C++ 标准IO流详解
C语言并未将输入/输出功能内置于语言本身。换言之,它没有像read或write这样的关键字。相反,它将输入输出功能交由外部库函数处理(例如stdio库中的printf和scanf)。ANSI C标准将这些输入输出函数称为标准输入输出包(stdio.h)。C++延续了这一做法,并在iostream和fstream等库中对输入输出功能进行了标准化和规范化。
C++IO特性
- C++的输入输出是类型安全的。
- C++的输入输出操作基于字节流,与设备无关。
一、流概述
C/C++的输入输出基于流,即程序中进出的字节序列(如同管道中的水和油流动)。在输入操作中,数据字节从输入源(如键盘、文件、网络或其他程序)流向程序;在输出操作中,数据字节从程序流向输出目标(如控制台、文件、网络或其他程序)。流作为程序与实际I/O设备之间的中介,使得程序员无需直接操作设备,从而实现设备无关的输入输出操作。
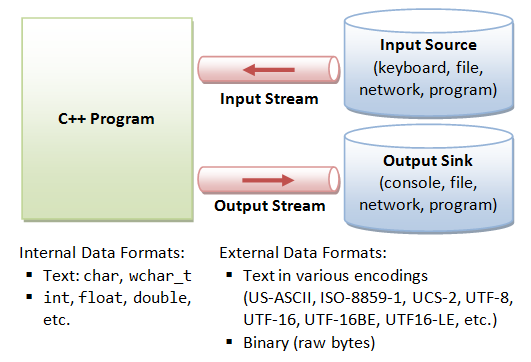
C++ 同时提供了格式化 I/O 和非格式化 I/O 函数。在格式化或高级 I/O 中,字节被分组并转换为特定类型,如 int、double、string 或用户自定义类型。在非格式化或低级 I/O 中,字节被视为原始字节,不进行任何转换。格式化 I/O 操作通过重载流插入运算符(<<)和流提取运算符(>>)来支持,这提供了一致的公共 I/O 接口。非格式化I/O使用类似于C语言的API接口(read(),write()等)实现。
| 特性 | 格式化 I/O (High-Level) | 非格式化 I/O (Low-Level) |
|---|---|---|
| 处理方式 | 字节被分组并转换为 int, double, string 等特定类型 |
字节被视为原始字节序列 (raw bytes),不做转换 |
| 主要操作符/函数 | << (插入符) 和 >> (提取符) |
read(), write(), get(), getline()等 |
| 典型场景 | 标准控制台输入输出、读写配置文件 | 二进制文件读写、网络数据包处理 |
| 优点 | 类型安全、直观便捷、代码简洁 | 效率高、精确控制、无数据转换开销 |
为了执行输入和输出,C++ 程序需要执行以下步骤:
- 构造一个流对象
- 将该流对象关联到一个实际的 I/O 设备(例如键盘、控制台、文件、网络、另一个程序)
- 通过流对象公共接口中定义的函数,以设备无关的方式对流执行输入/输出操作。其中一些函数负责在外部格式和内部格式之间转换数据(格式化 I/O),而另一些则不进行转换(非格式化或二进制 I/O)
- 断开流与实际 I/O 设备的关联(例如关闭文件)
- 释放流对象
二、C++IO类库
1.头文件
C++ 的 I/O 功能在以下头文件中提供:<iostream>(其中包含了 <ios>、<istream>、<ostream>和 <streambuf>)、<fstream>(用于文件 I/O)以及 <sstream>(用于字符串 I/O)。此外,<iomanip> 头文件提供了操纵器,如 setw()、setprecision()、setfill() 和 setbase(),用于格式化。
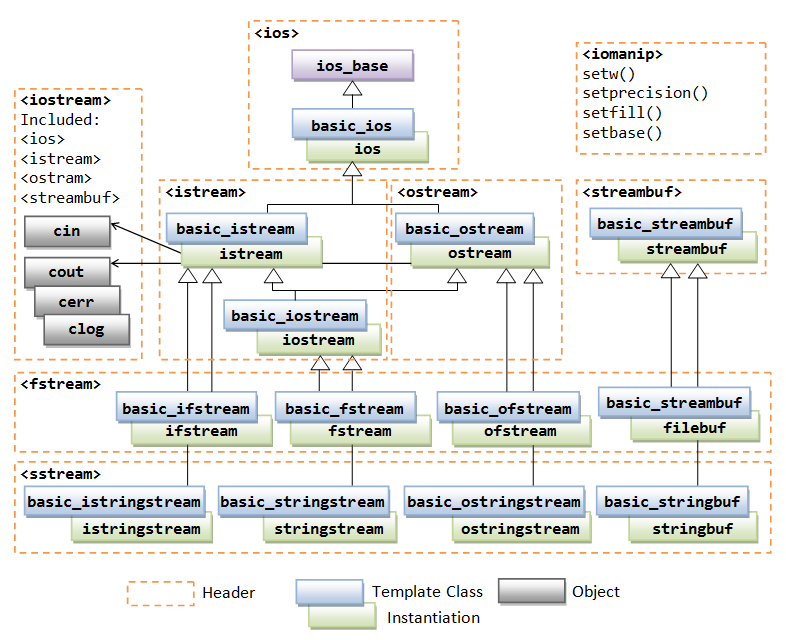
这些 C++ 头文件确实是 I/O 流库的核心组成部分。它们共同构建了一个强大、统一且可扩展的输入输出系统。
简单来说,<iostream>、<fstream> 和 <sstream> 分别负责控制台、文件和字符串三大 I/O 场景,而 <iomanip> 则专门用于精细化控制数据的显示格式。
为了更直观地理解它们的分工,可以参考下面的表格:
| 头文件 | 核心组件 | 主要用途 | 典型操作 |
|---|---|---|---|
<iostream> |
std::cin, std::cout, std::cerr, std::clog |
标准输入输出(控制台、终端) | std::cin >> var;std::cout << "Hello"; |
<fstream> |
std::ifstream, std::ofstream, std::fstream |
文件输入输出(读写磁盘文件) | std::ifstream in("data.txt");in >> value; |
<sstream> |
std::istringstream, std::ostringstream, std::stringstream |
字符串流(内存中的格式化转换) | std::ostringstream oss;oss << "Age: " << 25; |
<iomanip> |
std::setw(), std::setprecision(), std::setfill(), std::setbase() |
格式化输出(控制宽度、精度、填充字符、进制) | std::cout << std::setw(10) << std::setfill('*') << 42; |
设计理念:分层与复用
值得一提的是,<iostream> 本身并不是一个庞大的单体,它内部包含了 <ios>、<istream>、<ostream> 和 <streambuf>,这种设计体现了职责分离的思想:
<ios>定义了所有流共有的状态和类型。<istream>和<ostream>定义了输入和输出的核心逻辑。<streambuf>则作为底层接口,负责与实际的字符来源或目的地(如键盘、文件)打交道。
这种分层结构让开发者能够灵活地组合和扩展,比如通过继承 std::streambuf 就能创建支持自定义设备(如网络流)的 I/O 流。
2.模板类
核心思想是:避免为每种字符类型重复编写代码,而是用模板生成。为了支持各种字符集(C++98/03 中的 char 和 wchar_t;以及 C++11 引入的 char16_t、char32_t),流类被设计为模板类,可以使用实际的字符类型进行实例化。大多数模板类接受两个类型参数。例如:
template <class charT, class traits = char_traits<charT> >
class basic_istream;
template <class charT, class traits = char_traits<charT> >
class basic_ostream;其中:
charT是字符类型,例如char或wchar_t;traits是另一个模板类char_traits<charT>的实例,定义了字符操作的属性,例如字符集的排序顺序(排列序列)。
char_traits<charT> 是一个模板类,它封装了与字符类型相关的基本操作,例如:
| 操作 | 说明 |
|---|---|
eq(c1, c2) |
判断两个字符是否相等 |
lt(c1, c2) |
判断字符顺序(用于排序) |
length(s) |
获取字符串长度 |
copy(dst, src, n) |
复制字符序列 |
find(s, n, c) |
在字符串中查找字符 |
eof() |
返回文件结束标记 |
通过 traits 参数,basic_istream 不需要关心字符比较、复制等细节,只要调用 traits::eq() 即可。不同的字符类型可以拥有不同的 char_traits 特化。
(1)模板实例化与 typedef
如前所述,basic_xxx 模板类可以使用字符类型(如 char 和 wchar_t)进行实例化。C++ 进一步提供了 typedef 语句来为这些类命名:
typedef basic_ios<char> ios;
typedef basic_ios<wchar_t> wios;
typedef basic_istream<char> istream;
typedef basic_istream<wchar_t> wistream;
typedef basic_ostream<char> ostream;
typedef basic_ostream<wchar_t> wostream;
typedef basic_iostream<char> iostream;
typedef basic_iostream<wchar_t> wiostream;
typedef basic_streambuf<char> streambuf;
typedef basic_streambuf<wchar_t> wstreambuf;直接写 basic_istream<char> 太繁琐了,所以标准库提供了常见的类型别名:
| 原始模板实例化 | 类型别名 | 说明 |
|---|---|---|
basic_istream<char> |
istream |
普通字符输入流(最常用) |
basic_istream<wchar_t> |
wistream |
宽字符输入流 |
basic_ostream<char> |
ostream |
普通字符输出流 |
basic_ostream<wchar_t> |
wostream |
宽字符输出流 |
basic_iostream<char> |
iostream |
双向流(即可读又可写) |
basic_streambuf<char> |
streambuf |
流缓冲区基类 |
你平时写的 cin、cout 实际上就是 istream 和 ostream 类型的对象。
(2)char 类型的特化类
我们将重点关注 char 类型的特化类:
ios_base和ios:用于维护公共流属性的超类,如格式标志、字段宽度、精度和区域设置。超类ios_base(非模板类)维护与模板参数无关的数据;而子类ios(basic_ios<char>的实例化)维护与模板参数相关的数据。istream(basic_istream<char>)和ostream(basic_ostream<char>):提供输入和输出的公共接口。iostream(basic_iostream<char>):istream和ostream的子类,支持双向输入输出操作。请注意,istream和ostream是单向流;而iostream是双向流。basic_iostream模板和iostream类在<istream>头文件中声明,而不是在<iostream>头文件中。ifstream、ofstream和fstream:用于文件输入、输出和双向输入输出。istringstream、ostringstream和stringstream:用于字符串缓冲区的输入、输出和双向输入输出。streambuf、filebuf和stringbuf:为流、文件流和字符串流提供内存缓冲区,并提供访问和管理缓冲区的公共接口。
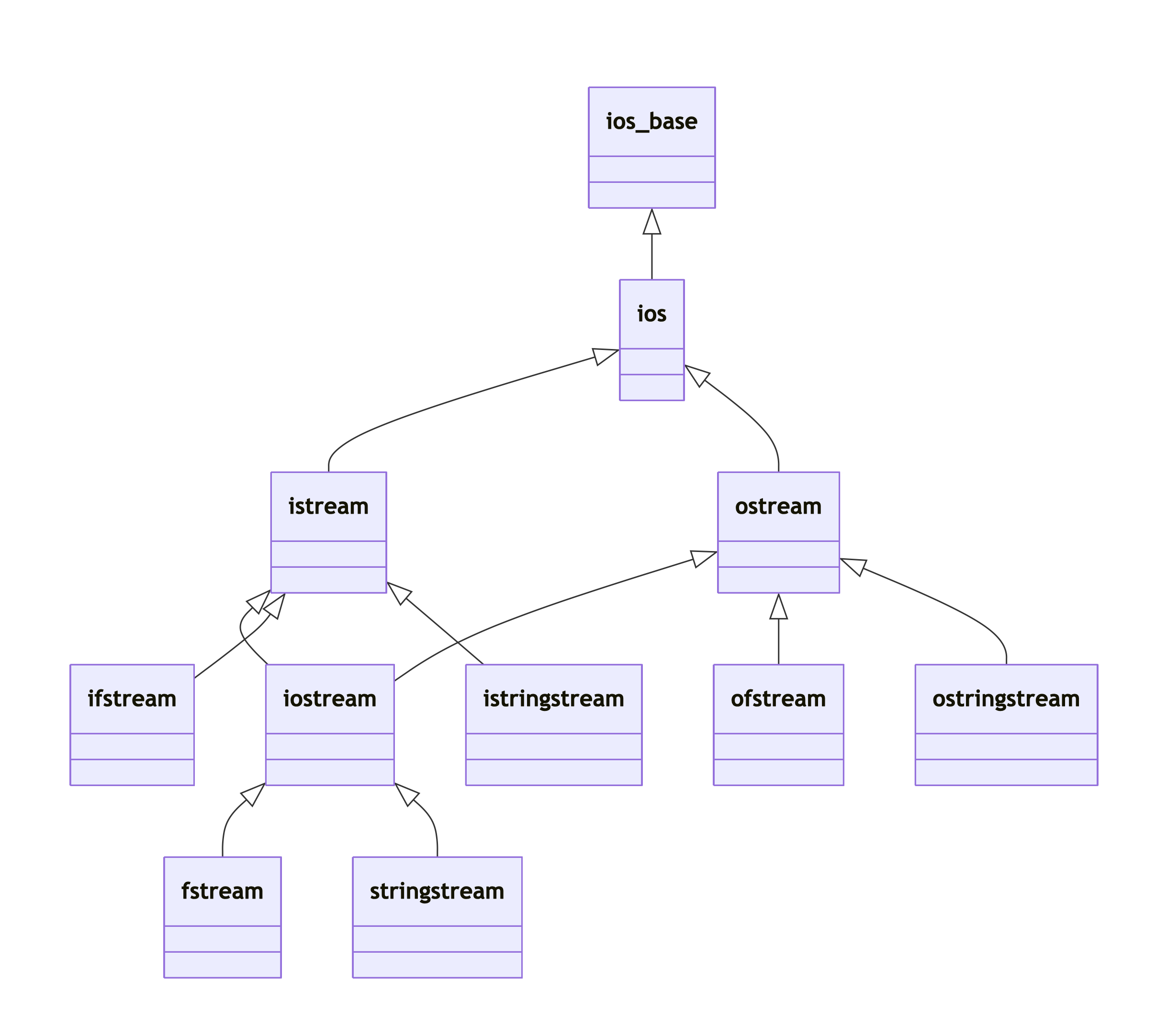
| 类名 | 职责 |
|---|---|
ios_base |
非模板基类,维护与字符类型无关的状态(如格式标志、字段宽度、精度、区域设置) |
ios |
basic_ios<char> 的别名,维护与 char 相关的状态 |
istream / ostream |
单方向输入/输出的公共接口(最常用) |
iostream |
双向流(继承自 istream 和 ostream),支持读写 |
ifstream / ofstream / fstream |
文件流(输入、输出、双向) |
istringstream / ostringstream / stringstream |
字符串流(在内存中的 string 上做 I/O) |
streambuf / filebuf / stringbuf |
缓冲区管理类,提供底层的内存或文件操作接口 |
一个容易被忽略的点:
basic_iostream和iostream虽然名字看起来像是iostream头文件中的内容,但它们实际上是在<istream>头文件中声明的(因为iostream同时依赖输入和输出,而输入的核心定义在<istream>中)。
三、Buffered IO
Buffered I/O(缓冲I/O) 是 C++ 标准库中 I/O 流系统的核心设计理念。它的基本思想是:在内存中维护一个缓冲区,批量地进行数据读写,而不是每次操作都直接访问底层设备(如磁盘、控制台、网络)。
直接操作底层 I/O 设备是非常昂贵的:
| 操作类型 | 代价 | 示例 |
|---|---|---|
| 直接 I/O | 很高 | 每次 read()/write() 都触发系统调用 |
| 缓冲 I/O | 较低 | 累积一定数据后,只触发少数系统调用 |
1.核心组件:streambuf
C++ 中缓冲机制的核心类是 std::streambuf。它负责:
- 管理缓冲区:维护一组指针(读/写缓冲区的位置)
- 填充缓冲区:从实际设备读取数据到缓冲区
- 刷新缓冲区:将缓冲区数据写入实际设备
// streambuf 维护的关键指针(示意图)
class streambuf {
char* pbase(); // 缓冲区起始位置
char* pptr(); // 写指针当前位置
char* epptr(); // 写缓冲区末尾
char* eback(); // 读缓冲区起始
char* gptr(); // 读指针当前位置
char* egptr(); // 读缓冲区末尾
};2.三种常用的 streambuf 派生类
| 派生类 | 用途 | 缓冲区位置 |
|---|---|---|
std::filebuf |
文件 I/O 缓冲 | 内存中的文件缓冲区 |
std::stringbuf |
字符串 I/O 缓冲 | std::string 对象 |
std::basic_streambuf |
自定义设备缓冲 | 由用户定义(如网络流) |
3.缓冲区刷新时机
| 触发条件 | 说明 |
|---|---|
| 缓冲区满 | 自动刷新 |
显式调用 flush() |
std::cout.flush(); |
输出 std::endl |
插入换行符 + 刷新 |
| 对象析构 | 流对象销毁时自动刷新 |
同步设置 std::unitbuf |
每次输出后立即刷新 |
| 输入操作请求 | 从输入流读取时可能刷新输出缓冲区 |
4.三种缓冲模式
C++ 流支持三种缓冲策略(通过 std::ios_base::sync_with_stdio 和相关设置):
| 模式 | 说明 | 典型流 |
|---|---|---|
| 全缓冲 | 缓冲区满才刷新 | 文件流(ofstream) |
| 行缓冲 | 遇到换行符刷新 | 终端输出(cout 通常为行缓冲) |
| 无缓冲 | 立即刷新 | 错误流(cerr) |
四、<iostream>简介
<iostream> 头文件还包含了以下头文件:<ios>、<istream>、<ostream> 和 <streambuf>。因此,你的程序只需要包含 <iostream> 头文件即可进行 I/O 操作。
一个常见的误解:很多人以为
<iostream>是 C++ I/O 的全部。实际上,真正的核心类(如basic_istream)定义在<istream>中,而<iostream>只是将这些组件组合在一起,并声明了全局对象。
<iostream> 头文件声明了以下标准流对象:
cin(istream类的对象,即basic_istream<char>的特化)、wcin(wistream类的对象,即basic_istream<wchar_t>的特化):对应标准输入流,默认关联到键盘。cout(ostream类的对象)、wcout(wostream类的对象):对应标准输出流,默认关联到显示控制台。cerr(ostream类的对象)、wcerr(wostream类的对象):对应标准错误流,默认关联到显示控制台。clog(ostream类的对象)、wclog(wostream类的对象):对应标准日志流,默认关联到显示控制台。
| 对象名 | 宽字符版本 | 类型 | 默认设备 | 典型用途 |
|---|---|---|---|---|
cin |
wcin |
istream |
键盘 | 程序输入 |
cout |
wcout |
ostream |
控制台 | 常规输出 |
cerr |
wcerr |
ostream |
控制台 | 立即输出错误信息(无缓冲) |
clog |
wclog |
ostream |
控制台 | 记录日志信息(有缓冲) |
理解这四个标准流对象,是掌握 C++ I/O 的起点。它们的设计体现了 C++ 的几个核心思想:类型安全(通过运算符重载)、设备无关性(可重定向)、以及国际化支持(窄/宽字符双版本)。
1. 关键区别:cerr vs clog
这是很多开发者容易混淆的地方:
| 特性 | cerr |
clog |
|---|---|---|
| 缓冲 | 无缓冲 | 有缓冲 |
| 刷新时机 | 每次输出立即刷新 | 缓冲区满或显式刷新 |
| 用途 | 紧急错误信息 | 普通日志/调试信息 |
| 性能 | 较慢(每次系统调用) | 较快(批量输出) |
#include <iostream>
#include <thread>
#include <chrono>
int main() {
std::cerr << "错误:立即显示" << std::endl;
std::clog << "日志:可能稍后才显示" << std::endl;
// clog 的输出可能会留在缓冲区中,直到程序结束或缓冲区满
}2. 字符集支持:窄字符 vs 宽字符
| 类型 | 字符类型 | 典型使用场景 |
|---|---|---|
窄字符版本(cin、cout 等) |
char |
英文、ASCII 文本 |
宽字符版本(wcin、wcout 等) |
wchar_t |
国际化文本、中文等 Unicode |
#include <iostream>
#include <locale>
int main() {
// 设置全局 locale 为中文环境
std::locale::global(std::locale("zh_CN.UTF-8"));
// 宽字符输出
wchar_t chinese[] = L"你好,世界!";
std::wcout << chinese << std::endl;
// 窄字符输出(英文)
std::cout << "Hello, World!" << std::endl;
return 0;
}3. 流的可重定向性
虽然 cout、cerr、clog 默认都输出到控制台,但你可以将它们重定向到不同的目标:
#include <iostream>
#include <fstream>
int main() {
std::ofstream logFile("log.txt");
// 将 clog 重定向到文件
std::clog.rdbuf(logFile.rdbuf());
std::clog << "这条日志会写入文件,而不是控制台" << std::endl;
// cout 仍然输出到控制台
std::cout << "这条输出到控制台" << std::endl;
return 0;
}4. 一个容易被忽略的细节:cerr 与 cout 的同步
cerr 和 cout 默认是关联的(tie在一起)。这意味着:
std::cout << "Hello";
std::cerr << "World";
// 即使没有换行,cerr 的输出可能会在 cout 之前出现
// 因为 cerr 的无缓冲特性可能导致输出顺序交错如果想保证顺序,可以显式刷新:
std::cout << "Hello" << std::flush;
std::cerr << "World";五、流插入与提取 运算符
格式化输出通过流插入运算符 << 和流提取运算符 >> 在流上执行。例如:
cout << value; // 将 value 发送到 cout(输出)
cin >> variable; // 从 cin 读取数据到 variable(输入)请注意,cin/cout 必须是左操作数,数据流动方向与箭头方向一致。
<< 和 >> 运算符被重载以处理基本类型(如 int、double)和类类型(如 string)。你也可以为自定义类型重载这些运算符。
cin << 和 cout >> 返回对 cin 和 cout 的引用,因此支持级联操作。例如:
cout << value1 << value2 << .... ; // 连续输出多个值
cin >> variable1 >> variable2 .... ; // 连续输入多个变量 这是C++ I/O 中最核心、最常用的两个运算符:<< 和 >>。它们的设计体现了 C++ 运算符重载的优雅之处。
1. 方向记忆技巧
| 运算符 | 名称 | 数据流向 | 记忆方法 |
|---|---|---|---|
<< |
流插入 | 数据 → 流 | 箭头指向流对象(如 cout) |
>> |
流提取 | 流 → 变量 | 箭头指向变量 |
直观理解:
cout << x:把x插入到输出流中 → 数据流出程序cin >> x:从输入流中提取数据到x→ 数据流入程序
2.为什么箭头方向是这样的
<< 和 >> 原本是 C++ 的左移和右移位运算符。Bjarne Stroustrup(C++ 之父)选择重载它们作为 I/O 运算符,是因为:
cout << x看起来像把x向左推向cout→ 直观- 运算符优先级和结合性也适合级联操作
3.级联操作的原理
cout << a << b << c;上述代码实际上被解析为:
((cout << a) << b) << c;cout << a返回cout的引用- 然后
(cout) << b继续操作 - 以此类推
这就是为什么可以无限级联的原因。
4.为自定义类型重载 << 和 >>
你可以让自己的类也支持流 I/O:
#include <iostream>
#include <string>
class Person {
private:
std::string name;
int age;
public:
// 构造函数
Person(const std::string& n = "", int a = 0) : name(n), age(a) {}
// 友元声明:重载输出运算符
friend std::ostream& operator<<(std::ostream& os, const Person& p);
// 友元声明:重载输入运算符
friend std::istream& operator>>(std::istream& is, Person& p);
};
// 输出运算符实现
std::ostream& operator<<(std::ostream& os, const Person& p) {
os << "Person{name: " << p.name << ", age: " << p.age << "}";
return os; // 返回流引用以支持级联
}
// 输入运算符实现
std::istream& operator>>(std::istream& is, Person& p) {
std::cout << "Enter name: ";
is >> p.name;
std::cout << "Enter age: ";
is >> p.age;
return is; // 返回流引用以支持级联
}
int main() {
Person p1("Alice", 25);
std::cout << p1 << std::endl; // 输出: Person{name: Alice, age: 25}
Person p2;
std::cin >> p2; // 输入: Alice 25
std::cout << p2 << std::endl;
return 0;
}关键要点:
- 必须返回流对象的引用(
std::ostream&或std::istream&) - 通常声明为友元函数(非成员函数),因为左操作数是流对象,不是你的类对象
- 输入运算符需要修改对象,所以参数是非 const 引用
5.endl 的配合使用
cout << "Hello" << endl; // endl 插入换行符并刷新缓冲区
cout << "World\n"; // \n 只插入换行符,不刷新缓冲区endl 在调试时很有用(确保输出立即显示),但会降低性能。生产代码中,优先使用 \n。
7. 输入运算符的链式输入
int a, b, c;
cin >> a >> b >> c;
// 等价于
// (cin >> a) >> b) >> c
// 用户输入: 10 20 30输入时,空格、Tab、换行符都作为分隔符。
六、ostream 类
ostream 类是 basic_ostream<char> 的 typedef。它包含两组输出函数:格式化输出和非格式化输出。
- 格式化输出函数(通过重载的流插入运算符
<<)将数值(如int、double)从其内部表示形式(例如 16/32 位int、64 位double)转换为表示该数值文本形式的字符流。 - 非格式化输出函数(如
put()、write())按原样输出字节,不进行格式转换。
| 类型 | 函数 | 数据转换 | 典型用途 |
|---|---|---|---|
| 格式化输出 | << |
二进制 → 文本 | 打印用户可读的文本、数字 |
| 非格式化输出 | put()、write() |
无转换 | 二进制文件写入、原始字节传输 |
#include <iostream>
int main() {
int num = 65;
// 格式化输出:将 65 转换为字符 '6','5'
std::cout << num << std::endl; // 输出: 65
// 非格式化输出:直接输出字节值
std::cout.put(65); // 输出: A (ASCII 65)
std::cout.write((char*)&num, sizeof(num)); // 输出二进制表示(可能不是可读字符)
return 0;
}1.重载的流插入运算符 << 进行格式化输出
ostream 类为每个 C++ 基本类型重载了流插入运算符 <<:char、unsigned char、signed char、short、unsigned short、int、unsigned int、long、unsigned long、long long(C++11)、unsigned long long(C++11)、float、double 和 long double。它将数值从内部表示形式转换为文本形式。
// 整数类型
ostream& operator<<(int val);
ostream& operator<<(long val);
ostream& operator<<(long long val);
ostream& operator<<(unsigned int val);
// ... 等等
// 浮点类型
ostream& operator<<(float val);
ostream& operator<<(double val);
ostream& operator<<(long double val);
// 字符和字符串
ostream& operator<<(char ch);
ostream& operator<<(const char* str);
// 指针
ostream& operator<<(void* ptr);<< 运算符返回对调用它的 ostream 对象的引用。因此,你可以级联 << 操作,例如:
cout << 123 << 1.13 << endl;<< 运算符还为以下指针类型重载:
const char*、const signed char*、const unsigned char*:用于输出 C 字符串和字面量。它使用空终止字符来判断字符数组的结尾。void*:可用于输出地址。
例如:
char str1[] = "apple";
const char* str2 = "orange";
cout << str1 << endl; // 使用 char*,打印 C 字符串
cout << str2 << endl; // 使用 char*,打印 C 字符串
cout << (void*)str1 << endl; // 使用 void*,打印地址(C 风格转换)
cout << static_cast<void*>(str2) << endl; // 使用 void*,打印地址(C++ 风格转换)2.刷新输出缓冲区
你可以通过以下方式刷新输出缓冲区:
| 方式 | 代码 | 是否插入换行 | 是否刷新缓冲区 |
|---|---|---|---|
输出 \n |
cout << "hello\n"; |
✅ | ❌(可能不刷新) |
endl |
cout << "hello" << endl; |
✅ | ✅ |
flush |
cout << "hello" << flush; |
❌ | ✅ |
cout.flush() |
cout.flush(); |
❌ | ✅ |
性能提示:频繁使用 endl 会降低性能,因为每次都会强制刷新缓冲区。在普通文本输出中,优先使用 \n。
(1)flush 成员函数或操纵器
// ostream 类的成员函数 - std::ostream::flush
ostream& flush();
// 示例
cout << "hello";
cout.flush();
// 操纵器 - std::flush
ostream& flush(ostream& os);
// 示例
cout << "hello" << flush;(3)endl 操纵器
endl 插入换行符并刷新缓冲区。输出换行符 '\n' 可能不会刷新输出缓冲区,但 endl 会。
// 操纵器 - std::endl
ostream& endl(ostream& os);(3)cin 输入前自动刷新
当输入操作等待时,输出缓冲区会被自动刷新。例如:
#include <iostream>
#include <thread>
#include <chrono>
int main() {
std::cout << "Please enter a number: "; // 没有 endl,也没有 \n
// 此时输出可能还在缓冲区中,尚未显示
std::this_thread::sleep_for(std::chrono::seconds(2)); // 假设一些计算
int num;
std::cin >> num; // ⬅️ 在这里,输出缓冲区被自动刷新,提示信息才显示出来
return 0;
}原理:cin 与 cout 通过 tie() 关联在一起。当 cin 等待输入时,会自动调用 cout.flush()。
3.字符串输出与地址输出的区别
这是一个容易混淆的地方:
#include <iostream>
int main() {
char str[] = "Hello";
std::cout << str << std::endl; // 输出: Hello(字符串内容)
std::cout << static_cast<void*>(str) << std::endl; // 输出: 0x7ffd...(内存地址)
// 不加转换时,编译器选择 const char* 重载
// 加转换后,编译器选择 void* 重载
}七、istream 类
与 ostream 类类似,istream 类是 basic_istream<char> 的 typedef。它也支持格式化输入和非格式化输入。
- 格式化输入:通过重载的提取运算符
>>,将文本形式(字符流)转换为内部表示形式(如 16/32 位int、64 位double)。 - 非格式化输入:如
get()、getline()、read()等函数,按原样读取字符,不进行转换。
| 类型 | 函数 | 数据转换 | 典型用途 |
|---|---|---|---|
| 格式化输入 | >> |
文本 → 二进制 | 读取用户输入的数字、单词 |
| 非格式化输入 | get()、getline()、read() |
无转换 | 读取含空格的字符串、二进制数据 |
#include <iostream>
#include <string>
int main() {
int num;
char line[100];
// 格式化输入:自动将 "123" 转换为整数 123
std::cin >> num;
// 非格式化输入:原样读取字符,包括空格
std::cin.getline(line, 100);
return 0;
}1.重载的流提取运算符 >> 进行格式化输入
istream 类为每个 C++ 基本类型重载了提取运算符 >>:char、unsigned char、signed char、short、unsigned short、int、unsigned int、long、unsigned long、long long(C++11)、unsigned long long(C++11)、float、double 和 long double。它通过将输入的文本转换为相应类型的内部表示来执行格式化。
>> 运算符有几个重要特性:
| 特性 | 说明 | 示例 |
|---|---|---|
| 跳过前导空白 | 自动跳过空格、Tab、换行符 | 输入 " 123" → 读取 123 |
| 空格分隔 | 遇到空白字符停止读取 | 输入 "hello world" → 只读 "hello" |
| 类型转换 | 自动将文本转换为目标类型 | 输入 "3.14" → double 变量得到 3.14 |
| 错误处理 | 类型不匹配时设置失败状态 | 输入 "abc" 给 int → failbit 被设置 |
istream& operator>> (type&); // type 为 int、double 等>> 运算符返回对调用它的 istream 对象的引用。因此,你可以级联 >> 操作,例如:
cin >> number1 >> number2 >> ...;>>运算符还为以下指针类型重载:-
char*、signed char*、unsigned char*:用于输入 C 字符串。它使用空白字符作为分隔符,并为 C 字符串添加空终止字符。
使用 >> 读取 C 字符串(char*)是不安全的:
char buffer[10];
std::cin >> buffer; // ⚠️ 如果输入超过 9 个字符,会发生缓冲区溢出!推荐做法:
- 使用
std::string代替 C 字符串 - 或使用
setw()限制宽度:std::cin >> std::setw(10) >> buffer;
2.刷新输入缓冲区 - ignore()
你可以使用 ignore() 来丢弃输入缓冲区中的字符:
istream& ignore (int n = 1, int delim = EOF);
// 读取并丢弃最多 n 个字符,或直到遇到 delim 字符(以先到者为准)场景一:清除残留的换行符
int age;
std::string name;
std::cin >> age; // 输入年龄后按回车,换行符留在缓冲区
std::cin.ignore(); // 清除缓冲区中的换行符
std::getline(std::cin, name); // 现在可以正确读取姓名(可能包含空格)场景二:跳过无效输入
int num;
std::cout << "Enter a number: ";
while (!(std::cin >> num)) {
std::cin.clear(); // 清除错误状态
std::cin.ignore(10000, '\n'); // 丢弃错误的输入
std::cout << "Invalid, try again: ";
}场景三:忽略整行
// 跳过当前行的剩余内容
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');3.cin >> 与 getline() 混用的常见陷阱
#include <iostream>
#include <string>
int main() {
int age;
std::string name;
std::cout << "Age: ";
std::cin >> age; // 用户输入: 25[Enter]
// 缓冲区: "25\n"
std::cout << "Name: ";
std::getline(std::cin, name); // ⚠️ 读取到的是空字符串!
// 因为 getline 读取了残留的 '\n'
// 解决方法:在 getline 前调用 ignore
// std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
return 0;
}八、 非格式化输入/输出函数
本段介绍 C++ 中非格式化 I/O 的核心函数。与格式化 I/O(<< 和 >>)不同,这些函数处理的是原始字节,不进行任何转换。
1.输入函数对比:get() vs getline() vs read()
| 函数 | 分隔符处理 | 是否保留分隔符 | 是否添加 \0 |
适用场景 |
|---|---|---|---|---|
get(char*, n, delim) |
遇到 delim 停止 | ✅ 保留在流中 | ✅ 是 | 需要查看分隔符的场景 |
getline(char*, n, delim) |
遇到 delim 停止 | ❌ 丢弃 | ✅ 是 | 常规行读取(推荐) |
read(char*, n) |
读取固定数量 | 不适用 | ❌ 否 | 二进制数据读取 |
示例:
#include <iostream>
#include <cstring>
int main() {
char buffer[100];
// get() 保留分隔符
std::cin.get(buffer, 100, '\n');
std::cout << "get(): " << buffer << std::endl;
// 需要手动处理残留的分隔符
std::cin.get(); // 消耗掉 '\n'
// getline() 丢弃分隔符
std::cin.getline(buffer, 100);
std::cout << "getline(): " << buffer << std::endl;
return 0;
}2. put() 与 write() 的区别
| 函数 | 输出内容 | 停止条件 | 典型用途 |
|---|---|---|---|
put(char) |
单个字符 | 输出一个字符 | 逐字符输出 |
write(buf, n) |
n 个字符 | 输出指定数量 | 二进制输出、固定长度块 |
#include <iostream>
int main() {
// put() - 单个字符
std::cout.put('H').put('i').put('\n');
// write() - 固定数量
char data[] = "Hello\0World"; // 包含空字符
std::cout.write(data, 11); // 输出 "HelloWorld"(空字符也会输出)
// 二进制数据输出
int num = 0x12345678;
std::cout.write(reinterpret_cast<char*>(&num), sizeof(num));
return 0;
}3. gcount() 的重要作用
gcount() 通常用于检查实际读取了多少数据:
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("data.bin", std::ios::binary);
char buffer[256];
file.read(buffer, sizeof(buffer));
std::streamsize bytesRead = file.gcount(); // 实际读取的字节数
std::cout << "尝试读取: " << sizeof(buffer) << " 字节" << std::endl;
std::cout << "实际读取: " << bytesRead << " 字节" << std::endl;
return 0;
}4. peek() 和 putback() 的典型用法
这两个函数用于前瞻和回退,在解析复杂格式时非常有用:
#include <iostream>
#include <cctype>
int main() {
char ch;
std::cout << "输入一个数字或字母: ";
ch = std::cin.peek(); // 偷看下一个字符,但不提取
if (std::isdigit(ch)) {
std::cin >> ch; // 确认是数字,正式读取
std::cout << "你输入了数字: " << ch << std::endl;
} else {
std::cin.get(ch); // 读取并处理字母
std::cout << "你输入了字母: " << ch << std::endl;
}
// putback 示例:读取后放回
char c = std::cin.get();
std::cout << "读取到: " << c << std::endl;
std::cin.putback(c); // 放回去
std::cout << "放回去了,可以重新读取" << std::endl;
return 0;
}5. 函数关系图
非格式化输入函数
├── 单字符输入
│ ├── get() → 返回 int(可检测 EOF)
│ └── get(char&) → 返回 istream&
├── 字符串输入
│ ├── get(buf, n, delim) → 保留分隔符
│ └── getline(buf, n, delim) → 丢弃分隔符
├── 二进制输入
│ └── read(buf, n) → 固定数量,无转换
└── 辅助函数
├── gcount() → 查询上次读取数量
├── peek() → 前瞻
└── putback() → 回退
6. 常见陷阱与注意事项
| 陷阱 | 说明 | 解决方案 |
|---|---|---|
getline() 与 >> 混用 |
>> 留下换行符,导致 getline() 读空行 |
使用 cin.ignore() 清除 |
read() 没有 \0 终止 |
直接输出可能越界 | 手动添加终止符或记录长度 |
gcount() 的返回值 |
只对最后一次非格式化输入有效 | 在需要的结果后立即调用 |
get() 返回 int 而不是 char |
为了能返回 EOF(通常是 -1) |
用 int 变量接收,检查 EOF |
九、流的状态
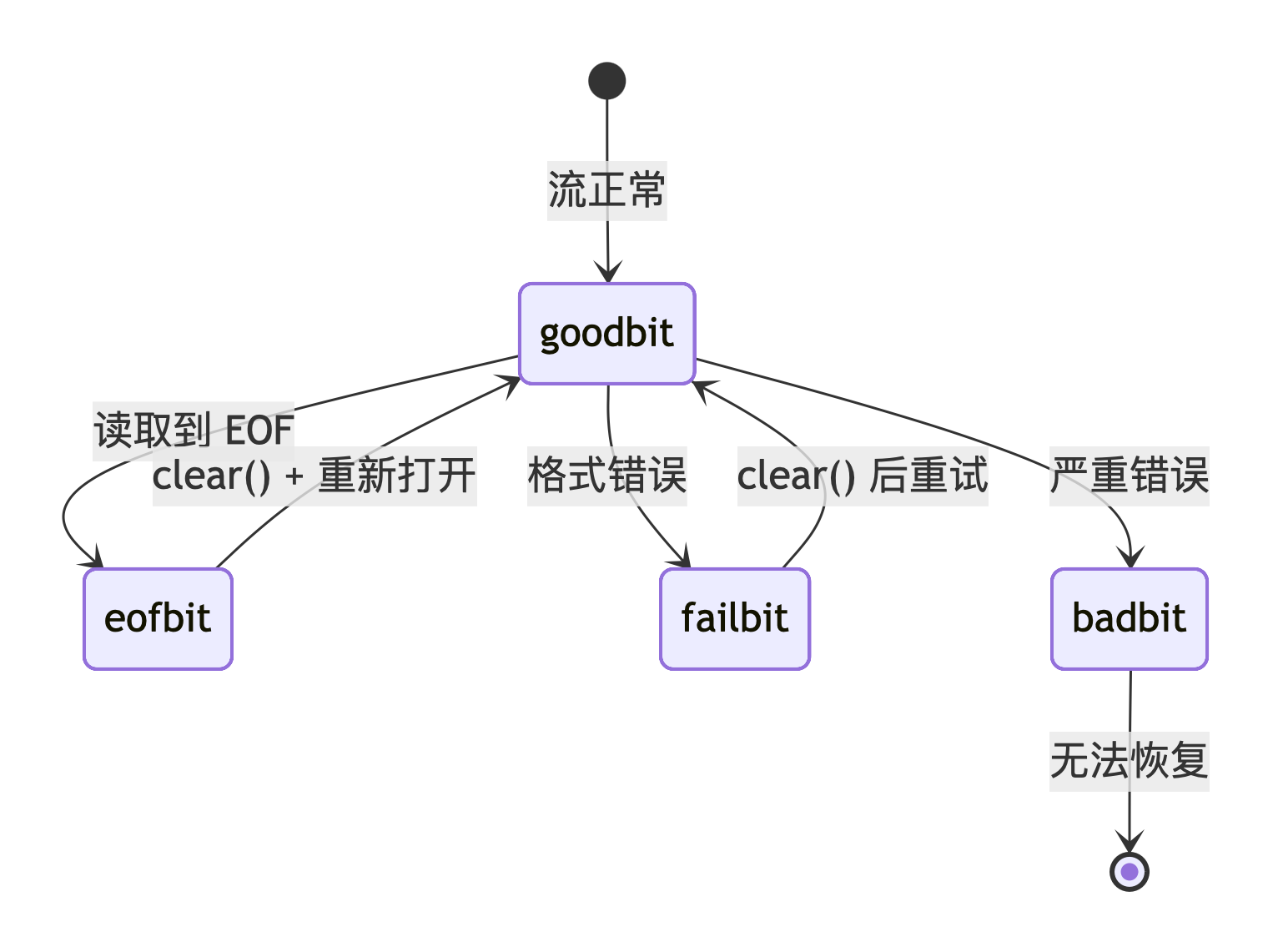
流超类 ios_base 维护一个数据成员来描述流的状态,这是一个类型为 iostate 的位掩码。标志包括:
eofbit:当输入操作到达文件末尾时设置。failbit:上一次输入操作未能读取预期的字符,或输出操作未能写入预期的字符时设置。例如,getline()在未遇到分隔符的情况下读取了n个字符。badbit:由于 I/O 操作失败(如文件读/写错误)或流缓冲区出现问题而导致的严重错误。goodbit:上述错误都不存在,值为 0。
这些标志在 ios_base 中声明为公共静态成员。可以通过 ios_base::failbit 直接访问,也可以通过子类如 cin::failbit、ios::failbit 访问。
然而,更方便的方式是使用 ios 类的以下公共成员函数:
| 成员函数 | 说明 |
|---|---|
good() |
如果设置了 goodbit(即无错误),返回 true |
eof() |
如果设置了 eofbit,返回 true |
fail() |
如果设置了 failbit 或 badbit,返回 true |
bad() |
如果设置了 badbit,返回 true |
clear() |
清除 eofbit、failbit 和 badbit |
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("data.txt");
int num;
file >> num;
// 检查流状态
if (file.good()) {
std::cout << "读取成功: " << num << std::endl;
}
if (file.eof()) {
std::cout << "到达文件末尾" << std::endl;
}
if (file.fail()) {
std::cout << "读取失败(格式错误或数据不足)" << std::endl;
}
if (file.bad()) {
std::cout << "严重错误(流损坏)" << std::endl;
}
return 0;
}1. 四种状态标志的含义
| 标志 | 含义 | 典型触发场景 | 是否可恢复 |
|---|---|---|---|
goodbit |
一切正常 | 无任何错误 | - |
eofbit |
到达文件末尾 | 读取到 EOF | 通常需要重新打开流 |
failbit |
逻辑错误 | 输入 "abc" 到 int 变量;getline 读到最大长度而未遇分隔符 |
✅ 可清除后重试 |
badbit |
严重错误 | 文件损坏、磁盘错误、流缓冲区不可用 | 通常无法恢复 |
2.状态标志的关系
good() == true ⇔ goodbit 被设置(无任何错误)
good() == false ⇔ eofbit 或 failbit 或 badbit 被设置
fail() == true ⇔ failbit 或 badbit 被设置(不包含 eofbit)
bad() == true ⇔ badbit 被设置
eof() == true ⇔ eofbit 被设置3.状态转换图
这是最经典的用法——在输入失败时恢复:
#include <iostream>
#include <limits>
int main() {
int age;
std::cout << "请输入年龄: ";
while (!(std::cin >> age)) {
// 输入失败:failbit 被设置
if (std::cin.eof()) {
std::cout << "输入流已关闭" << std::endl;
return 1;
}
std::cout << "无效输入,请输入数字: ";
// 清除 failbit
std::cin.clear();
// 丢弃错误的输入行
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
}
std::cout << "年龄是: " << age << std::endl;
return 0;
}4. clear() 的多种用法
#include <iostream>
int main() {
int num;
std::cin >> num;
// 清除所有错误标志
std::cin.clear();
// 清除特定标志(保留其他)
std::cin.clear(std::cin.rdstate() & ~std::ios::failbit);
// 设置特定状态
std::cin.clear(std::ios::eofbit);
return 0;
}5. 常见陷阱:eof() 与 fail() 的区别
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("numbers.txt");
int num;
// ❌ 错误的循环条件
while (!file.eof()) { // 陷阱:eofbit 在尝试读取后才会设置
file >> num;
std::cout << num << std::endl; // 可能多输出一次
}
// ✅ 正确的循环条件
while (file >> num) { // 读取成功才进入循环
std::cout << num << std::endl;
}
// 等价写法
while (true) {
file >> num;
if (file.fail()) break; // 读取失败(包括 eof)时退出
std::cout << num << std::endl;
}
return 0;
}6. rdstate() 获取原始状态
#include <iostream>
int main() {
int num;
std::cin >> num;
std::ios::iostate state = std::cin.rdstate();
if (state & std::ios::eofbit) {
std::cout << "EOF" << std::endl;
}
if (state & std::ios::failbit) {
std::cout << "FAIL" << std::endl;
}
if (state & std::ios::badbit) {
std::cout << "BAD" << std::endl;
}
return 0;
}十、格式化输入/输出
C++ 提供了一组操纵器来执行输入和输出格式化:(更详细的介绍可参考C++ 《iomanip》库全方位详解)
<iomanip>头文件:setw()、setprecision()、setbase()、setfill()<iostream>头文件:fixed/scientific、left/right/internal、boolalpha/noboolalpha等
1. 操纵器分类汇总
| 类别 | 操纵器 | 头文件 | 粘性 | 说明 |
|---|---|---|---|---|
| 字段控制 | setw(n) |
<iomanip> |
❌ | 设置字段宽度 |
setfill(c) |
<iomanip> |
✅ | 设置填充字符 | |
left/right/internal |
<iostream> |
✅ | 设置对齐方式 | |
| 浮点数 | setprecision(n) |
<iomanip> |
✅ | 设置精度 |
fixed/scientific |
<iostream> |
✅ | 设置格式模式 | |
showpoint/noshowpoint |
<iostream> |
✅ | 是否显示尾随零 | |
| 整数进制 | dec/hex/oct |
<iostream> |
✅ | 设置进制 |
setbase(n) |
<iomanip> |
✅ | 设置进制 | |
showbase/noshowbase |
<iostream> |
✅ | 显示进制前缀 | |
uppercase/nouppercase |
<iostream> |
✅ | 大写输出 | |
| 正号 | showpos/noshowpos |
<iostream> |
✅ | 显示正号 |
| 布尔值 | boolalpha/noboolalpha |
<iostream> |
✅ | true/false 或 0/1 |
2. 粘性(Sticky)vs 非粘性(Non-sticky)
这是使用操纵器时最容易出错的地方:
// setw() 是非粘性的
cout << setw(10) << 123 << 456 << endl; // 输出: " 123456"
// 只有 123 使用了宽度 10,456 使用默认宽度
// 其他操纵器是粘性的
cout << hex << 123 << " " << 456 << endl; // 输出: "7b 1c8"
cout << dec << endl; // 需要手动恢复3. internal 对齐方式的特殊用途
internal 对齐在显示带符号的数字时非常有用:
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
cout << showpos;
cout << setfill('0');
cout << internal << setw(8) << 123 << endl; // +0000123
cout << internal << setw(8) << -456 << endl; // -0000456
// 符号左对齐,数字右对齐
return 0;
}4. 浮点数格式的精度陷阱
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double pi = 3.14159265358979;
// 默认模式:总有效数字 4 位
cout << setprecision(4) << pi << endl; // 3.142
// fixed 模式:小数点后 4 位
cout << fixed << setprecision(4) << pi << endl; // 3.1416
// scientific 模式:小数点后 4 位
cout << scientific << setprecision(4) << pi << endl; // 3.1416e+00
return 0;
}5. 进制与 showbase 的组合效果
| 进制 | noshowbase(默认) |
showbase |
|---|---|---|
dec |
123 |
123 |
hex |
7b |
0x7b |
oct |
173 |
0173 |
cout << showbase;
cout << dec << 123 << endl; // 123
cout << hex << 123 << endl; // 0x7b
cout << oct << 123 << endl; // 01736. 保存和恢复格式状态
当需要临时改变格式时,最好保存当前状态:
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
// 保存当前格式状态
ios::fmtflags old_flags = cout.flags();
int old_precision = cout.precision();
char old_fill = cout.fill();
// 临时更改格式
cout << hex << showbase << setw(10) << setfill('0') << 255 << endl;
// 恢复格式状态
cout.flags(old_flags);
cout.precision(old_precision);
cout.fill(old_fill);
cout << 255 << endl; // 恢复正常输出
return 0;
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)