【第四十一周】论文复现记录04
文章目录
摘要
本周在进行评估模型的实验,同时阅读了论文《Compress and Cache:Vision Token Compression for Efficient Generation and Retrieval》
Abstract
This week, I conducted experiments to evaluate the model, and also read the paper Compress and Cache: Vision Token Compression for Efficient Generation and Retrieval.
一、评估记录:longbench
1. 评估流程
1,为数据集中的每条文本创建一个独一无二的UID
2,将这些带 UID 的文本,转换成 Glyph 模型能直接“阅读”和评估的图像格式。
3,长文本基准测试的评估,调用一个视觉语言模型(VLM)来对文本或多模态数据进行推理,并生成预测结果,并对结果格式进行处理。
4,评估结果
1.1 数据迁移
当生成UID时,没有修改生成路径,因此数据下载到服务器的系统盘,因此需要对数据进行迁移
方法一: 迁移常规项目文件 (如代码、数据)
将原本“code/Glyph-main”路径下的文件换至“/root/autodl-tmp/”
# 1. 移动项目文件夹到数据盘
mv ~/code/Glyph-main /root/autodl-tmp/
# 2. 创建软链接,让系统“以为”文件还在原处
ln -s /root/autodl-tmp/Glyph-main ~/code/Glyph-main
这样操作后,项目就迁到数据盘了,但通过软链接访问
方法二: 修改环境变量(迁移缓存的模型)
如果你想彻底改变缓存路径,可以通过设置 HF_HOME 环境变量来实现
# 1. 编辑 .bashrc 文件
vim ~/.bashrc
# 2. 在文件末尾添加以下两行
export HF_HOME="迁移后地址"
# 3. 保存后,让配置生效
source ~/.bashrc
方法三:迁移环境
1,设置新的环境默认路径:告诉 Conda,以后新建的环境都放到数据盘。
conda config --add envs_dirs /root/autodl-tmp/conda_envs
conda config --add pkgs_dirs /root/autodl-tmp/conda_pkgs
**注意:**多个 envs_dirs 中,Conda 会优先使用第一个路径。
2,重建并迁移现有环境:假设你需要迁移 Gen_env 这个环境。
# 激活环境,导出依赖清单
conda activate Gen_env
conda env export > environment.yaml
# 停用并删除旧环境
conda deactivate
conda remove -n Gen_env --all
# 在数据盘的新路径下重建环境
conda env create -n Gen_env -f environment.yaml
完成这些操作后,你就可以正常使用迁移后的环境了。
2. 修改推理代码
原本使用http api进行推理,由于部署了本地模型Glyph,因此需要对代码进行处理:
# ---------- 全局模型和处理器 ----------
processor = None
model = None
def load_model(model_path: str):
"""加载本地 Glyph 模型和处理器"""
global processor, model
if processor is None:
processor = AutoProcessor.from_pretrained(model_path)
if model is None:
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto"
)
return processor, model
def local_inference(
prompt: str,
image_paths: Optional[List[str]] = None,
max_pixels: int = 36000000,
max_new_tokens: int = 8192,
) -> Union[str, None]:
"""
使用本地 Glyph 模型进行推理
"""
global processor, model
if processor is None or model is None:
raise RuntimeError("Model not loaded. Call load_model() first.")
# 构建 messages 格式
messages = [{"role": "user", "content": []}]
# 添加图片(如果有)
if image_paths:
for img_path in image_paths:
# 打开图片并缩放(保持与原逻辑一致)
with Image.open(img_path) as pil_img:
pil_img = pil_img.convert("RGB")
w, h = pil_img.size
if w * h > max_pixels:
scale = math.sqrt(max_pixels / (w * h))
new_w, new_h = int(w * scale), int(h * scale)
pil_img = pil_img.resize((new_w, new_h), Image.Resampling.LANCZOS)
messages[0]["content"].append({"type": "image", "image": pil_img})
# 添加文本
messages[0]["content"].append({"type": "text", "text": prompt.strip()})
# 应用模板并生成
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=max_new_tokens)
output_text = processor.decode(
generated_ids[0][inputs["input_ids"].shape[1]:],
skip_special_tokens=False
)
return output_text
def parse_args(args=None):
parser = argparse.ArgumentParser()
parser.add_argument('--e', action='store_true', help="Evaluate on LongBench-E")
parser.add_argument('--use_image', action='store_true', help="Use image processing")
parser.add_argument('--model_path', type=str, default='/root/autodl-tmp/Glyph', help="Local path to Glyph model")
parser.add_argument('--input_dir', type=str, default='/root/autodl-tmp/Data/longbench/rendered_images', help="Input directory for dataset files")
parser.add_argument('--output_dir', type=str, default='/root/autodl-tmp/Data/longbench/pred', help="Output directory for prediction files")
parser.add_argument('--model_name', type=str, default='glyph', help="Model name for creating output subdirectory")
return parser.parse_args(args)
也可以直接使用http形式对模型进行调用,主要修改代码内容如下:
def post_api(
prompt: str,
image_paths: Optional[List[str]] = None,
max_pixels: int = 36000000,
model: str = "glyph", # 给一个默认值
temperature: float = 0.7,
api_url: str = "http://localhost:8000/v1/chat/completions", # 改为本地默认地址
) -> Union[str, None]:
...
payload = {
"model": model, # 改用传入的 model 参数
...
}
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {os.getenv("VLLM_API_KEY", "token-abc123")}' #从环境变量读取或直接写
}
修改后,启动本地 vLLM 服务(假设模型路径 /root/autodl-tmp/Glyph),指令如下:
vllm serve /root/autodl-tmp/Glyph --api-key token-abc123 --port 8000
问题:localhost:8000这个端口是随意指定还是需要根据自己的填写?根据自己的填写需要在哪里查找?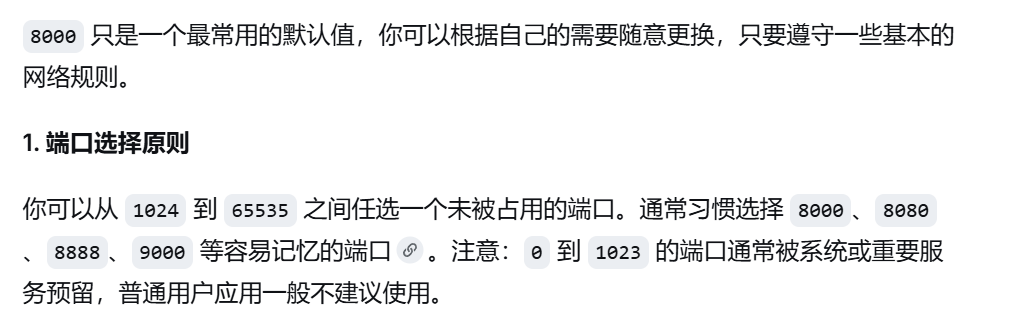
二、《Compress and Cache:Vision Token Compression for Efficient Generation and Retrieval》
1. 摘要
利用 LVLM 自身对视觉 token 进行压缩,采用 “双前向传播” 训练策略:
- 第一遍:LLM 将密集视觉 token 压缩为少量“摘要 token”。
- 第二遍:使用摘要 token 替代原始图像 token 进行语言指令处理。
(引入 对比损失 提升摘要 token 的判别能力)
最后效果:
生成任务:压缩率提升 2 倍,性能不降。
判别任务:在图像检索和组合性基准上达到 SOTA。
2. 相关工作
现有方法问题:
- 多数方法为 on-the-fly 压缩无专用压缩阶段,压缩能力有限。
- 不适用于 检索增强生成(RAG) 场景,无法提前缓存。
- 判别式 LVLM通常牺牲生成能力。
主要贡献
-
提出 C&C 方法:LVLM 自身作为压缩器,采用双前向传播训练策略。
C&C 的创新:
1,离线压缩 + 缓存 范式,适合 RAG 和端侧部署。
2,压缩与生成解耦,支持更复杂的压缩过程。
3,统一表示 同时支持生成与判别任务。 -
统一压缩表示:同时适用于生成和判别任务,支持缓存与重用。
-
引入对比损失:增强摘要 token 的判别能力,同时提升生成性能。
-
性能突破:
1,生成任务:2 倍压缩率,性能不降。
2,判别任务:SOTA 在图像检索和组合性基准。
3,Visual RAG:模型小 3.8 倍,性能优于 VisRAG-Ret。
3. 方法:双前向传播瓶颈算法
3.1 基础模型与符号定义

3.2 具体算法介绍
3.2.1 第一次前向传播(压缩)

3.2.2 第二次前向传播(生成)

3.2.3 设计动机
- LLM 擅长文本摘要 → 推广到“图像摘要”在连续潜空间中进行。
- 压缩表示同时位于 LLM 的输入空间和输出空间,便于后续判别任务。
- 解耦压缩与生成:允许在离线阶段进行更复杂的压缩(如多次迭代),在线阶段只需使用缓存的少量 token。
3.3 判别适配(对比损失)
为什么需要对比损失?
-
仅用自回归损失训练的摘要 token 主要服务于生成任务,判别能力(如检索)较弱。
-
对比损失可以强制摘要 token 在不同图像-文本对之间具有可分离性,提升检索和组合性理解能力。

3.4 推理流程

4. 实验
1,生成任务
2,判别任务(检索 + 组合性)
3,Visual RAG
4,消融实验
总结
C&C 是一种高效的视觉 token 压缩方法,统一支持生成与判别任务,适合离线缓存和 RAG 场景,显著提升 LVLM 的推理效率与存储效率。
局限性:
1,依赖预训练 LVLM,可能继承其偏见。
2,不适合无法离线预处理的场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)