用于 VoIP 隐写分析的校准感知跨视图注意力网络
Calibration-Aware Cross-View Attention Network for VoIP Steganalysis
用于 VoIP 隐写分析的校准感知跨视图注意力网络(CACVAN)
PyTorch implementation for VoIP steganalysis in low-bit-rate speech codecs.
1. 项目简介
本仓库开源了本人论文 Calibration-Aware Cross-View Attention Network for VoIP Steganalysis (CACVAN) 的 PyTorch 实现代码,目前这项研究还在进行中,欢迎感兴趣的研究者共同交流。
该工作面向 低比特率语音编解码场景下的 VoIP 隐写分析任务,重点关注在 低嵌入率、短语音片段以及复杂嵌入条件 下,隐写痕迹微弱、稀疏且容易被语音内容波动掩盖的问题。针对这些挑战,本文提出了一个融合 嵌入率感知数据增强、原始流/校准流双分支建模、跨视图特征交互以及混合注意力特征精炼 的深度神经网络框架。
2. 论文要解决的问题
VoIP 隐写,尤其是基于低比特率语音编解码器参数域(如 FCB 域)的隐写方法,具有较强隐蔽性和较大嵌入容量,因此给检测带来了较高难度。
现有方法在以下场景中仍然面临明显挑战:
- 低嵌入率场景:隐写扰动非常微弱,容易被自然语音内容变化淹没;
- 高嵌入率场景:重压缩校准过程可能引入额外结构失真,影响真实隐写特征建模;
- 短语音片段场景:有效判别线索更少,隐写特征更稀疏;
- 复杂实际场景:检测模型不仅要有较高精度,还要具备稳定性、鲁棒性和一定实时性。
为此,本项目提出 CACVAN,从数据增强、特征提取、跨流交互和特征精炼多个层面提升 VoIP 隐写分析性能。
3. 方法概述
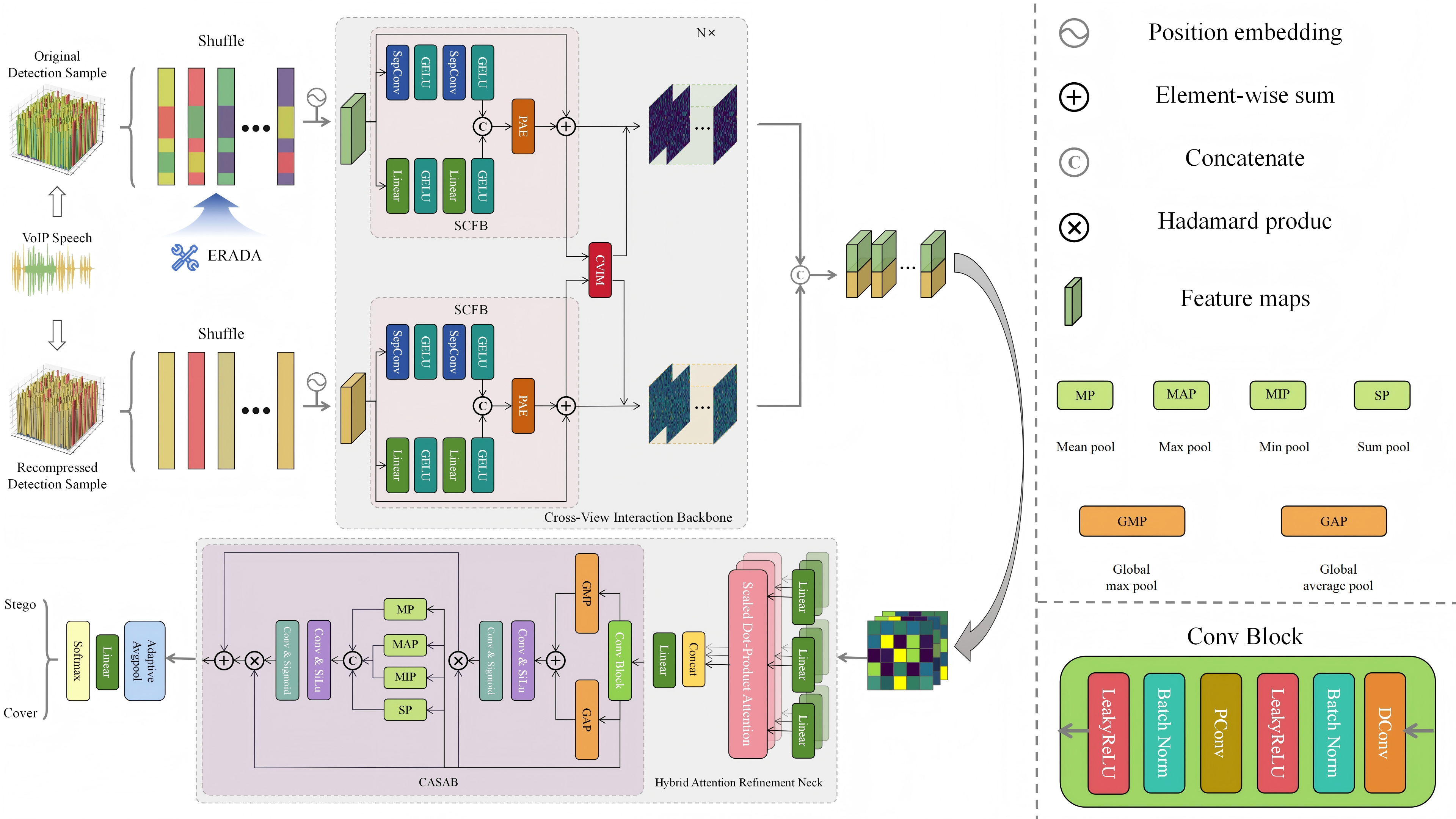
CACVAN 主要由四个部分组成:
3.1 ERADA:嵌入率感知数据增强模块
在训练阶段,引入基于 CutMix 的跨嵌入率样本混合策略,对不同嵌入率样本进行局部重组与融合:
- 增强低嵌入率样本中的弱隐写特征;
- 缓解高嵌入率样本在校准过程中可能带来的形变偏差;
- 提升模型面对嵌入率失配时的鲁棒性。
3.2 CVIB:跨视图交互骨干网络
网络采用 双分支结构:
- 一条分支处理 原始语音流(original stream)
- 一条分支处理 校准语音流(calibration stream)
每个分支通过层级化特征提取模块逐步学习判别表示,并在多个层级插入 跨视图交互模块(CVIM),实现原始流与校准流之间的信息交换,从而更有效地建模结构一致性与隐写扰动之间的细微差异。
3.3 HARN:混合注意力特征精炼模块
在双分支特征融合后,引入混合注意力模块进一步强化关键判别信息,包括:
- 通道注意力:增强对隐写敏感的特征通道;
- 空间注意力:聚焦局部关键扰动区域;
- 上下文建模:提升特征表达能力与稳定性。
3.4 SCH:分类头
最后使用分类头输出二分类结果,判断输入样本是否为隐写样本。
4. 模型整体流程
整体流程可以概括为:
- 输入成对样本:原始流 与 校准流
- 在训练阶段,可执行 嵌入率感知数据增强
- 原始流与校准流分别进入双分支骨干网络
- 在多个层级通过 CVIM 进行跨视图交互
- 将双分支特征拼接后送入注意力精炼模块
- 通过分类头输出最终隐写分析结果
5. 代码结构
当前仓库核心代码结构如下:
root/
├── data/
│ ├── __init__.py
│ └── data_loaders.py # 数据加载与增强
│
├── models/
│ ├── __init__.py
│ ├── models.py # 主模型定义(BIEN / CACVAN主体)
│ └── modules.py # 各类基础模块(EXT, CVIM, Attention, Classify等)
│
├── utils/
│ ├── __init__.py
│ ├── PlotCAM.py # 绘制CAM激活图
│ ├── PlotCOSINE.py # 绘制Cosine相似度图
│ ├── PlotHIST.py # 绘制特征直方图
│ ├── PlotTSNE.py # 绘制TSNE图
│ └── utils.py # 工具函数、CutMix、checkpoint保存等
│
├── modelWeight/ # 模型权重保存目录
│
├── dataset/ # 数据集文件(需自行准备)
│
├── main.py # 训练 / 测试入口
└── run.py # train / val / prediction 过程
6. 环境依赖
本项目基于 Python + PyTorch 实现,建议使用如下环境:
- Python 3.10.18
- PyTorch
- torchaudio
- NumPy
- Matplotlib
可以先按如下方式安装基础依赖:
conda env create -f environment.yaml
或者
pip install -r requirements.txt
如需复现实验,建议根据本机 CUDA 版本安装对应的 PyTorch 版本。
7. 数据准备
本项目使用 .npy 文件作为训练、验证和测试数据输入。
下载地址:BaiduNetDisk (PW: h3ts)。
数据文件的组织形式类似于:
./dataset/
├── data_{method}_{length}s_{em_rate}_train.npy
├── data_{method}_{length}s_{em_rate}_val.npy
├── data_{method}_{length}s_{em_rate}_test.npy
├── data_{method}_{length}s_RAND_train.npy
└── data_{method}_{length}s_RAND_val.npy
其中:
method:目标隐写方法,例如Geiser、Miao_enta1、Miao_enta2、Miao_enta4length:语音片段长度,如0.1~1.0em_rate:嵌入率,如10, 20, ..., 100RAND:用于嵌入率感知增强的混合样本文件
每条样本在加载后会被解析为三部分:
x:原始/目标样本特征re:校准样本特征y:类别标签
8. 训练
默认训练入口在 main.py 中。
8.1 基本训练示例
python main.py \
--method Miao_enta4 \
--mode sm_length \
--length 0.2 \
--em_rate 100 \
--epoch 40 \
--batch_size 8 \
--train True
8.2 嵌入率感知模式训练
当 mode=em_rate 时,训练和验证阶段会加载 RAND 数据,并执行基于 CutMix 的跨嵌入率样本增强:
python main.py \
--method Miao_enta4 \
--mode em_rate \
--length 0.2 \
--em_rate 100 \
--epoch 40 \
--batch_size 8 \
--train True
9. 测试
测试时将 train 设为 False,并指定模型权重:
python main.py \
--method Miao_enta4 \
--mode sm_length \
--length 0.2 \
--em_rate 100 \
--train False \
--model_path ./modelWeight/Miao_enta4/Length/2/ \
--model_weight epoch_12_best.pth.tar
程序会在测试结束后输出 Test Accuracy,并将结果保存到:
test_result.txt
10. 可视化分析
该项目还支持多种可视化分析选项,用于辅助理解模型特征表示。
10.1 T-SNE 可视化
python main.py --train False --TSNE True --TSNETYPE 2D
10.2 激活图可视化
python main.py --train False --Activation True
10.3 特征分布直方图
python main.py --train False --Hist True
10.4 余弦距离分析
python main.py --train False --Cosine True
11. 核心模块说明
11.1 BIEN / 主网络
主模型在 models.py 中定义,整体包括:
- Token Embedding
- Positional Encoding
- Original Backbone
- Calibration Backbone
- CVIM 跨视图交互模块
- Attention Neck
- Classification Head
11.2 EXT:分离卷积特征提取模块
EXT 模块结合了:
- 线性映射分支
- 深度可分离卷积分支
- 特征融合
- 自适应增强模块(PAEM)
- 残差连接与归一化
用于从 VoIP 参数序列中提取层级化判别特征。
11.3 CVIM:跨视图交互模块
CVIM 用于在原始流与校准流之间执行跨视图注意力交互,帮助模型从两种视角中提取互补信息。
11.4 混合注意力模块
颈部模块中引入通道注意力与空间注意力,对关键通道和关键区域进行重标定,提升对细粒度隐写痕迹的表达能力。
12. 实验设置说明
从当前代码默认参数来看,训练时主要支持如下设置:
- 隐写方法:
Geiser,Miao_enta1,Miao_enta2,Miao_enta4 - 语言类型:
Chinese,English - 样本长度:
0.1s ~ 1.0s - 嵌入率:
10% ~ 100% - 批大小:
8 - 默认 epoch:
40
你可以通过命令行参数灵活调整实验条件。
13. 项目特点
本项目具有以下特点:
- 基于 PyTorch 实现,结构清晰,便于复现与扩展;
- 支持 原始流 / 校准流双输入建模;
- 支持 嵌入率感知数据增强;
- 支持 跨视图交互建模;
- 支持多种 可视化分析工具;
- 适合用于 VoIP 隐写分析研究、论文复现与模型扩展实验。
14. 适用场景
该项目适用于以下方向的研究与实验:
- VoIP 隐写分析
- 低比特率语音编码参数安全分析
- 基于校准思想的隐写检测
- 多分支深度网络在语音安全任务中的应用
- 面向实时流式场景的轻量检测模型探索
15. Citation
如果你的研究或项目中使用了本仓库代码,欢迎引用相关论文:
@article{cacvan_voip_steganalysis,
title={Calibration-Aware Cross-View Attention Network for VoIP Steganalysis},
author={Muyuan Li},
journal={Ongoing research (研究进行中)},
year={2026}
}
16. Acknowledgement
本项目聚焦于低比特率语音编解码环境下的 VoIP 隐写分析问题。
感谢相关公开数据集、已有 VoIP 隐写/隐写分析研究工作以及 PyTorch 社区工具对本研究的支持。
17. TODO
后续可以继续完善的方向包括:
- 补充数据集构建说明
- 补充训练日志与实验结果表格
- 补充预训练权重下载方式
- 补充更详细的复现实验脚本
18. Contact
如果你对该项目感兴趣,欢迎通过 1186141415@qq.com 与仓库作者交流。
如果这篇文章对你有帮助,可以点个赞~
完整代码地址:https://github.com/1186141415/Calibration-Aware-Cross-View-Attention-Network-for-VoIP-Steganalysis

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)