,可以逐层排查——是过滤了?是配对修复了?还是缓存断点标记有问题?缓存断点标记的完整实现在缓存章节展开。
UserContext:注入到 messages[0] 的隐藏信息
除了用户主动输入的消息,还有一类“隐藏”的 UserMessage——UserContext。prependUserContext()(src/utils/api.ts L449-474)在消息数组最前面注入一条包裹在 <system-reminder> 中的 UserMessage:
// src/utils/api.ts L449-474(简化)
export function prependUserContext(messages, context) {
if (Object.entries(context).length === 0) return messages
return [
createUserMessage({
content: `<system-reminder>
As you answer the user's questions, you can use the following context:
${Object.entries(context).map(([key, value]) => `# ${key}\n${value}`).join('\n')}
IMPORTANT: this context may or may not be relevant to your tasks.
You should not respond to this context unless it is highly relevant to your task.
</system-reminder>`,
isMeta: true, // 对用户隐藏,不显示在终端
}),
...messages,
]
}
UserContext 包含两个关键信息:
claudeMd:CLAUDE.md 文件的内容——用户自定义的项目级指令。Claude Code 自动发现并加载所有 CLAUDE.md(当前目录及上级目录递归搜索)。模型在每个新会话中都能“看到”这些约定。
currentDate:当前日期,如 "Today's date is 2025-04-18."。模型需要知道“今天是哪天”来判断 Git 日志时效性、时间相关的 Bug 等。
注意那句精心设计的提示词:IMPORTANT: this context may or may not be relevant to your tasks. 它防止模型过度依赖 CLAUDE.md——用户问“今天天气怎么样”时,模型不应该引用 CLAUDE.md 里的 TypeScript 约定。
getUserContext() 使用 lodash.memoize 缓存,在 setSystemPromptInjection() 变更时清除。文件内容在会话期间不会变,读一次就够了。
关联模块:UserContext 注入到 Messages 板块(prependUserContext → messages[0]),与之对应的是 SystemContext 追加在 System Prompt 尾部——见第二章 2.6 节。
Attachments:补充信封的展开策略
Attachments 是 Claude Code 最独特的设计之一。它不是直接发给 API 的消息,而是一种“信封”——系统在每个 turn 自动收集各种补充信息,包装为 Attachment,然后通过 attachmentToMessages() 转换为 UserMessage 注入对话。
src/utils/attachments.ts(~4000 行)定义了 40+ 种 Attachment 子类型,分为 5 大类:

| 大类 | 典型子类型 | 触发时机 |
|---|---|---|
| 用户输入触发 | file(@-mention)、selected_lines_in_ide、mcp_resource |
用户操作时 |
| 线程级 | relevant_memories、date_change、diagnostics |
每 turn 自动收集 |
| Hook 相关 | async_hook_response、hook_blocking_error |
Hook 回调时 |
| 压缩恢复 | compact_file_reference、plan_file_reference、task_status |
压缩后自动恢复 |
| 系统/状态 | token_usage、deferred_tools_delta、mcp_instructions_delta |
状态变化时 |
Attachments 的生命周期:

如上图所示,附件从收集到最终发送给 API 经过 5 个阶段。每个阶段都有明确的职责边界——收集器只负责收集,转换器只负责转换,清洗管道只负责清洗。
为什么需要 Attachment 机制而不直接放 System Prompt?
答案在于"变化频率"。System Prompt 相对稳定(每会话只组装一次),但有一类信息是"系统自动收集、每 turn 可能变化"——比如 IDE 选中的代码、Hook 结果、deferred_tools_delta。这些信息变化频率太高,放在 System Prompt 里会破坏 prompt cache。作为附件注入到消息流中,可以保持 System Prompt 的稳定性。
这也解释了 mcp_instructions 的设计演进:原来是 DANGEROUS_uncachedSystemPromptSection()(每 turn 重算,破坏缓存),改为 mcp_instructions_delta 附件后,只在 MCP Server 连接/断开时注入增量,System Prompt 保持稳定。同样的信息,用不同的传递方式,可以带来巨大的成本差异。
关联模块:压缩恢复类附件(
compact_file_reference、task_status等)在 Full Compact 后自动注入——这是压缩系统保证模型不“失忆”的关键,详见后续压缩专题文章。
本章小结
Messages 看起来只是“用户说一句、模型回一句”的简单结构,但内部的工程体系远比表面复杂:
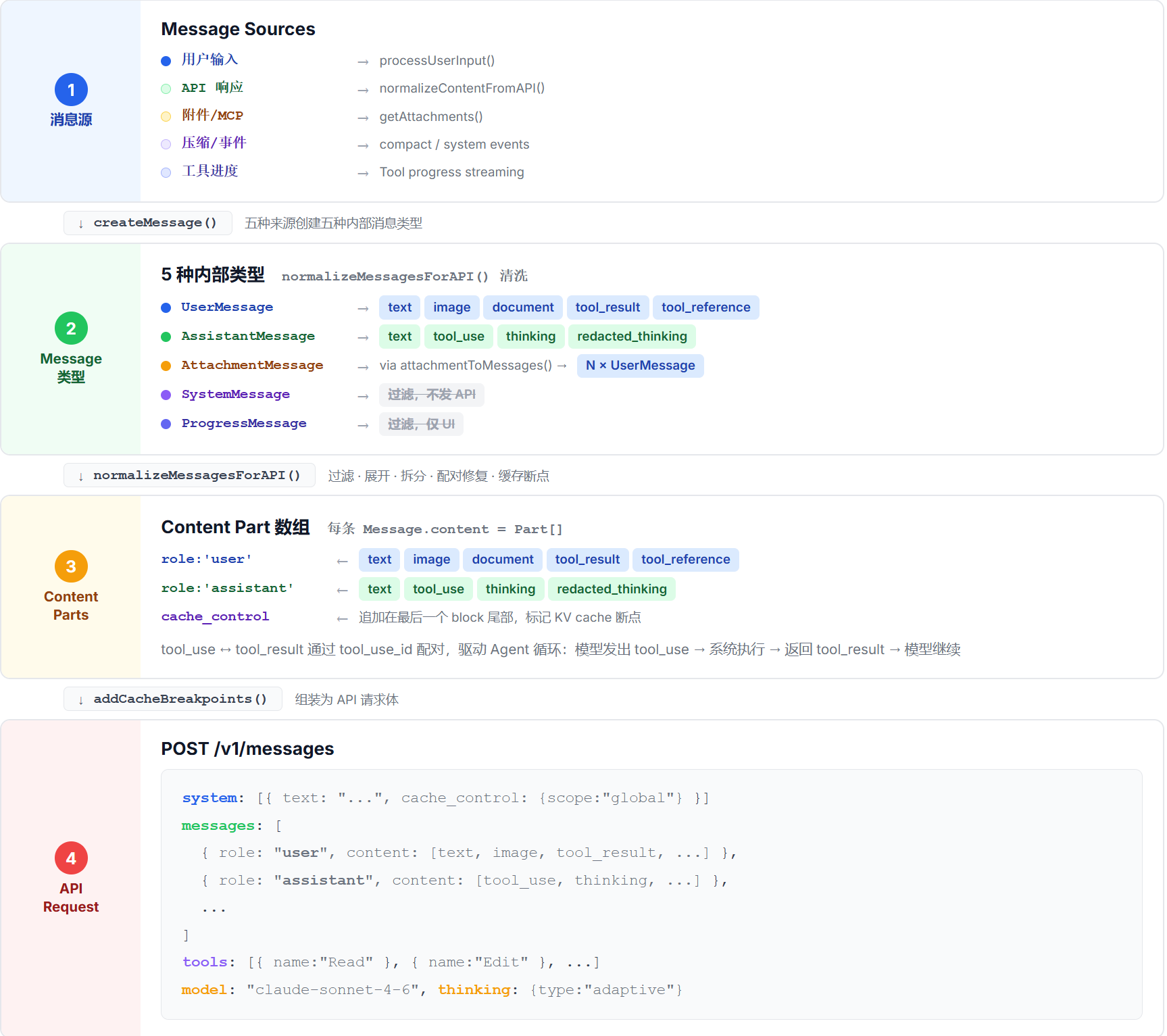
如上图所示,从消息源(用户输入、附件、系统信息)到最终发送给 API 的消息,经过了类型映射、Content Part 组装、清洗管道三个阶段。整个过程中有两个关键设计:变化隔离(附件注入 Messages 而非 System Prompt)和隐藏注入(UserContext 和系统提醒通过 isMeta 对用户隐藏)。
下一章我们进入上下文缓存——这些精心编排的内容如何避免重复计算。
Tools——模型能使用的“工具箱”
前两章拆解了 System Prompt 和 Messages——模型知道了自己是谁、对话发生了什么。但一个只会“说话”的模型什么都做不了:它不能读文件、不能执行命令、不能搜索代码。Tools 就是模型的手和脚,告诉模型“你能做什么”。
Claude API 的每次请求有三个顶层参数:system、messages、tools。Tools 以 JSON Schema 数组的形式传入,每个工具是一个对象,包含名称、描述、参数定义。模型看到 Tools 后,就可以在回复中声明“我要调用某个工具”,客户端执行后将结果返回给模型。
模型实际拿到的单个工具大概长这样:
{
"name": "Read",
"description": "Reads a file from the local filesystem...",
"input_schema": {
"type": "object",
"properties": {
"file_path": { "type": "string", "description": "The path to read" }
},
"required": ["file_path"]
}
}
Claude Code 有 30+ 个这样的内置工具(Read、Edit、Write、Bash、Glob、Grep 等),加上用户通过 MCP 协议接入的外部工具。全量发送可能占用数千 tokens。

如上图所示,内置工具按职责分为几大类:文件操作(Read/Edit/Write)、搜索(Glob/Grep)、执行(Bash)、信息获取(WebFetch/WebSearch)等。Tools 占上下文约 10%,但背后的编排逻辑涉及三个层面:工具从哪来、怎么精简、如何保持稳定。
工具来源与组装链路
Claude Code 的工具池由两部分组成:内置工具(30+ 个,如 Read、Edit、Write、Bash、Glob、Grep)和 MCP 外部工具(用户配置的 MCP Server 提供的工具)。组装过程:
getTools()获取内置工具,根据运行模式(标准/REPL)和权限规则过滤assembleToolPool()合并内置工具 + MCP 工具,按名称去重(内置优先),按字母排序toolToAPISchema()将每个 Tool 对象转为 API 格式的 JSON Schema
排序不是随意的——内置工具排前面、MCP 工具排后面,这个顺序保证了 prompt cache 的稳定性。如果 MCP 工具穿插在内置工具之间,每次 MCP 连接变化都会导致缓存失效。
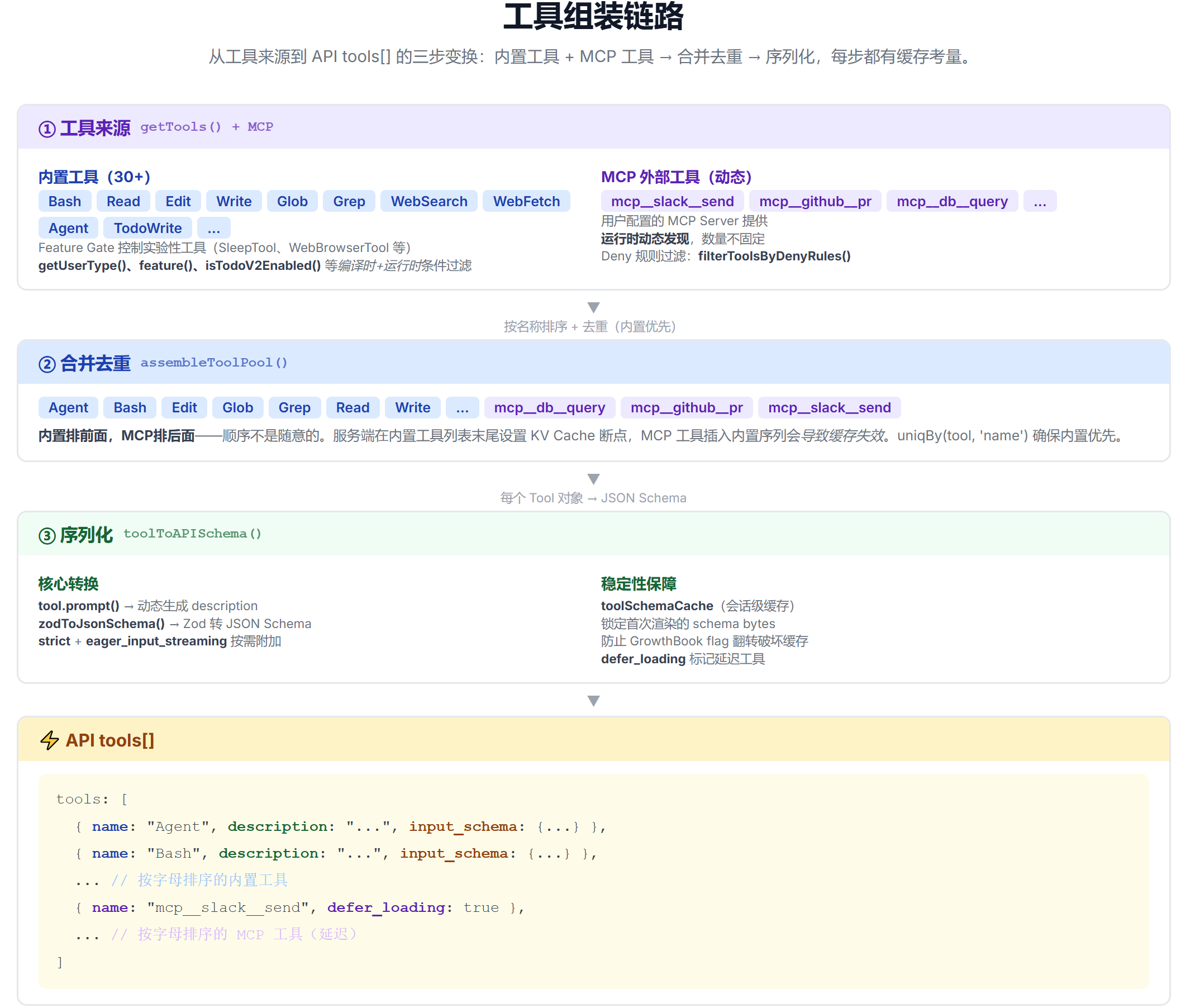
上图展示了从工具池到最终 API 请求的完整链路:内置工具和 MCP 工具分别经过权限过滤后,在 assembleToolPool() 中合并去重,再通过 toolToAPISchema() 转为 JSON Schema。
延迟加载:ToolSearch
工具数量多时(特别是有大量 MCP 工具时),全量传 Schema 会占用大量 token。Claude Code 引入了延迟加载机制:
- 非延迟工具(内置工具):每次调用都发送完整 Schema
- 延迟工具(MCP 工具默认延迟):只发工具名和一行摘要,不展开完整 Schema
- ToolSearchTool:一个特殊的内置工具,模型可以用它按需“搜索并加载”延迟工具
具体流程是这样的:假设用户配置了 Slack MCP,模型第一次调用时看不到 slack_send_message 的完整 Schema,只看到一个名字。当用户说“给我发一条 Slack 消息”时,模型意识到需要 Slack 工具,于是调用 ToolSearch(query: slack),系统返回 slack_send_message 的完整 Schema。从下一轮开始,这个工具就自动包含在完整工具列表中了。
这个设计有一个精妙的缓存考量:延迟工具标记了 defer_loading,API 服务端在计算 prompt cache 时会忽略这些工具的 token——这意味着工具的增减不会影响 System Prompt 的缓存命中。
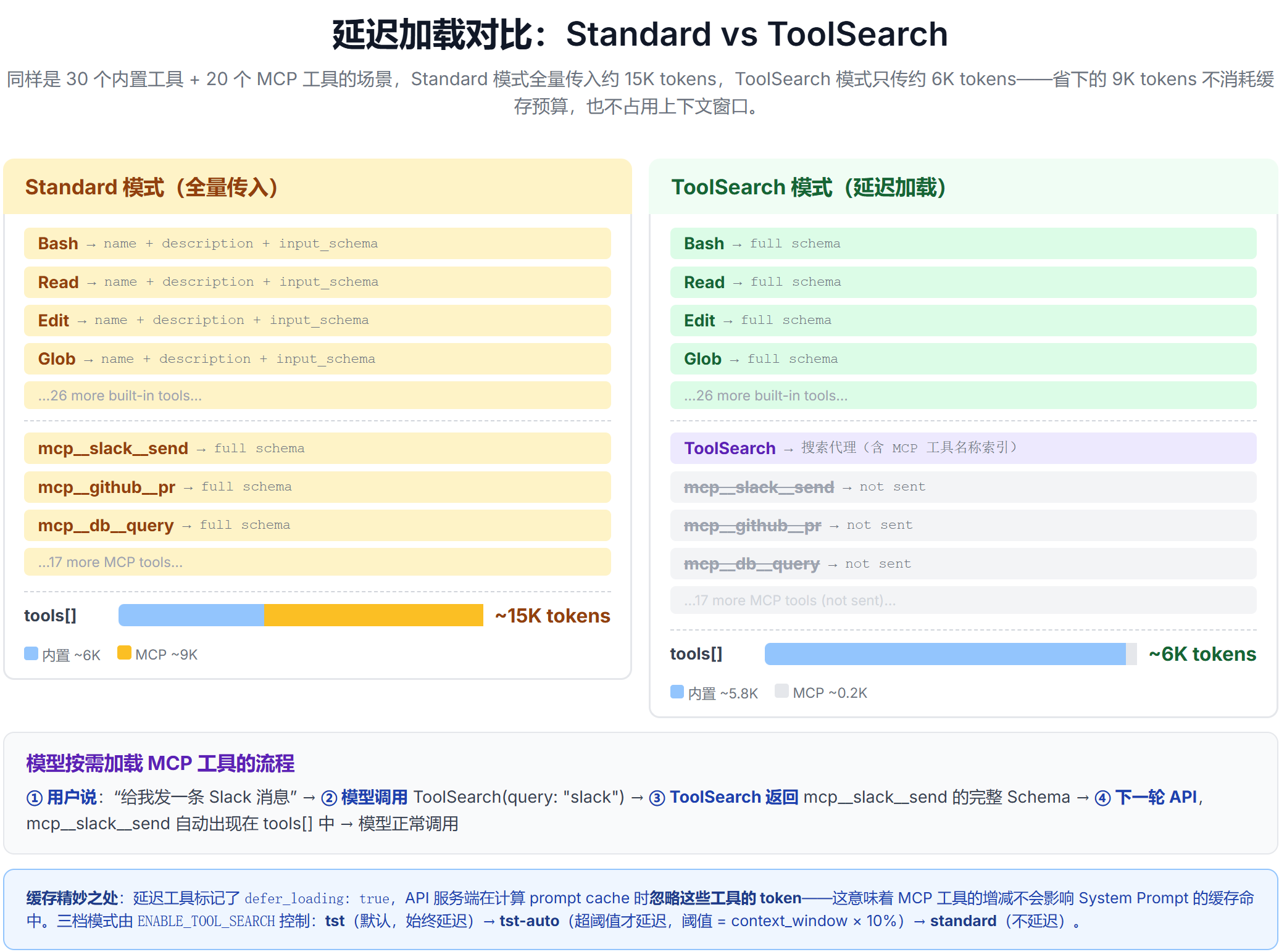
上图对比了延迟加载开启前后的差异:开启后,MCP 工具只占极少的 token(一个名字+一行摘要),而内置工具照常发送完整 Schema。
Schema 缓存
toolToAPISchema() 内部使用会话级缓存(toolSchemaCache,仅 27 行)。工具的 description 生成涉及 GrowthBook feature flag 检查(如 tengu_tool_pear、tengu_fgts),这些 flag 可能会话中途变化。如果每次重新序列化,Schema 的微妙变化会导致缓存失效。通过缓存,整个会话内工具 Schema 保持稳定。
本章小结
Tools 是上下文编排中“最安静”的一块——模型通常不会注意到它的存在,但它决定了模型能力的边界。工具组装的关键设计点:
- 来源合并:内置 + MCP,按名称去重,按字母排序保证缓存稳定
- 延迟加载:MCP 工具默认只报名不展开,通过 ToolSearch 按需加载
- Schema 缓存:会话级锁定,防止 feature flag 变化破坏缓存
- 全局缓存影响:有 MCP 工具时 System Prompt 跳过全局缓存(已在全景图章节提及)
工具的执行、调度、权限管理的完整拆解将在下一篇“工具与扩展系统”中展开。
上下文缓存——让每次调用更省钱
前三章讲了“组装什么”,这一章讲“怎么省着用”。
Prompt Caching 是 Anthropic API 提供的 KV cache 机制:如果连续请求的 prompt 前缀相同,可以跳过前缀的处理,直接从缓存读取。Claude Code 的一个典型 System Prompt 约 10K-15K tokens,一次对话可能有 50-100 个 turn。没有缓存时,每个 turn 都重新处理整个 System Prompt,总成本是 15K × 100 = 150 万 tokens。有了缓存,只有第一个 turn 处理完整 System Prompt,后续 turn 只处理变化部分,成本降到原来的 10-20%。
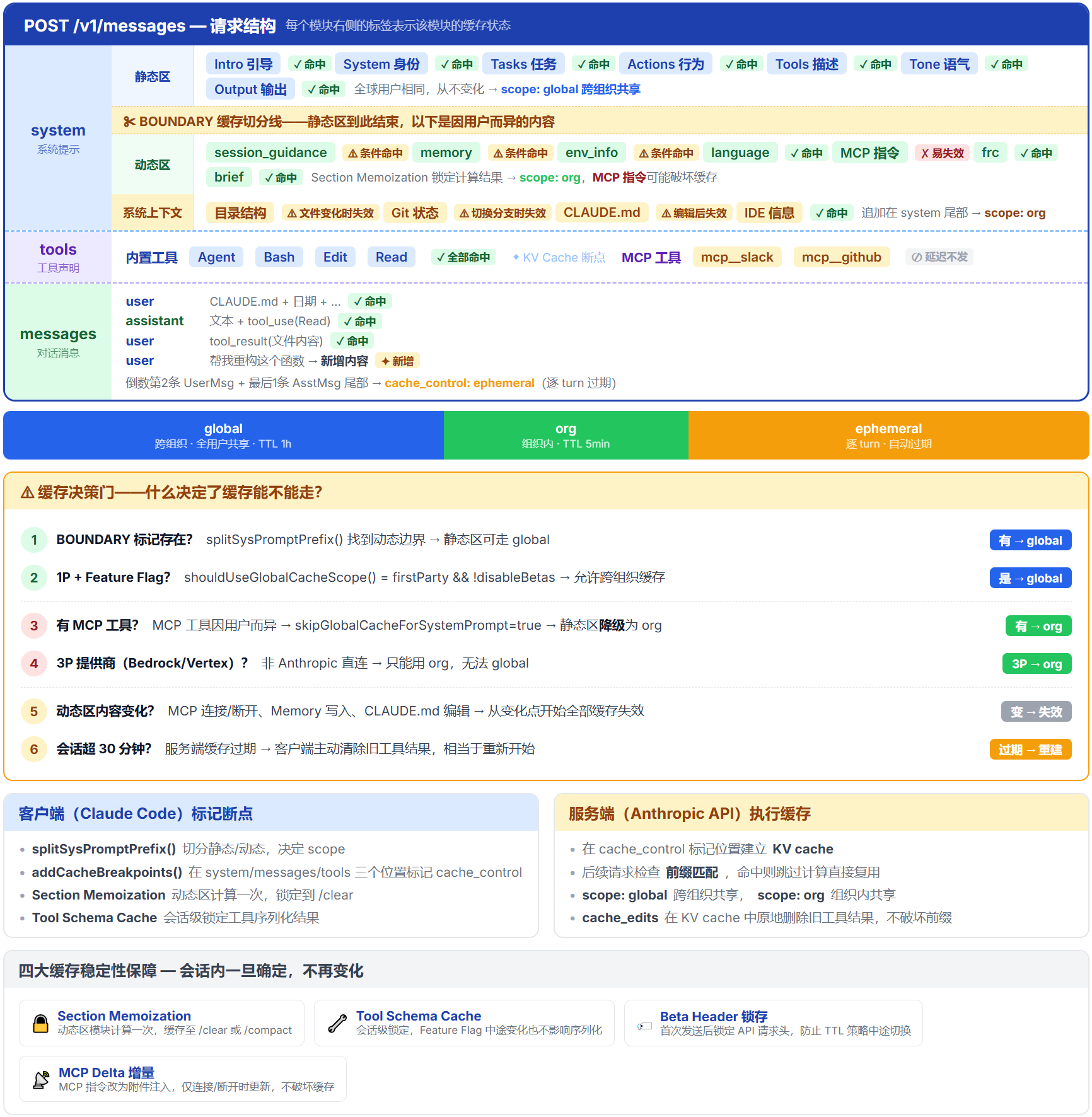
但缓存不是客户端单方面能完成的——它是一个两端协作的工程:客户端负责“在哪里标记缓存断点”,服务端负责“在哪里执行 KV cache 读写”。Claude Code 几乎每一个设计决策都考虑了缓存效率。
这一章拆解三层缓存标记(System Prompt / Messages / Tools)和四大稳定性保障,最后看一个精妙的案例——cache_edits 如何在不修改消息的前提下删除旧工具结果。
缓存解决什么问题?
模型处理 prompt 的方式是:将文本转为 token 序列,每个 token 映射为一个向量,然后逐层计算。如果 prompt 有 10K tokens,每层都要计算 10K 个向量的 attention——这是 O(n²) 复杂度的操作。
KV cache 的核心思想:如果连续请求的 prompt 前缀完全相同,服务端可以缓存前缀的 KV 向量,下次请求直接复用,跳过前缀的处理。缓存命中时,前缀部分不需要重新计算,只需要处理新增的部分。
但有一个关键约束:缓存是“前缀匹配”——一旦前缀发生变化(哪怕一个字符),从变化点开始的所有缓存全部失效。这就是为什么 Claude Code 花了那么多精力来保持前缀稳定。
上图展示了 KV cache 的工作原理:前缀相同时(绿色部分)直接复用缓存的 KV 向量,只计算新增部分(橙色部分)。一旦前缀变化(红色部分),从变化点开始的缓存全部失效,需要重新计算。
客户端标记 + 服务端执行:协作模型
Claude Code 的缓存策略是两端协作:
**客户端(Claude Code)**的职责:
- 决定在哪里放置
cache_control断点 - 保持 prompt 前缀稳定,避免不必要的变更
- 通过 Section Memoization、Schema Cache、Beta Header 锁存等机制保证字节一致性
**服务端(Anthropic API)**的职责:
- 接收带
cache_control标记的请求 - 在标记位置建立 KV cache
- 后续请求检查前缀匹配,命中则复用缓存
客户端的标记策略直接决定了缓存效率。让我拆解 Claude Code 的三层缓存标记。
System Prompt 缓存:global / org / ephemeral
System Prompt 的缓存切分由 splitSysPromptPrefix()(src/utils/api.ts)处理。它的设计目标很明确:尽可能让静态区命中最高级别的缓存共享,同时避免不同用户的动态内容互相干扰。
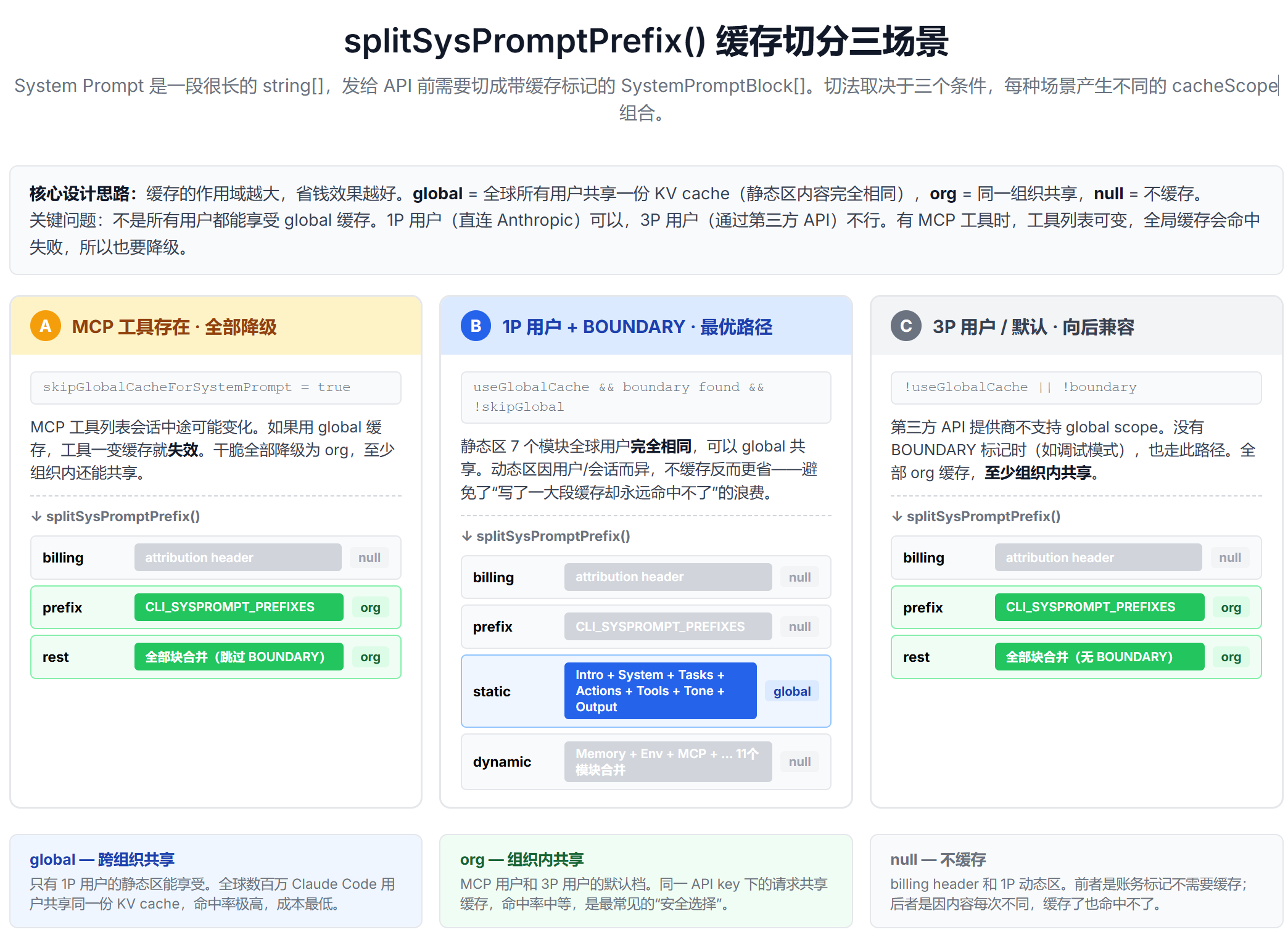
上图展示了三种场景的缓存策略。核心设计思路可以用一句话概括:能共享就共享,不能共享就降级。
场景 1:有 MCP 工具时——全部降级为 org。 不同用户配置的 MCP 工具不同,工具 Schema 会影响 System Prompt 的内容。此时全局缓存不可用(因为用户 A 的缓存里可能有用户 B 看不到的工具),所有内容降级为组织级缓存。
场景 2:无 MCP 工具 + 有 boundary marker——静态区命中 global。 这是最优场景。7 个静态模块对所有用户完全相同,可以跨组织、跨用户共享缓存——你的请求可能复用另一个用户 10 分钟前计算的结果。动态区因会话而异,不做额外缓存。
场景 3:第三方 API 提供商——回退到 org。 Bedrock、Vertex 等平台可能不支持全局缓存,统一用组织级。
这三种场景体现了“缓存策略应该是条件性的,而不是一刀切的”工程原则。
Messages 缓存:每条消息标记一个断点
Messages 的缓存策略更简单:在每条消息上标记一个 ephemeral 断点。 这样当新消息追加时,之前的消息可以从缓存读取——每轮只处理新增的那一条。
听起来简单,但实际的工程挑战在于:消息可能连续出现相同 role(API 要求 user/assistant 交替)、单条消息可能过大(需要拆分以优化缓存粒度)、工具搜索结果需要在正确位置插入。这些都是为了让“每条消息加一个标记”这件简单的事在复杂场景下也能正确工作。
四大缓存稳定性保障
保持前缀稳定是缓存命中的前提。Claude Code 实现了四个机制来保障缓存稳定性:
| 保障机制 | 保护对象 | 核心思路 | 代码位置 |
|---|---|---|---|
| Section Memoization | 动态区模块 | 计算一次,缓存到 /clear 或 /compact |
systemPromptSections.ts |
| Tool Schema Cache | 工具 JSON Schema | 会话级缓存序列化结果,即使 feature flag 中途变化也不影响 | toolSchemaCache.ts(27 行) |
| Beta Header 锁存 | API 请求头 | 首次发送后锁定,防止 TTL 等缓存策略中途切换 | getPromptCache1hAllowlist() |
| MCP Instructions Delta | MCP 使用说明 | 从“每 turn 重算”改为“仅在连接/断开时注入增量” | 附件方式 |
四个机制的核心逻辑一致:会话内一旦确定,不再变化。 每个机制背后都有真实的故障场景——Schema 微妙变化导致缓存失效、Beta header 中途切换导致行为不可预测、MCP 每轮重写浪费 500K tokens。这些不是理论上的风险,而是实际遇到并修复过的问题。
其中 MCP Instructions Delta 的收益最直观:假设 50 个 turn 的会话,只有 2 次 MCP 变化。如果用 DANGEROUS_uncached,50 次重写 × 10K tokens = 500K tokens 浪费;改为 delta 后,只有 2 次注入,成本接近零。
cache_edits:原地删除旧工具结果
这是缓存优化中最精妙的设计。
传统的“微压缩”是在本地删除旧工具结果,但这会修改消息数组,导致 prompt 前缀变化,缓存全部失效。省下的 token 还没补回来,缓存失效增加的成本就已经抵消了收益。
Cached Microcompact 用了一个完全不同的思路:不在本地修改消息,而是通过 API 的 Cache Editing 功能直接在服务端删除。
工作原理:
- Microcompact 检测到旧 tool_result 超过
keepRecent阈值 - 通过
pinCacheEdits()记录需要删除的 tool_use_id addCacheBreakpoints()在构建请求时插入cache_edits指令- 服务端收到请求后,在 KV cache 中原地删除对应的 tool_result
本地消息数组不变,System Prompt 不变,prompt 前缀完全一致——缓存完美命中。“删除”操作在服务端透明完成。
这就像告诉图书管理员“这些页的笔记不用给我看了”——书还是整整齐齐的,翻书速度不受影响。cache_edits 是压缩系统与缓存系统协同的关键接口,压缩的六道防线将在后续文章中展开。
缓存的代价与监控
缓存不是免费的。Claude Code 有时也会主动“放弃”缓存:调试时强制重算、服务端缓存过期后主动清理旧数据、Beta 策略切换时重建。系统还内置了缓存命中率监控——当异常下降时自动记录事件,方便排查“为什么这一轮突然变慢了”。
Compact Cache Reuse
缓存不仅服务于用户对话,还服务于系统内部的 Compact 操作。Compact 需要调用模型生成摘要,它复用主线程的 system prompt 和 tools,确保 prompt 前缀一致——你可以理解为 Compact 操作“借”了主线程的缓存身份,不用从零开始算。
本章小结
上下文缓存的核心是“两端协作”:客户端标记缓存断点,服务端执行 KV cache。三层缓存策略(global/org/ephemeral)+ 四大稳定性保障,确保绝大多数 turn 只处理增量。
当对话越来越长、token 接近上下文窗口限制时,缓存也救不了了——这时 Claude Code 会启动压缩策略。压缩是一个和缓存同等重要的命题,它有自己的六道防线和精妙设计,我们将在下一篇深入拆解。
总结:上下文编排的全景
回到开头提出的四个问题,现在逐一回答:
Q1:模型是怎么“看到”你的对话的?你的项目信息呢?
都不是直接“看到”的。模型对世界的全部认知,来自每次 API 请求里的三块文本:
| 板块 | 占比 | 承载的信息 |
|---|---|---|
| System Prompt | ~30% | 项目规则和身份设定 |
| Messages | ~60% | 对话历史 + 隐藏注入的项目上下文 |
| Tools | ~10% | 可用能力的声明 |
你打的文字在 Messages 里,CLAUDE.md 的项目规则藏在 messages[0],工具能力在 Tools 里——它们被分别塞进三个通道,到了模型那里合成一个完整的世界。
Q2:Claude Code 专业沉稳的“人设”是谁写的?
没有一个人、没有一个文件定义了它。18 个模块(7 静态 + 11+ 动态)按优先级链拼装:Override 可以覆盖、Coordinator 可以追加、Agent 可以替换。你在不同场景下看到的 Claude Code,其实是同一套骨架在不同模块组合下的不同面貌。
更微妙的是,Tools 也在塑造“人设”——模型知道自己有 Read 工具却没有 Send Email 工具时,行为模式自然不同。人格和能力是分开传递的(System Prompt vs Tools),但共同定义了模型的边界。
Q3:你只打了一句话,模型实际收到了多少信息?
远不止你的文字:
- CLAUDE.md 的指令被注入到 messages[0]
- 今天的日期跟着一起塞进去
- 剪贴板图片、IDE 选中代码、错误诊断作为 Attachments 展开
- 消息经过 6 步清洗管道(过滤→展开→配对修复→字段清理→不完整消息→缓存断点),最终只留下 user/assistant 两种类型
你看到的是一句话,模型收到的是一封被层层塞过信件的“信封”。
Q4:同一个项目聊了 50 轮,每一轮的 API 费用都一样吗?
差别可能达 10 倍——但你感觉不到,因为系统在背后做了三层防线:
| 防线 | 策略 | 效果 |
|---|---|---|
| 缓存优先 | 静态区全局缓存 + 动态区 Section 缓存 + 消息级缓存 | 绝大多数 turn 只处理增量 |
| cache_edits 兜底 | 服务端原地删除旧工具结果 | 省 token 不破坏缓存 |
| 压缩兆底 | token 即将超限时压缩对话历史 | 最后手段,保证功能可用 |
让你永远不需要关心 token 在翻倍。
把这四个答案放在一起,整个上下文编排系统的设计可以归纳为三个核心原则:
原则一:分层缓存。从全局缓存(静态区 scope:global)到组织缓存(动态区 scope:org),再到消息级缓存(per-message cache_control),每一层都有明确的缓存策略和失效机制。
原则二:变化隔离。高变化频率的内容(Attachments)和低变化频率的内容(System Prompt)通过不同的通道传递——Attachments 注入 Messages,System Prompt 保持稳定。这避免了高频变化破坏低频内容的缓存。
原则三:缓存优先,压缩兆底。正常情况下通过缓存优化成本;token 即将超限时通过压缩保证功能可用性。cache_edits 是唯一完美解决“压缩与缓存冲突”的策略——本地消息不变,服务端透明删除。
这不是一段 prompt,而是一套系统工程。
系列导航
本文属于 《Claude Code 源码 Deep Dive》 系列,专注于上下文的组成与缓存。
引导篇:Claude Code 源码架构概览:51万行代码的模块地图
后续篇目预告:
- 工具与扩展系统:30+ 工具的注册、调度、权限管理和 MCP 协议的完整链路
- 记忆系统:CLAUDE.md 的加载机制、会话记忆管理、跨会话知识持久化
- 压缩机制:六道防线的完整拆解——从 cache_edits 到 Full Compact
如果这篇文章对你有帮助,欢迎点赞收藏支持一下。如果你对 Claude Code 源码感兴趣,欢迎关注本系列后续更新。有任何想法或疑问,评论区见 👋

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)